Two Revolutions, One Network: The Co-Evolution of AI Training Cluster Topology and Protocol
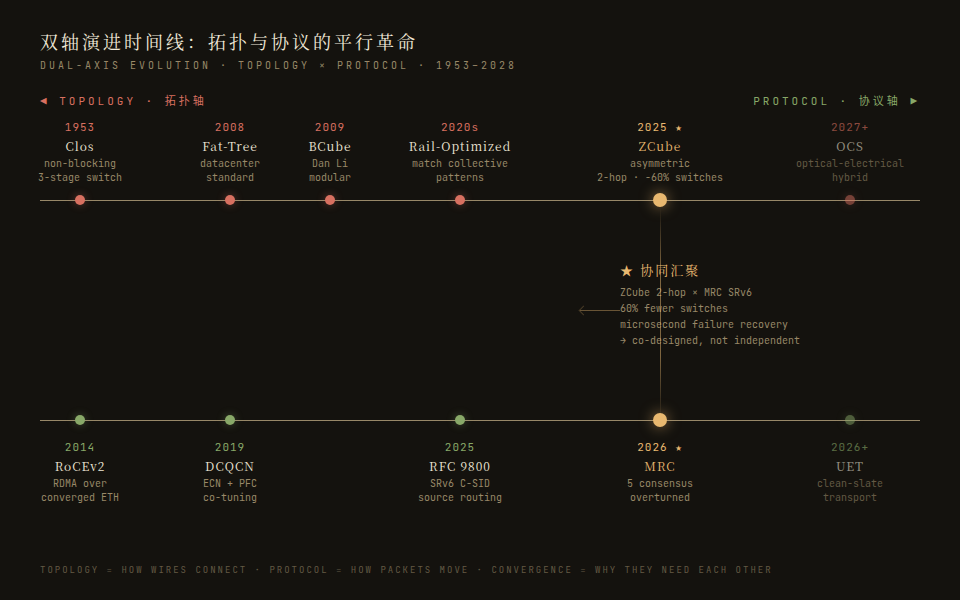
AI training networks at 100K GPU scale are undergoing simultaneous paradigm shifts on two axes: physical-layer topology (ZCube's asymmetric design cuts 60% of switches) and logical-layer protocol (MRC pushes intelligence from switches to NICs). The real story is that these two revolutions are mutually dependent — they must be co-designed. This overview builds a dual-axis framework, covering RoCEv2→MRC→UET protocol evolution, Clos→Rail→ZCube→OCS topology innovation, chip/vendor/cloud landscapes, and a scale-by-scenario decision framework.
This is the overview article of a three-part series. Companion piece one, "From CLOS to ZCube: Network Topology Evolution for AI Computing Clusters", dives deep into physical-layer topology innovation — ATOP automated search, asymmetric structures, sweet-spot scale, physical constraints. Companion piece two, "From RoCE to MRC: AI Cluster Transport Protocols and Chip Rearchitecture", dives deep into transport protocol evolution and chip implementation — EV state machine, SRv6 uSID, NIC/switch chip rearchitecture, China industry gap.
One Problem, Two Dimensions
By late 2025, OpenAI's production cluster runs 131,072 GPUs. ByteDance's training cluster reaches 16,384 GPUs. Google, Meta, Alibaba, and Microsoft are all pushing toward 100K GPU scale.
At this scale, the design assumptions of traditional datacenter networks collapse entirely. But the collapse doesn't happen in one place — it happens simultaneously on two dimensions:
Physical layer: how to connect. Traditional three-tier Clos at 100K GPU requires four switch layers, explosive numbers of optical modules, and severe latency stacking. Topology design shifts from "how to connect more" to "how to connect smarter."
Logical layer: how to route packets. RoCEv2's ECMP hashing inevitably produces flow collisions at scale. PFC creates cascading storms in multi-tier topologies. Dynamic routing convergence takes seconds while training jobs need microsecond-level recovery. Protocol design shifts from "how to route reliably" to "how to route fast and tolerate failures."
Over the past three years, each dimension has produced a paradigm-level breakthrough:
- Topology: ByteDance's SIGCOMM 2025 Best Paper ZCube transformed topology design from "expert intuition" to "automated search," discovering that asymmetric structures consistently outperform symmetric ones in AI training — cutting 60% of switches at the sweet-spot scale.
- Protocol: OpenAI, jointly with NVIDIA/AMD/Broadcom/Cisco/Arista, introduced MRC, simultaneously overturning five consensus assumptions in datacenter networking — rewriting everything from ECMP to PFC to dynamic routing, with the core idea of pushing intelligence from switches to NICs.
