This is the companion piece to "The Token Distribution Era," focusing on the technical optimization stack of MaaS services. For market analysis and business anatomy, see the main article.
DeepSeek reduced per-token inference cost from the industry baseline of $0.12 to approximately $0.005, a 96% reduction. This isn't the achievement of any single breakthrough but the compounding result of six independent technical levers. This article dissects each lever's principles, effects, trade-offs, and how they combine into a complete inference optimization stack.
1. Evaluation Framework: Effectiveness, Efficiency, Experience
Before discussing MaaS technical optimization, let's define the evaluation dimensions.
Effectiveness: the model's ability to complete user tasks. This is the hard threshold. Current flagship models have narrowed considerably: based on composite assessments across LMSYS Chatbot Arena (human-preference ELO ratings), MMLU (Massive Multitask Language Understanding), HumanEval (code generation), and other major benchmarks, Claude 4.5, GPT-5.5, Gemini 2.5 Pro, and DeepSeek V4 have a comprehensive gap of just 5-10% on general tasks. But the gap varies significantly by dimension: text summarization may differ by only 2-3%, math reasoning and code generation by 10-15%, and long-context understanding (LongBench, RULER) shows more scattered results. Effectiveness is no longer the sole dimension determining winners, but being in the top 20% is the entry ticket.
Efficiency: output per unit cost. Three sub-metrics: throughput (tokens per second), time to first token (TTFT, how long the user waits for the first output token), and per-token cost (dollars per million tokens). Efficiency is the primary battleground in current MaaS competition, and the subject of this article.
Experience: API stability (SLA, jitter rate), documentation completeness, SDK usability, billing transparency, and failover speed. This dimension is often underestimated but has enormous impact on developer retention. OpenRouter's investment in unified API format, real-time model status panels, and automatic failover is key to its sustained growth to 8 million users. Volcano Engine's Coding Plan experience (IDE plugin integration, streaming output, long context windows) is also significantly better than calling raw APIs directly.
Priority order: Effectiveness > Efficiency > Experience. Top-20% effectiveness is the hard gate, top-5% efficiency is the main battlefield, and continuous experience optimization is the retention key.
2. Six Levers of Inference Optimization
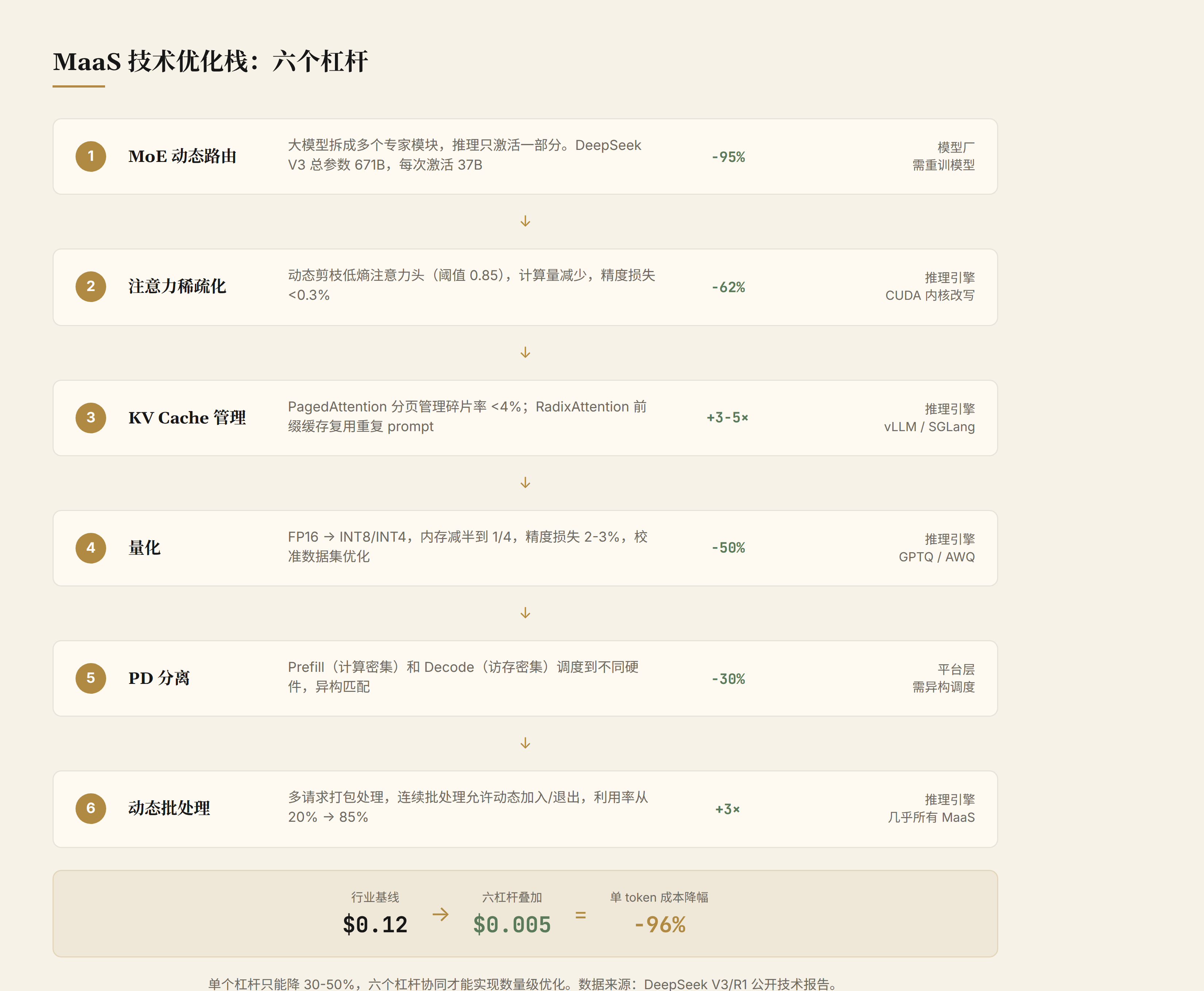
Lever 1: MoE Dynamic Routing
