From CLOS to ZCube: Network Topology Evolution for AI Computing Clusters
From Charles Clos's non-blocking telephone switching network in 1953 to ByteDance's SIGCOMM 2025 Best Paper ZCube — topology design has evolved from expert intuition to automated search. ZCube's asymmetric architecture eliminates 60% of switches at 16K GPU scale while boosting training speed by 5%, and Zhipu AI's production deployment proves it works beyond training.
This article is one of two companion pieces to "AI Training Networks: A Technical Panorama," focusing on physical-layer topology design. Companion piece two, "From RoCE to MRC: AI Cluster Transport Protocols and Chip Rearchitecture", dives deep into transport protocols and chip implementations. For the full overview, see "AI Training Networks: From CLOS to ZCube, from RoCE to MRC".
A Counterintuitive Finding: Symmetry Is Not Optimal
One remark from the review of the SIGCOMM 2025 Best Paper is worth noting: all traditional topology designs assume switches are homogeneous — same port count, same specifications. This assumption seems self-evident: identical switches are easier to procure, easier to stock spares for, and easier to operate.
But ATOP (Automated Topology Optimization Pipeline) discovered through automated search that under AI training traffic patterns, asymmetric architectures consistently outperform symmetric ones on the performance-cost trade-off. Not "roughly the same" — at every GPU scale searched, the optimal solution at the Pareto front knee exhibits the same asymmetric characteristics.
The deeper implication: the human preference for "symmetry" is a cognitive bias under AI training workloads. ATOP eliminated this bias and discovered ZCube.
From Clos (1953) to Fat-Tree (2008) to BCube (2009) to Rail-Optimized (2020s) to ZCube (2025), the topology design goal has shifted from "general-purpose non-blocking" to "AI-training-specific," and the design method from "manual design" to "automated search." This evolutionary path is worth tracing in full.
The Starting Point: Three Assumptions of Clos Topology
In 1953, Charles Clos published his theory of non-blocking multistage switching networks. The modern datacenter Fat-Tree is a direct application of the Clos topology. Clos carries three implicit assumptions, each of which collapses under AI training workloads:
Assumption 1: Traffic patterns are unpredictable. Clos is designed to provide full bisection bandwidth for "any input to reach any output." But AI training's collective communication patterns are highly regular — every training step repeats the same AllReduce/All-to-All patterns. You don't need "any-to-any"; you need "optimal for specific patterns."
Assumption 2: Many independent small flows. ECMP hashing achieves statistical evenness with many independent small flows. But AI training produces a small number of elephant flows, and the probability of two large flows being hashed to the same link is non-trivial. Flow collisions cause tail latency — in synchronous training, the slowest transfer determines the entire step time.
Assumption 3: Three layers of switching suffice. A three-stage 64-port Clos can connect at most ~32K endpoints. 100K GPUs require four layers or oversubscription, but every additional switch layer adds a hop of latency, and costs and power consumption escalate sharply.

Rail-Optimized: From "General Connectivity" to "Matching Communication Patterns"
Core Idea
A GPU server has 8 GPUs internally (e.g., DGX H100), each with its own NIC. Rail-Optimized's idea: instead of connecting all 8 NICs to the same ToR switch, connect GPUs in the same position across all servers to the same switch, forming 8 independent "Rails."
Why It Works for AI
In data parallelism, same-rank GPUs across servers communicate most frequently. Rail topology enables same-rank GPU communication in a single hop; most traffic is absorbed at the Leaf layer and never reaches the Spine.
Rail-Only vs Rail+Global (ROFT)
| Dimension | Rail-Only | Rail+Global (ROFT) |
|---|---|---|
| Structure | Rail switches only, no upper-layer interconnect | Rail Leaf + Global Spine |
| Cost | Significantly lower (no top-layer switches) | Requires additional Spine layer |
| Use case | DP training with highly localized communication | General AI training (including All-to-All) |
NVIDIA's DGX SuperPOD reference architecture uses ROFT. But ROFT's problem is that its three-layer structure means PP traffic needs 3-5 hops (Leaf→Spine→Aggregation→Spine→Leaf), causing severe latency stacking. The switch count is also high — 16K GPU ROFT requires 640 switches.
ZCube: Turning Topology Design into Hyperparameter Search
Paper Background
ZCube comes from the SIGCOMM 2025 Best Paper "From ATOP to ZCube." First author Zihan Yan (Tsinghua University), corresponding author Dan Li (李丹) — who was also the author of the 2009 SIGCOMM BCube paper. Core industrial validation comes from ByteDance; Haibin Lin is also a core author of MegaScale (NSDI'24) and ByteScale (SIGCOMM'25).
The name ZCube carries the lineage of BCube — B for Byte/Cube, Z for "the last letter, the ultimate Cube." From BCube to ZCube over 16 years, topology design moved from "manual" to "automated."
