2026 年 4 月,AWS 做了一件静悄悄但影响深远的事:所有全球新建的非 GPU 数据中心,默认网络架构从胖树(Fat Tree / Clos)切换为一种叫 RNG(Resilient Network Graphs)的扁平拓扑。路由器数量减少 69%,吞吐量最高提升 33%,网络设备功耗降低约 40%。
这不是实验。这是生产环境的默认选项。
消息直到 5 月 28 日才在 Amazon Science Blog 上公开。论文挂在 arXiv 上(2604.15261),作者包括华盛顿大学教授 Ratul Mahajan 和 UCSC 教授 C. Seshadhri——两位都是 Amazon Scholar。
RNG 的意义不在于它能不能替代胖树——那是结果,不是起点。真正值得关注的是:一条在数学上早就被证明更优、但工程上一直走不通的路线,被打通了。这意味着数据中心网络的设计空间突然变大了。以前只有胖树一个选项,现在有了第二个。而第二个选项的存在,会改变所有人重新审视第一个选项的方式。
这篇文章要做三件事:讲清楚 RNG 的原理和工程实现,标出它适用和不适用的边界,然后探讨这条新路线打开的可能性——特别是对推理集群和国内智算中心参考设计的影响。
胖树的根本问题:带宽被层级锁死了
胖树的核心设计是层级化的:服务器连到 Top-of-Rack(ToR),ToR 连到 Aggregation 交换机,Agg 连到 Spine。流量"先上后下",路径被层级锁死。
这个结构有一个数学上的死穴:容量不可复用(lack of capacity fungibility)。
北京到上海的高速堵死了,北京到广州的高速空着。你用不了那条空路,因为你的目的地是上海,公路网的结构决定了你只能走那条固定路径。
论文给了一个精确的例子:12 个 ToR 做 all-to-all 通信,3:1 oversubscribed 胖树只能利用 ToR 上行容量的约 40%。60% 的带宽白白浪费。
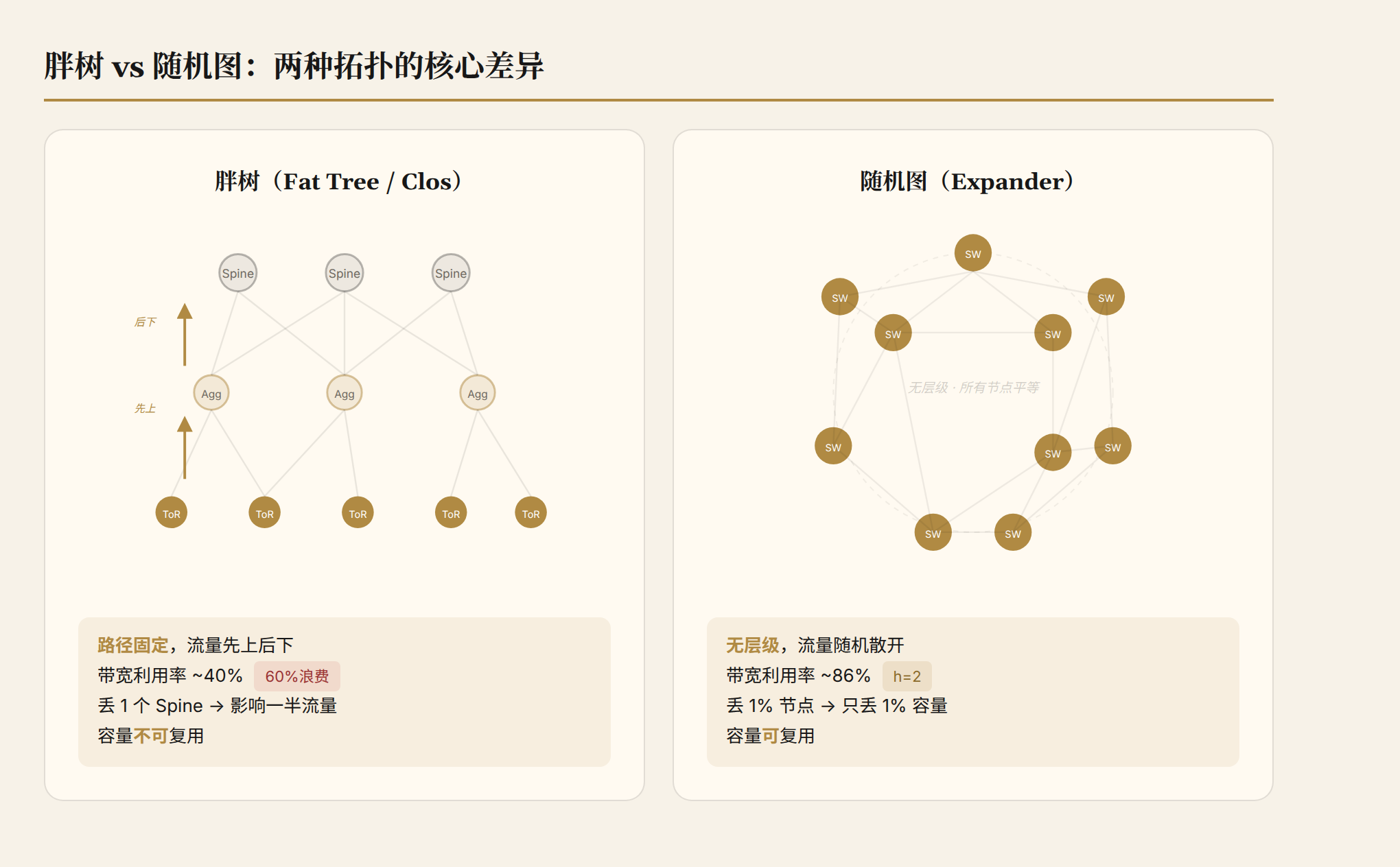
这在单租户场景下问题不大——你可以按需规划流量。但在多租户的数据中心里,你不知道哪个租户什么时候会往哪里发流量,层级化带宽分配必然导致全局性的过度配置。这就是胖树成本居高不下的根源。
故障场景更致命:丢一个 Spine,一半流量直接受影响。随机丢 1% 的交换机呢?影响远大于 1%,因为层级结构放大了故障的"爆炸半径"。
