Part 3 · Lingqu Software Deep Dive Series
The first two articles analyzed Lingqu's kernel layer and service layer. The kernel layer lets Linux see super-node hardware; the service layer coordinates 8,192 cards working together. Users don't directly operate either layer—they use Kubernetes.
The cloud layer answers the question: how do you expose Lingqu's hardware and service layer capabilities to users through K8s standard interfaces? The answer is openFuyao. It's not part of Lingqu per se, but whether Lingqu can break out of the Huawei ecosystem depends heavily on how well openFuyao performs.
1. openFuyao's Positioning: More Than Just Another K8s Distribution
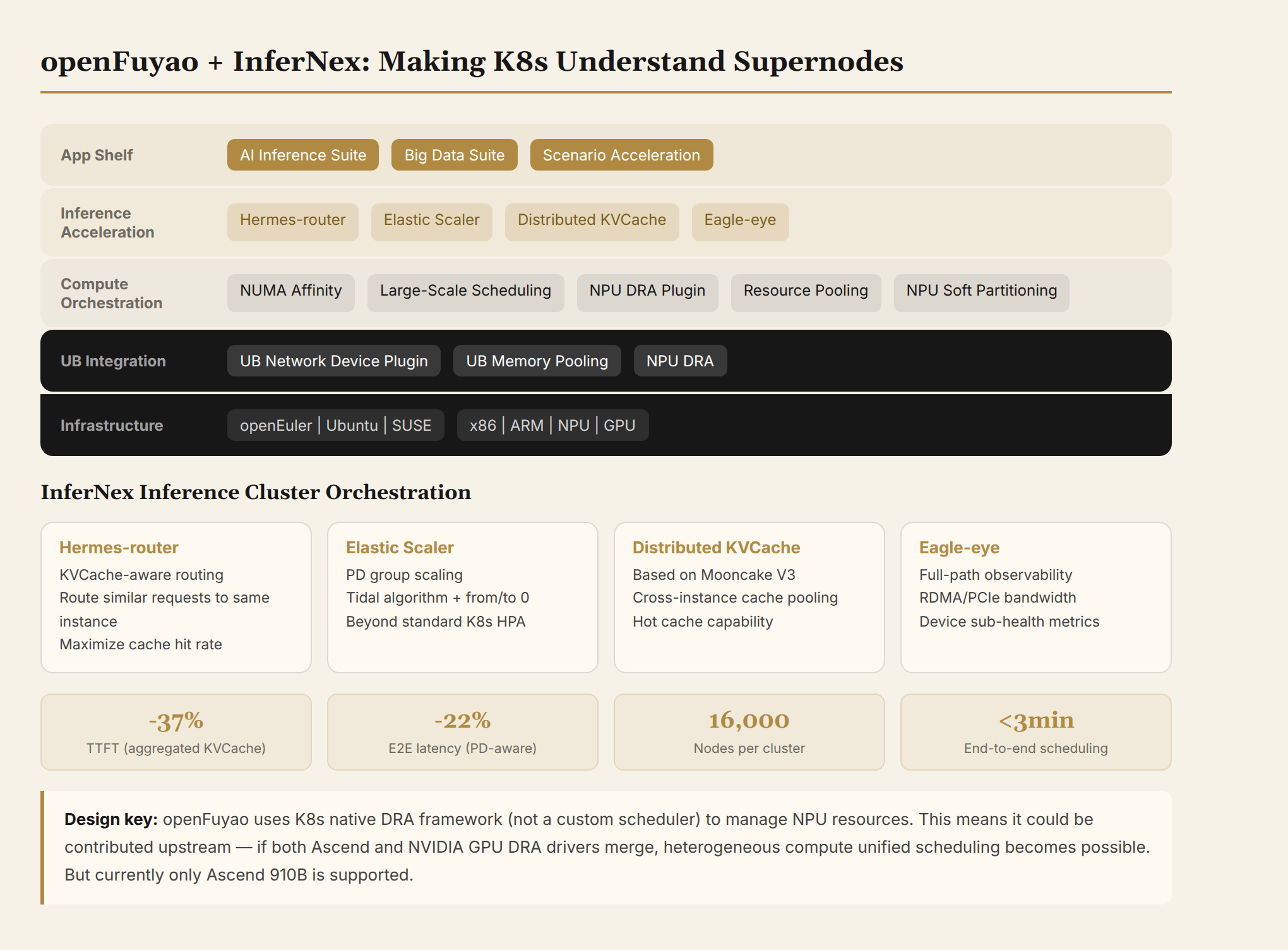
openFuyao's official site (openfuyao.cn) positions itself as "an open-source community for software technology innovation in general-purpose and intelligent computing clusters." In plain terms: a K8s distribution + a diverse-compute scheduling enhancement layer.
