Jalapeño 拆解:当 AI 公司开始造自己的心脏
2026 年 6 月 24 日,OpenAI 与博通联合发布首款自研 AI 推理芯片 Jalapeño。从架构到流片仅 9 个月,推理成本预计降低约 50%,性能对标 NVIDIA Blackwell 与 Google TPU。2026 年底部署,2029 年建成 10GW 算力集群。这颗芯片不只是一颗芯片。它是 OpenAI 从"模型公司"迈向"AI 全栈公司"的关键一跃,也是 AI 行业供应链逻辑被改写的起点。
引言:从 ChatGPT 到 Jalapeño 的三年半
时间回到 2022 年 11 月 30 日。ChatGPT 上线那天,OpenAI 还是一家"模型公司"。算力来自微软 Azure 的 NVIDIA GPU 集群,训练好的模型通过 OpenAI 的 API 暴露给世界。那时候没人想到,三年半后的同一家公司会站在博通的硅谷办公室里,从 Hock Tan 手中接过自己设计的晶圆。
但 Jalapeño 的故事不是"AI 公司突然有了造芯能力"。它是过去几年一系列决策的最终落地:
- 2023 年底:Richard Ho(Google Cloud TPU 团队核心工程师)加入 OpenAI,组建芯片团队
- 2024 年中:OpenAI 与博通开始秘密联合研发(18 个月周期的"前置阶段")
- 2025 年 10 月:双方公开战略合作。数十亿美元,10GW 算力部署目标
- 2026 年 6 月 24 日:Jalapeño 正式发布,工程样片已在 GPT-5.3-Codex-Spark 上跑通
这颗芯片的命名——Jalapeño(墨西哥辣椒)——延续了 Google TPU 用零食命名的传统(Boardwalk、Bristlecone、Trillium),也带着 OpenAI 一贯的"看似随意实则精心"的品牌感。它的命名风格注定让它很难像"B100"或"MI300X"那样严肃,但它的战略意义远超命名能传达的。
这篇文章会拆解 Jalapeño 的:
- 设计者。Google TPU 灵魂人物 + 40 人极简团队 + 博通工程力
- 制造。TSMC 3nm + 博通硅实现 + Celestica 系统集成
- 定位。为什么只做推理、不做训练是商业上唯一正确的选择
- 架构与规格。脉动阵列、HBM、Arm CPU、Tomahawk 互联
- 工艺与算力推算。对照 Google TPU v7/v8 与 Blackwell 的算力、能效、HBM
- 芯片物理分析。3nm、Die Size、晶体管数、封装、散热与内存层级
- 软件适配。垂直整合优势与生态封闭代价
- 横向对比。vs NVIDIA Blackwell / Google TPU v7-v8 / AWS Trainium3 / Microsoft Maia 200
- 国内大厂全景。阿里平头哥真武、字节买买买、DeepSeek 模型闭环、智谱全栈适配
- 结论。AI 公司的下一个形态
一、设计者:从 Google TPU 走出的灵魂人物

核心工程师 Richard Ho(理查德·何)
Jalapeño 的灵魂人物是 OpenAI 硬件项目负责人 Richard Ho。他此前在 Google 工作近九年,是 Cloud TPU 项目的核心架构师之一,主导了从 TPU v1 到 v4 的多代芯片从概念走向量产。
Richard Ho 的关键背景:
- 2014–2023:Google TPU 团队,是脉动阵列架构、内存层级、片上网络等关键模块的设计者
- 见证 TPU v1 (2016) 到 TPU v7 Ironwood (2025) 的全部演进
- 对"为什么 ASIC 路线能跑通""为什么需要 Tomahawk 级互联""为什么 HBM 选型如此关键"有最直接的工程理解
2023 年底,Sam Altman 开始大规模从 Google TPU 团队挖人。Richard Ho 正是这一时期加入 OpenAI,并牵头组建了 Jalapeño 团队。
这一人事流向的信号非常清晰:OpenAI 知道 ASIC 路线的可行性,但需要的是已经从 TPU 学到所有教训的人,而不是从零开始的探索者。Richard Ho 知道哪些坑不该踩。
OpenAI 芯片团队:40 人极简架构
截至发布时,OpenAI 芯片团队约 40 人。这个数字有几个对比维度:
| 团队 | 规模 | 备注 |
|---|---|---|
| OpenAI Jalapeño 团队 | ~40 人 | 架构设计 |
| Google TPU 团队 | 数千人 | 含编译器、软件、验证 |
| NVIDIA GPU 设计团队 | 数万人 | 横跨多个产品线 |
| Apple Silicon 团队 | 数千人 | 含 SoC、GPU、神经引擎 |
40 人为什么能造芯片?
因为 OpenAI 的 40 人只做一件事。架构定义和算法-硬件协同设计。RTL-to-GDS(从可综合代码到物理版图)的全部硅实现工作由博通的数百人团队承担。这种"OpenAI 定义'做什么',博通实现'怎么做'"的分工,是当前 AI 芯片行业最高效的造芯模式。
博通(Broadcom):真正的硅实现力量
博通是 ASIC 设计服务的真正巨头:
- 已有客户:Google、Amazon、Meta、字节跳动、Anthropic
- AI ASIC 设计能力:从 Tomahawk 网络芯片到 TPU 物理实现都是博通在做
- 2025 年 10 月:与 OpenAI 签署战略合作,10GW 算力部署目标
- CEO 陈福阳(Hock Tan)亲自督战:发布会上亲手把首批晶圆交到 Sam Altman 手中
博通的角色不只是"代工厂",而是 OpenAI 芯片团队的延伸。从 RTL、验证、综合、布局布线、时序签核,到 Tomahawk 网络芯片的集成,全部由博通完成。
天弘科技(Celestica)
加拿大电子制造服务商,负责板卡、机架和服务器系统的工业化。Celestica 的角色被低估。从芯片到可部署服务器,需要电源管理、散热、PCIe 接口、机箱结构等大量工程,Celestica 是 OpenAI 从"流片成功"到"数据中心可用"的关键桥梁。