数学家早就知道答案:随机图
1990 年代,数学家已经证明:最优路由网络的拓扑是随机图。
准确地说,是具有高边扩展性(edge expansion)的随机图。核心性质是:对图中任意一小撮节点 S,从 S 连出去的边数总是很多。不存在瓶颈节点,不存在"所有流量必须经过这里"的咽喉要道。
如果用随机图建数据中心网络:
- 每个交换机随机连 64 个其他交换机,没有层级
- 任意两个交换机之间有很多条完全不同的路径可选
- 某条路径堵了,换一条。某个交换机挂了,丢掉大约 1/n 的容量,剩下的照走
容量可复用、故障退化线性、不需要过度配置。理论上的完美拓扑。
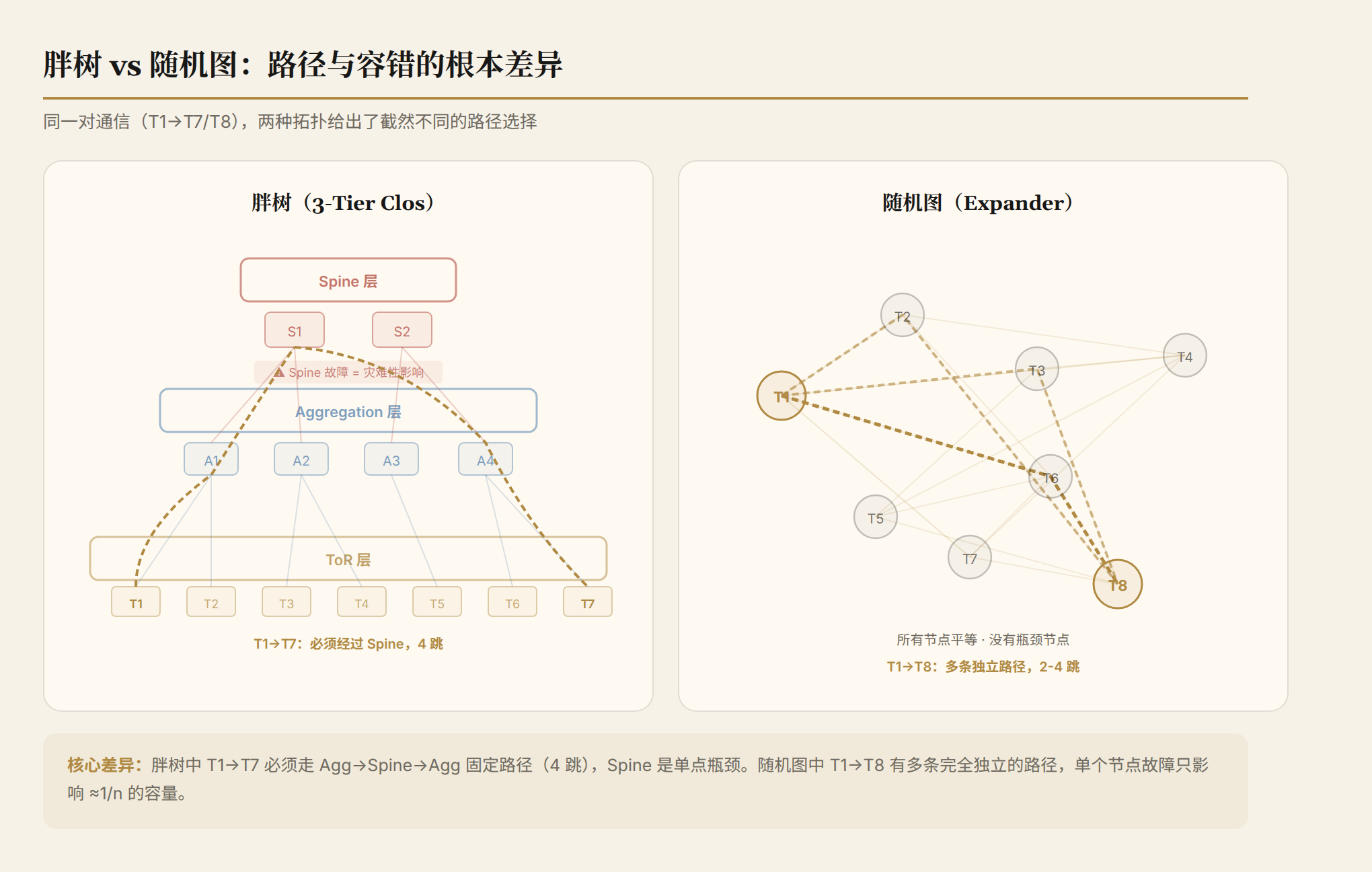
但理论到工程之间隔了三个致命问题,挡了十几年。
三个致命问题
路由怎么做? 标准的最短路径在随机图上效果差——两个节点之间可能只有 1 条最短路径。想找多条独立路径做负载均衡,要用 k-shortest-paths。但 k=8 就需要 20-80 倍的转发表内存,商用交换机芯片放不下。k=64 勉强能跑,但中位数独立路径只有 35 条,oversubscription 仍然有 4.7:1。
线怎么拉? 随机图意味着随机连线。1000 个交换机,每个连 64 个随机邻居,32000 条光纤在机房里随机穿插。AWS 副总裁 Matt Rehder 试过:"We did do the effective spaghetti mess of cabling. It was extremely onerous." 更要命的是增量扩容:每加一个新交换机,要从全机房随机断开几十条已有线重新分配。运营上不可接受。
性能怎么预测? 随机图没有解析模型。你选了 1000 个交换机、每个 64 个 uplink,oversubscription 是多少?不知道,只能靠模拟试。运维团队没法从目标性能反推参数。
三个问题,任何一个没解决就进不了生产环境。RNG 的贡献是同时解决了三个。
Spraypoint:先散开,再收拢
Spraypoint 是 RNG 的路由协议。它的核心洞察是:在随机图中,你不需要全局计算最优路径。源端把流量散开,宿端的"高扇入"自然会把流量收拢。
类比一下。你在北京给上海的朋友寄信。
胖树方式:所有信先送区邮局,再送市邮局,再送上海市邮局,再送区邮局。路径固定,市邮局挂了就全完了。
