Uber 四个月烧光全年 AI 预算。某企业一个月给 Anthropic 刷出 5 亿美元账单。Klarna 用 AI 替掉 700 人后悄悄重新招人。与此同时,OpenAI 和 Anthropic 季度收入突破百亿美元。一边是用户的焦虑,一边是厂商的狂欢。问题不只是贵——而是你花的每一块钱里,有多少在解决问题,有多少在帮模型公司冲收入?
一、5 亿美元月账单
2026 年春天,企业 AI 支出爆了几颗炸弹。
Uber 先炸的。CTO 在 4 月承认,全年的 AI 预算已经花光了——那年才过了四个月。罪魁祸首是 Claude Code。5000 名工程师几乎人手一个,人均 API 费用从每月 500 美元涨到 2000 美元,速度远超财务模型的预测。
更耐人寻味的是 Uber 总裁 Andrew Macdonald 在播客里的一句话:"很难说 AI 使用量的增加和实际交付给消费者的新功能之间有什么明确的联系。"
钱花了。花在了什么地方,说不清。
然后是那个 5 亿美元的匿名案例。一位 AI 顾问告诉 Axios,他的一家企业客户没有设置任何使用上限。一个月后,Claude 账单上赫然写着大约 5 亿美元。这个数字在 2026 年 5 月被多家媒体交叉确认。Uber 2025 年全年的研发支出是 34 亿美元。一家企业一个月的 AI 账单能烧掉 Uber 年研发预算的六十分之一。
预算被烧穿不是因为规模太小。是因为计费模式变了——AI 从"按座位收费"变成了"按水表走字"。水表还在加速转。
微软的动作侧面印证了这一点。2026 年 5 月,微软开始取消内部工程师的 Claude Code 许可证,把他们迁移到自家的 GitHub Copilot CLI。官方说法是"技术整合"。内部人士透露,财务压力才是核心动因。按 token 计费的模式,让微软这个体量的公司也开始肉疼。
Klarna 的故事更像一则寓言。2024 年,这家瑞典金融科技公司高调宣布 AI 聊天机器人替代了 700 名客服。CEO Sebastian Siemiatkowski 站在每一个能站上的讲台上,说"AI 正在取代人类"。一年后,Klarna 悄悄恢复了人类客服的招聘。CEO 本人承认,AI 客服的质量达不到公司标准。那些被裁掉的人,以"远程支持"的名义被重新招了回来。