二、制造:TSMC 3nm + 博通硅实现
Jalapeño 的制造分工是一个典型的 AI 时代 ASIC 协作网络:
| 环节 | 负责方 | 说明 |
|---|---|---|
| 架构设计 | OpenAI | 白板式设计,围绕 LLM 推理从零构建 |
| 硅片实现(RTL-to-GDS) | Broadcom | 物理设计、时序签核、DFT、可测性设计 |
| 晶圆代工 | TSMC | 3nm (N3) 先进制程 |
| 网络互联 | Broadcom | Tomahawk 网络芯片(机柜/集群互联) |
| 板卡/机架 | Celestica | 从芯片到服务器系统的工业化 |
| HBM 供应 | SK Hynix / Samsung | 高带宽内存(推测 HBM3E 或 HBM4) |
TSMC 3nm 工艺的真实含义
业内对"3nm"这个数字需要脱敏看待。台积电 N3 的真实物理栅极长度已经不再缩小,"3nm"更多是商业命名。但有几个客观可比的数字:
- TSMC N3 相对 N5:逻辑密度 +60-70%,同频功耗 -25-30%
- N3 在台积电的产能极度紧张。Apple、AMD、NVIDIA、MediaTek、博通客户都在抢
- 台积电已对 3-5nm 客户通知涨价 5-10%
对 OpenAI 来说,能在 N3 工艺上拿到流片窗口,本身就是博通长期客户关系带来的隐性资源。
9 个月流片:OpenAI 自称的"史上最快 ASIC 开发周期"
Jalapeño 从架构设计到 tape-out 仅用 9 个月。OpenAI 自称这是"高性能先进半导体领域有史以来最快的 ASIC 开发周期"。对比:
| 对比对象 | 开发周期 |
|---|---|
| OpenAI Jalapeño | 9 个月(架构到流片) |
| Google TPU v1 | ~15 个月(启动到部署) |
| Google TPU v2-v4 | 12-18 个月/代 |
| AWS Trainium v1 → v2 | ~24 个月 |
| Apple M 系列 | 24-36 个月 |
| 传统芯片公司同类项目 | 24-36 个月 |
⚠️ 值得注意:知乎专栏的分析师指出,"9 个月"可能从某个中间节点开始算。OpenAI 与博通的联合研发在 2024 年中就已启动("18 个月秘密研发"是当时媒体的描述),实际架构探索可能更早。把"18 个月"压缩成"9 个月"是 PR 选择,但即便如此仍极快。
"9 个月"的真正含金量
把时间节省拆开看:
| 时间节省来源 | 估算贡献 |
|---|---|
| 18 个月前置架构探索与博通合作铺垫 | 3-4 个月节省(被算入"正式研发") |
| AI 加速 PPA 优化(DSO.ai / Cerebrus 级别工具) | 2-3 个月节省 |
| Broadcom 复用既有 IP(Tomahawk、SerDes、HBM PHY) | 2-3 个月节省 |
| AI 加速验证、热仿真、签核 | 1-2 个月节省 |
| 传统电路设计、流片准备 | 2-3 个月(仍需) |
OpenAI 没有创造奇迹,而是把行业里所有可用的工具用到极致,加上博通的 ASIC 工程复用,最终才压到 9 个月。
三、定位:推理 ASIC,不是训练芯片
"Intelligence Processor"——OpenAI 对自己芯片的命名
这不是营销话术,而是定义了它与 GPU 的本质区别。
Jalapeño 不做训练,只做推理。
| 维度 | 训练 | 推理 |
|---|---|---|
| 目的 | 让模型学习 | 让模型回答问题 |
| 特点 | 一次性、高精度、疯狂算力 | 持续运行、延迟敏感、成本为王 |
| 成本性质 | 资本支出(CAPEX) | 运营支出(OPEX) |
| OpenAI 2025 年 H1 推理支出 | — | 50.2 亿美元 |
| 行业推理占比估计 | — | 训练/推理合计中推理占 60-70%(行业通用估计) |
为什么 2026 年才是推出时机?
2023 年推推理芯片风险太大。模型架构快速迭代(从纯 Transformer 到 MoE、到混合架构),ASIC 造完可能就被新架构淘汰。2026 年 Transformer + MoE 成为主流范式,架构趋于稳定,定制 ASIC 的商业风险降到可接受范围。
三个战略考量:
- 技术成熟度窗口:模型架构稳定,ASIC 不会落后
- 商业压力临界点:推理成本 2025 年突破临界值,必须有降本方案
- 供应链多元化的"地板":摆脱对英伟达的单一依赖
商业逻辑:打破 NVIDIA 依赖
OpenAI 算力基础设施历史:
- 2023–2024:~2 万张 H100(GPT-4 训练 + 推理)
- 2025:H200 + Grace Hopper(GPT-5 训练)
- 2026:B200/GB200(多模态模型训练)
成本结构:2025 年 OpenAI 总支出 340 亿美元,收入 130 亿美元,净亏损 209 亿美元。其中推理 H1 支出 50.2 亿美元(年化约 100 亿),约占总支出 30%(OpenAI 自身口径);行业通用估计是推理占总 AI 运营成本 60-70%。两个口径差距主要来自"AI 运营成本"是只算推理、还是含训练。CFO Sarah Friar 警告:如果收入增速追不上数据中心合同扩张速度,到 2028 年算力成本可能飙升至 850 亿美元。
Jalapeño 直接瞄准最频繁、最费钱的环节。推理。如果按 Hock Tan 的口径"成本降低 50%",意味着:
- 单 token 成本减半 → ChatGPT 免费用户的服务能力翻倍
- 同样预算可服务更多用户 → 直接影响 OpenAI 的盈亏平衡点
- 同等条件下腾出预算给训练侧(仍买 NVIDIA GPU)→ 整体算力扩张更快
四、架构与规格:脉动阵列、HBM、Arm CPU、Tomahawk 互联
核心架构:脉动阵列(Systolic Array)
脉动阵列是 Google TPU v1 (2016) 开创的 AI 加速器架构,名字取自心脏收缩(systole)—— 数据像血液一样规律地在处理单元(PE)之间流动,每个 PE 反复做同一件事(典型是乘加)。
