Introduction: The Network Is No Longer a Supporting Actor
When Broadcom announced Tomahawk 6 (TH6) at 102.4 Tbps in late 2024 — the industry's first single-chip switch to break the 100T barrier — the signal was unmistakable: AI networking has evolved from "infrastructure" to "strategic weapon."
A year earlier, NVIDIA, building on the Mellanox legacy, rapidly captured market share with its Spectrum-X turnkey solution, surpassing $2 billion in quarterly revenue. Now the battlefield has expanded — from switch chips to optical packaging, from scale-up interconnects to full-rack delivery, from standards bodies to customer alignments.
One core trend is accelerating: Ethernet is eating InfiniBand's market. DriveNets' summary at OCP 2025 was blunt — Ethernet has definitively won Scale-Out and Scale-Across. The next battleground is Scale-Up: NVLink (NVIDIA proprietary) vs. SUE (Broadcom-led) vs. UALink (AMD-led). 2026 will be an exceptionally dynamic market.
This article provides a full-stack comparison from chip to system, neither shying away from technical detail nor ignoring commercial logic.
1. Chip-Level Comparison: Switch Chips
This is the core battlefield. Three chips, three strategies.
1.1 Parameter Overview
| Parameter | Broadcom TH6 | NVIDIA Spectrum-6 | NVIDIA Quantum-X800 |
|---|---|---|---|
| Switching Capacity | 102.4 Tbps | 102.4 Tbps (SN6810) | 115.2 Tbps |
| Architecture | Single chip + SerDes chiplet | Single Spectrum-X CPO package 51.2T | 4×Quantum-X CPO packages |
| Process Node | 3nm | Undisclosed | Undisclosed |
| Port Density | 64×1.6T / 128×800G / 512×200G | 128×800G | 144×800G |
| SerDes | 512×200G or 1024×100G | Undisclosed | Undisclosed |
| Routing | Cognitive Routing 2.0 | Spectrum-X integrated | SHARP v4 (14.4 TFLOPS in-network compute) |
