Ⅰ. A Company with No Revenue, Sold for $4 Billion
In June 2026, Bloomberg reported that Qualcomm was in talks to acquire Modular at a valuation of roughly $4 billion. When the news broke, many financial outlets ran with the instinctive headline: "Qualcomm buys another AI chip company."
It was a misunderstanding. Modular does not make chips. It builds an AI compiler platform and a programming language called Mojo, with no disclosed revenue. Sina Finance later set the record straight: this was "a software company packaging itself as a chip asset."
The numbers tell an even more interesting story. Modular was founded in 2022, raised $380 million total, and was valued at $1.6 billion as recently as September 2025. Nine months later, Qualcomm offered $4 billion—a 2.5× premium. A software company with no revenue, worth $4 billion.
Answering why requires understanding exactly what Qualcomm is buying, and why this particular layer of the AI infrastructure stack is simultaneously the most strategic and the hardest to monetize on its own.
Ⅱ. Qualcomm Isn't Buying Revenue—It's Buying a Seat at a Second Table
The Modular deal can't be evaluated in isolation. Lay Qualcomm's acquisitions over the past two years and a clear picture emerges:
| Target | What It Fills | Value |
|---|---|---|
| Alphawave | "Connect" — high-speed chip interconnects | ~$2.4B |
| NUVIA | "Core" — ex-Apple CPU team | $1.4B |
| Ventana Micro | RISC-V datacenter CPU | undisclosed |
| Modular | "Software" — anti-CUDA compiler stack | ~$4B |
| Tenstorrent (in talks) | Team + next-gen architecture | $8-10B |
Qualcomm is assembling a complete, NVIDIA-independent datacenter proposal: its own CPU cores, its own interconnects, and its own compiler software stack. The hardest piece to fill—and the most expensive—is the software layer.
The reason is simple. An AI chip without a mature software stack is a brick. NVIDIA's dominance has never been about hardware alone; it's the CUDA ecosystem—a software environment that has taught a generation of algorithm engineers to write code that runs on NVIDIA hardware. For anyone hoping to sell non-NVIDIA silicon, the first barrier is not tape-out. It's software.
So Qualcomm's $4 billion isn't buying Modular's cash flow. It's buying "a seat at the second poker table." This is a strategic option, not a cash-flow asset. It's expensive, but for Qualcomm's strategic necessity, it's a tolerable premium.
Whether the deal is a good one depends not on what Modular earns today, but on how much the compiler layer position itself is worth—and whether that value can ultimately land in an independent company's pocket.
Ⅲ. Who Is Modular: The Man Who Built Two Generations of Compiler Foundations
Modular's core asset is founder Chris Lattner. His scarcity in the software industry is hard to overstate.
His career traces a single line through compiler infrastructure: as a PhD student he built LLVM (today the common substrate of C++, Rust, and Swift), earning the 2012 ACM Software System Award. At Apple he created Clang and Swift. At Google he led the TensorFlow infrastructure team, producing XLA (a just-in-time compiler for accelerated linear algebra) and MLIR (a modular framework for building compilers that now underpins XLA, IREE, Torch-MLIR, and more).
In other words, Lattner has built two generations of compiler foundation: LLVM and MLIR. Nearly every significant project in AI compilation today hits these two stones when you dig deep enough. Very few people in the past two decades have built two generations of compiler infrastructure; he is one of them.
Modular has two product lines:
- Mojo: A Python-superset language promising C-level performance. It made early headlines with "35,000× faster than Python" benchmarks and open-sourced its standard library core in 2024. But the company's commercial center of gravity has clearly shifted to MAX. Mojo is a strategic technology positioning, not a revenue product.
- MAX: A cross-hardware inference engine that lets the same model deploy on NVIDIA, AMD, and various NPUs without rewriting. This is where the business model actually lives.
