The Networking Challenge of 131,072 GPUs
By late 2025, OpenAI's production cluster was running 131,072 GPUs. Built with traditional InfiniBand or RoCEv2 networking, this scale would hit three hard ceilings:
First, ECMP hash collisions. Traditional networks use hashing to spread traffic across multiple equal-cost paths. But hashing is probabilistic — when a cluster has tens of thousands of links and billions of packets per second, hot-spots are inevitable. When two heavy flows simultaneously hash to the same link, latency spikes, and the tail latency of collective operations like AllReduce drags down the entire training step.
Second, PFC's cascading effects. RoCEv2 relies on Priority Flow Control for lossless networking — when a receiver's buffer is nearly full, it sends a pause frame to tell the sender to stop. But in large-scale Clos topologies, pause frames propagate upstream through the network, creating incast storms. Worse, pause frames at different priorities can deadlock against each other. The larger the scale, the more uncontrollable PFC becomes.
Third, dynamic routing convergence delay. BGP/OSPF must recalculate routing tables after a link failure. In a 100K-GPU cluster, convergence can take tens to hundreds of milliseconds. Training jobs are extremely latency-sensitive — a single routing convergence event can cause AllReduce to time out, forcing the entire job to restart from a checkpoint.
OpenAI's answer is MRC (Multipath Reliable Connection) — a network transport protocol designed from scratch. It doesn't just solve the three problems above; it fundamentally rethinks where intelligence should live in the network.
Five Overturned Conventions
MRC simultaneously overturns five data center networking conventions that have accumulated over three decades. Not incremental fixes — each one is overturned entirely.

1. ECMP Hashing → Entropy Value Packet Spraying
Old approach: Switches use a five-tuple hash to select the next hop. All packets of the same flow take the same path. Path selection is entirely determined by the switch; endpoints (NICs) have no control.
MRC approach: Each QP (Queue Pair) maintains 128–256 Entropy Values (EVs), with each EV mapped to an end-to-end path. When transmitting, the NIC round-robins across all active EVs, utilizing all 256 paths simultaneously.
Why: The fundamental problem with ECMP is that its granularity is too coarse — a single flow can only take one path. In AllReduce scenarios, a few large flows can saturate a single link. EV spraying distributes each QP's traffic across 256 paths, fundamentally eliminating hot-spots.
Production data: OpenAI reports that 256 paths evenly distribute traffic, raising bandwidth utilization from ~60% with ECMP to ~95%.
2. PFC Lossless Networking → Disable PFC, Allow Packet Loss
Old approach: RoCEv2 uses PFC pause frames to achieve lossless networking. When buffers are nearly full, it pauses to guarantee no packet loss. The cost is incast storms and deadlock risk.
MRC approach: PFC is disabled outright. Switches are allowed to drop packets. The consequences of packet loss are handled by the NIC itself — through selective ACK and precise retransmission of lost packets.
Why: In a 100K-GPU cluster, the propagation chain of PFC pause frames is too long. Any single failure point can trigger a cascading failure. MRC's philosophy: rather than spending enormous effort guaranteeing a lossless network, make packet loss the norm and handle it efficiently at the endpoint. This is consistent with the Internet's design philosophy — TCP achieves reliable transport over a network that drops packets.
3. Single-Path In-Order Delivery → Out-of-Order Direct Write
Old approach: RoCEv2 requires packets to arrive in PSN (Packet Sequence Number) order. When the receiver detects a gap in PSNs, it discards out-of-order packets and triggers go-back-N retransmission.
MRC approach: With 256 paths transmitting simultaneously, packets inevitably arrive out of order. MRC doesn't just tolerate this — it specifically designs for Out-of-Order Direct Write. Each packet carries its own RDMA virtual address and remote key, so regardless of arrival order, it writes directly to the corresponding memory location.
