一、开场:CPX 之死与 LPU 之生
一场安静的葬礼
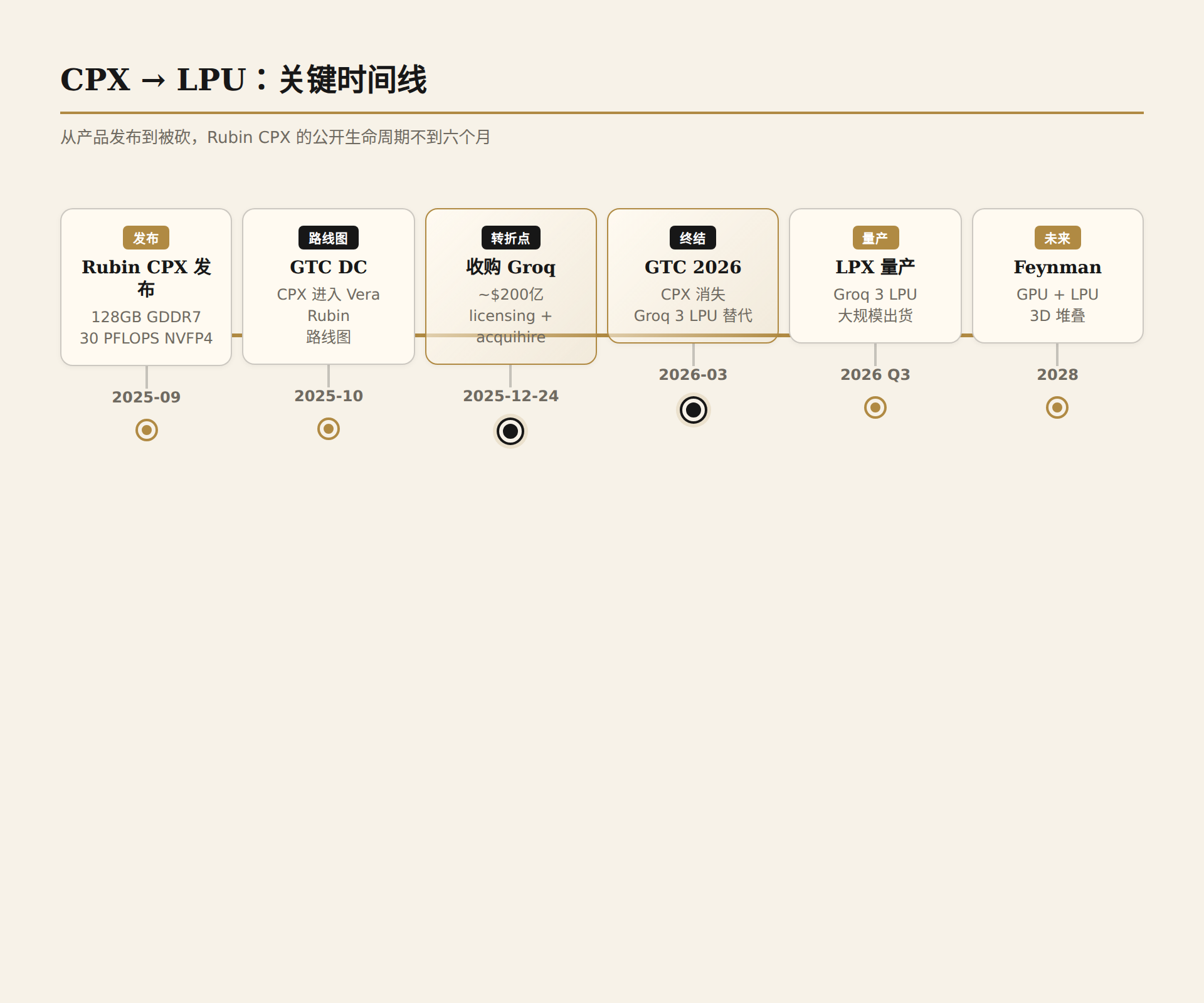
2026 年 3 月 17 日,San Jose,GTC 2026 主会场。Jensen Huang 照例穿着皮衣走上舞台,面对一万两千名开发者和分析师,开始了两个小时的主题演讲。他讲了 Vera Rubin NVL72,讲了 DGX Cloud,讲了 agentic AI 的未来愿景。但有一个名字,一个仅仅六个月前还被 NVIDIA 定位为"推理专用 GPU"战略核心的名字——Rubin CPX——整场演讲中没有被提及一次。
会后的幻灯片里,Rubin CPX 从产品路线图上消失了。取而代之的是一张全新的芯片:Groq 3 LPU。
这不是一次简单的产品延期或技术迭代。这是一家市值三万亿美元的公司,在不到六个月的时间里,砍掉了自己设计的推理 GPU,转而采用一种从零开始的全新架构——片上 SRAM、无 HBM、确定性数据流执行。而为此,NVIDIA 支付了 200 亿美元的 licensing-and-acquihire 费用。
时间线:从发布到消失
- 2025 年 9 月:NVIDIA 在 AI Infra Summit 上发布 Rubin CPX——一款基于 Rubin 架构的单 die 推理 GPU,搭载 128GB GDDR7 显存,30 PFLOPS NVFP4 算力,定位为百万 token 长上下文推理的专用芯片。
- 2025 年 10 月:GTC DC(GTC Fall)上,Rubin CPX 出现在 Vera Rubin 平台路线图中。NVIDIA 描绘了一个 disaggregated serving 愿景:Rubin GPU 负责训练和 prefill,CPX 负责纯 decode。
- 2025 年 12 月 24 日:NVIDIA 宣布以约 200 亿美元收购 Groq 的核心资产(非法律实体收购,而是 licensing + acquihire 结构)。Groq CEO Jonathan Ross 及核心团队加入 NVIDIA。这笔交易是 NVIDIA 史上最大一笔收购,也是 Groq 2025 年 9 月 69 亿估值的 2.9 倍溢价。
- 2026 年 3 月:GTC 2026,Rubin CPX 从路线图消失。Groq 3 LPU 及 LPX Rack 取代 CPX 成为 Vera Rubin 平台的推理加速方案。
从产品发布到被砍,CPX 的公开生命周期不到六个月。而这六个月里发生了什么,值得深入拆解。
四个核心问题
本报告试图回答四个问题:
- 为什么 GPU 在推理场景下效率低下? 训练和推理共享同一硬件的时代是否正在终结?
- CPX 的设计思路是什么?它差在哪里? NVIDIA 内部的推理 GPU 方案为什么不够好?
- LPU 的架构本质是什么? 片上 SRAM + 确定性执行为什么能在推理场景碾压 GPU?
- 这对 AI 基础设施意味着什么? 从数据中心设计到算力经济学,推理架构范式转移的实际影响有多大?
这不仅是 NVIDIA 一家公司的战略选择。这是整个 AI 行业从"训练为王"转向"推理为王"的硬件映射。
二、推理瓶颈的本质:为什么 GPU 不够用
训练 vs 推理:90% 的钱花在哪里
一个被反复引用但仍然被低估的事实:一个大型语言模型的生命周期中,80-90% 的计算成本发生在推理阶段,而非训练阶段。
以 GPT-4 级别的模型为例,训练一次可能花费数千万到上亿美元的算力成本。但模型一旦部署,每天面对数亿次请求、数千亿 token 的生成,推理的累积成本会迅速超过训练。据估计,AI 推理市场规模从 2025 年的约 1060 亿美元将增长到 2030 年的 2550 亿美元。
然而,直到 2025 年,AI 硬件的军备竞赛几乎完全围绕训练展开。H100、B200、Rubin R100——每一代旗舰 GPU 的核心指标都是训练性能:更高 FP8/FP4 算力、更大 HBM 容量、更快 NVLink 互连。推理只是训练硬件的"附带任务"。
这之所以成为一个问题,是因为训练和推理的计算模式截然不同:
| 维度 | 训练 | 推理(Decode 阶段) |
|---|---|---|
| 计算模式 | 大批量矩阵乘法,高密度并行 | 逐 token 自回归生成,串行依赖 |
| 瓶颈 | 算力(FLOPS) | 内存带宽(bytes/s) |
| 批处理 | 可以很大(数千样本同时处理) | 受延迟约束,batch size 通常很小 |
| KV Cache | 不需要(训练时所有 token 已知) | 需要维护,且随上下文长度线性增长 |
| 硬件利用率 | 算力利用率可达 60-80% | 带宽利用率低,算力利用率往往不到 10% |
核心矛盾在于:训练是 compute-bound,推理(decode)是 memory-bandwidth-bound。 训练时你可以把 batch size 开到很大,让每个 CUDA core 都在满负荷做矩阵运算。但推理时,每生成一个 token,你都必须把整个模型权重和全部 KV Cache 从内存读一遍——而每张卡的带宽是固定的。
自回归的诅咒
大语言模型的推理(decode 阶段)有一个无法并行化的本质特征:自回归(autoregressive)生成。
模型每生成一个 token,都需要:
- 将上一步的输出作为新的输入
- 用注意力机制(attention)查看之前所有的 token(KV Cache)
- 经过完整的 forward pass 计算概率分布
- 采样得到下一个 token
这个过程是严格串行的——你无法在知道第 N 个 token 之前开始计算第 N+1 个 token。
这意味着,无论你的芯片有多少 TFLOPS 算力,decode 阶段的速度上限取决于两个东西:
- 内存带宽:每秒能把多少字节从存储器搬到计算单元
- KV Cache 访问时间:随着上下文变长,需要读取的数据量线性增长
HBM 带宽瓶颈:定量分析
让我们用实际数据来量化这个问题。
场景:一个 70B 参数模型,FP8 精度,推理 serving。
- 模型权重:约 70 GB(FP8)
- KV Cache:取决于上下文长度。以 128K token 上下文为例,FP8 精度下约 20 GB
- 每 decode 一步需要读取的数据量:约 90 GB(权重 + KV Cache)
在主流 GPU 上的 decode 时间估算(仅内存读取时间):
| GPU | HBM 带宽 | 读取 90 GB 时间 | 理论最大 tokens/s |
|---|---|---|---|
| H100 SXM | 3.35 TB/s | ~27 ms | ~37 |
| B200 SXM | 8 TB/s | ~11 ms | ~90 |
| Rubin R100 (288GB HBM4) | 22 TB/s | ~4 ms | ~250 |
| Groq 3 LPU (SRAM) | 150 TB/s | ~0.6 ms | ~1,600+ |
注意这些数字是理想情况——实际推理中还有 attention 计算本身的开销、软件栈调度延迟、batch 管理等。但核心结论已经清晰:在 150 TB/s 的 SRAM 带宽面前,即使是 Rubin R100 的 22 TB/s HBM4 也慢了将近 7 倍。
而且这只是 128K 上下文。当上下文扩展到 1M token 时,KV Cache 在 FP8 下增长到约 160 GB。这意味着:
- H100:读取 230 GB(权重 + KV)需要 ~69 ms → 理论 ~14 tokens/s
- B200:读取 230 GB 需要 ~29 ms → 理论 ~35 tokens/s
- Rubin R100:读取 230 GB 需要 ~10.5 ms → 理论 ~95 tokens/s
- Groq 3 LPU:读取 230 GB 需要 ~1.5 ms → 理论 ~650+ tokens/s
上下文越长,带宽瓶颈越严重,SRAM 的优势越明显。

KV Cache:指数级压力
KV Cache 是推理场景独有的内存压力源,也是最容易被低估的成本因素。
对于每个 token 的上下文,注意力机制需要为每一层、每一个 KV head 存储 key 和 value 张量。以 Llama 3 70B 类模型为例(80 层、8 KV heads、128 head dim),每个 token 的 KV Cache 大小为:
2 × 80 layers × 8 heads × 128 dim × 2 bytes (BF16) ≈ 320 KB/token
这意味着:
| 上下文长度 | BF16 KV Cache | FP8 KV Cache | FP4 KV Cache |
|---|---|---|---|
| 32K tokens | ~10 GB | ~5 GB | ~2.5 GB |
| 128K tokens | ~41 GB | ~20 GB | ~10 GB |
| 256K tokens | ~82 GB | ~41 GB | ~20 GB |