Lattner's Modular published the "Democratizing AI Compute" series (at least nine parts) on Modular's blog, systematically dissecting why CUDA succeeded, where alternatives failed, and how the lock-in could be broken. The ambition is out in the open.
Understanding Lattner's pedigree clarifies why this is a "talent + technology" acquisition, not a product acquisition. Qualcomm is buying one of the few teams globally that could build an anti-CUDA software stack from scratch, plus a multi-year head start.
Ⅳ. Why the Compiler Layer Is "the Throat"
To evaluate everything that follows, you need to see exactly where the compiler layer sits in the AI technology stack.
Above it: frontend frameworks (PyTorch, TensorFlow). Below it: hardware (GPUs, NPUs, accelerators of every kind). Its job is to translate high-level compute graphs into machine instructions that run fast on a specific chip.
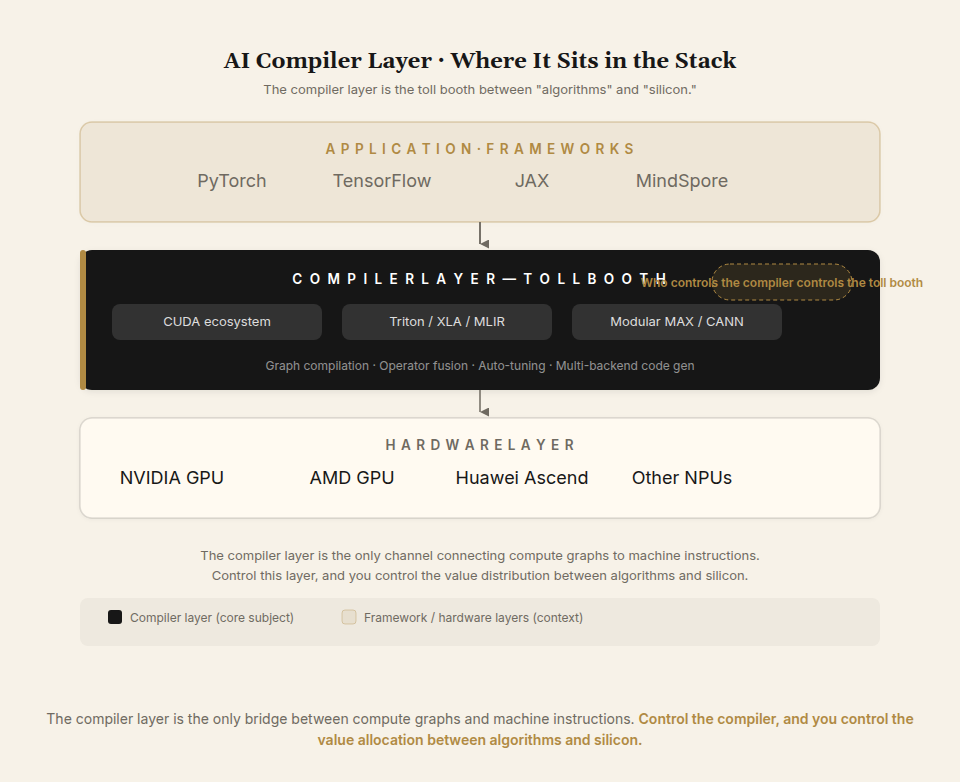
The key: the same piece of silicon can perform anywhere from 30% to 90% effective utilization depending on how good the compiler is. A $40,000 GPU running at 30% versus 90% is real money.
Whoever controls the compiler layer sits between "algorithms" and "silicon." That's exactly where CUDA lives: it's the single, habituated channel between NVIDIA hardware and the world's AI code. Control the channel, and you collect the toll.
This layer is hard because it forces several fundamentally contradictory goals onto a single system. The six technical bottlenecks below are all genuine problems—and each one ultimately circles back to the same question: who gets the money.
