As inference replaces training as the primary battlefield for AI infrastructure, GPU cluster network topology needs to be rethought from scratch.
1. Why Network Topology Suddenly Matters
As large model clusters evolve from thousands to tens of thousands of GPUs, raw GPU compute is no longer the sole bottleneck. The network links connecting that compute now directly determine a cluster's effective throughput.
Two landmark events occurred almost simultaneously:
- May 5, 2026: OpenAI, together with NVIDIA, AMD, Intel, Microsoft, and Broadcom, released the MRC (Multipath Reliable Connection) protocol — solving the network communication bottleneck for ultra-large-scale GPU clusters at the transport protocol layer.
- May 21, 2026: Zhipu AI, together with Tsinghua University and Yuxun Network, announced the ZCube networking architecture deployed in the GLM-5.1 production cluster — solving the same problem at the topology architecture layer.
These represent two complementary technical paths: protocol-layer optimization (MRC) and architecture-layer restructuring (ZCube).
This article uses ZCube as a baseline, analyzes its core value and limitations, derives P:D ratios and placement strategies for PD disaggregated inference, and then proposes RailFly — a pragmatic topology family covering mixed training+inference workloads, and its pure-inference evolution PDX-Fabric.
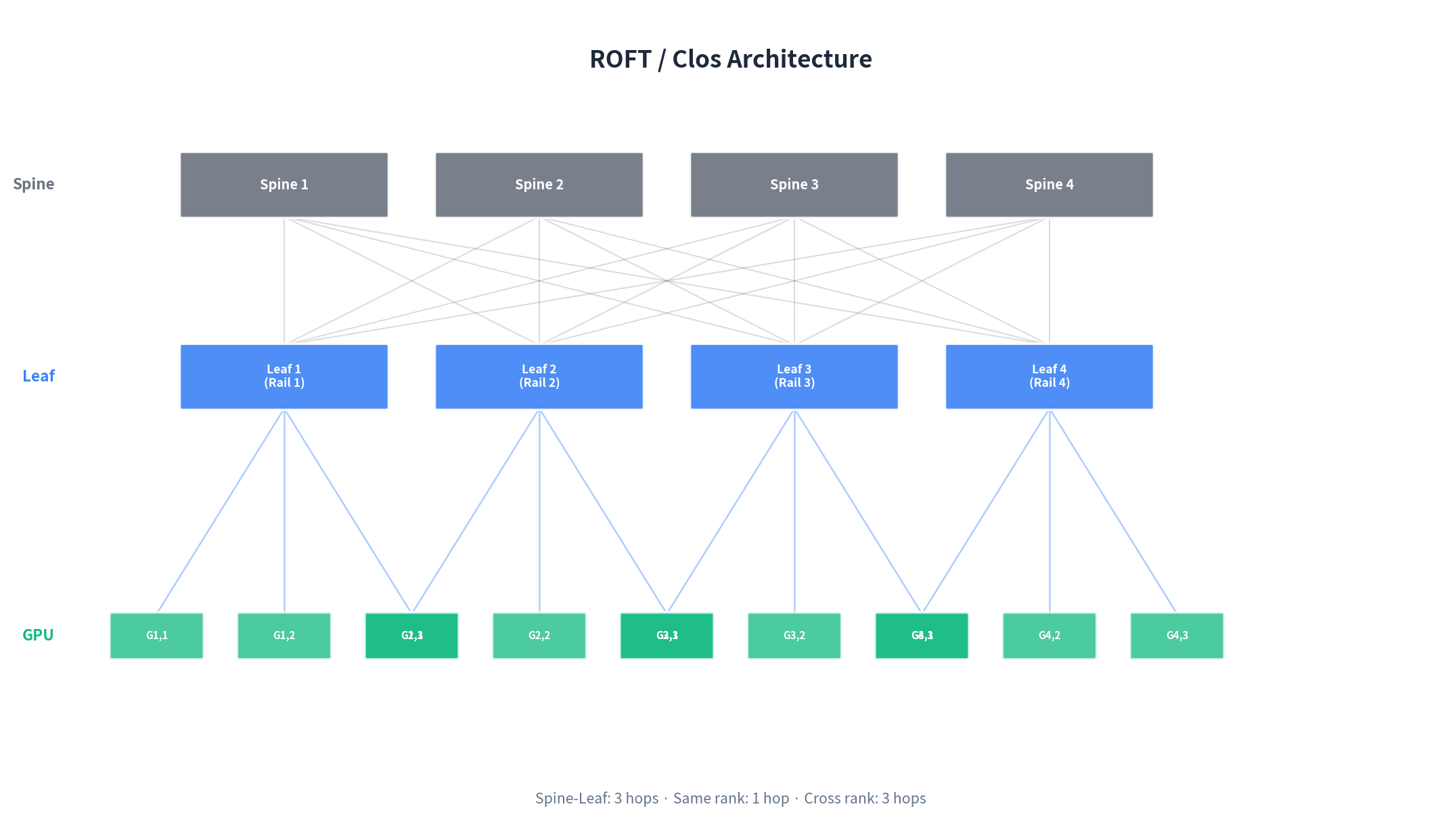
ROFT's Design Assumptions Are Breaking Down
Current mainstream GPU cluster networking is based on ROFT (Rail-Optimized Fat-Tree): GPUs are grouped by rank into rails, with same-rank GPUs connecting to the same switch. DP/PP communication during training completes in 1 hop within a rail. The design assumption is that same-rank GPUs communicate the most, so traffic naturally aligns with rails.