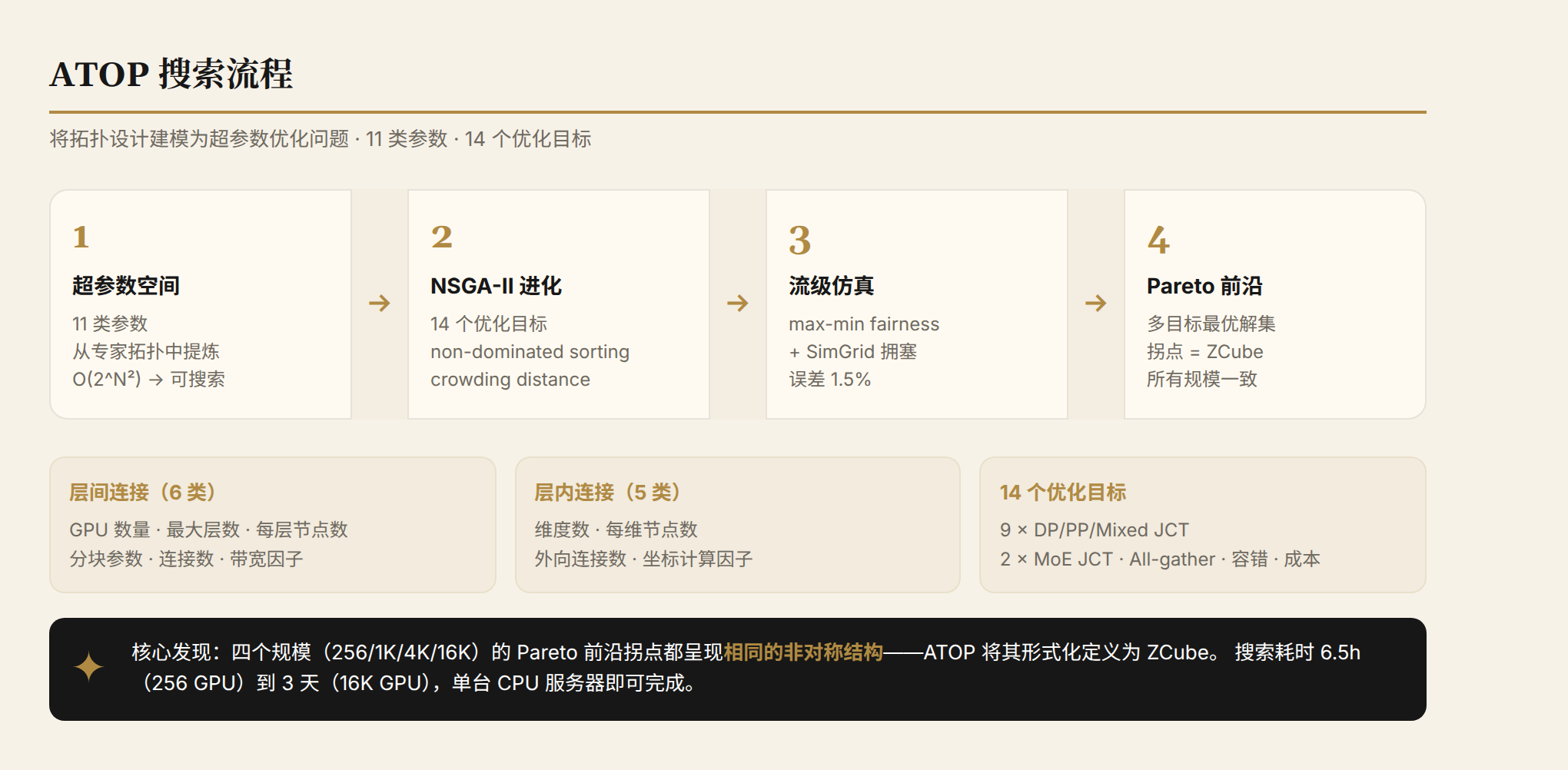
The ATOP Methodology
ATOP's core insight: you don't need to search topologies from scratch — instead, distill expert design intuition into a structured hyperparameter space, then search automatically.
Intuitively, what ATOP does: imagine you're designing a multi-room floor plan. The traditional approach is an architect drawing from experience — how many bedrooms, how many bathrooms, how large the living room, how wide the corridors. ATOP's approach: first define a set of tunable parameters ("bedroom count 1-8," "corridor width 1-3m," "living room faces south or east"...), then search across all parameter combinations for the optimum in "best lighting + highest area utilization + shortest circulation paths."
ATOP does exactly this for network topologies: it parameterizes design decisions like "how many switch layers," "how many per layer," "how to connect between layers," "how to connect within a layer," then searches the parameter space for the optimal balance across 14 objectives (training speed, cost, fault tolerance...).
The study surveyed nearly all mainstream topologies (CLOS, Fat-Tree, ROFT, Rail-only, HPN, BCube, DCell, HyperX, Torus, Dragonfly, etc.) and distilled them into 11 categories of searchable hyperparameters:
- Inter-layer connections: GPU count, max layer count, nodes per layer, blocking parameter, connection count, bandwidth factor (1-4 corresponding to 200G-800G)
- Intra-layer connections: number of dimensions, nodes per dimension, outward connection count, coordinate computation factor
This compresses the search space from O(2^N²) adjacency matrices to something searchable on a single CPU server in under 3 days.