OpenAI 选 systolic array,是继续押注已经被谷歌验证过的范式,而不是冒险试新。
脉动阵列对稠密模型推理的好处
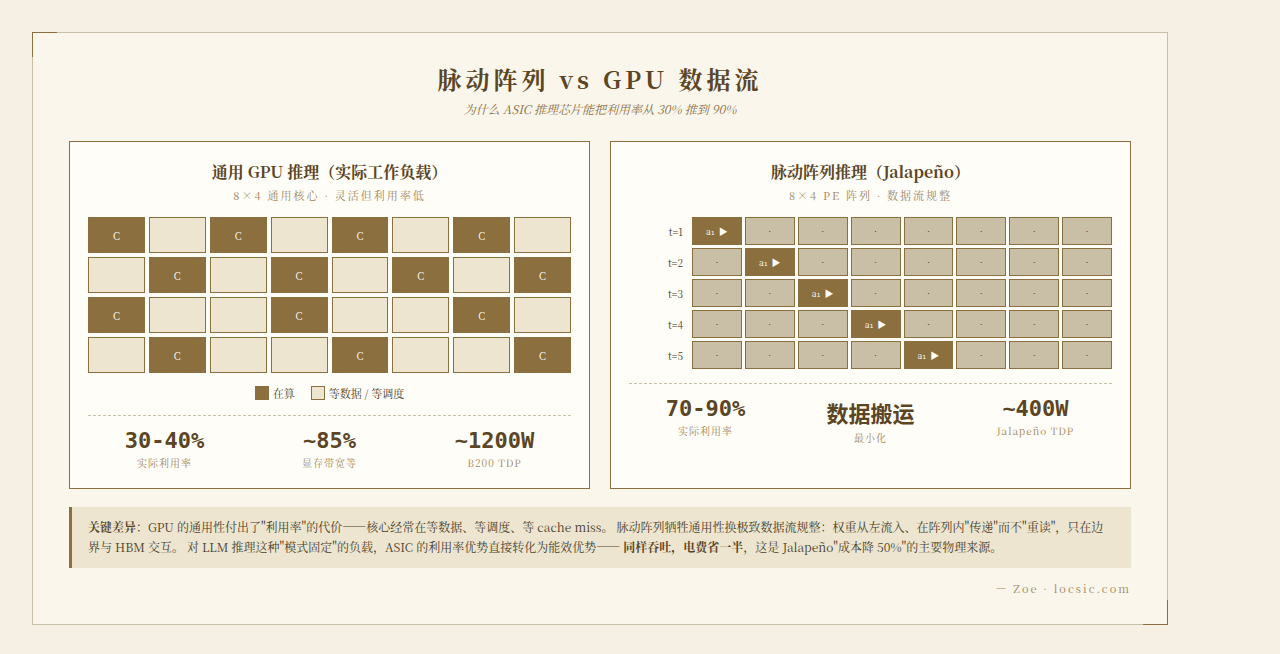
稠密模型(如 Llama-3-70B 风格)每次推理时所有参数都参与计算。
- 数据搬运最小化
- 传统 GPU:每个 CUDA core 都需要独立的寄存器读写
- 脉动阵列:权重从左侧流入,在阵列内"传递"而不"重读",只在边界与 HBM 交互
- 减少数据搬运 = 直接省功耗 = 提升每瓦性能
- 计算密度极致
- 一个 128×128 systolic array = 16,384 个 MAC 单元,全部同时工作
- 频率不需要很高,但每秒可完成 ~3.3 万亿次 INT8 运算
- 适合 Transformer 中"矩阵乘 → 矩阵乘 → 矩阵乘"的重复模式
- 数据流规整
- 推理阶段的 batch size、序列长度都相对稳定
- 不需要 GPU 那种"任何计算模式都能跑"的灵活性
- 硬件利用率可以稳定在 70-90%(远高于 GPU 的 30-40%)
脉动阵列对 MoE 模型推理的匹配与冲突

OpenAI 的 GPT-4 / GPT-5 / GPT-5.3 全部基于 MoE 架构。MoE 有两个关键特征:
- 稀疏激活:1.8 万亿参数总量,但每个 token 只激活 2%(约 360 亿参数)
- 专家路由:每个 token 由 Router 动态选择 Top-K 个专家(典型 K=2~8)
匹配的部分
- 局部矩阵乘仍然主导计算量
- 即使是 MoE,被激活的专家内部的 FFN 计算仍然是巨大的矩阵乘
- DeepSeek-R1 的每个激活专家 FFN:~50B 参数 × batch × seq_len
- 这部分完全适合 systolic array 的高密度矩阵乘
- 专家内计算是规整的
- 一旦 Router 决定了激活哪些专家,后续的矩阵乘路径是确定的
- 软硬件可以提前"预热"对应的脉动阵列区域
- 这种预判性 + 局部规整性正是 systolic array 的甜区
- KV Cache 复用友好
- MoE 推理中,注意力层(attention)的 KV Cache 在所有专家间共享
- 脉动阵列的数据流模型非常适合"权重驻留、KV 数据流动"的 attention 计算
冲突的部分
- 专家路由的动态性
- 不同 token 走不同的专家 → 阵列利用率可能剧烈波动
- 如果 K=2,可能只有 25% 的阵列在忙
- 应对:硬件上预留"专家广播总线",让阵列各部分加载不同专家的权重;或 token 排序后 batch 调度
- 通信开销加大
- MoE 的"专家并行"(Expert Parallelism)天然要求跨卡通信
- 路由决定后,被激活的专家可能在不同芯片上
- 这就是为什么 OpenAI 必须用 Broadcom Tomahawk(高速互联)做大规模集群
- 负载不均衡
- Router 的概率分布可能导致某些专家被频繁选中
- 需要"硬截断 + 重路由"机制
- 脉动阵列对这种不均衡比较敏感,因为 PE 阵列是物理固定的
Jalapeño 的应对策略推测
虽然没有公开 ISA 文档,但从 OpenAI 强调"为 LLM 推理从零设计"可推测:
- 阵列规模可能不是单一超大阵列,而是多个中等规模脉动阵列(比如 8-16 个 64×64 子阵列)
- 可根据路由结果灵活分配专家到不同子阵列
- Tomahawk 网络芯片支持大规模 expert parallelism,把"硬件稀疏"延伸到"集群稀疏"
已确认的技术细节
| 项目 | 推测值/确认 |
|---|---|
| 制程 | TSMC N3 |
| 核心架构 | 脉动阵列 (Systolic Array) |
| 内存 | HBM3E 或 HBM4(推测 80-144GB) |
| 任务调度 CPU | Arm 定制设计 |
| 网络互联 | Broadcom Tomahawk 系列交换芯片 |
| 理论算力(推测) | ~10-13 PFLOPS(INT8/FP8) |
| 单 Token 能耗 | 较 Blackwell 降低 ~30% |
| 推理成本降幅 | 约 50%(Hock Tan 原话) |
四大优化维度(Richard Ho 原话)
OpenAI 硬件负责人强调,Jalapeño 围绕四个维度做了全面优化:
- 内核(Kernel)。为 LLM 核心算子(矩阵乘、attention)做硬件级硬编码
- 内存传输(Memory Movement)。减少数据在 HBM 与计算单元之间的搬运
- 网络(Network)。通过 Tomahawk 实现大规模集群的低延迟互联
- 服务模式(Service Model)。针对在线推理的批处理、KV Cache 驻留等做协同优化
这四大优化让芯片的实际利用率逼近理论峰值,而不像 GPU 那样"峰值高、利用率低(30-40%)"。
五、工艺与算力推算:对照 Google TPU v7/v8
工艺推算基础
TSMC N3 相对 N5:逻辑密度 +60-70%,同频功耗 -25-30%。这是一个客观基准,对所有用 N3 的厂商都适用。
Google TPU 已知关键数据
| 芯片 | 发布时间 | 工艺 | FP8 算力/颗 | HBM | 集群规模 | 备注 |
|---|---|---|---|---|---|---|
| TPU v6 Trillium | 2024.5 | 5nm | ~1 PFLOPS | 32GB | 256 卡 | 较 v5e 性能 +4.7x |
| TPU v7 Ironwood | 2025.11 | TSMC 3nm | 4.6 PFLOPS | 192GB HBM3E | 9,216 卡 (42.5 EFLOPS) | 100% 液冷,单卡功耗 ~980W |
| TPU 8t "Sunfish" | 2026.4 发布 | 推测 3nm | 推测 ~12 PFLOPS | 推测 192GB+ | 同上 | 训练专用,博通设计 |