| CPO Solution | Davisson DR optical engine | Silicon Photonics (COUPE) | Silicon Photonics |
| Ship Status | Shipping (incl. CPO version) | Expected 2026H2 | Expected early 2026 |
Key Observations:
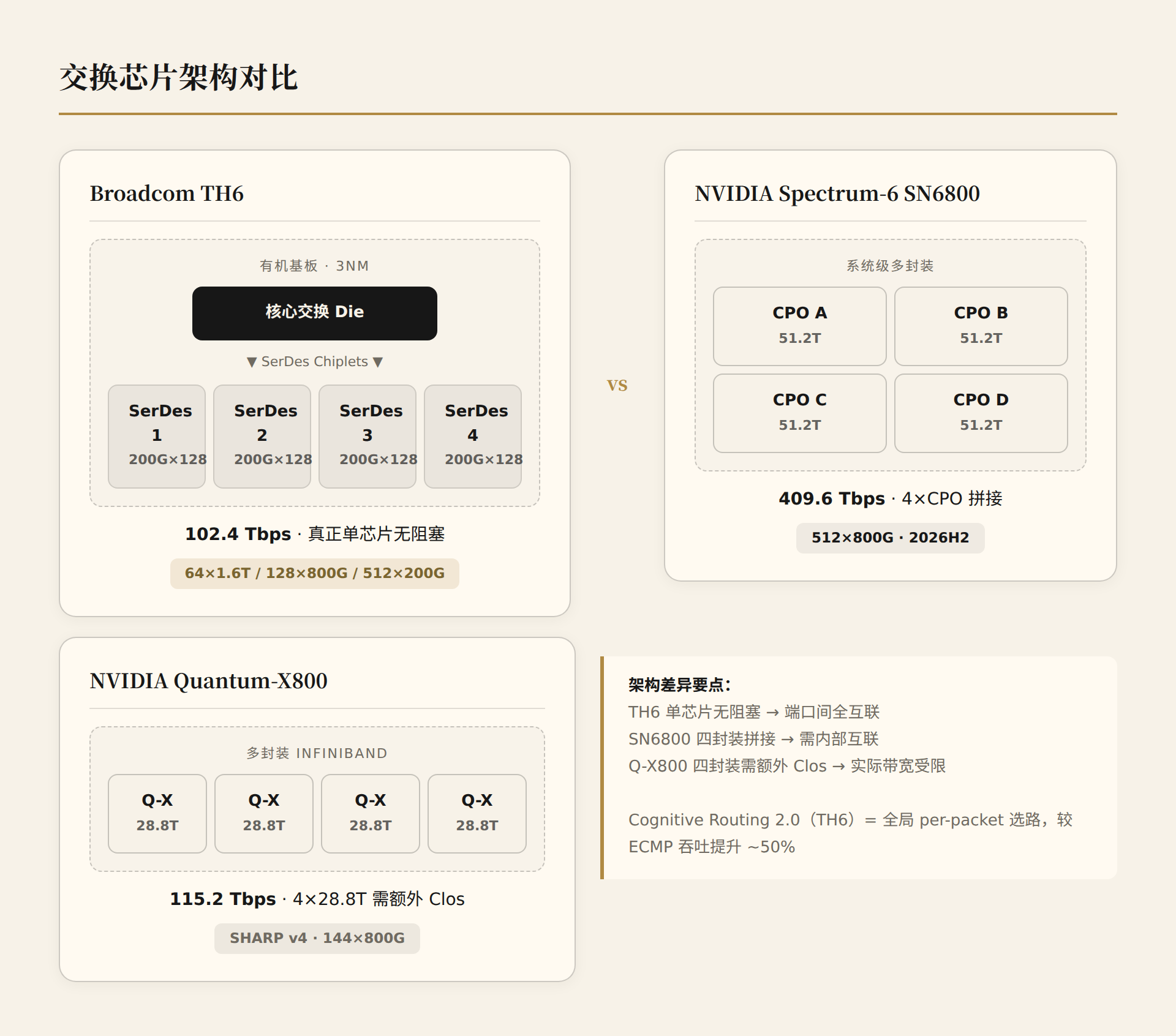
- TH6 is a true single-chip 102.4T, with a core switching die + SerDes chiplets on an organic substrate. This means non-blocking switching between all ports without additional Clos layers.
- NVIDIA Spectrum-6 SN6810 is also 102.4T, but the SN6800's 409.6T is assembled from 4 CPO packages — a multi-chip system, not a single chip.
- Quantum-X800's 115.2T comes from four 28.8T Quantum-X CPO packages. Four 28.8T chips don't constitute a true 115.2T non-blocking switch — additional Clos layers are needed for full interconnection. This is an architectural constraint, not just a marketing issue.
1.2 Architecture Comparison
1.3 Cognitive Routing 2.0: TH6's Secret Weapon
TH6 isn't just about bandwidth. Cognitive Routing 2.0 is Broadcom's major upgrade in software-defined routing:
- Global load balancing: Per-packet path selection based on real-time network-wide congestion information
- Compared to traditional ECMP static hash-based routing, throughput improves by approximately 50%
- This means TH6 can move more effective data on the same physical network
NVIDIA also integrates congestion control in Spectrum-X, but takes a different approach — relying more on end-to-end congestion signals and direct routing rather than switch-side global path selection.
2. NIC Comparison: The Starting Point of the Data Path
The NIC is the first hop from XPU to network, directly impacting actual AI training throughput.
| Parameter | Broadcom Thor Ultra | NVIDIA ConnectX-8 SuperNIC |