Prefill-Decode disaggregated inference breaks this assumption. KV Cache is transmitted cross-node from Prefill nodes to Decode nodes, and this traffic exhibits three characteristics:
- Strong source-destination asymmetry: The KV Cache transfer load across different GPUs can differ by orders of magnitude.
- Dynamic variation: Which P nodes pair with which D nodes is determined in real-time by the scheduler and is not predictable.
- Burstiness: Long-context requests generate large KV Cache transfers with high instantaneous bandwidth demands.
ROFT's rail mapping fails under this traffic pattern — traffic gets concentrated onto a few switches and links, triggering PFC backpressure, creating a structural problem of "abundant total bandwidth, frequent local congestion."
2. ZCube's Core Value and Limitations
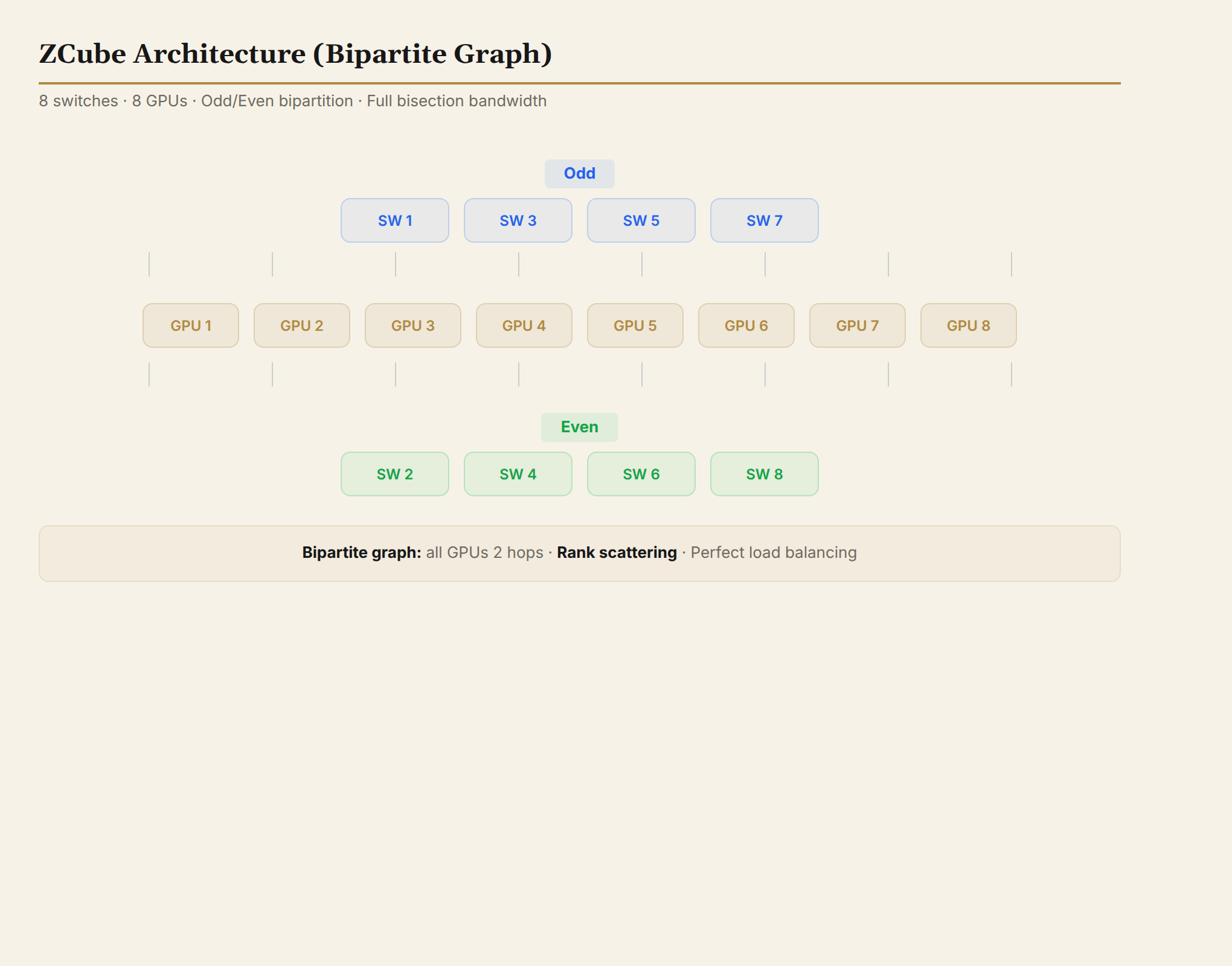
Architecture Design
ZCube completely breaks away from Clos hierarchical thinking, restructuring the network around fully flat bipartite graph interconnection:
- Eliminate the Spine layer. All switches are divided into odd-numbered and even-numbered groups.
- Each GPU's Port 1 connects to one odd switch, Port 2 connects to one even switch.
- A complete bipartite graph interconnection is formed between the odd and even groups.
All GPUs in the network are reachable within 2 hops. The routing goal is to have GPU pairs traverse unique/deterministic preferred paths, reducing the local hotspots and PFC backpressure caused by ECMP or static rail mapping.