Spraypoint 方式:你把信随机交给身边 64 个朋友中的一个。每个人都有一张表,告诉你"如果要寄给上海的张三,往这个方向走"。信件像涟漪一样散开,然后逐层向目的地收拢。
具体机制分三步:
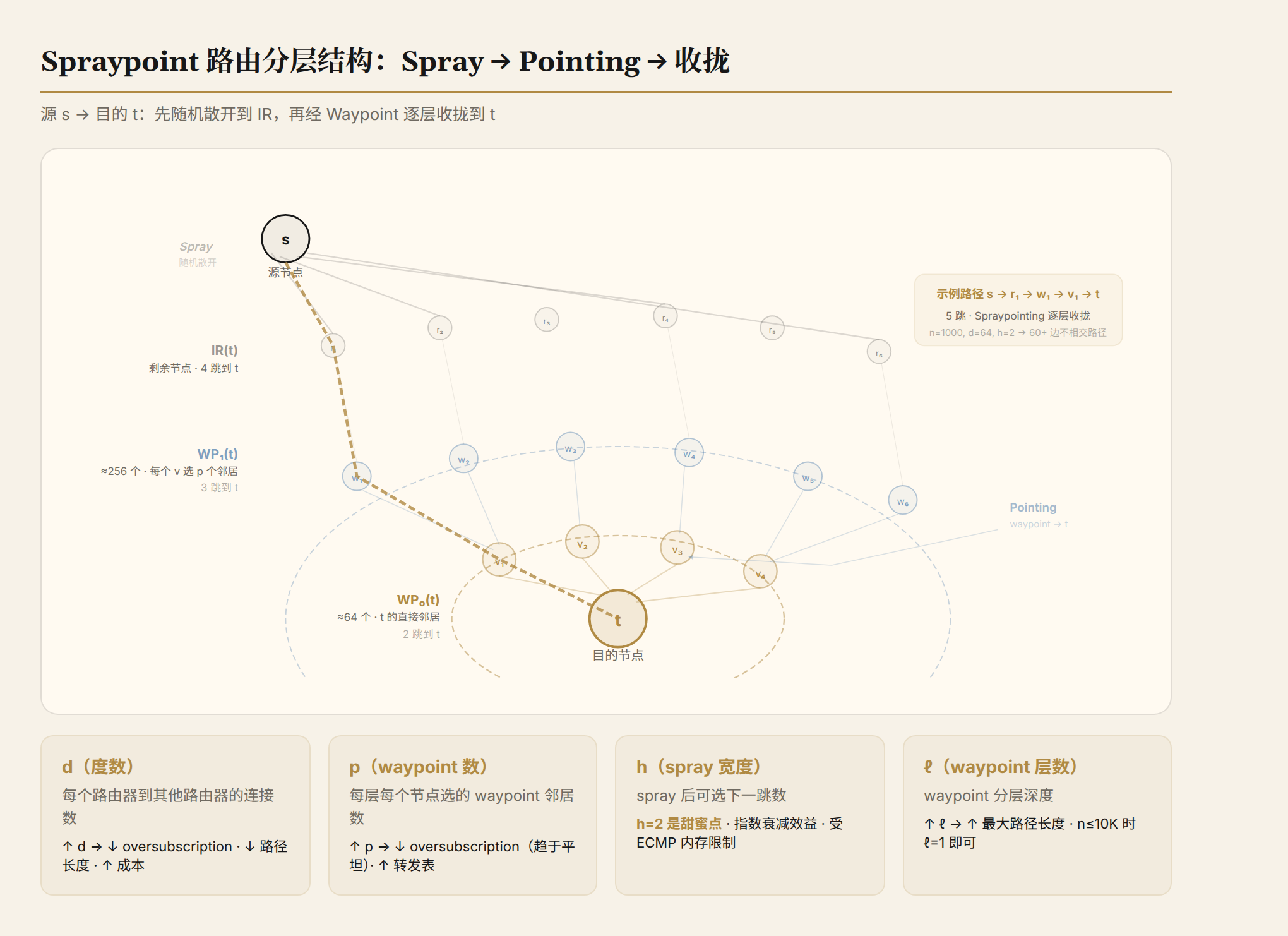
第一步,Spray(发散)。 源交换机收到一个包,目的地是 t。从自己的 64 个邻居中随机选一个(ECMP 哈希),把包发过去。
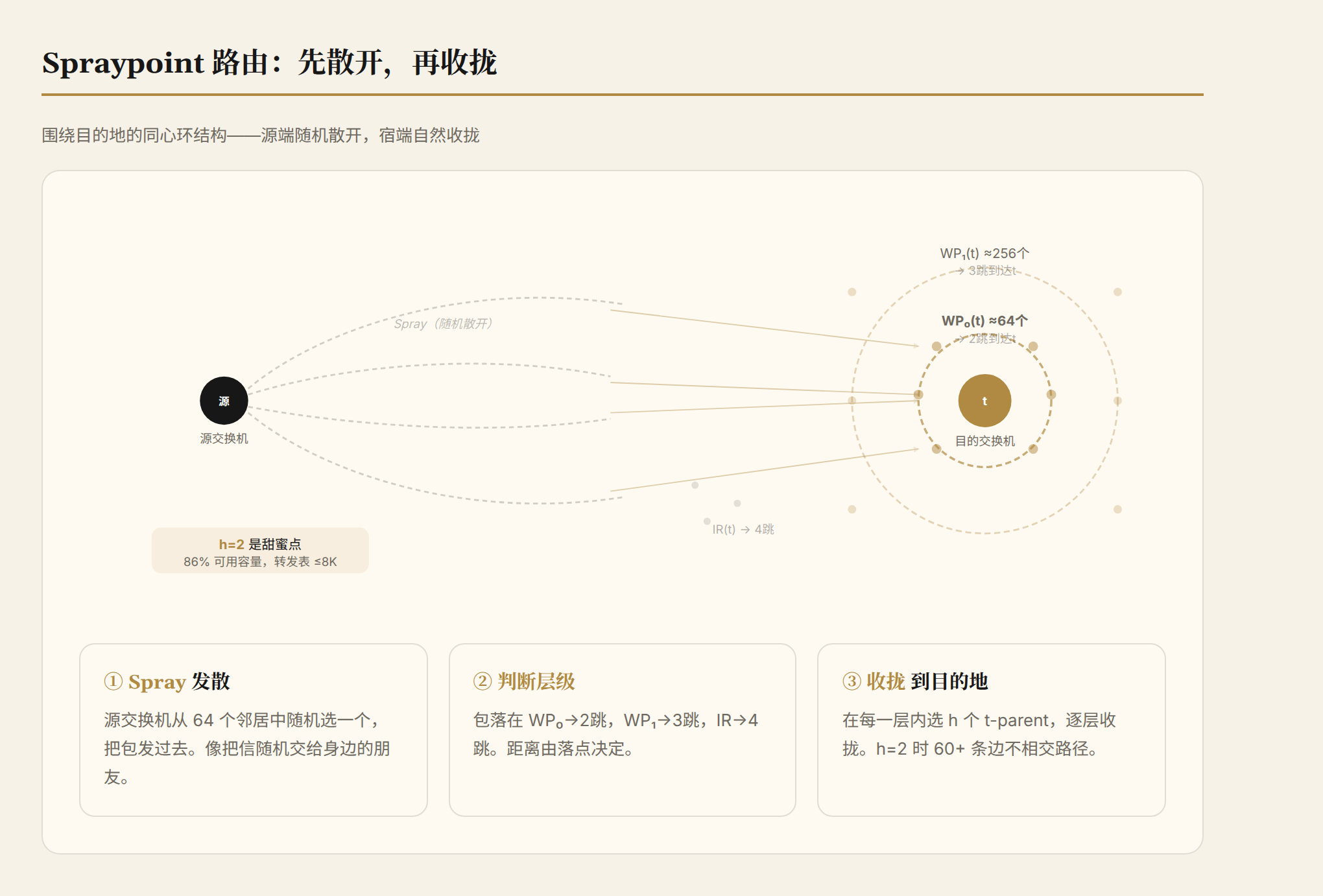
第二步,判断落在了哪一层。 围绕每个目的地 t,Spraypoint 预先计算了一个同心环结构:
- WP₀(t):t 的直连邻居(约 64 个)
- WP₁(t):每个 WP₀ 节点选 4 个邻居组成的集合(约 256 个)
- IR(t):连接到 waypoint 但不在上面层次里的节点(大多数)
- OR(t):不连接任何 waypoint 层次的节点(极少)
Spray 出去的包落在 WP₀(t)→2 跳到 t,落在 WP₁(t)→3 跳,落在 IR(t)→4 跳,落在 OR(t)→5 跳。
第三步,在每一层内部,参数 h 允许选择多个"t-parent"。 h=1 只选 1 个 t-parent,那条边坏了就没有备用。h=2 选 2 个,一条坏了还有另一条。h=3 选 3 个,但边际收益递减。
关键数字——为什么 h=2 是甜蜜点?
边不相交路径数 ≈ d·(1 - e^(-h))。
h=1:可用容量 63%。h=2:86%。h=3:95%。从 h=1 到 h=2 的跳变是 +23%,从 h=2 到 h=3 只有 +8.5%。指数衰减意味着 h=2 的性价比最高。
实际效果:n=1000, d=64, p=4, h=2 时,中位数找到 60+ 条边不相交路径。对比一下——8-shortest-paths 只有 5 条,64-shortest-paths 只有 35 条。Spraypoint 用商用交换机的标准硬件,跑出了比 64-shortest-paths 更好的路径多样性。
oversubscription 从 4.7:1(64-shortest-paths)降到了 3.25:1。
转发表需求:128 端口交换机、d=64、h=2 时,需要约 8K 条 ECMP 表项。商用交换机通常有 16K+。不需要特殊硬件。
ShuffleBox:把意面变成有序的管道网
路由问题解决了,布线问题怎么办?