But these two revolutions didn't happen independently. ZCube's 2-hop diameter dramatically simplifies MRC's failure detection; MRC's SRv6 static source routing makes asymmetric topology path management feasible. They are two faces of the same problem and must be understood together.
Topology Revolution: From General-Purpose Non-Blocking to AI-Load-Specific
Three Assumptions of Clos
Charles Clos's 1953 non-blocking multistage switching network forms the basis of modern datacenter Fat-Tree topologies. Charles Leiserson brought it into parallel computing in 1985. It carries three implicit assumptions:
- Traffic patterns are unpredictable — requiring full bisection bandwidth for "any input to any output"
- Many independent small flows — ECMP hashing distributes evenly statistically
- Switches are homogeneous — same port count, same specs, simplifying procurement and operations
Under AI training workloads, all three assumptions collapse: collective communication patterns are highly regular (AllReduce/All-to-All repeat the same pattern every step — "any-to-any" is unnecessary); elephant flows collide easily (ECMP is uneven with few large flows); and ATOP's automated search reveals asymmetric structures consistently outperform symmetric ones.
Scale ceiling: A three-tier Fat-Tree with 64-port switches supports ~32K endpoints; four tiers reach ~64K but with sharply higher latency and cost. Three-tier Clos at 100K GPU scale either needs four tiers (higher latency/cost) or oversubscription (no bandwidth guarantee).
Rail-Optimized: From "General Connectivity" to "Matching Communication Patterns"
NVIDIA DGX SuperPOD's Rail+Global design represents the first step in topology evolution — no longer pursuing full connectivity, but matching actual AI training communication patterns.
Core idea: a GPU server has 8 GPUs, each with its own NIC. Instead of connecting all 8 NICs to the same ToR switch, connect GPUs in the same position across all servers to the same switch, forming 8 independent "Rails." Same-rank GPU communication requires only one hop; most traffic is absorbed at the Leaf layer, reducing Spine pressure.
Rail-Only vs Rail+Global: Rail-Only eliminates top-tier switches for lowest cost, but only supports highly localized communication (e.g., pure data parallelism). Rail+Global adds a Spine layer for All-to-All and other global communication, but at higher cost. Rail-Optimized is effective for AI, but remains fundamentally a symmetric topology — it doesn't challenge the "switches must be homogeneous" assumption.
→ Detailed Rail-Optimized design and PD-disaggregated inference analysis in Companion Piece One.
ZCube: Turning Topology Design into Hyperparameter Search
ByteDance, jointly with Tsinghua University, did something simple but unprecedented with ATOP (Automated Topology Optimization Pipeline): encoded all topology design decisions into 11 hyperparameter classes and searched the Pareto front using NSGA-II evolutionary algorithm.
11 hyperparameter classes cover inter-layer connections (GPU count, layer count, nodes per layer, blocking parameters, connection count, bandwidth factor 200G-800G) and intra-layer connections (dimensions, nodes per dimension, outward connections, coordinate computation factors), compressing the search space from O(2^N²) adjacency matrices to something searchable on a single 256-core server in 3 days.
14 optimization objectives: 9 DP/PP/Mixed traffic JCT + 2 MoE JCT + ForestColl all-gather + APS fault tolerance + cost. The flow-level simulator achieves only 1.5% average error versus NS-3 packet-level simulation.
Asymmetric structure discovery: Across searches at 256/1024/4096/16384 GPU scales, the optimal solution at the Pareto front knee consistently exhibits the same asymmetric characteristic — 2n ports for first/last layers, 3n ports for middle layers. The paper formalizes this as ZCube.
ZCube(n,k) recursive definition:
- ZCube(n,1) = 1 switch + n GPUs
- ZCube(n,k+1) = n × ZCube(n,k) + n^k switches
- GPU count = n^(k+1), switch count = (k+1) × n^k, each GPU has k+1 NIC ports
Key property: Network diameter = k (ZCube(128,2) has diameter just 2, vs 5-7 hops for three-tier Clos). Low diameter directly reduces PP traffic completion time — the primary source of end-to-end training speedup.