Production Validation Data
The thousand-GPU production cluster for GLM-5.1 coding inference was migrated from ROFT to ZCube, with GPU hardware, software stack, and application unchanged:
- Switch and optical module CapEx reduced by ~33%
- Average GPU inference throughput +15%
- TTFT P99 reduced by 40.6%
The original paper also conducted a 32-GPU bandwidth ablation: increasing NIC available bandwidth from 100Gbps to 200Gbps improved throughput by ~19% and reduced TTFT by ~22%. This shows the bottleneck isn't purely GPU compute — it's KV Cache transfer and network hotspots under PD disaggregation that affect effective throughput.
Network cost-performance rough calculation: Network hardware cost becomes 0.67×, throughput becomes 1.15×, network hardware/throughput cost ≈ 0.67/1.15 ≈ 0.58, meaning network-layer cost-performance improves by ~70%.
Three Core Advantages
First, it disperses PD traffic's source/destination/scale asymmetry. The bipartite graph + dual-port single-rail/multi-rail access distributes dynamic P→D KV Cache traffic more evenly than Clos/ROFT.
Second, deterministic routing eliminates structural congestion. The topology itself doesn't assume any specific traffic pattern, eliminating topology-induced congestion hotspots at the root.
Third, gains come from reducing structural congestion, not adding GPUs. "Effective throughput per unit of network CapEx" improves significantly.
Four Practical Limitations
1. Physical topology restructuring, not a software patch. The original paper explicitly states that Clos-era cabling, IP addressing, routing policies, and switch configurations cannot be reused directly — they require redesign and automated validation.
2. It solves "avoidable congestion," not last-hop incast. When multiple Prefill nodes simultaneously push KV to the same Decode group, you still need scheduling, congestion control, and traffic shaping.
3. Full bipartite graph imposes high requirements on cabling and port counts. At larger scales, it increasingly depends on high-radix switches, breakout, automated cabling validation, and topology-aware scheduling.
4. Training scenarios lose rank locality. Same-rank GPUs no longer connect to the same switch, so DP/PP communication during training goes from 1 hop to 2 hops.
3. GLM-5.1's Inference Service Unit and KV Cache Bottleneck
Before discussing topology choices, we need to understand where the bottleneck actually is.
GLM-5.1 official specs: 744B-A40B, available in BF16 and FP8 versions; official vLLM/SGLang examples use --tensor-parallel-size 8, so an 8-GPU node/TP group is the minimal complete inference unit in practice.
Official parameters: maximum context 200K, maximum output 128K; input $1.4/MTok, output $4.4/MTok, output/input price ratio ~3.14. Price doesn't equal true cost, but it's a usable proxy: the serving cost/resource pressure per generated token is roughly 3× that per input token.
KV Cache Per-Token Estimation
Using the public config, a rough estimate for GLM-5.1's MLA/DSA-style KV latent cache stored in BF16:
78 × (512 + 64) × 2 ≈ 89,856 Bytes/token
78 is the number of layers, 512 is kv_lora_rank, 64 is qk_rope_head_dim, 2 is BF16 bytes. If actual KV Cache uses FP8 quantization, this roughly halves.
| Prompt Length | P→D Total KV/Request | Per-Card Share at TP=8 |
|---|---|---|
| 32K | ~2.94 GB | ~370 MB |
| 128K | ~11.5 GB | ~1.4 GB |
| 200K | ~18.2 GB | ~2.3 GB |
This is the fundamental reason topology optimizations can affect TTFT P99: each inference request generates hundreds of MB to several GB of cross-node transfers, and the network topology determines whether these transfers are evenly distributed or concentrated on a few hotspot links.
4. PD Disaggregation P:D Ratio Estimation
Without real token distribution data, the ratio can only be an engineering estimate, not a definitive answer. But we can start with a first-order formula:
P/D ≈ (Ī_eff) / (3.14 × Ō) × h
Where Ī_eff is the average input tokens missing the cache, Ō is the average generated tokens (including reasoning, tool-call JSON, final answer), 3.14 comes from the official output/input price ratio, and h is the TTFT/SLO headroom (recommended 1.1–1.2 under ZCube, higher under ROFT).
With context caching:
Ī_eff = Ī × [(1-H) + H × 0.26/1.4]
H is the cache hit ratio, 0.26/1.4 comes from the official cached input/input price ratio. When coding agents heavily reuse context, the P pool becomes noticeably lighter, and the ratio shifts from Prefill-heavy toward closer to 1:1 or even Decode-heavy.
| Workload Profile | Assumed Average Tokens | Formula-Estimated P:D | Recommended Starting Config |
|---|---|---|---|
| Deep thinking / long output | 16K in / 8K out | 0.64:1 | 1:1, or 2:3 |
| Typical coding agent | 24K in / 6K out | 1.27:1 | 3:2 |
| Repo-heavy long context | 32K in / 4K out | 2.55:1 | 2:1–5:2 |
| 32K/6K with 40% cache hit | effective input ≈21.6K | 1.15:1 | 4:3–3:2 |
Default recommendation: start with P:D ≈ 3:2. If production shows long output/reasoning tokens, lower to 1:1; for repo ingest, heavy long-context, short-output scenarios, raise to 2:1.
ZCube's 15% throughput improvement doesn't directly change the P:D formula, but it lets you reduce network congestion headroom and run closer to the theoretical ratio.
The D Pool Isn't Just About Compute — KV Memory Matters Too
Don't size the P/D ratio based solely on prefill/decode FLOPs. Another critical responsibility of Decode nodes: long-term retention of active sessions' KV cache.