Its five-layer architecture:
┌────────────────────────────────────────────────────────┐
│ Application Shelf: AI Inference Suite / Big Data Suite / Scenario Acceleration Suite │
├──────────────┬───────────────────┬─────────────────────┤
│ AI Inference Acceleration │ Big Data Acceleration │ Container Platform │
│ InferNex │ │ Console/Auth/Monitoring │
├──────────────┴───────────────────┴─────────────────────┤
│ Compute Release Innovation Components │
│ NUMA Affinity / Ultra-Large-Scale Clusters / Online-Offline Co-scheduling / Distributed Jobs │
│ KAE Operator / NPU Operator / Resource Pool / NPU Soft Partitioning │
├────────────────────────────────────────────────────────┤
│ Scheduling Components: Container Orchestration Engine (K8s) + Container/Network/Storage Runtimes │
├────────────────────────────────────────────────────────┤
│ OS: openEuler | SUSE | Ubuntu | ... │
│ Compute: x86 | ARM | CPU | NPU | GPU | ... │
└────────────────────────────────────────────────────────┘
The bottom layer claims support for x86 + ARM + CPU + NPU + GPU. Not just Huawei's Kunpeng and Ascend. At least in positioning, openFuyao aims to be a cross-hardware scheduling layer.
Release cadence: one major version every six months. v25.06 was the inaugural release, v25.12 the first LTS (K8s 1.34, 16,000-node cluster deployed), v26.03 the current latest (InferNex comprehensive upgrade + Lingqu UB integration + NPU DRA plugin).
2. Lingqu UB Integration: Translating Hardware Capabilities into K8s Language
v26.03 added three K8s-native components that interface directly with Lingqu hardware.
2.1 UB Container Network Device Plugin
Adapts Lingqu URMA devices. Containers can directly use Lingqu communication capabilities with 1.7–2.5μs latency, 90% lower than TCP.
User side: declare the need for URMA devices in the Pod spec; the scheduler automatically finds nodes with Lingqu capabilities and mounts the device into the container. Applications inside the container use the URMA API for communication without needing to know whether the underlying transport is Lingqu or RDMA.
2.2 UB Memory Pooling
Two capabilities:
Memory borrowing. When a node's memory utilization reaches a threshold, it automatically borrows memory from other nodes. The optimal borrowing ratio is 25%, with performance overhead <5%. Completely transparent to applications—the allocator thinks it's using local memory, which may actually come from three cabinets away.
Memory sharing. Cross-node, cross-process memory block import and export. Shared memory access latency is 300–400ns. First mapping takes 2–5s; subsequent access uses the Lingqu hardware path.
K8s side: declare the need for UB memory pooling capability in the Pod spec; openFuyao automatically configures memory borrowing and sharing. No need to manually configure NUMA policies or memory affinity.
2.3 NPU DRA Plugin
Based on the DRA (Dynamic Resource Allocation) framework introduced in K8s 1.26+. Automatically discovers Ascend NPUs, collects ID/memory/network topology information, and uses CEL expressions for fine-grained NPU resource allocation.
This design decision is important: using K8s-native DRA rather than a custom scheduler.
NVIDIA's GPU allocation currently follows the device-plugin + custom scheduling extension path. If both the Ascend NPU DRA driver and the NVIDIA GPU DRA driver are merged into the K8s upstream, heterogeneous compute unified scheduling would have a foundation—one cluster running both Ascend and NVIDIA GPUs, managed by the same K8s scheduling framework.
However, it currently only supports the Ascend 910B series. An NVIDIA GPU DRA driver doesn't exist yet. For the DRA approach to truly change the landscape, DRA drivers from at least two chip vendors need to be merged upstream.
3. InferNex: Inference Cluster-Level Orchestration—openFuyao's Most Commercially Valuable Component
3.1 The Main Battlefield of Inference Optimization Has Moved to the Cluster Level
In 2026, inference compute demand far exceeds training. But the main battlefield of inference optimization has already moved from the single-card level to the cluster level.
Once single-card optimization reaches its limit, the bottlenecks become:
- How are requests routed to the most suitable inference instance? (KV Cache hit rate)
- How do Prefill and Decode instances scale on demand? (PD disaggregation architecture)
- How is KV Cache shared across multiple inference instances? (distributed caching)
InferNex solves exactly these three problems. It's not an inference engine itself, but rather the scheduling/routing/caching orchestration layer above inference engines.
3.2 Architecture Breakdown
Hermes-router (intelligent routing). KVCache-aware, bucketing strategy, Pod-level state awareness. Core idea: route similar requests to the same inference instance to maximize KV Cache hit rate.
This approach is similar to vLLM's prefix caching, but implemented at the cluster level rather than the single-instance level. Hermes-router knows which prefixes each inference instance currently has cached; when a new request arrives, it routes to the instance with the highest cache hit probability.
Elastic Scaler. A dedicated scaler for PD disaggregation scenarios. Tidal algorithms, group-based scaling, from/to-0 elasticity. Key capability: scaling by group (forming Prefill+Decode groups)—standard K8s HPA cannot do this because HPA doesn't understand the pairing relationship between Prefill and Decode.