Why: If in-order delivery is required, any single slow path among 256 will stall the entire QP. This completely negates the advantage of parallel paths. Out-of-order direct write allows each path to progress independently without interference. A CQE (Completion Queue Entry) is generated to notify upper layers only when all packets for a given address range have arrived.
4. Dynamic Routing → SRv6 uSID Static Source Routing
Old approach: Switches run BGP/OSPF/IS-IS to dynamically compute routing tables. Link failures trigger routing convergence, and all affected flows are rerouted.
MRC approach: SRv6 uSID (16-bit compressed segment routing) is used to specify the complete path at the sender. Path information is encoded in the IPv6 destination address. Switches don't need to run any routing protocol — they do exactly one thing: match the destination address prefix, left-shift 16 bits, and forward to the corresponding port. The routing table is written at switch boot time and never changes.
Why: Dynamic routing has two fatal problems in large-scale clusters: convergence delay (traffic interruption after failure) and uncontrollable ECMP hash redistribution (uneven traffic distribution after convergence). Static source routing hands path control to the sender's NIC — the NIC knows which EVs are healthy and which are congested, so it can proactively select good paths without waiting for network convergence.
5. Switch-Managed Congestion Control → Switches Only Mark ECN
Old approach: Switches participate in congestion control through PFC pause frames and ECN (Explicit Congestion Notification). The network and endpoints cooperatively adjust sending rates.
MRC approach: The switch's role is simplified to the extreme — forward packets, mark ECN, nothing more. ECN marks carry an EV tag; when the NIC receives one, it knows exactly which path is congested, marks the corresponding EV as congested, and switches to another EV to continue transmitting. Don't slow down — switch paths instead.
Why: Switches don't maintain per-flow state. They don't know which QP is using which path. Asking them to do congestion control is making decisions with wrong information. The NIC has complete EV state and can make precise path selection decisions.
Four-Protocol Full Comparison
| Dimension | RoCEv2 | MRC | UET (UEC 1.0) | InfiniBand |
|---|---|---|---|---|
| Multipathing | None (ECMP flow-level) | ✅ Packet spraying 128-256 paths | ✅ Packet spraying | ✅ Adaptive routing |
| Loss recovery | Go-Back-N/selective retransmission | Selective retransmission + trimming | Selective retransmission + trimming | Link-level + transport-level retransmission |
| Flow control | PFC (lossless) | Disable PFC | Credit-based | Credit-based |
| Source routing | None | SRv6 C-SID | None | None |
| Failure recovery | Seconds (routing convergence) | Microseconds (NIC bypass) | Milliseconds (TBD) | Seconds (Subnet Manager) |
| Deployment complexity | Medium | Medium-high | High | Medium (NVIDIA integrated) |
| Cost | Low | Medium | Medium | High |
| Suitable scale | ≤64K GPU | 100K+ GPU | 100K+ GPU | ≤64K GPU (economic scale) |
| Software interface | RDMA Verbs (full) | RDMA Verbs (Write+WriteImm) | libfabric v2.0 | RDMA Verbs |
| Ecosystem maturity | ★★★★★ | ★★★★ (OpenAI/MS production) | ★★★ (spec just released) | ★★★★★ (NVIDIA full-stack) |
InfiniBand's role: NVIDIA dominates the IB ecosystem through its Mellanox acquisition. XDR (800 Gb/s) is being deployed (Quantum-X800 + ConnectX-8); GDR (1600 Gb/s) is on the roadmap. IB technical advantages (native lossless, ultra-low latency 1-2μs, full-stack compatibility) coexist with disadvantages (high cost, vendor lock-in, scarce operations talent). Gartner predicts >65% of generative AI clusters will be Ethernet-based by 2029, with IB retreating to latency-sensitive high-end niches.
