时间:2026年5月19-20日 · Shoreline Amphitheatre · Sundar Pichai 主题演讲 核心主题:从操作系统到智能系统(Intelligence System)——全栈 Agent 化飞轮完成第一轮闭环 增强版说明:在原文基础上增加深度技术分析、Mermaid 架构图、竞品对比、成本推算和商业模式分析
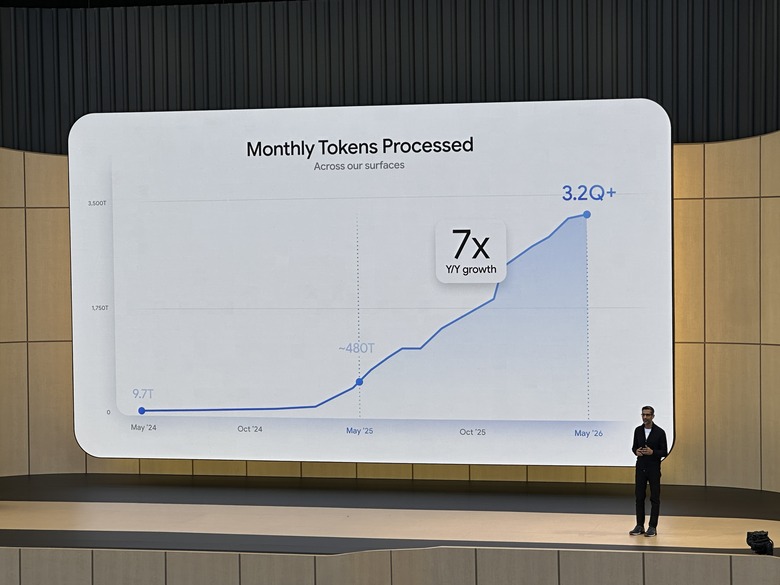
一、规模基线:Google 的 AI 飞轮有多大了?
Sundar 开场用三个数字定调:
| 指标 | 数据 |
|---|---|
| 月处理 Token 量 | 3.2 quadrillion(3200万亿),同比 7x 增长(去年 480T) |
| Gemini 月活用户 | 9 亿+(去年同期 4 亿) |
| AI Overviews 月活 | 25 亿 |
| AI Mode 月活 | 10 亿(仅上线一年) |
| 10 亿+ 用户产品 | 13 个(其中 5 个超 30 亿) |
| 开发者 | 850 万+ 月活开发者使用 Google 模型 |
| API 吞吐 | 190 亿 tokens/分钟 |
| 年 Capex | 1800-1900 亿美元(2022 年 310 亿的 6 倍) |
这些数字不是虚荣指标——Token 是 AI 任务的原子单位,3.2 quadrillion/month 意味着 AI 已经是 Google 的承重基础设施,不是实验项目。
🔬 深度技术分析:3.2Q Tokens/Month 的基础设施推算
Token 处理规模增长曲线(2022-2026)
xychart-beta
title "Google 月 Token 处理量增长(2022-2026,单位:万亿)"
x-axis ["2022", "2023", "2024-H2", "2025-H1", "2025-I/O", "2026-I/O"]
y-axis "月处理 Token 量(万亿)" 0 --> 3500
line [5, 30, 120, 250, 480, 3200]
关键推算:
| 推算维度 | 数值 | 计算逻辑 |
|---|---|---|
| 月 Token 量 | 3.2Q = 3.2 × 10¹⁵ | 官方数据 |
| 峰值 Token/秒 | ~1.2M tok/s | 3.2Q ÷ (30 × 24 × 3600),假设均匀分布 |
| 峰值 Token/秒(含波动) | ~3-5M tok/s | 考虑 3-4x 日内峰值 |
| 所需 TPU v5p 等效芯片 | ~200-400 万片 | 基于 TPU v5p ~5T tok/s/chip/year,考虑推理/训练混合负载 |
| TPU 第八代(Ironwood)等效 | ~50-100 万片 | 假设 Ironwood 性能是 v5p 的 4x |
| 数据中心电力需求 | ~2-4 GW | 基于 Ironwood ~500W/chip,含冷却和配套设施 |
| 数据中心面积 | ~200-400 万 sq ft | 基于 ~5MW/sq ft 的典型密度 |
| 年电力成本 | ~$30-60 亿 | 按 $0.06-0.08/kWh 工业电价 |
| Capex 回收周期 | ~3-5 年 | $1800-1900 亿年 Capex ÷ 年增量收入 |
关键洞察:
- 3.2Q tokens/month 的增长曲线是超指数级的——从 2024 年底的约 120T 到 2026 年的 3200T,不到两年增长 27x。这不是线性扩展,而是飞轮效应:更好的模型 → 更多用户 → 更多数据 → 更多基础设施 → 更好的模型。
- 190 亿 tokens/分钟的峰值吞吐意味着 Google 的推理基础设施已经接近传统互联网 CDN 级别的规模。这个数字对应的并发请求数大约在 数千万级(假设平均请求 2K tokens)。
- $1800-1900 亿 Capex 的核心问题是 ROI——如果按 Gemini API 均价 ~$3/M tokens 推算,3.2Q tokens/month 对应 ~$96 亿/月的潜在 API 收入天花板(实际远低于此,因为大部分是内部消耗和免费层)。这意味着基础设施投资的回收可能需要 3-5 年以上的时间窗口。
🔬 Google 全栈飞轮架构图
graph TB
subgraph "基础设施层 Infrastructure"
TPU["TPU Ironwood<br/>第8代"]
GCP["Google Cloud<br/>Agentic Data Cloud"]
ENERGY["数据中心<br/>~3-4 GW 电力"]
end
subgraph "模型层 Models"
FLASH["Gemini 3.5 Flash<br/>Agent/Coding 核心"]
PRO["Gemini 3.5 Pro<br/>下月发布"]
OMNI["Gemini Omni<br/>Any→Any 多模态"]
VEO["Veo 3.1<br/>视频生成"]
IMAGEN["Imagen 4<br/>文生图"]
LYRIA["Lyria 2<br/>音乐生成"]
end
subgraph "Agent 基座 Agent Platform"
AG["Antigravity 2.0<br/>Desktop/CLI/SDK"]
MAA["Managed Agents API<br/>托管沙箱"]
SPARK["Gemini Spark<br/>24/7 个人 Agent"]
FIREBASE["Firebase<br/>开发全链路"]
end
subgraph "消费入口 Consumer"
SEARCH["Search<br/>AI Mode 10亿+ MAU"]
GEMINI_APP["Gemini App<br/>9亿+ MAU"]
ANDROID["Android 17<br/>Gemini Intelligence"]
WORKSPACE["Workspace<br/>企业 AI 层"]
end
subgraph "硬件载体 Hardware"
GBOOK["Googlebook<br/>Intelligence Laptop"]
XR["Android XR 眼镜<br/>Gentle Monster/Warby Parker"]
PIXEL["Pixel / Samsung"]
end
TPU --> FLASH
TPU --> PRO
TPU --> OMNI
GCP --> MAA
ENERGY --> TPU
FLASH --> AG
FLASH --> MAA
OMNI --> VEO
OMNI --> IMAGEN
FLASH --> SPARK
AG --> SEARCH
MAA --> WORKSPACE
SPARK --> GEMINI_APP
AG --> FIREBASE
SEARCH --> GBOOK
GEMINI_APP --> XR
ANDROID --> PIXEL
WORKSPACE --> GBOOK
二、模型层:Gemini 3.5 Flash + Gemini Omni

2.1 Gemini 3.5 Flash —— "Flash 不再是廉价档"
这是 I/O 2026 技术含量最高的发布。Google 定位为"最强的 agent/coding 模型"(注意不是最强绝对智能),GA 即日可用。
核心规格:
- 上下文窗口:1M tokens
- 最大输出:65K tokens
- Thinking 级别:4 档(minimal / low / medium / high),medium 为新默认
- 跨轮次「思维保持」(Thought Preservation)
- 输入模态:文本 + 图片 + 视频 + 语音
- 价格:$1.50 / $9.00(输入/输出每百万 token),缓存输入 90% 折扣
关键 Benchmark:
| 指标 | 分数 |
|---|---|
| Terminal-Bench 2.1 | 76.2% |
| GDPval-AA (Agentic Elo) | 1656 |
| MCP Atlas | 83.6% |
| MMMU-Pro | 84% |
| Artificial Analysis Intelligence Index | 55(+9 vs Gemini 3 Flash) |
速度:
- 官方宣称比同级前沿模型快 4x
- Antigravity 内最高 12x(约 867 tok/s)
- 独立测速 > 280 output tok/s
值得注意的信号:
- Flash 标签正在吸收原来 Pro 的定位——价格也水涨船高(Artificial Analysis 报告运行成本是 Gemini 3 Flash 的 5.5x,比 Gemini 3.1 Pro 贵 75%)
- Gemini 3.5 Pro 下月发布,Flash 先行是为了快速铺量 agent 场景
- 幻觉率下降 31 个百分点(在 Artificial Analysis 全知测试中降至 61%)
外部评价:
- 正面:"insane evals for a Flash model"、"Google is back"
- 质疑:MRCR 和 ARC-AGI-2 表现一般,价格不再 Flash;GPT-5.5-medium 在某些 slice 上可能更优
🔬 深度技术分析:Gemini 3.5 Flash 技术架构
Thinking 4 档机制与推理成本分析
graph LR
subgraph "Thinking Level"
MIN["Minimal<br/>~1x token 成本"]
LOW["Low<br/>~2-3x token 成本"]
MED["Medium<br/>~5-8x token 成本<br/>【新默认】"]
HIGH["High<br/>~15-20x token 成本"]
end
MIN -->|+推理| LOW
LOW -->|+推理| MED
MED -->|+推理| HIGH
subgraph "输出特征"
SPEED["速度: High > Med > Low > Min"]
QUALITY["质量: High > Med > Low > Min"]
COST["成本: High >> Med > Low > Min"]
end
Thinking 4 档成本推算表:
| Thinking Level | 估算 Thinking Token 消耗 | 有效输入成本 | 有效输出成本 | 适用场景 |
|---|---|---|---|---|
| Minimal | ~500-1K tokens | ~$1.50/M | ~$9.00/M | 简单问答、格式转换 |
| Low | ~2K-5K tokens | ~$1.50/M + ~$1.50/M(think) | ~$9.00/M | 日常对话、基础编码 |
| Medium(默认) | ~5K-15K tokens | ~$1.50/M + ~$4.50/M(think) | ~$9.00/M | Agent 编排、复杂编码、分析 |
| High | ~20K-50K+ tokens | ~$1.50/M + ~$15-30/M(think) | ~$9.00/M | 困难推理、多步规划 |
关键洞察:
