2026 年 6 月底,SemiAnalysis 创始人 Dylan Patel 在 Sequoia Capital 的 Training Data 播客中做了一个判断:过去三年 AI 效率提升了远不止 30 倍,但其中硬件的贡献只是冰山一角。真正的 100 倍跃迁,来自模型、kernel 和芯片三层的协同优化——单独提升任何一层只能拿到 2-8 倍,三层同时优化才会产生乘法效应。
这不是空谈。DeepSeek 的模型架构为 NVIDIA Hopper 的矩阵单元量身裁剪,到 V4 又为 Blackwell 重新调整;NVIDIA 自己在 Rubin 平台上把"extreme co-design"写进了官方新闻稿;Google 的开源 Gemma 模型因 TPU 的形状差异做了与 GPU 模型不同的架构选择。软硬件协同设计已经不是"做得好的公司更高效",而是"不做协同设计的公司会逐渐丧失竞争力"。
本文先拆解 Dylan Patel 访谈的核心论点,然后分别梳理模型、kernel、芯片三层各自的技术方向,最后分析跨层协同的具体实践和产业影响。
一、访谈核心:为什么 100 倍在协同设计里
1.1 一组反驳性数据
Dylan Patel 在访谈中直接反驳了主持人"过去三年算力提升主要来自硬件"的说法。他的拆解逻辑如下:
- 硬件层:从 Hopper 到 Blackwell,在 DeepSeek 最优部署条件下系统级性能提升约 30 倍。这个数字需要拆解:单芯片计算能力提升约 3-5 倍(FP4/FP8 tensor core、HBM3e 带宽扩展);NVLink 5 把 72 GPU 连成一个共享内存域,通信效率提升约 2-3 倍;FP4 量化让同等带宽下可处理的数据量翻倍,又贡献约 2-3 倍。三者相乘落在 30 倍量级。30 倍是硬件系统+量化格式+部署优化共同作用的结果,不是单芯片架构的代际跳跃。
- 模型层:三年前对标的是 GPT-4,今天一个 27B 总参数、2B 活跃参数的 Qwen 模型就能超越它。单位智能的计算成本下降了一个数量级以上。
- 协同层:FlashAttention 从第 2 代迭代到第 4 代,推理框架(vLLM、SGLang、TensorRT-LLM)的持续优化,量化从 FP16 推进到 FP4——这些改进各自看起来是 2 倍级别的渐进提升,但当它们作用在同一个技术栈上时,乘积效应远超简单相加。
关键论断是:"The real breakthrough innovation is when you leapfrog a few layers — instead of being multiplicative to 8×, it's actually 100×." 当优化跨层同步发生时,消除层间的 mismatch 产生的是不连续跳跃,不是简单的 2×2×2=8。

1.2 DeepSeek 的公开案例
DeepSeek 是协同设计最好的公开样本。Dylan Patel 指出,DeepSeek V3 的 expert 维度和混合比例是明确按照 Hopper 的矩阵单元 tile 尺寸和内存层级来设计的。V4 进一步为 Blackwell 做了适配。
具体到技术层面,这意味着什么?
DeepSeek V3 采用细粒度专家分割(Fine-Grained Expert Segmentation),每个 routed expert 的参数量约 33M:SwiGLU 设计使用 gate_proj + up_proj + down_proj 三层映射,参数量 = 7168×1536 + 7168×1536 + 1536×7168 ≈ 33M。中间层维度 1536 的选择并非随意——Hopper 的 WGMMA(Warpgroup Matrix Multiply-Accumulate)指令在矩阵的 M/N/K 维度是 tile 边界(16/64/128/256)的整数倍时效率最高。当 1536 = 128×12 且 7168 = 128×56 时,tensor core 无需 padding,利用率可以从不对齐时的 40-50% 提升到 70% 以上(来源:SonicMoE 论文 arXiv 2512.14080 消融实验;SemiAnalysis InferenceX 基准对比)。
到 V4,DeepSeek 引入了 Compressed Sparse Attention(CSA)和 Heavily Compressed Attention(HCA),放弃了 V3 的 Multi-head Latent Attention(MLA)。设计动机直指 KV cache 压力——V4 实现了比 V3.2 减少 73% 的每 token 推理 FLOPs 和 90% 的 KV cache 内存负担。同时,V4 的 MoE 架构适配了 Blackwell 的新特性:TMEM(Tensor Memory,每 SM 256KB 的片上专用内存)和 Ping-Pong 调度机制让 GEMM 的 epilogue 与下一轮 MMA 重叠执行,这对专家数量更多、粒度更细的 V4(1.6T 总参数、49B 活跃)尤其重要。
1.3 TPU 为什么跑不好 DeepSeek