| 1M tokens | ~320 GB | ~160 GB | ~80 GB |
在 1M token 上下文下,BF16 的 KV Cache 是 320 GB——没有一块 GPU 能装得下。即使是 FP4 的 80 GB,也需要占用 B200 几乎全部 HBM 容量,留给模型权重和 batch 的空间几乎为零。
这还不是最糟糕的。每 decode 一步,attention 计算都需要读取完整的 KV Cache。这意味着 KV Cache 的大小直接决定了每一步的延迟——而且是线性关系。
Agentic AI:放大器
如果说长上下文推理让 GPU 的带宽瓶颈变得明显,那么 Agentic AI 就是把这个瓶颈放大到了系统级别。
一个 AI Agent 完成一次任务,通常需要经历多轮 PRA 循环(Plan → Reflect → Act):
- 理解用户意图,制定计划
- 调用工具,获取外部信息
- 反思执行结果,调整策略
- 可能失败后重试
- 最终生成完整回复
这意味着一个看似简单的用户查询,在 agent 内部可能触发 10-50 次 LLM 调用。每次调用都有自己的 prompt 和 context,累积的 token 消耗是一次普通聊天的 10-50 倍。
行业估算,Agentic AI 的 token 消耗大约是传统聊天模式的 15 倍。而随着 agent 系统越来越复杂(多 agent 协作、长链条推理、复杂工具编排),这个倍数还在上升。
推理成本的构成正在发生结构性变化:
- 2024 年:推理 = 主要是短上下文聊天,batch size 较大,GPU 利用率尚可
- 2025 年:RAG + 长文档处理开始普及,上下文长度从 32K 增长到 128K+
- 2026 年:Agentic AI 爆发,多轮调用 + 长上下文成为常态,推理算力需求指数级增长
这就是 NVIDIA 面对的市场现实:训练市场正在从超大规模基座模型转向更高效的训练方法(混合专家、蒸馏、合成数据),增长曲线开始趋缓。但推理市场——尤其是 Agentic 推理——正在以更陡的曲线加速。硬件需要适应这个变化,而不是让软件去将就硬件。
三、两条路线的碰撞:CPX vs LPU
CPX:用 GPU 思维做推理
Rubin CPX 的设计思路可以概括为一句话:在 GPU 架构内,用更便宜的内存换取更大的容量。
CPX 的核心设计选择:
- GDDR7 替代 HBM:128 GB GDDR7 显存,比 HBM 便宜得多,容量也更大。这对于存储大模型权重和 KV Cache 是合理的——128 GB 足以在单卡上容纳 70B FP8 模型(~70 GB)加上相当规模的 KV Cache。
- 单 die 设计:不同于 Rubin R100 的多 die 设计,CPX 采用单片 die,减少了 die-to-die 通信延迟,对 decode 阶段的串行计算更友好。
- 集成视频编解码:面向多模态推理,支持长视频理解等场景。
- 30 PFLOPS NVFP4 算力:继承 Rubin 架构的计算能力。
从 NVIDIA 的角度看,这个设计有其合理性。在 2025 年 9 月发布时,CPX 是一个务实的选择:用成熟的 GDDR7 技术解决推理场景的容量问题,同时保持 GPU 编程模型的兼容性——CUDA 生态、TensorRT、现有的推理框架无需大幅改动。
但 CPX 有一个根本性的架构局限:带宽。
GDDR7 虽然比 GDDR6 快很多,但其带宽天花板大约在 1.5-2 TB/s(128 GB 配置下)。作为对比:
- H100 SXM(HBM3):3.35 TB/s
- B200 SXM(HBM3e):8 TB/s
- Rubin R100(HBM4):22 TB/s
也就是说,CPX 的内存带宽大约只有 Rubin R100 的 1/11。 对于 compute-bound 的训练场景,这可以接受——你靠大 batch 填满计算单元。但对于 memory-bandwidth-bound 的 decode 场景,这就是致命缺陷。
NVIDIA 自己的数据也很说明问题。在 128K token 上下文、70B FP8 模型的 decode 场景下:
| 方案 | 内存带宽 | KV Cache 读取时间(128K FP8, ~20 GB) |
|---|---|---|
| CPX (GDDR7, ~2 TB/s) | ~2 TB/s | ~10 ms |
| Rubin R100 (HBM4) | 22 TB/s | ~0.9 ms |
| Groq 3 LPU (SRAM) | 150 TB/s | ~0.13 ms |
CPX 的 KV Cache 读取时间是 LPU 的 77 倍。这不是一个可以通过软件优化或更大的 batch size 弥补的差距——这是物理层面的架构差距。
再看 1M token 上下文(FP8,KV Cache ~160 GB):
| 方案 | 权重+KV 总读取 | 读取时间 | 理论最大 tokens/s |
|---|---|---|---|
| CPX (~2 TB/s) | ~230 GB | ~115 ms | ~9 |
| Rubin R100 (22 TB/s) | ~230 GB | ~10.5 ms | ~95 |
| Groq 3 LPU (150 TB/s) | ~230 GB | ~1.5 ms | ~650+ |
在百万 token 上下文下,CPX 只能跑到约 9 tokens/s——对于实时交互或 Agentic 场景来说几乎不可用。
LPU:推倒重来
Groq 3 LPU 代表了一种完全不同的思路:不试图让 GPU 更好地做推理,而是设计一个只能做推理但做得极好的芯片。
核心架构决策:
1. 片上 SRAM 替代一切外部存储
这是最根本的决定。LPU 没有 HBM、没有 GDDR、没有任何外部 DRAM。所有的权重和激活值都存储在 500 MB 的片上 SRAM 中。
500 MB 听起来很小——毕竟 H100 有 80 GB HBM,Rubin R100 有 288 GB HBM4。但关键在于系统级聚合。Groq 3 LPX Rack 包含 256 颗 LPU 芯片,总 SRAM 容量 128 GB——足够装载一个 70B FP8 模型加上可观的 KV Cache。
而带宽是碾压级的:
- 每颗 LPU:150 TB/s SRAM 带宽
- 整个 LPX Rack:聚合带宽达到 PB/s 级别
作为对比,单颗 Rubin R100 的 HBM4 带宽是 22 TB/s。LPU 的片上带宽是 R100 的 6.8 倍,是 CPX 的 75 倍。
2. 确定性数据流执行
GPU 的执行模型本质上是不确定的:线程调度由硬件动态管理,内存访问有 cache miss 的不确定性,DRAM 控制器有队列延迟的波动。这些不确定性在训练时无关紧要(训练可以容忍几毫秒的延迟波动),但在推理时——尤其是要求稳定的低延迟时——会显著影响性能预测和服务质量。
LPU 采用了完全不同的方式:编译器在编译时就把每一条指令、每一个数据移动、每一个时钟周期都安排好了。芯片执行的是一个固定的数据流图(dataflow graph),每个时钟周期做完全相同的操作。没有 cache hierarchy,没有 speculative execution,没有 prefetching。
这意味着:
- 延迟是确定性的:每个 token 的生成时间完全可预测
- 没有 cache miss:所有数据都在片上,不需要 cache
- 没有 DRAM 调度开销:没有 DRAM 控制器,没有 bank conflict
- 延迟与 batch size 无关(直到芯片容量上限)
这种确定性在实际部署中是一个被低估的优势。对于一个需要保证 P99 延迟的推理服务,GPU 需要预留大量的性能裕量来应对延迟尖峰,而 LPU 可以工作在更接近理论峰值的水平。
3. 静态调度与编译器主导
LPU 的另一个核心特点:性能的优化几乎完全由编译器完成,而非运行时。这和 GPU 形成了鲜明对比——GPU 推理的性能高度依赖运行时调度(CUDA stream、kernel fusion、memory allocator 等)。
在 LPU 的世界里,模型部署流程是:
- 将模型编译成 LPU 数据流图
- 编译器确定每个操作的时间片和资源分配
- 芯片按编译好的计划执行
这意味着编译时间较长(可能需要几十分钟到几小时),但一旦编译完成,运行时几乎没有开销。对于持续运行数周、数月的生产推理服务,这是理想的权衡。
关键参数对比
| 参数 | Rubin CPX(原设计) | Groq 3 LPU |
|---|---|---|
| 架构类型 | GPU(推理优化变体) | LPU(专用推理处理器) |
| 制造工艺 | 3nm (N3P) | Samsung 4nm |
| 晶体管数 | 未公布(预估 2000 亿+) | 980 亿 |
| 内存类型 | GDDR7(off-chip DRAM) | 片上 SRAM(无外部存储) |
| 内存容量(单芯片) | 128 GB | 500 MB |
| 内存带宽(单芯片) | ~1.5-2 TB/s | 150 TB/s |