- Thinking Token 的隐性成本——Google 没有公开 Thinking Token 的定价细节,但基于行业惯例(Anthropic 的 extended thinking 也消耗额外 token),medium 默认意味着每次 API 调用的实际成本比标称价格高 3-5x。
- Flash 定位的战略漂移——Gemini 3.5 Flash 的运行成本是 Gemini 3 Flash 的 5.5x,比 Gemini 3.1 Pro 还贵 75%。"Flash"这个标签正在从"便宜快速"漂移到"旗舰级但相对快速"。这对开发者的成本预期管理是一个风险。
- Antigravity 内 12x 加速的秘密——867 tok/s 的输出速度可能来自:a) 自定义 KV cache 优化;b) 推测解码(speculative decoding)配合更小的 draft model;c) 内部批处理优化。这暗示 Google 内部有一套未公开的推理加速栈。
Thought Preservation 技术含义
Thought Preservation(跨轮次思维保持)是一个被低估的技术特性。传统 LLM 对话中,每轮对话只有文本历史作为上下文;Thought Preservation 意味着:
传统模式:
User → [Text History + System Prompt] → Model → Response
Thought Preservation 模式:
User → [Text History + System Prompt + Previous Thinking Chains] → Model → Response
↑ 模型可以"看到"之前轮次的内部推理过程
实现挑战:
- 上下文窗口压力:如果保留所有 thinking token,10 轮对话可能消耗 100K+ tokens 仅用于思维链历史
- 选择性保留策略:Google 可能采用了某种"思维压缩"机制——不是保留原始 thinking token,而是保留推理的结构化摘要
- 隐私考量:Thinking token 可能包含对用户输入的推理细节,跨轮次保留增加了数据暴露面
- 一致性风险:如果前面轮次的 thinking 有错误,保留这些 thinking 可能导致错误放大
对 Agent 场景的价值: 这是 Antigravity 和 Spark 的关键技术支撑。Agent 需要跨多轮执行保持任务上下文和推理一致性,Thought Preservation 提供了比单纯文本历史更丰富的状态传递机制。
Gemini 3.5 Flash 技术架构
graph TB
subgraph "输入管线 Input Pipeline"
TEXT["文本输入<br/>Tokenization"]
IMAGE["图片输入<br/>ViT Encoding"]
VIDEO["视频输入<br/>帧采样 + ViT"]
AUDIO["语音输入<br/>ASR + 语义编码"]
end
TEXT --> FUSION["多模态融合层<br/>Cross-Attention Fusion"]
IMAGE --> FUSION
VIDEO --> FUSION
AUDIO --> FUSION
FUSION --> CONTEXT["上下文管理<br/>1M Token Window<br/>+ KV Cache"]
CONTEXT --> THINK["Thinking Engine<br/>4-Level Adaptive"]
THINK --> |"Minimal"| OUT_FAST["快速输出<br/>~280+ tok/s"]
THINK --> |"Medium(默认)"| OUT_MED["标准推理输出<br/>~150 tok/s"]
THINK --> |"High"| OUT_DEEP["深度推理输出<br/>~50 tok/s"]
subgraph "Thought Preservation"
TP_STORE["思维链存储"]
TP_COMPRESS["思维压缩"]
TP_RETRIEVE["跨轮次检索"]
end
THINK <--> TP_STORE
TP_STORE --> TP_COMPRESS
TP_COMPRESS --> TP_RETRIEVE
TP_RETRIEVE --> CONTEXT
2.2 Gemini Omni —— 从理解到创造的统一入口

定位: 将 Gemini 的推理/世界知识与 Google 生成式媒体栈合并,实现「any input → any output」。首发聚焦 视频。
核心能力:
- 输入:文本 / 图片 / 音频 / 视频
- 输出:视频生成与编辑(初始最长 10 秒,含原生音频)
- 多轮编辑:场景/角色一致性保持
- "Reimagine":用对话式指令重新想象用户上传的视频素材
- 更强的物理世界理解和运动一致性
发布节奏:
- 付费用户:Gemini App / Flow 即日可用
- YouTube Shorts/Create:本周免费开放
- API:未来几周
战略意义: Omni 不只是又一个视频模型——它是 Google 统一「多模态理解 + 媒体编辑 + 世界建模 + Agent 接口」的入口。和 DeepMind 的 world model 长线战略一致。
关联产品矩阵:
- Veo 3.1:文本→视频生成,已上线 Vertex AI,支持「首尾帧」/「场景扩展」/「对象插入」等高级编辑
- Imagen 4:Google 最高质量文生图模型
- Lyria 2:AI 音乐生成
- Flow / Flow Music:Google 的创意工作站,集成了以上所有模型
- Nano Banana:已累计生成 500 亿张图片

🔬 深度技术分析:Omni "Any→Any" 技术架构推演
graph TB
subgraph "输入编码器 Encoders"
I_TEXT["Text Encoder<br/>Gemini Tokenizer"]
I_IMAGE["Image Encoder<br/>ViT + Patch Embedding"]
I_AUDIO["Audio Encoder<br/>SoundStream/EnCodec"]
I_VIDEO["Video Encoder<br/>时空 Tokenizer"]
end
subgraph "统一潜空间 Unified Latent Space"
LATENT["多模态 Latent<br/>Diffusion Foundation<br/>+ World Model"]
end
subgraph "输出解码器 Decoders"
O_TEXT["Text Decoder<br/>Gemini LM Head"]
O_IMAGE["Image Decoder<br/>Diffusion + VAE"]
O_AUDIO["Audio Decoder<br/>Neural Vocoder"]
O_VIDEO["Video Decoder<br/>Temporal Diffusion<br/>+ 原生音频"]
end
I_TEXT --> LATENT
I_IMAGE --> LATENT
I_AUDIO --> LATENT
I_VIDEO --> LATENT
LATENT --> O_TEXT
LATENT --> O_IMAGE
LATENT --> O_AUDIO
LATENT --> O_VIDEO
subgraph "关键技术创新"
CONSISTENCY["场景/角色一致性<br/>Identity Preservation"]
PHYSICS["物理世界理解<br/>Physics Simulation"]
MULTI_TURN["多轮编辑<br/>Diffusion Inversion"]
end
LATENT --> CONSISTENCY
CONSISTENCY --> PHYSICS
PHYSICS --> MULTI_TURN
"Any Input → Any Output" 的技术架构推演:
Omni 的核心突破不是单个模态的质量,而是将所有模态映射到统一的 latent space。这意味着:
- 统一 Latent Space——Omni 可能采用了类似于 UniDiffuser 或 CM3leon 的架构思路,将所有模态编码到同一个高维空间,然后从这个空间解码到目标模态。这比级联式 pipeline(文本→图像→视频→音频)更高效。
- 多轮编辑的技术基础——Reimagine 功能暗示 Omni 支持 latent space 的 inversion 和编辑。用户上传视频后,Omni 将其编码到 latent space,然后用文本指令在 latent space 中定位和修改特定属性(风格、对象、场景),最后解码回视频。
- 原生音频生成的意义——10 秒视频包含原生音频,这意味着 Omni 的视频解码器和音频解码器是联合训练的,共享了时空表示。这是目前竞争对手(Sora、Runway Gen-4)都不完全具备的能力。
- 与 Agent 层的连接——Omni 作为 Gemini 生态的一部分,可以被 Antigravity Agent 直接调用。这意味着 Agent 不仅能处理文本/代码,还能生成和编辑多媒体内容。
三、Agent 层:Antigravity 2.0 + Gemini Spark
这是本次 I/O 最重要的架构性变化——Google 不再把 Agent 当作聊天模型的薄包装,而是构建了完整的执行基座。
3.1 Antigravity 2.0 —— Google 的 Agent 操作系统
| 组件 | 说明 |
|---|---|
| Desktop App | Agent-first 桌面,核心对话 + Artifacts + 多 Agent 编排 |
| CLI | 命令行版 Agent 执行环境 |
| SDK | 面向开发者的 Agent 开发包 |
| Managed Agents API | 单次 API 调用即可创建 Agent + 托管 Linux 沙箱(Bash/Python/Node、文件操作、浏览、自定义 Skills) |
| AI Studio → Antigravity | 一键导出 |
| Android 原生 | AI Studio 支持生成 Android 应用 |
标志性 Demo:
用 Antigravity + Gemini 3.5 Flash,93 个并行子 Agent 花了 12 小时构建了一个完整操作系统。15,000+ 次模型请求,消耗 26 亿 tokens。
虽然这是精心设计的 demo,但它揭示了 Google 想让开发者采用的架构:很多快的 Agent 协作,而不是一个慢的巨型模型单干。
Jeff Dean 的原话:3.5 Flash 是"deploy sub-agents that collaborate, run high-frequency iterative loops, and solve real-world problems at scale"的强力引擎。
外部评价:
- 正面:这是 Google 对 Codex / Claude Code / OpenClaw 的回应,基础设施故事更强
- 批评:品牌和产品混乱——Gemini CLI vs Antigravity CLI 傻傻分不清,UX 设计被吐槽
🔬 深度技术分析:Antigravity 2.0 架构全拆解
Antigravity 2.0 组件架构关系图
graph TB
subgraph "开发者入口 Developer Entry Points"