Standardization Landscape
AI network protocols currently follow three parallel standardization tracks:
| Project | Organization | Status | Description |
|---|---|---|---|
| RFC 9800 | IETF | ✅ Published | SRv6 Compressed Segment List (C-SID/uSID) |
| RFC 9743 | IETF | ✅ Published | New congestion control specification guidelines |
| MRC 1.0 | OCP | ✅ 2026.05 | OpenAI-led, open license |
| UET 1.0 | UEC | ✅ 2025.06 | 120+ member companies |
| 802.3df | IEEE | ✅ 2024 | 800G Ethernet standard |
| 802.3dj | IEEE | In progress | 1.6T Ethernet (200G/lane), expected 2026-2027 |
| XDR | IBTA | ✅ 2023.10 | 800 Gb/s InfiniBand |
The three tracks aren't mutually exclusive: MRC draws on UET technology; SRv6 serves MRC's source routing needs; IETF provides underlying source routing infrastructure.
Core Protocol Mechanisms
The Four-State EV State Machine
Each EV has four states, reflecting the health of its associated path:
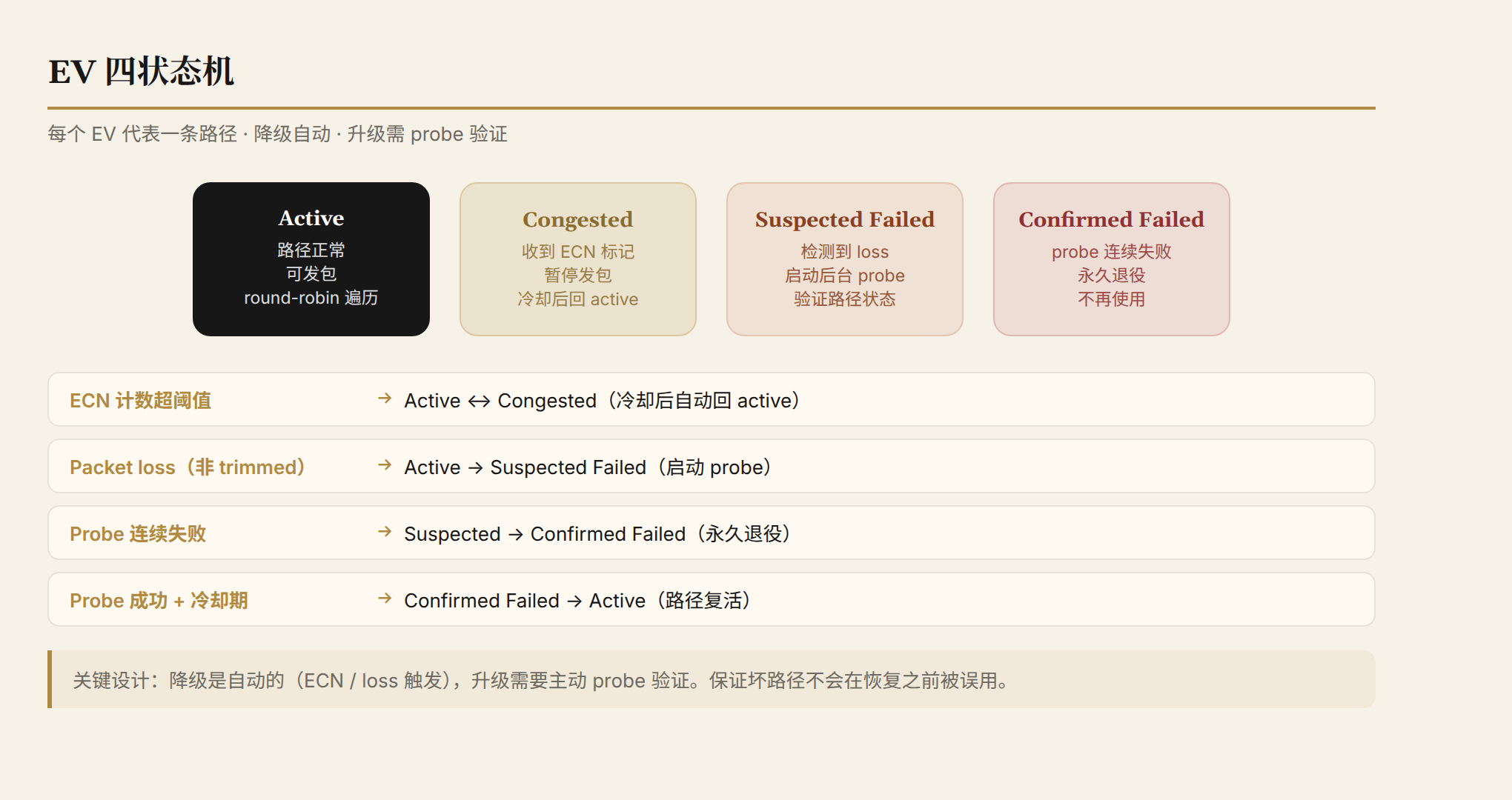
- Active: The path is healthy and can transmit. The sender round-robins across all active EVs.