Dylan Patel 给出了一个看似矛盾的事实:Google TPU "客观上是一款出色的芯片",但跑 DeepSeek 的效率很低。原因是模型架构与 TPU 拓扑不匹配。
NVLink 通过专用交换机连接最多 72 个 GPU,形成一个共享内存域。Google 的 ICI(Inter-Core Interconnect)不用交换机,而是让 token 通过中间芯片路由,最多可连接 8000 个芯片。两种互联架构的延迟和带宽特性完全不同,DeepSeek 的 expert 分散模式(每个 token 激活 8 个 routed expert + 1 个 shared expert)需要频繁的 all-to-all 通信,在 NVLink 的 72-GPU 域内可以高效完成,但在 TPU 的 switchless 拓扑上会产生额外的跳数延迟。
问题本质上是模型没有为 TPU 优化。Google 的 Gemma 系列模型做了不同的架构选择,因为 TPU 的 systolic array 形状与 GPU 不同。Dylan Patel 观察到一个趋势:Blackwell 和 TPU 在计算单元层面正在趋同(都支持 tile-based FP8/FP4 计算,systolic array 和 tensor core 的设计理念在靠拢),但互联拓扑的差异使它们适合的模型架构依然分化。
1.4 InferenceX:实证基准
SemiAnalysis 运营的 InferenceX 平台每天在超过 5000 万美元的捐赠硬件上运行自动化基准测试,覆盖 NVIDIA、AMD、Google、Amazon 等厂商的最新芯片。它的核心发现是:单位质量的推理成本每年下降约 40-60 倍。
这个数字本身比任何单层优化都更能说明协同设计的威力。硬件代际提升撑死了 5-10 倍(Hopper → Blackwell → Rubin),但加上模型架构演进(从 dense 到 MoE,从 175B 到 2B 活跃参数)和推理框架优化(FlashAttention、PagedAttention、speculative decoding),综合效率提升达到了每年接近两个数量级。
1.5 CUDA 护城河的转移
Dylan Patel 判断 CUDA 护城河"部分侵蚀",但真正的竞争优势已经从可编程性转移到了生态协同效应。逻辑链条如下:
前沿实验室可以用 AI coding 工具为 AMD 或其他芯片写 custom kernel,降低了 CUDA 的可编程性壁垒。但问题是,每一个主要的中国开源模型——DeepSeek、Qwen、Kimi——都是为 NVIDIA GPU 协同设计的。当你在这些模型上构建应用时,模型架构的 expert 形状、attention pattern、量化方案都已经与 NVIDIA 的 tensor core 和 NVLink 深度耦合。在非 NVIDIA 硬件上运行能跑,但跑不优。
护城河从"CUDA 难学"变成了"模型已经为 NVIDIA 量身定做"。开发者学不会 CUDA 已经不是壁垒,模型架构自己选了边才是。
二、三层各自往哪里走
2.1 模型层:稀疏化、长上下文、注意力机制革新
MoE 成为默认选择。 DeepSeek V3/V4、Qwen 系列都采用 MoE 架构,核心逻辑是用少量活跃参数实现大模型级别的表达能力。V3 的 671B 总参数只激活 37B(5.5%),V4-Pro 的 1.6T 只激活 49B(3%)。活跃参数占比越低,推理时的计算成本越接近一个小模型,但模型能力保持在大模型水平。
但 MoE 不是免费的午餐。更细粒度的专家分割意味着更多的 all-to-all 通信——每个 token 需要被分发到多个专家节点,计算完成后再汇总。专家数量增加(V3 的 256 个 routed expert 到 V4 更多),通信量线性增长。这就产生了计算与通信的权衡,而这个权衡的最优解取决于硬件互联带宽。
Sparse vs Dense 的路线分化。 OpenAI 的模型更 sparse(更高的专家数量、更低的单专家参数量),Anthropic 的模型相对更 dense。这导致两家公司在硬件选择上走向不同方向:OpenAI 重度依赖 GPU 集群的高带宽 NVLink 域来处理频繁的 expert 切换;Anthropic 的更 dense 的模型可以在 AWS Trainium 上获得更好的性价比,因为不那么依赖超低延迟的 expert 通信。
注意力机制持续革新。 从标准 Multi-Head Attention 到 GQA(Grouped-Query Attention)、MLA(Multi-head Latent Attention),再到 DeepSeek V4 的 CSA/HCA,注意力机制优化的核心目标是压缩 KV cache。V4 用 CSA/HCA 替换 MLA,把 KV cache 内存负担降低了 90%。这对长上下文推理至关重要——1M token 的上下文窗口如果用标准 attention,KV cache 会吃掉几百 GB 的 HBM。
