In April 2026, AWS did something quiet but consequential: all newly built non-GPU data centers worldwide switched their default network architecture from fat tree (Clos) to a flat topology called RNG (Resilient Network Graphs). Router count dropped 69%, throughput improved up to 33%, and network equipment power consumption fell roughly 40%.
This wasn't an experiment. It was the production default.
The news didn't go public until May 28, on the Amazon Science Blog. The paper is on arXiv (2604.15261), authored by University of Washington professor Ratul Mahajan and UCSC professor C. Seshadhri—both Amazon Scholars.
The significance of RNG isn't whether it can replace fat tree—that's the outcome, not the starting point. What's worth watching is this: a direction that was mathematically proven superior but engineeringly blocked for over a decade has been unblocked. The design space for data center networks just got bigger. There used to be one option; now there are two. And the existence of a second option changes how everyone re-examines the first.
This article does three things: explains how RNG works and how it's engineered, maps where it applies and where it doesn't, and explores the possibilities this new direction opens up—especially for inference clusters and the reference designs used by domestic AI compute centers.
Fat Tree's Fundamental Problem: Bandwidth Locked by Hierarchy
Fat tree's core design is hierarchical: servers connect to Top-of-Rack (ToR), ToR connects to Aggregation switches, Agg connects to Spine. Traffic goes "up then down"—paths are locked by hierarchy.
This structure has a mathematical Achilles' heel: lack of capacity fungibility.
The Beijing-to-Shanghai highway is jammed. The Beijing-to-Guangzhou highway sits empty. You can't use that empty road because your destination is Shanghai, and the road network's structure dictates that you take the fixed path.
The paper gives a precise example: 12 ToRs doing all-to-all communication, a 3:1 oversubscribed fat tree can only utilize about 40% of the ToR uplink capacity. 60% of bandwidth is wasted.
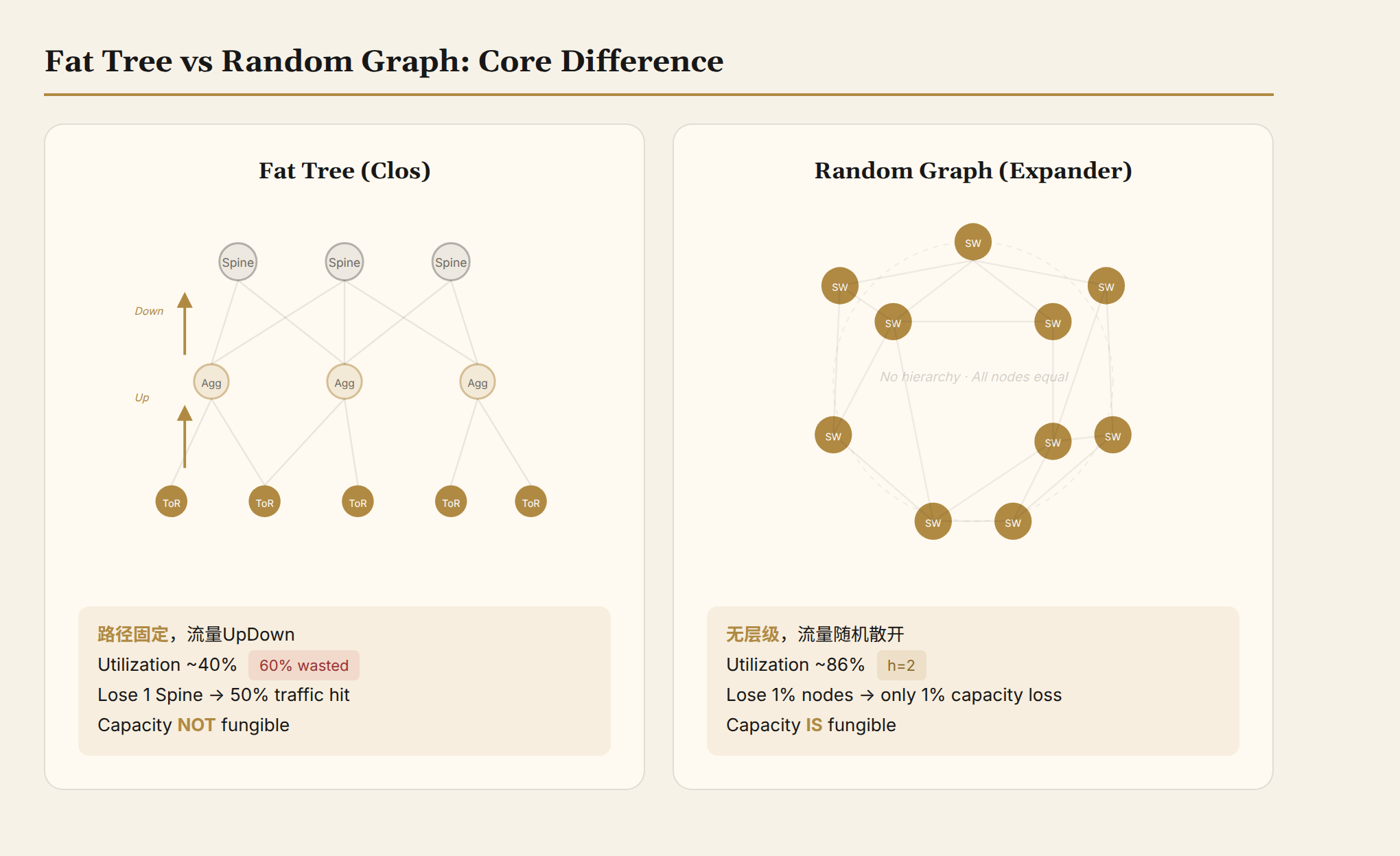
This isn't a big deal in single-tenant scenarios—you can plan traffic on demand. But in multi-tenant data centers, you don't know which tenant will send traffic where at any given moment. Hierarchical bandwidth allocation inevitably leads to systemic overprovisioning. This is the root cause of fat tree's stubbornly high costs.
Failure scenarios are worse: lose one Spine, and half your traffic is directly affected. What about randomly losing 1% of switches? The impact is far greater than 1%, because the hierarchical structure amplifies the blast radius of failures.
Mathematicians Knew the Answer: Random Graphs
In the 1990s, mathematicians had already proved that the optimal routing network topology is a random graph.
More precisely, a random graph with high edge expansion. The core property: for any small subset of nodes S, the number of edges leaving S is always large. There are no bottleneck nodes, no "all traffic must pass through here" chokepoints.
If you built a data center network with random graphs:
- Each switch randomly connects to 64 other switches, no hierarchy
- Any two switches have many completely independent paths to choose from
- If one path is congested, switch to another. If one switch dies, you lose roughly 1/n of capacity—the rest keeps working
Capacity is fungible, failure degradation is linear, no overprovisioning needed. The theoretically perfect topology.