意面问题
随机图要求每个交换机随机连 64 个其他交换机。这些"其他交换机"物理上散布在多个机房。如果真去拉线,你会得到一团光纤意面。增量扩容更恐怖——每加一个机架的交换机,要从全数据中心随机断开几十条已有线重新接。
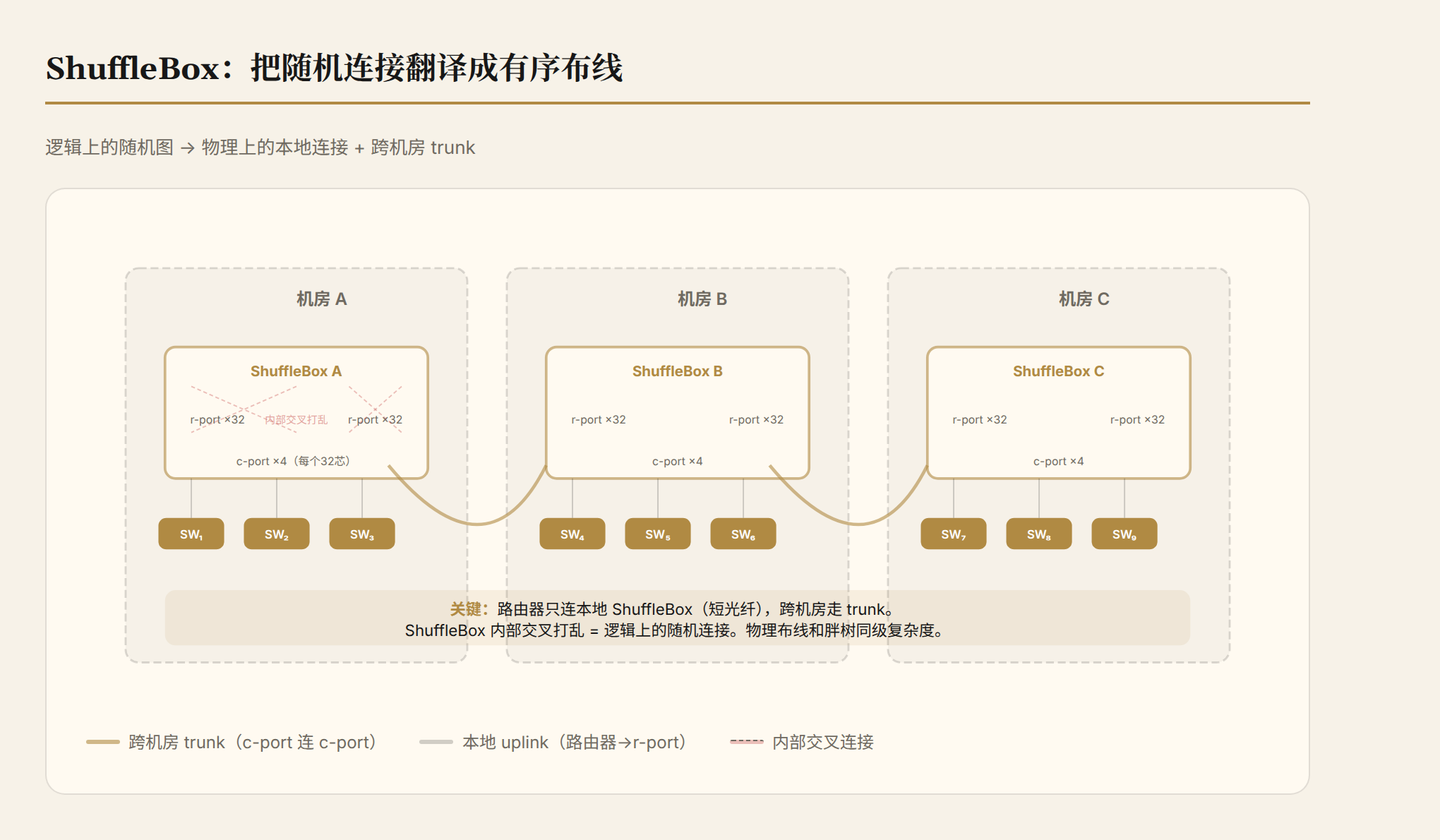
ShuffleBox 的设计
ShuffleBox 是一个无源光器件——不需要供电,不需要芯片,内部就是光纤的交叉连接。它做的事情很简单:把逻辑上的随机连接翻译成物理上的有序连接。
类比:ShuffleBox 就像地铁换乘站。你(路由器)只在本地站上车(插到本地 ShuffleBox)。换乘站内部的调度(内部交叉打乱)自然把你送到正确的远端。你不需要知道全局线路图。
结构上,每个 ShuffleBox 有两类端口:
- r-port(路由器端口):32 个,每个 4 根光纤。路由器的 uplink 插到这里。
- c-port(互联端口):4 个,每个 32 根光纤。连到其他机房的 ShuffleBox。
内部是完全二分图交叉:每个 c-port 的 32 根光纤分别来自 32 个不同的 r-port。每个 r-port 的 4 根光纤分别去往 4 个不同的 c-port。
如果没有这个内部打乱会怎样?32 个路由器的信号按顺序分配到 4 个 c-port,每个 c-port 固定服务 8 个路由器——这不是随机图,这是 4 个独立的子图。内部的交叉连接打破了这个限制,让每个路由器的信号被分散到 4 个不同的远端。
制造和成本:ShuffleBox 到底贵不贵
论文里有一句不起眼但重要的话:ShuffleBox 和 ShuffleBack 的成本"similar to traditional patch panels and loopbacks"——和传统 patch panel 以及光纤环回器差不多。
为什么能做到这么便宜?因为 ShuffleBox 内部没有有源器件。没有芯片,不需要供电,不需要散热。里面就是光纤的交叉连接,固定在一个外壳里。制造成本主要来自 MPO 连接器(多光纤推拉式连接器)和内部光纤布线。MPO 是成熟的标准品,32 芯 MPO 连接器在市场上大批量采购的价格在几十美元级别。
一个 ShuffleBox 服务 32 个路由器 uplink(dr=32, fr=4),用 4 个 32 芯 MPO 的 c-port。粗算:外壳 + 32 个 4 芯 MPO(r-port)+ 4 个 32 芯 MPO(c-port)+ 内部光纤阵列。整体成本在百美元量级。对比一个 128 端口交换机(数千到上万美元)和一个 400G 光模块(数百美元),ShuffleBox 的成本几乎可以忽略。
但有一个工程约束:fc=32 这个参数的选择不是随意的。论文明确说,更大的 fc 值意味着更少见的连接器规格(32 芯 MPO 已经接近市面上容易买到的上限),更小的 fc 值意味着更多的 c-port(因为 dr×fr=dc×fc),重平衡时需要操作的连接数更多。fc=32 是连接器可得性和运维复杂度之间的折中。
另一个工程细节:AWS 自己承认,首期生产部署时还没有量产的 ShuffleBox。他们用传统 patch panel 手动桥接单根光纤对来模拟内部打乱,加上定制的 ShuffleBack。这说明 ShuffleBox 的制造门槛并不高——传统 patch panel 就能临时替代,只是操作效率低。真正的 ShuffleBox 量产后,布线效率会更高。
物理布线
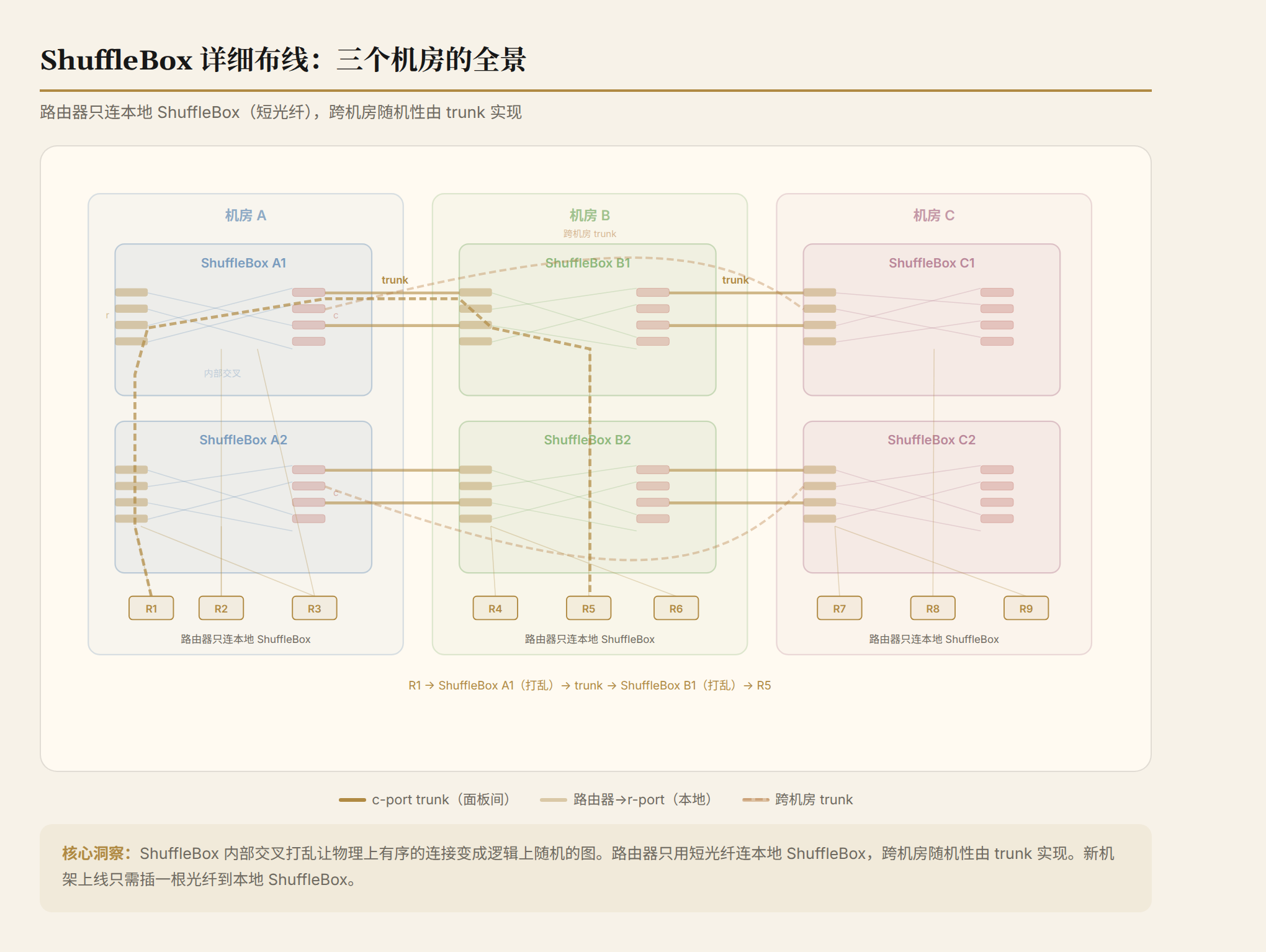
每个机房放一组 ShuffleBox(shuffle panel)。路由器 uplink 只插到本地 ShuffleBox 的 r-port,短光纤。面板之间用 trunk 光纤互联(c-port 连 c-port)。
论文把布线复杂度拆成三个维度做了对比:
| 维度 | 胖树 | RNG + ShuffleBox |
|---|---|---|
| 端点对数 | n(路由器)+ R² trunk | n(路由器到面板)+ R² trunk(同级) |
| 跨机房光纤量 | Agg↔Spine 三层 trunk | 只有一层面板间 trunk |
| 机架落地前的布线比例 | 大部分 trunk 可提前铺设 | 相同——面板间 trunk 在机房准备期铺设 |
| 机架落地时 | 只插本地线到 Agg | 只插本地线到 ShuffleBox |
这里 R 是机房数量(通常 O(10))。物理连接的端点对数是 n + R(R-1)/2,远小于逻辑连接的 n²。路由器只和本地 ShuffleBox 短光纤连接,跨机房的连接全部由面板之间的 trunk 处理。
