Uber burned through its annual AI budget in four months. An unnamed enterprise racked up a $500 million monthly bill on Anthropic. Klarna replaced 700 humans with AI, then quietly rehired them. Meanwhile, OpenAI and Anthropic are posting quarterly revenues in the tens of billions. Users are anxious; vendors are celebrating. The question isn't just whether AI is expensive—it's how much of every dollar you spend is solving your problem, and how much is padding a model company's revenue.
I. The $500 Million Monthly Bill
Spring 2026. Several bombs went off in enterprise AI spending.
Uber detonated first. In April, their CTO admitted the company had already exhausted its annual AI budget—and it was only month four. The culprit was Claude Code. Five thousand engineers, nearly one per person. Average API spend per engineer jumped from $500 to $2,000 per month, far outpacing what financial models had predicted.
More telling was a comment from Uber president Andrew Macdonald on a podcast: "It's very hard to say there is a direct link between AI usage increase and actually delivering new features to consumers."
Money spent. On what, exactly? Hard to say.
Then came the anonymous $500 million case. An AI consultant told Axios that one enterprise client, having set no usage limits whatsoever, received a Claude bill for roughly half a billion dollars in a single month. The number was cross-confirmed by multiple outlets in May 2026. For context: Uber's entire 2025 R&D budget was $3.4 billion. One company's monthly AI bill consumed one-sixtieth of Uber's annual R&D spend.
Budgets blew up not because the scale was too small, but because the billing model changed. AI moved from per-seat pricing to metered usage. And the meter is spinning faster with every release.
Microsoft's moves corroborated this. In May 2026, the company started revoking internal engineers' Claude Code licenses, migrating them to the in-house GitHub Copilot CLI. The official line was "technical integration." Insiders said the real driver was financial pressure. Token-based billing was making even Microsoft wince.
Klarna's story reads more like a parable. In 2024, the Swedish fintech loudly announced that AI chatbots had replaced 700 customer service agents. CEO Sebastian Siemiatkowski took every stage he could find to declare that "AI is replacing humans." A year later, Klarna quietly resumed hiring human agents. The CEO himself admitted AI-powered service couldn't meet the company's quality standards. The laid-off workers were brought back under the label of "remote support."
From "AI replacing humans" to "rehiring humans"—that arc took exactly one year.
II. "It's Not More Expensive—You're Just Using More"
Token unit prices really are plummeting. Between 2023 and 2026, per-token pricing for comparable models dropped roughly 280×. GPT-4 launched at $30 per million input tokens; GPT-5 sits at $2.50. DeepSeek V3.2 goes as low as $0.14.