| 算力(NVFP4) | 30 PFLOPS | ~1.2 PFLOPS (FP8) |
| 互连 | NVLink(Rubin 平台内) | 96 条 112 Gbps C2C 链路 |
| 首 Token 延迟 | 未公布 | < 0.1 s |
| 设计目标 | 长上下文 decode + 多模态 | 纯 autoregressive decode |
| 灵活性 | 高(CUDA 生态兼容) | 低(专用编译器) |
| 冷却方式 | 液冷(推测) | 全液冷(兼容MGX) |
| 状态 | 已取消 | 2026 Q3 量产 |
NVIDIA 为什么放弃 CPX
综合以上分析,NVIDIA 放弃 CPX 的原因可以归纳为四点:
1. 带宽差距是物理层面的,不是工程能弥补的
GDDR7 的带宽天花板(~2 TB/s)与 SRAM 的带宽(150 TB/s)之间是 75 倍的差距。这不是通过更好的缓存策略、更聪明的 batch 调度、或者更大的 batch size 能解决的。在 decode 阶段,你每个 token 都必须读取完整权重和 KV Cache,没有捷径。
2. CPX 在百万 token 上下文场景不可用
NVIDIA 自己的定位是"百万 token 推理"——代码生成、长视频理解、全文档 RAG。但在 1M token 上下文下,CPX 的 decode 速度只有约 9 tokens/s。对于需要实时交互的 Agentic AI 场景,这个速度远远不够。
3. LPU 的能效比碾压 GPU
NVIDIA 公布的数据显示,Groq 3 LPU 在推理场景的每瓦性能是 HBM GPU 的 35 倍。一个 700W 的 H100 跑 70B 模型约 3000 tokens/s(~4.3 tokens/watt),而 LPU 可以达到约 150 tokens/watt。对于数据中心运营商来说,这意味着同样的推理吞吐量,耗电量降低 97%。在 2026 年电力资源日益紧张的背景下,这不是一个可以忽略的数字。
4. CPX 的 GDDR7 优势(容量、成本)在系统级别被抵消
CPX 的核心卖点是 128 GB GDDR7——单芯片就能装下一个 70B 模型。但 LPU 通过 256 芯片聚合(128 GB 总 SRAM)达到了相同的系统级容量。虽然代价是更多的芯片数量,但每颗 LPU 的制造成本远低于一颗大 die GPU(Samsung 4nm vs TSMC N3P,SRAM-only vs 复杂 GPU logic),总体成本未必更高。
而且,LPX 机架的成本结构通过使用成熟制程的 LPU 芯片获得了优势——SRAM-only 设计不需要昂贵的 HBM,大幅降低了单芯片成本。
一个更深层的战略信号
NVIDIA 花 200 亿美元买 Groq,不仅仅是买一个芯片设计。这是 NVIDIA 第一次承认:GPU 不是所有 AI 工作负载的最佳答案。
自 2012 年 AlexNet 以来,GPU 就是深度学习的代名词。训练用 GPU,推理用 GPU,所有东西都跑在 GPU 上。CUDA 生态构建了巨大的护城河。但推理的 memory-bandwidth-bound 本质,意味着当推理成为 AI 算力的主要消耗时,GPU 的通用性反而成了劣势。
NVIDIA 选择在推理这个战场上引入一种全新架构,而不是继续优化 GPU——这个信号的意义,远大于 CPX vs LPU 的技术对比本身。
四、Groq 3 LPX 机架:256 颗 LPU 的系统工程
4.1 从芯片到机架:架构全景
当 NVIDIA 在 GTC 2026 上展示 Groq 3 LPX 机架时,舞台中央站着的不是一颗芯片,而是一整个系统。这不是偶然——单颗 LPU(Language Processing Unit)只有 500 MB 片上 SRAM,装不下任何有实际意义的生产级大模型。LPU 的战斗力从机架级别才开始显现。
LPX 机架的核心参数是一组让人过目难忘的数字:
| 指标 | 数值 |
|---|---|
| LPU 芯片数 | 256(32 托盘 × 8 芯片/托盘) |
| 聚合 SRAM 容量 | 128 GB |
| 片上 SRAM 带宽 | 40 PB/s |
| AI 推理算力(FP8) | 315 PFLOPS |
| Scale-up 带宽 | 640 TB/s |
拆开来看:32 个 1U 液冷计算托盘,每个托盘集成 8 颗 LP30 芯片、一颗主机处理器和 fabric 扩展逻辑。每个托盘提供 4 GB SRAM、1.2 PB/s 带宽、9.6 PFLOPS FP8 算力和 20 TB/s 的 Scale-up 带宽。32 个这样的托盘通过 LPU C2C(Chip-to-Chip)spine 互连,构成一台完整的推理加速机架。
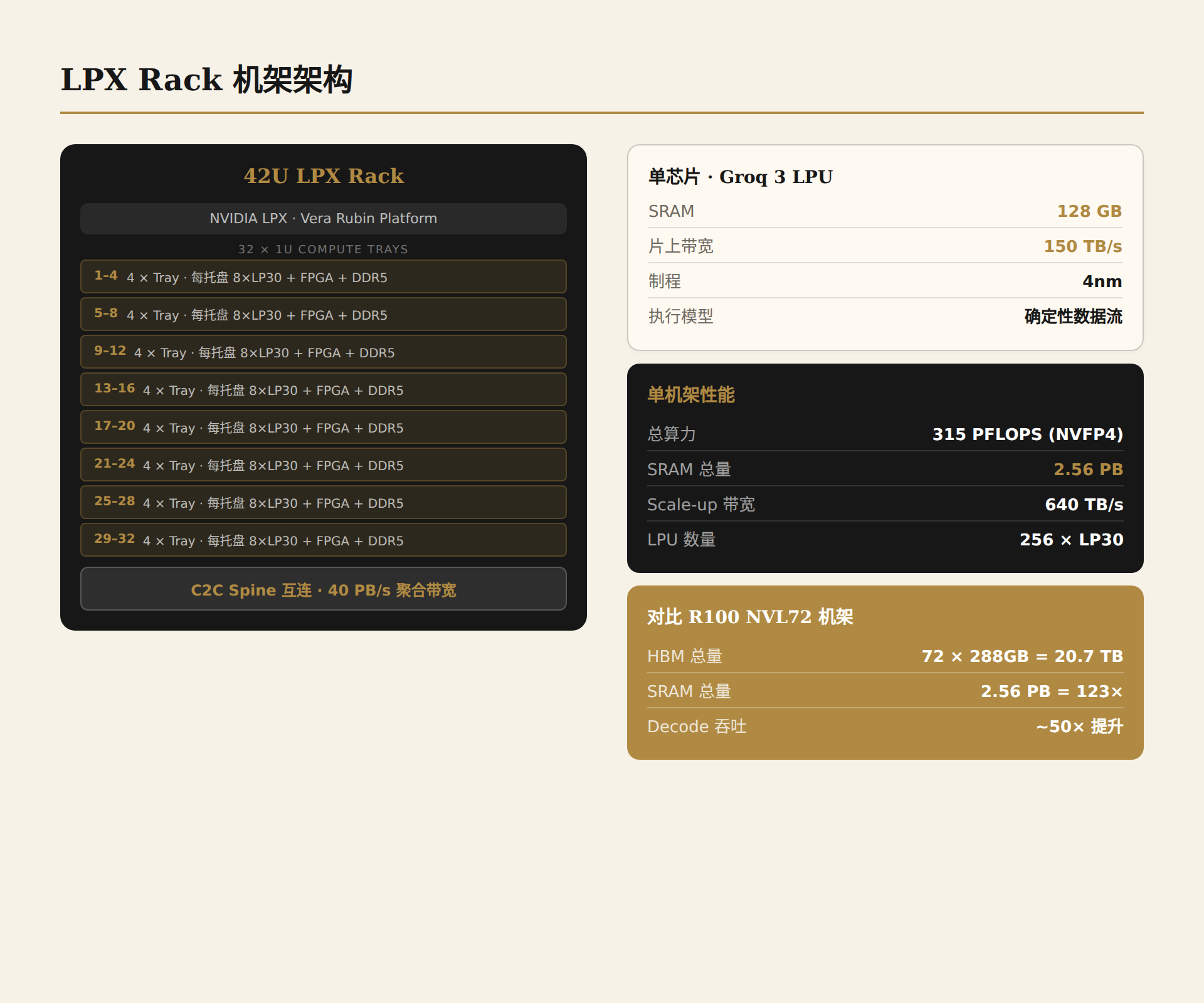
这个架构选择本身就是一种声明:LPU 不是 GPU 的替代品,而是 GPU 的互补品。一个 LPX 机架可以装下一个 70B FP8 模型的全部权重(约 70 GB),还有余量留给 KV Cache。但对于更大的模型——万亿参数级别——它需要与 Vera Rubin NVL72 协同工作。
4.2 SRAM:1800 倍带宽优势的本质
LPX 机架最引人注目的数字是 40 PB/s 的聚合 SRAM 带宽。这个数字需要拆解来理解。
单颗 LP30 芯片提供 150 TB/s 的片上 SRAM 带宽。作为对比,H100 SXM 的 HBM3 带宽是 3.35 TB/s,B200 SXM 的 HBM3e 带宽是 8 TB/s。按单芯片计算,LPU 的内存带宽是 H100 的约 45 倍。但更准确的比较对象是下一代 HBM4——三星和 SK 海力士规划的 HBM4 带宽约 22 TB/s。即使拿最激进的 HBM4 预期来看,SRAM 仍然快约 7 倍(单芯片维度)。
1800 倍这个数字的来源是另一种算法:如果把整个 LPX 机架的 40 PB/s 聚合带宽与单颗 GPU 的 HBM4 带宽(22 TB/s)相比,40,000 / 22 ≈ 1,818。这个比较在技术上不太公平——它把 256 颗芯片的聚合带宽与一颗芯片做对比——但它精确地传递了一个信息:当你把推理任务分布到 256 颗 SRAM-first 芯片上时,内存带宽不再是瓶颈。
这对 decode 阶段尤其关键。在自回归推理中,每生成一个 token 都需要把模型全部权重从内存读取一遍。以 70B FP8 模型(约 70 GB 权重)为例:
- H100(3.35 TB/s):权重加载时间 ≈ 21 ms
- B200(8 TB/s):权重加载时间 ≈ 8.75 ms
- 单颗 LPU(150 TB/s):权重加载时间 ≈ 0.47 ms
当模型生成速度向 1000 tokens/s 迈进时,每 token 的预算只有 1 ms。只有 SRAM 能把内存访问时间压缩到这个量级以下。
4.3 FPGA 调度中枢:硬件可编程的代价与回报
每个 LPX 计算托盘内置一颗 FPGA 作为调度中枢。按行业价格估算,一颗中高端 FPGA 约 1.2 万美元,32 颗就是 38.4 万美元——这已经接近 LPX 机架元器件成本的 10-15%。
为什么是 FPGA 而不是 ASIC?三个原因构成了逻辑闭环:
第一,调度策略在快速演化。 Prefill/Decode 分离(PD分离)由 UCSD Hao AI Lab 首创,而 AFD(Attention-FFN Disaggregation)将这一理念推向了更细粒度的层面。MoE 模型中 expert 的路由策略、prefill/decode 的负载均衡比例、多租户场景下的优先级调度——这些都在以季度为单位迭代。如果做成固定功能的 ASIC,每一次策略变更都需要重新流片,周期 12-18 个月,成本数百万美元。FPGA 可以在几周内完成重新编程。
第二,负载均衡需要硬件级响应速度。 在 256 颗 LPU 的分布式推理流水线中,token 在芯片间的流动需要精确的时序同步。LPU 的确定性执行模型要求可编程的链路调度器来管理 C2C 连接的时序和数据路由,而 FPGA 提供了这种灵活性。
第三,故障隔离和系统韧性。 256 颗芯片的系统中,单颗芯片故障的概率不可忽视。FPGA 可以在硬件级别重新映射数据流,绕过故障节点,而不需要软件层面的降级。
但 FPGA 的短板同样明显:编程门槛极高。 FPGA 开发需要硬件描述语言(Verilog/VHDL)专业知识,全球能熟练进行高性能 FPGA 调度逻辑开发的工程师可能不超过几千人。这对 NVIDIA 的软件生态整合能力提出了极高要求——如何让 FPGA 的可编程性对上层框架(Dynamo、TensorRT-LLM)透明,决定了 LPX 能否被大规模采纳。
4.4 DDR5 后援内存:SRAM 的蓄水池
每个计算托盘可通过 fabric 扩展逻辑接入最多 256 GB DRAM,加上主机 CPU 侧的 128 GB,单托盘最大 DRAM 容量约 384 GB。整个机架的 DDR5 总量约 12 TB。