NSGA-II evolutionary algorithm: 14 optimization objectives (9 DP/PP/Mixed JCT + 2 MoE JCT + ForestColl all-gather + APS fault tolerance + cost), with non-dominated sorting ensuring multi-objective fairness.
Flow-level simulator: max-min fairness + SimGrid congestion modeling, achieving an average error of only 1.5% compared to NS-3 packet-level simulation. Two-stage evaluation reduces 100K full evaluations to ~5,000, a 20× speedup.
Search efficiency (single 256-core AMD EPYC server):
| GPU Scale | Search Duration | Switch Throughput Limit |
|---|---|---|
| 256 | 6.5 hours | 6.4 Tbps |
| 1,024 | 10.6 hours | 12.8 Tbps |
| 4,096 | 25.4 hours | 25.6 Tbps |
| 16,384 | 71.2 hours (~3 days) | 51.2 Tbps |
ZCube Recursive Definition
Across searches at four scales — 256, 1024, 4096, and 16384 — the architectures at the Pareto front knee were strikingly similar. The paper formalizes this as ZCube.
- ZCube(n, 1) = 1 switch + n GPUs
- ZCube(n, k+1) = n × ZCube(n, k) + n^k switches
ZCube(n, k) contains: n^(k+1) GPUs, k+1 switch layers, n^k switches per layer, (k+1) × n^k total switches. Each GPU has (k+1) NIC ports.
Practical scales:
- ZCube(128,2): 16,384 GPUs, 256 switches, each GPU has 2 NIC ports (1×400G NIC split into 2×200G)
- ZCube(84,3)-partial: 592,704 GPUs, 84 pods interconnected via CLOS, network diameter 4
Asymmetry: Why ZCube Breaks the "Homogeneous Switch" Assumption
This is ZCube's core innovation. In ZCube(n, k):
- Edge layers (level-0 and level-(k-1)) require switches with 2n ports
- Middle layers (level-1 through level-(k-2)) require switches with 3n ports
Take ZCube(128,2): level-0 and level-1 switches both have 256 ports (128×200G), but entirely different traffic patterns. Edge layers connect directly to GPUs and primarily carry collective communication traffic (AllReduce/AllGather); core layers primarily carry inter-pod PP traffic.
Why is asymmetric better? Different switch layers carry different traffic patterns with different port utilization. Forcing all layers to use the same port-count switch inevitably over-provisions one layer. Asymmetric design precisely matches each layer's actual requirements.
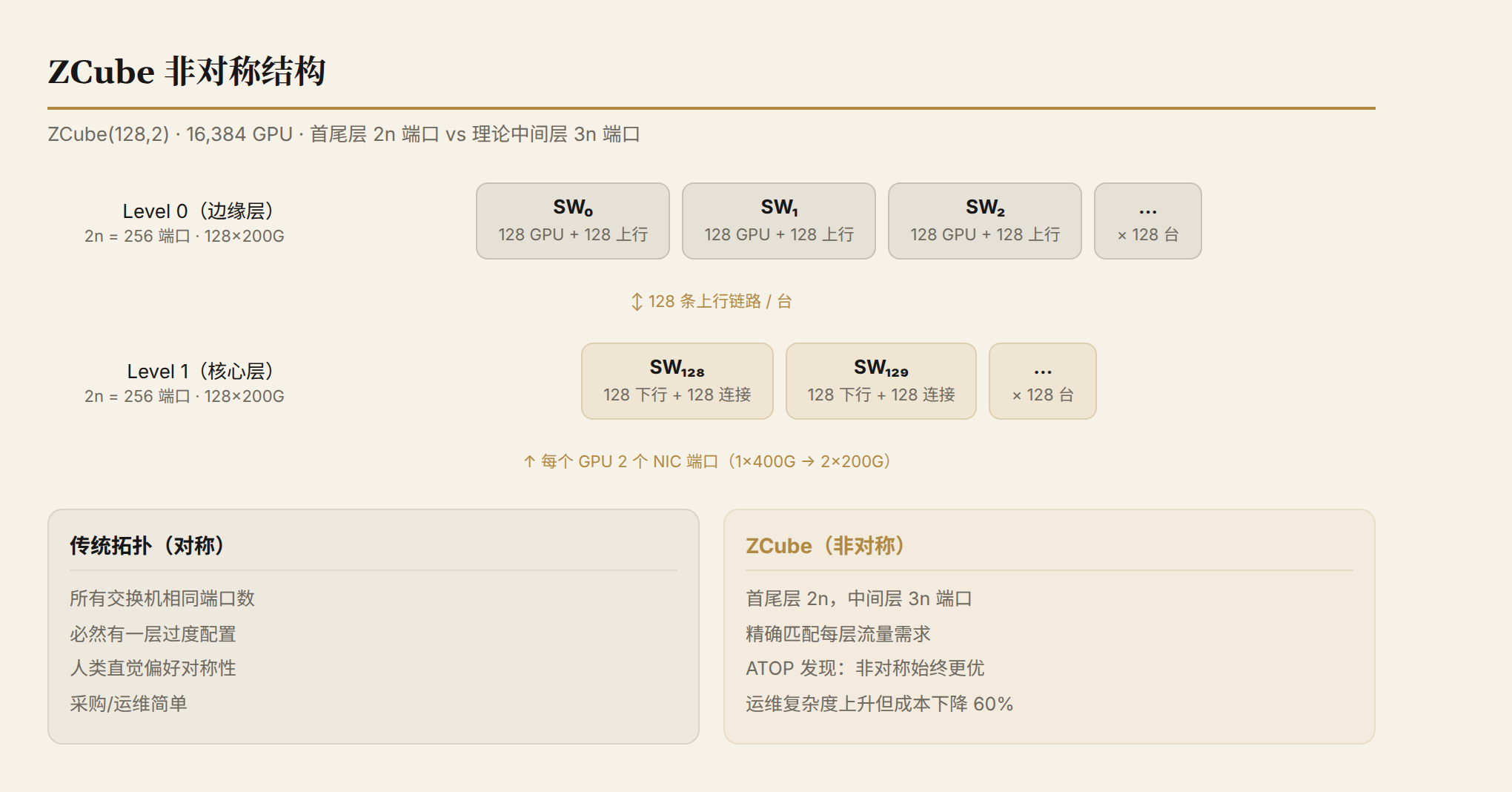
Operational reality check: Asymmetric topology means different layers need different switch specifications (2n vs 3n ports), increasing procurement and spare-parts management complexity. The paper does not deeply discuss operational issues. This is one of the practical barriers to ZCube adoption in production — but if the hardware cost savings are large enough (60% fewer switches), the operational complexity may be worth it.