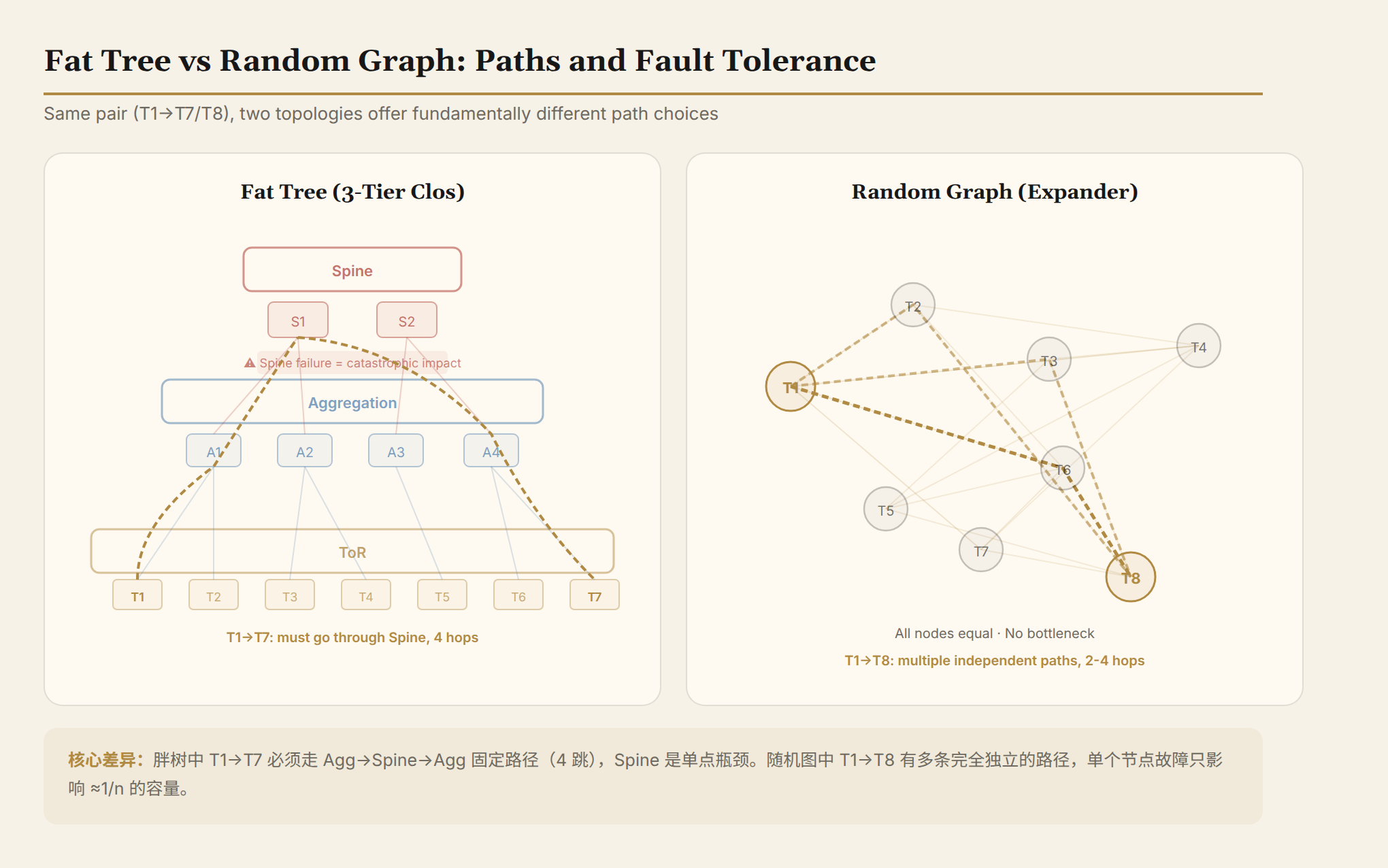
But between theory and engineering lay three fatal problems that blocked progress for over a decade.
Three Fatal Problems
How do you route? Standard shortest-path performs poorly on random graphs—two nodes may have only 1 shortest path. To find multiple independent paths for load balancing, you need k-shortest-paths. But k=8 requires 20-80× the forwarding table memory, which commercial switch ASICs can't hold. k=64 barely works, but the median number of independent paths is only 35, and oversubscription is still 4.7:1.
How do you cable? Random graphs mean random wiring. 1000 switches, each connected to 64 random neighbors, means 32,000 fiber strands crisscrossing the data center at random. AWS VP Matt Rehder tried it: "We did do the effective spaghetti mess of cabling. It was extremely onerous." Worse is incremental expansion: every time you add a new switch, you need to randomly disconnect dozens of existing cables across the entire facility and redistribute them. Operationally unacceptable.
How do you predict performance? Random graphs have no analytical model. You pick 1000 switches with 64 uplinks each—what's the oversubscription? You don't know; you can only simulate and iterate. Operations teams can't reverse-engineer parameters from target performance.
Any one of these unsolved keeps you out of production. RNG's contribution is solving all three simultaneously.
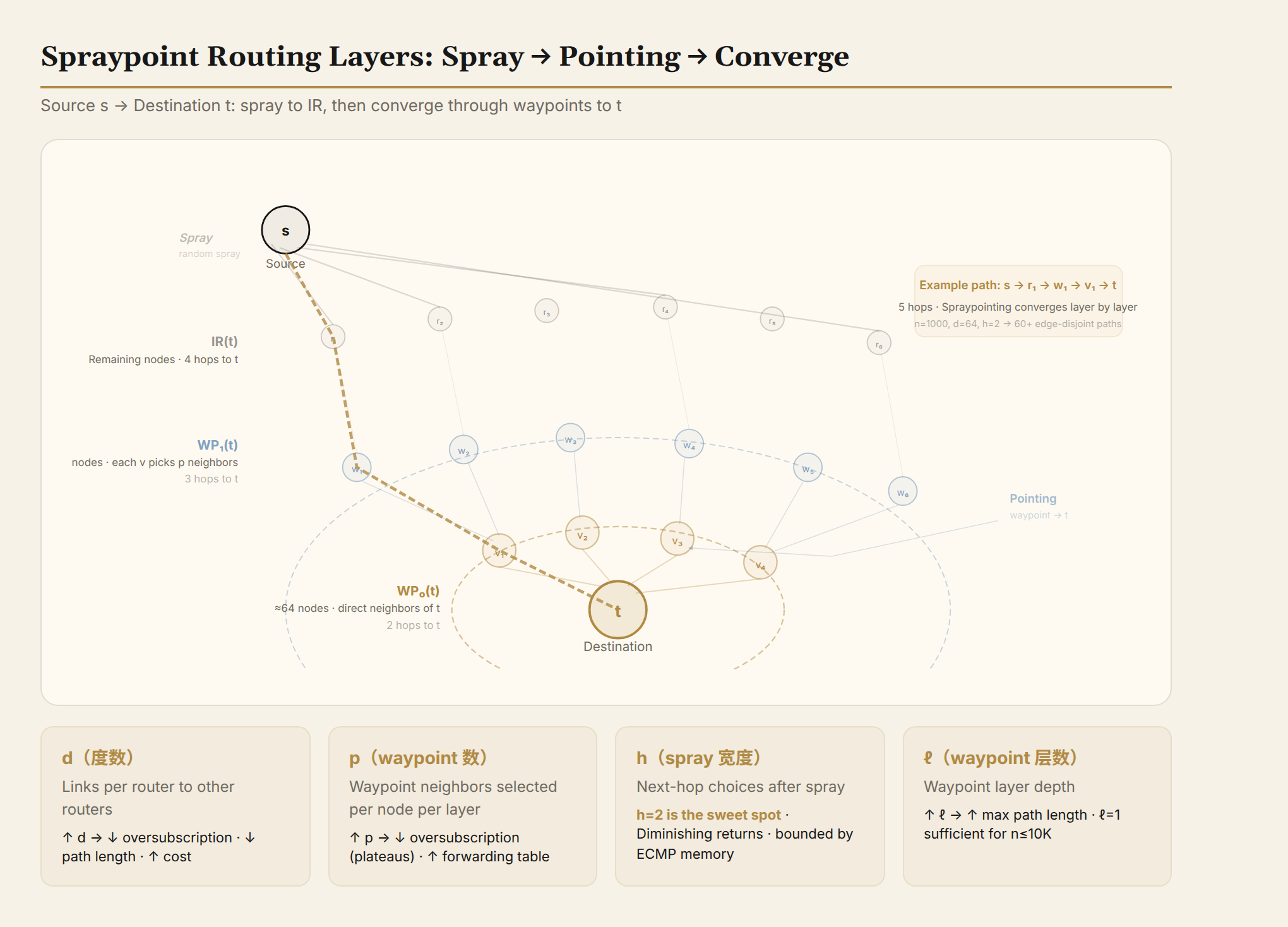
Spraypoint: Scatter First, Converge Later
Spraypoint is RNG's routing protocol. Its core insight: in a random graph, you don't need to globally compute optimal paths. The source scatters traffic, and the "high fan-in" at the destination naturally converges it.