Distributed KVCache. Cross-instance KVCache pooled storage and transport based on Mooncake. Hot cache capability—within a fixed memory budget, placing high-frequency KV Cache in faster storage tiers.
Eagle-eye (full-chain observability). Business runtime state → system runtime state → hardware health. Collects RDMA bandwidth, PCIe bandwidth, device sub-health metrics.
Inference backend. One-click deployment of cloud-native inference engines based on vLLM/vLLM-Ascend.
3.3 Measured Performance
v26.03 data on Ascend 910B:
| Routing Strategy | Scenario | E2E Latency Improvement | TTFT Improvement |
|---|---|---|---|
| Aggregated KVCache aware | Same-machine cluster | 9.15% | 37.35% |
| PD KVCache aware | Same-machine cluster | 22.08% | 27.73% |
| PD KVCache aware | Cross-machine cluster | 17.31% | 22.03% |
V3 architecture co-developed with the Mooncake community: production environment TTFT reduced by 40%, end-to-end latency reduced by 30%. These figures come with specific component version numbers (vllm-ascend 0.11–0.14, Hermes-router 0.21.0, etc.)—not just paper numbers.
3.4 InferNex's Competitive Landscape
Inference cluster-level orchestration is a hot direction in 2026. InferNex's main competitors:
| Solution | Source | Characteristics |
|---|---|---|
| InferNex | Huawei / openFuyao | KVCache routing + PD group scaling + Mooncake integration |
| vLLM serving | vLLM community | Single-instance prefix caching; cluster level relies on external load balancing |
| SGLang router | SGLang community | Similar approach, but more focused on single clusters |
| NVIDIA NIM | NVIDIA | Commercial solution, deeply tied to Triton + TensorRT |
InferNex's differentiation lies in PD disaggregation architecture with group-based scaling and deep integration with Mooncake distributed KVCache. These two capabilities are relatively rare in open-source solutions.
However, InferNex currently only works with Ascend NPUs. If it could provide a degraded but usable experience on non-Ascend hardware (e.g., standard NVIDIA GPUs + Ethernet), its user base would be much larger. There's no visible progress in this direction yet.
4. Ultra-Large-Scale Cluster Scheduling: The Engineering Challenge of 16,000 Nodes
4.1 Verified Scale
v25.12 deployed a 20,000-card super-node cluster at China Mobile Cloud: 16,000 nodes in a single cluster, end-to-end scheduling time <3 minutes.
Key engineering techniques:
- API Server multi-instance + IPVS load balancing
- APF (API Priority and Fairness) flow control
- Informer preloading
- Three-layer topology-aware scheduling (super-node → compute cabinet → physical server)
- Logical super-node abstraction
- Automatic fault detection and isolation + checkpoint/resume training
How does 16,000 nodes compare in the K8s community? The standard K8s officially supported upper limit is 5,000 nodes. Alibaba Cloud, ByteDance, and Google have internal 10,000+ node custom solutions, but none are open-sourced. If openFuyao's 16,000-node scheduling capability can truly be generalized, it would be a contribution to the K8s community.
4.2 Aether Elastic Scheduling Framework
Co-created with JD.com. Brain global decision-making + Driver runtime awareness + Executor process-level execution. Training effective time ratio improved to 97%, resource cost reduced by 30%.
97% means only 3% of time is spent on scheduling, communication, synchronization, and other non-compute overhead. For reference, public data from A5000 clusters training GPT-3 175B shows non-compute overhead typically accounts for 5–15% (depending on model parallelism strategy and cluster scale). If Aether's 3% was measured on large-scale MoE models, it's highly impressive. But the test conditions and model types are not public—different model architectures have very different communication-to-compute ratios; MoE's All-to-All communication is far more intensive than Dense models' AllReduce. Without this information, 97% can only serve as a directional reference.
5. Ecosystem Partners and Community Status
5.1 Partner List
| Partner | Role | Progress |
|---|---|---|
| Tianyi Cloud (China Telecom) | Carrier cloud | Community preparatory committee, 20,000-card cluster deployed |
| UnionTech Software | Domestic OS | Adapted openFuyao, 11 million units coverage |
| GRG Wuzhou | Server vendor | PentaPleiades HPC+AI dual-stack |
| Alauda Cloud | Cloud platform | ACP + openFuyao deep integration |
| JD.com | Internet | Aether elastic scheduling framework co-creation |
| Mooncake Community | Open-source project | KVCache V3 architecture collaboration |
5.2 Community Activity
The openFuyao community's December 2025–February 2026 operations report shows a governance structure of a preparatory committee + SIGs (Special Interest Groups). The partner list is dominated by companies within the Huawei ecosystem. There are no NVIDIA, AMD, or Intel among overseas chip vendors; no AWS, Azure, or GCP among overseas cloud providers.
