33 Years, Distilled into One Chip
June 1, 2026. Taipei Music Center, next to the Nangang Exhibition Hall. Jensen Huang stands on stage. Behind him, a cross-section diagram of a single chip.
"Everything we've learned over 33 years, distilled into one chip."
That chip is the RTX Spark. It's not just another GPU—it's NVIDIA's first complete SoC designed for Windows laptops: a 20-core ARM CPU (co-designed with MediaTek) + a 6,144-core Blackwell RTX GPU + up to 128GB of unified memory + 1 PetaFLOP of FP4 AI compute.
But RTX Spark is only the consumer story from this keynote. Over two hours, Huang also announced: full-volume production of the Vera Rubin data center platform, the DSX open-source AI factory framework, an 88-core Vera CPU, the 550B-parameter open-source model Nemotron 3 Ultra, and the open physical AI model Cosmos 3…
String all the announcements together, and a clear narrative emerges: NVIDIA is no longer just a GPU company. It is building full-stack AI infrastructure spanning data centers, PCs, and robots.
This article tries to answer three questions: What does RTX Spark actually mean? Why are Vera Rubin and DSX more than just "the next-gen GPU"? And what do these launches mean for the competitive landscape?
RTX Spark: More Than an ARM Laptop Chip
Official Specifications
NVIDIA released an official press release after the keynote. The specs:
| Parameter | RTX Spark (Full) | N1 Standard |
|---|---|---|
| GPU | Blackwell RTX, 6,144 CUDA Cores + 5th-gen Tensor Cores | 2,048–2,560 CUDA Cores |
| CPU | 20-core NVIDIA Grace CPU (co-designed with MediaTek) | 10–12 cores (7+3 / 8+4) |
| Interconnect | NVLink-C2C chip-to-chip | NVLink-C2C |
| Memory | Up to 128GB unified memory | Up to 64GB LPDDR5X |
| Memory Bandwidth | 600 GB/s | — |
| AI Performance | 1 PFLOP FP4 | — |
| TDP | 45–80W | 18–45W |

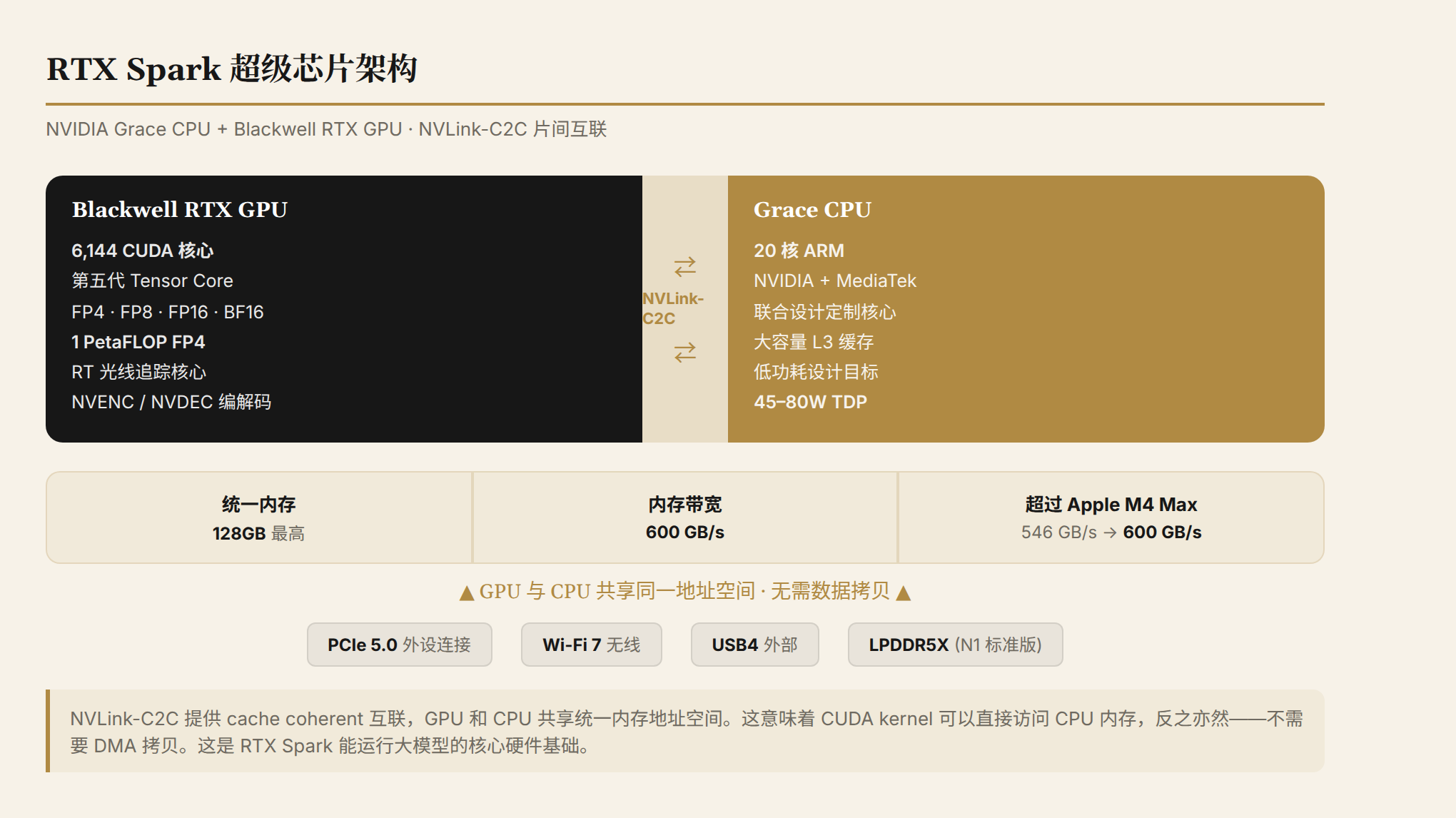
A few numbers deserve attention:
600 GB/s memory bandwidth. Earlier leaks put this at 273 GB/s—the actual figure is more than double. For reference, Apple's M4 Max delivers 546 GB/s of unified memory bandwidth. RTX Spark already exceeds it. For AI inference, memory bandwidth is the bottleneck—model parameters have to be moved to the compute units before any calculation happens, and bandwidth directly determines inference speed.
128GB unified memory. This means a 14mm-thin, 3-pound laptop can run a 120B-parameter model locally (roughly 240GB in FP16, but after FP4/INT4 quantization it fits within 128GB). The CUDA ecosystem, TensorRT, and NVIDIA's entire AI software stack are now coming to Windows laptops. This isn't the first attempt at an ARM PC—but it's the first time the CUDA ecosystem has arrived fully intact on a Windows laptop.