但有一个布线管理上的新挑战:随机性使得物理连接没有可辨识的模式。胖树里,你看到一根线从 ToR 走到 Agg,你知道它是什么。RNG 里,一根从路由器到 ShuffleBox 的线只是"随机连到某个 r-port",物理位置不提供任何语义信息。论文报告的错误接线率 < 1.5%,但在大规模部署中,这个数字意味着每 1000 根线有约 15 根接错。胖树的错误接线率通常更低,因为层级结构提供了物理层面的校验。
AWS 的应对是:用足够多的 ShuffleBox 确保每个机房有余量。因为机房能放多少机架取决于服务器的功耗(高密度 GPU 机架和普通 CPU 机架占用的功率完全不同),实际路由器数量会波动。AWS 用了一个估算的上限来确定每个机房需要多少 ShuffleBox,如果超了就把多出来的机架归入一个新的"逻辑机房",触发一次重平衡。论文承认,胖树在大型数据中心也有类似的超额配置问题。
光衰:ShuffleBox 不是免费的午餐
ShuffleBox 内部的交叉连接有一个物理代价:光路损耗增加。
每一次光纤的物理连接(两个连接器对接)都会引入插入损耗。典型的 MPO 连接器插入损耗在 0.3-0.5dB。一个信号从路由器出发,经过 r-port 连接器进入 ShuffleBox,内部交叉后从 c-port 连接器出来,再经过一个 trunk 连接器到远端 ShuffleBox 的 c-port,内部交叉后从 r-port 连接器出来,最终到达目的路由器。
这条路径上有多少个连接器?最少 4 个(路由器→r-port→c-port→远端c-port→远端r-port→路由器),但实际上信号可能在 ShuffleBox 内部经过更长的路径。论文给出的硬限制是:路径上超过 7 个连接器时,禁用该路径。
为什么是 7?这取决于商用光模块(transceiver)的光功率预算。一个典型的 400G SR4 光模块的功率预算约为 3-5dB(取决于具体规格和光纤长度)。每个连接器损耗 0.3-0.5dB,7 个连接器就是 2.1-3.5dB,加上光纤本身的衰减(多模光纤约 1dB/km),留给信号的信噪比裕量已经很紧。
光衰的影响不是均匀的。 胖树里,ToR→Agg→Spine 的路径通常有 2-3 个连接器。RNG 里,同一机房内的路径也是 2-3 个,但跨机房的路径可能有 5-7 个。这意味着远距离节点对的有效带宽可能低于近距离节点对——虽然路由层面所有路径都"可用",但物理层的光信号质量在长路径上更差。
这是一个容易被忽略的工程约束:RNG 的"所有路径平等"是逻辑层面的。物理层面,路径质量有差异。好在 Spraypoint 的偏好近距离 waypoint 优化(后文会讲)恰好缓解了这个问题——不是巧合,而是论文作者在设计路由时就考虑了光衰的物理约束。
增量扩容:新机架简单,新机房要小心
新机架上线很简单:插一根光纤到本地 ShuffleBox 的空 r-port。不需要碰任何其他线。和胖树的新机架上线操作完全一样。
新机房上线就复杂了。具体步骤:
- 安装新面板
- 重平衡:从已有面板随机选一些 c-port,拔掉 ShuffleBack 或断开已有 trunk,用新 trunk 连到新面板
- 如果是第 R 个机房,每个已有面板需要把 c-port 连接从均匀分到 R-1 个面板变成均匀分到 R 个面板
- 每次断开 c-port 连接前,必须先 drain(排空)该链路上的流量——这意味着重平衡是一个有损操作,需要维护窗口
重平衡的"爆炸半径":c-port 有 32 根光纤(fc=32),断开一个 c-port 影响的是 32 条逻辑链路。论文说 r-port ShuffleBack 的移除影响只有 4 条(fr=4),"blast radius is much smaller"。这意味着重平衡操作的影响范围是可控的,但不是零。
实际发生的频率:数据中心通常有 O(10) 个机房。如果一次性建成,不存在重平衡。如果是分期建设,可能发生 3-5 次重平衡。每次重平衡的操作量是每个已有面板断开约 C·dc/R 个 c-port(C 是每面板 ShuffleBox 数,R 是总机房数)。对于 C=4, dc=4, R=5,每个面板需要断开约 3 个 c-port,操作量不大,但需要精确跟踪哪些 c-port 已连、哪些有 ShuffleBack。
早期匹配率:第 1 个机房刚启动时,很多光纤找不到配对(对端路由器还没上线)。部署到 1/4 时匹配率约 25%,满部署时 100%。第 2 个机房开后跳到 >90%,之后接近 100%。对慢增长数据中心,论文给出了分阶段布线的优化——把第 1 个机房的面板分成多个 phase,逐步开放,使得部署到 25% 时就能达到 80% 以上的有效度数。
ShuffleBack:空端口怎么办?