|---|---|---|
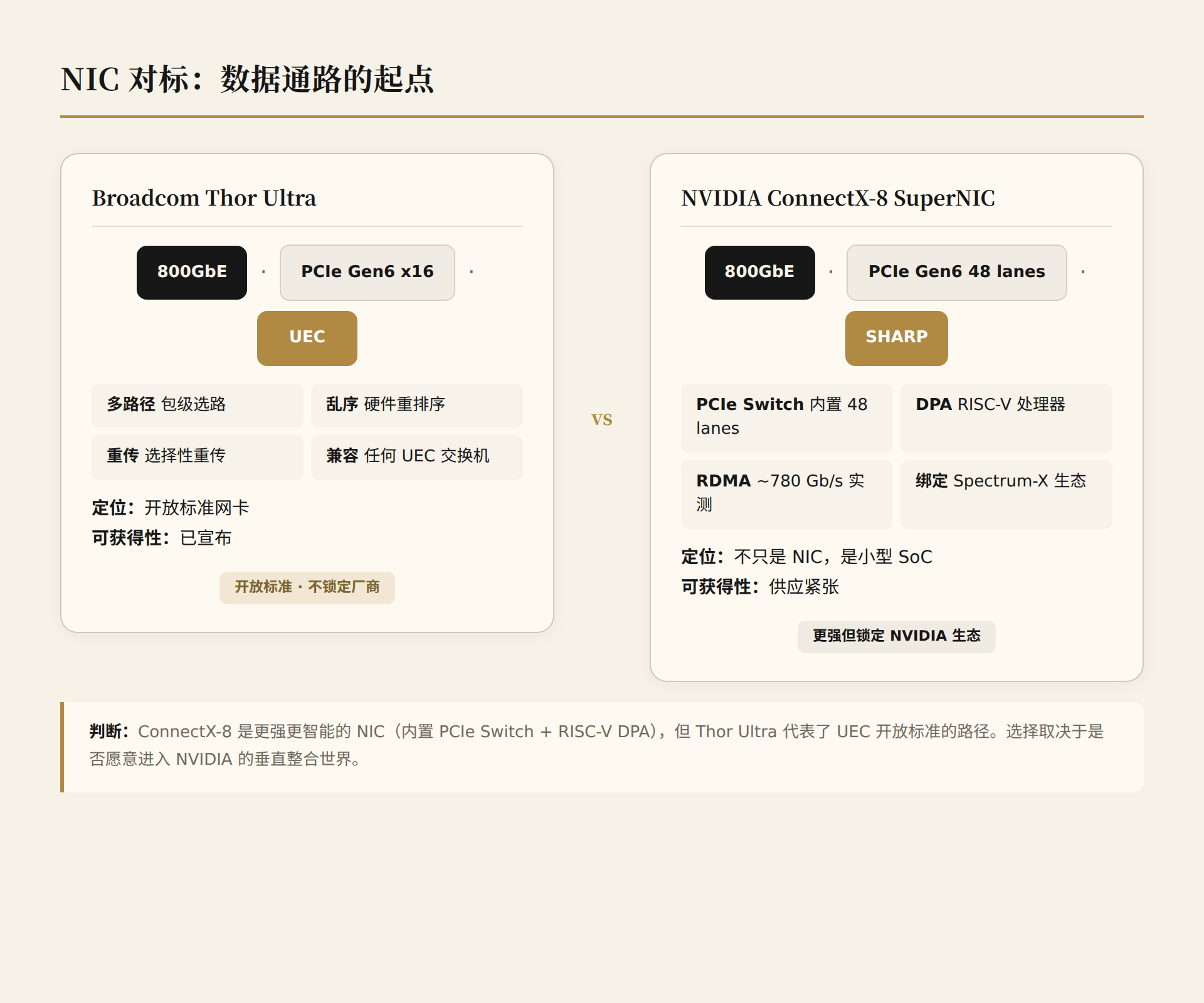
| Bandwidth | 800GbE | 800GbE |
| PCIe | Gen6 x16 | Gen6 (internal 48-lane Switch!) |
| UEC Support | Fully UEC-compliant | N/A (Spectrum-X/Quantum-X) |
| Key Features | Packet-level multipathing, out-of-order delivery, hardware selective retransmission | Built-in PCIe Switch, DPA (RISC-V), SHARP |
| Compatibility | Compatible with any UEC-standard switch | Locked to Spectrum-X or Quantum-X |
| Encryption | Embedded crypto acceleration | Integrated security engine |
| Availability | Announced | Supply constrained; media unable to obtain test samples |
Key Finding: ConnectX-8 Is More Than a NIC.
The most underrated feature of ConnectX-8 is its built-in PCIe Gen6 Switch (48 lanes). On the GB300 NVL72 platform, this switch simultaneously connects the Grace CPU (Gen5 x16), B300 GPU (Gen6 x16), and SSD (Gen5 x4). It's essentially a small SoC, not just a network interface.
Dell's real-world testing shows ConnectX-8 achieves near-800G line-rate RDMA — approximately 390 Gb/s per interface and ~780 Gb/s aggregated. This is strong practical performance.
But Thor Ultra's advantage lies in the UEC open standard. It supports packet-level multipathing, out-of-order delivery, and hardware selective retransmission — core UEC specification capabilities.
Judgment: ConnectX-8 is a stronger, smarter NIC, but Thor Ultra represents the open-standard path. The choice depends on whether you're willing to enter NVIDIA's vertically integrated world.
3. CPO Optical Solutions: Two Packaging Philosophies
CPO (Co-Packaged Optics) is mandatory in the 102.4T era — traditional pluggable optical modules can no longer keep up with power consumption and density requirements.