DESKTOP["Antigravity Desktop<br/>Agent-first IDE<br/>对话 + Artifacts + 多Agent编排"]
CLI["Antigravity CLI<br/>命令行 Agent 执行"]
SDK["Antigravity SDK<br/>Python/TypeScript SDK"]
STUDIO["AI Studio<br/>Prompt → Agent 一键导出"]
end
subgraph "运行时 Runtime"
LOCAL_RT["本地运行时<br/>Desktop/CLI 内置"]
MANAGED_RT["Managed Agents Runtime<br/>Google Cloud 托管"]
end
subgraph "托管沙箱 Managed Sandbox"
SANDBOX["Linux 沙箱环境"]
BASH["Bash 执行"]
PYTHON["Python 运行时"]
NODE["Node.js 运行时"]
FILES["文件系统操作"]
BROWSER["Headless Browser<br/>网页浏览"]
SKILLS["自定义 Skills<br/>技能注册表"]
end
subgraph "编排层 Orchestration"
ORCHESTRATOR["Agent Orchestrator<br/>单Agent/多Agent编排"]
SINGLE["单 Agent 模式<br/>简单任务"]
MULTI["多 Agent 协作<br/>复杂任务分解"]
end
subgraph "模型后端 Model Backend"
FLASH_BE["Gemini 3.5 Flash<br/>高频推理"]
PRO_BE["Gemini 3.5 Pro<br/>深度推理"]
API_BE["Gemini API<br/>1M Context + Thinking"]
end
DESKTOP --> LOCAL_RT
CLI --> LOCAL_RT
SDK --> LOCAL_RT
SDK --> MANAGED_RT
STUDIO --> DESKTOP
MANAGED_RT --> SANDBOX
SANDBOX --> BASH
SANDBOX --> PYTHON
SANDBOX --> NODE
SANDBOX --> FILES
SANDBOX --> BROWSER
SANDBOX --> SKILLS
LOCAL_RT --> ORCHESTRATOR
MANAGED_RT --> ORCHESTRATOR
ORCHESTRATOR --> SINGLE
ORCHESTRATOR --> MULTI
SINGLE --> FLASH_BE
MULTI --> FLASH_BE
SINGLE --> PRO_BE
Managed Agents API 沙箱安全模型推演
Google 官方只提到"安全远程环境"和"Linux 沙箱",没有披露具体技术实现。基于 Google Cloud 的现有技术栈和行业实践,推演如下:
graph TB
subgraph "安全边界 Security Boundary"
API_GATEWAY["API Gateway<br/>认证 + 限流"]
ORCHESTRATOR_S["Agent Orchestrator<br/>任务调度"]
end
subgraph "沙箱选项(推演)"
OPT1["选项1: gVisor<br/>用户态内核<br/>系统调用过滤<br/>★★★☆☆ 隔离性"]
OPT2["选项2: Firecracker microVM<br/>轻量虚拟机<br/>硬件级隔离<br/>★★★★★ 隔离性"]
OPT3["选项3: Linux Namespace<br/>+ cgroup + seccomp<br/>容器级隔离<br/>★★★☆☆ 隔离性"]
end
subgraph "安全控制"
NETWORK["网络隔离<br/>出站白名单"]
STORAGE["存储隔离<br/>临时文件系统"]
RESOURCE["资源限制<br/>CPU/Mem/Time"]
AUDIT["审计日志<br/>所有操作记录"]
end
API_GATEWAY --> ORCHESTRATOR_S
ORCHESTRATOR_S --> OPT1
ORCHESTRATOR_S --> OPT2
ORCHESTRATOR_S --> OPT3
OPT1 --> NETWORK
OPT2 --> NETWORK
OPT3 --> NETWORK
OPT1 --> STORAGE
OPT2 --> STORAGE
OPT3 --> STORAGE
OPT1 --> RESOURCE
OPT2 --> RESOURCE
OPT3 --> RESOURCE
NETWORK --> AUDIT
STORAGE --> AUDIT
RESOURCE --> AUDIT
最可能的实现方案推演:
| 方案 | 可能性 | 理由 |
|---|---|---|
| Firecracker microVM | ★★★★☆ | Google Cloud 已有 Firecracker 经验(通过 Kata Containers),硬件级隔离最安全,启动时间 ~125ms 可接受 |
| gVisor | ★★★☆☆ | Google 自研,但性能开销较大,不适合高频 Agent 场景 |
| Linux Namespace + cgroup | ★★☆☆☆ | 隔离性不够,多租户风险较高 |
| 混合方案 | ★★★★★ | 最可能:Firecracker 做基础隔离 + 自定义 seccomp 做系统调用过滤 + 网络策略做出站控制 |
安全边界设计的关键问题:
- 网络出口控制——Agent 需要"浏览网页",但又不能成为 DDoS 放大器或数据外泄通道。可能的方案是:出站请求通过 Google 的代理网关,带速率限制和域名白名单。
- 文件系统生命周期——"临时文件系统"意味着 Agent 的文件在任务结束后被销毁。这排除了持久化攻击的可能,但也限制了有状态 Agent 的能力。
- 技能注册的安全审查——自定义 Skills 的代码是否经过静态分析?是否有运行时监控?Google 没有披露,但这直接关系到供应链安全。
Agent 生命周期管理
stateDiagram-v2
[*] --> Created: API 调用 / CLI 启动
Created --> Initializing: 分配沙箱 + 加载 Skills
Initializing --> Ready: 环境就绪
Ready --> Executing: 接收任务
Executing --> Thinking: 推理中
Thinking --> Acting: 生成动作
Acting --> Observing: 执行动作 + 获取结果
Observing --> Thinking: 继续推理
Thinking --> WaitingConfirm: 需要用户确认
WaitingConfirm --> Executing: 用户批准
WaitingConfirm --> Aborted: 用户拒绝
Executing --> Completed: 任务完成
Executing --> Failed: 错误/超时
Failed --> Retrying: 自动重试
Retrying --> Executing: 重试成功
Retrying --> Failed: 重试耗尽
Completed --> Cleanup: 回收资源
Failed --> Cleanup: 回收资源
Aborted --> Cleanup: 回收资源
Cleanup --> [*]: 沙箱销毁
关键设计推演:
- 创建阶段:API 调用触发沙箱分配(Firecracker microVM 启动 ~125ms),加载预配置的 Skills 和环境变量
- 执行循环:遵循经典的 ReAct(Reasoning + Acting)模式——思考 → 生成动作 → 执行 → 观察结果 → 继续思考
- 确认机制:高风险操作(删除文件、发送邮件、支付)触发确认等待,Google 可能维护了一个"操作风险等级表"
- 故障恢复:Agent 应该有检查点(checkpoint)机制——如果中途中断,可以从上一个检查点恢复,而不是从头开始
- 资源回收:任务完成后沙箱被销毁,文件系统清空,审计日志归档
技能注册机制和自定义 Skills
Skill 注册结构(推演):
{
"skill_id": "web-scraper",
"name": "Web Scraper",
"description": "Extract structured data from web pages",
"runtime": "python", // 执行环境
"entry_point": "scraper.py", // 入口文件
"permissions": [ // 所需权限
"network.outbound.https",
"filesystem.read",
"filesystem.write.temp"
],
"dependencies": [ // 依赖包
"beautifulsoup4",
"requests"
],
"input_schema": { ... }, // 输入参数 schema
"output_schema": { ... } // 输出参数 schema
}
自定义 Skills 的实现方式(推演):
- 声明式注册——通过 YAML/JSON 配置文件声明 Skill 的元数据、权限需求和依赖
- 代码上传——将 Skill 代码打包上传到 Agent 的环境中
- 运行时加载——Agent 在执行时根据任务需要动态加载对应的 Skill
- 权限控制——每个 Skill 有独立的权限声明,沙箱在执行时按权限白名单控制
单 Agent vs 多 Agent 协作编排策略
graph TB
subgraph "单 Agent 模式"
SA_TASK["任务"] --> SA_AGENT["Agent<br/>+ 全部 Skills"]
SA_AGENT --> SA_RESULT["结果"]
end
subgraph "多 Agent 编排模式"
MA_TASK["复杂任务"] --> MA_ORCH["Orchestrator<br/>任务分解 + 分配"]
MA_ORCH --> MA_A1["Agent 1<br/>编码"]
MA_ORCH --> MA_A2["Agent 2<br/>测试"]
MA_ORCH --> MA_A3["Agent 3<br/>文档"]
MA_A1 -->|代码| MA_A2
MA_A2 -->|测试结果| MA_A1
MA_A1 --> MA_ORCH
MA_A2 --> MA_ORCH
MA_A3 --> MA_ORCH
MA_ORCH --> MA_RESULT["整合结果"]
end
编排策略选择(推演):
| 策略 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| 单 Agent | 简单任务、线性流程 | 简单、低延迟、低成本 | 无法并行、复杂任务容易迷失 |
| 主从编排 | 可分解的子任务 | 并行加速、任务清晰 | 通信开销、上下文共享困难 |
| 管道编排 | 有依赖关系的步骤 | 自然的依赖管理 | 无法并行、单点瓶颈 |