这个存储层次的设计意图很清晰:SRAM 是热数据的高速公路,DDR5 是温数据的蓄水池。 在 decode 过程中,活跃权重和当前 KV Cache 驻留在 SRAM 中,以 40 PB/s 的速度被计算单元消费。但不是所有数据都需要这个速度——冷门的 MoE expert 权重、长上下文中的早期 KV Cache、等待被调用的模型层——这些可以暂存在 DDR5 中,在需要时通过 DMA 搬运到 SRAM。
DDR5 还为模型切换提供了缓冲空间。当一个 LPX 机架需要从服务模型 A 切换到模型 B 时,模型 B 的权重可以从 DDR5 加载到 SRAM,而不需要从网络存储系统读取,大幅减少切换延迟。
4.5 全液冷与 MGX 兼容:部署的现实约束
LPX 机架采用全液冷设计,兼容 NVIDIA MGX(Modular GPU Accelerator)机架架构。
这不仅仅是散热选择,更是部署经济学。传统风冷机架的功率密度上限约 30-40 kW,而 LPX + Vera Rubin NVL72 的组合机架功率可能超过 100 kW。液冷将功率密度上限推高到 150 kW 以上,使数据中心可以在不大幅改造设施的前提下部署 LPX。
MGX 兼容性意味着 LPX 可以与 Vera Rubin NVL72 共享同一套机架基础设施、电源分配单元(PDU)和管理网络。对超大规模数据中心来说,这意味着不需要为 LPX 建设独立的机房区域——它就是 Vera Rubin 机柜旁边的另一个机柜。
4.6 供应链:富士康独家代工的风险与规模
计算托盘由富士康独家代工,计划 2026 Q3 开始出货,年产能目标 6000 台 LPX 机架,对应 153.6 万颗 LP30 芯片。独家代工意味着单一供应风险——富士康的产能波动(无论是因为需求冲突还是地缘因素)都会直接影响 LPX 的交付节奏。
LP30 芯片基于三星 4nm 工艺制造(Groq 3 LPU 公开规格为三星 4nm,980 亿晶体管)。与 Rubin GPU 的台积电 N3P 相比,LPU 选择三星 4nm 的逻辑清晰:SRAM-first 架构不依赖先进制程的密度优势,三星 4nm 在 SRAM 密度和成本之间提供了更好的平衡。
五、GPU + LPU 异构协同:Dynamo 与 AFD
5.1 AFD:为什么要把 Attention 和 FFN 拆开
Attention-FFN Disaggregation(AFD)是这个异构架构的理论基石。它源于一个对 Transformer 推理的精准观察:Attention 和 FFN 在推理时有截然不同的硬件需求。
Attention(注意力层) 在 decode 阶段是内存容量密集型的。KV Cache 随上下文长度线性增长——一个百万 token 的上下文窗口,KV Cache 可能占用数十 GB 内存。这个数据需要持久化存储,且访问模式是不规则的(attention score 计算需要访问所有历史 token 的 KV)。
FFN(前馈网络)/ MoE Expert 在 decode 阶段是计算密集型+内存带宽密集型的。它不需要维护跨 token 的状态——每个 token 独立通过 FFN 投影——但它需要高速读取权重矩阵。这正是 SRAM 的强项:权重固定、访问模式规律、需要极致带宽。
AFD(Attention-FFN Disaggregation)将 Prefill/Decode 分离的理念推向了更细粒度的层面——不是按阶段分离,而是按网络层类型分离。关键洞察是:在 MoE(混合专家)模型中,expert 并行本身就需要 all-to-all 通信。AFD 巧妙地搭了这趟便车——把 activation 在 Attention 和 FFN 之间的传递嵌入到已有的 expert routing 通信中,避免了纯 dense Transformer 中额外的通信开销。
5.2 GPU 负责 Prefill,LPU 负责 Decode:分工的逻辑
在 Vera Rubin NVL72 + LPX 的异构架构中,推理请求的生命周期被拆成了接力赛:
第一棒:GPU 处理 Prefill。 用户输入的 prompt 是一次性批量处理的矩阵乘法,高度 compute-bound。Rubin GPU 的 Tensor Cores 在这个阶段发挥极致 FLOPS 利用率——大规模 batch matmul 正是 GPU 的主场。Prefill 完成后,生成的 KV Cache 需要传递给下一棒。
第二棒:LPU 处理 Decode。 进入自回归 token 生成阶段后,每个 token 只需要做小 batch 的矩阵运算。在 GPU 上,这个阶段的 FLOPS 利用率只有 1-3%——计算单元大部分时间在等内存返回数据。而 LPU 的 SRAM 把这个等待时间压缩了 45 倍(单芯片维度),使 FLOPS 利用率接近峰值。
数据传递:KV Cache 从 GPU HBM 到 LPU SRAM。 这是整个架构中最关键、也是最脆弱的环节。KV Cache 从 GPU 的 HBM 通过 PCIe/CXL 或定制互连传输到 LPU 的 SRAM。传输延迟和带宽直接决定了系统的 TTFT(Time-to-First-Token)和请求切换开销。
NVIDIA 官方的比喻很贴切:Vera Rubin NVL72 是"灵活的通用型主力",负责训练和推理的高吞吐全流程;LPX 是"低延迟推理专用引擎",专门加速 decode 循环中延迟敏感的 FFN/MoE 执行。两者合在一起,构成了一个"异构推理架构"——在保持 AI 工厂级总吞吐量的同时,提供交互式推理的低延迟体验。

5.3 NVFusion:LPU 进入 CUDA 生态的技术路径
LPU 要被广泛采纳,必须解决一个根本问题:开发者不需要为一种新硬件重写代码。NVFusion 是 NVIDIA 对这个问题的回答——一种让 LPU 对开发者透明的技术路径。
从已知信息推断,NVFusion 的工作方式类似于 CUDA 对不同 GPU 架构的抽象:上层框架(PyTorch、JAX、TensorRT-LLM)发出标准的张量操作,NVFusion 运行时将这些操作路由到合适的执行设备——compute-bound 的操作去 GPU,memory-bandwidth-bound 的操作去 LPU。开发者看到的仍然是一个统一的 CUDA 设备池。
这种抽象的关键挑战在于 权重调度:模型权重需要在 GPU 和 LPU 之间动态分配。在 AFD 模式下,FFN/MoE 的权重驻留在 LPU SRAM 中,Attention 的权重和 KV Cache 驻留在 GPU HBM 中。权重从 GPU 到 LPU 的快速调度机制——如何在不中断推理服务的前提下完成权重加载和更新——是 NVFusion 运行时的核心工程难点。
5.4 软件栈:Dynamo 编排全流程
NVIDIA Dynamo 是整个异构推理架构的编排层,它负责管理从请求接收到 token 生成的完整生命周期。
Dynamo 的核心能力包括:
-
Prefill/Decode 分离调度。 Dynamo 将推理请求拆分为 prefill 和 decode 两个阶段,分别路由到 GPU 和 LPU 集群。它管理 KV Cache 在两者之间的传递,并根据实时负载动态调整 GPU-LPU 的分配比例。
-
Streaming Tokens。 Token 以流式方式返回给客户端,而不是等待整个序列生成完毕。在 Agentic 场景下,streaming 不只是体验优化——它是功能需求。推理、工具调用、代码生成都需要在 token 级别实时反馈,而非等一个完整响应。
-
Multi-Turn Agentic Harness。 这是 Dynamo 在 2026 年重点投入的方向。真实的 Agentic 推理是多轮结构化交互:assistant 的回复穿插推理(thinking)和工具调用(tool calls),用户(或 harness)的后续消息返回工具执行结果。Dynamo 需要精确管理每一轮的上下文状态——哪些 reasoning 应该保留到下一轮,哪些应该丢弃——这是模型特定、场景特定的策略,不能一概而论。
Dynamo 在实践中面临的挑战具体而真实。以 Anthropic 兼容 API 为例:Claude Code 等客户端在每个请求开头附带 session-specific 的 billing header,导致 KV Cache 无法跨会话复用。Dynamo 通过 --strip-anthropic-preamble 选项在 tokenize 之前剥离这个不稳定的 header。在一个 52K token prompt 的 B200 测试中,这一优化将 TTFT 从 912ms 降至 168ms——约 5 倍改善。
5.5 NVIDIA OpenShell:自主 Agent 的安全运行时
如果 Agentic AI 是目的地,OpenShell 是护城河。它是 NVIDIA 开源的自主 AI Agent 安全运行时,提供沙箱化的执行环境来保护数据和系统安全。
OpenShell 解决的核心问题是:当一个 AI Agent 能够自主执行 shell 命令、访问文件系统、发起网络请求时,如何在保持能力的同时约束风险?这不是一个纯粹的软件问题——它涉及到 Agent 的权限模型、资源隔离、审计日志、以及故障时的安全降级。