An analogy. You're in Beijing, sending a letter to a friend in Shanghai.
Fat tree approach: all mail goes to the district post office, then the city post office, then the Shanghai city post office, then the district post office. Fixed path—if the city post office goes down, everything stops.
Spraypoint approach: you randomly hand the letter to one of 64 friends nearby. Each person has a table telling them "if you're sending to Zhang San in Shanghai, head in this direction." The letters scatter like ripples, then converge layer by layer toward the destination.
The mechanism works in three steps:
Step 1, Spray. The source switch receives a packet destined for t. It randomly selects one of its 64 neighbors (via ECMP hash) and sends the packet there.
Step 2, Determine which layer it landed on. Around each destination t, Spraypoint pre-computes a concentric ring structure:
- WP₀(t): t's direct neighbors (about 64)
- WP₁(t): the set formed by selecting 4 neighbors from each WP₀ node (about 256)
- IR(t): nodes that connect to waypoints but aren't in the higher layers (the majority)
- OR(t): nodes that don't connect to any waypoint layer (very few)
A sprayed packet landing on WP₀(t) reaches t in 2 hops, WP₁(t) in 3 hops, IR(t) in 4 hops, OR(t) in 5 hops.
Step 3, Within each layer, parameter h controls how many "t-parents" are selected. h=1 selects only 1 t-parent—if that edge fails, there's no backup. h=2 selects 2; if one fails, the other remains. h=3 selects 3, but with diminishing returns.
The key number—why h=2 is the sweet spot:
Number of edge-disjoint paths ≈ d·(1 - e^(-h)).
h=1: usable capacity 63%. h=2: 86%. h=3: 95%. The jump from h=1 to h=2 is +23%; from h=2 to h=3, only +8.5%. The exponential decay means h=2 delivers the best cost-effectiveness.
Actual results: n=1000, d=64, p=4, h=2 yields a median of 60+ edge-disjoint paths. Compare—8-shortest-paths yields only 5, 64-shortest-paths yields only 35. Spraypoint, using standard commercial switch hardware, achieves better path diversity than 64-shortest-paths.
Oversubscription drops from 4.7:1 (64-shortest-paths) to 3.25:1.
Forwarding table requirements: a 128-port switch with d=64, h=2 needs about 8K ECMP entries. Commercial switches typically have 16K+. No special hardware needed.

ShuffleBox: Turning Spaghetti into Ordered Conduits
The routing problem is solved. What about cabling?
The Spaghetti Problem
Random graphs require each switch to randomly connect to 64 other switches. These "other switches" are physically scattered across multiple rooms. If you actually pull cables, you get a ball of fiber spaghetti. Incremental expansion is even worse—every time you add a rack of switches, you need to randomly disconnect dozens of existing cables across the entire data center and rewire them.