| 对等协作 | 探索性任务 | 灵活、自组织 | 难以控制、可能循环依赖 |
🔬 93 个 Agent 构建操作系统的 Demo 技术拆解
这是本次 I/O 最具话题性的 demo。让我们深度拆解其技术含义。
消耗分析
| 指标 | 数值 | 推算 |
|---|---|---|
| Agent 数量 | 93 | 官方数据 |
| 总 Token 消耗 | 26 亿(2.6B) | 官方数据 |
| 总模型请求 | 15,000+ | 官方数据 |
| 总耗时 | 12 小时 | 官方数据 |
| 每 Agent 平均 Token | ~2800 万 | 2.6B ÷ 93 |
| 每 Agent 平均请求 | ~161 次 | 15,000 ÷ 93 |
| 每请求平均 Token | ~17.3 万 | 2.6B ÷ 15,000 |
| 每请求平均耗时 | ~2.88 秒 | 12h ÷ 15,000 |
每 Agent 2800 万 token 的含义:
- 如果按 Gemini 3.5 Flash 的 $1.50/$9.00 定价(假设输入/输出各半),每 Agent 的 Token 成本约 $126(输入 14M × $1.50/M + 输出 14M × $9.00/M)
- 93 个 Agent 总成本约 $11,718
- 但如果使用 Thinking Token(medium 级别),实际成本可能翻 3-5x,达到 $35,000-60,000
- 如果按批量折扣和内部定价,实际成本可能远低于此
并行度分析
gantt
title 93 Agent OS 构建 Demo 调度推演
dateFormat X
axisFormat %H
section 阶段1: 架构设计
Master Agent 架构规划 :a1, 0, 3600
子系统划分 :a2, 3600, 7200
section 阶段2: 核心模块 (并行)
内核 Agent (×5) :b1, 7200, 18000
驱动 Agent (×8) :b2, 7200, 21600
文件系统 Agent (×6) :b3, 7200, 25200
内存管理 Agent (×4) :b4, 7200, 18000
section 阶段3: 用户空间 (并行)
Shell Agent (×3) :c1, 18000, 28800
工具链 Agent (×10) :c2, 18000, 32400
UI Agent (×8) :c3, 21600, 36000
网络栈 Agent (×6) :c4, 18000, 32400
section 阶段4: 集成测试
集成 Agent (×15) :d1, 32400, 39600
测试 Agent (×20) :d2, 36000, 43200
section 阶段5: 调试修复
修复 Agent (×8) :e1, 39600, 43200
并行度推演:
93 个 Agent 不可能全部并行——存在明确的依赖关系。推演的并行度分布:
| 阶段 | Agent 数 | 并行度 | 依赖关系 |
|---|---|---|---|
| 架构设计 | 1-3 | 串行 | 无(起始点) |
| 核心模块开发 | 20-25 | ~20 并行 | 依赖架构设计完成 |
| 用户空间开发 | 25-30 | ~25 并行 | 部分依赖核心模块 |
| 集成测试 | 15-20 | ~15 并行 | 依赖开发完成 |
| 调试修复 | 8-10 | ~8 并行 | 依赖测试结果 |
| 最大并行度 | ~25-30 |
与人类开发者工作量对比:
| 维度 | 93 Agent Demo | 等效人类团队 |
|---|---|---|
| 时间 | 12 小时 | 6-12 个月(10 人团队) |
| 人力 | 93 Agent × 12h = 1,116 Agent-hours | 10 人 × 1,600h = 16,000 人时 |
| 成本(Token) | ~$12,000-60,000 | ~$800K-1.6M(含工资+设施) |
| 成本效率 | 13-130x 成本优势 | |
| 代码质量 | Demo 级别(可能无法生产使用) | 生产级别 |
关键洞察: 这个 Demo 的真正价值不在于"AI 替代了 10 个程序员",而在于展示了多 Agent 协作的编排模式——93 个 Agent 如何被分解、调度、通信和合并。这是 Agent 基础设施能力的展示,不是代码生成能力的展示。
3.2 Gemini Spark —— 24/7 个人 Agent
本次 I/O 消费端最激进的发布。
核心概念:
- 你有一个专属 Gmail 地址,像给同事发邮件一样给 Spark 布置任务
- Spark 运行在 Google Cloud 专用虚拟机 上,24/7 在线
- 原生集成 Gmail、Calendar、Drive、Docs、Chrome 浏览
- 设备关机也能继续工作
- 执行重大操作前会请求你的确认
典型场景:
- "帮我监控这三个新闻源的更新,每天早上发一个摘要"
- "研究所有 2027 款电动 SUV 的对比评测,给我一个表格"
- "帮我安排下周所有会议,避开已有日程"
可用性: AI Ultra 订阅用户($200/月)下周开始
行业解读: Google 基本上跳过了 chatbot 时代,直接进入 persistent personal agent 时代。Spark 的存在意味着 Google 认为聊天窗口不是 AI 的最终形态——后台运行的、有邮箱地址的、能浏览网页的 Agent 才是。
🔬 深度技术分析:Gemini Spark 全拆解
Spark 24/7 Agent 工作流
graph LR
subgraph "用户接口 User Interface"
EMAIL["Gmail<br/>任务邮件"]
VOICE["Gemini Voice<br/>语音指令"]
APP["Gemini App<br/>对话接口"]
end
subgraph "Spark 引擎 Spark Engine"
PARSER["任务解析器<br/>Intent + Entity Extraction"]
QUEUE["任务队列<br/>优先级 + 调度"]
EXECUTOR["执行引擎<br/>Antigravity Runtime"]
NOTIFIER["通知引擎<br/>Email / Push"]
end
subgraph "Google Workspace 集成"
G_GMAIL["Gmail API<br/>读写邮件"]
G_CAL["Calendar API<br/>日程管理"]
G_DRIVE["Drive API<br/>文件操作"]
G_DOCS["Docs API<br/>文档编辑"]
G_CHROME["Chrome<br/>Autobrowse<br/>网页操作"]
end
subgraph "安全层 Security"
CONFIRM["确认机制<br/>高风险操作"]
AUDIT_S["审计日志"]
ISOLATION["数据隔离"]
end
EMAIL --> PARSER
VOICE --> PARSER
APP --> PARSER
PARSER --> QUEUE
QUEUE --> EXECUTOR
EXECUTOR --> G_GMAIL
EXECUTOR --> G_CAL
EXECUTOR --> G_DRIVE
EXECUTOR --> G_DOCS
EXECUTOR --> G_CHROME
EXECUTOR --> CONFIRM
CONFIRM -->|批准| EXECUTOR
CONFIRM --> NOTIFIER
G_GMAIL --> AUDIT_S
G_CAL --> AUDIT_S
EXECUTOR --> ISOLATION
持久化 Agent 的状态管理机制
Spark 作为 24/7 持久化 Agent,其状态管理是核心技术挑战:
| 状态类型 | 存储方式 | 生命周期 | 推演 |
|---|---|---|---|
| 任务队列 | Google Cloud Firestore/Spanner | 持久,直到任务完成或取消 | 需要支持优先级、依赖关系和定时触发 |
| 执行上下文 | Gemini Thought Preservation | 跨会话保持 | 通过跨轮次思维链保持任务连贯性 |
| 用户偏好 | 用户 Profile 存储 | 长期持久 | 逐步学习用户的习惯、风格和偏好 |
| 临时工作文件 | Google Drive 临时文件夹 | 任务期间存在 | 研究报告、表格草稿等中间产物 |
| 浏览器状态 | Headless Chrome Session | 任务期间保持 | 保持登录态、Cookie、浏览历史 |
| 通知状态 | Gmail/推送队列 | 即时消费 | 任务完成通知、确认请求等 |
权限模型:确认机制的边界条件
这是 Spark 安全设计中最关键的问题。基于 Google 的公开描述和行业实践,推演如下:
| 操作类型 | 风险等级 | 是否需要确认 | 推演理由 |
|---|---|---|---|
| 读取邮件 | 低 | ❌ 自动执行 | 只读操作,风险可控 |
| 搜索网页 | 低 | ❌ 自动执行 | 公开信息,无副作用 |
| 生成文档草稿 | 低 | ❌ 自动执行 | 草稿可以人工审核 |
| 发送日历邀请 | 中 | ⚠️ 可能需要 | 涉及第三方,但可撤销 |
| 发送邮件 | 中-高 | ✅ 大概率需要 | 不可撤销,代表用户身份 |
| 修改现有文档 | 中 | ⚠️ 可能需要 | 可通过版本历史恢复 |
| 删除文件/邮件 | 高 | ✅ 需要确认 | 不可逆操作 |
| 支付/购买 | 极高 | ✅ 必须确认 | 财务风险 |
| 修改系统设置 | 极高 | ✅ 必须确认 | 安全风险 |
确认机制的"黄金区间"问题:
- 如果确认太少 → 用户不信任,不敢用
- 如果确认太多 → 摩擦太大,用户放弃使用
- Google 的最优策略可能是自适应确认——初期更保守(多确认),随着模型学习用户偏好逐渐放宽
与 Google Workspace 集成架构
sequenceDiagram
participant User as 用户
participant Spark as Spark Engine
participant Gmail as Gmail API
participant Calendar as Calendar API
participant Drive as Drive API
participant Chrome as Chrome Autobrowse
participant Gemini as Gemini 3.5 Flash
User->>Spark: 发邮件 "帮我安排下周会议"
Spark->>Gemini: 解析任务意图
Gemini-->>Spark: 任务拆解:1.查看日程 2.联系参会者 3.创建邀请
loop 查看已有日程
Spark->>Calendar: 获取下周日程
Calendar-->>Spark: 返回日程数据
end
loop 搜索可用时间
Spark->>Gmail: 检查相关邮件线程
Gmail-->>Spark: 返回邮件内容
end
Spark->>Gemini: 综合分析 + 生成会议方案
Gemini-->>Spark: 会议方案(3个选项)