D pool size should be the maximum of three values:
N_D = max(N_D_decode_compute, N_D_KV_memory, N_D_KV_ingress)
If your workload includes many 64K, 100K, 200K context sessions, even if token compute models suggest more P, the D pool still can't be too small. Otherwise D-side gets bottlenecked on KV cache memory — P nodes idle, D nodes have full VRAM, requests can't be admitted, TTFT jitters.
Engineering recommendations:
- Short output, long prompt: can go 5:3, even close to 2:1
- General coding: ~3:2
- Long reasoning / multi-turn agent: 1:1 to 4:3
- Ultra-long context with high concurrency: prioritize D memory, even at the cost of fewer P
5. ZCube Cell Scale Design
ZCube formula from the original paper: total GPU count n, each switch connects k GPUs, total switches 2n/k, complete bipartite graph between the two groups; each switch has approximately k + n/k logical ports. Port utilization is optimal when k ≈ n/k ≈ √n.
With 8-GPU nodes, starting P:D ≈ 3:2:
| ZCube Cell Scale | 8-GPU Nodes | Balanced k | Logical Ports/Switch | Switches | Recommended P/D Node Config | Equivalent ROFT GPU Throughput |
|---|---|---|---|---|---|---|
| 1024 GPU | 128 | 32 | 64 | 64 | 80P / 48D | ~1178 |
| 4096 GPU | 512 | 64 | 128 | 128 | 320P / 192D | ~4710 |
| 16,384 GPU | 2048 | 128 | 256 | 256 | 1280P / 768D | ~18,842 |
"Equivalent ROFT GPU throughput" calculated at +15%. Conversely, to achieve the same throughput as an ROFT cluster, ZCube needs approximately N_roft/1.15 GPUs.
The 16,384 Port Problem
The original paper states that 51.2T, 128×400G switches can support 16,384 400Gbps NICs. Per the port formula, 16,384 corresponds to 256 logical ports per switch. A more practical engineering interpretation is that 400G NICs are split into 2×200G logical ports, with switches calculated at 256×200G breakout. If you insist on every logical port being full 400G with only 128 logical ports per switch, the clean single-plane scale is 4096 GPUs; 16K requires multi-plane or higher-radix switches.
6. Intra-Cell P/D Placement: Even Distribution, No Physical Partitioning
The point of ZCube is to disperse the dynamic, asymmetric KV cache transfers under PD disaggregation. The core intra-cell strategy: don't artificially create a high-traffic cut from a P zone to a D zone.
Wrong approach:
Rack/Zone A: all Prefill
Rack/Zone B: all Decode
This would compress all KV cache transfers onto a few A→B links, directly undermining ZCube's design intent.
Correct approach: Every local topology segment contains both P and D, and P/D density along each odd/even switch dimension is close to the global ratio.
Affinity Tile Partitioning
Using 1024 GPUs / 128 nodes as an example, general 3:2 configuration:
- 25 tiles, each tile = 3P + 2D
- 3 flex nodes distributed evenly across topology
- Total: 75P + 50D + 3 flex
Tiles are not physically contiguous rows of machines — they're evenly hashed across ZCube's two switch dimensions. The goal is for every switch to see a P/D port count close to the global ratio.
| Configuration | Tile Composition | Tile Count | Flex | Use Case |
|---|---|---|---|---|
| General 3:2 | 3P + 2D | 25 | 3 | General coding agent |
| P-heavy 5:3 | 5P + 3D | 16 | 0 | Long input, short output |
| Balanced 1:1 | 4P + 4D | 16 | 0 | Long reasoning, multi-turn agent |
Flex Pool Elasticity
The 3 flex nodes dynamically switch roles based on real-time load:
- Long prompt peak: convert to P
- Long output / D cache peak: convert to D
- On failure: assume the failed node's role
When to Change P/D Ratio vs. When to Change Pairing Strategy
Signals to add P: Prefill queue P95/P99 high, P GPU utilization high and D low, KV transfer not congested, D memory sufficient, TTFT mainly bottlenecked on prefill wait.
Signals to add D: Decode queue high, D KV memory near limit, active session admission failures, output token backlog high, P nodes frequently waiting for D lease.
Signals that you should change pairing/routing, NOT the ratio: Both P and D GPUs are underutilized, but KV transfer P99 is high, certain inter-switch edges are hot, certain D ingress is overloaded, TTFT has sporadic long tails. This means the problem is in pairing and routing, not quantity — optimize scheduling first, don't add machines first.
7. P/D Pairing: Affinity Groups + Dynamic Selection, Not Fixed Binding
Don't Use Fixed P-D Pairs
Fixed binding (P1 always paired with D1) is simple but has three problems: one slow D drags down its bound P; long and short prompts can't dynamically stagger; D-side KV memory easily fragments — locally full, globally empty.
A better approach is affinity tile + dynamic selection:
Tile-17:
P: P17-0, P17-1, P17-2
D: D17-0, D17-1
P candidate D priority:
primary: same tile D
secondary: adjacent topology tile D
tertiary: any D in same cell
last: cross-cell overflow
New Sessions vs. Existing Sessions: Different Pairing Directions
New sessions: joint P/D selection. No historical KV exists. First estimate prompt tokens / output tokens / KV bytes, then jointly select a (p,d) pair:
score(p,d) = α·Qp + β·Qd + γ·Tkv(p,d) + δ·Hpath(p,d) + ε·Md − ζ·Acache
Select the (p,d) with the lowest score.