OpenShell 与 Dynamo 的关系是互补的:Dynamo 负责推理层的编排(token 怎么流、KV Cache 怎么管),OpenShell 负责执行层的安全(Agent 的工具调用怎么执行、边界在哪)。当 Agent 通过 Dynamo 的 tool_call_dispatch 事件发出工具调用时,实际执行发生在 OpenShell 的沙箱中。
5.6 潜在问题:异构执行的工程代价
GPU + LPU 异构架构在理论上的收益是清晰的,但在工程实践中面临三重挑战:
两套执行模型的一致性。 GPU 是动态调度的——warp scheduler 在运行时决定指令的执行顺序,延迟可变。LPU 是确定性执行的——编译器在编译时精确安排每个时钟周期的操作。两种模型产生的数值结果应该在数学上等价,但在浮点精度和边界条件上可能存在微小差异。对于需要 GPU 和 LPU 协同处理同一模型的不同层的场景,这种差异是否会累积成可观测的质量退化,需要在生产环境中持续验证。
调试复杂度。 当一个推理请求同时涉及 GPU(prefill + attention)、LPU(FFN/MoE decode)和 FPGA(调度)三种硬件时,性能调优和故障定位的复杂度急剧上升。一个 latency spike 可能来自 GPU 的 HBM 访问竞争、LPU 的 C2C 通信拥塞、或 FPGA 的调度决策。目前的 profiling 工具是否足以在这种异构环境中提供端到端的可观测性,是一个开放问题。
故障隔离。 在纯 GPU 系统中,一颗 GPU 故障意味着该 GPU 上的请求需要重新路由到其他 GPU。在 GPU+LPU 异构系统中,一个组件的故障可能级联——如果负责某层 FFN 的 LPU 芯片故障,正在 decode 的请求无法继续,而 GPU 端的 KV Cache 已经生成。系统需要决定是丢弃请求、还是降级到纯 GPU 路径完成。这种故障切换逻辑的复杂性是纯 GPU 系统所没有的。
六、性能推演与成本分析
6.1 "每兆瓦推理吞吐量提升 35 倍"——如何得出?
NVIDIA 在 GTC 2026 上宣称 Vera Rubin + LPX 相比 Hopper(H100)平台"每兆瓦推理吞吐量提升 35 倍"。这是一个分层构建的数字,需要逐层拆解。
第一层:Blackwell vs Hopper。 根据 SemiAnalysis InferenceX 的数据,GB300 NVL72 相比 Hopper 平台在 Agentic AI 场景下实现了约 50 倍的每兆瓦吞吐量提升和 35 倍的每 token 成本下降。这来自于 NVFP4 低精度推理、TensorRT-LLM 优化、NVLink 5 的带宽提升、以及 NVL72 机架级别的全互连架构。
第二层:Rubin vs Blackwell。 NVIDIA 官方宣称 Vera Rubin NVL72 相比 Blackwell 实现了"每百万 token 成本降至 1/10"和"用 1/4 的 GPU 完成 AI 训练"。这意味着 Rubin 本身相对于 Blackwell 大约有 10 倍的推理效率提升。
第三层:Rubin + LPX vs Rubin 单独。 LPX 的加入进一步加速了 decode 阶段。在 AFD 模式下,LPU 承担了 FFN/MoE decode 的全部工作负载,释放 GPU 用于 prefill 和 attention。综合效果取决于 workload 中 prefill/decode 的比例——对于长输出、多轮 Agentic 场景(decode 占比 > 80%),LPX 的边际贡献最大。
35 倍的数字来自 Hopper → Rubin 的约 10 倍提升,叠加 LPX 在 decode-heavy 场景下的额外 3-4 倍提升。前提条件是: MoE 模型架构(AFD 只对 MoE 有效)、长上下文+长输出的 Agentic workload、以及 GPU+LPU 异构部署的完整软件栈(Dynamo + NVFusion)就绪。
6.2 数据不一致:307 vs 315 PFLOPS,38.4 vs 40 PB/s
在 LPX 的公开资料中,存在两组不一致的数据:
PFLOPS: NVIDIA 官方技术博客给出的 LPX 机架算力是 315 PFLOPS(32 托盘 × 9.6 PFLOPS/托盘 = 307.2 PFLOPS)。315 与 307.2 的差异(约 2.5%)可能来自:对单托盘算力的四舍五入、或包含了调度 FPGA 的辅助算力贡献、或 NVIDIA 在不同场景下的标称方式差异(峰值 vs. 持续)。这属于正常的工程误差范围,不影响系统级评估。
带宽: 40 PB/s 与 38.4 PB/s(256 × 150 TB/s = 38,400 TB/s = 38.4 PB/s)的差异类似。40 PB/s 可能是 NVIDIA 的向上取整标称值,38.4 PB/s 是严格乘法的结果。差异约 4%,在聚合带宽的语境下可以理解。
这些不一致不是致命问题,但它提醒我们:NVIDIA 的市场发布数据和技术规格之间存在系统性偏差——前者倾向于向上取整和理想化,后者更接近工程现实。在做成本分析时,应该使用较低的数字以保持保守。
6.3 Token 成本曲线:Blackwell → Rubin → Rubin + LPX
基于公开数据的 token 成本推演如下:
Blackwell 世代(2025-2026): H100 的每百万 token 成本约 $0.26(70B FP8,on-demand)。B200 通过 FP8 量化和大 batch 优化降至约 $0.30(看似更高,但吞吐量大幅提升使得实际每 token 成本在优化配置下可降至 $0.16 左右)。GB300 NVL72 的出现带来了规模化效应——NVIDIA 称其相比 Hopper 有 35 倍成本优势。
Rubin 世代(2026-2027): NVIDIA 官方宣称 Vera Rubin NVL72 相比 Blackwell 实现了 10 倍成本下降。如果 GB300 NVL72 的 token 成本是 Hopper 的 1/35,那么 Vera Rubin 的 token 成本大约是 Hopper 的 1/350。但这个数字需要在真实 workload 中验证——MoE 模型的 expert routing overhead、长上下文的 KV Cache 管理、以及多租户场景下的资源竞争都可能侵蚀理论优势。
Rubin + LPX: LPX 的加入主要在 decode 阶段进一步降低成本。对于 decode-heavy 的 Agentic workload,LPU 的 SRAM 带宽优势意味着每 watt 的 token 产出更高。粗略估算,相比纯 Rubin 方案,LPX 可以将 decode 阶段的每 token 成本再降低 2-3 倍(取决于 decode 占比)。
NVIDIA 推荐的 GPU-to-LPU 部署比例是 3:1,即约 25% 的推理计算预算投入 LPU。这个比例对应的是以 dense LLM 推理(7B-70B)为主的 workload。对于 MoE 大模型(万亿参数级),LPU 的占比可能需要更高——因为更多的 FFN/MoE expert 层需要 LPU 的带宽来加速。
6.4 Rubin 出货占比下修:29% → 22% 的信号
SemiAnalysis 报告指出,Rubin 的出货占比从先前预期的 29% 下修至 22%。这个调整的含义是多重的:
乐观解读: Blackwell(B200/B300/GB300)的需求超预期,客户在 Rubin 成熟之前大量采购 Blackwell 系统。这意味着 AI 推理的市场需求在加速增长,现有硬件的消化能力强于预期。
审慎解读: Rubin 的量产爬坡遇到了预期外的困难——可能是 HBM4 供应链瓶颈、液冷基础设施不足、或是软件栈成熟度不够。LPX 作为 Rubin 平台的一部分,其出货节奏直接受 Rubin 整体进度影响。如果 Rubin 延后,LPX 也会延后。
6.5 实际部署约束
LPX 的理论性能很漂亮,但实际部署面临三重约束:
HBM4 供应链。 Vera Rubin GPU 需要 HBM4,而 HBM4 的产能爬坡慢于预期。三星和 SK 海力士的 HBM4 产线在 2026 年仍处于早期阶段。如果 GPU 的 HBM4 供应不足,即使 LPX 机架就绪,整个异构系统也无法满负荷运行——因为 GPU 负责 prefill 和 attention,没有 GPU 就没有完整的推理流水线。
液冷工程。 LPX 机架的全液冷设计要求数据中心具备相应的液冷基础设施。全球能够支持 100 kW+ 机柜密度的数据中心比例仍然很低(估计 < 15%)。液冷的 capex 投入和运维复杂度构成了部署门槛。
FPGA 编程复杂度。 如前所述,FPGA 调度逻辑的开发和维护需要稀缺的专业人才。如果 NVIDIA 不能将 FPGA 的可编程性充分抽象化(通过工具链和自动化),LPX 的软件适配成本将成为大规模部署的障碍。
6.6 与纯 GPU 方案的 ROI 对比
最终的问题是:继续堆 GPU(B300/GB300),还是投资 GPU+LPU 异构方案?