Spark->>User: 推送确认请求
User->>Spark: 确认方案A
Spark->>Calendar: 创建会议邀请
Calendar-->>Spark: 创建成功
Spark->>Gmail: 发送邀请邮件
Gmail-->>Spark: 发送成功
Spark->>User: 通知完成
竞品对比:Spark vs OpenAI Operator vs Anthropic Computer Use
| 维度 | Google Spark | OpenAI Operator | Anthropic Computer Use |
|---|---|---|---|
| 运行模式 | 24/7 持久化,后台运行 | 按需会话式 | 按需会话式 |
| 任务接口 | 邮件 + 语音 + App | 聊天窗口 | 聊天窗口 |
| 执行环境 | Google Cloud VM | 沙箱浏览器 | 沙箱桌面 |
| 生态集成 | Gmail/Calendar/Drive/Docs/Chrome | Web 操作为主 | 桌面应用操作 |
| 状态持久化 | ✅ 跨会话 | ❌ 会话内 | ❌ 会话内 |
| 离线执行 | ✅ 设备关机继续 | ❌ 需在线 | ❌ 需在线 |
| 确认机制 | 自适应(推演) | 明确确认 | 明确确认 |
| 定价 | $200/月(含在 Ultra) | 含在 ChatGPT Pro | 含在 Max 订阅 |
| 成熟度 | 首发预览 | 已发布迭代 | 已发布迭代 |
| 核心优势 | 持久化 + 生态集成 | Web 交互能力强 | 桌面操作能力强 |
| 核心劣势 | Google 生态锁定 | 无持久化能力 | 无持久化能力 |
关键洞察: Spark 的持久化能力是其最大的差异化优势。Operator 和 Computer Use 都是"你问我做"的请求-响应模式,而 Spark 是"你托我盯"的委托-监控模式。这是 Agent 范式的本质差异。
🔬 Agent 安全与信任分析
Spark/Antigravity 的安全边界设计
| 安全维度 | Antigravity | Spark | 分析 |
|---|---|---|---|
| 执行环境 | 托管 Linux 沙箱 | Google Cloud VM | Antigravity 更严格(沙箱),Spark 更宽松(VM) |
| 网络访问 | 受限(推演:白名单) | 完整浏览器访问 | Spark 需要浏览网页,攻击面更大 |
| 数据范围 | 用户上传的代码/文件 | 用户全部 Workspace 数据 | Spark 接触面远大于 Antigravity |
| 操作权限 | 代码执行 + 文件操作 | 邮件/日历/文档/浏览 | Spark 权限更广泛,风险更高 |
| 审计能力 | 完整操作日志(推演) | 完整操作日志(推演) | 两者都需要强审计 |
与传统应用权限模型的本质区别
| 维度 | 传统应用 | AI Agent |
|---|---|---|
| 权限粒度 | API 级别(读/写) | 任务级别(自主决策) |
| 操作可预测性 | 高(确定性代码路径) | 低(模型推理驱动) |
| 错误模式 | Bug/崩溃 | 幻觉/误解/过度执行 |
| 责任归属 | 明确(开发者) | 模糊(模型 + 开发者 + 用户) |
| 审计复杂度 | 低(日志结构化) | 高(需理解模型推理链) |
| 修复方式 | 代码修复 | Prompt 调整 + 系统约束 |
核心挑战: 传统应用的权限模型是"白名单"——应用只能做被授权的事。AI Agent 的权限模型更像是"灰名单"——Agent 可以做授权范围内的事,但"范围"本身是由模型推理动态定义的,而不是静态代码决定的。这使得传统的安全审计方法(权限审查、渗透测试)变得不够用。
四、Search:从检索引擎到 Agent 监控平台

4.1 AI Mode 规模化
- AI Mode 已有 10 亿月活,查询量每季度翻倍
- 重新设计的搜索框,支持多模态输入
- Generative UI:搜索可以根据你的查询动态生成可视化工具和模拟器(利用 Antigravity + Gemini 3.5 Flash)
这是 Search 体验的一次本质变化——搜索不再只是返回蓝色链接或 AI 摘要,而是直接在你的查询场景中生成可交互的工具。例如搜索"比较两款相机的参数",Search 会动态生成一个交互式对比工具,而不只是展示文字。
4.2 Information Agents
- 持久监控任务:设定后持续追踪 web/新闻/社交媒体/实时信号
- 综合更新:附带链接和可执行操作
- 今年夏天对 Pro/Ultra 用户开放
战略转变: Search 从「你问,我答」变成「你设,我盯」。检索/排名退居底层,Agent 监控 + 生成的应用小程序成为新的用户界面。这对整个 SEO 行业和内容生态的影响将是深远的。
4.3 Ask YouTube
Google 还展示了 Ask YouTube 功能,允许用户以对话方式直接查询 YouTube 视频内容,获得基于视频内容本身的回答,而不仅仅是搜索视频标题和描述。
🔬 深度技术分析:Search 范式转移
Search 架构演进
graph TB
subgraph "Search 1.0(1998-2023)<br/>检索引擎"
S1_CRAWL["爬虫<br/>Web Index"]
S1_RANK["PageRank + ML 排序"]
S1_RESULT["蓝色链接<br/>10 条结果"]
end
subgraph "Search 2.0(2023-2025)<br/>AI 摘要引擎"
S2_CRAWL["爬虫 + 实时索引"]
S2_RAG["RAG<br/>检索 + 生成"]
S2_RESULT["AI Overview<br/>摘要 + 来源链接"]
end
subgraph "Search 3.0(2026-)<br/>Agent 监控平台"
S3_AGENT["Information Agents<br/>持久监控"]
S3_GENUI["Generative UI<br/>动态交互工具"]
S3_RESULT["定制化信息流<br/>+ 交互工具"]
end
S1_CRAWL --> S1_RANK --> S1_RESULT
S2_CRAWL --> S2_RAG --> S2_RESULT
S3_AGENT --> S3_GENUI --> S3_RESULT
Generative UI 技术实现推演
"搜索根据查询动态生成可交互的工具"——这在技术上如何实现?
sequenceDiagram
participant User as 用户
participant Search as Search AI Mode
participant Agent as Antigravity Agent
participant GenUI as Generative UI Engine
participant Render as 前端渲染
User->>Search: "比较 Sony A7IV 和 Canon R6II"
Search->>Agent: 解析意图 → 对比工具需求
Agent->>Agent: 调用 Gemini 3.5 Flash<br/>提取参数 + 生成 UI 描述
Agent->>GenUI: UI 规格描述<br/>(结构化 JSON)
GenUI->>GenUI: 安全沙箱生成<br/>React/Svelte 组件
GenUI->>Render: 编译后的 UI 组件
Render->>User: 渲染交互式对比工具
User->>Render: 拖动滑块调整 ISO
Render->>Agent: 参数变更请求
Agent->>Agent: 重新计算对比结果
Agent->>Render: 更新数据
技术实现推演:
- 意图识别 + UI Schema 生成——Gemini 3.5 Flash 理解查询意图后,生成一个结构化的 UI Schema(可能基于 JSON Schema 或类似的 DSL),描述需要的组件类型(表格、图表、滑块等)和数据绑定关系。
- 组件生成沙箱——Antigravity Agent 在沙箱中根据 Schema 生成前端组件代码(可能是 React/Web Components),经过安全审计后编译为可执行代码。
- 安全渲染——生成的 UI 组件在沙箱化的 iframe 或 Web Worker 中渲染,限制其对 DOM 和网络的访问。
- 交互循环——用户的交互操作触发新的 Agent 请求,Agent 返回更新数据,UI 实时更新。
SEO 的影响:
- 传统 SEO 衰退:如果 Search 不再返回蓝色链接,排名优化的价值断崖式下降
- Agent SEO 新赛道:优化内容以便 Agent 检索和引用成为新的优化方向
- 结构化数据更重要:Agent 更容易从结构化数据中提取信息
- 广告模式重构:蓝色链接旁边的广告位消失,广告需要融入 Generative UI
五、Android 17 + Gemini Intelligence
5.1 Gemini Intelligence:从 OS 到 Intelligence System
Google 将 Gemini Intelligence 定义为 Android 的下一层进化——不只是预装一个 AI 助手,而是让 AI 成为操作系统的核心调度层。
关键能力:
| 功能 | 说明 |
|---|---|
| 智能日程管理 | AI 理解你的习惯和偏好,主动提议日程安排 |
| 跨应用自动填充 | 从 Gmail / Drive / Calendar 等提取数据,自动填充文档和表单 |
| AI 生成 Widget | 用自然语言描述想要的桌面 Widget,系统自动生成 |
| 屏幕自动化 (Screen Automation) | Gemini 可以操作屏幕上的 UI 元素,完成多步任务 |
| Chrome Autobrowse | 在 Chrome 中自动浏览、填表、提取信息 |
| 语音转文字增强 | AI 自动去除"嗯""啊",输出干净文本 |
5.2 Android 17 界面和生态更新
- Material 3 Expressive 设计语言全面铺开:更富表现力的字体和更流畅的动画
- Google Maps 边到边全屏:沉浸式导航体验
- Instagram Edits Smart Enhance:设备端 AI 图片/视频增强(与 Meta 合作)
- Adobe Premiere 登陆 Android:含 YouTube Shorts 专用模板和效果
- 实时威胁检测:系统级安全增强
5.3 设备覆盖和发布节奏
Gemini Intelligence 将覆盖手机、手表、车载、眼镜、笔记本电脑——Google 在构建一个 Gemini 覆盖所有屏幕的统一体验层。
- 首批设备:今年夏天,Samsung Galaxy 和 Google Pixel
- 后续扩展到其他 OEM 和设备类型
🔬 深度技术分析:Gemini Intelligence 系统架构
Gemini Intelligence 在 Android 中的系统架构
graph TB
subgraph "应用层 Applications"
APP_3RD["第三方应用"]
APP_GOOGLE["Google 应用<br/>Gmail/Maps/Chrome/..."]