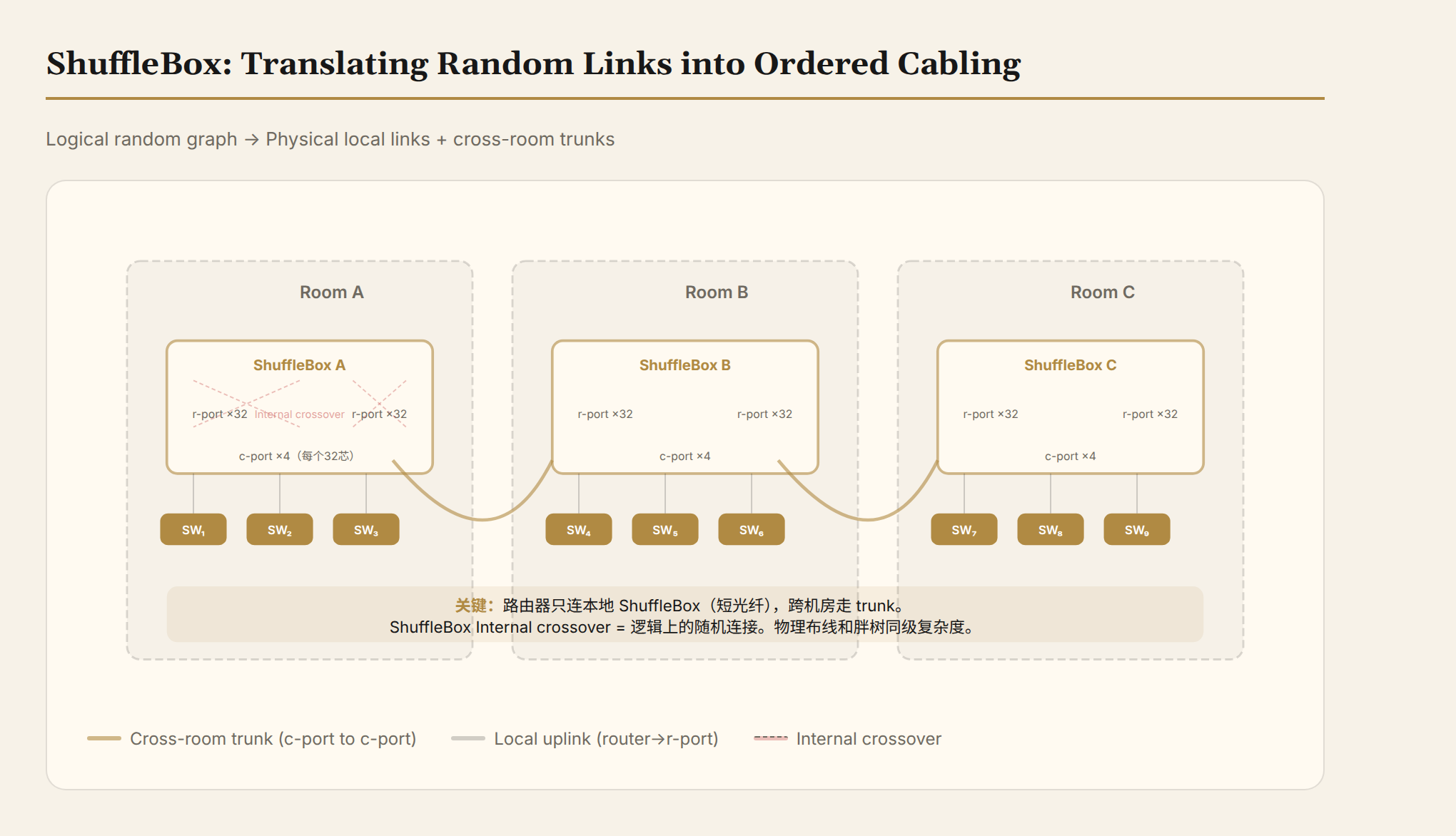
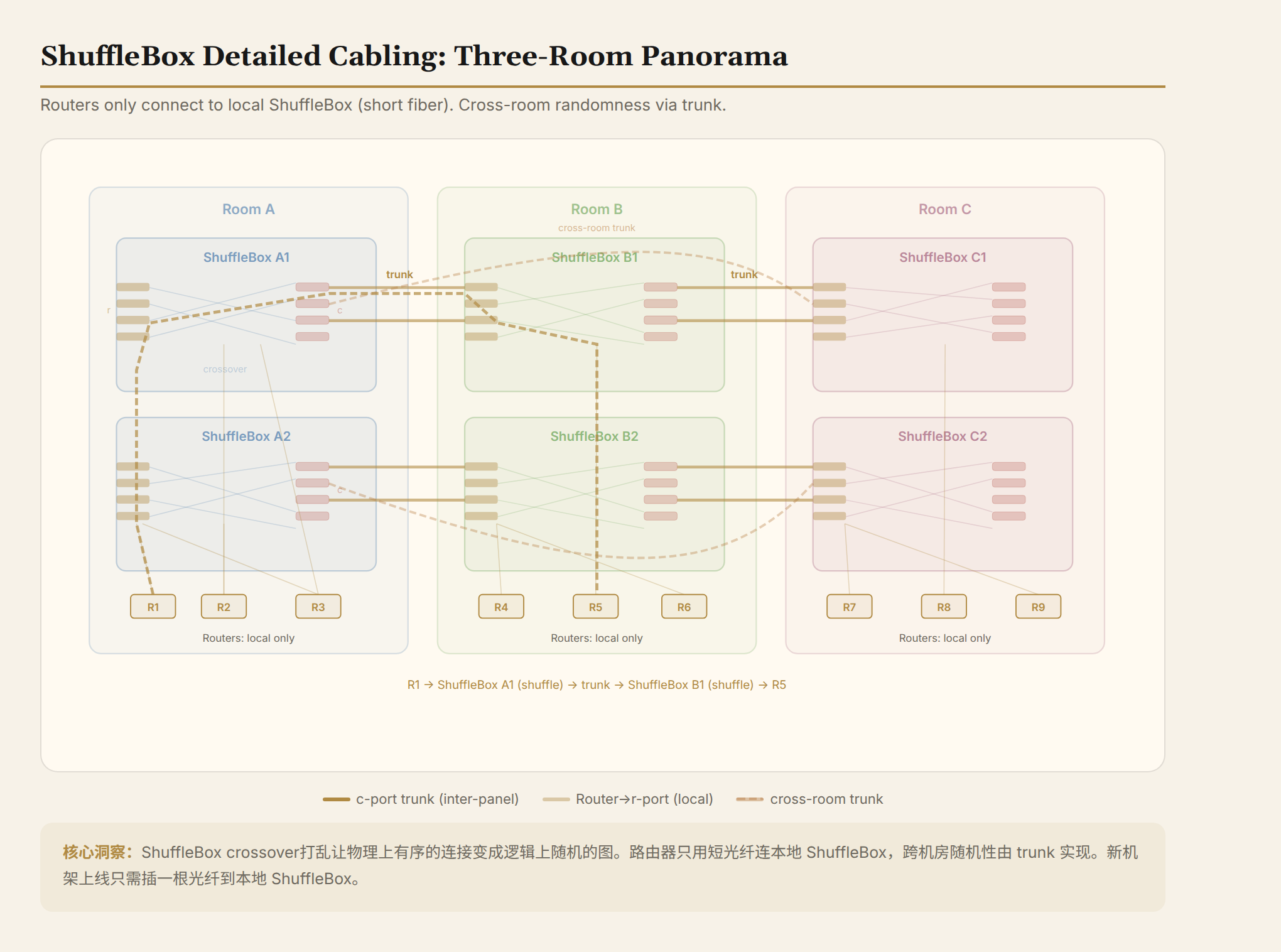
ShuffleBox Design
ShuffleBox is a passive optical device—no power, no chips, just fiber cross-connects internally. What it does is simple: it translates logically random connections into physically orderly ones.
Analogy: ShuffleBox is like a metro interchange station. You (the router) board only at your local station (plug into the local ShuffleBox). The interchange's internal scheduling (internal cross-connect shuffling) naturally routes you to the correct remote end. You don't need to know the global route map.
Structurally, each ShuffleBox has two types of ports:
- r-port (router port): 32 of them, 4 fibers each. Router uplinks plug in here.
- c-port (interconnect port): 4 of them, 32 fibers each. Connect to ShuffleBoxes in other rooms.
Internally it's a complete bipartite cross-connect: each c-port's 32 fibers come from 32 different r-ports. Each r-port's 4 fibers go to 4 different c-ports.
What happens without the internal shuffling? 32 routers' signals get assigned in order to 4 c-ports, each c-port serving a fixed set of 8 routers—that's not a random graph, that's 4 independent subgraphs. The internal cross-connect breaks this constraint, distributing each router's signals across 4 different remote ends.
Manufacturing and Cost: Is ShuffleBox Actually Expensive?
There's an understated but important line in the paper: ShuffleBox and ShuffleBack cost "similar to traditional patch panels and loopbacks"—comparable to traditional patch panels and fiber loopbacks.
How can it be this cheap? Because ShuffleBox has no active components internally. No chips, no power, no cooling. It's just fiber cross-connects fixed inside an enclosure. Manufacturing cost comes mainly from MPO connectors (multi-fiber push-pull connectors) and internal fiber routing. MPO is a mature standard product; 32-fiber MPO connectors cost tens of dollars at volume.
One ShuffleBox serves 32 router uplinks (dr=32, fr=4), using 4 c-ports with 32-fiber MPO each. Rough math: enclosure + 32 × 4-fiber MPO (r-ports) + 4 × 32-fiber MPO (c-ports) + internal fiber array. Total cost is in the hundreds of dollars. Compared to a 128-port switch (thousands to tens of thousands of dollars) and a 400G optical transceiver (hundreds of dollars), ShuffleBox's cost is essentially negligible.
But there's an engineering constraint: the choice of fc=32 isn't arbitrary. The paper explicitly states that larger fc values mean rarer connector specs (32-fiber MPO is already near the upper limit of what's readily available commercially), while smaller fc values mean more c-ports (since dr×fr=dc×fc), requiring more connections to manage during rebalancing. fc=32 is the tradeoff between connector availability and operational complexity.