Principle. MoE (Mixture of Experts) is a conditional computation architecture. Traditional dense models run all parameters during every inference, while MoE splits the model into multiple "expert" sub-networks. A router (gating network) dynamically selects which experts to activate based on the current input.
DeepSeek V3's architecture uses 256 routing experts + 1 shared expert, with total parameters of 671B (670 billion). Each inference activates only 8 routing experts plus 1 shared expert, engaging approximately 37B parameters. Computation drops to 5.5% of the dense model. From the user's perspective, this delivers the knowledge capacity of a 671B model at the computational cost of a 37B model.
Key design: Shared Expert. DeepSeek V3's shared expert is a full-scale expert that is always activated, handling general semantic understanding. Routing experts handle specialized capabilities (code, math, multilingual, etc.). This design solves a real problem in pure-routing MoE: some experts are selected frequently (hot experts) while others are barely used (cold experts), causing load imbalance. The shared expert absorbs general computation, making routing expert loads more uniform.
Key design: Load Balancing Loss. MoE training requires an auxiliary loss function to encourage the router to distribute tokens evenly across experts. Without this, the router collapses to selecting only a few experts. DeepSeek V3 uses a no-auxiliary-loss load balancing strategy (bias-based routing), dynamically adjusting routing bias terms to achieve balance, avoiding the interference that auxiliary loss imposes on main-task gradients.
Effect. Compared to a dense model with equivalent total parameters, MoE reduces inference computation to 5.5%. This equates to approximately 18x throughput improvement on the same hardware. This is the single largest effect among the six levers.
Trade-off. MoE cannot be retrofitted onto existing dense models. It must be used from the pre-training stage, with specialized design for training configuration, data mix, and routing strategy. MoE training is also more challenging: inter-expert communication overhead is high (requiring All-to-All communication), demanding specific network topologies; training stability is harder to control (router collapse, expert deadlock). Additionally, MoE models still require full parameter loading into memory (all 671B parameters), even though computation is reduced. This means MoE inference requires large memory configurations and is a heavy consumer of HBM (High Bandwidth Memory).
Who uses it. DeepSeek V3/V4 (256+1 experts), Mixtral 8x22B (8 experts), Qwen-MoE series, Switch Transformer (Google, one of the earliest large-scale MoE models). GPT-4 is also reported to use MoE architecture (not officially confirmed).