从"AI 替代人类"到"重新招人",这个弧线只用了一年。
二、"不是贵了,是你用多了"
Token 单价确实在暴跌。2023 年到 2026 年,同等级模型的 token 价格下降了大约 280 倍。GPT-4 刚出时 $30/百万 token 输入,今天 GPT-5 只要 $2.50。DeepSeek V3.2 低至 $0.14。
所以模型公司有充分的理由说:我们越来越便宜了。
但账单在涨。
因为每次调用的 token 消耗量增长得比单价下降得更快。这不是感觉,有数据。
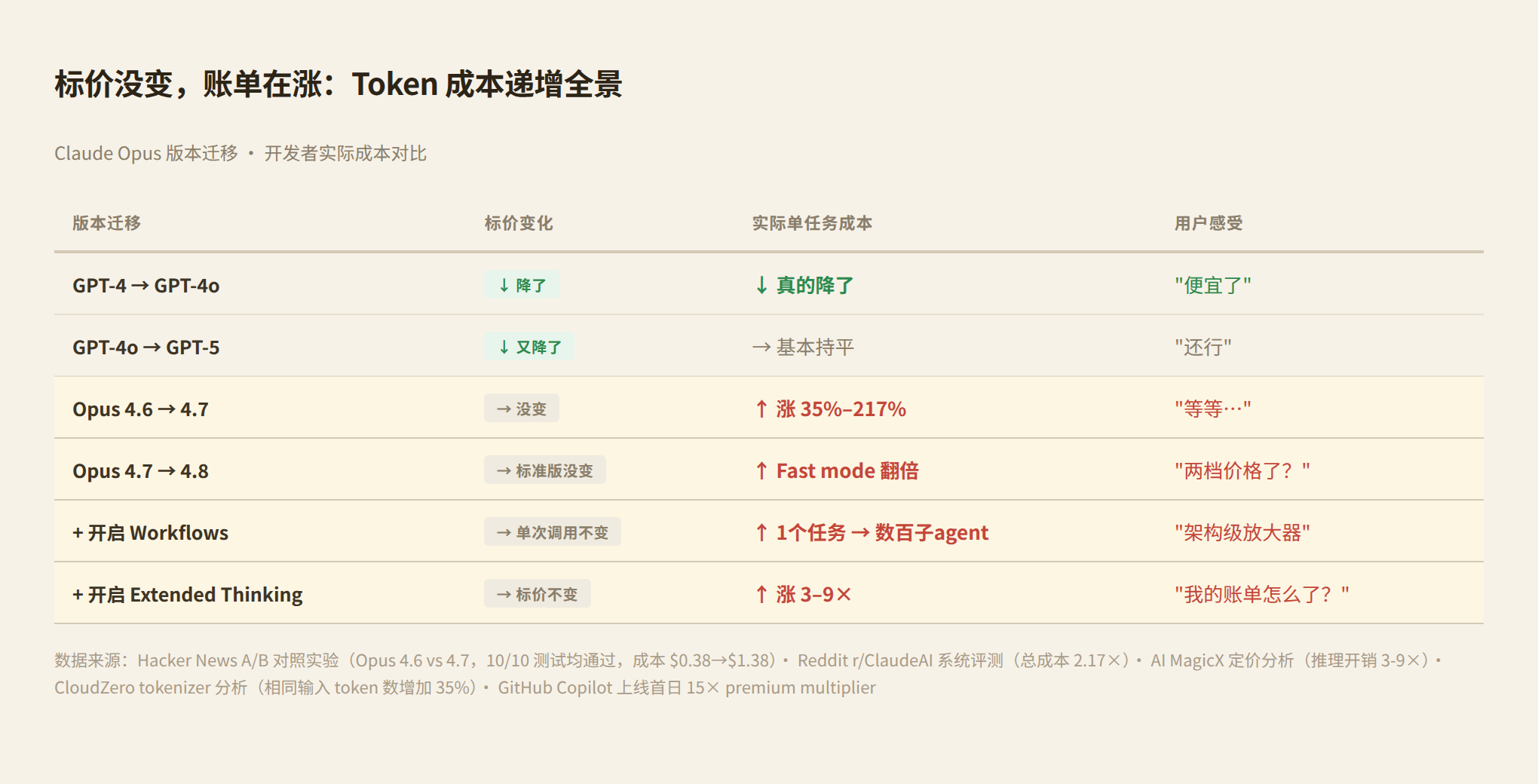
第一个证据:新 tokenizer。 Claude Opus 4.7 在 2026 年 4 月发布时,Anthropic 宣布"价格不变,仍是 $5/百万输入 token"。开发者实测发现,新 tokenizer 对相同文本多产生 35% 的 token。你输入完全一样的提示词,4.7 比 4.6 多消耗三分之一以上的 token。价格表上一个数字都没变,但你每次调用多花了 35%。这不是涨价——这只是"同样的文本占更多 token 了"。
第二个证据:对照实验。 一位开发者在 Hacker News 上做了严格的对比。同样的编程任务,Opus 4.7 消耗了 3.6 倍的 token,成本从 $0.38 涨到 $1.38。测试结果呢?完全一样——都通过了 10/10 测试。多花的一美元买到了更好的代码风格和更充分的注释,核心输出没有变化。
第三个证据:effort level 的默认值。 Opus 4.7 新增了 xhigh effort level,在 Claude Code 中被设为默认值。大多数用户不知道自己正在为更高强度的推理付费。Reddit 上的系统实测:Opus 4.7(xhigh effort)相比 Opus 4.6(high effort),总成本是 2.17 倍。输入 token 略少,但输出 token 大幅增加,agentic 模式下的工具调用从 16 次涨到 22 次。一个 YouTube 视频的标题说出了社区情绪:"Opus 4.7 Is GREAT (except the token usage)"。