量化到 FP4 及其边界。 NVIDIA 从 Blackwell 开始原生支持 FP4 tensor core(第五代),Rubin 进一步增强了 NVFP4 支持。FP4 相比 FP8 在同等 HBM 带宽下可以多塞一倍的权重数据,对内存受限的推理场景(单卡部署大模型)是决定性的。但 FP4 不是万能的:权重用 FP4 量化通常可以接受(大部分权重分布在正态曲线中央,4-bit 指数+尾数足够覆盖),但 activation 的量化更敏感——极端激活值在 FP4 下会被截断,导致长尾分布信息丢失。NVIDIA 的 NVFP4 格式(Normal Float 4-bit)试图缓解这个问题:它假设权重和激活服从正态分布,用非均匀量化在原点附近密集取点,比均匀量化的 INT4 保留更多有效信息。实际部署中常见的策略是权重用 FP4、activation 保留 FP8 或 BF16 的混合精度方案——DeepSeek V3 的 FP8 mixed precision 训练就是这个思路的前身。
Rubin 的一个关键架构决策进一步强化了这个方向:tensor core 宽度翻倍(从 Blackwell 的 16384 FP4 MACs/clock 增至 32768 FP4 MACs/clock)只适用于 FP4 和 FP8,BF16 和 TF32 保持与 Blackwell 相同(来源:SemiAnalysis Vera Rubin 分析,2026 年 2 月)。这意味着 NVIDIA 在用芯片面积投票——未来主流计算负载会迁移到 FP4/FP8,BF16 将逐渐边缘化。如果模型团队的量化方案不能在 FP4/FP8 下高效运行,他们能获得的硬件加速能力会越来越差。
2.2 Kernel/Runtime 层:融合、专门化、AI 辅助开发
FlashAttention 的三代进化。 从 2022 年第一代引入 IO-aware 的 tiling 算法,到 FA-2 改进并行度和工作划分,再到 FA-3 在 Hopper 上利用异步执行和 warp specialization 达到 740 TFLOPS(H100 BF16),直到 2026 年的 FA-4 在 Blackwell 上实现了 1613 TFLOPS(B200 BF16,71% 利用率)。
FA-4 的技术跳跃值得展开。它用 CuTeDSL(CuTe Domain Specific Language)编写而非传统 CUDA C。原因不止是偏好——Blackwell 引入的 TMEM(Tensor Memory,每 SM 256KB 专用内存)和 UMMA(Unified Matrix Multiply-Accumulate)指令是全新的硬件抽象层,CUDA C 无法直接表达这些操作。CuTeDSL 提供了 tiled tensor 抽象,让开发者精确控制 TMEM 布局和 UMMA 发射时序。核心创新包括:全异步 MMA 流水线(计算与数据加载完全重叠)、更大的 tile 尺寸(利用 TMEM 的 256KB/SM 容量)、软件模拟的指数函数(避免硬件 exp 单元成为瓶颈)、条件 softmax rescaling(在 tile 累加过程中动态调整数值范围)、以及 2-CTA MMA(跨两个 Cooperative Thread Array 的矩阵乘法,突破单 CTA 的 shared memory 限制)。这些特性让 FA-4 在 B200 上达到 1613 TFLOPS(BF16,71% 利用率),比 cuDNN 9.13 快 1.3 倍,比 Triton 快 2.7 倍。
Kernel fusion 是推理性能的关键杠杆。 推理的 decode 阶段是内存带宽受限的——每一次不必要的 HBM 往返都在浪费带宽。kernel fusion 把多个算子合并成一个 kernel 执行,消除中间结果的读写。典型的 fusion 组合包括:attention + rotary embedding + layernorm,以及 MoE 的 gate + token dispatch + expert GEMM + combine。FlashInfer 库(由 NVIDIA 主导贡献,包含 TensorRT-LLM 的高性能 kernel)成为 vLLM 和 SGLang 的统一 kernel 后端,在 batch 8-64 场景下减少 29-69% 的 inter-token 延迟。
推理框架的路线分岔。 三个主流框架走出了不同的路线:
- vLLM:通用优先。PagedAttention 管理碎片化 KV cache,continuous batching 提高吞吐,部署简单,支持最广的模型范围。不需要编译步骤,是多数团队的首选默认。
- SGLang:前缀复用和结构化生成。RadixAttention 对共享前缀的请求(如 agent 工作流、RAG pipeline)有显著优势,适合 agentic 场景。
- TensorRT-LLM:编译优先。把模型编译成优化的 TensorRT engine,执行前一次性完成 kernel fusion、memory layout tuning、hardware-specific acceleration。编译后吞吐比 vLLM 高 8-13%,但编译耗时数十分钟,模型变更成本高。