So model companies have every reason to say: we're getting cheaper.
But the bills keep climbing.
Because token consumption per task is growing faster than unit prices are falling. This isn't a feeling. There's data.
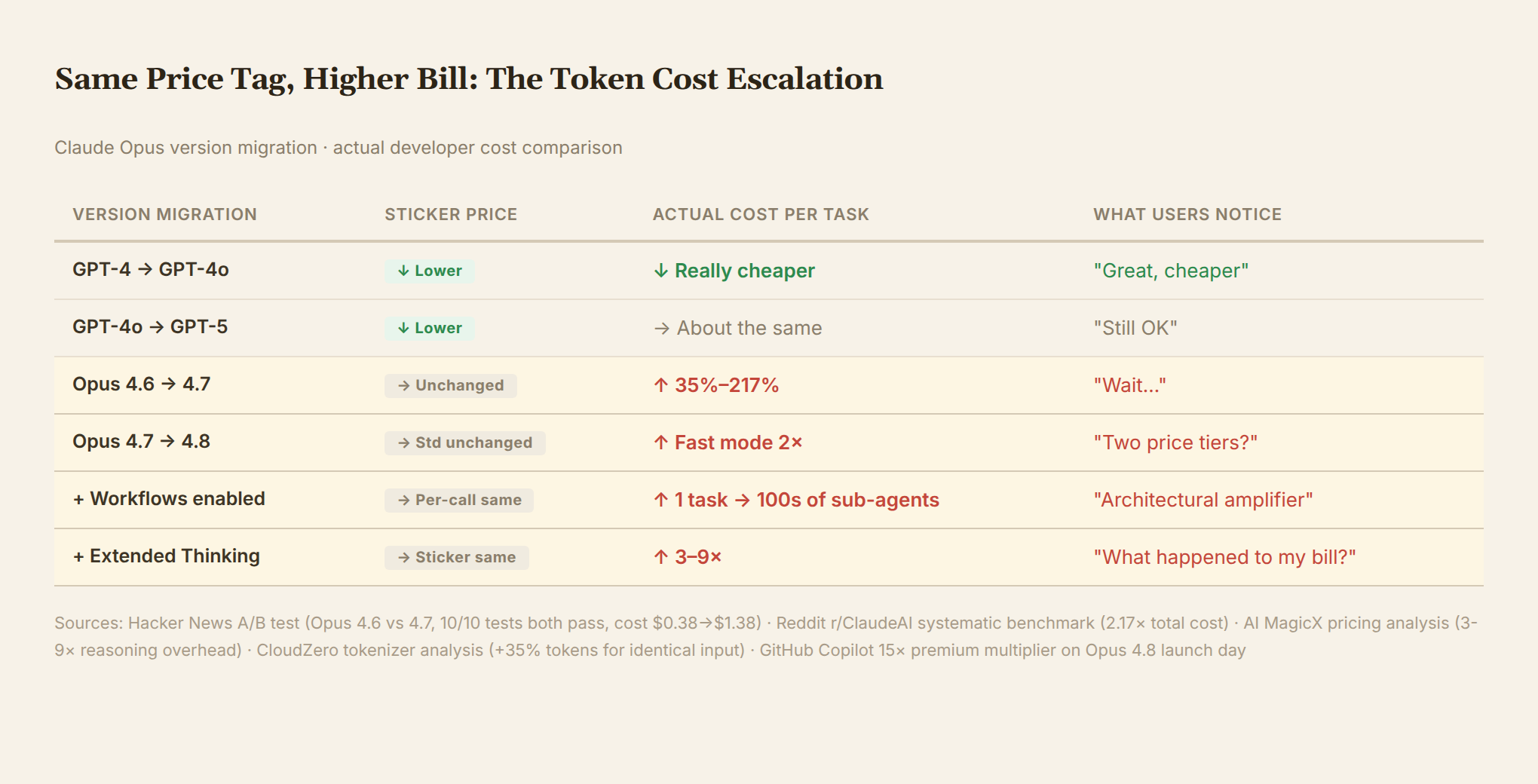
Evidence #1: The new tokenizer. When Claude Opus 4.7 launched in April 2026, Anthropic announced that "pricing is unchanged, still $5 per million input tokens." Developers discovered that the new tokenizer produces 35% more tokens for identical text. You send the exact same prompt, Opus 4.7 consumes over a third more tokens than 4.6. Not a single number changed on the price sheet, but every API call costs 35% more. This isn't a price hike—it's just "the same text now takes up more tokens."
Evidence #2: The A/B test. A developer on Hacker News ran a strict comparison. Same coding task: Opus 4.7 consumed 3.6× the tokens, cost rose from $0.38 to $1.38. Test results? Identical—both passed 10/10 tests. The extra dollar bought better code style and more thorough comments. The core output was unchanged.
Evidence #3: The default effort level. Opus 4.7 introduced the xhigh effort level, set as the default in Claude Code. Most users had no idea they were paying for higher-intensity reasoning. Systematic testing on Reddit: Opus 4.7 (xhigh effort) versus Opus 4.6 (high effort)—total cost was 2.17×. Input tokens were slightly lower, but output tokens surged, with tool calls in agentic mode jumping from 16 to 22. One YouTube video title captured the community's mood: "Opus 4.7 Is GREAT (except the token usage)."
Evidence #4: Fast mode doubles the price. Six weeks later, Opus 4.8 arrived (May 28, 2026). Standard pricing unchanged at $5/$25. But a new Fast mode was added: $10/$50. Straight double. Fast mode delivers 2.5× output speed; Anthropic says it's "roughly three times cheaper than fast inference on prior models." Whether it's actually cheaper depends on your reference point. If you switch from 4.7 standard to 4.8 Fast mode, you're paying twice the rate.
Evidence #5: Workflows—an architectural token amplifier. Opus 4.8 introduced the Workflows primitive: one agent plans a task, then fans out to hundreds of parallel sub-agents for execution, merging results at the end. One user action, hundreds of independent API calls, each with its own token consumption. This isn't a user "choosing to use more"—it's the product architecture making that choice for you.
Evidence #6: The hidden cost of reasoning models. AI MagicX's pricing analysis found that using reasoning models (o3, Claude extended thinking) actually costs 3-9× the sticker price. The "thinking process" generates tokens billed separately, but most users don't separate thinking tokens from output tokens in their mental math.