没用的 c-port 插 ShuffleBack——一个小连接器,把同一端口内的光纤两两桥接(FP1→FP2, FP3→FP4...),信号在本地折返。类比环岛:出口还没修好,车流在环岛内循环,仍然能到达同一个环岛的其他出口。这样即使网络未建满,拓扑仍然有效。
数学原理:为什么随机图"几乎必然"好
RNG 论文的数学基础是概率图论中的集中不等式,特别是 Chernoff bound。这里展开讲核心的一步,因为它解释了为什么随机图有"几乎不可能失败"的性质。
Claim:如果节点集合 S 有至少 nd/4 条未配对半边(光纤),则 S 连接到图外每一个节点的概率 ≥ 1 - n⁻⁴。
推导过程:S 的每条半边独立随机选一个全局半边配对。图外节点 v 有 d 条半边,单次配对连到 v 的概率 ≥ d/(nd) = 1/n。k 次尝试都没连到的概率 ≤ (1-1/n)^k ≤ e^(-k/n)。k ≥ nd/4 时,e^(-k/n) ≤ e^(-d/4)。d ≥ 4·ln n 时,e^(-d/4) ≤ n⁻⁴。对所有 n 个节点做 union bound:n × n⁻⁴ = n⁻³。
n=1000 时,"存在某个节点连不到 S"的概率 < 10⁻⁹。实际上不可能发生。
这个概率保证是整个 RNG 的数学基石——waypoint 层次的大小、路径长度的分布、边不相交路径数的估计、oversubscription 的解析模型,全部建立在这个"几乎必然"的基础上。
oversubscription 的解析模型基于六条原则(贪心短路径优先、平均情况分析、随机删除、可行路径、唯一位置、二项式拥塞),最终给出一个多项式公式。论文用 LP 求解 multi-commodity flow 做仿真对比,模型预测和实际值高度吻合。运维团队可以用公式直接从目标性能反推拓扑参数,和传统胖树的设计体验一致。
准随机图和真随机图等价的数学保证来自 Chung, Graham, Wilson 1989 年的结果:满足部分准随机属性的图,在所有准随机属性上都和真随机图一致——包括谱间隙(spectral gap,衡量扩展性的核心指标)。这意味着 RNG 的"部分确定 + 部分随机"的连接模式和真随机图功能上等价,但物理上可控。
一个反直觉的事实和两个简单解法
RNG 的跳数比胖树少(4 vs 6),但延迟反而可能更高。
原因:胖树的 Agg→Spine 连接通常在同一机房内(几米到几十米)。RNG 的随机连接可能跨越整个数据中心(几百米)。跳数少了 2 跳,但每跳的传播延迟更大。
300m 跨度的仿真:RNG 中位延迟 8.4μs,胖树 7.1μs,高了 15%。数据中心里微秒级的延迟差会在往返中累积,运维对此很敏感。
两个优化很简单,但有效:
偏好近距离 waypoint:选 waypoint 时优先选距离目的地近的候选。排序函数是机房级距离(不是精确光纤长度,避免系统性偏好靠近电缆桥架的节点)。延迟降 0.3μs。
减少跨机房连线:参数 α 控制跨机房连接比例,α=0.5 时跨机房连接减半。仍有足够跨机房容量保证吞吐量,延迟再降 1μs。额外好处:跨机房光缆减少 50%。
两者结合后,RNG 中位延迟与胖树持平。而且这两个优化不降低吞吐量。
实际部署:不是实验,是默认架构
RNG 的生产部署有两个独立的 fabric(server mesh + edge mesh)。2024 年底在都柏林附近首次部署,2026 年 4 月成为全球新建非 GPU 数据中心的默认架构。
量化指标:
| 指标 | 数值 |
|---|---|
| 路由器数量减少 | 69% |
| 吞吐量提升 | 最高 33% |
| 网络设备功耗降低 | ~40% |
| 基础设施成本降低 | 9-45%(取决于 oversubscription) |
成本节省和 oversubscription 比率强相关:3:1 oversubscription 时节省最多(约 45%),因为 capacity fungibility 的价值在这个区间最大。1:1 non-blocking 时只省约 9%,因为胖树本身不怎么浪费容量。这个结论和直觉吻合——oversubscription 越高,层级化分配的浪费越大,flat topology 的优势越明显。
应用性能测试(与同 oversubscription 胖树对比):127 条并发流量吞吐量分布完全一致,64B 小包 PPS 略高,存储读取 IOPS 匹配。零用户报告的性能问题。 延迟差异在应用层不可见——这对"随机图路径长度不一致"的担忧是有力的反驳。
运维侧的错误接线率 < 1.5%。ShuffleBox 尚未量产,首期部署用传统 patch panel 加定制 ShuffleBack 模拟。Spraypoint 的收敛时间和 Amazon 现有链路状态协议相当。
但运维侧的改造量远不止"换一种拓扑"这么简单。
维护的挑战:胖树给了直觉,flat 拓扑夺走了它
胖树的层级结构不只是拓扑设计,它也是运维的心智模型。AWS 论文里有一段话很直白:"The hierarchy of fat trees was embedded deeply into these tools, starting from device names itself to managing redundancy during maintenance."
翻译过来:胖树的层级结构写进了设备命名里。一个 ToR 叫"pod3-agg-rack12-tor1",你一看就知道它在哪个 Pod、连的是哪组 Agg。RNG 里没有 Pod,没有 Agg,设备命名体系需要重建。
更实质的影响是维护调度。胖树里,ToR 是叶子节点,互相不依赖。你要升级 10 个 ToR 的固件,可以同时做——每个 ToR 只影响自己机架的服务器。RNG 里不行。ToR 之间有 inter-dependency(它们通过 ShuffleBox 互连),同时升级太多邻居会导致某些区域的连通性下降。你需要计算"哪些 ToR 可以安全地同时升级"——这是一个图着色问题(graph coloring),邻居不能同时着色。对于度数 d=64 的图,你最多能同时升级的 ToR 数量远小于胖树。
故障排查也变了。胖树里,如果 Agg→Spine 链路出问题,你查那条链路就行。RNG 里,一条端到端路径经过多个随机中间节点,没有"自然的"故障定位层级。论文说 AWS "built new tools to easily determine the paths between ToRs for troubleshooting"——他们必须开发新工具来追踪任意两个 ToR 之间的实际路径,因为人工追踪几乎不可能。
新增的工具需求总结:
| 工具类型 | 胖树 | RNG |
|---|---|---|
| 设备命名 | 层级化(Pod-Agg-ToR) | 需要新体系 |
| 冗余管理 | 同层级交换机互为备份 | 邻居互为备份,需图算法确定升级组 |
| 维护调度 | 同层级可批量操作 | 图着色算法限制并行度 |
| 故障定位 | 沿层级排查 | 需要端到端路径追踪工具 |
| 拓扑可视化 | 树形结构直观 | 需要 expander 图的专门可视化 |
| 容量规划 | 按层级扩容 | 用解析模型按 oversubscription 目标设计 |
这些工具的开发量不小。AWS 没有透露具体投入,但论文暗示这是一个持续多年的工程——从 2023 年项目启动到 2026 年成为默认架构,中间有大量工具链的开发工作。对于想复制 RNG 方案的团队,工具链的开发成本不应该被低估。
RNG 的边界:每条新路线都有它走不通的地方
RNG 不是万能的。AWS 明确说了:GPU 训练集群仍然用胖树(UltraServer / Rail-optimized 变体)。