1 PFLOP FP4. A single laptop hitting 1 PetaFLOP of AI compute. Two years ago, that required a desktop workstation.
Seven OEMs on Stage Together
The keynote featured an unusual lineup: seven PC manufacturers standing on stage together, confirming day-one launches:
| Company | Confirmed Product | Speaker |
|---|---|---|
| Dell | XPS 16 Creator Edition | Michael Dell |
| HP | OmniBook ("one of the thinnest RTX Spark laptops") | Bruce Broussard (interim CEO) |
| Lenovo | Specific model not announced | Yuanqing Yang (CEO) |
| Microsoft | Surface Laptop Ultra | Brett Ostrum |
| ASUS | Specific model not announced | Jonney Shih (Chairman) |
| MSI | Specific model not announced | Jeans Huang (CEO) |
| Acer / GIGABYTE | Launching after the first wave | — |
Microsoft's participation is particularly noteworthy. The Surface Laptop Ultra means Microsoft isn't just providing Windows on ARM system support—it's getting into the hardware itself. The logic mirrors how the original Surface Pro pushed touch-screen laptops into the mainstream.

Not "Yet Another ARM Laptop Chip"
Over the past decade, ARM laptops have had several less-than-successful attempts: Qualcomm's Windows on ARM, Samsung's Exynos laptops, Apple's M-series (successful, but closed).
What makes RTX Spark different is that it's not trying to "replace x86"—it's creating a new category that x86 fundamentally can't cover: the AI-native PC.

Huang's positioning on stage was clear:
"For forty years, you launched apps. Click. Type. With RTX Spark and Microsoft Windows, you ask — and the PC does the work."
In technical terms: the traditional PC interaction model is "human drives software." RTX Spark aims to enable "agent drives workflow." The combination of 128GB unified memory + CUDA + local AI inference capability transforms the PC from "a terminal that runs applications" into "a node that runs agents."
Whether this positioning holds up depends on two things:
First, game and creative software compatibility on ARM. NVIDIA announced at the keynote that XBOX, NetEase, and Remedy have signed on to support RTX Spark's gaming ecosystem. The specific compatibility approach (native ports vs. translation layers) wasn't disclosed. This is the biggest risk point—if AAA games can't run smoothly, RTX Spark gets relegated to "an AI developer's specialty machine" and fails to reach the mainstream.
Second, pricing. NVIDIA didn't announce chip pricing. The BOM cost of a Blackwell GPU + 128GB unified memory won't be low. If OEMs price RTX Spark laptops at $2,000+, they'll be out of reach for most consumers.
Vera Rubin Full Production: The AI Factory's "Second Engine"
If RTX Spark is the consumer story, Vera Rubin is the industrial foundation of this keynote.