AI coding 工具改变 kernel 开发。 前沿实验室开始用 AI 辅助编写 custom kernel——给定目标硬件的特性(tensor core 规格、shared memory 大小、warp 数量),AI 可以生成针对特定算子组合的 fused kernel。这在一定程度上降低了 CUDA 的可编程性壁垒。DeepSeek 团队自己开发的 DeepGEMM(FP8 GEMM kernel 库)就是这种模式的产物——专门为他们的 MoE expert 形状优化,而非通用 GEMM。
2.3 芯片层:低精度、大内存、互联密度
NVIDIA 的三代演进。 Hopper(H100/H200)引入 FP8 Transformer Engine 和动态精度切换。Blackwell(B200/B300)新增第五代 tensor core 原生 FP4 支持,NVLink 5 带宽翻倍到 1.8 TB/s,HBM3e 扩展到 192-288 GB,并引入了 TMEM(每 SM 256KB 片上专用内存)和 UMMA 指令。Rubin(R100)在 3nm 工艺上实现 336B 晶体管,HBM4 提供 22 TB/s 带宽,FP4 计算达 50 PFLOPS(Blackwell 的 5 倍),NVLink 6 再翻倍到 3.6 TB/s。
Rubin 的一个关键架构决策:tensor core 宽度翻倍只适用于 FP4 和 FP8,BF16 和 TF32 保持与 Blackwell 相同。这意味着 NVIDIA 在押注——未来主流计算负载会迁移到 FP4/FP8,BF16 将边缘化。这个赌注如果成立,模型量化和低精度训练的路线会进一步加速。
Google TPU 的差异化。 TPU 的核心差异不在计算单元(systolic array 在 FP8/FP4 上的效率不输 tensor core),而在互联拓扑。ICI 的 8000 芯片无交换机互联适合需要大规模参数并行的 dense 模型,但对 MoE 的 fine-grained all-to-all 通信不友好。Google 内部的 Gemini 模型自然是完全为 TPU 优化的,但 Google 也开始向外部客户(包括 Anthropic)物理出售 TPU——这是一个策略转变。
AWS Trainium 的位置。 Anthropic 作为 Trainium 的锚定用户(超过 100 万颗 Trainium2 芯片,承诺超过 1000 亿美元/10 年),验证了定制 ASIC 在前沿实验室场景下的可行性。Trainium 的优势在于成本可控和供应链多元化,但软件生态(Neuron SDK)的成熟度仍是追赶项。
Cerebras 和 Groq 的 niche。 SRAM-based 架构在推理速度上有极端优势——Cerebras 可以做到接近瞬时的 token 生成,SemiAnalysis 自己也大量使用于速度敏感任务。但 SRAM 的容量限制使其难以扩展到超大模型 + 长上下文场景。这是一条专门化路线,不替代通用 GPU/TPU 集群。
2.4 GPU 内部架构:计算单元之间的此消彼长
以上是芯片级的演进。往下看 GPU 的微架构层,几个关键硬件单元之间的资源分配和设计权衡,直接决定了某个模型跑在芯片上的真实效率。
Tensor Core:从通用加速器到 AI 专用引擎。 Volta(2017)首次引入时,每 SM 有 8 个 tensor core(4 个 partition 各 2 个),只支持 FP16 矩阵乘。Hopper 的第四代每 SM 有 4 个 tensor core(4 个 partition 各 1 个),但每个 tensor core 的 tile 吞吐能力大幅扩展(支持更大的 M/N/K 尺寸和 FP8),加上 WGMMA 异步指令和 TMA 流水线,整体 GEMM 吞吐是 Volta 的几十倍。Blackwell 的第五代增加了原生 FP4/FP6 支持、TMEM(256KB/SM 的专用 accumulator 内存)和 UMMA 指令,让 epilogue 与 MMA 流水线重叠。Rubin 把 tensor core 宽度翻倍到 32768 FP4 MACs/clock(Blackwell 的两倍),但仅限 FP4 和 FP8。
tensor core 的演化方向很明确:面积和功耗更偏向低精度计算,高精度(BF16、TF32)不再获得同等的硬件资源增长。这意味着模型设计如果坚持用 BF16,能获得的硬件加速会落后于切换到 FP4/FP8 的方案。

CUDA Core:标量计算单元的收缩。 和 tensor core 的扩张形成对比。Hopper 的 H100 SM 有 128 个 FP32 CUDA core、64 个 INT32 core——三路并行流水线(FP32 + INT32 + 4 个 FP64 单元)各有独立的执行单元。Blackwell 把 INT32/FP32 合并为统一流水线(每 SM 约 128 个统一单元),FP64 缩减到每 SM 约 2 个。CUDA core 数量没有大幅增长,但统一调度让混合精度时更灵活。