第四个证据:Fast mode 翻倍定价。 六周后,Opus 4.8 发布(2026 年 5 月 28 日)。标准模式标价不变,$5/$25。但新增了 Fast mode:$10/$50。直接翻倍。Fast mode 跑到 2.5 倍输出速度,Anthropic 说"大致比之前模型的快速推理便宜三倍"。是不是便宜了三倍,取决于你的参照系。如果你从 4.7 标准模式切到 4.8 Fast mode,你付的是双倍价格。
第五个证据:Workflows——架构级的 token 放大器。 Opus 4.8 引入了 Workflows 原语:一个 agent 规划任务后,扇出数百个并行子 agent 分别执行,再合并结果。一次用户操作,数百次独立 API 调用,每次都是独立的 token 消耗。这不是用户"选择多用"——这是产品架构在替你决定多用。
第六个证据:推理模型的隐藏成本。 AI MagicX 的定价分析指出,使用推理模型(o3、Claude extended thinking)的实际成本是标价的 3-9 倍。"思考过程"产生的 token 被单独计费,但大多数用户不会把 thinking tokens 和 output tokens 分开计算。
把这些拼在一起:
| 版本迁移 | 标价变化 | 实际成本变化 | 用户感知 |
|---|---|---|---|
| GPT-4 → GPT-4o | ↓ 降了 | ↓ 真的降了 | "便宜了" |
| GPT-4o → GPT-5 | ↓ 又降了 | → 基本持平 | "还行" |
| Opus 4.6 → 4.7 | → 没变 | ↑ 35%-217% | "等等……" |
| Opus 4.7 → 4.8 | → 标准没变 | ↑ Fast mode 翻倍 | "两个价格了?" |
| 开启 Workflows | → 单价不变 | ↑ 一个任务 = 数百子任务 | "架构级放大器" |
| 开启 extended thinking | → 标价不变 | ↑ 3-9× | "我的账单怎么了?" |
还有一个细节值得记住:GitHub Copilot 在 Opus 4.8 上线当天加了 15x premium multiplier——不是涨 15%,是乘以 15。直到使用量计费在 6 月 1 日生效后才调整回来。连分发渠道都觉得新模型的消耗量需要价格护栏。