Existing sessions: D sticky, P reverse-selected. A multi-turn agent or coding session already has KV cache on a particular D — don't casually switch Ds, or you'd need to migrate historical KV at high cost. Existing sessions prioritize continuing on D_home, selecting a P that's topologically close to D_home for incremental prefill, transmitting only delta KV.
This is critical for coding agents — they're often multi-turn long-context, not one-shot prompts.
KV Transfer Credit: Lease First, Then Send KV
The most dangerous scenario in PD disaggregation: multiple Prefills complete simultaneously, the scheduler finds an idle D, and multiple Ps send GB-scale KV to the same D at once — D ingress, last hop, D NIC, D KV allocator all overload, TTFT P99 jitters.
Solution: D-side maintains KV ingress credits. Only when both D and path have credit can P start sending KV. Recommend each D concurrently receive 2–4 large KV streams; long prompts must reserve path credit in advance, short prompts can go best-effort.
Leveraging ZCube's Dual Paths for Load-Aware Routing
Within a ZCube cell, each node has two topology coordinates: P = (A_p, B_p), D = (A_d, B_d). P to D typically has two two-hop paths:
path 1: P → A_p → B_d → D
path 2: P → B_p → A_d → D
The scheduler doesn't just check if D is free — it also checks which path is less loaded. Fine-grained per-packet ECMP is not recommended (KV transfers are typically large; out-of-order delivery hurts RDMA/TCP efficiency). Instead, split by TP rank or route at the request level. For example, with an 8-GPU TP group: rank 0,2,4,6 take path1, rank 1,3,5,7 take path2.
TP Rank Consistency
For large model inference like GLM-5.1 where both P and D use TP=8, enforce Prefill TP rank i → Decode TP rank i. Don't do P rank i → D rank j — unless you explicitly plan a KV reshape, this adds an all-to-all or KV reordering that directly negates ZCube's network benefits.
8. RailFly: A Pragmatic Choice for Mixed Training+Inference Workloads
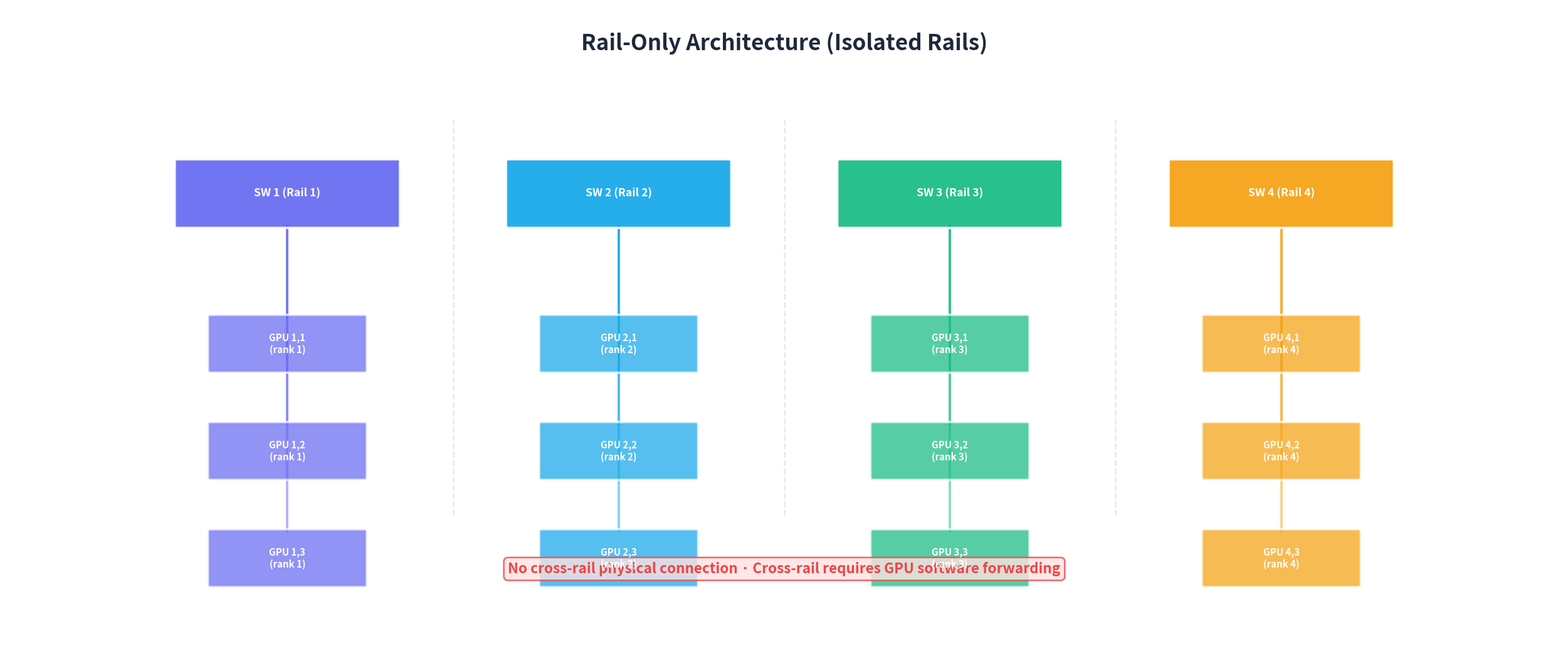
Design Motivation
Rail-Only (MIT CSAIL + Meta, 2023) has a core insight: in LLM training, 99%+ of cross-node communication occurs between same-rank GPUs, and the Spine is idle most of the time — it can be removed. Training-optimal (same rank in 1 hop), extremely low cost (38–77% cheaper than Clos). But it's basically unusable for PD disaggregated inference: cross-rail GPU software forwarding has unstable latency, P99 degrades severely.