Put it all together:
| Version Migration | Sticker Price | Actual Cost Change | User Perception |
|---|---|---|---|
| GPT-4 → GPT-4o | ↓ Lower | ↓ Really cheaper | "Nice, cheaper" |
| GPT-4o → GPT-5 | ↓ Lower again | → About the same | "Still OK" |
| Opus 4.6 → 4.7 | → Unchanged | ↑ 35%–217% | "Wait..." |
| Opus 4.7 → 4.8 | → Standard unchanged | ↑ Fast mode 2× | "Two price tiers?" |
| + Workflows enabled | → Per-call unchanged | ↑ 1 task = 100s of sub-tasks | "Architectural amplifier" |
| + Extended Thinking | → Sticker unchanged | ↑ 3–9× | "What happened to my bill?" |
One more detail worth remembering: GitHub Copilot added a 15× premium multiplier on the day Opus 4.8 launched. Not a 15% increase—15 times. It wasn't adjusted until usage-based billing kicked in on June 1. Even distribution channels felt the new model's consumption warranted price guardrails.
A Reddit user posted in early June: they had consumed 1.15 billion input tokens in May alone. Their advice? "Go audit your cache hit rates."
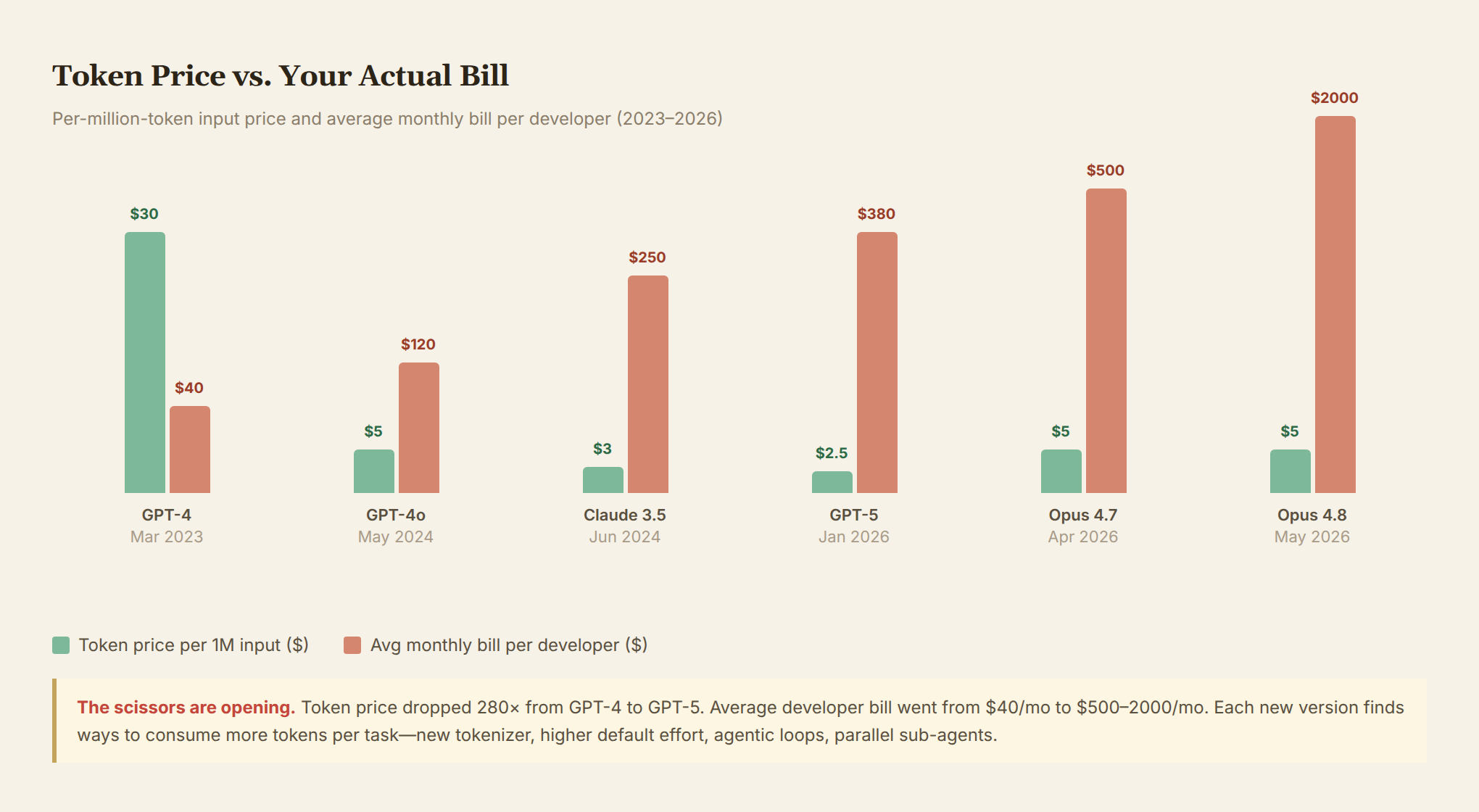
Token unit prices are falling. But every new model version consumes more tokens for the same task, then charges double for Fast mode, fans out hundreds of sub-tasks via Workflows, inflates token counts with a new tokenizer, and pushes up per-call costs with higher default effort levels.