Ⅴ. Six Technical Bottlenecks
Bottleneck 1: Performance Portability—The Deepest Curse of This Layer
This is the meta-problem of the entire domain. Every cross-hardware compiler promises "write once, run anywhere with high performance." The dirty secret of the industry: correctness portability was solved long ago. Performance portability is essentially unsolved.
The reason lies in the unabstractability of hardware microarchitecture. To extract peak performance, you must exploit specific chip details: memory hierarchy (register file size, SRAM capacity, L2 behavior), the M×N×K dimensions of matrix multiply-accumulate instructions (NVIDIA Ampere's mma.m16n8k16 / Hopper's wgmma, AMD CDNA's matrix core, Ascend Cube's 16×16×16 mode), and each chip's ratio of compute to bandwidth. These differ for every piece of silicon.
The contradiction is structural: higher abstraction means better portability but worse peak performance (30-70% losses); closer-to-metal means better performance but worse portability.
Where CUDA truly won is precisely not portability. On the contrary, it lets you go all the way down to bare metal when you need to, while NVIDIA feeds you hand-tuned libraries (cuBLAS, cuDNN, CUTLASS) so most people never have to. Modular's MAX claims to have cracked this curse, but the evidence is thin. This is the single biggest question mark behind the $4 billion valuation.
Bottleneck 2: Long-Tail Operators—A Function of Time and Ecosystem
Modern models are long past matmul-plus-attention. The operator surface area explodes with every new architecture: Mamba-style state-space models, MoE routing, FlashAttention variants, DeepSeek's MLA—each introduces a crop of new fused kernels.
Half of CUDA's moat is the thousands of optimized kernels that NVIDIA and the community have written over eighteen years. A new chip and a new compiler start at zero. AMD's ROCm "works" but underperforms precisely because the kernel library is thinner.
This bottleneck has a nasty property: kernel library depth is an integral of time × ecosystem. You cannot catch up in a single technical breakthrough—at least not until AI learns to write kernels itself. That thread comes back later.
Bottleneck 3: Auto-Tuning's Combinatorial Explosion Meets Dynamic Shapes
Even on a single chip, finding the optimal execution schedule (tile sizes, loop order, vectorization, memory layout, pipeline depth) is a massive search space. TVM's Ansor, Triton's autotuner—they all fight combinatorial explosion. Searching one operator for one shape can take hours.
Worse, LLM inference is highly dynamic: batch size varies, sequence length varies, KV cache grows continuously. Static compilation assumes fixed shapes; runtime flexibility must be traded for performance. As a result, the optimization center of gravity has shifted from pure compilation to runtime scheduling and serving layers. vLLM heavily uses Triton-compiled fused attention kernels—it's a "runtime scheduling + compiled kernel" hybrid, not a binary choice. Pure compilation alone cannot perfectly handle dynamic shapes.
Bottleneck 4: PyTorch's Frontend Lock-In
PyTorch won the framework war; roughly 90% of research runs on it. PyTorch 2.0 chose TorchInductor + Triton as its default compilation backend.
The consequence is profound: Triton has effectively become the "second intermediate language" of the AI world after CUDA. Any hardware vendor wanting PyTorch users must make Triton run on their chip. Since mid-2024, Triton's governance has been transitioning to the multi-stakeholder PyTorch Foundation framework, but OpenAI, as the original designer and largest contributor, retains deep technical influence.
For new entrants, this is an admission tax: you must plug into PyTorch, and the default path is already occupied by Triton. Either ride Triton (accepting its abstraction ceiling) or build your own torch.compile backend (enormous engineering with a maintenance treadmill that never stops).
Bottleneck 5: MLIR's "Unfinished" Problem
MLIR is a brilliant design from Lattner, but it's a framework for building compilers, not a compiler itself. It distributes the hardest work—writing dialects, lowering passes, translations—to every adopter. The result is a large number of MLIR-based projects but no dominant, MLIR-built, cross-hardware, "ready-to-use" compiler. Even Lattner's own Modular must build for years on top of MLIR.