Supply Chain Scale Doubled
Huang announced that Vera Rubin has entered full-volume production, with supply chain scale at twice that of Grace Blackwell. This spans 350+ factories, 30 countries, and 150 Taiwanese partners.
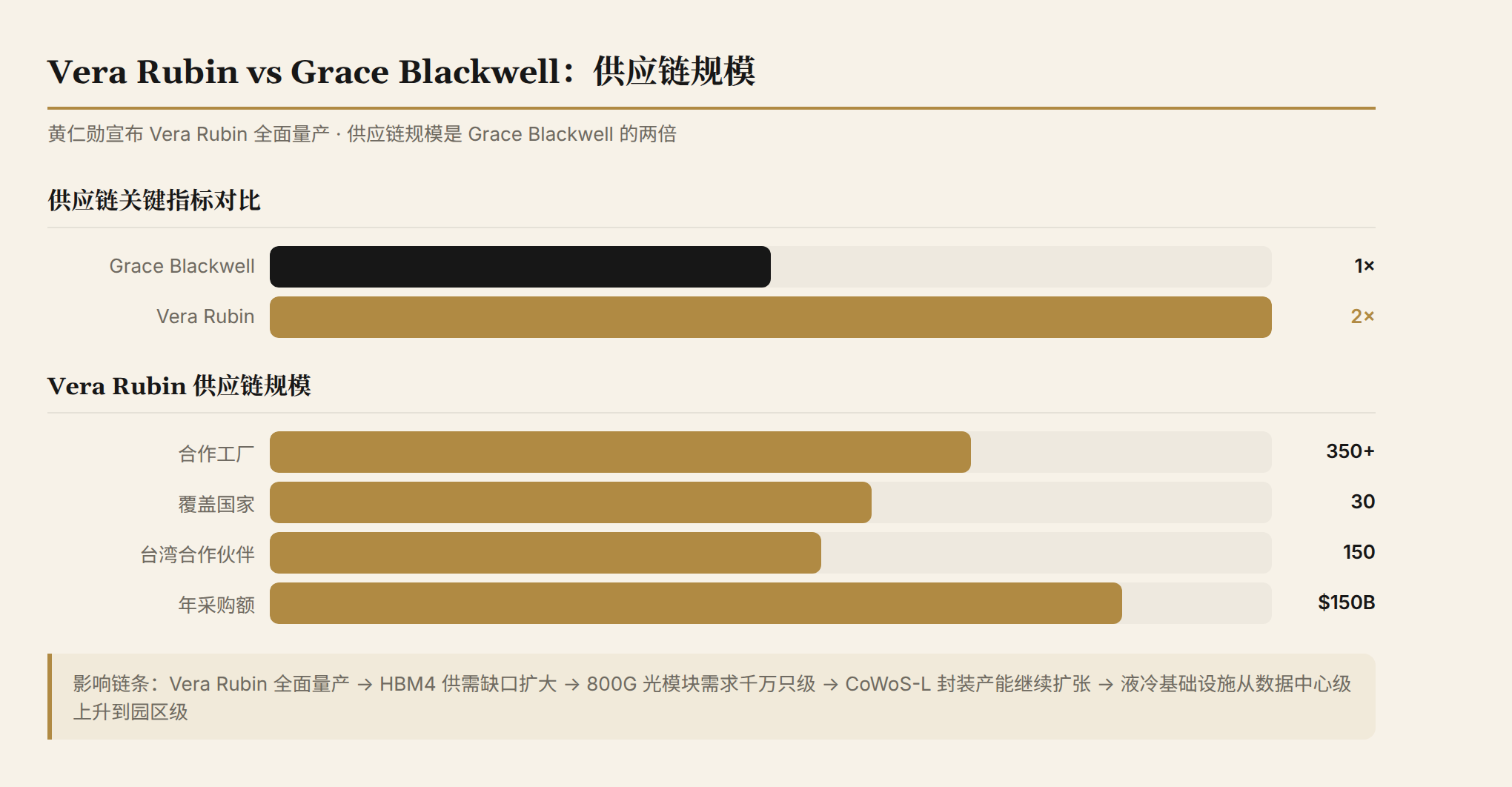
The "twice" figure needs careful interpretation. It doesn't just mean chip shipments have doubled—it means the entire supply chain's capacity, component variety, and partner count have all doubled. Grace Blackwell was already one of the largest-scale chip production programs in semiconductor history. Vera Rubin doubling that on top means:
- HBM4 demand will once again exceed supply capacity (HBM3E is already in short supply)
- 800G optical module procurement will scale from the millions to the tens of millions
- TSMC's CoWoS-L packaging capacity needs to continue expanding
- Liquid cooling infrastructure demand scales from the data center level to the campus level
Vera CPU: A Processor Designed for Agents
The keynote included a dedicated spec reveal for the Vera CPU:
| Parameter | Vera CPU |
|---|---|
| Cores | 88 |
| Memory Bandwidth | 1.2 TB/s LPDDR5X |
| On-chip Interconnect | 3.6 TB/s, no chiplet boundaries |
| Instructions per Clock | 10 |
Huang's exact words:
"We created CPUs for humans in the past... There will be billions of agents, and these agents are going to be using the CPUs with very little patience."