This isn't technological inevitability. It's a systematic commercial choice.
III. The Other Side of Runaway Revenue
While enterprise clients were hurting, model company revenues were soaring.
OpenAI posted $5.7 billion in Q1 2026 revenue. Anthropic hit $4.8 billion in the same period, projecting a doubling to $10.9 billion in Q2, with annualized revenue targeting $45 billion. Its latest funding round aimed for $30-50 billion at a $95 billion valuation—surpassing OpenAI's $85 billion.
Both companies are on the IPO track. Revenue growth velocity directly determines the valuation ceiling.
A CNBC commentary identified the crux: AI demand metrics are distorted. Token consumption is the metric vendors love to cite—"look, our token usage grew 10×!" But token consumption measures how much time engineers spend on AI, not what they produce.
Sam Altman said something in March 2026 that got quoted repeatedly: "We see a future where intelligence is a utility, like electricity and water, and people buy it from us by the meter."
That's a vision. It's also a pricing strategy.
When you define AI as a utility, metered billing becomes self-evident. More usage means more revenue. "Encouraging users to use more" becomes the core of the business model. Anthropic's approach is even more direct: shifting from flat-rate Enterprise plans to pure token-based billing. CNBC called it "more honest"—at least revenue reflects actual usage. But it also means Anthropic's revenue growth is pegged to clients' token consumption. Every cent of client "waste" is Anthropic's revenue.
The incentive misalignment is clear. Model companies benefit when users consume more tokens. Users benefit when they solve more problems with fewer tokens. These two directions are fundamentally opposed.
And when revenue is tied to token consumption, "making each task consume more tokens" stops being a side effect—it becomes the core objective of product design.
IV. Are Models Still Improving?
If model capabilities were advancing rapidly, the growth in token consumption could at least be rationalized: we're paying for better capabilities. But the evidence from the first half of 2026 doesn't support that narrative.
New Scientist evaluated GPT-5 in two words: gains are modest. OpenAI claims GPT-5 is a "PhD-level expert," but independent evaluators aren't buying it. Multi-dimensional benchmarks show the gap between GPT-5 and GPT-4.5 is far smaller than the leap from GPT-4 to GPT-4.5.
HEC Paris's analysis was more blunt: "The open secret in the industry is that frontier models have hit a ceiling." Scaling law—that empirical rule that once convinced the AI world "just add compute and data and it gets better"—is showing diminishing marginal returns.
An MIT paper proposed "Meek Model Convergence": low-budget models are rapidly catching up to the most advanced ones. Spend 100× on training, and the advantage is shrinking.
But let's be honest about the other side. Models haven't completely stalled. Opus 4.8 is the only model to complete every case end-to-end on the Super-Agent benchmark, surpassing GPT-5.5. It posted the highest score on the Legal Agent Benchmark. Claude Mythos represents a qualitative leap in vulnerability discovery—Project Glasswing expanded to over 200 organizations, including the US government and major tech companies. GPT-5.4 Pro hit 94.6% on SWE-bench Verified. These are real advances.
The problem isn't that models aren't improving. The problem is that the cost-effectiveness of improvement is deteriorating. The capability gain per dollar from GPT-3 to GPT-4 was far larger than from GPT-5 to GPT-5.4. Marginal returns are diminishing, while marginal costs—measured in token consumption—are rising.
Capability plateau and token consumption explosion happening simultaneously point to the same conclusion: vendors are using "more token consumption" to compensate for the revenue pressure created by slowing per-call capability improvements.