这不是 CUDA core 性能退步——而是 NVIDIA 在赌 AI 推理和训练已经不依赖通用标量计算。到 Blackwell 时代,95% 以上的计算量落在 tensor core 上,CUDA core 更多用于控制流、地址计算和非矩阵数据处理。统一流水线虽然单指令吞吐与之前持平,但芯片面积省给了 tensor core 和 TMEM。
TMA(Tensor Memory Accelerator):被低估的数据搬运引擎。 Hopper 引入的 TMA 是 SM 内部的数据移动专用硬件。传统 GPU 做 GEMM 时,CUDA core 必须参与数据搬移——从 HBM 拷贝到 shared memory 再启动 tensor core 计算。TMA 让数据搬移独立于 CUDA core:一条线程提交 TMA 操作(源地址、目标 shared memory、tile 尺寸),TMA 硬件自动完成流转。结果:数据搬移和计算可以完全重叠,GPU 利用率显著提升。
DPX(Dynamic Programming Accelerator):小众但重要的补充。 Hopper 引入的 DPX 单元专为动态规划算法(如序列比对、最短路径)提供硬件加速,单个指令完成 max/min + add + clamp to zero。这反映了 GPU 架构正在从"尽量通用"转向"识别高频模式并硬化",与 tensor core 的哲学一脉相承。
NVLink + NVSwitch:通信成为芯片级设计约束。 这是 GPU 内部架构之外的另一条主线——GPU 之间的相互通信。NVSwitch 是连接机架内所有 GPU 的高带宽交换机,每代翻倍的 NVLink 带宽(4→5→6:900 GB/s → 1.8 TB/s → 3.6 TB/s per GPU)直接影响 MoE 训练和推理的 all-to-all 通信效率。但 NVLink 域内的带宽(H100: 900 GB/s)与跨节点的网络带宽(典型值 400 Gb/s ≈ 50 GB/s 每端口 InfiniBand)之间有约 18 倍的差距——这就是为什么所有分布式训练框架都需要层次化 reduce:先做 NVLink 域内的 reduce-scatter,再做跨节点的 all-reduce,最后在 NVLink 域内 all-gather。
NVLink SHARP:交换机内归约。 NVSwitch 第三代开始支持 SHARP(Scalable Hierarchical Aggregation and Reduction Protocol),让 all-reduce 的求和操作在交换机内部完成,而不是消耗 GPU 计算资源。传统的 ring all-reduce 需要每个 GPU 先发数据、收数据、归约、再转发,2(N-1)/N 次数据传输。有了 SHARP,每个 GPU 只需发送一次数据到交换机,交换机完成归约后广播结果回来。NCCL 的 NVLS 算法专为这种拓扑设计,NVLS Tree 进一步用树状扇出处理节点间通信。
集体操作的四种算法,各有取舍。 NCCL 根据消息大小和拓扑自动选择:Ring 适合大批量数据(所有链路同时繁忙,带宽最优);Tree 适合小消息扩展到大规模(log(N) 跳数,延迟最优);NVLS 利用 NVSwitch SHARP(减少传输轮次);CollNet 利用 InfiniBand SHARP(跨节点归约)。同一集体操作(如 all-reduce)在 NVLink 域内用 NVLS 做,在跨节点时转成 ring,NCCL 自动切换——这就是上一段提到的层次化通信的核心实现。
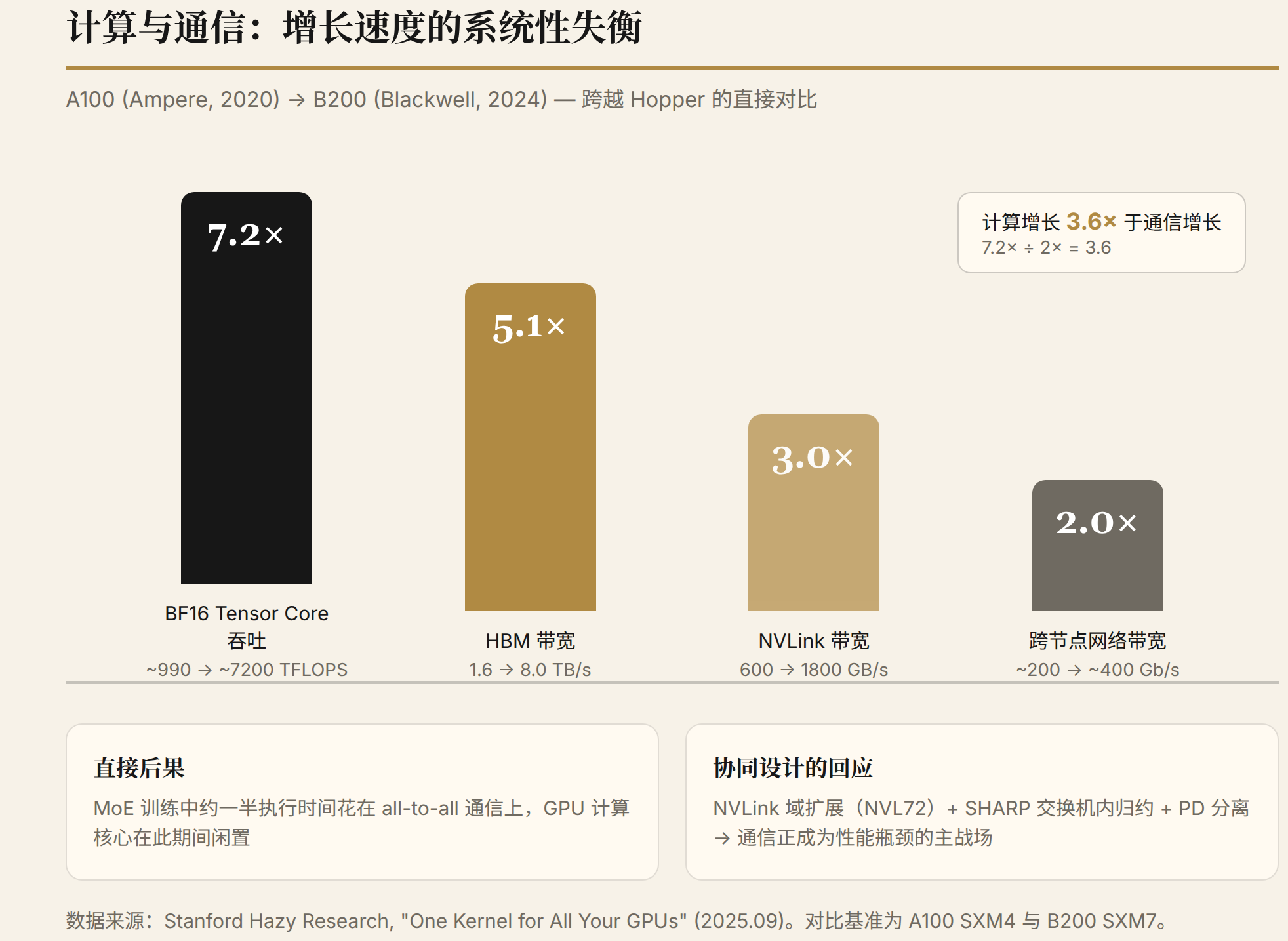
计算与通信的权衡定量化。 Stanford Hazy Research 2025 年的实测显示(One Kernel for All Your GPUs),从 A100(Ampere)到 B200(Blackwell)跳过 Hopper 的直接对比中,BF16 tensor core 吞吐提升 7.2 倍,HBM 带宽提升 5.1 倍,NVLink 带宽提升 3 倍,跨节点网络带宽仅提升 2 倍。通信带宽的增长速度系统性落后于计算——在 MoE 训练中,约一半的执行时间可能花在 all-to-all 通信上,GPU 计算核心在这段时间内闲置。这解释了为什么通信结构的 co-design(NVLink 域扩展、SHARP 卸载、PD 分离)正在成为性能瓶颈的主战场。
2.5 软件→硬件的两条反向路径
以上是从硬件特性出发看能做什么。反向来看——软件如何利用现有硬件特性、又在哪些地方暗示下一代硬件应该优化什么——是理解 co-design 完整图景的另一半。
2.5.1 利用硬件:软件如何"借用"GPU 特性