纯 GPU 方案的优势是简单和灵活。同一套 GPU 集群可以跑训练、推理、fine-tuning、multimodal——没有任何 workload 被排除在外。Blackwell Ultra(B300)和 GB300 NVL72 已经在 Agentic AI 场景下实现了显著的效率提升。
GPU+LPU 方案的优势是 decode 阶段的极致效率。对于 decode 占比 > 80% 的 Agentic workload,LPU 的 SRAM 带宽可以将每 watt 的 token 产出提升一个数量级。但代价是架构复杂性(两套硬件、异构调度、FPGA 编程)和 workload 限制(LPX 只能跑 LLM decode,不能跑训练和 prefill)。
ROI 的临界点在于: 你的推理 workload 是否足够 decode-heavy、是否以 MoE 模型为主、是否需要 1000+ tokens/s 的交互速度。如果答案都是"是",GPU+LPU 的投资回报周期可能在 12-18 个月内转正。如果 workload 多样化、模型尺寸跨幅大、或 batch-oriented 推理占主流,纯 GPU 方案在总拥有成本上可能仍然更优。
一个务实的部署策略是 NVIDIA 推荐的 3:1 混合比例——75% GPU、25% LPU。这样可以在不牺牲灵活性的前提下,对最 latency-sensitive 的 decode workload 获得专用加速。随着 LPX 的软件生态成熟和定价公开,这个比例可以根据实际 ROI 数据动态调整。
七、供应链与市场格局
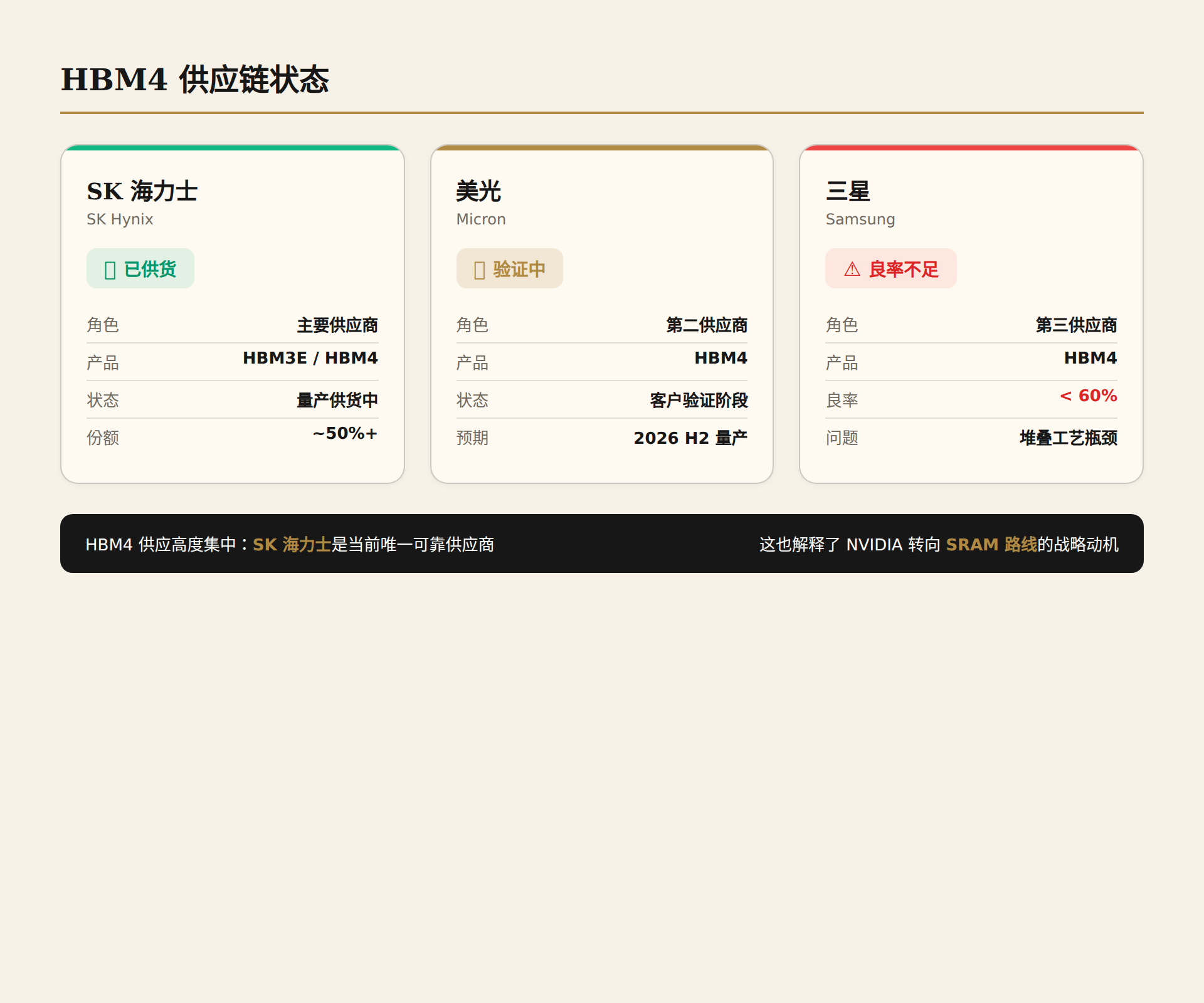
HBM4:卡住Rubin脖子的第一个瓶颈
NVIDIA在2025年下半年将HBM4的单引脚速率目标从8Gbps激进提升至11.7Gbps——一个接近物理极限的数字。三大供应商被迫重新验证,量产节奏随之打乱。
截至2026年5月,局面呈现明显的梯队分化:
- SK海力士进展最快,2026 Q1已向NVIDIA供货,验证顺利推进,基本锁定首批HBM4主力供应商的位置。
- 美光进入高量产阶段,但验证节奏落后一个身位。
- 三星是最大变量:内部验证已通过并提供了客户样品,但DRAM良率仍低于60%——距离量产门槛的70%有相当距离。如果三星不能在Q2末之前将良率拉到合格线,NVIDIA的HBM4总供应量将被压缩约三分之一。
这个缺口正在迫使NVIDIA做出一个不太情愿的妥协:考虑接受次高速版本的HBM4。这意味着部分Rubin GPU可能以低于设计规格的内存带宽出货,性能随之打折。对于一个以"Token成本降至Blackwell十分之一"为核心卖点的平台来说,内存带宽的任何缩水都直接影响经济模型。
三家供应商预计2026 Q2末完成全部验证。如果时间线再次滑移,Rubin的Q3大规模出货计划将面临实质性风险。
Rubin出货占比下修:从29%到22%
出货占比从29%下修至22%,表面看是7个百分点的微调,实际影响远大于此:
- 绝对数量:以NVIDIA FY2027数据中心收入基准计算,7个百分点对应约$50-70亿的营收延迟确认。
- 客户信心:微软、谷歌、亚马逊、Meta、Oracle五家首批客户已经签订了交付窗口。下修意味着部分客户将不得不延长Blackwell的运行周期,或转向ASIC方案补位。
- 机会成本:推迟的Rubin出货窗口正是Google TPU v6e和Amazon Trainium3加速渗透的时段。每一周的延迟都在把潜在客户推向自研ASIC。
下修的根本原因不仅仅是HBM4验证。液冷工程复杂度是另一个被低估的制约因素——Vera Rubin NVL72机架功耗超过120kW,对数据中心的液冷基础设施提出了前所未有的要求。部分客户的数据中心改造进度跟不上芯片交付进度,形成了"芯片到了但机房没准备好"的尴尬局面。
SOCAMM2:CPU侧的内存革命
在GPU侧的HBM4抢尽注意力的同时,NVIDIA悄然推进了一个可能改变AI服务器内存架构的新标准:SOCAMM2。
SOCAMM2(Small Outline Compute Accelerated Memory Module 2)由NVIDIA主导,与三星、SK海力士、美光联合开发。核心参数:
- 基于LPDDR5X,128bit位宽,8533 MT/s
- 单模块容量128GB
- 成本约为HBM的1/4
- 可更换、可扩容——这一点在HBM世界不可想象
SOCAMM2的定位不是替代HBM,而是为CPU侧提供大规模数据缓存。Vera CPU配备256GB SOCAMM2,为数据预处理、模型加载、KV Cache管理提供了充裕的低成本内存空间。
这是一个聪明的分层策略:用HBM服务GPU计算核心的带宽饥饿,用SOCAMM2填充CPU侧的容量缺口,两者之间通过NVLink-C2C互联。成本结构由此优化——如果把256GB全用HBM实现,仅CPU侧内存成本就接近$8000;换成SOCAMM2,成本降至$2000以下。
富士康产能扩张:从1000到2000
富士康正在执行一项激进的产能扩张计划:将AI服务器机架的周产能从1000台提升至2000台。这不仅仅是产线的线性扩张——它要求:
- 液冷组装线的成倍扩充,每台Vera Rubin NVL72机架需要定制化的冷板和管路安装
- 测试产能的同步提升,72颗GPU+36颗CPU的互联测试单台耗时超过48小时