Building a domestic ecosystem takes time and sustained investment. openFuyao remains a Huawei-centric ecosystem, still far from being a "unified scheduling layer for diverse compute."
6. Assessment of the Lingqu Software Stack

Three articles have analyzed Lingqu's complete software stack from kernel to cloud. Returning to the most fundamental question: where is the strategic value of the Lingqu software stack, and where are its limits?
6.1 Core Value: Unified Programming Model
The most valuable innovation of the Lingqu software stack is not any single component, but the URMA programming model—using load/store instructions to directly access any memory within a super-node.
The value chain of this programming model:
- The kernel layer's UMMU provides hardware-level address translation (300–400ns)
- The service layer's MemFabric weaves distributed memory into a unified address space
- The cloud layer's openFuyao exposes it to users through K8s-native interfaces
The result of three layers stacked together: an inference instance running in cabinet A can use standard memory operations to read KV Cache on an NPU's HBM in cabinet Z, with 300–400ns latency, nearly transparent to the application.
This is what makes Lingqu truly irreplaceable. CXL's coverage is insufficient (within cabinet); RDMA's latency isn't low enough (microsecond-level); no other solution can provide unified memory access across a hundred cabinets at sub-microsecond latency.
6.2 Core Risk: Self-Reinforcing Closed Ecosystem
Every component of Lingqu only runs on Huawei hardware. UB OS Component is tied to Lingqu controllers, MemFabric is tied to Lingqu interconnect, HCCL is tied to Ascend NPUs, and openFuyao's deep integration is tied to Lingqu UB.
NVIDIA's CUDA is also closed, but CUDA's closed nature is predicated on NVIDIA GPUs holding 80%+ of data center AI compute. Lingqu's closed nature is predicated on Ascend's share of the domestic AI accelerator market, currently estimated at 10–20% (mainly from government and carrier orders). Being closed isn't inherently wrong, but 10–20% market share can't sustain a full-stack closed ecosystem.
The real risk of being closed is self-reinforcement:
- Hardware is closed → only Huawei's chips can run Lingqu software
- Software is closed → only Lingqu software can fully leverage Lingqu hardware
- Ecosystem is closed → third-party chip vendors have no incentive to adapt to Lingqu; third-party software vendors have no incentive to adapt to Ascend
Breaking this cycle requires not more technical investment, but changes in business model—making the Lingqu protocol a true industry standard (not just publishing specification documents, but having third-party chip vendors participate in development); making UBS Core a truly open community project (with non-Huawei maintainers, contributors, and decision-making power); making openFuyao a truly cross-hardware platform (with NVIDIA/AMD GPU support and overseas user adoption).
An even more fundamental question: architecture blueprints can get clusters running, but keeping clusters running depends on unsexy engineering details like observability, version compatibility, and CVE response. Part 1 deduced FRs, Part 2 deduced SLs, and this part deduces SRs. Across all three parts, 88 functional requirements were deduced, consolidated into 41 system-level specifications after deduplication, of which 51% remain undisclosed. These gaps don't appear on architecture diagrams—they show up in production operations tickets.
Without these transformations, Lingqu is just a better NVLink—useful, but not landscape-changing.
6.3 InferNex Is the Most Noteworthy Commercial Opportunity Today
Inference is the most urgent compute demand in 2026. Inference optimization has already moved from the single-card level to the cluster level. InferNex's KVCache-aware routing + PD group scaling + Mooncake distributed caching is one of the few truly open-source solutions doing inference cluster-level orchestration on the market.
But InferNex currently only works with Ascend NPUs. Its value maximization path is: first prove effectiveness within the Ascend ecosystem (initially validated), then gradually decouple—Hermes-router's routing logic theoretically doesn't depend on Lingqu hardware, and Mooncake is an independent open-source project. If InferNex can provide a degraded but usable experience on standard NVIDIA GPUs + Ethernet, its user base would expand from "domestic customers using Ascend" to "all teams needing inference cluster orchestration."
6.4 Tracking Signals
To assess the Lingqu software stack's trajectory over the next 12–24 months, track these five signals:
1. Non-Huawei contributor ratio in UBS Core. All 24 commits are from Huawei. If this remains unchanged a year after open-sourcing, "open source" is symbolic. The real inflection point is a third party submitting a UBPU driver.
2. Whether third-party chip vendors adopt the Lingqu protocol. Changes in membership of the Lingqu Interconnect Community (unifiedbus.com). Whether any non-Huawei chip has announced UB support.
3. openFuyao's hardware support scope. v26.03 only supports Ascend 910B. Will the next version add NVIDIA GPU or other domestic NPU support?
4. Production data from Atlas 950 SuperPoD. URMA latency distribution at 8,192-card scale, HCCL AllReduce bandwidth utilization, UBS Engine failure recovery time. Currently, not a single public data point exists.