FlashAttention 对 TMA 和 TMEM 的分层利用。 FA-3 在 Hopper 上的高性能依赖两个硬件特性:TMA 负责异步数据搬移(Q、K、V tile 从 HBM → shared memory),WGMMA 负责异步矩阵计算。这两个硬件单元各自的异步性被 FlashAttention 的软件流水线精确编排——tile 加载 + softmax 计算 + 结果写回三阶段完全重叠。FA-4 更进一步,用 Blackwell 的 TMEM 替代传统寄存器作为累加器,省下了大量寄存器压力,让更大的 tile 尺寸(256KB/SM 的 TMEM 容量)成为可能。软件设计直接围绕硬件特性展开。
DeepSeek MLA 对冲 HBM 带宽瓶颈。 Multi-head Latent Attention 的核心是把 KV cache 压缩到一个低维 latent 空间(约 4-8 倍压缩),每个 token 只存储压缩后的 latent vector 而非完整 KV。这本质上是软件层面对 HBM 带宽墙的回应——在 HBM 带宽增长跟不上模型上下文窗口膨胀的现实下,通过算法减少每 token 的 HBM 读取量。V4 的 CSA/HCA 是这条路径的延续。
Speculative decoding 填充 GPU 空闲周期。 推理的 decode 阶段是带宽受限的——GPU 计算单元大部分时间在等待 KV cache 从 HBM 到达。Speculative decoding 的思路是让一个轻量级 draft 模型先做快速预测(消耗少量计算),然后用目标模型批量验证(大幅提高单次 decode 的 token 产出)。这是用软件策略解决硬件利用率问题——把内存带宽瓶颈期的空闲 SM 用于轻量级推理。
MoE expert routing 感知 NVLink 拓扑。 DeepSeek 和 Kimi K2.5 的 expert routing 策略在语义路由之外加入了硬件拓扑约束:优先把 token 路由到同 NVLink 域内的 expert,避免跨域通信。NVLink 域内带宽 1.8 TB/s(Blackwell)远高于跨节点带宽(~100GB/s),模型层的路由决策隐含了这个数量级差距。
2.5.2 反推硬件:哪些软件模式值得硬化
软件层不断涌现的标准模式,正在为下一代硬件提供设计方向。
Attention 机制趋于标准化 → 专用 attention 单元。 FlashAttention 在四年间从学术原型变成每个推理引擎的标配。Causal multi-head attention + softmax + KV cache 的操作序列已经高度标准化。Groq 的 LPU 已经用 SRAM 流式架构实现了 attention 专属硬件;NVIDIA 的路径是逐代增加 attention 的硬件支持——TMA(数据搬移)→ TMEM + UMMA(矩阵积累)→ 下一步可能是一个完整的 attention accelerator 流水线。这个判断与 Dylan Patel 在访谈中的观点一致:当某个操作模式持续几代都稳定,它就应该在硬件里。
PD 分离从实验到产品 → 异构推理芯片。 DeepSeek 的 PDC 架构公开验证了 prefill(计算密集)和 decode(带宽密集)需要不同的硬件配置。NVIDIA 用 Groq 3 LPX 收购验证了这个方向——单独一颗 SRAM-based 芯片专门管 decode,主 GPU 管 prefill 和训练。如果 PD 分离成为推理部署的标准模式,下一代推理硬件很可能走向芯片级异构:高计算密度芯片(prefill)+ 高内存带宽芯片(decode)。
MoE all-to-all 通信模式 → SHARP 和 PXN。 MoE 的核心通信模式(token dispatch + expert computation + combine)对 all-to-all 延迟极其敏感。NCCL 2.12 的 PXN 技术(Proxy eXtended NIC)通过 NVLink 域内重排数据位置减少跨节点传输量,NVSwitch 的 SHARP 把归约操作卸载到交换机。这些本质上都是把软件层的痛点在下一轮硬件中硬化。未来的 NVSwitch 可能会支持专门的 all-to-all 原语。
FP4 量化的工业标准化 → tensor core 原生支持。 FP4 从 Blackwell 开始获得 tensor core 原生支持,Rubin 进一步把 tensor core 宽度翻倍对标 FP4 而非 BF16。这个演进路径很清晰:先是软件模型团队验证了 FP4 精度够用(DeepSeek V3 的 FP8 mixed precision 训练),然后 NVIDIA 软件定义出 NVFP4 格式,最后在硬件层硬化为原生路径。软件先验证 → 硬件再加持,是最健康的 co-design 节奏。
三、协同设计的重点方向
3.1 模型架构向硬件 tile 对齐
SonicMoE 论文(2026 年)给出了模型↔芯片协同设计最具体的技术实现:tile-aware token routing。核心思路是让 MoE router 分发给每个专家的 token 数量始终是 GEMM tile 尺寸的整数倍。在 Hopper 上,这意味着每个专家收到的 token 数是 128 的倍数(WGMMA tile 高度);在 Blackwell 上,tile 形状变了(UMMA 的 tile 配置不同),最优 token 数也相应调整。