3.1 Broadcom Davisson: Simple, Compact, Non-Replaceable
- Optical engines permanently bonded to the switch chip on an organic substrate
- 16 Davisson DR optical engines, each at 6.4 Tbps
- Significant power advantage: ~5.4W/800G vs ~15W pluggable — approximately 65% savings
- Disadvantage: Optical engine failures cannot be field-replaced; port operates in degraded mode
3.2 NVIDIA Silicon Photonics: Modular, Maintainable, More Complex
- Uses TSMC COUPE process with EIC+PIC 3D stacking
- Removable OSA (Optical Sub-Assembly) modules
- Claims 10x reliability improvement and 3.5x power efficiency improvement
- Disadvantage: More complex packaging process, higher cost
3.3 The Third Path: LPO
Andy Bechtolsheim (Arista co-founder) continues to champion LPO (Linear Pluggable Optics) over CPO. If pluggable optical module power consumption can continue to be optimized, CPO's primary advantage disappears.
Judgment: Davisson's simplicity offers practical advantages in hyperscale deployment. NVIDIA's removable solution is better for operational friendliness. 2026 will be a coexistence validation period.
4. The Scale-Up Battle: AI Training's Decisive Contest
Scale-Up networking connects multiple XPUs within the same compute node and is the critical bottleneck for AI training performance.
4.1 Three Technical Paths
| Parameter | NVIDIA NVLink/NVL576 | Broadcom SUE (Tomahawk Ultra) | UALink |
|---|---|---|---|
| Bandwidth | 1.8 TB/s/GPU (NVLink 5) | 51.2 Tbps switching capacity | Not yet finalized |
| Latency | Extremely low (direct connect) | 250ns (switched) | TBD |
| Scale | NVL72 rack / 576 GPU logical unit | 1024 accelerators | 1024 accelerator target |
| Protocol | NVIDIA proprietary | Scale-Up Ethernet (optimized header 46B→10B) | Open standard |