一位 Reddit 用户在 6 月初发帖:他 5 月份消耗了 11.5 亿 input tokens。他的建议是——"去审计你的缓存命中率"。
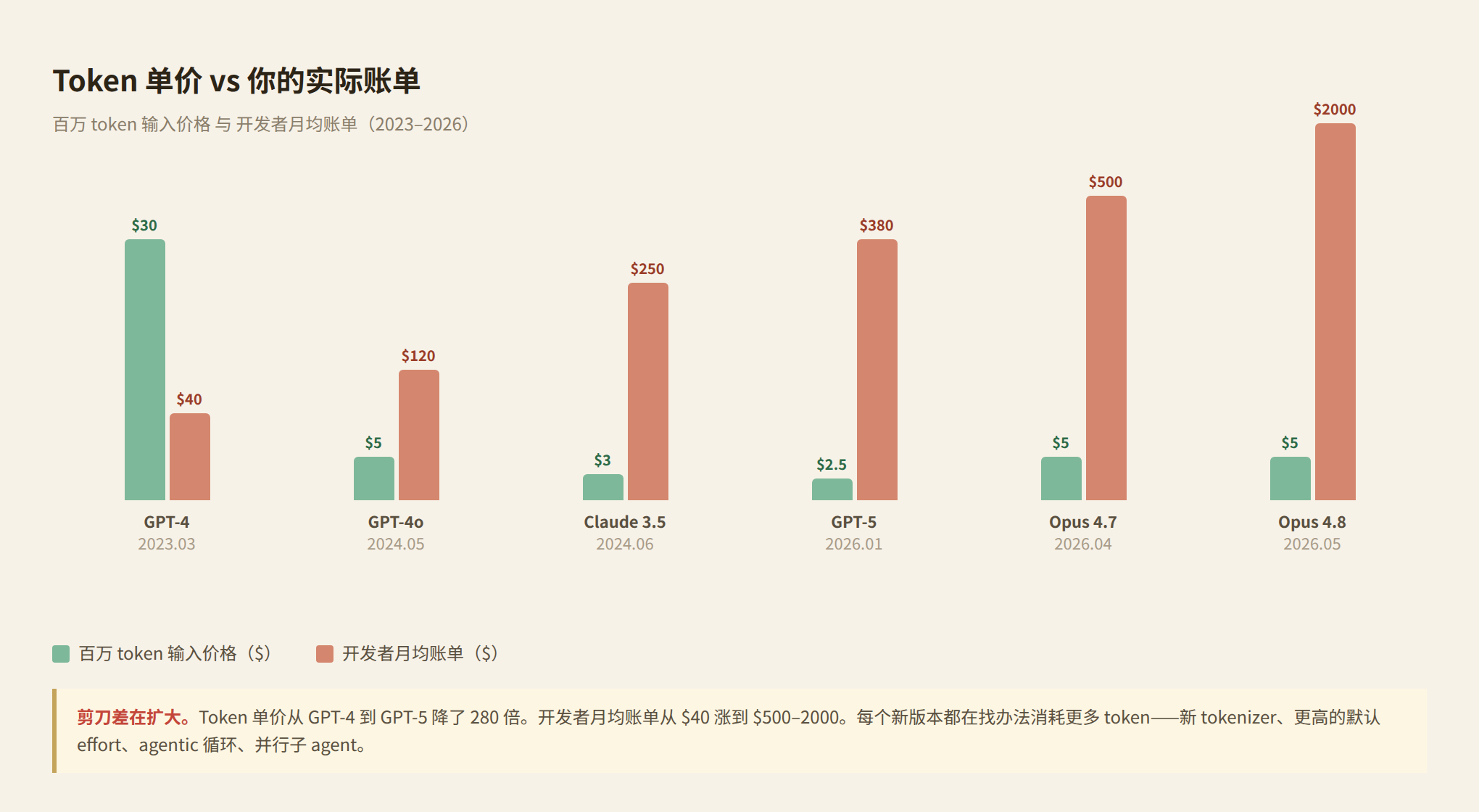
Token 单价在降。但每个版本的模型都在用更多 token 完成同样的任务,然后用 Fast mode 翻倍定价,用 Workflows 扇出数百个子任务,用新 tokenizer 增加每次输入的 token 数,用更高的默认 effort level 推高单次推理成本。
这不是技术必然。这是系统性的商业选择。
三、收入狂飙的另一面
就在企业客户叫苦的时候,大模型公司的收入在狂飙。
OpenAI 2026 年 Q1 收入 57 亿美元。Anthropic 同期 48 亿美元,预计 Q2 翻倍到 109 亿美元,年化冲向 450 亿美元。最新一轮融资目标 300-500 亿美元,估值 9500 亿美元——超过 OpenAI 的 8500 亿美元。
两家公司都在冲刺 IPO 的路上。收入增长的速度直接决定估值的天花板。
CNBC 的一篇评论点出了关键:AI 需求指标是扭曲的。 Token 消耗量是厂商最爱引用的数字——"看,我们的 token 用量又涨了 10 倍!"但 token 消耗量衡量的是工程师在 AI 上花了多少时间,不是他们产出了什么。
Sam Altman 在 2026 年 3 月说了一句话,后来被反复引用:"我们看到一个未来,智能像水电一样是一种公共事业,人们从我们这里按表购买。"
这是愿景。也是定价策略。
当你把 AI 定义为公共事业,按用量计费就天经地义。用量越大,收入越高。"鼓励用户多用"就变成了商业模式的核心。Anthropic 的做法更直接:从固定价格的 Enterprise 套餐转向纯按 token 计费。CNBC 认为这是"更诚实"的做法——至少收入反映了真实使用量。但这也意味着,Anthropic 的收入增长和客户的 token 消耗量绑定了。客户的每一分"浪费",都是 Anthropic 的收入。
激励错位在这里显现。 模型公司的利益是让用户多消耗 token。用户的利益是用更少 token 解决更多问题。这两个方向天然相反。
而当收入和 token 消耗绑定时,"让每次任务消耗更多 token"就不再是副作用——它是产品设计的核心目标。
四、模型进步在放缓吗?