- Congested: Entered upon receiving an ECN mark with an EV tag. The EV temporarily stops transmitting, then returns to active after a cooldown period.
- Suspected Failed: Entered upon detecting packet loss (not trimming). A background probe is initiated to test whether the path is truly broken.
- Confirmed Failed: The probe has failed repeatedly. The EV is permanently retired and never used again.
A key design principle of state transitions: downgrades are automatic (triggered by ECN or loss), but upgrades require proactive probe verification. This ensures that a bad path is never mistakenly reused before it has actually recovered.
SRv6 uSID: Why Not Standard SRv6?
SRv6 (Segment Routing over IPv6) already has mature deployments in carrier networks. But MRC chose uSID (Micro SID, RFC 9800), a compressed variant, rather than standard SRv6. This wasn't an arbitrary choice.
The problem with standard SRv6: Each segment is a 128-bit SID, and multiple SIDs form an SRH (Segment Routing Header) — a variable-length extension header. Switch chip parsers need to skip over the SRH to read the inner header. At high bandwidth, the latency of processing variable-length headers is unpredictable, and many chips can't do it at line rate.
uSID's solution: Compress multiple 16-bit uSIDs into a single 128-bit IPv6 destination address. No SRH extension header needed. The switch's forwarding operation becomes three steps:
- Match the first 48 bits of the destination address (local locator)
- Left-shift the destination address by 16 bits (moving the next uSID to the front)
- Look up the static forwarding table and forward to the corresponding port