This is an interesting positioning: Vera isn't trying to compete with AMD EPYC or Intel Xeon in the general-purpose server CPU market. It's specifically designed for AI agent workloads—high memory bandwidth (1.2 TB/s), low-latency on-chip interconnect (3.6 TB/s, monolithic with no chiplets), and high IPC. These traits aren't top design priorities for traditional server CPUs, but they're critical for agent-dense inference and orchestration workloads.
Five-Rack Unified Platform
Vera Rubin's deployment form factor is a five-rack platform:
| Component | Function |
|---|---|
| Vera Rubin NVL72 | GPU compute (72 GPUs per rack) |
| Vera CPU | Agent orchestration and inference |
| Groq 3 LPX | Inference acceleration |
| Spectrum-6 SPX Ethernet | Networking |
| BlueField-4 STX | Security and multi-tenancy |
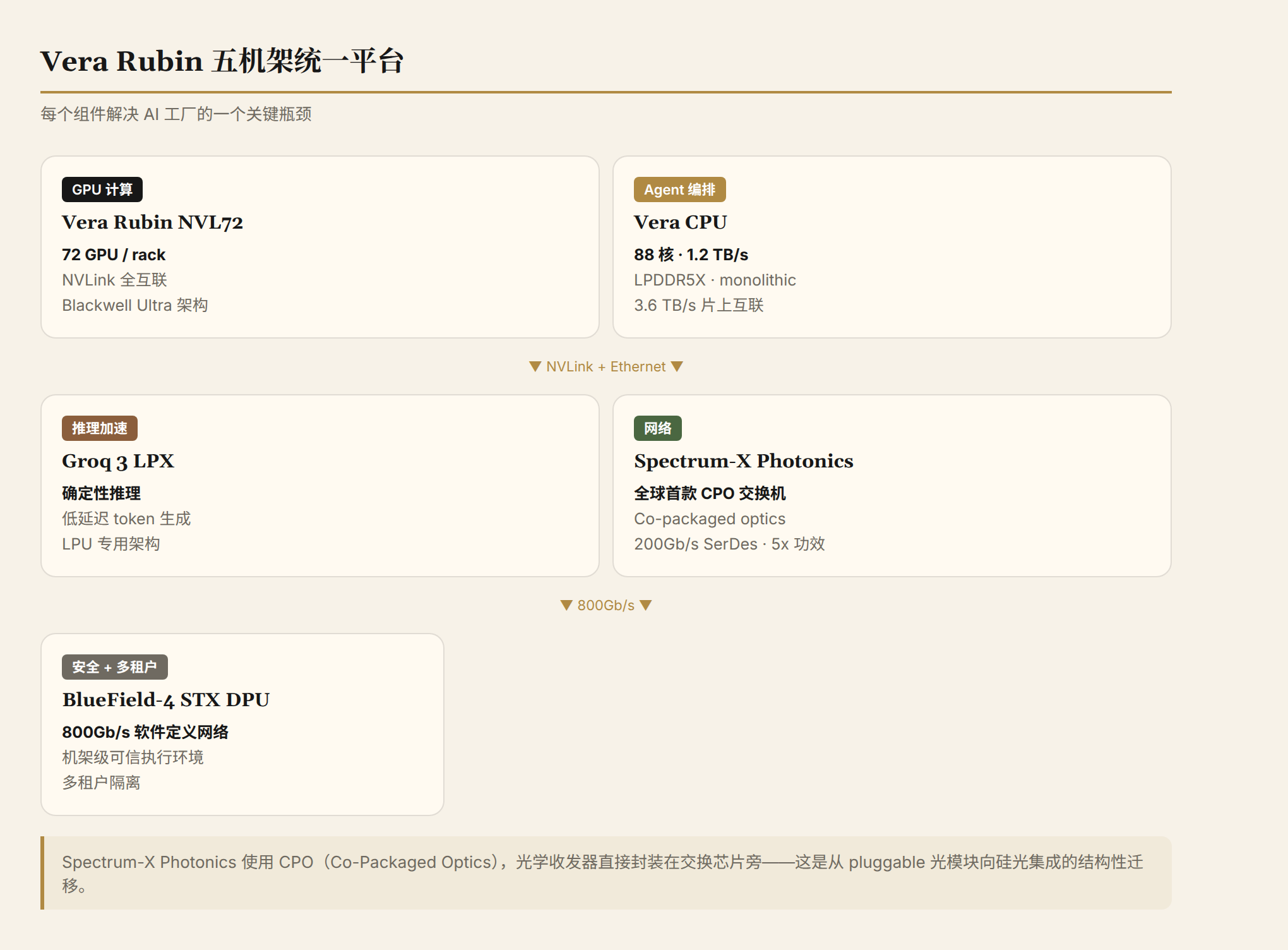
What's worth watching in this "five-rack" combo is the Spectrum-X Ethernet Photonics—the world's first switch based on co-packaged optics (CPO). CPO packages optical transceivers directly alongside the switch ASIC, eliminating the electro-optical conversion losses of traditional pluggable transceivers. NVIDIA claims the CPO approach delivers a 5x improvement in power efficiency over conventional designs.