Lever 2: Attention Sparsification
Principle. The Transformer's self-attention mechanism computes attention weights between every token and every other token in the sequence. For a sequence of length N, the attention matrix is N×N, with computational complexity growing quadratically. For a 128K-context model, this means computing 128,000 × 128,000 = 16.4 billion attention pairs per inference.
The core insight of sparsification: not all attention pairs are meaningful. Analyzing attention weight distributions reveals that most weights concentrate on a few tokens (local attention), while long-range attention weights are small but cover a wide area. Dynamically skipping low-contribution attention computation during inference can drastically reduce compute.
Methods. DeepSpeed and vLLM have implemented different forms of attention sparsification. One typical approach is entropy-based pruning: computing the attention distribution entropy for each attention head. Heads with low entropy (concentrated distribution) are kept; heads with high entropy (uniform distribution, low information) are disabled. Different implementations use different thresholds, with industry experience values in the 0.8-0.9 range (normalized entropy).
Another approach is Local-Global Separation: splitting attention into a local window (only attending to the nearest 1024 tokens) and global sampling (sparsely sampling tokens from the full sequence), skipping most mid-range attention. Longformer and Big Bird adopted this strategy.
Effect. Based on engineering practice experience, attention sparsification can reduce attention computation by approximately 60%, with overall inference speed improvement of 30-40%. Precision loss is about 0.3% (on MMLU and similar benchmarks), acceptable for most application scenarios.
Trade-off. Requires CUDA kernel-level rewriting of the inference engine. Standard FlashAttention kernels don't support sparse mode, requiring custom Triton or CUDA kernels. This area is still rapidly evolving, without a mature standard solution like PagedAttention. Sparsification effectiveness varies significantly by task: good for long-text summarization, nearly ineffective for short dialogue.
Who uses it. DeepSeek's self-developed inference engine has attention sparsification built in. vLLM and SGLang have different implementations in experimental branches. Commercial MaaS services generally don't disclose whether they use this technique, but performance data suggests that top-tier providers' inference engines have similar optimizations.
Lever 3: KV Cache Memory Management
The Problem. KV Cache is the most memory-hungry component in LLM inference. During autoregressive generation, each token stores a pair of Key-Value vectors for subsequent tokens' attention computation. For a 70B model with 80 layers and hidden dimension 8192, a single token's KV Cache is approximately 2.6MB (FP16). A 4K-context request needs about 10GB; a 128K long-context request needs about 340GB.
Traditional memory allocation (pre-allocating contiguous maximum-length space for each request) has two serious problems. First, internal fragmentation: requests typically use far less than the maximum length, wasting pre-allocated space. Second, external fragmentation: frequent creation and release of differently-sized cache blocks fragment memory space, causing new requests to wait even when total free memory is sufficient, because no contiguous block is large enough.
PagedAttention (vLLM). Borrowing from operating system virtual memory paging, KV Cache is split into fixed-size "pages" (blocks), each storing KV vectors for a fixed number of tokens. A request's KV Cache doesn't need to be physically contiguous; page tables map to scattered physical blocks. Fragmentation drops from 60%+ to under 4%.
More importantly, PagedAttention enables flexible memory sharing. Different requests with the same prompt (e.g., multiple beam search candidates) can share the same KV Cache pages, only copying new pages when outputs diverge. In parallel sampling (generating multiple answers at once), memory usage can be reduced by 55%.
RadixAttention (SGLang). Building on paged management, this introduces a Radix Tree structure to manage and reuse prefixes. Multiple requests sharing the same prefix (system prompt, few-shot examples, tool descriptions) share the same path in the radix tree, creating new branches only where content diverges. Combined with LRU (Least Recently Used) cache eviction, high-frequency prefix cache hit rates can reach 80%+.
Effect. KV Cache management has the highest engineering maturity among all six levers. PagedAttention boosted vLLM throughput 3-5x over HuggingFace Transformers (across different load patterns). RadixAttention adds another 2-3x in scenarios with heavy prefix reuse (e.g., Agent workflows).