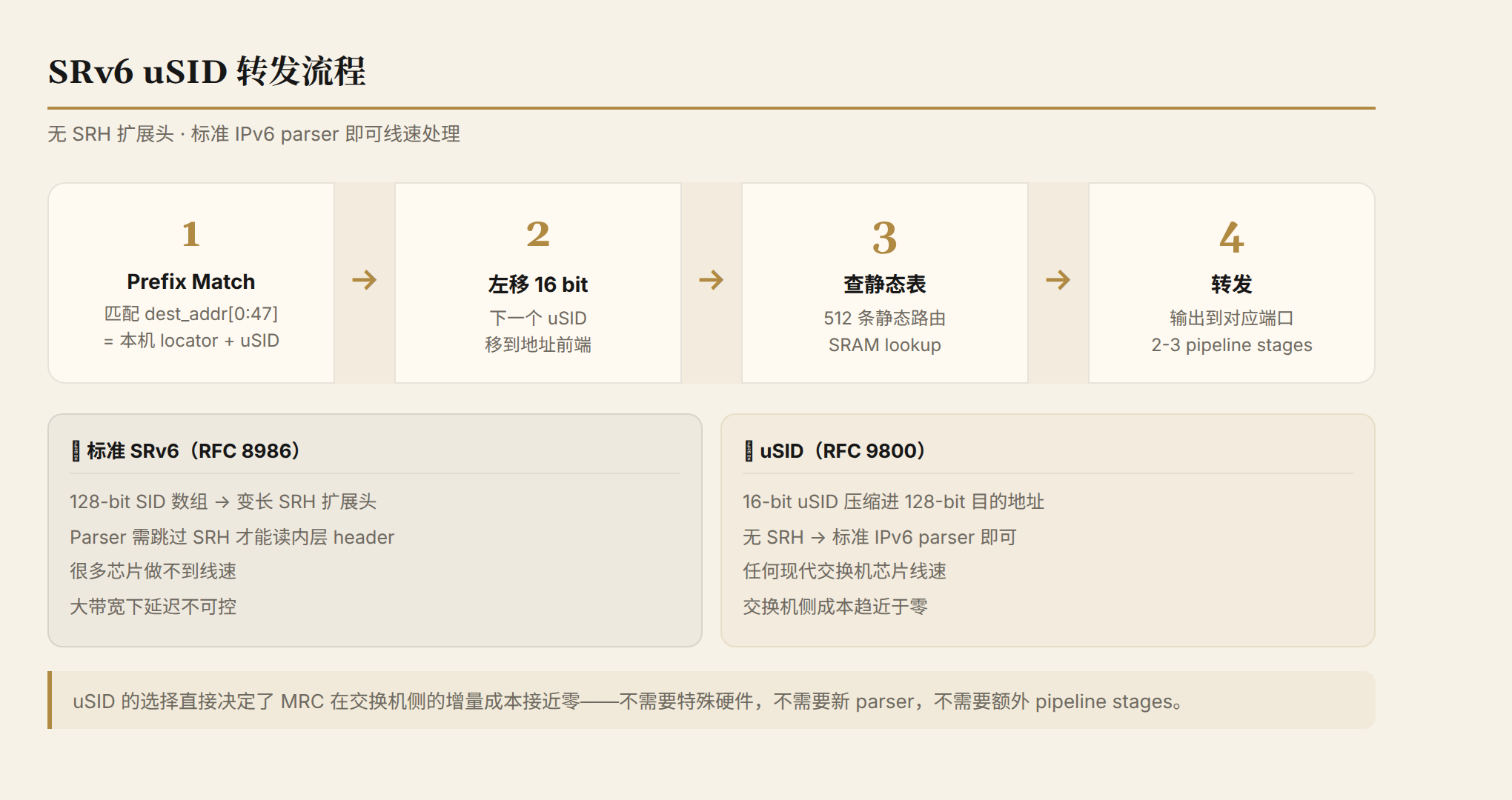
This three-step operation requires only 2–3 pipeline stages and can be done at line rate by any modern switch chip. A standard IPv6 parser is sufficient — no special hardware required.
This is a critical design decision: The choice of uSID directly ensures that MRC's cost on the switch side approaches zero.
Packet Trimming: Congestion Without Dropping Data
Packet trimming is an elegant MRC design: when a switch detects congestion, instead of dropping the entire packet, it can keep only the header and strip the payload, forwarding the trimmed header as a priority packet to the receiver.
When the receiver NIC receives a trimmed header, it knows two things:
- The path is still alive (just congested) → send a NACK to trigger retransmission
- No need to wait for a timeout → reduces retransmission latency
If the NIC receives nothing at all (not even a header), it knows the path may be down → retire the corresponding EV.
This design splits packet loss events into two semantic categories: "congestion loss" is handled by trimming (the path is still up), while "failure loss" is handled by EV retirement (the path may be down). Precisely distinguishing between these two cases makes recovery strategies more targeted.
At the Chip Level: What NICs Need
Protocol design is one thing; burning it into silicon is another. MRC's hardware requirements for NICs are structural — not just adding a few registers, but requiring new IP cores.
Per-QP State: From 512 Bytes to 16KB
Traditional RoCE's QP (Queue Pair) context is very lightweight — PSN, memory windows, a few pointers, roughly 256–512 bytes.
