In June 2026, China's MaaS (Model as a Service) market presents a seemingly contradictory picture: nearly every major provider is cutting prices, some dropping below cost, yet token consumption is surging.
Doubao (ByteDance) processed about 120 billion tokens per day when it launched in May 2024. By March 2026, that number exceeded 120 trillion (source: QuestMobile, Aotou Finance). Roughly 1,000x in two years. Meanwhile, ByteDance's 2025 computing-related expenses surpassed 30 billion yuan, with net profit down 70% year-over-year.
Around the Dragon Boat Festival in 2026, DeepSeek, Alibaba Qwen, ByteDance Doubao, Zhipu GLM, Baidu ERNIE, and iFLYTEK Spark nearly simultaneously announced new price cuts or limited-time discount packages. Zhipu's GLM-4-Flash went free entirely, Qwen-plus dropped from 4 yuan to 2 yuan, and Doubao Pro cut some model prices by over 80%.
The more they cut, the more people use. Economists call this the Jevons Paradox: when resource efficiency improves, total consumption rises rather than falls, because lower prices unlock demand that was previously suppressed. MaaS is replaying this scenario. Understanding this paradox is the key to understanding the survival strategies of every participant in the MaaS market.
A critical question follows: with a break-even line of 5-7 yuan per million tokens, how do MaaS providers survive? What service models can withstand the price war?
1. Break-Even Economics
1.1 Accounting: The Real Cost of 100 Million Tokens
Let's break down the numbers. For a large model in the 70-billion parameter class (e.g., DeepSeek V3, Qwen-max) deployed on an H100 80GB cluster, the actual cost of processing 100 million tokens:
| Cost Item | Details | Yuan/100M tokens |
|---|---|---|
| Computing (GPU rental) | H100 80GB at ~3 yuan/h per card (internal cost, June 2026), 8-card inference node processing ~50K tokens/s | 140-180 |
| Hardware depreciation | Self-built cluster, 3-year depreciation, including HBM (High Bandwidth Memory), NVMe, networking | 150-200 |
| Operations (power + network + staff) | Liquid cooling PUE (Power Usage Effectiveness) 1.15, network bandwidth, ops team | 100-150 |
| Sales and platform | Customer acquisition, API gateway, monitoring and billing | 40-60 |