Trade-off. Page table management has approximately 4% extra CPU overhead. Radix tree maintenance and querying add latency overhead in high-concurrency scenarios. But these costs are far smaller than the gains.
Who uses it. vLLM (PagedAttention), SGLang (RadixAttention), TensorRT-LLM (NVIDIA's own KV Cache management), DeepSeek's self-developed engine. Volcano Engine and Alibaba Cloud Bailian's inference services are built on vLLM or its derivatives.
Lever 4: Quantization
Principle. Large model weights are stored by default in FP16 (16-bit floating point). Quantization compresses weights from high to low precision: INT8 (8-bit integer) or INT4 (4-bit integer). A 70B model requires approximately 140GB in FP16, 70GB in INT8, and only 35GB in INT4. Memory usage halves to quarter, and inference speed increases correspondingly (GPU INT8/INT4 compute throughput is far higher than FP16).
Mainstream Approach Comparison.
| Method | Principle | Advantage | Disadvantage |
|---|---|---|---|
| GPTQ | Layer-wise quantization based on second-order information | Good precision, supports group-wise quantization | Requires calibration dataset, time-consuming |
| AWQ | Activation-aware weight quantization | Protects weight channels sensitive to activations, good precision | Requires small amount of calibration data |
| SmoothQuant | "Smooths" activation outliers into weights | Excellent INT8 precision, supports W8A8 (both weights and activations quantized) | INT4 performance is mediocre |
| GGUF (llama.cpp) | Quantization format for CPU/edge | Low deployment barrier, runs on CPU | GPU inference speed inferior to other methods |
DeepSeek's Approach. DeepSeek V3 ships directly with an INT4 quantized version. Original FP16 weights are approximately 1.3TB (671B parameters), reduced to approximately 340GB after INT4 quantization. This is the key optimization that makes a 671B model runnable on reasonable hardware configurations. DeepSeek's quantization scheme combines group-wise quantization (independent quantization per 128 weights) with FP8 activations (activation values in 8-bit floating point rather than integer), achieving a good balance between precision and speed.
Effect. INT8 quantization typically loses 1-2% precision (MMLU benchmark), INT4 loses 2-3%. For inference speed, INT8 is approximately 2x faster than FP16, INT4 approximately 3-4x faster (limited by the number of low-precision compute units on the GPU).
Trade-off. Quantization is irreversible lossy compression. While precision loss is small, it can amplify in extreme scenarios (long-chain reasoning, code generation edge cases, math competition problems). Quantized models also need re-evaluation; precision cannot be assumed unchanged.
Lever 5: PD Disaggregation (Prefill-Decode Separation)
Principle. LLM inference has two stages with fundamentally different computational characteristics:
Prefill stage: understanding the input prompt, performing massive matrix multiplications, generating KV Cache. This is compute-bound; GPU compute units are fully loaded but memory utilization is low. For 4000 input tokens, Prefill might complete in 200ms.
Decode stage: generating output tokens one at a time, each requiring a full read of the KV Cache for attention computation. This is memory-bound; GPU compute units are mostly idle but HBM bandwidth is saturated. For 500 output tokens, Decode might take 5-10 seconds.
The traditional approach runs Prefill and Decode on the same GPU pool. The problem is that the two stages' resource utilization is complementary but cannot be simultaneously satisfied: during Prefill, memory bandwidth is idle; during Decode, compute is idle. The GPU spends half its time waiting.
PD Disaggregation schedules the two stages onto different hardware pools. The Prefill pool uses compute-strong GPUs (e.g., H200, high FP16 throughput), while the Decode pool uses memory-bandwidth-heavy GPUs (e.g., H100 NVL, large HBM bandwidth), or even cheaper hardware (L40S or CPU/FPGA) for low-priority Decode requests. The two pools scale independently, each maintaining high utilization.
Engineering Challenge. PD disaggregation introduces cross-node communication overhead: KV Cache generated during Prefill must be transferred to Decode nodes. A 4K-context request's KV Cache is approximately 10GB; with RDMA/InfiniBand, latency is about 5-10ms; with Ethernet, it could be 50-100ms. Whether this latency is acceptable depends on the scenario: significant impact for TTFT-sensitive scenarios (real-time chat), negligible for throughput-priority scenarios (batch processing).