Another engineering detail: AWS admits that in the initial production deployment, mass-produced ShuffleBoxes weren't ready yet. They used traditional patch panels to manually bridge individual fiber pairs to simulate the internal shuffling, plus custom ShuffleBacks. This shows that ShuffleBox's manufacturing barrier isn't high—a traditional patch panel can serve as a temporary substitute, just with lower operational efficiency. Once real ShuffleBoxes are mass-produced, cabling efficiency will be even better.
Physical Cabling
Each room has a set of ShuffleBoxes (a shuffle panel). Router uplinks plug only into the local ShuffleBox's r-ports via short fibers. Panels are interconnected via trunk fibers (c-port to c-port).
The paper breaks down cabling complexity across three dimensions:
| Dimension | Fat Tree | RNG + ShuffleBox |
|---|---|---|
| Endpoint pairs | n (routers) + R² trunks | n (routers to panels) + R² trunks (same level) |
| Cross-room fiber volume | Agg↔Spine three-layer trunk | Only one layer of inter-panel trunk |
| Pre-rack-install cabling ratio | Most trunk can be pre-laid | Same—inter-panel trunk laid during room prep |
| At rack installation | Plug local cables to Agg | Plug local cables to ShuffleBox |
Here R is the number of rooms (typically O(10)). The number of physical connection endpoint pairs is n + R(R-1)/2, far less than the logical connections' n². Routers only connect to local ShuffleBoxes via short fibers; cross-room connections are all handled by inter-panel trunks.
But there's a new cabling management challenge: randomness means physical connections have no identifiable pattern. In a fat tree, you see a cable from ToR to Agg and you know what it is. In RNG, a cable from router to ShuffleBox is just "randomly connected to some r-port"—physical location provides no semantic information. The paper reports a miswiring rate < 1.5%, but at scale, that means about 15 out of every 1000 cables are wrong. Fat tree miswiring rates are typically lower because the hierarchical structure provides physical-level validation.
AWS's mitigation: deploy enough ShuffleBoxes to ensure each room has headroom. Since the number of racks a room can hold depends on server power draw (high-density GPU racks and standard CPU racks consume completely different amounts of power), actual router counts fluctuate. AWS uses an estimated upper bound to determine how many ShuffleBoxes each room needs; if exceeded, excess racks are assigned to a new "logical room," triggering a rebalancing event. The paper acknowledges that fat trees face similar overprovisioning issues in large data centers.
Optical Loss: ShuffleBox Isn't Free
ShuffleBox's internal cross-connects have a physical cost: increased optical path loss.
Every physical fiber connection (two connectors mating) introduces insertion loss. A typical MPO connector has 0.3-0.5 dB insertion loss. A signal travels from the router, enters ShuffleBox through the r-port connector, exits via the c-port connector after internal cross-connect, passes through another trunk connector to the remote ShuffleBox's c-port, crosses internally, exits through the r-port connector, and finally reaches the destination router.
How many connectors on this path? At least 4 (router→r-port→c-port→remote c-port→remote r-port→router), but the signal may traverse a longer path inside the ShuffleBox. The paper's hard limit: disable any path with more than 7 connectors.
Why 7? It comes down to the optical power budget of commercial transceivers. A typical 400G SR4 transceiver has a power budget of about 3-5 dB (depending on specs and fiber length). Each connector loses 0.3-0.5 dB; 7 connectors means 2.1-3.5 dB. Add fiber attenuation (multimode fiber, about 1 dB/km), and the SNR margin is already tight.
Optical loss impact is not uniform. In a fat tree, a ToR→Agg→Spine path typically has 2-3 connectors. In RNG, intra-room paths also have 2-3, but cross-room paths may have 5-7. This means effective bandwidth for distant node pairs may be lower than for nearby pairs—even though routing treats all paths as "available," physical-layer signal quality degrades on longer paths.
This is an easily overlooked engineering constraint: RNG's "all paths are equal" holds at the logical layer. Physically, path quality varies. Fortunately, Spraypoint's preference for nearby waypoints (discussed later) mitigates this—not coincidentally, but because the paper's authors factored optical loss constraints into the routing design.
Incremental Expansion: New Racks Are Easy, New Rooms Need Care
Bringing up a new rack is simple: plug a fiber into an empty r-port on the local ShuffleBox. No other cables need to be touched. Identical to adding a rack in a fat tree.
Adding a new room is more complex. The steps:
- Install new panels
- Rebalance: from existing panels, randomly select some c-ports, disconnect ShuffleBacks or existing trunks, and connect new trunks to the new panel
- If this is the R-th room, each existing panel needs to redistribute c-port connections from R-1 panels to R panels evenly
- Before disconnecting any c-port, you must drain traffic on that link—meaning rebalancing is a disruptive operation requiring a maintenance window
Rebalancing blast radius: a c-port has 32 fibers (fc=32), so disconnecting one c-port affects 32 logical links. The paper notes that removing an r-port ShuffleBack affects only 4 links (fr=4), so the "blast radius is much smaller." This means rebalancing's impact scope is controllable, but not zero.
How often it happens in practice: data centers typically have O(10) rooms. If built all at once, no rebalancing occurs. If built in phases, it might happen 3-5 times. Each rebalancing operation requires disconnecting about C·dc/R c-ports per existing panel (C is the number of ShuffleBoxes per panel, R is total rooms). For C=4, dc=4, R=5, each panel needs about 3 c-ports disconnected—manageable, but requires precise tracking of which c-ports are connected and which have ShuffleBacks.
Early match rate: when the first room starts up, many fibers can't find pairs (the remote routers aren't online yet). At 25% deployment, match rate is about 25%; at full deployment, 100%. Opening the second room jumps to >90%, approaching 100% thereafter. For slow-growth data centers, the paper proposes phased panel deployment—splitting the first room's panels into multiple phases, progressively enabling them so that at 25% deployment you already achieve 80%+ effective degree.
ShuffleBack: What About Unused Ports?
Unused c-ports get ShuffleBack—a small connector that bridges fiber pairs within the same port (FP1→FP2, FP3→FP4...), folding signals back locally. Analogy: a roundabout where the exit hasn't been built yet—traffic circulates within the roundabout and can still reach other exits on the same roundabout. This keeps the topology valid even when the network isn't fully built out.
Mathematical Foundations: Why Random Graphs Are "Almost Surely" Good
The mathematical foundation of the RNG paper rests on concentration inequalities from probabilistic graph theory, specifically the Chernoff bound. Let's unpack the core step, because it explains why random graphs have a "practically impossible to fail" property.
Claim: If a node set S has at least nd/4 unpaired half-edges (fibers), then the probability that S connects to every node outside S is ≥ 1 − n⁻⁴.
Proof sketch: Each half-edge in S independently picks a global half-edge to pair with. An outside node v has d half-edges; the probability that a single pairing hits v is ≥ d/(nd) = 1/n. The probability that k attempts all miss v is ≤ (1−1/n)^k ≤ e^(−k/n). When k ≥ nd/4, e^(−k/n) ≤ e^(−d/4). For d ≥ 4·ln n, e^(−d/4) ≤ n⁻⁴. Union bound over all n nodes: n × n⁻⁴ = n⁻³.
For n=1000, the probability that "some node is unreachable from S" is < 10⁻⁹. Effectively impossible.