5. InferNex's hardware decoupling progress. Can it run on non-Lingqu hardware? Even degraded to standard RDMA mode.
7. Reconstructing System Software Functional Specifications from Deduction
Part 1 deduced 32 FRs (Functional Requirements) from the kernel layer, finding 34% implemented and 66% unknown. Part 2 deduced 15 SLs (Service Layer requirements) from the service layer, all undisclosed. This part analyzed the cloud layer. Now we consolidate the deductions across all three parts, reconstructing a functional specification for super-node system software organized by functional domain rather than software layer.
SRs (System Requirements) don't duplicate FRs and SLs, but reorganize them from a full-stack perspective. Key items from FRs (e.g., UMMU address translation, UBM heartbeat convergence) appear at higher granularity in SRs, with cross-references to their corresponding FRs/SLs. This way, reading all three parts sequentially shows the progression from layer-level requirements to system-level requirements, while reading Part 3 alone doesn't require flipping back to Part 1.
7.1 Specification Writing Principles
Each specification (SR) must satisfy:
- Has a deduction source: not imagined out of thin air, but a conclusion from earlier technical analysis or boundary reasoning
- Has verification criteria: can be judged as "implemented / not implemented / partially implemented / undisclosed"
- Has priority assessment: impact on super-node usability
7.2 Interconnect and Topology Management
A super-node is first and foremost a network. The management capabilities of this network determine all upper limits.
| ID | Functional Specification | Deduction Source | Status |
|---|---|---|---|
| SR-1 | Routing table supports programmable topologies (fat tree/Mesh/custom), dynamically optimized by communication pattern | Part 1 FR-2: 8,192-card clusters don't have a single workload; training and inference have different communication patterns | ❓ |
| SR-2 | Routing table aggregation to manageable scale: full-mesh O(n²) 67M entries infeasible, switch topology aggregated to ~8,192 entries + ECMP multi-path | Part 1 routing table scale calculation: O(n²) full-mesh 160 cabinets = 67M entries, must use topology aggregation | ✅ Deployed |
| SR-3 | UBM heartbeat probing completes a single round in <5s at 8,192 UBPU scale | Part 1 estimation: thousand-card in seconds → 8,192 cards potentially tens of seconds; ops SLA requires faster convergence | ❓ |
| SR-4 | Topology change events notify HostOS, triggering application-layer rerouting | Part 1 FR-28: during topology convergence, applications need to know which paths are unavailable | ❓ |
| SR-5 | Fault isolation granularity configurable: single-device isolation vs. cabinet-level isolation, selectable by SLA | Part 1 FR-26: training can tolerate precise isolation; inference may need rapid isolation | ❓ |
SR-3 is the scale ceiling. Heartbeat probing time determines the fault detection window. If 8,192 cards require >10s to complete a round of topology probing, then initialization, fault recovery, and topology recalculation latency all inflate accordingly. This number directly determines how large Lingqu super-nodes can scale.
7.3 Cross-Node Memory System
Lingqu's core value—unified memory address space. But going from "addressable" to "usable" involves a series of specification requirements.
| ID | Functional Specification | Deduction Source | Status |
|---|---|---|---|
| SR-6 | UMMU hardware address translation: virtual address → {NodeID, UASID, VA}, latency 300–400ns |
Part 1 §2.2 UMMU analysis | ✅ |
| SR-7 | UMMU TLB capacity and miss penalty are observable | Part 1 estimation: 8,192 UBPU × N concurrent UASIDs, TLB misses may be a source of latency spikes | ❓ |
| SR-8 | Borrowing ratio adjustable (not fixed at 25%), supports locality detection and weighted latency estimation | Part 1 deduction: 25% is optimal under uniform distribution, but actual workload locality varies significantly | ✅ Framework exists |
| SR-9 | Borrowed memory NUMA distance precisely annotated (distinguishing remote HBM from remote DRAM) | Part 1 FR-9: different media have different latencies; distance can't use a one-size-fits-all value | ❓ |
| SR-10 | Data location awareness API: applications can query physical location of virtual addresses, proactively trigger migration | Part 1 FR-12: "single-machine semantics is a programming simplification, not performance equivalence"—performance-critical paths need location awareness | ❓ |
| SR-11 | Batch owner transfer for shared memory: single call transfers write ownership of N regions | Part 1 deduction: gradient accumulation involves hundreds of regions with alternating writes; per-region set_ownership overhead accumulates | ❓ |
| SR-12 | Cross-node memory cgroup limits: restrict total remote memory borrowing per container/process | Part 1 FR-13: prevent memory starvation in multi-tenant scenarios | ❓ |
| SR-13 | Page migration granularity and latency configurable (4KB/2MB/1GB), large-page migration uses hardware-accelerated path | Part 2 storage semantics vs. memory semantics analysis: 4KB page migration granularity has high latency overhead in cross-node scenarios | ❓ |
| SR-14 | UCM (Unified Cache Management) explicit management layer: distinguish hot data auto-residency from warm data on-demand loading | Part 2 analysis: page migration latency issues suggest UCM may need explicit cache policy rather than pure page-fault-driven approach | ❓ |
SR-10 and SR-13 are key to whether "unified memory" can move from concept to engineering. SR-10 gives applications the ability to do data layout optimization—not all data needs cross-node access; hot data locally, warm data remotely is a basic strategy, but the prerequisite is that applications can sense location. SR-13 solves page migration granularity—4KB granularity in cross-node scenarios means frequent small data transfers with amplified latency; if hardware-accelerated large-page migration paths are provided, cross-node bulk data transfer efficiency can improve dramatically.