Bottleneck 6: The Hidden Tax of Numerical Correctness
Fusion and reordering change floating-point results (addition is not associative). In training, this can affect convergence; in inference, it can change outputs. Verifying that an optimized kernel is numerically equivalent to the reference (within tolerances) is hard and often manual. It's a hidden cost on every optimization, and everyone pays it.
Ⅵ. Value Creation ≠ Value Capture
Flipping the six bottlenecks over reveals where the money actually goes. This is the key to understanding the whole domain.
The value the compiler layer creates is enormous—it's the difference between 30% and 90% utilization of the same hardware. But the value created does not, for the most part, belong to the compiler layer itself.
Who captures it?
| Entity | How | How Much |
|---|---|---|
| Hardware vendors (NVIDIA, Huawei) | CUDA/CANN are free, but they protect 75%+ hardware gross margins | The vast majority |
| Cloud providers (Google, neoclouds) | Better compilation → higher utilization → higher cloud rental margin | Some |
| OpenAI (Triton) | Strategic leverage of a neutral middle IR, not direct revenue | Strategic power |
| Independent compiler companies | Toll collection impossible | Negligible |
Why can't independent compiler companies collect the toll? They are squeezed between two giants, with neither side willing to cede margin.
Upward: the framework layer is free (PyTorch is a public good subsidized by Meta). Downward: hardware vendors will always build their own software stack—this software is the keystone of hardware margin and can never be safely outsourced. End users treat compilation as "infrastructure that should be free" (nobody pays for GCC).
There are counterexamples: Anaconda, JetBrains, and MathWorks (MATLAB's compiler stack) prove that compiler-adjacent software can be independently commercialized. But their common thread is binding to a specific runtime ecosystem or development workflow—not standalone, cross-hardware, pure compilation. That path has not yet been validated.
Three acquisition cases nail this reality:
| Company | Exit | Acquirer |
|---|---|---|
| OctoAI (TVM team) | 2024.10, ~$250M | NVIDIA |
| CentML | 2025.7, ~$400M | NVIDIA |
| Modular | In talks, ~$4B | Qualcomm |
The pattern is clear: compiler-layer companies end up acquired by hardware vendors who use them to protect hardware margin, or by model companies who need the infrastructure. They create value but trap it.
Think of the compiler layer as an exceptional bridge builder standing by a river. Both banks are owned by giants. They either hire you or build their own bridge. The better your bridge, the more they want to buy you—not pay you a toll. A position's value is not the same as an independent company's value. Qualcomm's bet isn't that the compiler can stand alone as a business, but that it adds compounding value when bound to hardware.
Ⅶ. The Sweet Spot Is in the Middle; the Moat Is in the Last Stretch
The economic value of compiler improvement is not linear. It follows a diminishing marginal return curve.
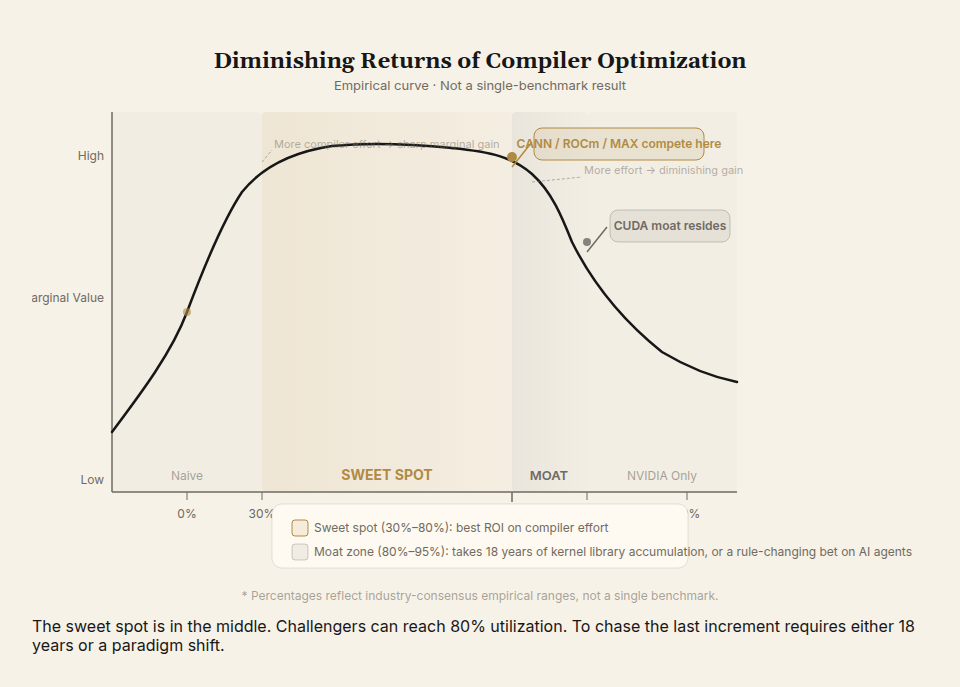
- From 10% to 50% utilization: enormous value. The same hardware produces several times more effective compute.