| TPU 8i "Zebrafish" | 2026.4 发布 | 推测 3nm | 推测 3-4 PFLOPS | 384MB SRAM×3 | 同上 | 推理专用,联发科设计 |
Jalapeño 算力推算
OpenAI 没有公布 die size、HBM 数量、晶体管数。但有公开线索:
- 工艺:TSMC N3(与 TPU v7 Ironwood 同代)
- 网络:Broadcom Tomahawk
- Hock Tan 声称"性能可比 Blackwell"
如果按 TPU v7 Ironwood 的 4.6 PFLOPS 作为基准。Blackwell B200 在 FP8 是 20 PFLOPS,但那是双 die、2080 亿晶体管、1600mm² die size、1200W TDP 的巨型芯片。
Jalapeño 作为单 die ASIC 的算力推算要分两步走。
(a) FP8 峰值算力推算(与 Blackwell 直接对标):
- 理由 1:ASIC 架构效率比 GPU 高,同样晶体管预算可拿到更多等效算力
- 理由 2:Hock Tan 说"可与 Blackwell 媲美"。这是等效吞吐对标(见 b),不直接等于 FP8 峰值对标
- 理由 3:雷科技推测"10 PFLOPS"在合理区间
- 理由 4:如果采用 FP4/FP6 量化,数字可能冲到 20+ PFLOPS(接近 Blackwell Ultra 的 FP4 15 PFLOPS)
- FP8 峰值算力推算区间:8-13 PFLOPS
(b) 实际推理吞吐对标(Hock Tan 真正在说的):
- ASIC 在 LLM 推理工作负载下利用率 70-90%,GPU 普遍 30-40%
- 同样的"FP8 峰值算力",ASIC 实际吞吐可达 GPU 的 2 倍
- Hock Tan 说"媲美 Blackwell"指的是这种等效吞吐,不是峰值 FP8 等价
- 注意:Hock Tan 的原话在公开报道中未引用具体语境,这个解释是我的合理推断
直接算力对比表(推算)
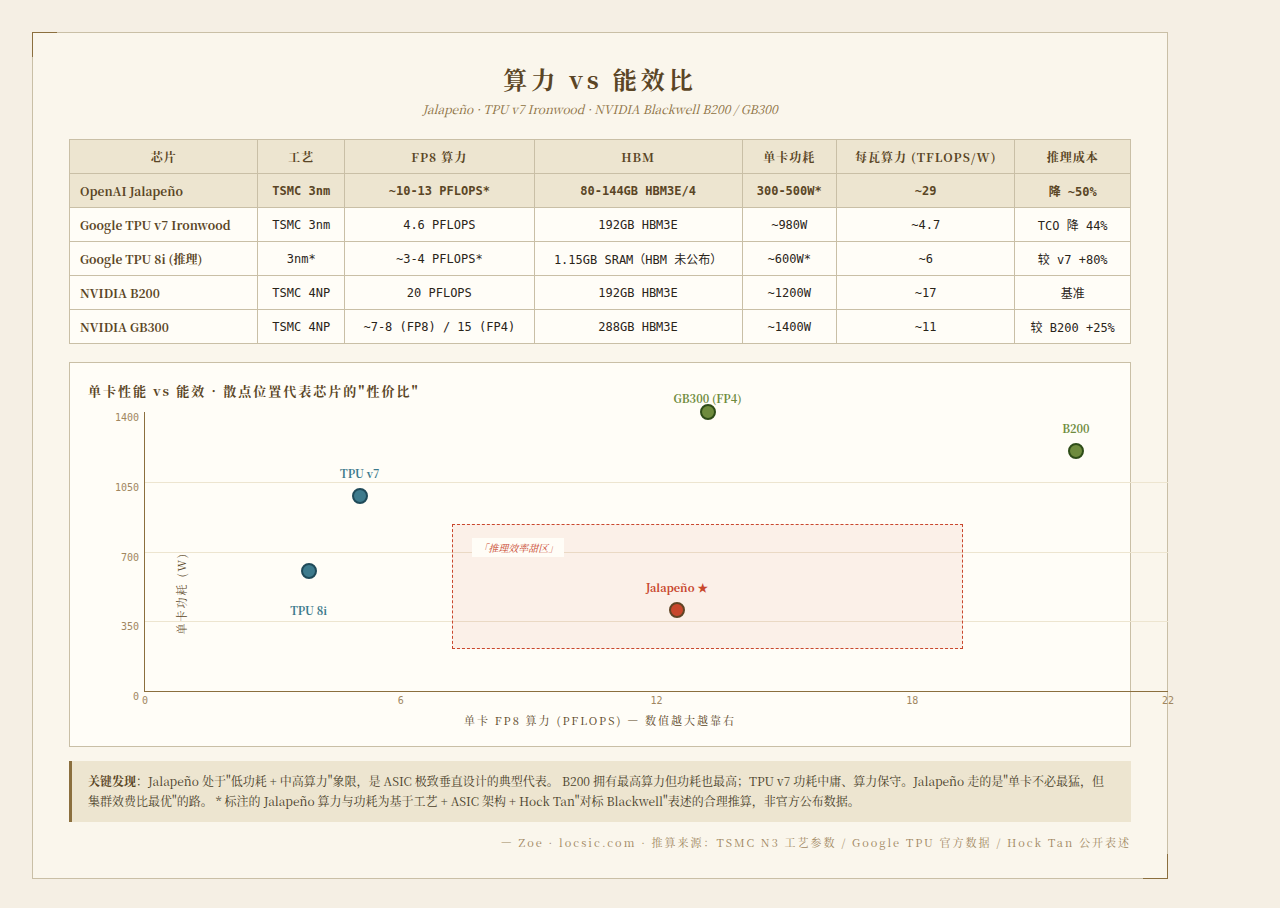
| 芯片 | 工艺 | FP8 算力 | 内存 | 单卡功耗 | 互联 |
|---|---|---|---|---|---|
| OpenAI Jalapeño(推算) | TSMC 3nm | ~10-13 PFLOPS | 80-144GB HBM3E/4 | 300-500W(推测) | Broadcom Tomahawk |
| Google TPU v7 Ironwood | TSMC 3nm | 4.6 PFLOPS | 192GB HBM3E | ~980W | OCS Jupiter 32Tbps |
| Google TPU 8i(推理) | 推测 3nm | 推测 3-4 PFLOPS | 1.15GB 片上 SRAM(主 HBM 未公布) | 推测 600W | 同上 |
| Google TPU 8t(训练) | 推测 3nm | 推测 12 PFLOPS | 推测 192GB+ HBM3E | 推测 980W | 同上 |
| NVIDIA B200 | TSMC 4NP | 20 PFLOPS | 192GB HBM3E | 1200W | NVLink 5.0 1.8TB/s |
| NVIDIA GB300 | TSMC 4NP | ~7-8 PFLOPS(FP8 估计) / 15 PFLOPS FP4 | 288GB HBM3E | ~1400W | NVLink 5.0 |
几个关键观察
- Jalapeño 单卡算力可能超过 TPU v7 Ironwood 如果推算准确(10-13 PFLOPS FP8),Jalapeño 的单卡算力是 Ironwood 的 2-3 倍。但 ASIC vs ASIC 需要打折扣。TPU 还要兼顾 VPU(向量处理单元)等通用部分,die area 不全是 systolic array。
- HBM 是 Jalapeño 的潜在短板
TPU Ironwood 有 192GB HBM3E、7.4 TB/s 带宽。如果 Jalapeño 是 80-144GB、3-4 TB/s 带宽:
- 大模型推理(70B-200B 参数)需要 HBM 容纳权重 + KV Cache
- 144GB 刚好装下 70B FP16 权重(140GB),没有多少 KV 空间
- 这意味着 Jalapeño 必须配合模型分片或量化才能服务大模型
- 推测 Jalapeño 服务的是 GPT-5.3 这种混合精度 + MoE 专家分片 模型,单卡只持有部分专家
- 单卡功耗是 Jalapeño 的明显优势
- ASIC 的能效比 GPU 高 2-3 倍是行业共识
- 300-500W TDP 可以用更简单的散热(风冷或轻量液冷)
- 这可能是 Jalapeño 推理成本下降 50% 的主要来源。不只是芯片便宜,电费也省
- 集群扩展性是 Jalapeño 的悬念
TPU Ironwood 集群支持 9,216 卡,42.5 EFLOPS 集群算力。Jalapeño 的 Tomahawk 网络能扩展到多少?OpenAI 没有公开,但 10GW 数据中心的目标意味着需要数百万张卡。
每瓦性能:能效比的真正决战
| 维度 | OpenAI Jalapeño | Google TPU v7 Ironwood | NVIDIA B200 |
|---|---|---|---|
| 单卡 FP8 算力 | ~10-13 PFLOPS | 4.6 PFLOPS | 20 PFLOPS |
| 单卡功耗 | 300-500W | 980W | 1200W |
| 每瓦 FP8 算力 (TFLOPS/W) | ~29 | ~4.7 | ~17 |
| 推理成本(相对) | 50% | 44% TCO 优势 | 基线 |
如果 Jalapeño 真的是 ~29 TFLOPS/W 的能效比(理论范围 20-43 TFLOPS/W,取决于实际功耗和算力的具体组合),这将是有史以来能效最高的 AI 加速器。 但这是单卡纸面数字,实际推理工作负载下的"每瓦有效吞吐"还要打折扣。