SR-14 is an implicit requirement derived from boundary analysis. Lingqu claims "single-machine memory semantics," but page migration latency (page fault → UMMU translation → cross-node DMA → page fill) can never match truly local memory. If UCM has an explicit cache management layer (similar to CPU cache prefetch/evict hints), applications can prefetch needed remote data during predictable operations like checkpointing or gradient sync, avoiding runtime page faults. There's currently no public information about this capability, but it's a hard requirement deduced from performance requirements.
7.4 Collective Communication and Compatibility Layer
Communication is the infrastructure for both training and inference. Lingqu has two lines at the communication layer: native URMA and compatibility layers.
| ID | Functional Specification | Deduction Source | Status |
|---|---|---|---|
| SR-15 | HCCL collective communication library: AllReduce/AllGather/ReduceScatter etc., adapted to Lingqu topology | Part 2 §3.1 HCCL analysis | ✅ |
| SR-16 | RoUB compatibility layer: libibverbs interface compatibility | Part 1 §2.3 zero-modification migration | ✅ |
| SR-17 | Socket over UB compatibility layer | Part 1 §2.3 transparent TCP application acceleration | ✅ |
| SR-18 | Communication performance full-chain observability: latency distribution, bandwidth utilization, URMA/UDMA queue depth | Part 1 FR-17: three-tier adaptation path benefits need real-world verification | ❓ |
| SR-19 | RDMA application compatibility certification matrix: verification status of mainstream RDMA frameworks on RoUB | Part 1 FR-18: cold start needs a migration path | ❓ |
| SR-20 | URMA → UCX adaptation layer, enabling UCX applications to run on Lingqu hardware | Part 1 open-source alternative analysis: UCX is the closest cross-platform communication framework | ❓ |
SR-19 determines whether a cold start can happen. The first question in user migration isn't "how much faster is Lingqu than RDMA," but "can my existing NCCL/MPI/oneCCL applications run directly?" Without a compatibility matrix, migration decisions stall at step one.
7.5 Virtualization and Multi-Tenancy
Super-node compute needs to be sliced and allocated.
| ID | Functional Specification | Deduction Source | Status |
|---|---|---|---|
| SR-21 | UB device vfio passthrough: VMs can directly use Lingqu communication and memory capabilities | Part 1 §2.4 compliance scenarios | ✅ |
| SR-22 | vfio + UMMU coordination implemented as vfio_iommu_ub independent type, without modifying vfio core code |
Part 1 deduction: modifying vfio core increases upstream compatibility risk | ❓ |
| SR-23 | VM cross-node memory mapping + live migration, migration latency <100ms | Part 1 §2.4 super VM | ✅ |
| SR-24 | Super VM remote memory limits: restrict total cross-node memory usable by a single VM | Part 1 FR-23: multi-tenant isolation | ❓ |
| SR-25 | Alternative solution when hardware CC (cache coherence) is infeasible: software-level coherence protocol + selective snoop | Part 1 estimation: snoop filter scale O(n²), invalidation ack bounded by slowest node → hardware CC infeasible at 8,192-card scale | N/A Confirmed infeasible |
The significance of SR-25 is: this specification shouldn't need to exist, but deduction shows it must. Hardware cache coherence across 8,192 UBPU is physically infeasible—snoop filter capacity, O(n²) growth of coherence traffic, and invalidation ack bottleneck from the slowest node form a triple constraint. Lingqu's choice of load/store semantics over cache coherence was correct. But this means: visibility guarantees after cross-node writes need a software layer to supplement. Lingqu's UMMU provides address translation but not cache consistency—so where is the consistency protocol? URMA's synchronization mode? Explicit flush? Or reliance on application communication primitives (barriers)? The answer to this question determines the true complexity of the cross-node memory programming model.