This probabilistic guarantee is the mathematical bedrock of the entire RNG framework — bounds on waypoint layer size, path length distributions, edge-disjoint path counts, and the analytical model for oversubscription all rest on this "almost sure" foundation.
The oversubscription analytical model is built on six principles (greedy shortest-path priority, average-case analysis, random deletion, feasible paths, unique positions, binomial congestion), ultimately yielding a polynomial formula. The paper validates it against LP-based multi-commodity flow simulations — model predictions match empirical values closely. Operations teams can plug target performance directly into the formula and solve for topology parameters, matching the design experience of traditional fat trees.
The mathematical guarantee that quasi-random graphs are equivalent to true random graphs comes from Chung, Graham, and Wilson's 1989 result: graphs satisfying a subset of quasi-random properties are equivalent to true random graphs across all quasi-random properties — including spectral gap, the core metric for expansiveness. This means RNG's "partially deterministic + partially random" connection pattern is functionally equivalent to a true random graph, but physically controllable.
A Counterintuitive Fact and Two Simple Fixes
RNG has fewer hops than fat trees (4 vs. 6), but latency can actually be higher.
The reason: in a fat tree, Agg→Spine links typically sit within the same room (a few meters to tens of meters). RNG's random connections can span an entire datacenter (hundreds of meters). Two fewer hops, but each hop has much larger propagation delay.
Simulation at 300m span: RNG median latency 8.4μs, fat tree 7.1μs — 15% higher. In datacenters, microsecond-scale latency differences accumulate over round trips, and operations teams are sensitive to this.
Two optimizations, simple but effective:
Prefer nearby waypoints: when selecting waypoints, prioritize candidates closer to the destination. The ranking function uses room-level distance (not exact fiber length, avoiding systematic bias toward nodes near cable trays). Latency drops 0.3μs.
Reduce cross-room links: parameter α controls the fraction of cross-room connections. At α=0.5, cross-room connections are halved. There's still enough cross-room capacity for throughput, and latency drops another 1μs. Bonus: 50% fewer cross-room fiber runs.
Combined, RNG median latency matches the fat tree. Neither optimization reduces throughput.
Production Deployment: Not an Experiment — the Default Architecture
RNG's production deployment uses two independent fabrics (server mesh + edge mesh). First deployed near Dublin in late 2024; became the default architecture for all new non-GPU datacenters globally in April 2026.
Quantified results:
| Metric | Value |
|---|---|
| Router count reduction | 69% |
| Throughput improvement | Up to 33% |
| Network equipment power reduction | ~40% |
| Infrastructure cost reduction | 9–45% (depending on oversubscription) |
Cost savings correlate strongly with oversubscription ratio: at 3:1 oversubscription, savings peak (~45%), because the value of capacity fungibility is highest in this range. At 1:1 non-blocking, only ~9% — because fat trees don't waste much capacity at 1:1. The conclusion matches intuition: higher oversubscription means more waste from hierarchical allocation, and flat topology advantages become more pronounced.
Application performance testing (against fat trees at the same oversubscription): identical throughput distribution across 127 concurrent flows, slightly higher 64B small-packet PPS, matching storage read IOPS. Zero user-reported performance issues. Latency differences are invisible at the application layer — a strong rebuttal to concerns about "inconsistent path lengths in random graphs."
On the operations side, the cabling error rate is < 1.5%. ShuffleBox isn't yet in mass production; initial deployments use traditional patch panels with custom ShuffleBack modules to simulate. Spraypoint convergence time is comparable to Amazon's existing link-state protocols.
But the operational transformation goes far beyond "swap one topology for another."
The Maintenance Challenge: Fat Trees Give You Intuition; Flat Topologies Take It Away
A fat tree's hierarchical structure isn't just a topology design — it's also the operations team's mental model. The AWS paper puts it bluntly: "The hierarchy of fat trees was embedded deeply into these tools, starting from device names itself to managing redundancy during maintenance."
In plain terms: the hierarchy is baked into device names. A ToR called "pod3-agg-rack12-tor1" tells you immediately which Pod it's in and which Agg group it connects to. In RNG, there are no Pods, no Agg layers — the naming system needs to be rebuilt from scratch.
The more substantive impact is on maintenance scheduling. In a fat tree, ToRs are leaf nodes with no mutual dependencies. Want to upgrade firmware on 10 ToRs? Do them all simultaneously — each ToR only affects its own rack's servers. Not so in RNG. ToRs have inter-dependencies (they're interconnected through ShuffleBox); upgrading too many neighbors at once degrades connectivity in certain regions. You need to compute "which ToRs can safely be upgraded simultaneously" — this is a graph coloring problem, where neighbors can't share the same color. For a graph with degree d=64, the number of ToRs you can upgrade in parallel is far smaller than in a fat tree.
Fault diagnosis also changes fundamentally. In a fat tree, if an Agg→Spine link has issues, you check that one link. In RNG, an end-to-end path traverses multiple random intermediate nodes — there's no "natural" hierarchical fault localization. The paper notes that AWS "built new tools to easily determine the paths between ToRs for troubleshooting" — they had to develop new tooling to trace actual paths between any two ToRs, because manual tracing is nearly impossible.
Summary of new tooling requirements:
| Tool Type | Fat Tree | RNG |
|---|---|---|
| Device naming | Hierarchical (Pod-Agg-ToR) | New scheme required |
| Redundancy management | Same-tier switches as backups | Neighbors as backups; graph algorithms to determine upgrade groups |
| Maintenance scheduling | Same-tier batch operations | Graph coloring limits parallelism |
| Fault localization | Trace along hierarchy | End-to-end path tracing tools required |
| Topology visualization | Tree structure is intuitive | Purpose-built expander graph visualization needed |
| Capacity planning | Expand by tier | Analytical model designed around oversubscription targets |
This is a substantial tooling investment. AWS hasn't disclosed specifics, but the paper implies a multi-year engineering effort — from project kickoff in 2023 to becoming the default architecture in 2026, with extensive toolchain development throughout. For any team looking to replicate the RNG approach, the toolchain development cost should not be underestimated.
RNG's Limits: Every New Path Has Places It Can't Reach
RNG isn't universal. AWS is explicit: GPU training clusters still use fat trees (UltraServer / Rail-optimized variants).
The reason: large-model training requires locality and aggregation islands — all-reduce traffic among the same group of GPUs needs high-bandwidth, low-latency "island"-style connectivity. Flat topology has no islands; all nodes are equal, which is counterproductive for workloads with strong locality requirements.
Another boundary: network scale. The current configuration (ℓ=1 waypoint layer) works for n ≤ 10K routers. Larger networks need additional waypoint layers, increasing path lengths and model complexity.
Optical attenuation also limits physical span — as discussed above, paths exceeding 7 connectors get pruned, so cross-room node pairs have fewer path options than nearby nodes.
What Possibilities Does the New Path Open?
Having read the paper and AWS's deployment data, I believe the most important signal is this: the design space for datacenter topologies has expanded. Before, fat tree was the only viable option. Now there's a second. The existence of a second option changes how everyone scrutinizes the first — even if you ultimately choose fat tree, your reasons will be different.
Where does RNG have a clear advantage? Multi-tenant, heterogeneous workloads, unpredictable traffic patterns — general-purpose compute, storage, inference clusters. AWS has proven 9–45% cost savings and up to 33% throughput improvement with real deployments. Capacity fungibility delivers real economic value in these scenarios.