六、芯片物理分析:3nm、Die Size、晶体管数
Die Size 与晶体管数
虽然 OpenAI 没有公开 die 照片或详细物理尺寸,但结合已知参数可推断:
- 工艺:TSMC N3(与 Apple M4 同代)
- 晶体管数量:未公布。考虑到 3nm 密度和小型团队的设计能力,估计在 500-1500 亿晶体管 量级(NVIDIA Blackwell B200 约 2080 亿晶体管、双 die)
- Die Size 推测:约 600-900mm²(单 die,远小于 B200 的 1600mm²)
- 封装:推测采用 CoWoS-S 或 CoWoS-L 先进封装,HBM 与计算 die 通过硅中介层互联
散热设计
3nm 工艺本身的能效优势加上 ASIC 架构的低功耗特性:
- 推测 TDP:300-500W(远低于 Blackwell 的 1200W)
- 散热方案:可能用风冷 + 部分液冷,或全液冷
- 这意味着 OpenAI 数据中心的散热成本可能只有 Blackwell 集群的 1/2-1/3
HBM 与内存层级
- HBM3E(推测 6-8 颗堆叠)
- 总容量推测:80-144GB
- 带宽推测:3-4 TB/s
关键的物理瓶颈:HBM 的成本占了 AI ASIC 总成本的 30-40%。Hock Tan 已公开表示,HBM 拉高了博通定制 AI 芯片的成本,利润率不如网络交换机等其他产品线。
"AI 设计 AI 芯片" 的真实含金量
OpenAI 的公开叙事是"GPT 模型参与了芯片设计"。但这句话是 PR 口径,需要拆成两个层次看:
- ✅ 真实情况:AI 参与了逻辑电路布线优化、热性能管理、功耗预测等 EDA 环节。这些工作传统上需要工程团队反复迭代数周,AI 可小时级完成
- ❌ 偷换概念:这不等于"AI 设计了芯片"。最关键的前端架构定义(systolic array 的选择、内存层级设计、ISA 定义)仍由 Richard Ho 团队完成
业界 AI 辅助芯片设计的真实进展

这部分在 2026 年已经非常清晰。AI 辅助芯片设计不是 OpenAI 的发明,而是整个 EDA 行业这两年正在发生的范式转移:
- Synopsys DSO.ai(Design Space Optimization AI)
- 2020 年发布,行业最早的 AI 辅助 EDA 工具
- 在芯片综合、布局布线阶段,用强化学习搜索 PPA 最优解
- 已帮助三星、Renesas、NVIDIA 等完成数百次流片
- 实测:相比人工,能把工程时间从数周压缩到数小时,在功耗、性能、面积上拿到 10-20% 额外优化
- Cadence Cerebrus
- 2022 年发布,对标 DSO.ai
- 自动并行运行 Innovus 物理实现流程,AI 调节参数
- 关键数据:截至 2026 年 6 月,已被超过 2000 次芯片流片采用
- 运算效率提升 ~4 倍
- 周转时间缩短 ~2 倍
- PPA 提升 ~15%
- Cadence ChipStack(2026 年最新发布,行业首款 L5 级自主芯片设计 AI Agent)
- 2026 年 6 月推出,全球首个"虚拟 IC 设计工程师"
- EDA 自主化分级(类比自动驾驶 L1-L5):
- L1-L3:AI 作为工具辅助(现状)
- L4:AI 能理解目标、自主调用工具
- L5:AI 能独立完成 RTL 生成、验证规划、形式验证、调试、收敛全流程
- Cadence 的"心智模型"(Mental Model)解决了 LLM 在芯片设计中的幻觉问题
- Siemens Celus + Cadence Allegro X AI
- 主攻 PCB 板级设计
- AI 自动生成原理图初版、布局布线初版
- 中国 EDA 进展
- 上海培风图南半导体(2026 年总部迁入张江)
- 华大九天、概伦电子等已上市企业加速 AI 原生 EDA
结论:OpenAI 9 个月流片的"真实水位"是 "OpenAI + Broadcom 团队此前未公开的预研(3-4 个月)+ AI 加速 PPA 优化(2-3 个月)+ Broadcom 复用既有 IP(2-3 个月)+ AI 加速验证和热仿真(1-2 个月)",并非"AI 从头到尾设计了芯片"。
七、软件适配:垂直整合优势与生态封闭代价
优势:OpenAI 是自己在给自己做芯片
Jalapeño 最大的软件优势是没有生态迁移问题。它不需要对外销售,只需要适配 OpenAI 自己的模型:
- 模型适配范围:已通过 GPT-5.3、Codex、Spark 验证
- 对模型迭代的兼容性:Richard Ho 表示"可适应未来各种版本的大语言模型"
- 推理框架:OpenAI 自有推理栈(可能是基于 Triton 的开源编译器或自研引擎)
- MRC 协议的前置铺垫:2025-2026 年 OpenAI 已在模型层面引入 MRC(多径可靠连接)协议,联合 AMD、博通、Intel、NVIDIA、微软做多芯片高速通信优化
与 NVIDIA 生态的差距
NVIDIA 的 CUDA 护城河不仅仅是编程语言,而是:
- 500+ 个优化库(cuBLAS、cuDNN、TensorRT、TensorRT-LLM)
- 数百万开发者生态
- 完整的训练→推理→部署工具链
相比之下,Jalapeño 的软件栈是为 OpenAI 定制的垂直栈。这是优势(极致优化)也是劣势(不通用,无法获取外部生态红利)。
软件适配的真实赌注
Jalapeño 不需要让全球开发者写 CUDA 代码,但必须解决:
- 模型从 H100 移植到 Jalapeño 的工具链
- 推理优化(量化、KV Cache 复用、continuous batching)
- 与 OpenAI 现有推理基础设施的整合
- 集群调度(Tomahawk 互联的低延迟路由)
这是 Jalapeño 真正的风险所在。硬件按时流片了,软件能不能在 2026 年底大规模部署前打磨好?历史上,硬件交付容易,软件生态成熟需要 2-3 年。
八、横向对比:AI ASIC 战场全景
旗舰 ASIC 规格对比