7.6 Inference Cluster Orchestration
InferNex is the primary outlet for the Lingqu software stack in inference scenarios.
| ID | Functional Specification | Deduction Source | Status |
|---|---|---|---|
| SR-26 | KVCache-aware routing: route requests to the instance with highest cache hit probability | Part 3 §3.2 Hermes-router | ✅ |
| SR-27 | PD disaggregation group scaling: Prefill and Decode instance pair management; standard HPA doesn't support this | Part 3 §3.2 Elastic Scaler | ✅ |
| SR-28 | Distributed KVCache three-tier storage: HBM / DRAM / NVMe tiering, hot data auto-promotion | Part 2 ICMSP analysis: HBM ~$20/GB / DRAM ~$3/GB / NVMe ~$0.3/GB | ✅ |
| SR-29 | KVCache three-tier storage latency/cost configurable: each tier's capacity, promotion/demotion policy adjustable | Part 2 deduction: 70x cost difference across tiers; hot/cold distribution varies by scenario | ❓ |
| SR-30 | Hardware decoupling mode: InferNex can run in degraded mode on non-Lingqu hardware (standard RDMA mode) | Part 3 §6.3 value maximization path | ❌ |
| SR-31 | Full-chain observability: business metrics + system metrics + hardware sub-health, three-layer linkage | Part 3 §3.2 Eagle-eye | ✅ |
SR-30 is key to whether InferNex can break out of the Ascend ecosystem. Currently InferNex is deeply tied to Ascend NPUs and Lingqu communication. Hermes-router's routing logic theoretically doesn't depend on Lingqu hardware, and Mooncake is an independent open-source project. If InferNex could provide an RDMA degradation mode—using standard RoCEv2 instead of URMA, standard GPUs instead of Ascend NPUs—its potential user base would expand from "domestic customers using Ascend" to "all teams needing inference cluster orchestration." Currently there's no public progress on this.
7.7 Scheduling and Resource Management
Super-node compute scheduling needs to understand super-node topology.
| ID | Functional Specification | Deduction Source | Status |
|---|---|---|---|
| SR-32 | Three-layer topology-aware scheduling: super-node → compute cabinet → physical server | Part 3 §4.1 16,000-node cluster | ✅ |
| SR-33 | NPU DRA (Dynamic Resource Allocation) plugin, using K8s-native framework rather than custom scheduler | Part 3 §2.3 architecture decision analysis | ✅ |
| SR-34 | Logical super-node abstraction: applications can declare "need 64-card super-node," scheduler automatically allocates physical resources | Part 3 §4.1 ultra-large-scale clusters | ✅ |
| SR-35 | Heterogeneous compute unified scheduling: same cluster simultaneously managing Ascend NPUs and NVIDIA GPUs | Part 3 §2.3 DRA path analysis: needs DRA drivers from 2+ chip vendors merged upstream | ❌ |
| SR-36 | Training effective time ratio observability: the measurement methodology behind the 97% figure needs transparency | Part 3 §4.2 Aether data: test conditions and model types not public | ❓ |
SR-35 is the ultimate test of openFuyao's positioning as a "diverse compute scheduling layer." Currently only Ascend 910B is supported. If the DRA path succeeds, heterogeneous compute unified scheduling would have a technical foundation. But the DRA path needs more than just Huawei—it needs NVIDIA's DRA driver to also be merged into the K8s upstream. This depends on NVIDIA's strategic decisions, not on openFuyao.
7.8 Version Management and Operations
The operational complexity of 128 cabinets, a three-layer software stack, and 8,192 cards.
| ID | Functional Specification | Deduction Source | Status |
|---|---|---|---|
| SR-37 | Three-layer version compatibility matrix auto-checking: compatibility for any combination of DeviceOS / UBM / HostOS | Part 1 deduction: three-layer versions × multiple models = O(n³) compatibility matrix; manual checking infeasible | ❓ |
| SR-38 | Three-layer independent upgrade/rollback: upgrading any layer doesn't affect other layers; failures can be rolled back | Part 1 deduction: the hidden tax of openEuler fork—upgrading UBM firmware shouldn't require HostOS reboot | ❓ |
| SR-39 | Kernel module ABI stability across versions: UB OS Component's user-kernel ABI doesn't change with versions | Part 1 FR-32: unstable ABI means user-space toolchain must be updated accordingly | ❓ |
| SR-40 | openEuler fork CVE window quantifiable: maximum delay from upstream CVE disclosure to fork fix merge, in days | Part 1 deduction: fork's hidden tax—CVE response delay is a security risk | ❓ |
| SR-41 | CXL subsystem conflict detection: UB OS Component modifications must not block future mainline CXL code merging | Part 1 deduction: fork modifies bus model and memory management extensions, which may conflict with mainline CXL subsystem | ❓ |
SR-37 through SR-41 are about whether 128 cabinets can actually be operated. Lingqu's public materials showcase architecture blueprints and performance highlights. But the person operating 128 cabinets, a three-layer software stack, and 8,192 cards faces questions like: does upgrading a UBM firmware require stopping business? When a CVE comes out, how many days from upstream fix to Lingqu fork merge? Will a kernel module upgrade break user-space tools? The answers to these questions aren't on architecture diagrams—they're in production operations tickets.
SR-41 is particularly noteworthy. The Lingqu kernel layer modifies the Linux bus model (adding ub_bus_type), memory management extensions (cross-node unified addressing), and PCIe subsystem interactions. These modifications are based on an openEuler fork. If Linux mainline's CXL subsystem makes incompatible changes in the future, the merge cost for the Lingqu fork will accumulate over time. This isn't a current problem, but could become a structural risk in 3–5 years.