Diameter: What 2 Hops Means
The paper's Theorem 1 proves: the network diameter of ZCube(n,k) is k.
| Topology | GPU Count | Diameter |
|---|---|---|
| ZCube(128,2) | 16,384 | 2 |
| 3-layer ROFT | 16,384 | 5 |
| ZCube(42,4) | 3,111,696 | 4 |
| 128-port 3-layer Fat-Tree | 524,288 | 5 |
PP traffic requires 3-5 hops in ROFT but at most 2 hops in ZCube(128,2). 3 fewer hops = 3 fewer switch forwarding latencies + 3 fewer serdes retiming stages + 3 fewer O-E-O conversions. For latency-sensitive PP traffic, this gap directly shows up in training speed.
The Sweet Spot: ZCube(32,2) at 1024 GPUs
The ZCube paper's flagship case is 16K GPU ZCube(128,2). But in practice, most training and inference clusters operate at 128-1024 GPU scale. Is ZCube worthwhile at these scales?
A hard constraint: ZCube(n, k) requires each GPU to have k NIC ports. k=2 means each GPU needs 2 ports (1×800G NIC broken out into 2×400G), which most servers can support. k=3 requires 3 ports, which most servers cannot accommodate. So k=2 is the only practical option for ZCube deployment.

128 GPUs: Flat Is Optimal
A single 128×400G switch directly connecting 128 GPUs: 1 hop, full bisection bandwidth, 0 extra switches. ZCube(11,2) would need 22 switches with only 22 ports each — more switches than 1/6 the GPU count, completely uneconomical.
Conclusion: Use Flat for 128 GPUs, not ZCube.
256 GPUs: Transition Zone
ZCube(16,2) requires 32 switches with 32 ports each. Switch/GPU ratio = 1:8, too dense. Rail-only (8×32-port switches) is simpler — although only same-rail GPUs are 1 hop apart, 256-GPU AllReduce communication patterns are usually well-covered within rails.
A 2-tier Clos also needs only 4×128-port switches. At 256 GPU scale, ZCube's advantage is not significant enough.
512 GPUs: ZCube Starts to Show Advantages
ZCube(23,2) requires 46 switches with 46 ports each, with all GPU pairs at 2 hops and full bisection bandwidth. Rail-only uses 8×64-port switches, with cross-rail communication requiring longer paths.
46 switches sounds like a lot, but each has only 46 ports — on Tomahawk 5 (51.2T), this uses less than half the port density, leaving headroom. Switch/GPU = 1:11, entering the reasonable range.