This means AI factory networking is migrating from "copper + pluggable optical modules" toward "silicon photonics integration." For optical module vendors, this is a structural shift worth watching carefully.
DSX: The Open-Source AI Factory Operating System
Vera Rubin is the hardware. DSX is the software. Together, they form the complete AI factory solution.
Four Components
| Component | Function | Analogy |
|---|---|---|
| DSX MaxLPS | 45°C liquid cooling + rack technology, fitting 40% more GPUs at the same power | Data center "space optimization" |
| DSX OS | Open-source modular AI factory operations software | Data center "operating system" |
| DSX Sim | High-fidelity factory simulation (partnering with Cadence, Dassault, PTC, Siemens) | Data center "digital twin" |
| DSX Flex | Grid-responsive power consumption adjustment | Data center "smart meter" |
Making DSX OS "open source" is a shrewd strategy. NVIDIA isn't just selling hardware—it's defining the operational standard for AI factories. If DSX OS becomes the de facto standard, NVIDIA transcends being a chip supplier and becomes the platform owner for AI infrastructure—similar to Red Hat's role in the Linux ecosystem.
"Compute is Revenue"
Huang repeatedly emphasized one logic in the keynote:
"If you have 1 gigawatt of power, then throughput per watt is revenue. Choosing the wrong architecture just because the chips are cheaper doesn't make sense."
"The more you buy, the more you make."
The logic behind these statements: in an AI factory, GPUs are not cost centers—they're revenue centers. The number of AI inference tokens each GPU can generate per hour maps directly to revenue. So choosing a more expensive but higher-throughput architecture (Vera Rubin) makes more economic sense than choosing a cheaper but lower-throughput alternative.
This logic holds up for inference scenarios—inference can be billed per token. But does it hold for training? Training is a one-time investment whose output is model weights, not something you can sell per token. This argument may face challenges in the training market.
DGX Station for Windows: Trillion-Parameter Models at Your Desk
At the top of the RTX Spark product matrix shown at the keynote sits the DGX Station for Windows:
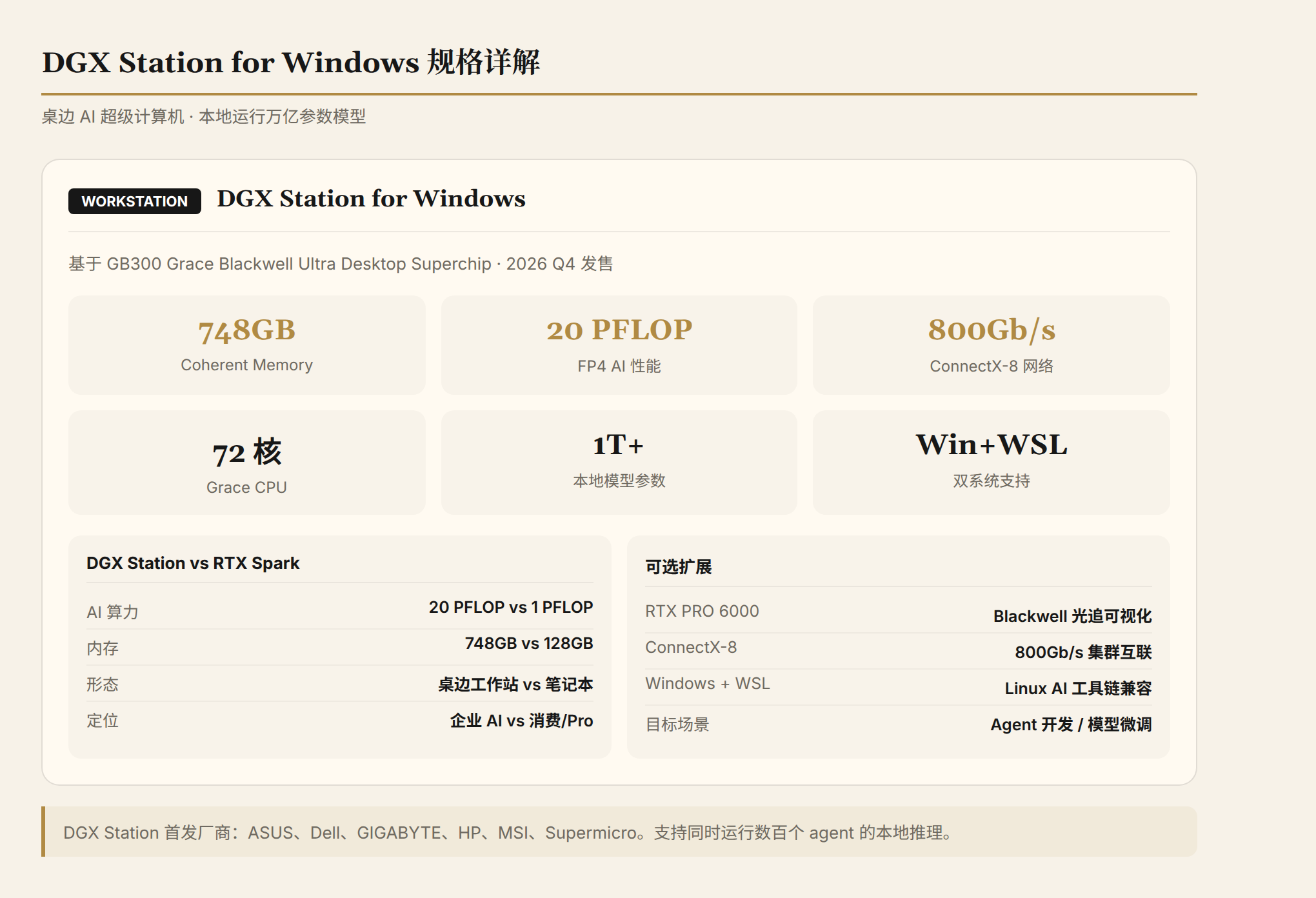