The scheduling system is also far more complex than unified scheduling. It needs to predict Prefill completion time, evaluate Decode pool load, and determine request routing. Mooncake (Moonshot AI/Kimi), Splitwise (Microsoft Research), and DistServe are all explorations in this direction.
Effect. Resource utilization improves 30-40%. In Kimi's practice, PD disaggregation reduced TTFT for long-context requests (128K+) by 60% while increasing overall throughput by 40%.
Trade-off. Requires heterogeneous hardware pools and high-bandwidth network interconnects. The scheduling system has high development and maintenance costs. Cross-node KV Cache transfer is sensitive to network latency.
Who uses it. DeepSeek (self-developed scheduling system), Kimi/Moonshot (Mooncake system), Volcano Engine (partial PD disaggregation), Alibaba Cloud (PD disaggregation in experiments).
Lever 6: Continuous Batching
Principle. GPU compute efficiency depends heavily on batch size. At batch size 1, GPU utilization might be only 20-30%; at batch size 32, it can reach 70-85%. MaaS services need to process large numbers of user requests simultaneously; packing these requests into a batch for parallel computation is the fundamental way to improve efficiency.
Traditional static batching accumulates requests into a batch before computing together. The problem: the first request to finish in a batch must wait for the slowest request to complete before returning, so response latency is dragged down by the slowest request.
Continuous Batching (also called In-flight Batching or Iteration-level Batching) solves this. It schedules at the token level: at each Decode iteration step, it checks whether new requests can join the current batch and whether completed requests can exit. Requests don't need to wait for a full batch to start, nor do they wait for other requests to finish before returning.
Effect. GPU utilization increases from 20-30% (single request) to 70-85% (multi-request continuous batching). Throughput improves 3-4x. This is the lowest engineering cost among all six levers: no model changes, no heterogeneous hardware, just requires the inference engine to support token-level scheduling.
Trade-off. Almost none. Continuous batching is a standard feature of modern inference engines. The only consideration is QoS (Quality of Service): when high-priority and low-priority requests are mixed in the same batch, scheduling policies must ensure that high-priority request latency isn't affected by low-priority requests.
Who uses it. All modern inference engines support it: vLLM, SGLang, TensorRT-LLM, DeepSeek's self-developed engine.
3. Inference Engine Comparison
The six levers don't operate independently; they need to be integrated into an inference engine that coordinates their work. Current mainstream inference engines:
| Engine | Developer | Characteristics | Main Users |
|---|---|---|---|
| vLLM | UC Berkeley / Community | Native PagedAttention, widest ecosystem, easy deployment | SiliconFlow, 302.AI, many small/medium MaaS |
| SGLang | LMSYS / Community | RadixAttention + structured generation, strong for Agent scenarios | DeepSeek API (partial), research institutions |
| TensorRT-LLM | NVIDIA | Deep CUDA optimization, fastest on NVIDIA hardware | Large enterprises, cloud providers (Baidu, Tencent) |
| DeepSeek Inference Engine | DeepSeek | Self-developed full-stack, all six levers built-in, industry benchmark | DeepSeek's own services |
| Mooncake | Moonshot AI | PD disaggregation specialist, long-context optimization | Kimi |
| LMDeploy | OpenMMLab/Shanghai AI Lab | Domestic open-source, Ascend-compatible | Some Ascend ecosystem users |
A noteworthy trend is "convergent evolution" among inference engines. vLLM is adding SGLang's prefix caching capabilities, while SGLang is borrowing vLLM's continuous batching implementation. TensorRT-LLM has hardware-level advantages on NVIDIA GPUs (directly calling CUTLASS kernels) but poor cross-hardware compatibility. DeepSeek's self-developed engine leads in performance but is not open-source, preventing other providers from using it directly.
Engine choice has enormous impact on MaaS services. Volcano Engine's core inference engine relies on vLLM and SGLang, with engineering depth limited by open-source community iteration speed. DeepSeek's self-developed engine is the key moat enabling its $0.005/token pricing. SiliconFlow needs to adapt across multiple engines (different models may require different engines), creating high engineering complexity.