| 维度 | OpenAI Jalapeño | Google TPU 8i | Google TPU 8t | AWS Trainium3 | AWS Inferentia2 | NVIDIA B200 | 微软 Maia 200 |
|---|---|---|---|---|---|---|---|
| 定位 | 推理 ASIC | 推理 ASIC | 训练 ASIC | 训练 ASIC | 推理 ASIC | 通用 GPU | 通用推理 |
| 制程 | TSMC 3nm | 推测 3nm | 推测 3nm | TSMC 3nm | 5nm | TSMC 4NP | 推测 5nm |
| 算力(推测/确认) | ~10-13 PFLOPS | ~3-4 PFLOPS | ~12 PFLOPS | ~2.5 PFLOPS/颗(原文"2.52 EFLOPS"应为 PFLOPS 单位,否则与 144 颗=362 PFLOPS 矛盾) | 较低 | 20 PFLOPS | 较低 |
| 内存 | HBM3E/4 (80-144GB) | 1.15GB 片上 SRAM(主 HBM 未公布) | 推测 192GB+ HBM3E | 144GB HBM3E | 较低 | 192GB HBM3E | 较高 |
| 互联 | Tomahawk | OCS Jupiter 32Tbps | 同上 | 定制 | 定制 | NVLink 5.0 (~1.8TB/s) | 推测以太网 |
| 功耗 | 300-500W | 推测 600W | 推测 980W | 较高 | 较低 | ~1200W | 较高 |
| 成本优势 | ~50% vs GPU | 60-70% vs GPU | 40-50% vs GPU | ~50% vs H100 | ~80% vs H100 | 基准 | 推测 30% |
| 可用性 | 仅 OpenAI 内部 | 对外销售 | 对外销售 | AWS 云服务 | AWS 云服务 | 全行业 | Azure 内部 |
| 训练能力 | ❌ 不支持 | ❌ | ✅ 主力 | ✅ 主力 | ❌ | ✅ | ❌ |
| 开发者生态 | 无(专有) | 开放(JAX/XLA) | 开放 | Neuron SDK | Neuron SDK | CUDA 生态 | 推测封闭 |
核心结论
- 谷歌 TPU:最成熟的 ASIC 范式
Google 从 2016 年 TPU v1 开始,已有 10 年 ASIC 积累。TPU 8i(推理)/ 8t(训练)分别对应 OpenAI 的当前路线和未来方向。
关键差异:
- 生态开放:2026 年 Google 宣布对外出售 TPU,与 Blackstone 联合成立 250 亿美元 AI 云计算公司
- 软件成熟:JAX + XLA 编译器 + TensorFlow 深耦合
- 集群能力:TPU v7 单个 Pod 4096 卡,v7 Ironwood 集群可达 9,216 卡、42.5 EFLOPS
- 功耗代价:TPU v7 单芯片 980W
- 推理成本优势:TCO 比 GB200 低 44%
- AWS Trainium:云端最大规模的 ASIC 部署
- Trainium3 FP8 算力推测 ~2.5 PFLOPS/颗(原始报道"2.52 EFLOPS"应为 PFLOPS 单位,否则 144 颗不可能=362 PFLOPS),144GB HBM3e
- Trainium3 较 Trainium2 性能提升 30-40%、能耗降低 40%
- AWS 最大的优势:绑定云服务,开发者不用买芯片,租用即可
- 劣势:Neuron SDK 迁移成本高,Cohere/Stability AI 反馈 Trainium1/2 在某些场景不及 H100
- 微软 Maia 200:最被低估的竞争者
2026 年初发布的 Maia 200 距离 Maia 100 两年多迭代。微软的特殊地位在于:
- 同时是 OpenAI 的最大投资方
- Azure 也在大规模部署 NVIDIA GPU
- 有双重身份:既是芯片玩家,又是 OpenAI 的算力供应商
- NVIDIA Blackwell:防守姿态,但弹药充足
- MLPerf 6.0 训练全部 7 项第一
- GB300 NVL72 相较 GB200 训练速度提升 1.6 倍
- 单芯片功耗 1200W,下一代 Rubin 预计 2300W
- 最大护城河:CUDA 生态 + 全栈软件(TensorRT-LLM、NeMo、Megatron)
- 8192 GPU 集群已验证 DeepSeek-V3 671B 训练
- OpenAI Jalapeño 的独特定位
Jalapeño 是表中唯一一个从第一天起只服务于一个模型系列(GPT)、一种负载(LLM 推理)的垂直 ASIC。这是它的最大优势。极致垂直。也是它最大的限制。不对外销售,无法摊薄研发成本。
九、国内大厂自研芯片全景
中国 AI 芯片战场在 2026 年呈现"国家队 + 互联网巨头 + 模型公司"三路并进的态势。
1. 阿里平头哥:唯一"全栈自研"对标 OpenAI 路线
最新发布:真武 M890(2026.5.20 阿里云峰会)
| 规格 | 真武 810E(2024) | 真武 M890(2026.5) | 真武 V900(2027Q3 路线) |
|---|---|---|---|
| 工艺 | 未公开 | 推测 5nm | 推测 3nm |
| HBM | 96GB HBM2e | 144GB HBM | 216GB |
| 片间互联 | 700 GB/s | 800 GB/s | 1200 GB/s |
| 相对性能 | 1x(基准) | 3x | 9x |
| 用途 | 训推一体 | 训推一体 + Agent 优化 | 训推一体 |
关键事实:
- 量产:中芯国际负责
- 累计出货 56 万片(截至 2026 年 5 月)
- 金融行业部署突破 10 万卡,覆盖 150+ 机构
- 自研 ICN Switch 1.0 互联芯片,可将 64-128 卡组成超节点
- 配套阿里玄铁 RISC-V CPU、倚天 Arm 服务器、镇岳 SSD 主控、磐脉智能网卡
- 路线图:"一年一代"迭代(与 OpenAI 计划相同)
与 OpenAI 路线对比:
| 维度 | OpenAI Jalapeño | 阿里平头哥真武 |
|---|---|---|
| 定位 | 纯推理 | 训推一体 |
| 外售 | ❌ 仅 OpenAI 内部 | ✅ 阿里云 + 政企客户 |
| 代工 | TSMC 3nm | 中芯国际(推测 5nm) |
| 生态 | 专有(仅自用) | 平头哥 + 阿里云 |
| 制程差距 | 3nm(领先) | 推测 5nm(落后一代) |
2. 字节跳动:买买买 + 部分自研
字节的打法是不主要靠自研,而是大规模采购国产芯片:
2026.6 的 5 万颗采购单:
| 供应商 | 数量 | 用途 | 工艺 |
|---|---|---|---|
| 天数智芯 智铠 MR-V100/MR-V100x | ~3.2 万 | 推理主力 | 7nm |
| 百度昆仑芯 P800 | 1.5 万 | 视频理解、推荐 | 推测 7nm |
| 海光 DCU K100ai | 0.3 万 | 边缘审核 | - |
为什么字节不买 H100/H200?
- H20 后门事件(2025 年底)让合规风险变大
- H100/H200 不在中国出口管制豁免范围
- 国产推理芯片已经"可用",且单价仅 H20 的 1/3(智铠 2 万元 vs H20 ~6 万元)
字节的算力账:
- 2026 年 AI 基础设施资本开支:2000-7000 亿元(口径不同)
- 豆包月活 3.45-3.68 亿
- 日均 Token 调用量 120 万亿
- 日算力成本 数千万元
- 字节 2025 年净利润同比缩水超 70%
3. DeepSeek:模型 + 国产芯片闭环(不走 OpenAI 路线)
最新里程碑:DeepSeek V4 Pro(2026.4)
- 参数总量:1.6 万亿(MoE)
- 实际激活:约 5-8%
- 全球首次实现万亿参数大模型对华为昇腾芯片的全栈适配
- 推理速度相比迁移昇腾初期提升 35 倍(DeepSeek 公开口径,对比基准为 V4 适配昇腾过程的早期版本,非 H100 或其他模型的对比)
DeepSeek 的特殊性:
DeepSeek 不自研芯片,而是让模型完美适配国产芯片。这条路线比自研芯片更聪明:
- 模型公司直接控制训练-推理的全栈
- 把"哪些算子用 ASIC 硬编码、哪些用通用计算"的选择权握在自己手里
- 与华为昇腾、寒武纪、海光、摩尔线程、沐曦等多家合作
DeepSeek V4 在华为昇腾上的关键数据:
- 通过 PTX 算子层重写 + 通信层优化
- API 定价仅为 OpenAI 的 1/10
估值:
- 2026.6 完成首轮外部融资 500 亿元人民币(~74 亿美元)
- 投后估值 超 500 亿美元(两个月内从 100 亿美元飙到 500 亿)
- 国家大基金领投,腾讯、阿里、宁德时代、京东、网易跟投
- 创始人梁文锋个人出资 200 亿元
4. 智谱 AI:与国产芯片集群深度适配
最新动作:GLM-5 + 国产芯片全适配(2026.2)
| 国产芯片 | 适配完成 | 性能 |
|---|---|---|
| 华为昇腾 | ✅ | 首次实现 W4A8 混合精度量化,单 Atlas 800TA3 机对标 H100 双机 |
| 摩尔线程 | ✅ | - |
| 寒武纪 | ✅ | - |
| 昆仑芯 | ✅ | - |
| 沐曦 | ✅ | - |
| 燧原 | ✅ | - |
| 海光 | ✅ | - |
智谱的特殊贡献:
- 在昇腾上首次实现 W4A8 量化(权重 4-bit、激活 8-bit),这是业界突破
- 长序列、低时延场景下,部署成本减少 50%
- 智谱本身不自研芯片,但作为"模型层"推动了"模型-芯片"协同设计
5. 国产芯片总体格局
国产 AI 芯片出货量(IDC 2025 统计,含 NVIDIA 等外资中国区出货与华为/阿里部分自用估算):
- 中国 AI 加速卡年出货 400 万张
- 国产合计 165 万张,市场份额 41%
- 摩根士丹利预测 2030 年国产占 76%
- 注:165 万国产里含华为自用昇腾 + 阿里真武自用部分;不含自用则纯商业出货约 ~120 万张
国测 I 级认证的 9 款国产 AI 芯片(2026.5.26):
- 华为海思昇腾
- 海光 DCU
- 壁仞科技
- 中星微技术(星光智能五号)
- 平头哥(真武系列)
- 燧原科技
- 摩尔线程
- 沐曦股份
- 昆仑芯
6. 字节 vs 阿里 vs DeepSeek vs 智谱:路线对比

| 维度 | 字节 | 阿里 | DeepSeek | 智谱 |
|---|---|---|---|---|
| 自研芯片 | ❌(仅传闻) | ✅ 真武系列(已两代) | ❌ | ❌ |
| 主要策略 | 采购+整合 | 全栈自研 | 模型适配国产 | 模型适配国产 |
| 制程 | 7nm 国产 | 推测 5nm | 沿用国产 | 沿用国产 |
| 训推一体 | ✅(买 GPU) | ✅ 真武 | ✅ 昇腾 | ✅ 昇腾等 |
| 对标 OpenAI | 不直接对标 | 全栈路线类似 | 模型路线类似 | 模型路线类似 |
| 与 OpenAI Jalapeño 对标度 | 低 | 中(路线对标,制程落后) | 高(路线互补) | 高(路线互补) |
| 当前算力规模(口径不同,需对照) | 本轮采购 5 万+ | 累计出货 56 万片 | 推测万卡 | 推测千-万卡 |
7. 三条路线的方法论差异
把国内四家的策略抽象出来,可以看到三种完全不同的方法论:
路线 A:自研芯片(阿里平头哥)
- 与 OpenAI 路线最接近
- 优势:长期成本控制、技术自主
- 劣势:研发周期长、起步落后一代、生态建设难
路线 B:模型适配国产芯片(DeepSeek、智谱)
- 不碰硬件,让模型主动适配
- 优势:路径短、灵活性高、不被单一供应商绑定
- 劣势:依赖国产芯片性能上限、训练侧仍需突破
路线 C:大规模采购 + 自研少量专用(字节)
- 把算力当作商品采购
- 优势:快速扩容、不分散精力
- 劣势:议价能力弱、长期成本不可控
核心结论:
- 阿里平头哥是国内唯一可与 OpenAI 路线对标的全栈自研玩家。但制程仍落后 1 代