| Parameter | Specification |
|---|---|
| Chip | GB300 Grace Blackwell Ultra Desktop Superchip |
| CPU | 72-core Grace CPU |
| GPU | Blackwell Ultra GPU |
| Memory | Up to 748GB coherent memory |
| AI Performance | 20 PFLOP FP4 |
| Networking | ConnectX-8 SuperNIC, 800Gb/s |
| Capability | Run trillion-parameter models locally |
748GB of memory, 20 PFLOP of compute, 800Gbps networking—this isn't a workstation. It's an AI supercomputer that sits on your desk. It supports Windows + WSL, meaning developers can use Linux AI toolchains within a Windows environment.
Pricing wasn't announced, but given the BOM of a GB300 + 748GB memory + ConnectX-8, expect it to land in the $15,000–25,000 range. The target customers are enterprise AI teams and research institutions.
Other Announcements: From Models to Robots
Nemotron 3 Ultra: 550B Open-Source MoE
NVIDIA released Nemotron 3 Ultra—a 550B-parameter mixture-of-experts model. The key selling point: 5x inference speedup and roughly 30% lower operating costs compared to current leading open models.
Post-training adaptation covers mainstream agent platforms: Hermes Agent, LangChain Deep Agents, OpenClaw, OpenHands, OpenCode. CrowdStrike and Palantir are among the first adopters.
Available June 4 via Hugging Face, ModelScope, and OpenRouter.
Cosmos 3: Open Physical AI Foundation Model
A physical AI omnimodel built on a mixture-of-transformers architecture, natively supporting multimodal inputs: text, image, video, ambient sound, and action. It ranks first on multiple physical AI benchmarks.
Three variants: Cosmos 3 Super (highest accuracy), Nano (real-time inference), and Edge (edge devices).
Isaac GR00T: Open Humanoid Robot Reference Design
A complete open-source humanoid robot reference design based on the Jetson Thor platform. This is NVIDIA's first fully open-source hardware design for robotics.
Agent Toolkit + CUDA-X Agent Skills
Huang defined the agentic computing pattern:
"An agent that is a model, wrapped in a harness that uses tools with skills and runs in a runtime."
CUDA-X libraries (cuDF, cuOpt, AI-Q, NeMo, PhysicsNeMo, CUDA-Q) have been packaged as agent skills, available on the Claude Code plugin marketplace and Hermes Skills Hub. Cadence and NVIDIA's joint chip verification agent claims 40x verification speedup.