16K GPU Quantitative Comparison
Using Broadcom Tomahawk 5 (51.2T) switches:
| Topology | Switches | Cables | Training Iteration | Network Cost |
|---|---|---|---|---|
| ROFT | 640 | 49,152×400G | 5.19s | $92.93M |
| Rail-only | 384 | 32,768×400G | 5.15s | $76.38M |
| HPN | 384 | 16,384×400G + 32,768×200G | 5.10s | $84.03M |
| ZCube(128,2) | 256 | 49,152×200G | 4.95s | $57.28M |
ZCube uses 60% fewer switches than ROFT, 200G cables (vs 400G) cutting optical module cost by 25-50%, training 3-7% faster, with 26-46% lower network cost.
Sweet-Spot Scale and Production Validation
ZCube(n,k) requires each GPU to have k NIC ports. k=2 means each GPU needs 2 ports (one 800G NIC breakout into 2×400G), which most servers support. k=3 is beyond most servers.
| GPU Scale | Optimal ZCube | Switches | Worth it? |
|---|---|---|---|
| <500 | — | — | ❌ Flat is optimal |
| 512 | ZCube(23,2) | 46 | ⚠️ Marginal advantage |
| 1024 | ZCube(32,2) | 64 | ✅ Sweet spot |
| 4096 | ZCube(64,2) | 128 | ✅ |
| 16384 | ZCube(128,2) | 256 | ✅ Paper's core case |
1024-GPU ZCube(32,2) is the sweet spot: 64-port switches perfectly map to Tomahawk 5's standard configuration, zero port waste. Zhipu AI's ~1000-GPU inference cluster benefits at this scale — saving 1/3 optical modules and switches, boosting inference throughput 15%.
Fault tolerance: at 16K GPU, single ToR failure causes only 2.8% performance degradation for ZCube (vs 46.9% for ROFT). Fault-free probability: ZCube 93% (vs ROFT 83%) — fewer switches is itself a source of higher reliability.
→ Complete ZCube analysis (ATOP methodology, NVLink domain expansion, fault tolerance, production validation details, OCS comparison) in Companion Piece One.
OCS: Another Path for Topology Evolution
ZCube optimizes topology "within the electrical switching framework." Another path: replace Spine-layer electrical switches with Optical Circuit Switching (OCS).
Google Apollo has deployed OCS at scale since 2022 (3D MEMS micro-mirror arrays), saving an estimated $3B+ (SemiAnalysis). SIGCOMM 2025's InfiniteHBD goes further — integrating dynamic connection capability at the optical transceiver level.
| Dimension | Electrical Switching | OCS |
|---|---|---|
| Switching granularity | Packet-level (μs) | Circuit-level (ms) |
| Latency | Multi-hop accumulation | All-optical path, minimal |
| Power | Electrical processing per hop | Optical path passthrough |
| Best for | General purpose | Coarse-grained, predictable traffic |
OCS wins when: traffic is large, patterns are predictable, and scale is sufficient to make the Spine layer a bottleneck. AI training's collective communication fits perfectly. ZCube and OCS aren't competing — ZCube saves electrical switches, OCS replaces the Spine layer; they complement at different scale points.
Topology Evolution Summary
Four parallel directions:
- From symmetric to asymmetric (ZCube) — ATOP search proves asymmetric is superior
- From three tiers to two tiers (MRC multi-plane Clos) — OpenAI/Microsoft compress to two tiers
- From electrical to optical-electrical hybrid (Google Apollo OCS) — optics replacing electrical in Spine
- From switch intelligence to endpoint intelligence (MRC) — routing decisions shift from switch to NIC
→ Complete topology evolution path, quantitative comparisons, NVLink domain expansion, fault tolerance analysis, physical constraints (optical module cost, cabinet power, cabling distance as hard limits on topology choice) in Companion Piece One.
Protocol Revolution: From Switch Intelligence to NIC Intelligence
RoCEv2: Status and Limitations
RoCEv2 (RDMA over Converged Ethernet v2) is the de facto standard for AI training networks. 2-5μs latency, mature operations, only 0.5%-3% performance gap versus InfiniBand. Meta deploys RoCEv2 + DCQCN + ECN at >30K GPU scale — the industry benchmark.
But as scale grows, three bottlenecks cascade:
ECMP hash collisions. Each flow is hashed to one path. AI training produces few elephant flows (collective communication); two large flows landing on the same link causes congestion. Larger scale = higher collision probability.
PFC storms. RoCEv2 relies on PFC for lossless transport — when receive buffers near full, pause frames tell senders to stop. In multi-tier topologies, pause frames propagate upstream forming head-of-line blocking; pause frames at different priorities can even deadlock each other.
Dynamic routing convergence. BGP/OSPF recalculation after link failure takes tens to hundreds of milliseconds. Training jobs are extremely latency-sensitive — one convergence event can cause AllReduce timeout.