| Maturity | Large-scale deployed (GB200/GB300) | Shipping (TH5 pin-compatible) | Standard development in progress |
| Standards Body | None (NVIDIA proprietary) | ESUN (OCP) | UALink Consortium |

4.2 Key Analysis
NVLink's moat is latency and maturity. Direct-connect interconnect latency is inherently lower than switched approaches.
Tomahawk Ultra's killer feature is scale. 250ns latency is sufficient for a 1024-accelerator Scale-Up domain. Optimized Ethernet frames (header compressed from 46B to 10B) dramatically improve efficiency.
ESUN is the new variable. Broadcom pivoted to ESUN after leaving the UALink board — suggesting it prefers solving Scale-Up within the Ethernet framework.
5. System-Level Comparison: From Rack to Turnkey
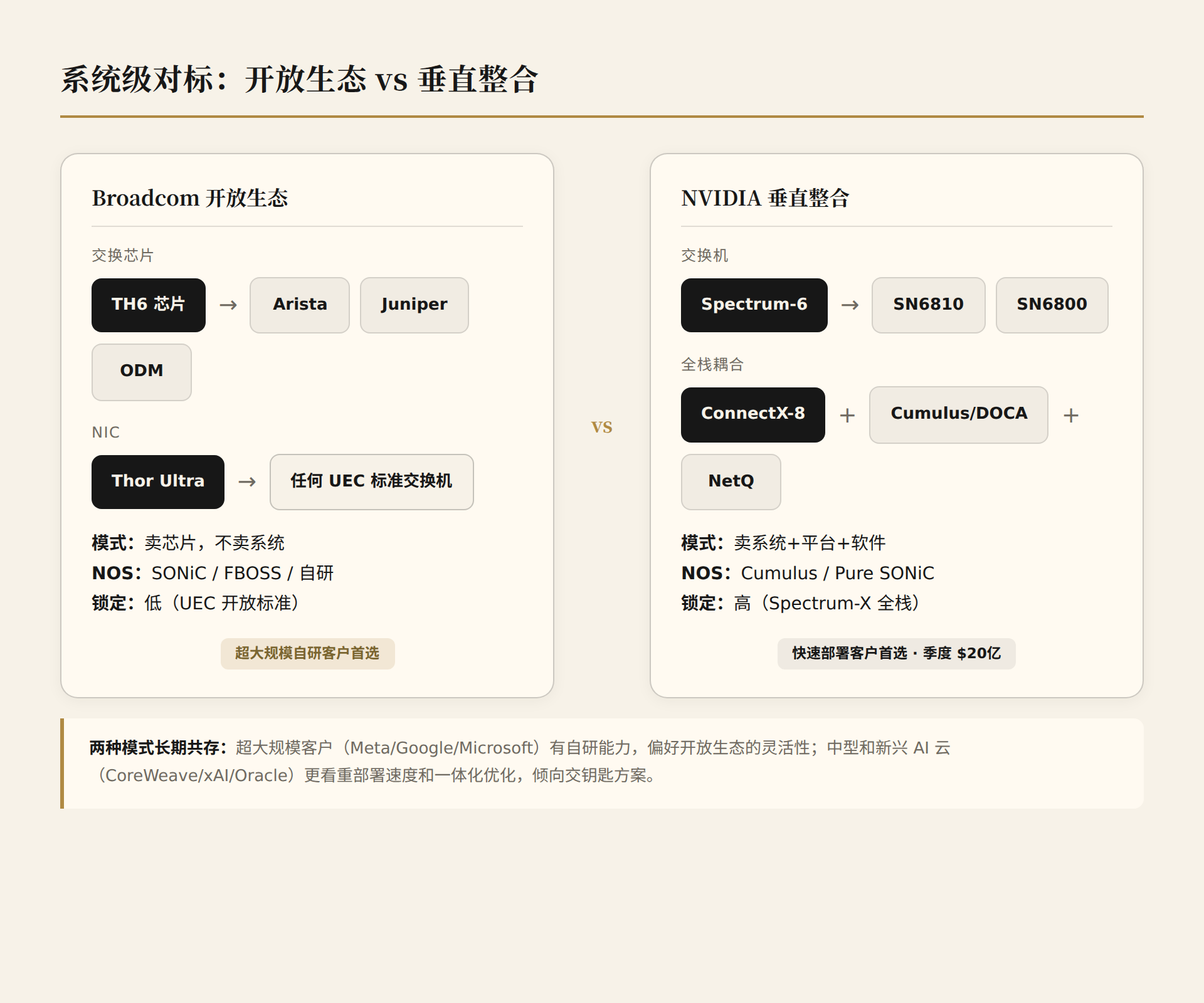
5.1 Broadcom Camp: Open Ecosystem
Broadcom sells chips, enabling Arista, Juniper, Wistron, Wiwynn, Delta to build switches. High flexibility, but integration work falls on the customer.
5.2 NVIDIA Camp: Vertical Integration
Spectrum-X is a turnkey solution: switches + NICs + software as one package. Revenue: $2 billion per quarter.
5.3 Comparison
6. Deployment Case Analysis
6.1 Meta: From Self-Developed to Hybrid
- Traditional: FBOSS + Minipack switches (Broadcom chips)
- New: Adopting Spectrum-X while maintaining FBOSS — a multi-vendor strategy
- Also evaluating Davisson CPO solution
6.2 Oracle: NVIDIA's Showcase Customer
Building giga-scale AI factories with Spectrum-X on Vera Rubin architecture.
6.3 CoreWeave and xAI: Speed First
Core requirement is rapid deployment, maximizing GPU utilization — exactly where Spectrum-X excels.
6.4 Hyperscale TH6 Deployments
Multiple 100,000+ accelerator-scale TH6 deployments in planning through Arista, Juniper, and ODM partners.
7. Ecosystem and Strategy: Open vs. Closed
7.1 Standards Body Dynamics
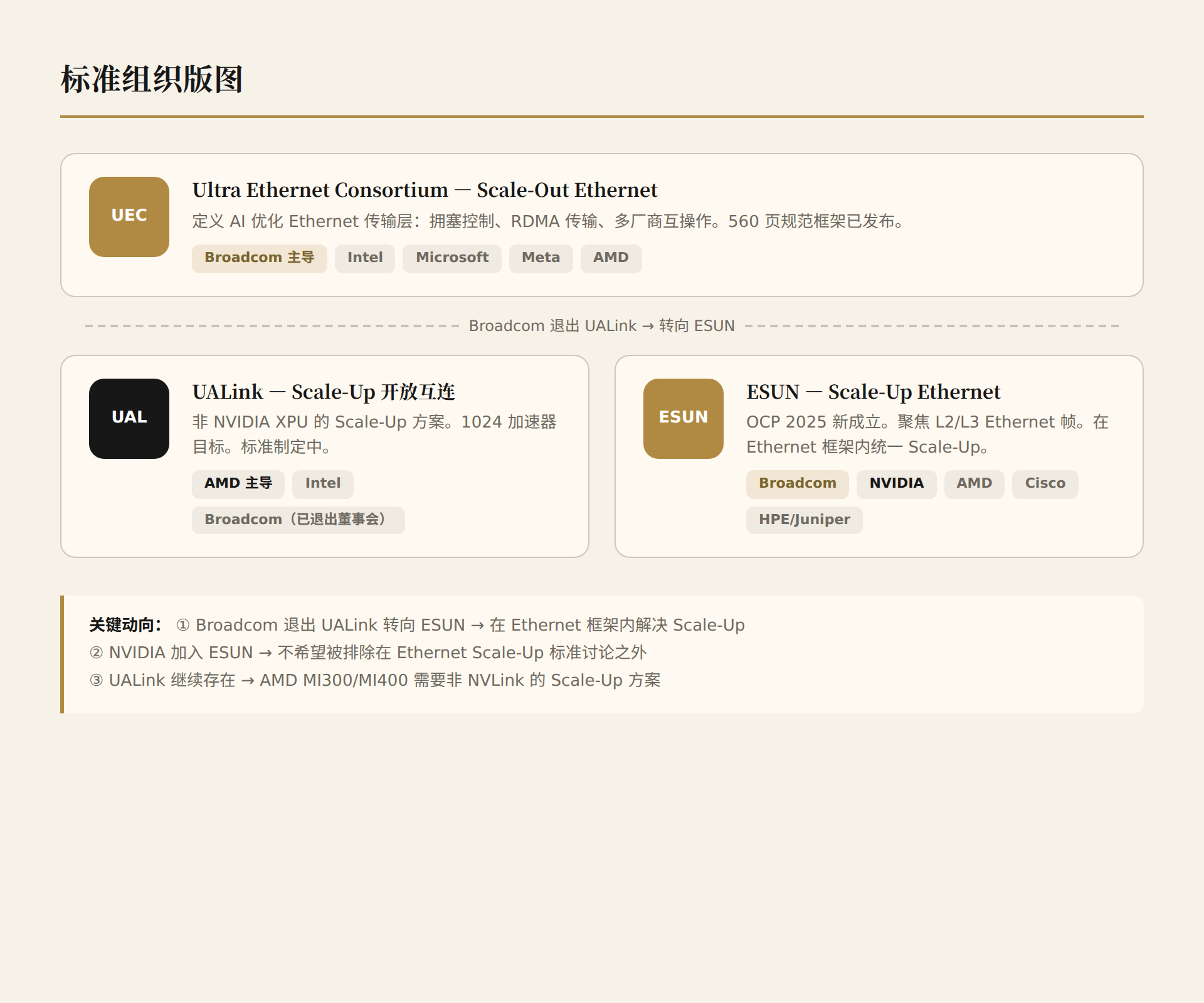