4. Compounding Effects and Marginal Returns
| Lever | Standalone Cost Reduction | Combined Contribution | Maturity |
|---|---|---|---|
| MoE Dynamic Routing | ~95% (computation) | Largest single contribution | Production-mature |
| Attention Sparsification | ~60% (attention compute) | Medium, scenario-dependent | Experimental to production |
| KV Cache Management | Throughput 3-5x | Large, engineering must-do | Production standard |
| Quantization | Memory 50-75% | Large, lowers hardware barrier | Production-mature |
| PD Disaggregation | Utilization +30-40% | Medium, requires heterogeneous hardware | Top-tier providers using |
| Continuous Batching | Utilization +50-60% | Foundational, must-do | Production standard |
Six levers combined: DeepSeek V3/R1 series per-token cost from industry baseline $0.12 to approximately $0.005, a 96% reduction (source: DeepSeek V3 technical report). With only one lever (e.g., only quantization), costs drop 30-50%. Two levers combined (quantization + KV Cache management) achieve 70-80%. Truly breakthrough cost reduction requires four or more levers working in concert.
But the levers have interaction effects; they're not simple multiplication. MoE reduces computation but increases memory requirements (all expert parameters must be loaded). Quantization reduces memory, potentially affecting PD disaggregation's KV Cache transfer strategy. Attention sparsification has different effects on different MoE experts. These interactions mean the inference engine needs global joint optimization, not per-lever independent tuning.
The Jevons Paradox applies here again. Technology compressed costs by 96%, but total token consumption grew over a thousandfold. The industry's total computing expenditure didn't decrease; it increased. ByteDance's 2025 computing bill of 30+ billion yuan is the evidence. This means the ceiling for inference optimization isn't "cost going to zero" but rather "every optimization unlocks new demand that the Jevons Paradox absorbs, requiring continued optimization."
5. Frontier Directions
Inference optimization continues to evolve rapidly. Several directions worth watching:
Speculative Decoding. A small model (draft model) quickly generates several candidate tokens, then a large model (target model) verifies them in parallel. If the small model's guesses are correct, it's equivalent to producing large-model output at small-model cost. Llama 3 and DeepSeek are both exploring this direction. Measured throughput improvement of 2-3x, but requires finding a draft model whose distribution matches the target model.
FP8 Inference. FP8 (8-bit floating point) sits between FP16 and INT8, with minimal precision loss but speeds approaching INT8. NVIDIA H100/H200 natively supports FP8 computation. TensorRT-LLM and vLLM are both adding FP8 support. This could become the standard configuration for next-generation inference engines.
Multi-tier Caching. Layering KV Cache storage across HBM, DRAM, and SSD, with LRU eviction policies migrating between tiers. For ultra-long context (128K-1M) scenarios, a single GPU's HBM cannot hold the complete KV Cache. Multi-tier caching makes long-context inference feasible. The Mooncake system has done deep exploration in this direction.
Compiler Optimization. AI compilers (TorchInductor, TensorRT, OpenAI Triton) can perform global computation graph optimization: operator fusion (combining multiple small operators into one large kernel), memory reuse, automatic mixed precision. Deep integration between inference engines and compilers is the next optimization frontier. DeepSeek's self-developed engine reportedly makes heavy use of Triton custom kernels rather than relying on framework-provided CUDA kernels.
On-device Inference. As model quantization and small models (7B-14B) improve, more inference can happen on-device (phones, PCs, edge devices). Apple Neural Engine, Qualcomm AI Engine, and Intel AI PC are all pushing this direction. On-device inference latency (<10ms) is far superior to cloud (50-200ms), but model capability is limited. Edge-cloud collaboration (simple tasks on-device, complex tasks in cloud) is the long-term direction.
Disclaimer: This article is based on publicly available information, with technical data primarily referencing the DeepSeek V3 technical report (arXiv:2412.19437), vLLM paper (PagedAttention, SIGGRAPH 2023), SGLang paper (RadixAttention, ICML 2024), Mooncake technical report, Longformer/Big Bird papers, and official documentation and GitHub repositories of various inference engines. Cost data represents engineering estimates; actual values vary significantly based on deployment conditions. This is not investment advice. Data as of June 2026.