Meta's Ghost paper (SIGCOMM 2024) reveals a deeper problem: link flapping causes topology knowledge invalidation, producing "ghost" nodes. This isn't a "fix RoCEv2" problem — it's systematic design assumption collapse at scale.
RFC 9800: SRv6 Source Routing Infrastructure
RFC 9800 (published June 2025) defines Compressed SRv6 Segment List Encoding (C-SID/uSID/micro-SID). Standard SRv6 SID occupies 128 bits; a 10-segment path needs 160 bytes overhead — unacceptable in large-scale datacenters. C-SID packs multiple 16-32 bit compressed SIDs into one 128-bit container, reducing SRH overhead by 50%+.
Two implementation approaches: NEXT-C-SID (Cisco/F5, shift-and-lookup) and REPLACE-C-SID (China Mobile, deployed in 2022 cloud backbone, 10+ vendor interop tested).
Significance for AI networks: source routing enables multipathing — the sender encodes the complete path in the packet header; switches don't need dynamic routing. C-SID compression makes encoding overhead manageable. Microsecond-level failure bypass — path information is in the packet header, not the forwarding table; NICs detect failures and immediately switch to backup paths.
MRC: Overturning Five Consensus Assumptions
In May 2026, OpenAI jointly with AMD/Broadcom/Intel/Microsoft/NVIDIA released MRC (Multipath Reliable Connection) at OCP. Not a patch on RoCEv2 — a systematic overturning:
| Consensus | Traditional | MRC | Core Change |
|---|---|---|---|
| Load balancing | ECMP hash (flow-level) | Entropy Value packet spraying (packet-level) | Eliminates flow collision |
| Lossless transport | PFC (pause frames) | Disable PFC + selective retransmission | Eliminates head-of-line blocking |
| Ordered delivery | Single-path ordered | Out-of-order direct write (per-packet virtual address) | Eliminates ordering latency |
| Routing | Dynamic (BGP/OSPF) | SRv6 uSID static source routing | Eliminates convergence latency |
| Congestion control | Switch + host cooperative | Switch only marks ECN | Eliminates control plane conflict |
Design philosophy: push intelligence from switches to NICs; let switches return to stateless forwarding.
MRC is a minimal extension to RoCEv2 RC transport, retaining only RDMA Write and Write-with-Immediate (AI workloads need only this subset), reusing existing RDMA Verbs/QP ecosystem. MRC explicitly "draws on multiple techniques from UET" (paper's own words).
Multi-plane two-tier Clos: Each 800G NIC breakouts to 8×100G connecting 8 T0 switches. A 51.2T switch goes from 64×800G to 512×100G; a single plane accommodates 131,072 GPUs. Versus three-tier: optical modules reduced to 2/3, switches to 3/5, longest path only 3 hops.
Production deployment: OpenAI's largest NVIDIA GB200 supercomputer (including Oracle/OCI's Abilene, Texas site), Microsoft Fairwater (Atlanta + Wisconsin). During training, hot-restarting 4 T1 switches required no coordination with the training team — jobs continued running.
UET: Parallel Evolution
UEC (Ultra Ethernet Consortium, 120+ members, Linux Foundation's fastest-growing working group) released UET Specification 1.0 in June 2025. Technical foundation ~75% from HPE Slingshot transport protocol.
UET and MRC share multiple core concepts: packet spraying, out-of-order placement, selective retransmission, packet trimming. Key differences:
| Dimension | MRC | UET |
|---|---|---|
| Design path | Minimal RoCEv2 RC extension | Entirely new transport stack |
| Software interface | RDMA Verbs (Write+WriteImm) | libfabric v2.0 |
| Flow control | Disable PFC | Credit-based |
| Source routing | SRv6 uSID | None (relies on switch routing) |
| Deployment barrier | Medium (MRC NIC + SRv6 switch) | High (entirely new software stack) |
| Production validation | OpenAI/MS 131K GPUs | Spec just released |
AMD's NSCC congestion control algorithm also became part of the UEC congestion control specification. MRC and UET are complementary, not competing — MRC takes the pragmatic fast-deployment path; UET takes the clean-slate long-term evolution path.
InfiniBand: The Last Bastion of Closed Ecosystems
NVIDIA dominates IB through its Mellanox acquisition. XDR (800 Gb/s) is being deployed (Quantum-X800 + ConnectX-8); GDR (1600 Gb/s) is on the roadmap.