如果模型能力在快速提升,那 token 消耗的增长至少可以说服自己:我们是在为更好的能力买单。但 2026 年上半年的证据并不支持这个叙事。
New Scientist 对 GPT-5 的评价是两个词:gains are modest(进步有限)。OpenAI 声称 GPT-5 是"phD-level expert"(博士级专家),但独立评测机构不买账。多维度评测显示,GPT-5 与 GPT-4.5 之间的差距远小于 GPT-4 到 GPT-4.5 的飞跃。
HEC Paris 的分析用了更直白的判断:"业内公开的秘密是,前沿模型已经碰到了天花板。" Scaling law——那个让 AI 圈相信"只要加算力加数据就能变强"的经验规律——正在显现边际递减。
MIT 的一篇论文提出了"Meek Model Convergence":低预算模型的性能正在快速追赶最先进的模型。花 100 倍的钱训练出来的模型,优势在缩小。
但让我们诚实地说另一面。模型没有完全停滞。 Opus 4.8 在 Super-Agent benchmark 上是唯一一个端到端完成所有 case 的模型,超越了 GPT-5.5。Legal Agent Benchmark 上拿了最高分。Claude Mythos 在安全漏洞发现上的能力是质的飞跃——Project Glasswing 扩展到 200 多家组织,包括美国政府和主要科技公司。SWE-bench Verified 上 GPT-5.4 Pro 达到了 94.6%。这些进步是真的。
问题不是模型没有进步。问题是进步的性价比在恶化。从 GPT-3 到 GPT-4 的跨越,每一美元买到的能力增量远大于从 GPT-5 到 GPT-5.4 的跨越。边际收益在递减,边际成本——以 token 消耗衡量——在上升。
能力 plateau 和 token 消耗爆炸同时发生,指向同一个结论:厂商在用"更多 token 消耗"来弥补"每次调用能力提升放缓"带来的收入压力。
Extended Thinking 让模型在回答前"想更久",消耗更多 token。Agentic loop 让模型反复迭代,每次迭代都是新的 token 消耗。Opus 4.7 把 xhigh effort 设为默认,推高单次推理成本。Opus 4.8 引入 Workflows,一次操作扇出数百子 agent。OpenAI 的 o 系列推理模型同样走"思考更久"的路线。
当模型单次调用的能力提升放缓,延长推理链是最直接的增收手段。用户得到更长的等待时间。模型公司得到更多的 token 收入。
Reddit 上一个 Claude Code 用户的帖子说得直白:"LLM 的能力已经 plateau 了。过去半年的进步大部分是更好的工具链(tooling),而不是模型本身变聪明了。"

五、用户到底想要什么?
回到一个基本问题:用户为 AI 付费,想买到的是什么?