- DeepSeek + 智谱代表"模型层下沉"路线。比硬造芯片更现实,正在快速形成"国产模型 × 国产芯片"生态闭环
- 字节走的是"NVIDIA 路线"。大量采购 + 自研少量专用芯片
- 国内战场的核心矛盾:训练侧仍依赖英伟达 H100/H200,推理侧正在被国产替代
- OpenAI Jalapeño 这种"软硬件极致垂直整合"的玩法,国内只有阿里平头哥在尝试,但出货规模、客户多样性、技术成熟度都还差一个量级
十、结论:AI 公司的下一个形态是"AI 全栈公司"
产业坐标里的 Jalapeño
把 Jalapeño 放进历史坐标系看,过去三年里"AI 公司是否需要自研芯片"这个问题走过了一条清晰的曲线:
- 2023 年:OpenAI 与大多数 AI 实验室一样,只关心模型。算力是采购对象
- 2024 年:算力价格和供应都开始困扰模型公司。Anthropic、Meta 内部开始讨论自研芯片可行性
- 2025 年:Google 通过 TPU 对外销售,把"自研芯片"变成了一种商业产品
- 2026 年 6 月:OpenAI 用 Jalapeño 把这条路闭合,第一个估值过千亿美元的 AI 实验室亲自下场造芯片
这不是终点,只是时间轴上的一个坐标点。
五个可观测的成败硬指标
判断 Jalapeño 是否真正"工作",未来 18 个月看这五个硬指标:
- 首批部署时间:是否在 2026 年底上线、规模能否到 GW 级
- 能效比兑现:Hock Tan 的"50% 推理成本降低"是否在 2027 年财报里得到验证
- 软件生态成熟度:PyTorch / Triton 对 Jalapeño 的原生支持是仅演示级别,还是进入日常训练流水线
- HBM 与产能:2027-2028 年 HBM4 与 TSMC N3 产能能否稳定供应 10GW 路线图
- 第二代迭代节奏:OpenAI 承诺的"每年一代"能否兑现。如果 2028 年没有第二代,自研芯片就成了资本套利项目,而不是技术进化
两个产业观察
观察一:自研芯片从"差异化优势"变成了"基础设施必要条件"。Google TPU 10 年积累、AWS Trainium 3 代、Microsoft Maia、Meta MTIA,加上现在的 OpenAI Jalapeño,主流 AI 公司都已上场。还没下场的(如 Anthropic)会被供应安全和成本结构卡住脖子。
观察二:模型与芯片的耦合会越走越深。Jalapeño 这种"只为 GPT 系列设计"的垂直 ASIC,本质上是在赌 OpenAI 的模型架构会保持 Transformer + MoE 范式。如果 Transformer 被新架构取代(例如 Mamba / SSM 类),Jalapeño 的所有优化会瞬间过时。这是 OpenAI 自研路线最大的隐性赌注,赌自己的模型架构稳定性。
对国内产业的含义
Jalapeño 是一个压力测试案例。它证明"AI 公司能造芯片"在工程上可行,但对小公司来说代价高昂:40 人核心团队 + 博通数百人 + 数亿美元流片成本。
国内最现实的反应不是模仿这条路线(除了阿里平头哥),而是反其道而行:让国产芯片适配主流模型,而不是让模型适配某颗芯片。DeepSeek V4 + 昇腾、智谱 GLM-5 + 全国产芯片走的就是这条路。面对出口管制的现实答案。
总结
OpenAI 用 9 个月做出了 Jalapeño。把它当作 AI 公司挑战 NVIDIA 的标志性时刻是过度的解读;把它当作"模型 + 自研芯片"全栈范式的最新一个坐标点,更接近事实。
Jalapeño 这颗墨西哥辣椒的真正价值,不在它的算力数字,而在它确认了一个趋势:AI 行业的竞争单元正在从单一模型,升级为模型 + 芯片 + 数据中心 + 互联 + 调度的整栈。这个升级一旦完成,行业格局的重塑就不以任何单一公司的意志为转移了。
附录 A:关键时间线
- 2023 年底:Richard Ho 加入 OpenAI,组建芯片团队
- 2024 年中:OpenAI 与博通开始秘密联合研发
- 2025 年 10 月:双方公开战略合作,10GW 算力部署目标
- 2026 年 6 月 24 日:Jalapeño 正式发布
- 2026 年底:首批部署上线
- 2027 年:规模化部署
- 2028 年上半年:全面发力,1-3GW 单集群
- 2028 年:下一代 Jalapeño 发布
- 2029 年:10GW 算力集群建成
附录 B:术语表
- ASIC(Application-Specific Integrated Circuit):专用集成电路,为特定用途定制的芯片
- HBM(High Bandwidth Memory):高带宽内存,3D 堆叠 DRAM
- MoE(Mixture of Experts):混合专家模型架构,参数总量大但每个 token 只激活部分
- PFLOPS / EFLOPS:千万亿次 / 百亿亿次浮点运算每秒
- Systolic Array:脉动阵列,数据像血液流动规律通过处理单元
- TDP(Thermal Design Power):热设计功耗,决定散热需求
- Tape-out:流片,把芯片版图数据提交给晶圆厂制造
- W4A8:权重 4-bit 量化、激活 8-bit 量化的混合精度
附录 C:参考资料
- OpenAI 官方公告(2026.06.24)
- Reuters / CNBC / The Verge 报道
- Broadcom 官方新闻稿
- Google Cloud Next 2026 TPU v8 公告
- Cadence Cerebrus / ChipStack 官方产品页
- 百度百科「第八代张量处理单元」
- 百度百科「Blackwell」
- 百度百科「真武系列 AI 芯片」
- IT之家 / 第一财经 / 财联社 / 钛媒体 / 虎嗅 / 36氪 报道
- SemiAnalysis 深度分析
- 知乎专栏 & 什么值得买技术帖
- IDC 2025 中国 AI 加速卡出货数据
- 《金融时报》OpenAI 审计财务文件
声明:本文截稿于 2026.06.27。所有推算值已在文中标注「推测」「推算」或「*」。未公开的具体规格以 OpenAI / Broadcom 未来发布的技术报告为准。