IB technical advantages: native lossless (credit-based, no PFC storms), native multipathing, ultra-low latency (1-2μs), NVIDIA full-stack compatibility guarantee. Disadvantages: high cost, vendor lock-in (effectively only NVIDIA), scarce operations talent, closed ecosystem.
Trend: IB retains the high-end market in 2026, but Ethernet (MRC/UET) eroding it is the probable medium-term outcome. NVIDIA itself supports both paths (ConnectX-8 supports both RoCEv2 and MRC). Gartner predicts >65% of generative AI clusters will be Ethernet-based by 2029.
Protocol Comparison Matrix
| Dimension | RoCEv2 | MRC | UET | InfiniBand |
|---|---|---|---|---|
| Multipathing | None (ECMP flow-level) | ✅ Packet spraying 128-256 paths | ✅ Packet spraying | ✅ Adaptive routing |
| Loss recovery | Go-Back-N/selective retransmission | Selective retransmission + trimming | Selective retransmission + trimming | Link-level + transport-level retransmission |
| Flow control | PFC (lossless) | Disable PFC | Credit-based | Credit-based |
| Source routing | None | SRv6 C-SID | None | None |
| Failure recovery | Seconds (routing convergence) | Microseconds (NIC bypass) | Milliseconds (TBD) | Seconds (Subnet Manager) |
| Deployment complexity | Medium | Medium-high | High | Medium (NVIDIA integrated) |
| Cost | Low | Medium | Medium | High |
| Suitable scale | ≤64K GPU | 100K+ GPU | 100K+ GPU | ≤64K GPU (economic scale) |
Standardization Landscape
Three parallel tracks: IETF (SRv6/RFC 9800) provides underlying source routing infrastructure; OCP (MRC) takes the pragmatic path of minimally modifying RoCEv2 for rapid deployment; UEC (UET/UEC 1.0) takes the clean-slate transport stack path. The three aren't mutually exclusive: MRC draws on UET technology; SRv6 serves MRC's source routing needs.
→ Protocol core mechanisms (EV state machine details, SRv6 uSID forwarding process, Packet Trimming, NIC/switch chip quantitative analysis), protocol comparison details and standardization progress (IETF/OCP/UEC/IEEE/IBTA) in Companion Piece Two.
Why These Two Revolutions Are Mutually Prerequisite
This is the overview's core argument: topology and protocol revolutions are deeply coupled co-designs; they cannot be chosen independently.

Synergy 1: Short Diameter Reduces Protocol Complexity
ZCube's 2-hop diameter doesn't just reduce latency — it directly simplifies every key aspect of the transport protocol:
- Faster failure detection: MRC's EV four-state machine (active → congested → suspected_failed → confirmed_failed) judges path health every RTT. 2-hop topology RTT is far shorter than 5-7-hop three-tier Clos; convergence is faster, confidence higher.
- Lower SRv6 overhead: 2 hops need only 2-3 uSID segments; overhead after compression is negligible. 5-7 hops need more segments; accumulated overhead eats into payload.
- Simpler reordering: Fewer intermediate nodes = less out-of-order extent = lighter NIC reorder buffer and SACK logic.
Conversely, MRC works in traditional three-tier Clos, but 5-7-hop paths weaken packet spraying advantage, SRv6 overhead is larger, and failure detection is slower.
Synergy 2: Source Routing Makes Asymmetric Topology Feasible
Traditional ECMP requires multiple equal-cost paths — this implicitly assumes symmetric topology. Asymmetric topology (ZCube's 2n first/last layer vs 3n middle layer) creates unequal path counts under ECMP; some links may be overused or idle.
MRC's SRv6 static source routing bypasses this constraint: NICs encode complete paths at send time; switches forward per SRv6 headers without understanding topology. Path management shifts from "switches need complex routing protocols" to "NIC pre-computation + static encoding."
Without MRC (or similar source routing), ZCube's asymmetric structure would be much harder to manage in production. Conversely, without ZCube-class short-diameter topology, MRC's packet spraying and fast failure detection advantages are weakened.
Synergy 3: Dual Savings from Switch Simplification and Topology Cost
| Dimension | Traditional 3-tier Clos + RoCEv2 | ZCube + MRC |
|---|---|---|
| Switch count | Baseline | -60% |
| Per-switch complexity | Large TCAM/Buffer/PFC needed | Net reduction ~50MB buffer, no dynamic routing |
| Optical module count | Baseline | -40% (shorter paths = fewer modules) |
| Failure recovery | ~100ms (routing convergence) | ~10μs (NIC autonomous bypass) |
| Paths per flow | 1 | 128-256 |
| NIC overhead | Baseline | +16KB/QP (EV/SRv6/SACK/retransmit/OOO) |
Network cost reduction comes not from topology alone or protocol alone, but from both together. Switches become simpler, so reducing count doesn't sacrifice reliability; topology becomes shallower, so protocol failure detection windows shrink.