The problem: P→D KV Cache flow is not stable same-rail communication — it's dynamic, asymmetric, with high source-destination variation. Pure Rail-only relies more on NVLink/HB domain forwarding, easily shifting TTFT tail latency elsewhere.
RailFly's approach: starting from Rail-Only, gain cross-rail hardware forwarding capability with minimal changes.
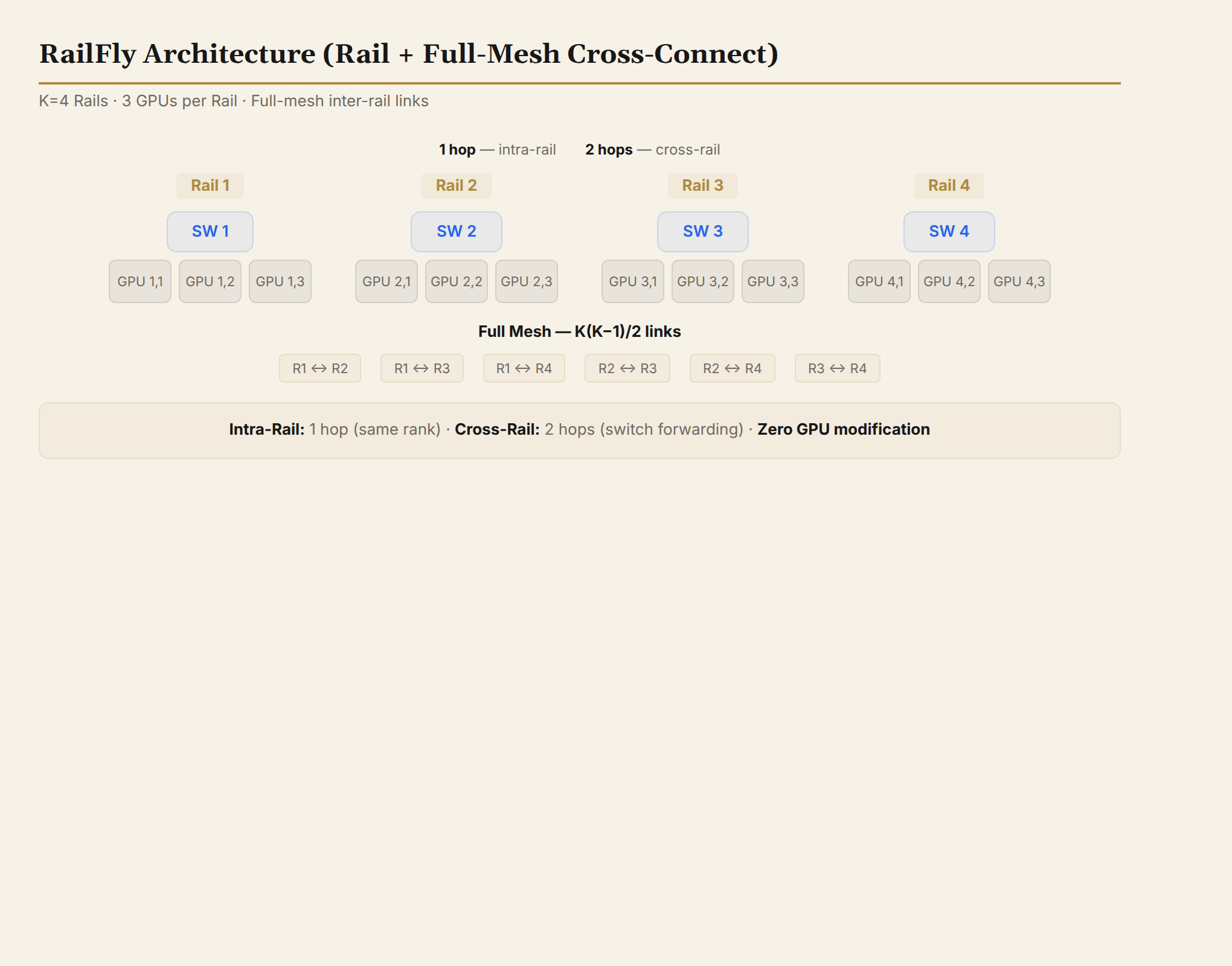
Architecture Definition
- K rails, each served by one switch. Same-rank GPUs connect to the same rail switch (Rail-Only rule unchanged).
- The K switches are fully interconnected (28 links when K=8).
- GPU port allocation unchanged — zero modification.
Core property: inter-group links are fixed at 28, not growing with cluster scale.
Scale and Oversubscription Ratio
| Configuration | Ports per Rail | Total GPUs | Inter-Group Links |
|---|---|---|---|
| 8× fixed 51.2T | 121 | 968 | 28 |
| 8× modular Arista 7800R3 | 569 | 4,552 | 28 |
| 8× modular H3C S12500R | 761 | 6,088 | 28 |
Compared to ZCube's scaling complexity:
| GPUs | RailFly Inter-Group Links | ZCube Bipartite Links |
|---|---|---|
| 1,000 | 28 | 15,876 |
| 4,000 | 28 | 250,000 |
| 8,000 | 28 | 1,000,000 |
Oversubscription ratio = downlink GPU bandwidth / uplink inter-group bandwidth. High oversubscription doesn't mean congestion — if a rail-aware scheduler achieves 90% PD pairing within rail, only 10% crosses rails, and 10:1 oversubscription is sufficient. The oversubscription ratio is not a pure network parameter — it's a joint optimization problem of the network and the scheduler.