1024 GPUs: ZCube(32,2) Is the Sweet Spot
| Scheme | Switches | Switch Ports | Diameter | NIC Ports/GPU | Full Bisection BW |
|---|---|---|---|---|---|
| ZCube(32,2) | 64 | 64 | 2 | 2 | ✅ |
| Rail-only (8×128) | 8 | 128 | 2 | 1 | ❌ Cross-rail degraded |
| 2-tier Clos | 16 | 128 | 2 | 1 | ✅ |
ZCube(32,2)'s parameters map almost perfectly to off-the-shelf switches:
- 64-port switches = Tomahawk 5 standard configuration (64×800G or 128×400G breakout)
- 2 ports per GPU = 1×800G NIC broken out into 2×400G
- 64 switches = 4 standard racks (16 switches per rack)
- Switch/GPU = 1:16 = proportional scaling of ZCube(128,2)'s 1:64 at smaller scale
Why is 1024 the sweet spot rather than 512? 512-GPU ZCube(23,2) needs 46-port switches — not a standard spec. Real deployment would require 64-port switches with 18 wasted ports, or custom ordering. 1024-GPU ZCube(32,2) needs 64-port switches — exactly Tomahawk 5's native port configuration, zero waste.
Zhipu AI's 1000-card inference cluster falls right in the 1024 GPU range — at this scale, ZCube saves 1/3 of optical modules and switches while boosting throughput by 15%, not from theoretical projection but from production data.
Sweet Spot Summary
| GPU Scale | Recommended Topology | ZCube Worthwhile? |
|---|---|---|
| 128 | Flat (single switch) | ❌ No |
| 256 | Rail-only or 2-tier Clos | ⚠️ Marginally, advantage is small |
| 512 | ZCube(23,2) starts to pay off | ✅ Worth considering |
| 1024 | ZCube(32,2) | ✅ Sweet spot |
| 4096 | ZCube(64,2) | ✅ Paper-validated |
| 16384 | ZCube(128,2) | ✅ Paper's core case |
NVLink Domain Expansion: When the Atomic Unit Changes from GPU to Rack

All ZCube calculations use a single GPU as the atomic unit. But in 2025-2026, the Scale-Up domain is expanding from 8 GPUs (single server) to 72 GPUs (NVL72), and potentially to 256-576 GPUs. When the NVLink domain = 72 GPUs, the Scale-Out network's "atomic unit" shifts from GPU to NVLink domain.
Impact on ZCube parameters:
| Parameter | Per GPU | Per NVLink Domain (72 GPUs) |
|---|---|---|
| 1024 GPU cluster | ZCube(32,2), 64 switches | ZCube(15,2), 30 switches (1024/72 ≈ 14.2 domains) |
| 16K GPU cluster | ZCube(128,2), 256 switches | ZCube(16,2), 32 switches (16384/72 ≈ 227 domains) |
| NIC ports/unit | 2 per GPU | 2 per NVLink domain (shared by 72 GPUs within) |
| Switch ports | 32-128 ports | 15-227 ports |
Key change: The larger the NVLink domain, the fewer Scale-Out network nodes, the smaller ZCube's n value, and the fewer switches needed. But each NVLink domain has limited external NIC ports — NVL72 typically provisions 8-18 external NIC ports — which constrains the upper bound of k.