| Total | 430-590 |
Converted to per million tokens: 4.3-5.9 yuan. Adding brand premium, R&D amortization, and security compliance, the conservative break-even line is 5-7 yuan per million tokens.
This figure assumes: self-built clusters, 70-100B parameter models, continuous batching utilization above 70%. With on-demand cloud GPU rental, costs rise another 30-50%.
Several key variables affect this: input-output ratio (output tokens consume 3-5x the compute of input tokens), KV Cache hit rate (cache hits avoid redundant Prefill), and model scale (MoE, or Mixture of Experts, activates far fewer parameters than total parameters). These variables are the core battleground for MaaS cost optimization.
1.2 June Pricing Distribution
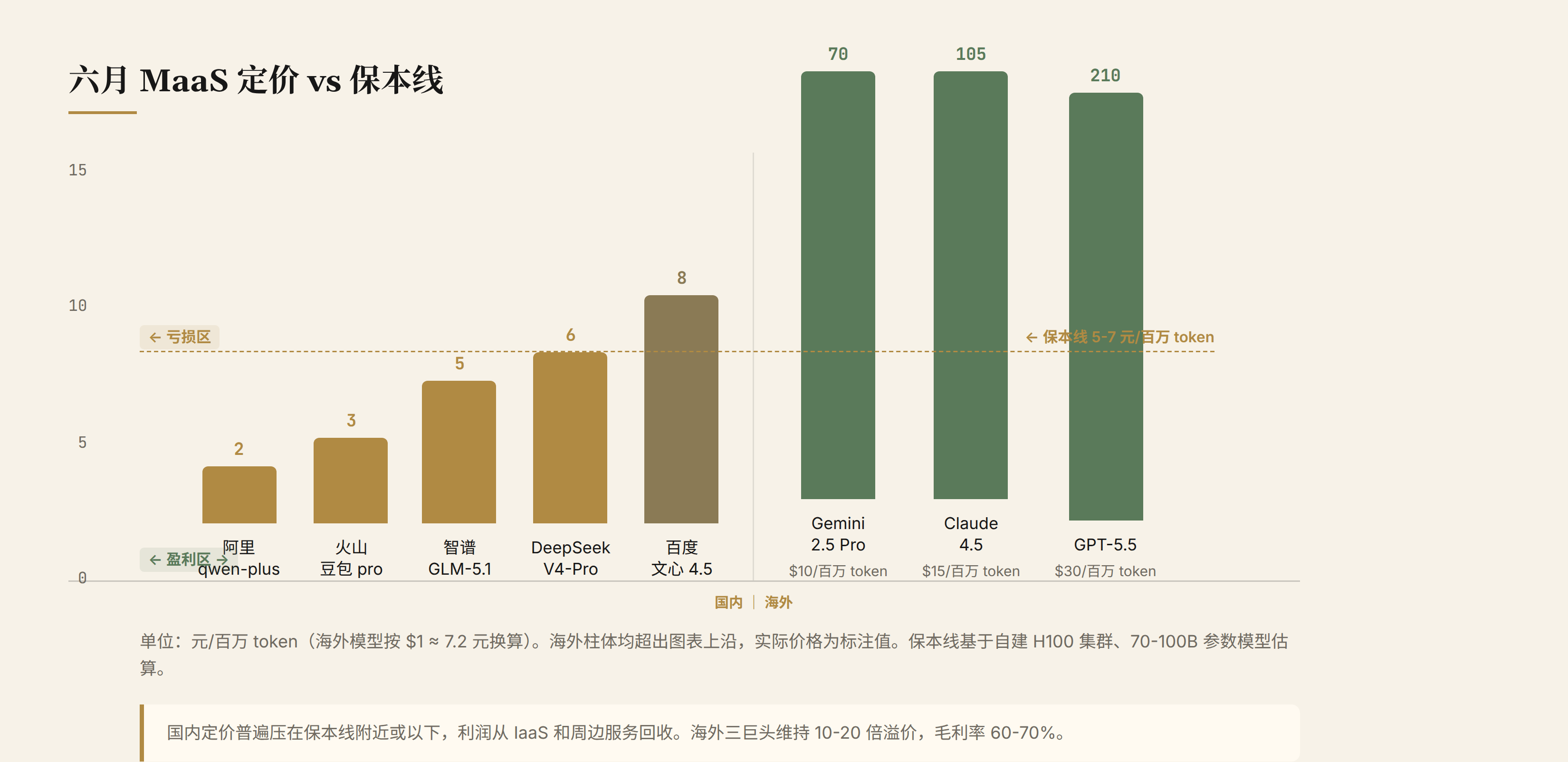
Pricing distribution of mainstream models in June 2026:
| Model | Price (yuan/million tokens) | vs Break-Even |
|---|---|---|
| Alibaba Qwen-plus | 2 | Far below break-even |
| Volcano Doubao Pro | 2-4 | Below break-even |
| Zhipu GLM-5.1 | 5 | Near break-even |
| DeepSeek V4-Pro | 6 | At break-even |
| Baidu ERNIE 4.5 | 8 | Slightly above break-even |
| OpenAI GPT-5.5 | ~210 ($30) | Far above break-even |
| Anthropic Claude 4.5 | ~105 ($15) | Far above break-even |
| Google Gemini 2.5 Pro | ~70 ($10) | Far above break-even |
Domestic pricing is generally at or below the break-even line, while the three overseas giants maintain 10-20x premiums.
The direct implication: if domestic MaaS providers relied solely on token margins, most would be losing money. Qwen-plus at 2 yuan/million tokens is 3-5 yuan below break-even, meaning Alibaba loses 300-500 yuan per 100 million tokens processed.
But Alibaba isn't really losing money. The reason is that MaaS revenue goes far beyond token margins. IaaS cloud servers, databases, data lakes, security products, and enterprise customization are the real profit sources. Qwen-plus's low price is a traffic entry point, pulling developers into the Alibaba Cloud ecosystem and monetizing through IaaS.
1.3 The Math of Token Multiplication
Understanding MaaS business logic requires unpacking the multiplier effect of token consumption.
A direct user dialogue scenario: 1,000 input tokens, 500 output tokens, 1,500 tokens consumed per interaction.