不是 token。不是推理步骤。不是 Extended Thinking 的内部独白。不是 Workflows 扇出的数百个子 agent。
用户想用更少的时间、更少的钱,解决更难的问题。
这个需求和大模型公司的商业模型之间存在结构性矛盾。
Claude Code 的用户反馈两极分化。Agentic 模式确实能完成更复杂的任务。但一个中等复杂度的重构任务可能消耗 50 万 token,成本远超预期。用户在"好用"和"用不起"之间反复拉扯。
企业 CTO 的焦虑更具体。McKinsey 的数据:2026 年春季,95% 的工程师每月都在用 AI 工具,70% 的已提交代码源自 AI。但 Uber 的 Macdonald 说出了大家的心声——没法证明 AI 使用量和业务产出之间的因果关系。
Amazon 的案例是黑色幽默。内部 AI 使用排行榜按团队 token 消耗量排名。工程师们为了冲排名疯狂刷 token。公司后来关闭了这个排行榜——因为它奖励的是浪费,不是产出。
更尖锐的数字来自 Bessemer Venture Partners 的 AI 定价报告:每 1 美元的 AI token 支出中,只有 0.18 美元产生了直接用户价值。0.44 美元用于修复 AI 引入的 bug。 如果这个数字接近真实,token 经济的一半是在兜圈子。
六、两条可能的出路
按结果计费(Outcome-based Pricing)
Bessemer、a16z 等投资机构在 2026 年密集推动的方向。不再按 token 计费,而是按"解决了多少问题"计费——每次成功的代码合并、每次准确的安全漏洞发现、每次被用户采纳的客服回复。
Intercom 的 AI 客服产品 Fin 已经在做:按"解决的对话"计费,而不是按 token。据说效果不错。
但按结果计费要跑通,前提是"结果"可以被清晰定义和度量。编程场景还算容易(PR 是否被 merge)。写作、研究、创意场景就难了。而且这要求模型公司从根本上改变收入结构——从"用户用得越多我赚越多"变成"用户问题越少我赚越多"。不符合任何一家冲刺 IPO 的公司的短期利益。
模型成本继续下降
Token 单价确实在跌。Google I/O 2026 发布 Gemini 3.5 Flash,宣称可以帮助企业每年节省 10 亿美元 AI 成本。DeepSeek V3.2 的 $0.14/百万 token 让 Anthropic 的 $5/百万 token 显得奢侈。
但悖论还在:token 单价在降,总账单在涨。 模型公司通过 agentic loop、extended thinking、新 tokenizer、Workflows 扇出等方式,让每次任务的 token 消耗量增长得比单价下降得更快。Opus 4.7 的案例已经证明了这一点。
开源模型在提供替代选择。DeepSeek、Llama、Qwen 在特定场景下已经接近 GPT-4.5 水平。当"够用"的模型可以自己部署、成本可控,企业对前沿模型的高价 token 就有了退出选项。
七、结论:不是泡沫,是定价权之争
Token 大撤退容易被简化为"AI 泡沫破裂"。事实更微妙。
AI 的价值是真实的。编程效率的提升、安全漏洞的发现、客服成本的下降——这些不是虚构的。问题出在定价权上。当前的市场结构下,大模型公司掌握定价权,定价方式和用户利益方向不一致。
模型能力 plateau 让这个问题更尖锐了。当模型不再每半年有一次显著飞跃,用户自然会问——我多花的那些 token,到底买到了什么?
答案的一部分是:更长的思考链、更多的工具调用、更冗余的迭代过程——以及模型公司 Q2 的收入增长。
Opus 4.7 的案例值得记住:当一个模型公司告诉你"价格没变"的时候,检查一下 token 消耗。 新 tokenizer、更高的默认 effort level、更长的推理链——都是不涨价只涨量的手法。Opus 4.8 走得更远:标准价格不变,Fast mode 直接翻倍,Workflows 把一次操作拆成数百次调用。在"智能按表计费"的时代,水表的转速比单价更重要。
市场迟早会找到新的均衡点。可能是按结果计费。可能是开源模型的大规模替代。可能是企业自建推理能力的普及。
在那之前,用户唯一能做的是:盯紧账单,给 AI 设限额,审计缓存命中率。别让"智能公共事业"变成你关不掉的水龙头。
数据来源:Forbes, Fortune, CNBC, The Information, Axios, New Scientist, HEC Paris, Bessemer Venture Partners, Context Studios, Fast Company, Yahoo Finance, Hacker News, Reddit r/ClaudeAI, Finout, CloudZero, pricepertoken.com, Anthropic 官方公告。截至 2026 年 6 月 4 日。