APP_SYSTEM["系统应用<br/>设置/电话/消息"]
end
subgraph "Gemini Intelligence Layer"
GI_API["Gemini API<br/>开发者接口"]
GI_SERVICE["Gemini System Service<br/>核心调度服务"]
GI_ONDEVICE["设备端模型<br/>Gemini Nano"]
GI_CLOUD["云端模型<br/>Gemini 3.5 Flash"]
GI_AGENT["Agent Runtime<br/>任务编排引擎"]
end
subgraph "系统能力 System Capabilities"
SCREEN_READ["屏幕理解<br/>UI Element Tree"]
ACTION_EXEC["动作执行<br/>Accessibility API"]
NOTIF_CTRL["通知管理"]
WIDGET_GEN["Widget 生成引擎"]
AUTO_FILL["智能填充"]
end
subgraph "Android Framework"
FRAMEWORK["Android 17 Framework<br/>Activity Manager / Window Manager"]
LINUX_KERNEL["Linux Kernel"]
end
APP_3RD --> GI_API
APP_GOOGLE --> GI_SERVICE
APP_SYSTEM --> GI_SERVICE
GI_API --> GI_SERVICE
GI_SERVICE --> GI_ONDEVICE
GI_SERVICE --> GI_CLOUD
GI_SERVICE --> GI_AGENT
GI_AGENT --> SCREEN_READ
GI_AGENT --> ACTION_EXEC
GI_AGENT --> NOTIF_CTRL
GI_AGENT --> WIDGET_GEN
GI_AGENT --> AUTO_FILL
SCREEN_READ --> FRAMEWORK
ACTION_EXEC --> FRAMEWORK
NOTIF_CTRL --> FRAMEWORK
WIDGET_GEN --> FRAMEWORK
AUTO_FILL --> FRAMEWORK
FRAMEWORK --> LINUX_KERNEL
关键架构推演:
- Gemini System Service——这是 Android 中的一个系统级服务(类似于 SystemUI 或 ActivityManager),运行在独立进程中,拥有系统级权限。它接收来自各应用的 AI 请求,并调度到设备端模型(Nano)或云端模型(Flash)。
- 屏幕自动化的技术基础——Screen Automation 依赖 Android 的 Accessibility Service API。Gemini 通过这个 API 获取屏幕上所有 UI 元素的语义树(类似 DOM),然后用模型推理决定点击/滑动/输入等操作。这与 Anthropic 的 Computer Use 概念类似,但底层实现更结构化(基于 UI 树而非视觉像素)。
- 设备端 + 云端混合——简单任务(语音转文字、自动填充)使用设备端 Gemini Nano,复杂任务(日程管理、信息研究)使用云端 Gemini 3.5 Flash。这种混合策略在延迟和成本之间取得平衡。
- 隐私挑战——Screen Automation 意味着 Gemini 可以"看到"用户屏幕上的所有内容,包括密码、银行信息、私人消息。Google 必须有非常严格的隔离机制来防止这些数据被发送到云端或用于训练。
六、Googlebook —— 全新产品品类

定位: 从零开始为 Gemini Intelligence 设计的笔记本电脑——Chromebook 的精神继任者,但更高定位。
架构:
- 基于 Android 技术栈 + ChromeOS 世界级浏览器体验
- Gemini Intelligence 作为连接层贯穿每个交互
- 不是取代 Chromebook,而是一个全新的高端品类
- Google 明确说这是一个"intelligence system"而不是传统 OS
核心特性:
| 特性 | 说明 |
|---|---|
| Magic Pointer | AI 光标,理解上下文并提供智能建议 |
| 自定义 Widget | 用 prompt 描述需求,系统生成桌面 Widget |
| Cast My Apps | 手机应用无缝投射到桌面运行 |
| Glowbar | 硬件特色设计元素 |
| 无缝文件同步 | 手机和笔记本间自动同步 |
| 快速特性迁移 | 因为基于 Android,手机特性可以更快带到笔记本上 |
意义: Google 终于找到了一个把 Android 带入笔记本的可信路径。这不再是 Android 桌面模式那种生硬的移植,而是 Gemini 优先、Android 技术栈驱动、ChromeOS 浏览器优势保留的全新计算范式。
隐含信息: Google 没有明确说 OS 就是"Android",而是说"Android 和周围的所有技术是其重要组成部分"——这暗示 Googlebook 可能是 Android 和 ChromeOS 的混合体,或者说是两条技术栈的融合起点。
🔬 深度技术分析:Googlebook 技术栈
Googlebook 技术栈架构(Android + ChromeOS 融合)
graph TB
subgraph "用户交互层"
MAGIC_PTR["Magic Pointer<br/>AI 光标"]
WIDGET_G["AI 生成 Widget"]
GLOWBAR["Glowbar<br/>硬件交互"]
end
subgraph "Gemini Intelligence Layer"
GI_DESKTOP["Gemini Desktop Service<br/>笔记本优化版"]
GI_AGENT_D["Desktop Agent Runtime<br/>桌面任务编排"]
end
subgraph "融合 OS 层 Fusion OS"
ANDROID_RUNTIME["Android Runtime<br/>ART + App 兼容层"]
CHROME_RUNTIME["Chrome Runtime<br/>浏览器引擎"]
CAST_ENGINE["Cast My Apps<br/>手机应用投射引擎"]
FILE_SYNC["文件同步引擎<br/>手机 ↔ 笔记本"]
end
subgraph "Linux 内核层"
KERNEL["Linux Kernel<br/>桌面优化配置"]
DRIVER["硬件驱动<br/>笔记本外设"]
GPU_ACCEL["GPU 加速<br/>AI 推理"]
end
MAGIC_PTR --> GI_DESKTOP
WIDGET_G --> GI_DESKTOP
GI_DESKTOP --> GI_AGENT_D
GI_AGENT_D --> ANDROID_RUNTIME
GI_AGENT_D --> CHROME_RUNTIME
CAST_ENGINE --> ANDROID_RUNTIME
FILE_SYNC --> KERNEL
ANDROID_RUNTIME --> KERNEL
CHROME_RUNTIME --> KERNEL
KERNEL --> DRIVER
KERNEL --> GPU_ACCEL
技术融合推演:
Googlebook 的 OS 不是简单的"Android 桌面版"或"ChromeOS + Android 应用",而是一个融合体:
- Android Runtime 提供 App 兼容性——Googlebook 可以运行所有 Android 应用,Cast My Apps 更是让手机应用无缝投射到桌面。这是 ChromeOS 的 Android 兼容层从未达到的体验。
- Chrome Runtime 提供浏览器体验——ChromeOS 的浏览器优势(性能、Web 兼容性、扩展生态)被保留。这是纯 Android 桌面模式缺失的。
- Gemini Intelligence 作为统一交互层——Magic Pointer、AI Widget 等不是独立功能,而是 Gemini Intelligence 在桌面环境的自然延伸。这意味着 Googlebook 的每个交互都可能有 AI 参与。
- 硬件 AI 加速——考虑到 Googlebook 的定位,很可能搭载 NPU/TPU 芯片用于设备端 AI 推理,支持部分 Gemini Intelligence 功能的离线运行。
战略意义: Googlebook 是 Google 对 "AI PC" 赛道的回答——不是在传统 PC 上堆 AI 功能(微软 Copilot+ PC),而是从 AI 原生出发重新设计计算设备。风险在于:市场是否准备好了接受一个全新的 OS 生态。
七、Android XR 智能眼镜

最接近消费者现实的一次智能眼镜发布。
7.1 产品形态
- 两个设计合作伙伴:
- Gentle Monster(时尚前卫路线)
- Warby Parker(日常可穿戴路线)
- 硬件合作:Samsung(负责工程制造)
- 兼容性: Android + iOS
- 定位: 手机的伴侣设备(通过蓝牙/WiFi 连接手机处理计算密集型任务)
7.2 功能
- 实时语音导航(Google Maps + Gemini)
- 通知推送
- 实时语音/文字翻译
- Gemini 语音控制
- 免手拍照
7.3 I/O 现场Demo
- 通过语音导航步行路线
- 用 Gemini + DoorDash 免手点咖啡
- AI 文本摘要和日历更新
- 全程不需要掏出手机
7.4 评价

比之前所有 Google 眼镜尝试都更像可能出现在街上的产品。关键改变有三点:
- 不自己做硬件设计了,交给 Gentle Monster 和 Warby Parker——让专业的人做专业的事
- 伴侣设备定位而非独立计算设备——降低了重量、功耗和价格的门槛
- Gemini 全天集成——不是 AR 显示屏,而是 AI 语音助手 + 必要时的轻量视觉反馈
发售时间: 今年秋天。价格和详细规格尚未公布。
八、开发者工具 & Cloud
8.1 开发者工具全景
| 工具 | 说明 |
|---|---|
| Antigravity Desktop | Agent-first 桌面 IDE,核心对话 + Artifacts + 多 Agent 编排 |
| Antigravity CLI | 命令行版 Agent 执行环境 |
| Antigravity SDK | 面向开发者的 Agent 开发包 |