The Competitive Landscape: NVIDIA's Three Identities
Look at all the announcements together, and NVIDIA is simultaneously playing three roles:
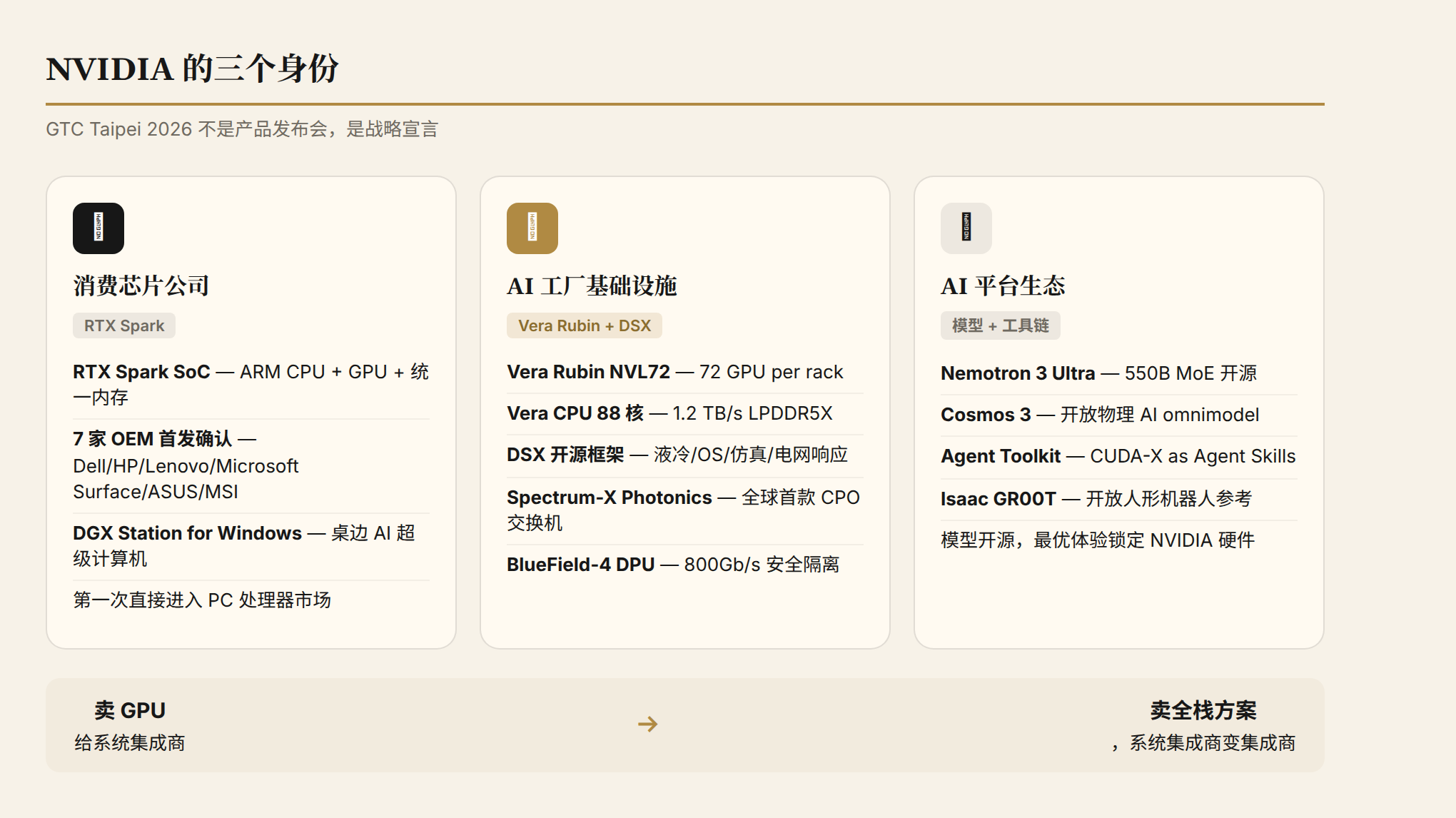
First, a consumer chip company. RTX Spark marks NVIDIA's first direct entry into the PC processor market. Not selling GPUs to PC makers—selling complete SoCs. This changes NVIDIA's relationship with Intel, AMD, and Qualcomm. Former partners (NVIDIA selling discrete GPUs, Intel selling CPUs) are now direct competitors.
Second, an AI factory infrastructure company. Vera Rubin + DSX + Spectrum-X + BlueField—NVIDIA is no longer providing just GPUs, but the entire full-stack AI factory solution. From chips to networking to liquid cooling to operating systems to simulation software. This also changes the relationship with traditional data center vendors (Dell, HPE, Lenovo). They go from being NVIDIA's customers to being integrators of NVIDIA's solutions.
Third, an AI platform ecosystem company. Nemotron 3 Ultra, Cosmos 3, Agent Toolkit, CUDA-X Agent Skills—NVIDIA is building its own AI ecosystem. The models are open-source, the toolchains are open, but the optimal experience is always on NVIDIA hardware. It's a strategy of "open enclosure."