Where is fat tree still superior? GPU training clusters. They need locality and aggregation islands, with predictable, highly concurrent traffic patterns. Flat topology's "all nodes are equal" is a disadvantage here. AWS itself still uses UltraServer / Rail-optimized fat trees for GPU clusters.
Where's the most interesting gray area? Inference clusters. Inference traffic patterns sit between training and multi-tenant general compute — request sources and destinations are unpredictable (like multi-tenant), but same-batch token processing requires low-latency coordination (like training). Which topology fits better? There's no answer yet. But this question wouldn't even have been asked before, because fat tree was the only option. RNG's existence makes the question meaningful. In China, inference cluster topology selection is barely discussed — most reference designs use the same fat tree architecture for both training and inference, or simply don't distinguish between the two scenarios' different requirements.
Where are there no answers yet? Mid-scale enterprise datacenters, private clouds, edge datacenters — the scale and heterogeneity in these scenarios may not be enough for RNG's advantages to outweigh toolchain migration costs. The answer depends on specifics; more validation is needed.
AWS hasn't open-sourced the ShuffleBox or Spraypoint implementations. But the paper provides sufficient design principles and parameter selection strategies to serve as a starting point for reference designs. For teams looking to replicate this approach, the supply-chain additions are custom passive optical components (ShuffleBox/ShuffleBack) and a Spraypoint firmware implementation on commercial switches.
Hard engineering constraints for production deployment:
First, ShuffleBox is a custom component with no market-standard equivalent. But the barrier is low — it's a passive optical device, and AWS simulated it with traditional patch panels in initial deployments. What actually needs customization is the internal crossover pattern and ShuffleBack. For China's optical communication supply chain (Innolight, Accelink, etc.), manufacturing capability isn't the issue — it's whether demand volume justifies spinning up a production line.
Second, fat tree toolchain maturity far exceeds that of flat topologies. AWS spent roughly three years on toolchain transformation (2023–2026). Migration cost isn't just writing code — it's rebuilding the operations team's mental model, from "hierarchical troubleshooting" to "graph-theoretic troubleshooting." This is an organizational-level change.
Third, optical attenuation limits physical span. Paths exceeding 7 connectors get pruned, meaning cross-room node pairs may have fewer path options than nearby ones. Spraypoint's nearby-waypoint preference mitigates this but doesn't eliminate it. For datacenters with very large physical spans (cross-building, cross-floor), optical attenuation may become a binding constraint before oversubscription does.
Fourth, fault diagnosis in flat topologies is more complex than in fat trees. No hierarchy means the blast radius of failures is smaller (losing 1% of nodes ≈ losing 1% of capacity), but fault localization requires new end-to-end path tracing tools. You can no longer rely on "check the Spine status" as an intuitive diagnostic.
What China's Big Players Are Doing: Each Their Own Path
AWS's RNG targets hyperscale multi-tenant datacenters. China's big players face different problems — different scales, different workloads, different supply chains. But their respective explorations in datacenter networking validate the RNG paper's core judgment from different angles: fat tree isn't the only answer; workload determines topology.
Alibaba: HPN Customizes Topology for Training; Stellar Rebuilds the Transport Layer for Inference
Alibaba is the most prolific Chinese hyperscaler in datacenter networking publications.
At SIGCOMM 2024, Alibaba presented HPN (High Performance Network). The core design philosophy: simple physical topology + efficient multipath and congestion control. HPN uses a multi-track physical topology — not a standard three-tier fat tree, but one that constrains same-track GPU traffic within a single plane, with cross-track traffic going through a dedicated core layer. Path selection complexity drops from fat tree's O(2304) to O(60). A single Pod supports 15,360 GPUs.
This approach runs opposite to AWS RNG's direction: RNG uses randomness for capacity fungibility; HPN uses carefully designed locality for path predictability. But the goal is the same — reduce path selection complexity and improve load balancing efficiency.
At Apsara 2025, Alibaba released HPN8.0 with 800G throughput, double the previous generation. Positioning is clear: serving AI model training, inference, and reinforcement learning.
At SIGCOMM 2025, Alibaba will present Stellar — its third-generation high-performance network transport stack, purpose-built for intelligent computing. Stellar focuses not on topology but on the transport layer: RDMA congestion control, multipath selection, and joint optimization with AI workloads.
Alibaba's strategy is clear: custom topology for training (HPN multi-track), proprietary transport protocol (Stellar), the two decoupled. This differs from AWS's approach of replacing both topology and routing simultaneously, but it's more pragmatic — no need to rebuild the entire operations toolchain; modifying just the transport layer captures part of the benefit.
ByteDance: Heavy Capital Investment, Silent on Topology
ByteDance's capital expenditure leads among Chinese hyperscalers. Approximately ¥80B in 2024, projected ¥150B in 2025, of which about ¥100B goes to hardware procurement, with switches and other network equipment comprising ~11% (~¥16.5B).
But on network topology research, ByteDance is nearly silent. SIGCOMM 2025 features one ByteDance paper — ByteScale (ultra-long context training on 16,384 GPUs) — but the focus is communication efficiency optimization, not topology innovation. Another paper, Jakiro, enables simultaneous RDMA and TCP support on VPC — a transport-layer effort. Self-developed DPU direction has been disclosed, but zero public discussion on topology.
Two possible explanations: ByteDance's current cluster scale (tens of thousands of GPUs) still works with fat tree / Rail-optimized topologies, and topology isn't the bottleneck yet; or their networking team is working on something but hasn't published. Either way, RNG's emergence will push ByteDance to reassess — especially as inference cluster scale grows to the point where multi-tenant network resource sharing becomes necessary.
Tencent: Solving the Optical Layer, Not Touching Topology
Tencent's CPO (Co-Packaged Optics) switch, Gemini, represents the boldest Chinese investment in datacenter networking hardware. Developed in collaboration with Broadcom in 2022, it delivers 25.6T switching capacity with 16× 800G optical interfaces + 32× QSFP112 pluggable interfaces. Half the volume of traditional switches, 26% lower power consumption, 20% lower latency.
But Gemini solves a physical layer problem — replacing copper with optics, increasing port density and transmission distance. Topology remains fat tree / Spine-Leaf.
Tencent's strategy: use CPO to break through physical bottlenecks (bandwidth, power, cable management) while staying conservative on topology. This strategy is safe in the short term — no toolchain rebuild required. But medium to long term, once CPO solves the physical layer bottleneck, the topology-layer bottleneck will surface. At that point, RNG-style flat topologies become the next question to answer.
ZCube: Another Answer from Academia
SIGCOMM 2025 also features a noteworthy paper: ATOP→ZCube. The authors, from Tsinghua University, work on automated topology optimization — parameterizing network topology as a set of hyperparameters and using search algorithms to find optimal topologies at scales from 256 to 16,384 GPUs.
The result is ZCube, a new asymmetric topology: low network diameter, strong training performance, good fault tolerance, and better cost-effectiveness than existing schemes.
Whether ZCube itself gets adopted remains uncertain. But the value of the ATOP framework is this: it transforms topology design from "pick fat tree parameters based on experience" into "a computable optimization problem." This aligns with the RNG paper's approach of using analytical models to design topologies — both replace intuition with mathematics.