An AI Agent scenario: a user sends one instruction, the Agent decomposes it into 3-5 subtasks, each requiring 1-3 rounds of tool calls, averaging 2,000-5,000 tokens per call. A single instruction typically consumes 20,000-50,000 tokens, exceeding 70,000 in extreme cases. That's 10-30x more than direct dialogue.
Doubao's 120 trillion daily tokens largely come from AI feature calls across ByteDance products (Douyin, Feishu, Toutiao). These calls consume enormous token volumes, but the per-token business value to ByteDance is also high: AI summaries improve content consumption efficiency, AI search improves ad matching precision.
The Jevons Paradox holds because AI's marginal utility doesn't decline linearly. Every batch of tokens processed enables one more task completed by an agent, one more business workflow optimized. The demand ceiling is nowhere in sight. This is precisely why aggregation-routing and platform models have a foundation to exist: total demand is expanding, but unit prices are falling, and fragmented calls need an intermediary layer to absorb complexity.
2. Four Service Models
Understanding the MaaS market isn't about who cuts prices the most, but about how different service models coexist. Four clearly distinguishable models exist today.
2.1 Direct-to-Market
Typical players: DeepSeek, ByteDance Doubao, Alibaba Qwen, OpenAI, Anthropic.
The core characteristic is proprietary models, proprietary branding, and direct access to end users or developers. Pricing power is entirely in-house, and model iteration pace and direction are internally determined.
DeepSeek is the most distinctive player in this category. Its strategy uses engineering optimization to substitute for scale amortization: through a self-developed tech stack including MoE dynamic routing, attention sparsification, PD separation, and INT4 quantization, it reduced per-token cost from the industry baseline of $0.12 to approximately $0.005 (source: DeepSeek V3 technical report, a 96% reduction). This allows DeepSeek to operate near break-even at 6 yuan/million tokens while maintaining model quality. DeepSeek doesn't need a cloud ecosystem to subsidize losses, but it lacks distribution channels. Developers must actively seek out the DeepSeek API rather than being pulled in by a cloud platform.
OpenAI and Anthropic represent the overseas direct-to-market approach, taking the opposite path: high pricing maintains 60-70% gross margins, earning through model performance and brand premium. GPT-5.5 at $30/million tokens is 35x more expensive than DeepSeek. How long this gap persists depends on how long the performance gap holds.
2.2 Cloud Ecosystem
Typical players: Volcano Engine (ByteDance), Alibaba Cloud Bailian, Baidu AI Cloud, Huawei Cloud MaaS.
This is the largest market share model in China's MaaS market. IDC 2025 data: Volcano Engine holds 49.5%, Alibaba Cloud 28%, Baidu 10%. The top three combined: 87.5%.
The core logic of the cloud ecosystem model is "total package": not just selling tokens, but selling a complete AI infrastructure stack including computing, storage, databases, model services, data governance, security compliance, and enterprise customization. MaaS pricing can go below break-even because profits are recovered through IaaS and surrounding services.
The advantage of this model is ecosystem stickiness. Once an enterprise deploys AI models on Volcano Engine, its data, workflows, and monitoring systems are all tied to Volcano Engine, making migration extremely costly. The disadvantage is internal cannibalization between MaaS and IaaS: the more MaaS prices drop, the more GPU consumption in IaaS increases, but MaaS itself loses more, requiring IaaS profits to fill the gap.
Huawei Cloud MaaS is a noteworthy variant. It takes a "model-neutral" approach, integrating not only Pangu models but also third-party models like DeepSeek, GLM, Qwen, and Llama. In April 2026, it expanded to nine Southeast Asian countries, supporting Pangu alongside DeepSeek V4, GLM-5.1, and other third-party models. Huawei's chips are Ascend processors combined with CloudMatrix supernode architecture, using proprietary hardware to bind model services and differentiate from the NVIDIA ecosystem. In the government and enterprise market, Huawei's compliance capabilities and private deployment experience form an additional moat that pure technical dimensions can't measure.
2.3 Aggregation Routing
Typical players: OpenRouter, SiliconFlow, 302.AI, CatRouter, Shiyun API.
The core characteristic is model neutrality, unified API, and intelligent routing. These players don't own models; they act as "dispatchers" between models.