Not Two Independent Choices
- ZCube with RoCEv2: Asymmetric topology creates ECMP path management difficulties; PFC cascading effects persist
- MRC with traditional 3-tier Clos: 5-7 hops weaken packet spraying; SRv6 overhead larger; failure detection slower
- Only both together achieve 2-hop + source routing + no PFC + microsecond-level failure recovery
→ More detailed technical analysis: Companion Piece One's "ZCube and MRC Synergy" section (how 2-hop diameter simplifies EV state machine, why asymmetric topology needs source routing, relationship between k ports and multipathing), and Companion Piece Two's "MRC and Asymmetric Topology Synergy" section (source routing enables asymmetry, short paths amplify packet spraying, unexplored joint optimization space).
Chip Industry Landscape
NIC: From Accessory to Core
Traditional NICs are server peripherals — simple function, low differentiation. MRC makes NICs the core of network intelligence — EV state machine, SRv6 encoding, packet spraying scheduling, and out-of-order reassembly all happen on the NIC. Per-QP state balloons from 512 bytes to ~16KB (EV set 2KB + SRv6 mapping 4KB + SACK 0.5KB + retransmit 8KB + OOO tracker 1.5KB); at 2000+ QP scale, on-chip SRAM is insufficient, requiring DDR or HBM.
| Vendor | Product | Strategy | SRv6 | MRC |
|---|---|---|---|---|
| NVIDIA | ConnectX-8 | Firmware + DDR cache | ✅ | ✅ |
| AMD | Pollara 400 | Hardware + HBM cache | ✅ (via UEC) | ✅ (first compatible) |
| Broadcom | Thor Ultra | NPL programmable | ✅ native | ✅ native |
NIC die cost is trending up: MRC functionality occupies ~15-20% of die area. Acceptable for NVIDIA/Broadcom; a higher barrier for newcomers.
Switches: Simpler But Not Cheaper
MRC returns switches to stateless forwarding — net reduction ~50MB buffer + significant TCAM. But bandwidth demand grows exponentially: 102.4T → 204.8T requires more advanced SerDes (200G→400G/lane) and CPO (co-packaged optics).
| Chip | Generation | Bandwidth | MRC Support | Key Features |
|---|---|---|---|---|
| Broadcom TH6 | 102.4T | 64×800G / 128×400G / 512×100G | ✅ Hardware | Cognitive Routing 2.0, Packet Trimming (CSIG) |
| Cisco G300 | 102.4T | 64×800G | ✅ P4 | uSID acceleration, high programmability |
| NVIDIA Spectrum-6 | 102.4T | 64×800G | Limited/roadmap | Unified IB ops stack |
| Marvell Teralynx 10 | 51.2T | 64×800G | — | No multipathing support currently |
| Huawei CloudEngine | — | — | — | China market leader |
Chip × Protocol Matrix: Broadcom leads in MRC support with TH6 + Thor Ultra end-to-end; Cisco maintains flexibility through P4 programmability; NVIDIA keeps exclusivity in IB ecosystem. MRC/UET support is the key differentiator in the 102.4T generation — switch chips without multipath reliable transport will be marginalized in the AI market.
Path to 204.8T: 200G/lane SerDes design difficulty grows exponentially; CPO shifts from "optional" to "essential"; cross-die coherence in chiplet architectures is an unsolved problem.
Competitive Landscape
| Strategy | Players | Advantage | Disadvantage |
|---|---|---|---|
| Closed full-stack | NVIDIA (IB+ETH+GPU), Google (TPU+ICI+OCS) | Peak performance, tight integration | High cost, vendor lock-in |
| Chip + Device | Cisco (Silicon One+Nexus), Huawei (in-house+CloudEngine) | Differentiation + control | Narrower ecosystem |
| Device + Software | Arista (Broadcom chip+EOS) | Software differentiation | Chip dependency on Broadcom |
| Component Supply | Broadcom, Marvell | Horizontal platform | Lower margins |
The open ecosystem (MRC/OCP + UEC, 120+ members) is systematically challenging closed ecosystems. Most hyperscalers choose a hybrid strategy: NVIDIA IB for core training, open Ethernet for scale-out and inference.