| Managed Agents API | 单 API 调用创建托管 Agent,Google 托管 Linux 沙箱 |
| Gemini API 升级 | 支持 3.5 Flash + Omni,thought preservation |
| AI Studio → Antigravity | 一键导出 Prompt 为 Agent |
| AI Studio Android | 原生 Android 应用生成 |
| Firebase 集成 | Agent 开发全链路 |
8.2 Managed Agents API 技术细节
这是面向企业开发者的关键发布:
- 单次 API 调用即可创建一个自定义 Agent
- Agent 运行在 Google 托管的安全远程环境中
- 支持 Bash / Python / Node 执行
- 支持文件操作、网页浏览、自定义 Skills
- 内置安全沙箱和审计日志
8.3 Google Cloud
- Gemini Enterprise Agent Platform:企业级 Agent 开发平台
- Agentic Data Cloud:为 Agent 场景设计的数据基础设施
- AI Content Detection API:AI 生成内容检测,即日可用
- TPU 第八代(Ironwood):此前已在 Cloud Next '26 公布
- Gemini 3.5 Flash 即日可在 Agent Platform 上使用
- Workspace Intelligence:企业 Workspace 的 AI 层升级
九、安全、内容溯源与定价
9.1 SynthID 全栈扩展
- SynthID 标记扩展到 Search、Gemini、Chrome、硬件/媒体全栈
- 跨行业合作:Google 联合 OpenAI、NVIDIA、Kakao、ElevenLabs 推广 SynthID 标准
- 新的 AI Content Detection API 供企业使用
容易被低估的信号: Google 在推动 SynthID 成为行业标准。如果成功,Google 将在 AI 内容溯源领域获得规则制定权——这在监管日益收紧的环境下是一个巨大的战略资产。
9.2 定价策略调整
| 档位 | 月费 | 说明 |
|---|---|---|
| AI Free | $0 | 基础 Gemini 使用 |
| AI+ | 新增 $100/月 | 面向进阶用户 |
| AI Ultra | $200/月(从 $250 降价) | 含 Spark、Omni、最高级模型 |
| Gemini API | 按量付费 | Flash: $1.50/$9.00 per M tokens |
策略解读: Google 在用更激进的定价争夺高端用户(开发者 + 创作者),同时通过 Ultra 降价扩大用户基数。$100 档的引入填补了免费和 $200 之间的空白。
🔬 深度技术分析:定价策略与商业模式
定价策略 vs 竞争对手对比
graph LR
subgraph "Google"
G_FREE["AI Free<br/>$0/月"]
G_PLUS["AI+<br/>$100/月"]
G_ULTRA["AI Ultra<br/>$200/月<br/>含 Spark + Omni"]
end
subgraph "OpenAI"
O_FREE["Free<br/>$0/月"]
O_PLUS["Plus<br/>$20/月"]
O_PRO["Pro<br/>$200/月<br/>含 Operator"]
end
subgraph "Anthropic"
A_FREE["Free<br/>$0/月"]
A_PRO["Pro<br/>$20/月"]
A_MAX["Max<br/>$100-200/月<br/>含 Computer Use"]
end
G_FREE -.->|"竞争"| O_FREE
G_PLUS -.->|"竞争"| O_PRO
G_ULTRA -.->|"竞争"| O_PRO
定价策略深度分析:
| 维度 | OpenAI | Anthropic | |
|---|---|---|---|
| 免费层 | Gemini App 基础功能 | ChatGPT 基础 | Claude 基础 |
| 中端 | AI+ $100/月(新) | Plus $20/月 | Pro $20/月 |
| 高端 | Ultra $200/月 | Pro $200/月 | Max $100-200/月 |
| API 定价 | Flash $1.50/$9.00/M | GPT-5.5 ~$5/$15/M | Sonnet 4 ~$3/$15/M |
| 核心差异 | Spark 持久化 Agent | Operator Web Agent | Computer Use 桌面Agent |
| 硬件捆绑 | Googlebook/XR 眼镜 | 无 | 无 |
| 搜索捆绑 | AI Mode 10亿+ | SearchGPT | 无 |
$200/月 Ultra 的 ARPU 分析:
| 项目 | 估算 |
|---|---|
| Ultra 订阅收入 | $200/月/用户 |
| Spark 运行成本(VM + Token) | $30-80/月/用户(推演) |
| Omni/Veo 使用成本 | $10-30/月/用户(推演) |
| 毛利率 | ~50-70% |
| 年 ARPU | $2,400 |
| 目标用户数(估算) | 50-100 万(第一年) |
| 年收入贡献 | $12-24 亿 |
十、其他值得关注的产品更新
10.1 Gemini App 消费端
- "Neural Expressive" 设计语言:全新的视觉体系
- Gemini Live Voice:inline/instant 语音对话,无需等待
- Daily Brief:个性化每日摘要,整合邮箱/日历/任务
- macOS App:桌面端原生应用
- Spark + Voice Desktop 工作流:即将推出
10.2 Workspace
- Gemini Intelligence 深度集成到 Gmail、Docs、Sheets、Slides
- Agent 驱动的自动化工作流
10.3 Project Genie + Street View

- 用 AI 模拟真实世界的地点和场景
- 基于 Street View 数据的交互式世界构建
10.4 Gemini for Science
- 新的科学工具和实验集合
- 扩展科学探索的规模和精度
10.5 SIMA 2
- AI Agent 可以在虚拟 3D 世界中游玩、推理和学习
十一、整体判断
Google 在做什么?——全栈飞轮闭环
每一层同步推进,互相强化。单独看任何发布都是增量的,放在一起看是结构性的。
Business Engineer 的分析很精准:"Read any single announcement in isolation, and it is incremental. Read them together, and you see something structural: the full-stack flywheel completing its first revolution."
Google 的优势
- 分发优势:13 个 10 亿+ 用户的产品,Gemini 覆盖 230+ 国家 70+ 语言
- 基础设施:3.2Q tokens/month 的运行经验 + TPU 自研,850 万开发者
- 多模态整合:Omni 把理解、生成、编辑、世界建模统一了,竞争对手目前没有对等方案
- Agent 基座:Antigravity 比"套壳聊天"深了几个数量级——从 IDE 到 CLI 到 SDK 到托管平台,全链路
- 硬件品类扩展:Googlebook + XR 眼镜同时在两个方向(笔记本和穿戴)布局
风险和疑虑
- 产品命名混乱:Gemini CLI vs Antigravity CLI,Flash 越来越贵却还叫 Flash——普通用户甚至开发者都困惑
- 价格通胀:Flash 运行成本是前代 5.5x,Artificial Analysis 明确指出性价比不如预期,Flash 标签正在失去其原始含义
- Benchmark 自报:Google 自测数据太漂亮,第三方结论更审慎。部分 benchmark(MRCR、ARC-AGI-2、TerminalBench-Hard)表现并不突出
- Agent 安全与信任:Spark 可以发邮件、浏览网页、操作日历——权限边界在哪?出错谁负责?Google 说"重大操作前会请求确认",但定义和执行细节不明
- 新品类风险:Googlebook 和 XR 眼镜都是新品类,消费者接受度未知。Google 的硬件历史(Nest、Stadia、Glass)并不让人完全放心
- 锁定风险:企业将业务逻辑构建在 Antigravity / Managed Agents 上后,迁移成本会很高
对行业的信号
- Agent 是主战场,聊天模型只是过渡态。Google、OpenAI、Anthropic 都在朝这个方向走,但 Google 的全栈布局最完整
- 视频生成进入实用阶段——Omni + Veo 3.1 + Flow 构成从创意到成品的完整创作链,10 秒带音频的视频生成已经是可用产品
- 智能眼镜可能是下一个终端——Google 选择和时尚品牌合作而非自己做硬件,是正确的姿态。Meta Ray-Ban 已经验证了需求
- AI 正在成为文明级基础设施——3200万亿 token/月的规模意味着 AI 已经不是"功能",而是像电力一样的底层服务
- Search 的范式转移:从检索到监控 + 生成,SEO 行业和内容生态将面临深层重构
- 个人 Agent 的商业化元年:Spark 的 $200/月定价意味着 Google 认为足够多的人愿意为 24/7 AI 助手付费
十二、竞争格局深度分析
🔬 Google vs OpenAI vs Anthropic 全栈能力对比
graph TB
subgraph "全栈能力对比"
direction TB
subgraph "Google — 全栈最完整"
G_MODEL["✅ 顶级模型<br/>Gemini 3.5 Flash/Pro"]
G_SEARCH["✅ 搜索引擎<br/>AI Mode 10亿+"]
G_OS["✅ 操作系统<br/>Android 17"]
G_CLOUD["✅ 云基础设施<br/>TPU + GCP"]
G_HW["⚠️ 硬件<br/>Pixel/XR/Googlebook"]