OpenRouter is the benchmark case for this model. In May 2026, it completed a $113 million Series B (led by CapitalG, with NVentures participating), reaching a $1.3 billion valuation (doubled in six months). Annualized revenue of approximately $50 million, up 5x in half a year. Weekly processing of 25 trillion tokens, approximately 100 trillion monthly, over 8 million users, commission rate around 5.5% (source: OpenRouter Series B announcement, May 2026).
SiliconFlow is the Chinese version of the aggregation routing model. In June 2026, it completed financing of over 2 billion yuan, with daily token processing reaching the trillion level and revenue growing 10x year-over-year. It serves simultaneously as the channel for Chinese models on OpenRouter (Chinese models account for 41.3% of OpenRouter's weekly call volume) and as the model aggregation gateway for domestic developers.
The core value of aggregation comes from four capabilities: multi-model failover (automatic switching when a single model goes down), intelligent routing (automatically selecting the optimal model based on task type, cost, and performance), cross-vendor billing reconciliation (one invoice for all models), and cross-border channels (Chinese models going overseas, foreign models entering China).
The risks are equally clear. Upstream model providers are pursuing "disintermediation" strategies. OpenAI and Anthropic now sign enterprise contracts directly, bypassing aggregation layers. Model providers building their own aggregation (Anthropic Console, Google Vertex AI Model Garden) are also encroaching on the aggregation niche. If model performance gaps narrow, "quality-based routing" loses value, leaving aggregation with only the thin margin of "price-based routing." But the Jevons Paradox provides counter-support here: total demand is expanding far faster than performance is converging, and fragmented use cases (Agent workflows, multi-model collaboration) actually need routing layers more to absorb complexity.
2.4 Platform
Typical players: Hugging Face, Replicate, Cloudflare Workers AI, Dify.
The core characteristic is developer ecosystem-driven. Hugging Face offers not just model inference but a model repository, dataset platform, and community. Developers can choose models, adjust parameters, and deploy themselves. Cloudflare Workers AI embeds inference directly into the edge network, achieving extremely low latency.
The platform model has the narrowest commercialization path. Hugging Face charges through enterprise subscriptions and inference hosting, but most developers use only the free tier. Replicate charges per token but at higher unit prices than direct-to-market providers. Dify positions itself as an Agent development platform, monetizing through workflow orchestration and model routing, but its scale is far smaller than aggregation players.
The platform model's long-term value lies in long-tail coverage. As the number of models expands from dozens to hundreds, enterprises can't integrate with each model provider individually. The platform model offers a "model supermarket" experience in this position. Moreover, the rapid development of open-source models (Llama, Qwen open-source versions, DeepSeek open weights) is expanding the platform model's value: more enterprises are choosing to self-host inference on Hugging Face or Dify, bypassing MaaS entirely to use open weights. This poses a long-term erosion threat to the mid-to-low-end market of both direct-to-market and cloud ecosystem models.
2.5 Competitive Dynamics Among Four Models

These four models are not substitutes for each other; they are nested. A typical enterprise AI stack might look like this: Alibaba Cloud IaaS as the computing foundation (cloud ecosystem), SiliconFlow's unified API for multi-model access (aggregation routing), Dify for Agent workflow orchestration (platform), and direct connections to DeepSeek or GPT-5.5 for core tasks (direct-to-market).
Who eats whom? Not in the short term. Each model provides irreplaceable value in its position: computing, routing, orchestration, models. But the direction of profit allocation is clear: the closer to the computing infrastructure (cloud ecosystem), the thicker the profits; the closer to the model layer (direct-to-market), the stronger the pricing power; the middle layers (aggregation, platform) have the hardest time.
One easily overlooked variable is large enterprises self-hosting inference. Industries with strict data security and compliance requirements, such as banking, insurance, and government, prefer to build their own GPU clusters, deploy open-source models, or purchase private deployment services rather than use public MaaS. This directly limits the addressable market size for MaaS. IDC estimates that self-built and private deployments account for over 40% of Chinese enterprise AI inference spending, exceeding 60% in government and finance. Huawei Cloud has a natural advantage here, as it sells both chips and private deployment solutions.
3. Three Paths: Who's Winning How
MaaS market competition is not just a price war; it's a race among three distinct paths.

DeepSeek takes the technology-intensive path. Its self-developed full-stack inference engine pushes MoE dynamic routing, attention sparsification, PD separation, and INT4 quantization to their limits, reducing per-token cost from the industry baseline of $0.12 to approximately $0.005, a 96% reduction (source: DeepSeek V3 technical report). It uses engineering advantages to offset scale disadvantages, maintaining pricing competitiveness through ultra-low per-token costs. But its ceiling is distribution channels: without a cloud ecosystem, developers must actively come to it.