Who Uses What
| Cloud Provider | Network Solution | Scale | Key Characteristic |
|---|---|---|---|
| OpenAI/MS | MRC + multi-plane 2-tier Clos | 131K GPU | Largest MRC production deployment |
| OCS + ICI + Virgo | TPU full-stack in-house | Only fully self-developed path | |
| Meta | RoCEv2 + large-scale tuning | >30K GPU | Largest RoCEv2 + ECN/DCQCN deployment; Ghost paper reveals reliability risks |
| ByteDance | ZCube + Rail-Optimized | 16K GPU | ZCube paper source |
| Alibaba | HPN + Stellar | >15K GPU | Most SIGCOMM 2025 contributions (11 papers) |
| AWS | EFA/SRD | In-house | Non-mainstream approach |
| xAI | Ethernet | — | Arista + Broadcom |
Software-side common trends:
- AI-driven network operations (AgenticOps / Intent-Based Networking) becoming the new management battlefield
- Shift from "manually tune PFC/ECN parameters" to "AI adaptive optimization"
- Dramatically increased observability investment — 100K GPU network state cannot be inspected manually
China market specifics:
- Domestic substitution is irreversible; Huawei + H3C + Ruijie dominate
- Domestic 800G switch shipments grew from 15K (2023) to 60K (2025), CAGR >100%
- DeepSeek and other domestic LLMs driving inference-side 200G/400G switch demand
- SIGCOMM 2025 Chinese institutional contributions are exceptionally prominent (Alibaba 11 papers, ByteDance 2 best papers, Tsinghua/PKU/HKUST) — hyperscale practice demands drive systematic academic innovation
Decision Framework

Topology by Scale × Protocol by Scenario
| GPU Scale | Recommended Topology | Recommended Protocol | Rationale |
|---|---|---|---|
| >50K | Multi-plane 2-tier Clos | MRC + SRv6 | Failure recovery and packet spraying are essential |
| 10K-50K | Multi-plane or Rail+Global | MRC or RoCEv2+tuning | Transition zone |
| 1K-10K | ZCube / Rail-Optimized | RoCEv2 or MRC | ZCube sweet spot |
| <1K | 1-hop / Flat | RoCEv2 | Protocol choice insensitive |
Scenario Differentiation
Large-scale synchronous pre-training (>10K GPU): Most sensitive to tail latency and failure recovery. MRC's packet spraying and microsecond-level failure bypass are optimal. Multi-plane 2-tier Clos provides shortest paths.
Medium-scale training (1K-10K): RoCEv2 + DCQCN + ECN tuning is manageable at current scale. ZCube provides better cost efficiency.
Inference services: More sensitive to cost and throughput; lower tail latency requirements. ZCube's advantage is most pronounced here (Zhipu AI: 15% throughput + 1/3 hardware savings).
Mixed workloads (training+inference+general): Consider RoCEv2 + UET evolution path, or zoned deployment (training zone MRC + inference zone ZCube).
China Industry: Gap and Opportunity
→ Full analysis in Companion Piece Two's China industry section. Core judgments:
- Hardware gap: Domestic NIC chips lag 1-2 generations in MRC support; cannot produce ConnectX-8/Thor Ultra equivalents short-term
- Software gap: MRC's open-source implementation (OCP) provides a catch-up window, but requires deep standards participation
- Opportunity: China's hyperscale deployment demands are driving original academic contributions. ZCube itself is a ByteDance+Tsinghua collaboration
Key Judgments and Risks
Core Judgments
Judgment 1: Ethernet will become the mainstream AI backend network within 3-5 years. RoCEv2 + MRC/UET systematically resolve Ethernet's three core shortcomings in AI (single path, PFC storms, slow failure recovery). InfiniBand won't disappear but retreats from mainstream to a latency-sensitive high-end niche.
Judgment 2: MRC is the most aggressive Ethernet solution today. MRC + SRv6 + multi-plane Clos represents the frontier: eliminate dynamic routing, replace with source routing, replace ECMP with packet spraying, replace multi-tier with multi-plane. OpenAI and Microsoft production validation provides the strongest practical endorsement.
Judgment 3: Topology design shifts from "engineering intuition" to "automated search." ATOP's methodological contribution is greater than ZCube itself — reusable, eliminates cognitive bias, supports multi-objective. When new hardware/models appear, just re-run ATOP.