With the same 128 switches, RailFly uses 1 port per GPU, 5.5% for interconnection, connecting ~15,488 GPUs; ZCube uses 2 ports per GPU, 50% for interconnection, capping at 4,096 GPUs. Under equal hardware budgets, RailFly connects ~3.8× more GPUs.

9. From Rail-Only to Hybrid ZRail / Sparse-ZCube
Adding switch direct connections to Rail-only gradually turns it into ZCube or Sparse-ZCube, not traditional Rail-only. A better approach is PD-aware Hybrid ZRail:
1. Intra-cell ZCube/full-bipartite: Within a 1024–4096 GPU cell, a complete bipartite graph ensures any P→D is 2 hops, paths are deterministic, and load is dispersed.
2. Inter-cell sparse expander/dragonfly-like direct connections: Beyond 4K, no need for global full-bipartite. Scheduling keeps P and D in the same cell whenever possible; cross-cell only for overflow.
3. Dual-rail QoS isolation: One rail handles traditional rail/local collective traffic; the other handles ZCube/expander traffic, with QoS isolation between KV transfer, control, and collective.
4. Topology-aware scheduling: Decode selection considers not just GPU idleness, but also P-switch-to-D-switch edge load, D pool queue depth, and last-hop incast.
5. Sparse direct-connect degree d determined by traffic: Port budget R = k + d; full ZCube is d = S. When PD traffic has locality, using d << S for an expander may be more cost-efficient.
Decision criterion: For maximum robustness, random P→D, multi-tenant mixed workloads, use ZCube/full-bipartite. When you can control P/D placement, cache locality is high, and business traces are stable, use Sparse-ZCube / Hybrid ZRail. Pure Rail-only is not recommended as the primary network for PD disaggregated inference.
10. RailFly's Pure-Inference Evolution: PDX-Fabric
ZCube is an excellent static topology. But PD inference isn't purely arbitrary traffic — it has four characteristics that a stronger architecture can exploit:
- P→D KV flows are large, and their size can be estimated when prefill begins;
- D is the state residency point — multi-turn sessions should generally stick to the same D or D group;
- Warm prefix / repo cache has clear locality;
- D-side is prone to ingress incast, not uniform all-to-all.
So a stronger architecture shouldn't just ask "how many hops between any two points" — it should ask:
- Can large KV flows reserve congestion-free paths?
- Is D-side ingress oversubscribed?
- Can cache-hit requests avoid cross-cell KV migration?
- Can the scheduler determine D before prefill starts and pre-provision the path?
PDX-Fabric is RailFly's evolution for pure-inference scenarios: retaining standard Ethernet switches as the base, adding a sparse expander foundation + KV Fast Lane + Cache/Home logical plane to achieve stronger P99 TTFT and D-side incast control than ZCube — without introducing OCS or dedicated hardware.
Three-Layer Capability
┌─────────────────────────────┐
│ Global PD Scheduler │
│ P/D load + KV size + cache│
└──────────────┬──────────────┘
│
┌──────────────┼──────────────────────┐
│ │ │
┌───────▼────────┐ ┌────────▼────────┐ ┌────────▼────────┐
│ Base Fabric │ │ KV Fast Lane │ │ Cache/Home Plane│
│ sparse expander│ │ priority queues │ │ logical policy │
│ control/small │ │ scheduled KV │ │ session locality│
└───────┬────────┘ └────────┬────────┘ └────────┬────────┘
│ │ │
P tiles / D tiles P leaf ↔ D leaf D island / cache
Base Fabric (Sparse-ZCube / Expander): Handles control plane, small KV, failure fallback, and general RDMA. Doesn't pursue a complete bipartite graph. Each switch uses k GPU downlinks + d electrical packet expander links + q dedicated KV fast lane links.
KV Fast Lane (Pure Ethernet QoS + Dedicated Links): Handles GB-scale P→D KV cache migration. No OCS — instead uses dedicated Ethernet links + priority queues + scheduler reservation to achieve congestion-free transfer for large KV flows. Each switch reserves 8–12 high-priority links exclusively for KV bursts, physically isolated or strictly QoS-isolated from the base fabric's expander links. The scheduler pre-reserves D ingress credits and link bandwidth quotas based on KV size before prefill begins.
Cache/Home Logical Plane: Keeps long sessions, warm prefixes, and shared repo cache within the same D island whenever possible. Warm sessions preferentially return to their original D island; only cold long prompts use the global KV fast lane.
Why PDX-Fabric Outperforms ZCube
Better P99 TTFT. ZCube reduces the probability of topology-induced congestion; PDX-Fabric further reduces queuing and contention for large KV flows. The scheduler knows approximate KV size before prefill begins and pre-reserves D buffer, D ingress, and link bandwidth quotas.
Better D-side incast handling. PDX-Fabric can design the D side asymmetrically — D-bearing switches have more inter-switch links, higher ingress credits, and more dedicated KV fast lane links. This better matches the real traffic characteristics of PD disaggregation.
Better scalability beyond 16K. ZCube's full bipartite graph requires 256 logical ports per switch at 16K. PDX-Fabric's expander degree d ≈ 8–16, KV fast lane q ≈ 8–24, approximately constant or slowly growing as scale increases. The tradeoff is dependence on the scheduler and traffic locality.