Volcano Engine takes the scale-plus-ecosystem path. Its 100,000-card-scale clusters push unit GPU costs to industry lows, compounded by internal call volumes from ByteDance products (Douyin, Feishu, Toutiao) building a data flywheel, then locking in enterprise customers through IaaS stickiness. MaaS pricing can go to zero as long as IaaS and surrounding services recover the cost. Another card: hybrid subscription and usage-based billing. The Coding Plan dropped from 40 yuan/month to 9.9 yuan/month (2.5x discount for the first two months), classic SaaS funnel logic. Volcano's ceiling is engineering depth; its core inference engine relies on the open-source vLLM/SGLang.
OpenRouter takes the asset-light aggregation path. Holding no computing power and doing no inference optimization, it focuses on unified API, intelligent routing, cross-vendor billing, and cross-border channels. With 8 million users and 100 trillion tokens processed monthly, its 5.5% commission generates over $50 million in annualized revenue. Its ceiling is the "disintermediation" strategy of upstream model providers.
| Dimension | DeepSeek | Volcano Engine | OpenRouter |
|---|---|---|---|
| Core advantage | Self-developed inference engine, industry-lowest per-token cost | 100K-card scale + ByteDance ecosystem binding | Asset-light, 8M users, unified API |
| Business model | Pure token pricing | Subscription + usage + ecosystem binding + IaaS monetization | 5.5% commission + cross-border channels |
| Ceiling | Lacks distribution channels | Relies on open-source inference engines | Upstream providers building own aggregation |
The technical optimization details (how six levers combine to achieve 96% cost reduction) warrant a separate article. Here, one judgment suffices: the Jevons Paradox means that while technology compressed costs by 96%, total token consumption grew over a thousandfold. The industry's total computing expenditure didn't decrease; it increased. ByteDance's 2025 computing bill of 30+ billion yuan is the evidence.
4. China's MaaS Market Landscape

Reviewing the evolution of China's MaaS market over the past two years.
In early 2024, the landscape was fragmented. Baidu, Alibaba, ByteDance, and Huawei each had their strongholds, with no clear leader. By end of 2025, Volcano Engine secured the top position with 49.5% market share, driven by Doubao's explosive growth and internal call volumes from ByteDance products. Alibaba held 28% thanks to the Qwen series and Alibaba Cloud IaaS's massive customer base. Baidu held 10%.
Three major variables emerged in the first half of 2026.
First, the release of DeepSeek V4. DeepSeek established a reputation as the "value-for-money king" in tech circles. V4-Pro narrowed the comprehensive gap with overseas flagship models to 5-10% across mainstream benchmarks (MMLU, HumanEval, Chatbot Arena). But DeepSeek doesn't build cloud ecosystems, so its direct revenue share is limited, penetrating the market more through aggregation platforms like SiliconFlow. Its real impact is anchoring the industry's price floor: as long as DeepSeek exists, other providers struggle to raise prices.
Second, the rise of SiliconFlow. Entering through aggregation routing, it simultaneously captured domestic developers and the OpenRouter channel, reaching daily token processing at the trillion level. In June 2026, it completed financing of over 2 billion yuan with revenue growing 10x year-over-year. That SiliconFlow's business model works is indirect validation of the Jevons Paradox: once total demand reaches a certain scale, the routing demand for fragmented calls becomes a significant business in itself. This growth rate suggests it could challenge Baidu's third position by 2027. But the risk is equally clear: if Volcano Engine or Alibaba pushes into aggregation routing, SiliconFlow's niche will be directly squeezed.
Third, Huawei Cloud MaaS going overseas. Launched in Singapore in April 2026, covering nine Southeast Asian countries, integrating Pangu, GLM-5.1, DeepSeek, and other multi-source models. Huawei's strategy uses Ascend chips and CloudMatrix supernode architecture for differentiation, separating from the NVIDIA ecosystem. Why Southeast Asia instead of the Middle East or Latin America? Because Southeast Asia has the fastest AI demand growth (Indonesia and Vietnam's AI adoption rates growing over 200% annually), with minimal regulatory resistance to Chinese chips. In Southeast Asia and Belt and Road markets, Huawei's government-enterprise relationships and compliance capabilities may be more persuasive than model performance.