G_AGENT["✅ Agent 平台<br/>Antigravity + Spark"]
G_MEDIA["✅ 媒体生成<br/>Omni + Veo + Imagen"]
G_WORKSPACE["✅ 生产力工具<br/>Workspace"]
end
subgraph "OpenAI — 模型+应用最强"
O_MODEL["✅ 顶级模型<br/>GPT-5.5"]
O_SEARCH["⚠️ SearchGPT<br/>规模有限"]
O_OS["❌ 无操作系统"]
O_CLOUD["⚠️ Azure 合作<br/>无自有基础设施"]
O_HW["❌ 无硬件"]
O_AGENT["✅ Agent 平台<br/>Codex + Operator"]
O_MEDIA["⚠️ Sora<br/>仅视频"]
O_WORKSPACE["❌ 无生产力工具"]
end
subgraph "Anthropic — 安全+研究最强"
A_MODEL["✅ 顶级模型<br/>Claude Opus 4"]
A_SEARCH["❌ 无搜索引擎"]
A_OS["❌ 无操作系统"]
A_CLOUD["⚠️ AWS 合作<br/>无自有基础设施"]
A_HW["❌ 无硬件"]
A_AGENT["✅ Agent 平台<br/>Claude Code + Computer Use"]
A_MEDIA["❌ 无媒体生成"]
A_WORKSPACE["❌ 无生产力工具"]
end
end
竞品深度对比表
模型层:Gemini 3.5 Flash vs GPT-5.5-medium vs Claude Sonnet 4
| Benchmark | Gemini 3.5 Flash | GPT-5.5-medium(估) | Claude Sonnet 4(估) | 分析 |
|---|---|---|---|---|
| 推理/代码 | Terminal-Bench 2.1: 76.2% | ~72-75% | ~70-74% | Flash 略领先 |
| Agent 能力 | GDPval-AA: 1656 | ~1620-1640 | ~1600-1630 | Flash 明显领先 |
| 工具调用 | MCP Atlas: 83.6% | ~80-82% | ~78-81% | Flash 领先 |
| 多模态 | MMMU-Pro: 84% | ~80-82% | ~75-78% | Flash 显著领先 |
| 推理速度 | 280+ tok/s | ~120-150 tok/s | ~100-120 tok/s | Flash 2-3x 快 |
| 价格(输入) | $1.50/M | ~$5/M | ~$3/M | Flash 最便宜 |
| 价格(输出) | $9.00/M | ~$15/M | ~$15/M | Flash 最便宜 |
| 上下文窗口 | 1M | ~256K-1M | ~200K | Flash 最大 |
| 幻觉率 | 61%(仍偏高) | ~55-60% | ~50-55% | Sonnet 更可靠 |
Agent 平台:Antigravity vs Codex vs Claude Code
| 维度 | Antigravity 2.0 | OpenAI Codex | Claude Code |
|---|---|---|---|
| 入口 | Desktop + CLI + SDK | Cloud + CLI | CLI + API |
| 执行环境 | Google 托管沙箱 | OpenAI 沙箱 | 本地 + 沙箱 |
| 编程语言 | Bash/Python/Node | Python/JS | Bash/Python/Node |
| 多 Agent | ✅ 原生支持(93 Agent Demo) | ⚠️ 有限支持 | ⚠️ 通过工具编排 |
| 自定义 Skills | ✅ 支持 | ❌ 不支持 | ⚠️ 通过 MCP |
| IDE 集成 | Desktop App | ChatGPT 内嵌 | VS Code / JetBrains |
| 文件操作 | ✅ 完整 | ✅ 完整 | ✅ 完整 |
| 网页浏览 | ✅ 内置 | ✅ 内置 | ⚠️ 有限 |
| Android 集成 | ✅ 原生 | ❌ | ❌ |
| 成熟度 | 首发预览 | 已迭代多版本 | 已迭代多版本 |
| 品牌清晰度 | ❌ 混乱(Gemini CLI vs Antigravity CLI) | ✅ 清晰 | ✅ 清晰 |
硬件生态:Google vs Apple vs Meta
| 维度 | Apple | Meta | |
|---|---|---|---|
| 手机 | Pixel + Samsung 生态 | iPhone | 无 |
| 笔记本 | Googlebook(新品类) | MacBook | 无 |
| 智能眼镜 | Android XR(秋天上市) | Vision Pro | Ray-Ban Meta ✅ |
| 手表 | Wear OS | Apple Watch | Meta Watch(已停) |
| 车载 | Android Auto | CarPlay | 无 |
| AI 芯片 | TPU Ironwood | Apple Neural Engine | MTIA v2 |
| AI OS 层 | Gemini Intelligence | Apple Intelligence | Meta AI |
| 硬件设计 | 合作(Samsung/Gentle Monster) | 自研 | 合作(Ray-Ban/EssilorLuxottica) |
| 硬件成功记录 | ⚠️ 混合(Pixel 成功,Stadia 失败) | ✅ 强 | ⚠️ Quest 成功,其他失败 |
🔬 商业模式推演
AI+ $100/月档的目标用户画像
| 用户画像 | 需求 | 付费意愿 | 预估规模 |
|---|---|---|---|
| 重度创作者 | Omni + Veo 高质量视频生成 | 高 | 200-500 万 |
| 专业开发者 | 更多 API 调用 + 高级模型 | 中-高 | 500-1000 万 |
| 知识工作者 | Workspace AI 增强 + 深度分析 | 中 | 1000-2000 万 |
| AI 爱好者 | 最新模型 + 高级功能 | 中 | 500-1000 万 |
| 预估 TAM | 2200-4500 万 |
Managed Agents API 定价逻辑和 TAM 估算
定价逻辑推演:
| 成本项 | 估算 | 说明 |
|---|---|---|
| Token 消耗 | $1.50-9.00/M tokens | 按量计费 |
| 沙箱计算 | ~$0.05-0.20/小时 | Firecracker VM 成本 |
| 存储临时文件 | ~$0.01-0.05/GB | 临时存储成本 |
| 网络流量 | ~$0.01-0.10/GB | 出站流量成本 |
| 单个 Agent 任务总成本 | $0.50-50/任务 | 取决于任务复杂度 |
| 平台加价率 | 2-5x | SaaS 标准加价 |
| 单价范围 | $1-250/任务 | 从简单到复杂 |
TAM 估算:
| 市场层 | 规模 | 说明 |
|---|---|---|
| 开发者工具 | $50-100 亿/年 | 替代部分 CI/CD、测试、运维工具 |
| 企业自动化 | $100-300 亿/年 | 替代 RPA、工作流自动化 |
| AI Agent 即服务 | $200-500 亿/年 | 新市场(Agent 托管 + 编排) |
| 总可寻址市场 | $350-900 亿/年 | 5-10 年时间窗口 |
Search AI Mode 对广告商业模式的影响
| 维度 | 当前模式 | AI Mode 模式 | 影响 |
|---|---|---|---|
| 广告形式 | 蓝色链接 + 文字广告 | Generative UI 中的原生广告 | 广告需要重新设计 |
| 广告位数量 | 10+ 广告位/页 | 1-3 广告位/查询 | 广告位减少 50-70% |
| 点击价值 | 高(用户主动点击) | 可能降低(Agent 直接给出答案) | CPC 下降 |
| 广告相关性 | 中(关键词匹配) | 极高(语义理解) | 转化率可能提升 |
| 衡量方式 | CPM/CPC | 可能转向 CPA/订阅 | 商业模式重构 |
关键风险: 如果 Search 从"10 条蓝色链接"变成"1 个 AI 回答 + Generative UI",广告位的减少可能对 Google 的核心收入产生显著冲击。Google 的策略可能是:
- 在 Generative UI 中嵌入原生广告(对比工具中的产品推荐)
- 用 Information Agents 创造新的广告场景(监控类任务中的商业推荐)
- 通过 AI+ 和 Ultra 订阅弥补广告收入下降
3.2Q Tokens/Month 的成本结构推算
| 成本项 | 年估算 | 计算逻辑 |
|---|---|---|
| TPU/计算 | $600-900 亿 | Capex 的主要部分 |
| 数据中心设施 | $200-300 亿 | 建筑、冷却、电力设施 |
| 电力 | $30-60 亿 | 基于 ~3-4 GW × $0.06-0.08/kWh |
| 网络带宽 | $20-40 亿 | 全球 CDN 和骨干网 |
| 人员 | $50-80 亿 | AI 研究员 + 工程师 |
| 软件/许可 | $10-20 亿 | 第三方软件和服务 |
| 总计 | $910-1400 亿/年 | 与 $1800-1900 亿 Capex + $300-500 亿 Opex 量级一致 |
收入覆盖分析:
- Google 2025 年总收入约 $4000 亿+
- AI 相关收入(API + 订阅 + 搜索增量)估算 $200-400 亿/年
- AI 基础设施投资占收入比约 25-35%——这是战略押注级别的投入
分析基于 Google I/O 2026 主题演讲(2026-05-19)、Google 官方博客、Latent Space AINews、Artificial Analysis、The Verge、Wired、Engadget、PCMag 等多个来源。第三方 benchmark 数据来自 Artificial Analysis 和 Arena。深度技术推演基于公开信息和行业实践,标记为"推演"的部分为分析师推算,非官方确认。
增强版 v2 · 2026-05-20 · 深度技术分析版