- From 50% to 80%: significant value.
- From 80% to 95%: diminishing. Requires hand tuning. Worth doing only at hyperscale.
- From 95% to 99%: only hyperscalers and NVIDIA bother.
The sweet spot is in the middle—taking a new chip from "barely works" (naive compilation at 10-30% utilization) to "competitive" (60-80%). Modular's MAX, Huawei's CANN, AMD's ROCm—all compete in this segment. Note: these utilization ranges are empirical, based on industry consensus, not a single benchmark.
The final 15-20% is where the moat actually lives. CUDA's eighteen-year accumulation of hand-tuned kernels still crushes everything here. This explains a counterintuitive pattern: challengers can reach 80% reasonably quickly, but chasing the last stretch takes either another eighteen years or a rule-changing bet.
Ⅷ. The Domestic Landscape: China's Two Paths
China's situation adds a dimension beyond margin economics. Under export controls, running AI on domestic chips is a survival question, not just an economic one. The country has roughly split into two approaches.
Huawei's CANN pursues full-stack self-reliance: CANN as the CUDA counterpart, MindSpore as the PyTorch counterpart, Ascend C as the CUDA kernel counterpart. On August 5, 2025, Huawei rotating chairman Xu Zhijun announced at the Ascend Summit that CANN would go fully open source (covering operator libraries, graph engine, and Mind-series toolchains), with a target completion date of December 30. This is a smart move—using openness to counter NVIDIA's closed ecosystem, competing for developer mindshare. A hardware manufacturer voluntarily opening its core software stack is an implicit acknowledgment that ecosystems cannot be built behind closed doors.
The remaining domestic chip vendors split into two camps. The CUDA-compatible camp (Hygon, Muxi, Moore Threads, Biren) benefits from existing ecosystem compatibility at the cost of performance loss and perpetual trailing. The non-compatible camp (Enflame, Cambricon) bets on differentiation at the cost of building an ecosystem from scratch.
The project worth watching most closely is the Beijing Academy of Artificial Intelligence's (BAAI) FlagOS. Built on the Triton route, FlagOS has produced FlagTree—a unified multi-chip compiler that already supports twelve domestic chip vendors. Its vision is to unify the downstream chip ecosystem under a single open standard, which is the only winning strategy for a latecomer. Rather than having twelve chip vendors each chase NVIDIA's closed standard, one open standard could aggregate them.
Viewed together, CANN's open-sourcing and FlagOS suggest China's optimal path is emerging: not case-by-case CUDA compatibility, but an open standard confronting a closed one.
Ⅸ. Two Variables That Could Reshuffle Everything
The preceding analysis rests on two premises: "kernel library depth cannot be closed quickly" and "the compiler layer cannot make money independently." Two variables could upend both.