Judgment 4: The open ecosystem is systematically challenging closed ecosystems. MRC (OCP open source), UET (UEC 120+ members), P4 programmable chips, multi-vendor devices — building high-performance AI networks without NVIDIA lock-in. But NVIDIA's top-end full-stack optimization remains irreplaceable.
Judgment 5: Chinese institutions are already globally leading in AI networking academic research. Not accidental — hyperscale practice demands drive systematic innovation.
Key Risks
- MRC interoperability: Not yet fully validated in multi-vendor heterogeneous environments. UET is still early; from spec to large-scale deployment takes 1-2 years.
- PFC alternative uncertainty: MRC disables PFC, UET uses credit-based, SIGCOMM 2025 DCP proposes a third path — which approach works reliably at the broadest scale needs more validation.
- Ghost problem: Link flapping causing topology knowledge invalidation may become a systemic risk at 100K GPU scale; faster failure detection alone cannot fundamentally solve it.
- 1.6T physical layer: 200G/lane SerDes difficulty grows exponentially; CPO serviceability and supply chain unresolved; 204.8T chiplet cross-die coherence is unknown.
- Supply chain geopolitics: Export controls and domestic substitution requirements affect equipment availability and cost.
Three-Year Roadmap
2026: MRC begins small-scale deployment beyond OpenAI/MS. ZCube trials by vendors beyond ByteDance/Zhipu. UEC 1.0 interoperability testing begins. 102.4T switch chips enter mass production.
2027: 800V power distribution + 102.4T + MRC "golden combination" becomes the default for new hyperscale training clusters. OCS pilots in non-Google environments. 1.6T ports and CPO begin small-scale deployment.
2028: UET ecosystem matures, complementing MRC. 204.8T chips in mass production. Topology-protocol co-design becomes mainstream methodology — ATOP-class tools integrate MRC constraints for joint search.
Advice by Role
AI infrastructure decision-makers:
- Short-term (2026): New training clusters should prioritize Ethernet + RoCEv2 with MRC-upgradable equipment; 1K-10K scale consider ZCube
- Medium-term (2027-2028): Evaluate MRC/UET migration as ecosystem matures; watch 1.6T and OCS deployment timing
- Avoid lock-in: Choose P4 programmable switch chips for protocol evolution headroom
Network equipment vendors:
- Differentiation shifts from "speed competition" to "architecture competition" — Buffer management, programmability, load balancing strategy
- Software value: AI-driven network operations (AgenticOps), Intent-Based Networking (IBN) are the new battlefield
- Chinese vendors: Domestic substitution window accelerating; Huawei full-stack + H3C DDC innovation has differentiation space
Chip vendors:
- MRC/UET support is the key differentiator in the 102.4T generation
- CPO capability is the entry ticket for the 204.8T generation
- P4 programmability provides "standards not yet set, chips first" insurance for customers
Researchers and investors:
- Watch: MRC adoption speed, UEC interoperability results, ZCube validation at 64K+, OCS deployment outside Google
- Investment directions: Optical interconnect (CPO/DSP/silicon photonics), open Ethernet ecosystem (UEC/MRC), AI network management, China domestic substitution
Appendix: Paper and Standards Tracking
SIGCOMM/NSDI Papers
SIGCOMM 2025 (core AI networking papers):
- ZCube / ATOP (ByteDance + Tsinghua) — Best Paper, automated topology search
- InfiniteHBD (OCS optical circuit switching new approach)
- DCP (de-PFC congestion control new approach)
SIGCOMM 2024:
- Ghost in the Datacenter (Meta) — link flapping causes topology knowledge invalidation
- MegaScale / ByteScale (ByteDance) — large-scale training systems engineering
IETF / OCP / UEC / IEEE / IBTA Standards
→ See Companion Piece Two's standardization landscape section for details. Core standards: RFC 9800 (SRv6 C-SID), MRC 1.0 (OCP), UET 1.0 (UEC), 802.3dj (1.6T Ethernet in progress), XDR (IBTA).
Three-Part Series Navigation
| Article | Focus | Core Content |
|---|---|---|
| This overview | Dual-axis synergy framework | Topology × Protocol cross-relationships, chip/device/cloud landscape, decision framework, risks and roadmap |
| Companion One: Topology | Physical-layer deep dive | ATOP methodology, asymmetric structures, sweet-spot quantitative comparison, NVLink domain expansion, fault tolerance, production validation, OCS, physical constraints |
| Companion Two: Protocol | Logical-layer deep dive | MRC five consensus overturns, EV state machine, SRv6 uSID forwarding, Per-QP state, three NIC comparison, switch resource add/subtract, China industry gap |