- 供应链协同:台积电N3P产线的Rubin芯片产出、三星4nm的LPU芯片产出、HBM4供应,三条线必须对齐到周级别的交付节奏
富士康同时承担了Groq 3 LPX计算托盘的独家代工,并负责机柜组装的主要份额。2026年预计交付6000台LPX机架,2027年再追加10000台。这意味着富士康在AI服务器代工中的角色正在从"组装厂"向"系统级集成商"跃迁。
国内对标:元川微的LPU+
在NVIDIA + Groq之外,中国的LPU赛道正在出现第一个有分量的选手:元川微。
2026年4月,元川微完成数亿元天使轮融资。投资方包括东方嘉富、元禾原点(十年前投了寒武纪)、峰瑞资本。创始人杨滨拥有22年华为无线基带经验——这个背景值得关注:基带处理器本质上就是一种高吞吐、确定性的信号处理芯片,其设计哲学与LPU的确定性执行模型天然契合。
元川微的LPU+芯片宣称原生支持大语言模型、MoE架构和多模态推理。与Groq从推理加速切入的路径不同,LPU+试图在架构层面为MoE的稀疏专家路由提供硬件级支持,这意味着在DeepSeek、Qwen等国产MoE模型上可能有更高的效率优势。
但现实挑战同样明显:Groq拥有NVIDIA的软件生态(NVFusion、Dynamo)和全球顶级客户背书;元川微需要从零构建软件栈,并在国内算力市场的价格战中找到利润空间。台积电CoWoS产能中,国内客户的份额仍然有限,先进封装可能成为另一个瓶颈。
推理市场格局:从GPU垄断到双轨制
CPX之死和LPU上位,正在改变AI基础设施的采购逻辑。
过去,推理和训练共享同一套GPU基础设施,区别只在batch size和精度设置。NVIDIA的垄断地位无人撼动。但LPU的出现意味着推理第一次有了专用硬件的经济合理性。
对于超大规模云厂商,新的采购决策树正在成形:
- 训练:继续使用GPU(Rubin NVL72),HBM的高带宽不可替代
- Prefill(首Token生成):GPU的算力优势仍然明显,特别是大batch场景
- Decode(逐Token解码):LPU的SRAM架构和确定性执行提供10倍以上的吞吐优势
NVIDIA正在从一个"GPU垄断者"转变为"GPU+LPU双轨供应商"。这个转变对NVIDIA自身的组织、定价策略和客户关系都是全新的考验。Jon Peddie的评价精准到位:"LPU不与GPU竞争,而是补完。"
而对推理市场的后来者——Cerebras($950亿市值IPO)、SambaNova、以及元川微——来说,NVIDIA自我革命比NVIDIA顽固防守更有利:它验证了专用推理硬件的市场存在性,教育了客户,打开了采购预算的品类窗口。
八、前瞻:Feynman与CPO的终极融合(2028+)
一个芯片,两种灵魂
如果说Vera Rubin是NVIDIA学习如何让GPU和LPU共存的第一步,那么Feynman架构就是终极答案:不是让两种芯片在同一机架里协作,而是把它们做进同一颗芯片。
Feynman基于台积电A16工艺——1.6nm,全球首款1nm以下AI芯片。GAA(Gate-All-Around)晶体管提供比FinFET更精确的电流控制,SPR(Super Power Rail)背面供电技术将电源网络从晶体管正面移到背面,释放出宝贵的布线资源。
这些听起来像工艺节点的常规进步。但A16对Feynman的真正意义在于:背面供电释放的正面空间,为3D堆叠提供了物理条件。
SoIC混合键合:LPU叠在GPU之上
Feynman的核心架构创新是SoIC(System on Integrated Chips)混合键合——将Groq LPU的计算单元直接堆叠在GPU主芯片之上。
这不是简单的芯片封装,而是两个功能完全不同的计算架构在硅层面的垂直整合:
- 底层(GPU die):负责训练和Prefill,高带宽计算,通过HBM获取模型权重
- 顶层(LPU die):负责Decode,大量SRAM提供确定性高速推理,无HBM依赖
- 层间互连:SoIC混合键合的互连密度达到μm级别,层间带宽远超任何板级互联方案
垂直堆叠解决了Vera Rubin架构中GPU和LPU之间通过FPGA和NVLink连接的延迟和带宽瓶颈。物理距离从"机架内跨板"缩短到"同一颗芯片内μm级跨层",延迟下降几个数量级。
理论推理性能达到50 PFLOPS——与Blackwell相比提升5倍。注意这个数字的含义:它不是单靠工艺微缩带来的性能增益,而是架构范式转换的成果。
CPO硅光互连:铜缆的终结者
Feynman架构的另一条腿是CPO(Co-Packaged Optics,共封装光学)。
当单芯片功耗突破2000W、单机架功耗超过150kW时,铜缆互连的物理极限已经成为不可回避的瓶颈。信号衰减、功耗、体积、散热——铜在每一个维度都在逼近物理边界。
CPO用硅光子技术替代铜缆:
- 传输损耗降低60%:光信号在硅波导中的衰减远低于电信号在铜线中的衰减
- 能耗降低70%以上:不需要信号放大和均衡电路
- 带宽密度提升:单光纤可承载多个波长的信号,等效带宽远超铜缆
- 物理体积缩减:光纤替代铜缆,机架内布线空间大幅释放
CPO在Feynman中的角色不仅是GPU之间的互联,更是GPU+LPU垂直堆叠芯片之间的外部扩展互联。当一颗Feynman芯片同时包含GPU和LPU的完整推理能力时,多颗Feynman芯片之间的协同通信需要CPO级别的带宽和能效。
金刚石散热:2000W的现实挑战
单芯片功耗突破2000W意味着什么?