原因:大模型训练需要 locality 和 aggregation island——同一组 GPU 之间的 all-reduce 流量需要高带宽、低延迟的"岛屿"式连接。flat 拓扑没有岛屿,所有节点平等,反而不适合这种有强 locality 需求的场景。
另一个边界是网络规模。当前配置(ℓ=1 层 waypoint)对 n ≤ 10K 个路由器有效。更大的网络需要更多 waypoint 层,路径变长,模型复杂度上升。
光衰也限制了物理跨度——上文讨论过,路径超过 7 个连接器就被截断,跨机房节点对的路径选择比近距离节点更少。
新路线打开了什么可能性
读完论文和 AWS 的部署数据,我认为最重要的信号是:数据中心拓扑的设计空间变大了。 以前只有胖树一个可行选项,现在有了第二个。第二个选项的存在,会改变所有人审视第一个选项的方式——即使你最终仍然选择胖树,你的选择理由会不同。
哪些场景 RNG 有明显优势? 多租户、异构工作负载、流量模式不可预测的环境——通用计算、存储、推理集群。AWS 用实际部署证明了 9-45% 的成本节省和最高 33% 的吞吐提升。capacity fungibility 在这些场景下有真实的经济价值。
哪些场景胖树仍然更优? GPU 训练集群。需要 locality 和 aggregation island,流量模式可预测、高并发。flat 拓扑的"所有节点平等"在这里反而是劣势。AWS 自己的 GPU 集群仍然用 UltraServer / Rail-optimized 胖树。
最值得探索的灰区在哪里? 推理集群。推理的流量模式介于训练和多租户通用计算之间——请求的来源和目的地不可预测(像多租户),但同批次 token 的处理需要低延迟协作(像训练)。胖树和 flat topology 哪个更适合?目前没有答案。但这个问题以前根本不会被提出来,因为只有胖树一个选项。RNG 的存在让这个问题变得有意义了。推理集群的网络拓扑选择目前在国内几乎没有讨论——大部分参考设计仍然用同一套胖树架构覆盖训练和推理,或者根本没区分这两种场景的不同需求。
哪些场景暂时没有答案? 中等规模的企业数据中心、私有云、边缘数据中心——这些场景的规模和异构性可能不足以让 RNG 的优势覆盖工具链改造成本。结论取决于具体场景,需要更多人去验证。
ShuffleBox 和 Spraypoint 的具体实现 AWS 没有开源。 但论文给出了足够的设计原则和参数选择策略,可以作为参考设计的起点。对于想复制这套方案的团队,供应链上的额外环节是定制的无源光器件(ShuffleBox/ShuffleBack),以及商用交换机上 Spraypoint 的固件实现。
工程落地的几个硬约束:
一是 ShuffleBox 是定制器件,市场无标准品。但门槛不高——无源光器件,AWS 首期用传统 patch panel 就能模拟。真正需要定制的是内部的交叉连接模式和 ShuffleBack。对于国内的光通信产业链(中际旭创、光迅科技等),制造能力不是问题,关键是需求规模是否值得开产线。
二是胖树的运维工具链成熟度远高于 flat 拓扑。AWS 花了约三年完成工具链改造(2023-2026)。迁移成本不只是写代码,更是重建运维团队的心智模型——从"层级化排查"到"图论化排查",这是一个组织层面的转变。
三是光衰限制了物理跨度。路径超过 7 个连接器就被截断,这意味着两个跨机房节点之间的路径选择可能比近距离节点更少。Spraypoint 的偏好近距离 waypoint 优化缓解了这个问题,但没有完全消除。对于物理跨度特别大的数据中心(如跨楼宇、跨层),光衰可能成为比 oversubscription 更先碰到的约束。
四是 flat 拓扑的故障排查比胖树更复杂。没有层级结构意味着故障的"爆炸半径"虽然小了(丢 1% 节点 ≈ 丢 1% 容量),但定位故障需要新的端到端路径追踪工具,不能再靠"查 Spine 状态"这种直觉式排查。
国内大厂在做什么:各自的路线
AWS 的 RNG 是针对超大规模多租户数据中心的。国内大厂面对的问题不完全一样——规模不同、工作负载不同、产业链不同。但它们各自在数据中心网络上的探索,恰好从不同侧面验证了 RNG 论文的核心判断:胖树不是唯一答案,工作负载决定拓扑。
阿里:HPN 为训练定制拓扑,Stellar 为推理重建传输层
阿里是国产大厂里在数据中心网络论文产出上最激进的。
SIGCOMM 2024,阿里发了 HPN(High Performance Network)。核心设计思想是:简单物理拓扑 + 高效多路径和拥塞控制。HPN 采用多轨道(multi-track)物理拓扑——不是标准的三层胖树,而是把同轨 GPU 的流量限制在同一个平面内,跨轨流量走专门的 core 层。路径选择复杂度从胖树的 O(2304) 降到了 O(60)。单 Pod 支持 15360 个 GPU。
这个思路和 AWS RNG 的方向相反:RNG 靠随机性获取容量可复用性,HPN 靠精心设计的 locality 来获取路径可预测性。但目的相同——减少路径选择复杂度,提高负载均衡效率。
Apsara 2025,阿里发布了 HPN8.0,800G 吞吐量,翻倍于上一代。定位明确:服务于 AI 模型的训练、推理和强化学习。
SIGCOMM 2025,阿里要发 Stellar——自研的第三代高性能网络传输协议栈,专门为智能计算场景优化。Stellar 的重点不在拓扑,而在传输层:RDMA 协议的拥塞控制、多路径选择、和 AI 工作负载的联合优化。
阿里的策略清晰:训练用定制拓扑(HPN multi-track),传输层用自研协议(Stellar),两者解耦。这和 AWS 把拓扑和路由一起换的路径不同,但更务实——不需要重建整个运维工具链,只改传输层就能拿到一部分收益。
字节:重资本投入,拓扑上沉默
字节的资本开支在国产大厂中居首。2024 年约 800 亿元,2025 年预计 1500 亿元,其中约 1000 亿用于硬件采购,交换机等网络设备约占 11%(约 165 亿元)。
但在网络拓扑的公开研究上,字节几乎沉默。SIGCOMM 2025 有一篇来自字节的 ByteScale(16384 GPU 上的超长上下文训练),但重点是通信效率优化,不是拓扑创新。还有一篇 Jakiro,做的是 VPC 上同时支持 RDMA 和 TCP——传输层的工作。自研 DPU 的方向已有披露,但拓扑层面的公开讨论为零。
这个沉默有两种解释:一是字节目前的集群规模(万卡级)用胖树/Rail-optimized 还能撑住,拓扑还不是瓶颈;二是字节的网络团队在做什么但没发论文。无论哪种,RNG 的出现会促使字节重新评估——特别是当推理集群的规模增长到需要多租户复用网络资源的时候。
腾讯:走光的路,不碰拓扑
腾讯的 CPO(Co-Packaged Optics)交换机 Gemini 是国内在数据中心网络硬件上最大胆的投入。2022 年和博通合作开发,25.6T 交换容量,16 个 800G 光接口 + 32 个 QSFP112 可插拔接口。体积是传统交换机的一半,功耗降 26%,延迟降 20%。
但 Gemini 解决的是物理层的问题——光进铜退,提高端口密度和传输距离。拓扑仍然是胖树/Spine-Leaf。
腾讯的策略是:用 CPO 突破物理瓶颈(带宽、功耗、线缆管理),在拓扑上保持保守。这个策略在短期内是安全的——不需要重建运维工具链。但中长期来看,当物理层瓶颈被 CPO 解决后,拓扑层瓶颈会浮现。到那时,RNG 类的 flat topology 会成为下一个要回答的问题。
ZCube:学术界的另一种回答
SIGCOMM 2025 还有一篇值得注意的论文:ATOP→ZCube。作者来自清华大学,做的是自动化的拓扑优化——把网络拓扑参数化为一组超参数,用搜索算法在 256 到 16384 GPU 的规模上找最优拓扑。