- Broadcom left UALink → pivoted to ESUN — unify Scale-Up/Scale-Out within Ethernet
- NVIDIA joined ESUN — doesn't want to be excluded from Ethernet Scale-Up discussions
- UALink continues — AMD's MI300/MI400 needs a non-NVLink Scale-Up solution
7.2 Business Model Differences
| Dimension | Broadcom | NVIDIA |
|---|---|---|
| Core Business | Sell chips | Sell systems + platforms |
| Lock-in Level | Low (UEC standard) | High (Spectrum-X full stack) |
| Customer Profile | Hyperscale self-build | Fast-deployment customers |
8. Conclusions: 2026 AI Networking Market Landscape
8.1 Six Core Judgments
1. Ethernet won Scale-Out; InfiniBand retreats to HPC.
2. TH6's 102.4T single chip is genuine technical leadership. True single-chip non-blocking 102.4T with Cognitive Routing 2.0.
3. Scale-Up is the most consequential battlefield in 2026. NVLink has maturity, but SUE's 1024-accelerator scale and Ethernet compatibility are real differentiation.
4. CPO will become standard for 100T+ switches, but the packaging route is unsettled. 2026 will be a coexistence validation period.
5. Open ecosystem and vertical integration will coexist long-term.
6. Supply capacity is a hidden competitive dimension. ConnectX-8 supply constraints are a real concern.
8.2 2026 Market Landscape Forecast

8.3 Recommendations for Decision-Makers
- Hyperscale cloud providers: TH6 + Thor Ultra + UEC for maximum flexibility
- AI cloud startups: Spectrum-X turnkey for fastest time-to-production
- Networking equipment vendors: TH6 is the 2026 baseline platform
- Investors: Watch ESUN standard progress and Broadcom's Scale-Up deployment velocity
This article is based on publicly available technical documentation, OCP 2025 Global Summit information, vendor announcement data, and industry analysis reports. All data as of May 2025.