当前最先进的直接芯片液冷(DLC)方案在1000W左右已经接近实用的舒适区。2000W将散热推入未知领域。Feynman引入了金刚石散热方案——利用人造金刚石极高的热导率(~2000 W/m·K,铜的5倍)作为芯片与冷板之间的热界面材料。
金刚石散热在实验室中已验证可行性,但在大规模量产中的成本和可靠性仍是问号。人造金刚石的成本在快速下降,但与传统的热界面材料(TIM)相比仍然高出一个数量级。NVIDIA需要在散热性能和量产成本之间找到平衡点。
英特尔的参与:EMIB封装
一个容易被忽视的细节:NVIDIA对英特尔$50亿战略投资正在结出果实。英特尔EMIB(Embedded Multi-die Interconnect Bridge)封装技术将参与Feynman约25%的封装任务。
EMIB是一种高密度硅桥接技术,在有机封装基板中嵌入小型硅芯片,提供芯片之间的高密度互连。与台积电的CoWoS相比,EMIB在中等互连密度场景下有成本优势,且不需要整个封装都使用硅中介层。
NVIDIA让英特尔分担约四分之一的封装任务,既是产能多元化(降低对台积电CoWoS产能的单一依赖),也是地缘政治风险管理。但这也意味着Feynman的封装良率将同时受台积电和英特尔两家工艺能力的影响——质量管控的复杂度显著上升。
工程挑战清单
Feynman在2028年的落地面临三重工程挑战:
1. 散热密度。 3D堆叠将两个热源叠在一起,局部热流密度可能超过100 W/cm²。即使使用金刚石散热,如何将热量从LPU层穿过GPU层传导到冷板,是一个尚未被完全解决的问题。
2. CUDA兼容性。 LPU使用确定性执行模型,与传统GPU的SIMT架构有根本差异。NVFusion软件层需要确保现有的CUDA程序能透明地利用LPU资源,而不需要开发者重写代码。这个"透明性"的完成度将直接决定Feynman的生态壁垒。
3. 良率。 3D堆叠意味着两个die的良率相乘。如果GPU die良率80%,LPU die良率90%,堆叠后的整体良率只有72%。在A16工艺的初期阶段,单个die的良率可能远低于80%,堆叠后的有效产出率可能低到令人不安。
九、总结与判断
CPX之死的深层含义
2025年9月,NVIDIA发布Rubin CPX——一颗使用GDDR7内存、专门面向大规模上下文推理的GPU。五个月后,CPX从路线图上消失,被Groq 3 LPU替代。
表面看,这是一次产品线调整。深层看,这是NVIDIA第一次正式承认:推理需要专用架构,而不是"降配版训练GPU"。
CPX的设计思路是传统的:用更便宜的内存(GDDR7替代HBM)降低推理成本。但它仍然是一颗GPU,仍然受制于SIMT架构的并行调度模型,仍然在Decode阶段面临内存带宽瓶颈。
LPU用一种完全不同的方式解决问题:抛弃HBM,用大量片上SRAM实现确定性内存访问;抛弃并行调度,用确定性执行消除调度开销。这不是"更好的GPU",而是"另一种东西"。
NVIDIA花$200亿收购Groq来换取这个认知转型,代价不菲。但比起在错误路线上继续投入CPX产品线的工程资源,这个学费值得。
LPU是互补,不是替代
一个正在成形的市场共识是:LPU不会取代GPU,而是与之形成功能互补。
- GPU擅长:训练、Prefill、高吞吐计算、灵活的模型适配
- LPU擅长:Decode、低延迟推理、确定性吞吐、长上下文处理
这种互补关系改变了AI基础设施的采购逻辑。过去,CTO/VP级别的算力采购决策是"买多少GPU"。现在,决策变成了"训练集群买多少GPU、推理集群买多少GPU+LPU的组合比例"。
NVIDIA Dynamo软件栈正在将这个组合自动化:GPU负责Prefill(注意力计算),LPU专注Decode(逐Token生成),中间的AFD(Attention-FFN Disaggregation)机制在两者之间动态调度工作负载。从用户视角看,这是一个统一的推理服务;从硬件视角看,它是两种完全不同的芯片在协作。
短期风险(未来6个月)
HBM4供应链是最大的短期风险。三星良率如果不能在Q2末突破70%门槛,NVIDIA将被迫接受次高速HBM4,Rubin的实际性能和成本竞争力都会打折扣。
FPGA成本是一个被低估的隐性成本。Groq 3 LPX机架每台标配32颗FPGA,单颗$1.2万,单机架FPGA硬件成本高达$38.4万。在一个标价数百万美元的机架中,这个比例可能看起来不大,但它意味着LPX的成本结构中有一块是无法通过芯片量产摊薄的——FPGA是可编程器件,单颗成本相对固定。
软件成熟度是第三个短期风险。NVFusion和Dynamo都是新软件栈,需要时间在生产环境中打磨。Groq被收购仅4个月就完成产品化,被称为"半导体史上最快产品化"——快是好事情,但快也意味着实战验证不足。
中期看点(2026 Q3-Q4)
2026 Q3 LPX首批部署的实际性能数据将是关键观察窗口。6000台LPX机架的部署将产生第一批真实世界的benchmark数据:
- 实际Token吞吐与理论值的差距
- LPU与GPU协同(AFD)的延迟表现
- 液冷系统的长期稳定性
- 不同模型架构(稠密 vs MoE)的效率差异
这些数据将决定LPX是"继续扩大部署"还是"需要大幅调整"。对于正在评估推理基础设施的CTO来说,Q3的数据比任何产品宣讲都有说服力。
长期赌注(2028+)
Feynman的3D堆叠能否真正解决GPU+LPU的物理距离问题?
这是NVIDIA在AI推理领域的终极赌注。如果SoIC混合键合和CPO硅光互连能够按计划在2028年落地,NVIDIA将拥有一个在单一芯片内同时覆盖训练和推理的完整方案,彻底消除GPU和LPU之间的互联延迟。
但这个赌注的风险同样极端:
- A16工艺的量产良率尚不可知
- 3D堆叠将散热问题从"平面"升级为"立体"
- 金刚石散热的量产成本仍是未知数
- 英特尔EMIB与台积电SoIC的混合封装质量管控
如果Feynman成功,NVIDIA将在推理领域建立一代人的技术领先。如果失败——或延迟到2029-2030——竞争对手(Google TPU、Cerebras、乃至国内的元川微)将获得2-3年的窗口期来建立自己的推理生态。
最后的判断
NVIDIA正在做一件困难但正确的事情:用收购和自我颠覆来避免被颠覆。 $200亿收购Groq不是一个防御性动作,而是一次进攻性的架构重构——把推理从一个"GPU降配任务"升级为一个需要专用硬件的核心业务。
CPX之死不是失败,是学习。LPU上位不是权宜,是方向。Feynman不是愿景,是赌注。
对于观察者来说,2026年Q3将是验证这一切的第一个真实数据点。在那之前,所有的50 PFLOPS和2000W都是纸面上的数字。
附录
附录A:Vera Rubin NVL72 完整规格表
| 参数 | 规格 |
|---|---|
| GPU | |
| 芯片名称 | Rubin GPU |
| 制程 | 台积电 3nm (N3P) |
| 晶体管数量 | 3360亿 |
| 内存 | 288GB HBM4 |
| 内存带宽 | 22 TB/s |
| 互联 | NVLink 6,单GPU双向3.6 TB/s |
| 推理性能 (FP4) | 50 PFLOPS |
| 训练性能 | 35 PFLOPS |
| CPU | |
| 芯片名称 | Vera CPU |
| 架构 | 88核 Olympus (Armv9.2) |
| 互联 | NVLink-C2C |
| 内存 | 256GB SOCAMM2 LPDDR5X |
| 系统 | |
| GPU数量 | 72颗 Rubin GPU |
| CPU数量 | 36颗 Vera CPU |
| 系统互联 | 72 GPU无阻塞NVLink通信 |
| Token成本 | Blackwell的1/10 |
| 2026年预计出货 | ~12,000台 NVL72 |
| 单机架价格 | 约$1.8亿 |
附录B:Groq 3 LPU / LPX机架规格表
| 参数 | 规格 |
|---|---|
| LPU芯片 | |
| 芯片名称 | Groq 3 LPU |
| 制程 | 三星 4nm |
| 晶体管数量 | 980亿 |
| 片上SRAM | 500MB |
| 外部内存 | 无HBM |
| 芯片带宽 | 150 TB/s(HBM4的7倍) |
| FP8算力 | 1.2 PFLOPS |
| 首 Token延迟 | < 0.1s |
| C2C链路 | 96条 112Gbps |
| LPX机架 | |
| FPGA数量 | 32颗/机架(每计算托盘1颗) |
| 单颗FPGA价值 | ~$1.2万 |
| 单机架FPGA总成本 | ~$38.4万 |
| 代工 | 富士康独家(计算托盘) |
| 交付计划 | |
| 2026年出货 | 6000台 LPX机架 |
| 2027年出货 | 10000台 LPX机架 |
| 2026年芯片出货 | 150万颗 (LP30+LP35) |
| 2027年芯片出货 | 250万颗 |
| 2027年下一代 | LP40(支持NVLink) |
附录C:NVLink带宽演进表
| 世代 | NVLink版本 | 单GPU双向带宽 | 对应平台 | 时间 |
|---|---|---|---|---|
| NVLink 4 | 4.0 | 900 GB/s | Hopper H100 | 2024 |
| NVLink 5 | 5.0 | 1.8 TB/s | Blackwell B200 | 2025 |
| NVLink 6 | 6.0 | 3.6 TB/s | Vera Rubin NVL72 | 2026 H2 |
| NVLink 7(预计) | 7.0 | ~7.2 TB/s(预估) | Feynman | 2028+ |
注:NVLink每代带宽基本翻倍。NVLink 7尚未官方确认,基于NVLink 6的翻倍趋势推算。
附录D:关键术语表
| 术语 | 全称 | 说明 |
|---|---|---|
| LPU | Language Processing Unit | 专用语言推理芯片,使用SRAM而非HBM,确定性执行模型,面向Decode场景优化 |
| AFD | Attention-FFN Disaggregation | 注意力-前馈分离,GPU负责Prefill(注意力计算),LPU负责Decode(FFN计算) |
| CPO | Co-Packaged Optics | 共封装光学,将硅光子器件与计算芯片封装在一起,替代铜缆互联 |
| SOCAMM2 | Small Outline Compute Accelerated Memory Module 2 | 基于LPDDR5X的模块化内存标准,成本约HBM的1/4,面向CPU侧大规模缓存 |
| NVFusion | NVIDIA Fusion | NVIDIA软件中间层,使LPU无缝嵌入CUDA生态,对开发者透明 |
| SPR | Super Power Rail | 台积电A16工艺的背面供电技术,将电源网络从晶体管正面移至背面 |
| SoIC | System on Integrated Chips | 台积电3D堆叠技术,通过混合键合实现芯片间μm级高密度互连 |
| EMIB | Embedded Multi-die Interconnect Bridge | 英特尔封装技术,在有机基板中嵌入硅桥接实现高密度die间互连 |
| GAA | Gate-All-Around | 全环绕栅极晶体管,A16工艺采用的晶体管架构,比FinFET有更精确的电流控制 |
| Dynamo | NVIDIA Dynamo | NVIDIA推理编排框架,支持多轮Agentic推理,Streaming Tokens + Tools |
| NVL | NVLink | NVIDIA GPU互联架构,NVL72表示72颗GPU通过NVLink全互联 |
| CPX | Context Processing eXtension | 已取消的Rubin推理GPU方案,使用GDDR7内存,2026-03被LPU替代 |
| DLC | Direct Liquid Cooling | 直接芯片液冷,将冷却液直接导向芯片表面的散热方案 |
| CoWoS | Chip on Wafer on Substrate | 台积电先进封装技术,2.5D硅中介层实现多芯片高密度集成 |
| PD分离 | Prefill-Decode Disaggregation | 将推理的Prefill和Decode阶段分配到不同硬件,由UCSD Hao AI Lab首创 |