Another structural variable cannot be ignored: regulation. China's model registration system, content review requirements, and data export restrictions form tangible entry barriers for the MaaS market. Volcano Engine has the largest consumer-side share, but Huawei Cloud's advantage in the government and enterprise market stems largely from compliance capabilities, not just hardware. Baidu's share is declining, but its compliance accumulated in search and education means it won't exit easily. Regulatory barriers prevent China's MaaS market from simply evolving into "winner-takes-all."
5. Risks and Outlook
Near-Term Pressures (6-12 months)
Token consumption is growing faster than costs are falling. The Jevons Paradox means that cutting prices leads to burning more money. ByteDance's 2025 computing expenses exceeded 30 billion yuan with -70% net profit, and other providers face similar conditions. If financing environments tighten or parent companies adjust strategy, MaaS divisions may face budget compression. But there's a counterintuitive buffer: the Jevons Paradox also means the total pie is expanding as token consumption surges. Even with per-token losses, total revenue is still growing. As long as cash flow keeps turning, MaaS can keep burning.
Model homogenization is a more practical pressure. When the performance gap between Claude, GPT, Gemini, DeepSeek, and Qwen narrows to 5-10%, "using the best model" is no longer a necessity; "using the cheapest model" becomes the default. This benefits direct-to-market players with good cost control (DeepSeek), is neutral for aggregation (routing value shifts from quality-based to price-based), and poses a real threat to high-priced overseas providers.
Open-source models become critical at this stage. Llama 4, Qwen open-source versions, and DeepSeek open weights let anyone self-host inference. Open-source model downloads on Hugging Face grew 340% year-over-year in Q1 2026. This directly erodes the mid-to-low-end MaaS market: if developers can run an open-source model at 85% of flagship quality for free, why pay API fees? This isn't a distant threat; it's happening now.
Mid-Term Differentiation (12-24 months)
Tiered pricing will shift from "optional" to "standard." Three-tier pricing (input/output/cache) will cover mainstream MaaS services, with the price spread between high-precision inference (math, code) and low-precision inference (chat, summarization) widening to over 10x. This means MaaS revenue structures will become more complex and healthier.
The aggregation layer may differentiate. The top 2-3 players will capture over 70% of routing traffic (OpenRouter and SiliconFlow are the most likely candidates), vertical aggregation (code, video, medical, finance) will take 20%, and the remainder will be absorbed by cloud and model providers building their own aggregation. The survival space for bottom-tier aggregation will continue to shrink.
Long-Term Variables (24+ months)
NVIDIA's acquisition of Groq is a signal. Groq's LPU (Language Processing Unit) uses deterministic execution to replace GPU dynamic scheduling, offering unique advantages in latency-sensitive inference scenarios. Once NVIDIA integrates LPU technology into the CUDA ecosystem, the hardware foundation for PD separation will mature, potentially pushing inference costs down another step. If inference hardware shifts from GPUs to specialized accelerators, the entire MaaS cost structure will be rewritten.
New inference paradigms may emerge in text generation. Diffusion models have already demonstrated an alternative to autoregression in image generation. Google's DiffusionGemma experiments show that diffusion paradigms can achieve higher throughput in certain text generation scenarios. If this direction matures, inference engine tech stacks will need to be rebuilt.
The tipping point for domestic chips is approaching. Huawei's Ascend 950 is already in commercial use on Huawei Cloud MaaS, and Alibaba's Hanguang is being optimized for inference. If domestic chips break through the H100 cost-performance inflection point in 2027-2028, China's MaaS cost structure will be fundamentally rewritten. At that point, the next cycle of the Jevons Paradox begins: lower costs, greater demand, continued growth in total spending.
Disclaimer: This article is based on publicly available information, drawing from IDC "China Enterprise MaaS Market Report" (2025), QuestMobile Doubao token data reports (2026), DeepSeek V3 technical report, OpenRouter Series B funding announcement (May 2026), Baidu Baike OpenRouter entry, Cailian Press/Wall Street See SiliconFlow financing reports, LMSYS Chatbot Arena evaluation data, and official pricing pages of various providers. This is not investment advice. Data as of June 16, 2026.