Huawei, H3C, and Ruijie: Each Equipment Vendor's Path Forward
Huawei's product line for AI datacenter networks centers on the CloudEngine series (800GE core switch 16800-X) and the Xinghe AI Network. On topology, they promote fat tree variants (including Rail-optimized), focusing on port speed increases and RoCEv2 optimization.
H3C has gone furthest among equipment vendors, with the most complete product line. It maintains three product lines simultaneously:
First, a standard RoCE solution based on Broadcom and Centec switching ASICs, targeting lossless Ethernet. This is the mature, highest-compatibility offering for mainstream customers and currently the highest-volume product line. Centec is the Chinese switching ASIC vendor closest to the high end; H3C's partnership reduces chip supply risk.
Second, a DDC (Distributed Disaggregated Chassis) architecture next-generation lossless network solution. The core switch S12500AI series introduces cell switching and VOQ (Virtual Output Queue) technology, claiming 100% load balancing and zero-congestion transport. Tolly-verified: DDC architecture improves effective bandwidth by up to 107% compared to ECMP. DDC fundamentally replaces traditional ECMP hashing with cell switching — the same conceptual move as AWS RNG replacing shortest-path with Spraypoint: both solve the inefficiency of fat tree path selection. But DDC still relies on Spine-Leaf physical topology; it doesn't change the topology itself. Xiaohongshu has completed China's first large-scale validation of DDC-based AI networking with H3C.
Third, 800G CPO switches in the S9827 series, already deployed at major internet companies. Also announced: a single-chip 102.4T 800G AI switch, the S9828-128EP (128× 800G ports). On scale, the DDC architecture supports 9,216× 400G ports per cluster, scaling to 73,728 across multiple clusters.
Ruijie Networks occupies a unique position in the Chinese switch market — not designing its own ASICs, but building systems integration and scenario-specific solutions on commercial ASICs from Broadcom and others. In 2025, Ruijie announced the AI-Fabric AI datacenter network solution, also using DDC architecture: NCP (Network Cloud Pod) + NCF (Network Cloud Fabric) three-tier network, supporting 18K–32K GPU clusters. Core technology is the same cell switching + VOQ + credit-based flow control, similar to H3C's DDC approach.
Ruijie's differentiation is a decentralized distributed OS — control plane and management plane are decoupled, allowing independent device upgrades. This solves the single-point-of-failure and version compatibility pain points of traditional DDC architectures' NCC (Network Cloud Controller). Ruijie also successfully delivered a dual-plane high-availability AI network for a top cloud provider (1,000 GPU servers, 8,000× 800G NICs), with AllReduce bandwidth stable above 760GB/s.
Customers include Alibaba, ByteDance, and Tencent.
Commonalities and differences among equipment vendors: Huawei leads on speed and ecosystem; H3C has gone furthest with DDC/cell switching (with actual customer validation); Ruijie has an edge in cost-effectiveness and operational simplicity. None of the three have touched the topology layer — all optimize load balancing and transport efficiency within the fat tree / Spine-Leaf framework. RNG-style flat topology currently has only one deployment (AWS); vendors are unlikely to include it in reference designs without more validation. But H3C's DDC architecture already demonstrates how far "replacing ECMP with cell switching within the fat tree framework" can go — if that path hits a ceiling, flat topology is the next step.
Core Assessment of China's Position
Looking at all the major players together, a clear picture emerges:
| Company | Focus Area | Topology Change | Relationship to RNG |
|---|---|---|---|
| Alibaba | HPN multi-track + Stellar | Yes (custom topology for training) | Parallel — optimizing locality for training, not multi-tenant capacity fungibility |
| ByteDance | Capital investment + DPU | No public action | Watching — fat tree handles current scale, but inference growth may change the calculus |
| Tencent | CPO co-packaged optics | None | Complementary — solves physical layer bottleneck; topology TBD |
| Tsinghua ZCube | Automated topology search | Yes (academic exploration) | Same direction — mathematical topology design |
| Huawei | High-speed switches + RoCEv2 | None | Conservative — waiting for more deployment data |
| H3C | Standard RoCE + DDC cell switching + 102.4T 800G | Load balancing layer (no topology change) | Partially aligned — cell switching replaces ECMP, but within fat tree framework |
| Ruijie | AI-Fabric DDC + 800G dual-plane | Load balancing layer (no topology change) | Partially aligned — same as above, plus operational simplicity and cost-effectiveness |
Nobody is directly following RNG's flat topology path. But everyone is answering the same question in their own way: what comes after fat tree? Alibaba chose custom topology; Tencent chose physical-layer breakthroughs; ByteDance chose not to touch it yet; academia chose automated search.
RNG's greatest significance for China isn't "copy this" — it's providing a validated reference point: in multi-tenant, heterogeneous workload scenarios, flat topology delivers clear cost and performance advantages. When Chinese hyperscalers' inference clusters grow to the point where capacity fungibility matters, this reference point becomes useful.

Conclusion
Fat tree has ruled datacenter networking for forty years — not because it's optimal, but because alternatives kept failing. Three engineering problems (routing, cabling, performance prediction) were stuck for over a decade. RNG solves all three simultaneously: Spraypoint makes routing work on commercial switches, ShuffleBox brings cabling complexity down to fat-tree parity, and the analytical performance model lets operations design topologies by formula.
AWS validated feasibility with large-scale production deployment. But RNG's greatest value isn't replacing fat tree — it's expanding the datacenter networking design space from one dimension to two.
Before, the question in network design was "what oversubscription ratio for my fat tree?" Now there's a new question you can ask: "should this scenario use a fat tree at all?" That question is more valuable than any answer to it.
Directions worth exploring: flat topology feasibility for inference clusters (no public exploration from Chinese hyperscalers yet), the path to ShuffleBox-class components in China's supply chain (optical communication industry has the manufacturing capability; what's missing is demand), next-generation commercial switches with Spraypoint-like routing support (vendors are watching), and more benchmark data across scales and scenarios.
Chinese hyperscalers already invest heavily in networking (ByteDance's 2025 network equipment budget is approximately ¥16.5B), but the investment focuses on training-side speed improvements and protocol optimization. Topology-level exploration has barely begun. Alibaba's HPN is the closest Chinese approach to topology innovation, but it optimizes for locality — the opposite direction from RNG's capacity fungibility. These two paths aren't competing — they answer different questions for different workloads.
Next observation points: whether Alibaba will experiment with flat topology for general-purpose compute and inference; whether ByteDance will reassess topology choices as inference cluster scale grows; whether H3C/Ruijie's DDC architectures will hit load-balancing ceilings at 10K+ GPU scale, driving evolution toward flat topology.
Disclaimer: This article is based on AWS's publicly published paper arXiv:2604.15261v3, "RNG: Flat Datacenter Networks at Scale" (submitted April 2026), and publicly available information from Amazon Science Blog (May 28, 2026), cross-verified with reporting from Tom's Hardware, Data Center Knowledge, SDxCentral, and other sources. The Chinese hyperscaler sections draw on publicly available information from SDxCentral, Fiber Online, LinkedIn (Dennis Cai), ACM SIGCOMM 2024/2025 accepted paper lists, and Sinolink Securities research reports. This article does not constitute investment advice. Data is current as of June 5, 2026.