Variable 1: AI Agents Writing Their Own Kernels
This is the most important second-order dynamic in the entire space. If LLMs can automatically generate, auto-tune, and auto-verify kernels:
CUDA's eighteen-year kernel library advantage would compress dramatically. The "performance portability" bottleneck would be attacked from a new angle: instead of one portable kernel for all hardware, generate one specialized kernel per hardware configuration, on the fly. Human compiler experts devalue; auto-tuning and auto-verification frameworks appreciate.
In January 2026, a developer known as johnnytshi used Claude Code to port a complete CUDA backend (for the chess AI project Leela Chess Zero) to AMD's ROCm in thirty minutes. The ported code achieved usable performance (Strix Halo, FP16 >2000 nodes/s). AMD's software VP Anush Elangovan responded publicly: "The future of GPU programming belongs to AI agents." Multiple Chinese and English media outlets covered the event. BAAI's KernelGen and FlagOS projects in China are pursuing the same direction.
The key nuance: CUDA's moat is not just kernel code volume. It includes toolchains, debuggers, profilers, hundreds of third-party library dependencies, and the muscle memory of over 4 million developers. AI-generated kernels primarily compress the "kernel library depth" dimension; other moat dimensions don't disappear overnight. But if this variable develops as projected, Qualcomm's $4 billion bet on "cross-hardware without rewriting" is at least being undermined from the kernel layer upward.
Variable 2: Value Shifts from Training Compilation to Inference Economics
Inference demand is already 10-15× that of training. China's daily token consumption has surpassed 140 trillion (disclosed by National Data Administration director Liu Liehong at a State Council Information Office press conference in March 2026). Dongwu Securities concurrently reported that the compute demand center has shifted "from training-dominant to inference-dominant," with inference data volume exceeding training for the first time in 2025. The compiler layer's value is moving from "training-time optimization" to "inference-cost optimization." Whoever compiles inference to the lowest per-token cost wins the inference economics game.
This is the underlying logic of Broadcom's ASIC thesis and the direction real capital is flowing. It implies that the future winner in the compiler layer may not be the most general-purpose solution, but the one most tightly bound to a specific inference chip, compressing inference cost to the absolute limit.
Ⅹ. Five Judgments
Integrating the technical bottlenecks and the value-capture picture yields five judgments.
First, the root technical problem is the structural unsolvability of performance portability. Every cross-hardware compiler is trying to circumvent this curse in a different way; nobody has truly broken it. Modular claims it has—that's the biggest question mark on its $4 billion valuation.
Second, the hardest technical problem is also the least monetizable position. The compiler layer is sandwiched between free frameworks and hardware-own software stacks. It creates enormous value but captures almost none. Three acquisition cases have proven it cannot stand alone as a large independent business.
Third, the sweet spot is in the middle; the moat is in the last stretch. Challengers can reach 80% utilization with reasonable effort. Chasing the final increment takes either eighteen years, a bet on AI agents rewriting the rules, or a new computing paradigm (photonics, analog computing, near-memory computing) that renders the entire software stack obsolete.
Fourth, the only compiler layer that can sustainably capture value is the one bound to hardware. Value is captured through the hardware; the compiler is only the toll booth, and the hardware owns the road. CUDA, CANN, and XLA all follow this model. Independent neutral stacks—Modular, TVM, Triton—end up acquired.
Fifth, this wave of M&A is, at bottom, hardware vendors using cash to buy the "de-NVIDIA-ification" software option. They aren't buying revenue. They're buying the right to sit at the second table. And AI agents that auto-generate kernels could make this expensive option depreciate significantly within three to five years—that is the real risk exposure of Qualcomm's bet.
The toll booth sits at the throat. The position is critically important. But the owner of the toll booth has never been the one who built it. -e
Data cutoff: June 23, 2026. This is a technical analysis, not investment advice. Some data sourced from China's National Data Administration, Dongwu Securities research reports, and public market reporting.