Extended Thinking makes the model "think longer" before answering, consuming more tokens. Agentic loops iterate repeatedly, each iteration a fresh token spend. Opus 4.7 sets xhigh effort as default, pushing up per-call inference costs. Opus 4.8 introduces Workflows, fanning one operation into hundreds of sub-agents. OpenAI's o-series reasoning models follow the same "think longer" playbook.
When per-call capability gains slow down, extending the reasoning chain is the most direct way to boost revenue. Users get longer wait times. Model companies get more token revenue.
A Claude Code user on Reddit put it plainly: "LLMs have plateaued. The progress over the last half year is mostly better tooling, not the model itself getting smarter."
V. What Do Users Actually Want?
Back to a basic question: what are users paying for when they buy AI?
Not tokens. Not inference steps. Not Extended Thinking's internal monologue. Not the hundreds of sub-agents fanned out by Workflows.
Users want to solve harder problems in less time, for less money.
This desire has a structural conflict with model companies' business models.
Claude Code user feedback is polarized. Agentic mode genuinely handles more complex tasks. But a moderately complex refactoring job can consume 500,000 tokens, far exceeding expectations. Users oscillate between "this is great" and "I can't afford this."
Enterprise CTOs have a more specific anxiety. McKinsey data shows 95% of engineers using AI tools monthly in spring 2026, with 70% of committed code originating from AI. But Uber's Macdonald voiced what everyone was thinking—nobody can prove causation between AI usage and business output.
Amazon's case is dark comedy. An internal AI usage leaderboard ranked teams by token consumption. Engineers frantically burned tokens to climb the rankings. The company later shut down the leaderboard—because it rewarded waste, not output.
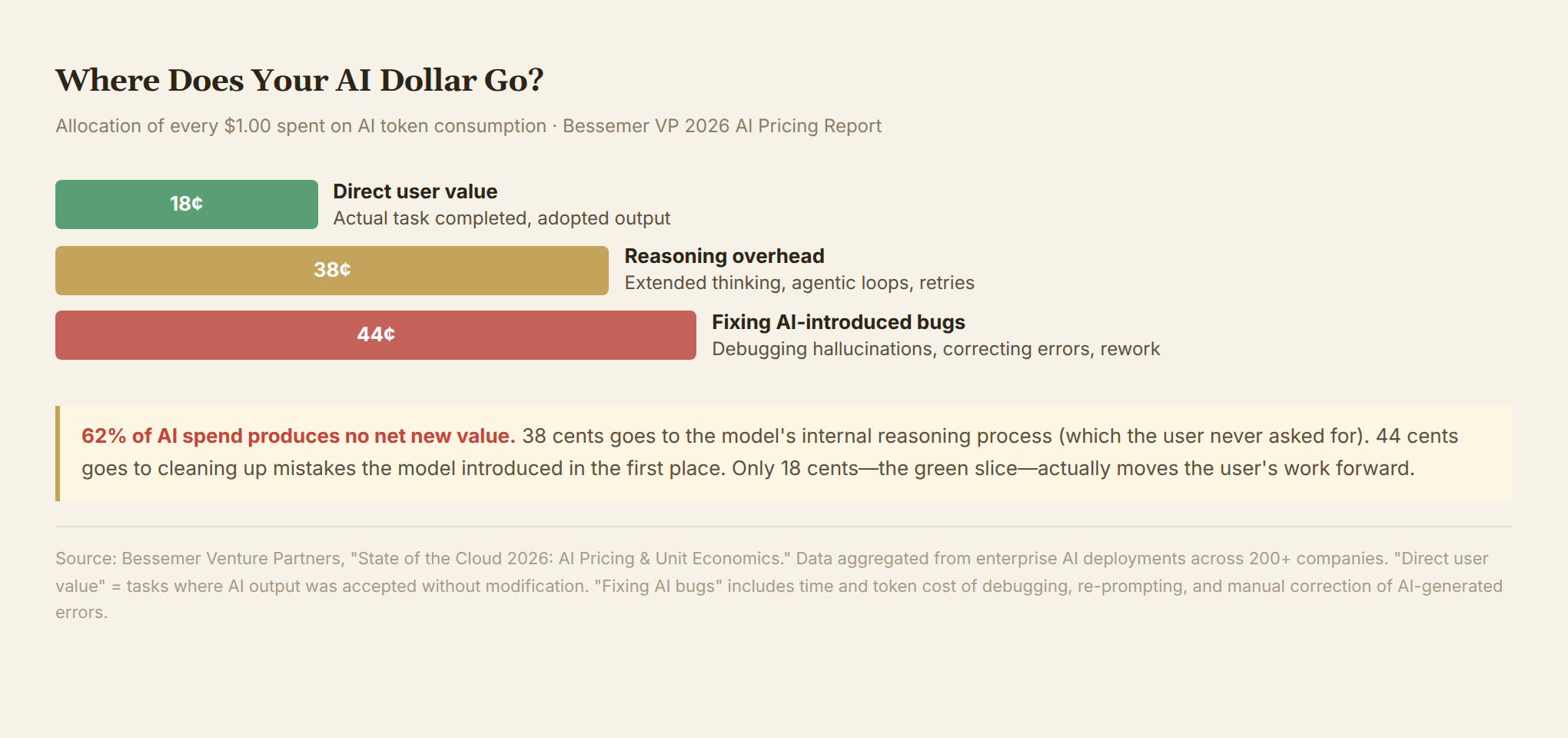
The sharpest number comes from Bessemer Venture Partners' AI pricing report: of every $1.00 spent on AI tokens, only $0.18 generates direct user value. $0.44 goes toward fixing bugs that AI introduced. If that number is anywhere near accurate, half the token economy is going in circles.