7.9 Functional Specification Panorama Summary
| Functional Domain | Spec Count | ✅ Implemented | ❓ Undisclosed | ❌ Missing |
|---|---|---|---|---|
| Interconnect and Topology Management | 5 | 1 | 3 | 1 |
| Cross-Node Memory System | 9 | 1 | 7 | 1 |
| Collective Communication and Compatibility | 6 | 3 | 2 | 1 |
| Virtualization and Multi-Tenancy | 5 | 2 | 2 | 0 (1 infeasible) |
| Inference Cluster Orchestration | 6 | 4 | 1 | 1 |
| Scheduling and Resource Management | 5 | 3 | 1 | 1 |
| Version Management and Operations | 5 | 0 | 5 | 0 |
| Total | 41 | 14 (34%) | 21 (51%) | 5 (12%) + 1 infeasible |
Combined with the 32 FRs from the kernel layer in Part 1 (11 implemented + 21 unknown), the three parts deduced a total of 73 functional requirements. After consolidation and deduplication, there are 41 system-level specifications.
Several structural conclusions:
1. "Implemented" items cluster in visible layers. URMA communication, vfio passthrough, topology discovery, InferNex routing—these are capabilities that can be demonstrated upon deployment. "Undisclosed" items cluster in invisible layers: TLB observability, page migration granularity, version compatibility matrix, CVE response delay—these are problems that surface only after three months of production operation.
2. Observability is the largest systemic gap. SR-7 (TLB miss), SR-10 (data location), SR-18 (communication full chain), SR-36 (training effective time measurement methodology), SR-37 (version compatibility check)—the common gap across functional domains is the inability to observe internal system state. Lingqu provides Eagle-eye for hardware health monitoring, but software-layer internal observability (UMMU translation efficiency, memory borrowing locality, communication path selection logic) has almost no public information.
3. Multi-tenant isolation specifications are nearly blank. SR-12 (memory borrowing limits), SR-24 (VM remote memory limits), SR-25 (cross-node consistency alternative)—these are hard requirements when a super-node is shared among multiple business units. Lingqu's current public materials assume the super-node runs a single workload (training one large model or deploying one inference service), but in actual production, 8,192 cards won't run just one task.
4. Operations specifications are a vacuum. SR-37 through SR-41 are all undisclosed. Upgrades, rollbacks, CVE response, mainline compatibility—at 128-cabinet scale, these aren't nice-to-haves; they're the baseline for whether the system can keep running.
7.10 Looking at Lingqu's Priorities from This Specification Document
If I were Lingqu's product owner and received this specification document, the priority ranking would be:
P0 (must-have for usability):
- SR-3 (UBM heartbeat convergence <5s)—determines scale ceiling
- SR-37 (three-layer version compatibility auto-check)—determines whether deployment is possible
- SR-40 (CVE window quantifiable)—determines whether security audits can be passed
P1 (must-have for usability quality):
- SR-10 (data location awareness API)—prerequisite for application performance optimization
- SR-7 (UMMU TLB observability)—prerequisite for diagnosing latency issues
- SR-19 (RDMA compatibility matrix)—prerequisite for cold start
- SR-13 (page migration granularity configurable)—prerequisite for cross-node memory efficiency
- SR-12/SR-24 (multi-tenant memory limits)—prerequisite for shared super-nodes
P2 (must-have to raise the ceiling):
- SR-1 (programmable routing)—prerequisite for training/inference time-sharing
- SR-30 (InferNex hardware decoupling)—prerequisite for breaking out of Ascend ecosystem
- SR-35 (heterogeneous compute unified scheduling)—prerequisite for openFuyao delivering on its positioning
- SR-41 (CXL mainline conflict detection)—long-term technical debt management
Without P0, an 8,192-card super-node is just a demo environment. Without P1, a production environment will accumulate undiagnosable performance issues and security tickets after three months of operation. Without P2, Lingqu will forever be a closed full-stack system that can't break out of the Huawei ecosystem.
Sources: 灵衢系统软件架构&部署公开课 PPT(牛涛)、openEuler UB Service Core 白皮书 2.0、APNet'21 "Huawei UB: Towards Compute-Native Networking" 技术报告(Bojie Li)、华为全联接大会 2025 徐直军主题演讲、灵衢互联社区(unifiedbus.com)规范文档、openEuler SIG-Long 异构融合 SIG 资料、KADC 2026 openFuyao 分论坛、openFuyao 官网(openfuyao.cn)、openFuyao v26.03 Release Notes、openFuyao 社区 2025.12-2026.2 运作报告、CLK 2025 技术演讲、comentropy 超节点产业链分析、ubs-core GitHub 仓库(atomgit.com)、Mooncake 项目文档