这个设计产生了一个有趣的硬件-模型耦合:token routing 不再是纯粹由模型语义决定的路由决策,而是被硬件 tile 尺寸约束的工程问题。SonicMoE 实测在 Hopper 和 Blackwell 上取得 1.86 倍吞吐量提升(86% 加速),相比传统 ScatterMoE baseline。其中 token rounding 消除 padding 浪费贡献了约 16 个百分点,其余来自与 Blackwell TMEM pipeline 的重叠优化。模型质量损失可忽略。
3.2 推理范式与芯片架构的互相塑造
Reasoning 模型的兴起(OpenAI o 系列、DeepSeek R1)改变了推理负载的特征:从短输入 → 短输出生成,变成了短输入 → 长链式推理 → 长输出生成。这意味着 decode 阶段(内存带宽受限)成为性能瓶颈,而不是 prefill(计算受限)。
Cerebras 和 Groq 在 reasoning 场景获得了 SRAM/流式架构的先天优势——高吞吐的 sequential token 生成正好发挥了其确定性执行和低延迟的特性。这是 Dylan Patel 在 MatX 播客中提到的"reasoning 和 RL 打乱了硬件路线图"的含义:为传统 inference(短 prompt → 短输出)设计的芯片,在 reasoning(短 prompt → 长链推理 → 长输出)下 memory-to-compute 比需要重新设计,从 ~1:10 偏向 ~1:20+。
3.3 NVIDIA 的"Extreme Co-Design"策略
Rubin 是 NVIDIA 用硬件迁就模型负载的最直接体现——与 DeepSeek 的"模型迁就硬件"形成互补的另一个方向。官方明确使用了"extreme co-design"这个词,不再只是 GPU 的迭代,而是把六颗芯片(Rubin GPU、Vera CPU、NVLink 6 Switch、ConnectX-9、BlueField-4、Spectrum-6)设计成一个协同计算单元。
具体到协同效应:
- Vera CPU 与 Rubin GPU 双向相干共享数据,减少 CPU-GPU 之间的 PCIe 传输瓶颈。
- NVLink 6 把 72 GPU 扩展到更大域(Rubin NVL72 rack),让 MoE 的 expert all-to-all 通信在单机架内完成。
- ConnectX-9 和 BlueField-4 处理网络和存储 offload,让 GPU 专注计算。
- 第三代 Transformer Engine 用新的 sparsity 模式替换了 2:4 structured sparsity,配合 NVFP4 实现有效 50 PFLOPS 的 FP4 性能。
结果:相比 Blackwell 平台,Rubin 声称实现 10 倍推理 token 成本降低和 4 倍 MoE 训练 GPU 数量减少。这些数字只有在跨层协同设计下才可能实现——单芯片性能提升不可能达到 10 倍。
3.4 MLP 与 Attention 的分离部署
MatX 播客中讨论了一个更激进的协同设计方向:将 transformer 的 MLP 层和 attention 层分离到不同的硬件资源上。两种算子的资源特征根本不同,这不是工程偏好:
- MLP 层是计算密集型。主要操作是两大片矩阵乘法(GEMM),受限于 tensor core 的 FLOPS 吞吐。decode 阶段 batch size 较小时,每个 token 的 MLP 计算只需几百微秒,但要求 SM 在这段时间内全速运行。
- Attention 层是内存带宽密集型。decode 阶段每生成一个 token,都要读取整段 KV cache——对于一个 128K 上下文、671B 参数量级的 MoE 模型,KV cache 可达数十 GB。计算量不大,但 HBM 带宽是瓶颈。
把两者放在同一组 GPU 上交替执行时,资源利用率必然不均衡:算 MLP 时 HBM 带宽大量闲置(GEMM 数据在 shared memory / TMEM 中循环使用),算 attention 时 tensor core 大量闲置(只做点积但不启动大规模矩阵乘法)。整体 GPU 利用率通常只有 30-40%。
分离部署的逻辑是让一组 GPU 专门跑 GEMM(可以配置为高计算密度模式,甚至用不同电压/频率曲线),另一组专门管理 KV cache(用更大 HBM 容量、更低计算规格的配置)。理论上,两组资源的利用率都可以提到 60-70% 以上。
DeepSeek 的 PDC(Prefill-Decode Disaggregated Serving)架构是先行案例。PDC 把 prefill 和 decode 分离到不同节点——prefill 节点处理长 prompt 输入(计算密集),decode 节点逐 token 生成(带宽密集)。根据 DeepSeek V3 技术报告(2024 年 12 月)及其生产环境部署数据,PDC 部署相比混合部署可以提升 2 倍以上的有效吞吐。MLP/attention 的进一步分离是按照算子类型(compute-bound vs memory-bound)而非阶段切分硬件资源,更细粒度。