Open question: When the NVLink domain expands to 576 GPUs (NVSwitch), a 16K GPU cluster has only ~28 Scale-Out nodes. At that point, ZCube(5,2) needs only 10 switches — but 5-port switches are too small; a 1-hop Flat topology might be better. Scale-Up domain expansion may shift ZCube's advantage zone upward — from 512-16K GPUs to 4K-64K GPUs.
This analysis has no paper support yet; it's simple arithmetic based on ZCube's recursive definition. When NVIDIA's NVLink 5 + Vera Rubin NVLink domain specs are published, it will be worth re-running ATOP search.
16,384 GPU Quantitative Comparison
Using Broadcom Tomahawk 5 (51.2T) switches, each server with 8 GPUs + 8×400G NICs:
| Topology | Switches | Cables | GPT-3 175B Iteration | Network Cost |
|---|---|---|---|---|
| ROFT | 640 | 49,152×400G | 5.19s | $92.93M |
| Rail-only | 384 | 32,768×400G | 5.15s | $76.38M |
| HPN | 384 | 16,384×400G + 32,768×200G | 5.10s | $84.03M |
| ZCube(128,2) | 256 | 49,152×200G | 4.95s | $57.28M |
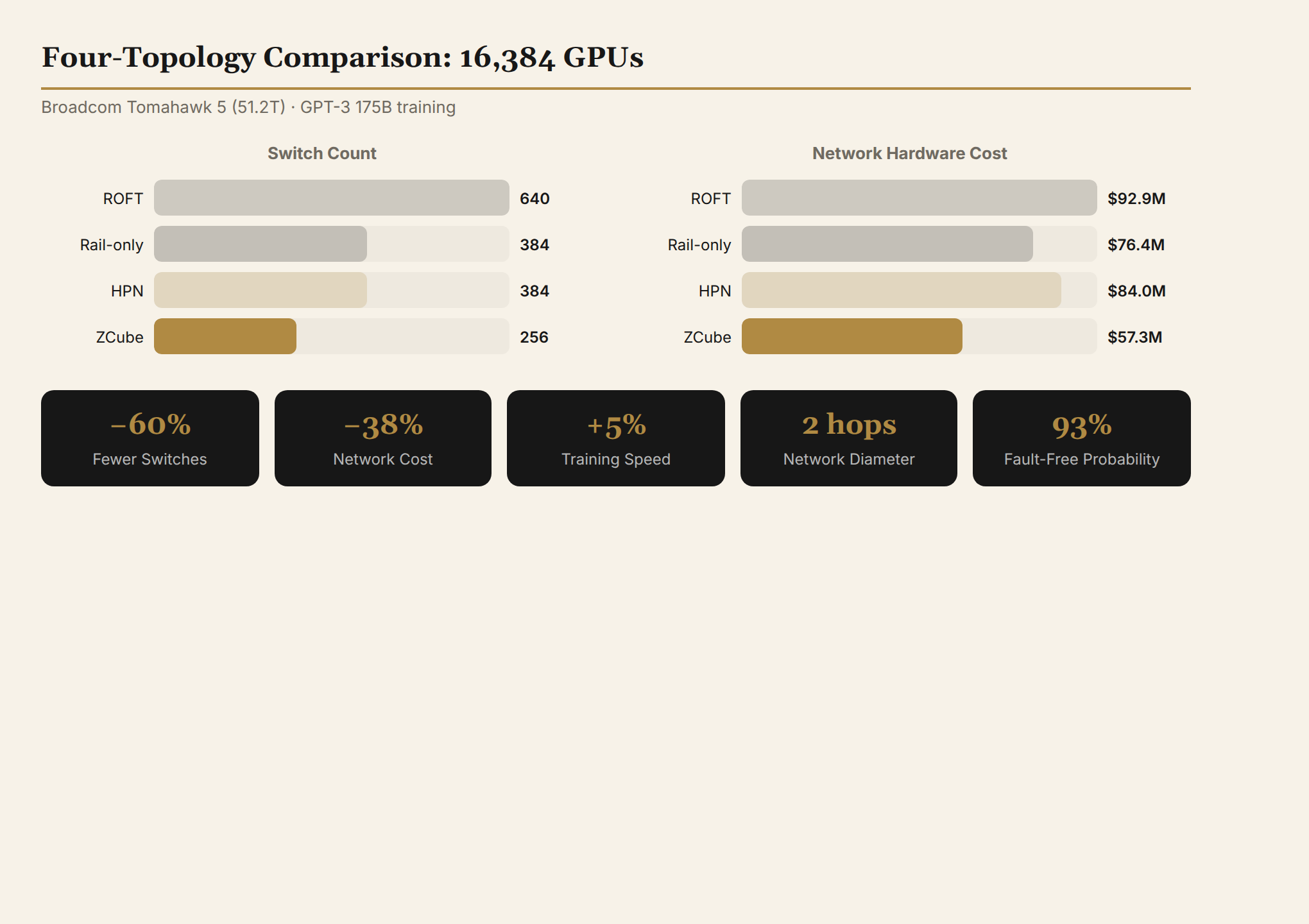
Key findings:
- 60% fewer switches (256 vs 640), 33% fewer than Rail-only/HPN
- Optical module cost reduced 25%-50%: ZCube uses 200G cables (vs ROFT's 400G)
- 3%-7% faster training, 26%-46% lower cost — winning on both performance and cost simultaneously
- MoE-GPT: ZCube 6.06s vs ROFT 6.41s; BCube(128,2) degrades to 13.79s due to lacking full bisection bandwidth
- ForestColl all-gather: all topologies achieve the same theoretical optimum
Key insight: ZCube is not trading off performance against cost — it simultaneously optimizes both on the Pareto front. Fewer switches, cheaper cables, faster training.
Fault Tolerance: Fewer Switches = Higher Reliability
Single ToR failure (4K GPUs, GPT-3 175B):
| Topology | Performance Degradation |
|---|---|
| ZCube(64,2) | 2.8% (failed GPU traffic switches to alternate NIC port) |
| HPN | 9.0% |
| Rail-only | 15.0% |
| ROFT | 46.9% (ToR failure forces GPU traffic through PXN via NVLink forwarding) |
ZCube's fault tolerance advantage comes from two factors: fewer switches (lower failure probability) and each GPU having multiple NIC ports connected to different switches (rapid failover).
Failure-free probability (16,384 GPUs, per-switch failure rate 0.03%):
| Topology | Switch Count | Failure-Free Probability |
|---|---|---|
| ROFT | 640 | 83% |
| HPN/Rail-only | 384 | 89% |
| ZCube | 256 | 93% |
Link failure degradation curves (1%-15% random link failures): ZCube degrades most gradually with the smallest standard deviation. Fewer switches don't just save money — they are a source of higher reliability.