结果发现了一种新的非对称拓扑 ZCube:网络直径低、训练性能好、容错性强、成本效益优于现有方案。
ZCube 本身是否会被采纳还不确定。但 ATOP 这个框架的价值在于:它把拓扑设计从"凭经验选胖树参数"变成了"可计算的优化问题"。这和 RNG 论文用解析模型设计拓扑的思路一致——都在用数学方法替代直觉。
华为、新华三和锐捷:设备商的各自突围
华为在智算中心网络上的产品路线是 CloudEngine 系列(800GE 核心交换机 16800-X)和星河 AI 网络。拓扑选择上主推胖树变体(包括 Rail-optimized),重点在端口速率提升和 RoCEv2 优化。
新华三在设备商里走得最远,路线也最全。它同时维持三条产品线:
一是标准 RoCE 方案,基于博通和盛科(Centec)交换芯片,走以太网无损网络路线。这是面向主流客户的成熟方案,兼容性最好,也是当前出货量最大的产品线。盛科是国产交换芯片里最接近高端的厂商,新华三和它的合作降低了芯片供应风险。
二是DDC(Distributed Disaggregated Chassis,分布式解耦机框)架构的新一代无损网络解决方案。核心交换机 S12500AI 系列引入信元交换机制和 VOQ(Virtual Output Queue)技术,宣称实现 100% 负载均衡和零拥塞传输。经 Tolly 验证,DDC 架构在有效带宽方面相比 ECMP 最高提升 107%。DDC 本质上是用信元交换替代传统 ECMP 哈希——和 AWS RNG 用 Spraypoint 替代最短路径是同一个思路的两种实现:都在解决胖树路径选择效率低的问题。但 DDC 仍然基于 Spine-Leaf 物理拓扑,没有改拓扑本身。小红书已经和新华三完成了国内首个基于 DDC 架构的智算网络规模化验证。
三是800G CPO 交换机 S9827 系列,已应用于头部互联网企业。还发布了单芯片 102.4T 的 800G AI 智算交换机 S9828-128EP(128 个 800G 端口)。在组网规模上,DDC 架构单集群支持 9216 个 400G 端口,多集群扩展到 73728 个。
锐捷网络在国产交换机市场里定位独特——它不是自研芯片,而是基于博通等商用芯片做系统集成和场景化方案。2025 年锐捷发布了 AI-Fabric 智算中心网络方案,也是 DDC 架构:NCP(Network Cloud Pod)+ NCF(Network Cloud Fabric)三级网络,支持 18K-32K GPU 卡集群。核心技术同样是信元交换 + VOQ + Credit 流控,和新华三的 DDC 方案类似。
锐捷的差异化在于去中心化的分布式 OS——控制面和管理面解耦,设备可以独立升级。这解决了传统 DDC 架构中 NCC(网络云控制器)单点故障和版本兼容性痛点。锐捷还成功为头部云厂商交付了基于 800G 网卡的双平面高可靠智算网络方案(1000 台 GPU 服务器、8000 张 800G 网卡),AllReduce 带宽稳定在 760GB/s 以上。
客户包括阿里巴巴、字节跳动、腾讯。
设备商的共同点和差异:华为在速率和生态上领先,新华三在 DDC/信元交换上走得最远(有实际客户验证),锐捷在性价比和运维简化上有优势。三家都没有触及拓扑层——都在胖树/Spine-Leaf 的框架内优化负载均衡和传输效率。RNG 类的 flat topology 目前只有一个部署案例(AWS),设备商不太可能在没有更多验证的情况下把它写入参考设计。但新华三的 DDC 架构已经展示了"在胖树框架内用信元交换替代 ECMP"这条路能走多远——如果这条路碰到天花板,flat topology 就是下一个台阶。
国内跟进的核心判断
把国内大厂的路线放在一起看,一个清晰的图景浮现出来:
| 大厂 | 重点投入 | 拓扑层变化 | 和 RNG 的关系 |
|---|---|---|---|
| 阿里 | HPN multi-track + Stellar | 是(训练定制拓扑) | 并行——为训练优化 locality,不是多租户容量复用 |
| 字节 | 资本投入 + DPU | 无公开动作 | 观望——规模撑得住胖树,但推理增长可能改变这个判断 |
| 腾讯 | CPO 光电合封 | 无 | 互补——解决物理层瓶颈,拓扑层待定 |
| 清华 ZCube | 拓扑自动化搜索 | 是(学术探索) | 同向——数学方法设计拓扑 |
| 华为 | 高速交换机 + RoCEv2 | 无 | 保守——等更多部署案例 |
| 新华三 | 标准 RoCE + DDC 信元交换 + 102.4T 800G | 负载均衡层(不改拓扑) | 部分同向——信元交换替代 ECMP,但在胖树框架内 |
| 锐捷 | AI-Fabric DDC + 800G 双平面 | 负载均衡层(不改拓扑) | 部分同向——同上,加上运维简化和性价比 |
没有人直接跟进 RNG 的 flat topology 路线。 但每个人都在用自己的方式回答同一个问题:胖树之后是什么?阿里选择了定制拓扑,腾讯选择了物理层突破,字节选择了暂不碰,学术圈选择了自动化搜索。
RNG 对国内的最大意义不是"照着抄",而是提供了一个已验证的参照点:在多租户、异构工作负载的场景下,flat topology 有明确的成本和性能优势。当国内大厂的推理集群规模增长到需要考虑 capacity fungibility 的时候,这个参照点会变得有用。

结论
胖树统治数据中心网络四十年,不是因为它最优,而是因为替代方案一直走不通——三个工程问题(路由、布线、性能预测)卡了十几年。RNG 把这三个问题同时解决了:Spraypoint 让路由跑在商用交换机上,ShuffleBox 让布线复杂度降到和胖树同级,解析性能模型让运维可以按公式设计拓扑。
AWS 用大规模生产部署验证了可行性。但它最大的价值不是替代胖树——而是让数据中心网络的设计空间从一维变成了二维。
以前你做网络设计,问题是"胖树的 oversubscription 选多少"。现在你有了一个新的问题可以问:"这个场景该不该用胖树?" 这个问题本身比它的答案更有价值。
值得探索的方向:推理集群的 flat topology 可行性(国内大厂目前无公开探索)、ShuffleBox 类器件在国内供应链中的落地路径(光通信产业链有制造能力,缺需求驱动)、下一代商用交换机对类似 Spraypoint 路由能力的支持(设备商观望中)、以及更多规模和场景下的实测数据。
国内大厂在网络上的投入已经很大(字节 2025 年网络设备预算约 165 亿元),但投入方向集中在训练侧的速率提升和协议优化,拓扑层面的探索刚刚开始。阿里 HPN 是目前最接近拓扑创新的国产方案,但走的是 locality 优化路线,和 RNG 的容量复用路线正好相反。这两条路线不是竞争关系——它们回答的是不同工作负载下的不同问题。
下一个观察节点:阿里是否会在通用计算和推理场景下尝试 flat topology;字节推理集群规模增长后是否会重新评估拓扑选择;新华三/锐捷的 DDC 架构在万卡以上规模是否会碰到负载均衡天花板、从而驱动向 flat topology 演进。
声明: 本文基于 AWS 公开发表的论文 arXiv:2604.15261v3 "RNG: Flat Datacenter Networks at Scale"(2026 年 4 月提交)及 Amazon Science Blog 公开信息(2026 年 5 月 28 日),结合 Tom's Hardware、Data Center Knowledge、SDxCentral 等多源报道进行交叉验证后撰写。国内大厂部分基于 SDxCentral、光纤在线、LinkedIn(Dennis Cai)、ACM SIGCOMM 2024/2025 论文录用列表、国金证券研究报告等公开信息。不构成投资建议。文中数据截至 2026 年 6 月 5 日。