Impact on the Competitive Landscape
| Company | Impact Level | Reason |
|---|---|---|
| Intel | 🔴 High | RTX Spark directly competes in consumer CPUs; Vera CPU competes in data center CPUs; Arc G3 offers a first handheld solution but at far smaller scale than NVIDIA |
| AMD | 🟠 Medium-High | Zen 6 won't launch until 2027, leaving NVIDIA's ARM PC solution an entire year of uncontested window; data center GPU (MI400) needs to prove itself in H2 |
| Qualcomm | 🟡 Medium | Snapdragon C covers the $300 low end and doesn't directly compete with RTX Spark; but the power to define the ARM PC market may shift from Qualcomm to NVIDIA |
| Apple | 🟡 Medium | The M-series has a first-mover advantage in ARM laptops, but lacks the CUDA ecosystem. AI developers and creators are the contested ground |
| Chinese GPU Vendors | 🔴 High | Vera Rubin full production + DSX standardization widens the generational gap in AI infrastructure |
Other Highlights from Computex 2026
Intel Arc G3: Purpose-Built Silicon for Handhelds
Intel launched the Arc G3 series, its first chips purpose-built for handheld gaming:
- Arc G3 Extreme: 14-core Panther Lake + 12 Xe3 cores + 50 TOPS NPU, Intel 18A process
- Standard Arc G3: 10 Xe3 cores, 10–20% lower performance
- Launch devices: Acer Predator Atlas 8, MSI Claw 8 EX AI+
Intel 18A is Intel's most advanced process node. Arc G3 is the first consumer gaming chip manufactured on Intel 18A. If this chip hits its yield and performance targets, it carries signaling value for Intel Foundry's efforts to attract external customers.
AMD: A Conservative Year
AMD's Computex cadence this year leaned conservative. Zen 6 "Medusa Point" has appeared on Geekbench (10C/20T, 32MB L3), but won't launch until 2027. This year is Zen 5 refreshes + Gorgon Halo for the mobile transition.
Biostar teased next-gen AMD motherboards, hinting that the Zen 6 desktop platform may arrive ahead of mobile. The iGPU continues using RDNA 3.5 rather than RDNA 4, possibly signaling that RDNA 5 will launch alongside Zen 6 in 2027 as a unified release.
DDR6 + CAMM2
JEDEC confirmed that CAMM2 will become the new standard for desktop PCs. DDR6 starts at 8.8 Gbps, maxing out at 17.6 Gbps. MSI showcased the world's first CAMM2 DDR5 desktop motherboard at this year's Computex.
A 32GB LPDDR6 CAMM2 module is estimated at around $500—cost remains a barrier to mass adoption. But the direction is set: the DIMM era is coming to an end.

Assessment
Can NVIDIA's RTX Spark Succeed?
Most likely yes, but it won't be smooth sailing.
Favorable factors:
- The CUDA ecosystem is a killer advantage. AI developers, creators, and researchers have no real alternative—AMD ROCm and Intel oneAPI are years behind in ecosystem maturity
- Microsoft + seven OEMs jointly on stage provides enough launch momentum
- 128GB unified memory + 1 PFLOP has no competition in laptop form factor
Risk factors:
- Gaming compatibility on ARM. If AAA games can't run smoothly, RTX Spark gets boxed into the niche "AI pro laptop" market
- Pricing. The BOM for a Blackwell GPU + 128GB unified memory isn't low
- ARM PCs have a history of "this time it's different" failures (Windows RT, Qualcomm 8cx)
What Does Vera Rubin Mean for the Supply Chain?
Vera Rubin entering full production means the supply chain bottlenecks of 2026–2027 will be even more severe. The supply-demand gap for HBM4, 800G optical modules, CoWoS-L packaging, and liquid cooling infrastructure will continue to widen. For companies in these supply chains, the question isn't whether demand is sufficient—it's whether capacity can keep up.
AI Infrastructure Competition Enters the "Full-Stack" Phase
It used to be enough to buy GPUs and slot them into servers. Now NVIDIA sells complete AI factories—chips, networking, liquid cooling, operating systems, simulation, models. Competitors who can't offer an equally complete solution are reduced to component suppliers.
For traditional server vendors like Dell, HPE, and Lenovo, this means a role shift: from "designing servers" to "integrating NVIDIA solutions." Profit margins will be squeezed.
Next Observation Points
- Microsoft Build (June 2–3): Windows agent development details, RTX Spark software support
- Fall 2026: RTX Spark laptops go on sale, first benchmarks and gaming compatibility tests
- Q3–Q4 2026: First Vera Rubin volume shipments, actual performance data
- Q1–Q2 2027: AMD Zen 6 launches, ARM PC competitive landscape becomes clearer
Disclosure: This article is based on NVIDIA's GTC Taipei Keynote (June 1, 2026) official press release and presentation content, cross-verified with reporting from The Verge, Tom's Hardware, XDA Developers, HotHardware, TechRadar, STORDIS, ServeTheHome, and other media outlets. It does not constitute investment advice. Data in this article is current as of June 1, 2026.