Production Validation
16 GPU Physical Testbed
The paper built a 16 GPU physical testbed (4 servers × 4 H800 GPUs, 8 Mellanox QM9790 IB switches), comparing ZCube(4,2) with ROFT:
- All-reduce: identical performance across all message sizes (1M-16G)
- All-to-all: identical performance
- Cost: ZCube uses 48×200G links vs ROFT's 32×400G — 25% cost reduction
Zhipu AI Inference Cluster
Zhipu AI (z.ai) upgraded its ~1000-GPU GLM-5.1 inference cluster from ROFT to ZCube. Without changing GPU hardware or modifying applications:
- Saved 1/3 of optical modules and switches
- 15% inference throughput improvement
ZCube's advantage in inference scenarios is particularly pronounced: MoE expert all-to-all, KV Cache migration in PD-separated setups, and other traffic patterns align naturally with ZCube's asymmetric topology. This is direct evidence that ZCube is not limited to training scenarios.
ZCube and MRC Synergy: Why Two Revolutions Must Be Examined Together
ZCube and MRC are currently evolving independently, but in combination they have natural structural advantages. Understanding these synergies is key to understanding why each is a prerequisite for the other.
2-Hop Diameter Simplifies Protocol-Layer Failure Management
ZCube's 2-hop diameter is one of its most important topological properties — it doesn't just reduce latency, it directly simplifies transport protocol complexity.
MRC's EV four-state machine (active → congested → suspected_failed → confirmed_failed) needs to determine path liveness within each RTT. In a 5-7 hop three-layer Clos, one RTT can be tens of microseconds, and any intermediate node on the path can be a failure point. In ZCube's 2-hop topology, paths are short with few intermediate nodes — the EV state machine converges faster, and failure determination has higher confidence.
SRv6 encoding also benefits from short paths: 2 hops require only 2-3 uSID segments, making header overhead almost negligible. A 5-7 hop Clos requires 5-7 uSID segments, which even with C-SID compression has cumulative overhead eating into payload space.
Asymmetric Topology Requires Source Routing
Traditional networks rely on ECMP for load balancing, and ECMP assumes multiple equal-cost paths — which implicitly assumes a symmetric topology. ZCube's asymmetric structure (edge layers with 2n ports vs middle layers with 3n ports) creates unequal path counts under ECMP: some links may be overutilized or idle due to port count differences.
MRC's SRv6 static source routing bypasses this problem: the NIC encodes the complete path at packet emission time, and switches forward based on the SRv6 header without needing to understand the topology. This transforms path management for asymmetric topologies from "switches need complex routing protocols" to "NIC-side pre-computation + static encoding."
k Ports per GPU = Natural Multipath Foundation
ZCube requires each GPU to have k NIC ports (k=2 means each GPU connects to 2 different switches), with each port providing an independent path. This is exactly the physical foundation for MRC's multipath transport — packet spraying across 128-256 paths requires GPUs to have sufficient physical egress. ZCube's k=2 configuration (2 independent paths) is the minimum viable configuration; at k=3 or higher, MRC's path diversity becomes more ample.
An Unverified Critical Question
The ZCube + MRC synergy has not been validated by papers or production data. The key unknowns: Does ZCube's asymmetric topology require special adaptation for MRC's source routing? How does standard ECMP actually perform on ZCube (the paper only verified full bisection bandwidth without deeply analyzing ECMP hash distribution on asymmetric topologies)? The answers may determine whether ZCube at scale requires MRC as a mandatory companion, or whether ECMP suffices.
→ For in-depth analysis, see companion piece two: "From RoCE to MRC: AI Cluster Transport Protocols and Chip Rearchitecture".
ATOP's Generality: Beyond Greenfield Datacenters
The paper demonstrates ATOP's applicability across five scenarios:
- Greenfield (256-16K GPUs): The most cost-effective topology at every scale is ZCube
- Retrofitting existing DCs (4K GPU ROFT rewiring): Replacing only optical modules and cables, ZCube remains optimal
- Expansion (1K→4K GPUs): Retaining existing equipment, ZCube remains on the Pareto front
- Multi-tenant (16K split across 4 tenants at 4K each): ZCube remains the knee point
- Heterogeneous (H100+A100 mixed): Under strict constraints, ZCube falls outside the search space, but ATOP still finds a topology 6% higher performance and 11% lower cost than ROFT
ATOP's value extends beyond discovering ZCube — it is a reusable topology optimization tool. When new hardware, new models, or new constraints emerge, simply re-run ATOP.
OCS: Another Direction for Topology Evolution
ZCube represents "optimizing topology within the electrical switching framework." There is another evolutionary path: replacing Spine-layer electrical switches with Optical Circuit Switching (OCS).
Google Apollo
Google has deployed OCS at scale since 2022 (codenamed Apollo), using 3D MEMS micromirror arrays to replace the Spine layer. SemiAnalysis estimates Apollo has saved Google over $3 billion in network equipment procurement.
InfiniteHBD (SIGCOMM 2025)
Going further — integrating connectivity and dynamic switching capability at the optical transceiver level. Each optical transceiver can dynamically change its connection target, constructing datacenter-scale high-bandwidth domains.