制约因素是通信开销:分离后 MLP 和 attention 之间的激活值需要经 NVLink 传输,引入约 5-10 微秒的额外延迟。对于追求极低延迟的交互场景(如实时对话),这个开销需要权衡。但对于吞吐优先的批处理推理(reasoning、batch API),分离部署的收益远大于通信成本。
3.5 产业格局:协同设计成为竞争壁垒
Dylan Patel 的判断对产业格局有几个深层含义:
NVIDIA 的真正护城河:生态协同锁定,不是 CUDA。 当 DeepSeek、Qwen、Kimi 等主流开源模型的架构都为 NVIDIA GPU 优化后,下游用户选择非 NVIDIA 硬件的代价不只是重写 kernel,而是模型架构层面的性能折损。Jensen Huang 故意支持 NeoCloud(CoreWeave 等)的目的是让 GPU 分散部署到更多买家手中,而非短期收入——"今天卖给 CoreWeave 的一颗 GPU,五年后会削弱 Google TPU 和 Amazon Trainium 的竞争力"。
自研 ASIC 的账。 Google 和 Amazon 投入巨资开发 TPU 和 Trainium,核心驱动力是协同设计的自主权,而非芯片成本(先进制程的 NRE 成本极高)。Google 可以让 Gemini 的架构完全匹配 TPU 的 systolic array 形状,Amazon 可以让 Trainium 的 sparse 计算能力适配 Anthropic 的 dense 模型。这种垂直整合的优势只有在模型团队和芯片团队紧密协作时才能兑现。
中国 AI 芯片的挑战。 据 SemiAnalysis DeepSeek V4 深度分析(2026 年 6 月 9 日)报告,DeepSeek V4 在发布首日即支持了华为昇腾 950 部署,说明协同设计已经跨出了 NVIDIA 生态。但昇腾面临的挑战是:NVIDIA 每年迭代一代架构(Hopper → Blackwell → Rubin),模型也跟着调整。中国芯片要跟上这个协同设计的节奏,需要模型团队和芯片团队的同步演进,而不仅仅是单点性能追赶。
四、总结:协同设计的下一阶段
Dylan Patel 的 100x 框架提供了一个理解 AI 效率提升的清晰模型:驱动 AI 降本增效的是模型架构、kernel 优化和芯片设计三层的乘法效应,而非任何单一层的进步。
这个框架的推论是:
- 模型团队不能只关心模型。 模型架构决策(expert 多大、多稀疏、什么 attention 机制)直接影响硬件能跑多快。不关心硬件 tile 尺寸的模型团队,会在推理成本上吃亏。
- 芯片公司不能只看 FLOPS。 Rubin 的 50 PFLOPS FP4 数字只有在模型真正使用 NVFP4 量化、attention pattern 适配 TMEM 调度时才能兑现。芯片的竞争力越来越取决于它与上层软件栈的协同深度。
- 推理框架的差异化在收窄。 FlashInfer 作为 NVIDIA 主导的统一 kernel 库正在吸收 TensorRT-LLM 的高性能 kernel 到 vLLM 和 SGLang 中,三大框架的 kernel 质量差距在缩小。差异化将更多来自调度策略(如 PD 分离、prefix 复用)而非 kernel 本身。
- 下一个 100 倍可能来自更激进的架构变革。 Dylan Patel 提到的几个长期赌注——Analog compute(芯片物理层)、energy-based models(算法范式)、co-packaged optics(互联层)——每一个都有可能打破当前的协同设计范式,开启新一轮乘法效应。但它们分别作用于不同的栈层,时间和成熟度差异很大。CPO 的落地最接近(预计 2030 年前),analog compute 和 EBM 尚处于基础研究阶段。
但至少在未来 3-5 年内,主导 AI 效率提升的仍然是当前范式的深化:更细粒度的 MoE、更激进的量化、更深的 kernel fusion、更紧密的模型-硬件耦合。Dylan Patel 的判断——inference 将成为比石油更大的市场——如果是正确的,那么谁能在这条协同设计链上做到极致,谁就掌握了 AI 时代最值钱的基础设施层。
声明: 本文基于 Sequoia Capital Training Data 播客第 92 期(2026 年 6 月 30 日,Dylan Patel 访谈)、MatX 播客(2026 年 4 月 20 日,Clive Chan / Dylan Patel / Reiner Pope 对谈)、SemiAnalysis DeepSeek V4 深度分析(2026 年 6 月 9 日)、SonicMoE 论文(arXiv 2512.14080)、NVIDIA Rubin 官方技术文档及 SemiAnalysis Vera Rubin 分析(2026 年 2 月 25 日)等公开信息综合撰写。不构成投资建议。文中数据截至 2026 年 7 月 5 日。