VI. Two Possible Exits
Outcome-Based Pricing
This is the direction Bessemer, a16z, and other investors pushed heavily in 2026. Stop billing by token. Bill by how many problems get solved—each successful code merge, each accurately discovered vulnerability, each customer service response accepted by the user.
Intercom's AI customer service product Fin is already doing this: billing per "resolved conversation" rather than per token. Reportedly working well.
But outcome-based pricing requires "outcomes" to be clearly defined and measurable. Coding is relatively easy (was the PR merged?). Writing, research, creative work—much harder. And it demands a fundamental restructuring of model company revenue: from "the more users consume, the more I earn" to "the fewer problems users have, the more I earn." That doesn't align with the short-term interests of any company sprinting toward an IPO.
Continued Cost Decline
Token unit prices really are falling. Google I/O 2026 launched Gemini 3.5 Flash, claiming it could save enterprises $1 billion annually in AI costs. DeepSeek V3.2 at $0.14 per million tokens makes Anthropic's $5 look extravagant.
But the paradox persists: unit prices drop, total bills rise. Model companies use agentic loops, extended thinking, new tokenizers, and Workflows fan-out to make each task's token consumption grow faster than the per-token price declines. The Opus 4.7 case already proved this.
Open-source models offer alternatives. DeepSeek, Llama, and Qwen approach GPT-4.5 levels in specific scenarios. When a "good enough" model can be self-hosted at controllable cost, enterprises gain an exit option from frontier-model premium pricing.
VII. Conclusion: Not a Bubble—A Pricing Power Struggle
The token retreat narrative is easily reduced to "AI bubble bursting." The reality is more nuanced.
AI's value is real. Coding efficiency gains, vulnerability discovery, customer service cost reduction—these aren't fictional. The problem lies in pricing power. Under the current market structure, model companies hold pricing power, and the pricing model is misaligned with user interests.
Model capability plateau sharpens this problem. When models no longer make a significant leap every six months, users naturally ask: what exactly did those extra tokens buy me?
Part of the answer is: longer thinking chains, more tool calls, more redundant iteration cycles—and model companies' Q2 revenue growth.
The Opus 4.7 case is worth remembering: when a model company tells you "pricing is unchanged," check your token consumption. New tokenizers, higher default effort levels, longer reasoning chains—these are all methods of raising volume without raising price. Opus 4.8 goes further: standard pricing unchanged, Fast mode outright doubled, Workflows splitting one operation into hundreds of calls. In the era of "intelligence by the meter," the meter's spin rate matters more than the unit price.
The market will eventually find a new equilibrium. It might be outcome-based pricing. It might be large-scale open-source substitution. It might be the proliferation of enterprise self-hosted inference.
Until then, the only thing users can do is: watch the bill, set hard limits, audit cache hit rates. Don't let the "intelligence utility" become a faucet you can't turn off.
Sources: Forbes, Fortune, CNBC, The Information, Axios, New Scientist, HEC Paris, Bessemer Venture Partners, Context Studios, Fast Company, Yahoo Finance, Hacker News, Reddit r/ClaudeAI, Finout, CloudZero, pricepertoken.com, official Anthropic announcements. As of June 4, 2026.