OCS Applicability Conditions
OCS is unsuitable for packet-level switching (millisecond-scale switching speed), but AI training traffic is coarse-grained — collective communication persists for milliseconds to hundreds of milliseconds. OCS's winning conditions are: large flows, predictable patterns, and sufficient scale for the Spine layer to become a bottleneck.
| Dimension | Electrical Switching | OCS |
|---|---|---|
| Switching granularity | Packet-level (microseconds) | Circuit-level (milliseconds) |
| Latency | Multi-hop accumulation | All-optical path, extremely low |
| Power consumption | Electrical processing per hop | Optical path passthrough |
| Applicable scenario | General-purpose | Coarse-grained, predictable traffic |
Topology Evolution Trend Analysis
Four Directions
- From symmetric to asymmetric: ZCube proves asymmetric is superior under AI workloads
- From three layers to two layers: OpenAI's multi-plane Clos (MRC) and Microsoft Fairwater both compress to two layers
- From electrical to electro-optical hybrid: Google Apollo proves OCS is feasible at the Spine layer
- From switch intelligence to endpoint intelligence: MRC shifts routing decisions from switches to NICs
Topology by Scale
| GPU Scale | Recommended Topology | Rationale |
|---|---|---|
| < 500 | 1-hop (single 128×800G switch) | Simplest, lowest latency |
| 500 - 4K | ZCube or Rail-only | Two layers suffice, asymmetric optimization yields real benefits |
| 4K - 16K | ZCube(128,2) | Optimal cost/performance/fault-tolerance balance point |
| 16K - 64K | Multi-Plane Clos + ZCube pod | Multi-plane + ZCube as intra-pod topology |
| 64K+ | Multi-Plane Clos (MRC) or Fairwater flat network | Requires multipath protocol cooperation |
Open Questions
- ZCube performance at 64K+ scale is unknown — the paper only validates up to 16K. ATOP search computational cost and simulation accuracy at larger scales are both challenges.
- Operational cost of asymmetric topology — different layers require different switch specifications, increasing spare-parts management complexity. Will production environments accept the operational overhead for the performance/cost gains?
- ZCube + MRC synergy — the two are currently evolving independently but have natural structural advantages when combined. ZCube requires each GPU to have k NIC ports; at k=2, each GPU has 2 independent paths — exactly the physical foundation for MRC's multipath transport. MRC's EV state machine could sense path state across ZCube's different layers for more precise path selection. But their synergy has not been validated by papers or production data. A key open question: does ZCube's asymmetric topology (2n vs 3n port switches) require special adaptation for MRC's source routing? Or is ECMP sufficient on ZCube?
- OCS vs ZCube — competition or complement — ZCube eliminates 60% of electrical switches; OCS attempts to replace the Spine layer with optical switches. Will the two paths converge at some scale point?
Physical Constraints: The Real Ceiling on Topology Choice
The above discussion operates in the theoretical space of topology structure. But actual deployment faces three physical constraints that may limit the freedom of topology choice.
Optical module cost and power. ZCube's sweet spot uses 200G optical modules instead of 400G — lower per-port cost. But optical modules remain one of the largest cost items in the network. For 1024-GPU ZCube(32,2), 49,152 × 200G links at $50-100 each = $2.5-5M, accounting for 40-60% of total network cost. In the 1.6T era, optical module costs may double, compressing the cost savings from topology optimization.
Rack power limits. Each GPU server (8×H100/H200) draws approximately 10-12kW. A standard 42U rack is typically limited to 20-30kW (air-cooled), accommodating at most 2-3 servers. This means ToR switch GPU port density is naturally limited — even if the topology design allows denser connections, physical space and power constraints prevent it. 800V DC distribution can raise rack power limits to 120kW+, but requires entirely new power infrastructure.
Copper vs fiber distance constraints. GPU server to ToR switch cabling is typically 1-3m (copper) or 3-10m (active optical cable AOC / direct attach copper DAC). ZCube's asymmetric structure means different layers may be in different physical locations, and inter-layer cabling distances may exceed the effective range of copper, forcing the use of optical modules — increasing cost. ATOP's search space currently assumes all links are equivalent, but physical distance is a hard constraint in deployment.
These three constraints mean: the "optimal topology" from ATOP search needs revalidation under physical constraints. The theoretical Pareto front may shrink due to physical limitations.
ATOP's True Contribution: Methodology > Specific Topology
If the ZCube paper only delivered the ZCube topology, its value would be limited — hardware generations change, models evolve, and optimal topologies shift.
But ATOP's contribution is at the methodology level:
- Transforming topology design from "experts relying on intuition" to "automated optimization in a formalized search space"
- Eliminating human cognitive biases (symmetry preference, homogeneity preference)
- Multi-objective optimization (performance, cost, fault tolerance considered simultaneously)
- Reusable — when new hardware, models, or constraints emerge, simply re-run
From BCube (2009) to ZCube (2025), Dan Li's group's 16 years of topology research traces a clear line: topology design is transitioning from "art" to "engineering."
Disclaimer: This article is based on the SIGCOMM 2025 Best Paper "From ATOP to ZCube," public technical materials from ByteDance and Zhipu AI, and public reports on Google Apollo, cross-validated before writing. This article does not constitute investment advice. Data herein is current as of June 1, 2026.