Better for cache-heavy coding agents. ZCube optimizes "transmit more smoothly"; PDX-Fabric also optimizes "transmit less, transmit closer, transmit only deltas." For multi-turn coding sessions, the same session stays on the same D group, the same repo cache stays on the same cache island, and Prefill reverse-selects a P close to D/cache.
1024 GPU Cell Deployment
Using the base configuration of 128 8-GPU nodes, 75P/50D/3 flex, 25 3P+2D affinity tiles:
64 Ethernet switches
Each switch:
32 GPU/NIC downlinks
8 expander inter-switch links (base fabric)
8–12 KV fast lane dedicated links (QoS isolated)
ZCube comparison: 32 downlink + 32 inter-switch = 64
PDX-Fabric: 32 downlink + 8 expander + 8–12 KV fast lane = 48–52
Request scheduling flow:
- Warm session: D-first, prefer D_home, select a P close to and idle near D_home, transmit only delta KV
- Cold long prompt: P/D joint select, reserve D ingress credit, reserve KV fast lane bandwidth quota, P pushes KV to D in write mode
- Short prompt: Use base expander fabric, don't occupy KV fast lane
Core principle: large KV takes reserved KV fast lanes, small KV uses base expander, warm KV avoids long-distance transfer, D ingress must have credit.
Simplified Variant: D-centric Asymmetric Expander
If you don't want the complexity of KV fast lane + QoS isolation, a simpler pure Ethernet approach is possible:
- Eliminate spine; inter-switch connections form a high-quality expander rather than a full bipartite graph
- D-bearing switches have higher inter-switch degree than P-bearing switches
- D nodes have more uplinks / higher credits
- P/D placement is strictly cache-aware and tile-aware
Normal P switch: 32 downlink + 8 expander links
D-heavy switch: 24–28 downlink + 12–16 expander links
Fewer static inter-switch links than ZCube, better cross-rail P→D support than Rail-only, better Decode ingress accommodation than a plain expander. But if P→D is completely random with low cache locality, stability is weaker than ZCube. Suitable for cost-sensitive scenarios where the scheduler is controllable.
11. Positioning of Three Pure Ethernet Architectures
| Architecture | Best For | Advantage over ZCube | Main Risk |
|---|---|---|---|
| ZCube | General-purpose, random P→D | Simple, stable, strong static topology | Doesn't exploit cache locality; large KV and small traffic share links |
| RailFly | Mixed training+inference, 10K+ scale | Inter-group complexity doesn't grow; 3.8× GPU capacity under equal hardware | Cross-rail bandwidth depends on scheduler pairing quality |
| PDX-Fabric (RailFly pure-inference evolution) | Long context, GB-scale KV, multi-turn agent | Better P99 TTFT, D incast, 16K+ scalability | Complex control plane; QoS isolation requires switch support |
12. Scenario Recommendations and Deployment Guide
| Scenario | Recommended Architecture | Reason |
|---|---|---|
| Pure PD disaggregated inference (thousand-GPU scale) | ZCube cell | Best load balancing, +15% throughput |
| Pure training | Rail-Only | Rail locality is key |
| Mixed training + inference | RailFly | Balances both, simple scaling |
| 10K+ GPU mixed workloads | RailFly + Hybrid ZRail | Inter-group complexity doesn't grow with scale |
| Long KV + multi-turn agent + controllable scheduling | PDX-Fabric | Large KV uses KV fast lane, cache-aware minimizes KV migration |
Three-Tier Deployment Recommendation
Tier 1, thousand-GPU production validation: 1024 GPUs, 128 8-card nodes, ZCube cell, 75P/50D/3 flex, 25 affinity tiles. The most stable starting point.
Tier 2, scaled production: 4096 GPUs, 512 8-card nodes, single cell or 4×1024-GPU cells, default 320P/192D. For 16K GPUs, recommend splitting into 4×4096 cells.
Tier 3, next-generation dedicated inference cluster: PDX-Fabric = Sparse expander + Ethernet KV fast lane + cache-aware D island + D-centric endpoint oversubscription. All based on standard Ethernet switches, suited for long-context coding agent GB-scale KV scenarios.
One-Line Summary
ZCube is "better static Ethernet"; a pure-Ethernet PD inference network stronger than ZCube should be "sparse expander base + KV fast lane dedicated links + cache-aware scheduling" — all on standard Ethernet switches, no OCS or scale-up hardware. RailFly finds the pragmatic sweet spot for mixed training+inference workloads in this spectrum: fixed 28 inter-group links, cross-rail hardware forwarding, 3.8× GPU capacity under equal hardware budgets.
References
- Yan, Z., et al. From ATOP to ZCube. ACM SIGCOMM 2025.
- Ghobadi, M., et al. Rail-only: A Low-Cost High-Performance Network for Training LLMs with Trillion Parameters. arXiv:2307.12169, 2023.
- Araujo, J., et al. Resilient AI Supercomputer Networking using MRC and SRv6. OpenAI, 2026.
- Zhipu AI Tech Blog. Next-Generation Large Model Inference Network Architecture: How ZCube Effectively Resolves Network Bottlenecks. z.ai/blog/zcube
- Wang, Z., et al. Opus: An Elastic, Reconfigurable Optical Interconnect for Compute Pods. NSDI 2026.
- Together AI. Chunked Prefill-Decode Disaggregation for Long-Context Serving. 2026.
- FlowKV: Global KV Cache Management for Disaggregated LLM Serving. 2026.