MRC drives this number up to ~16KB per QP:
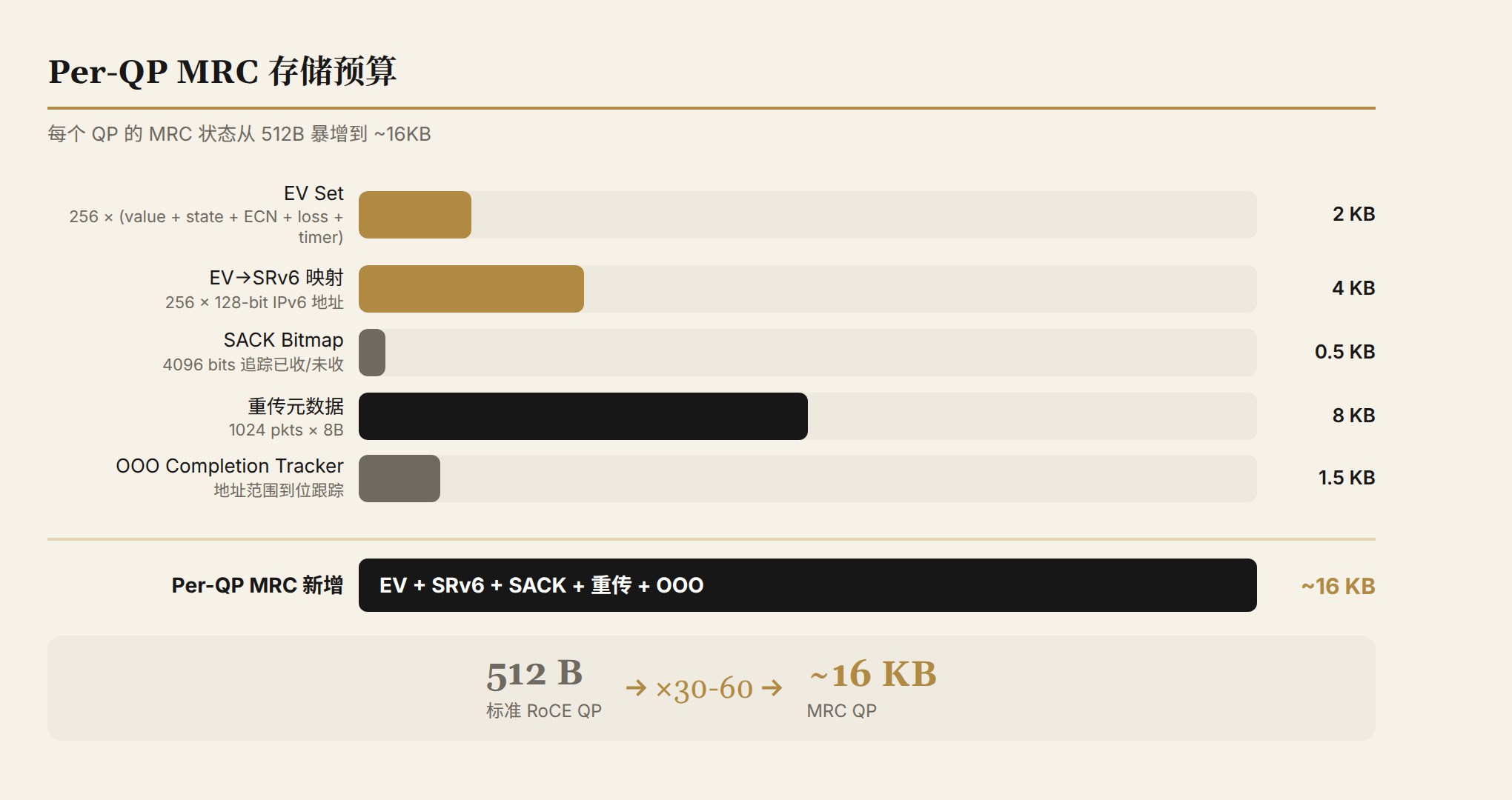
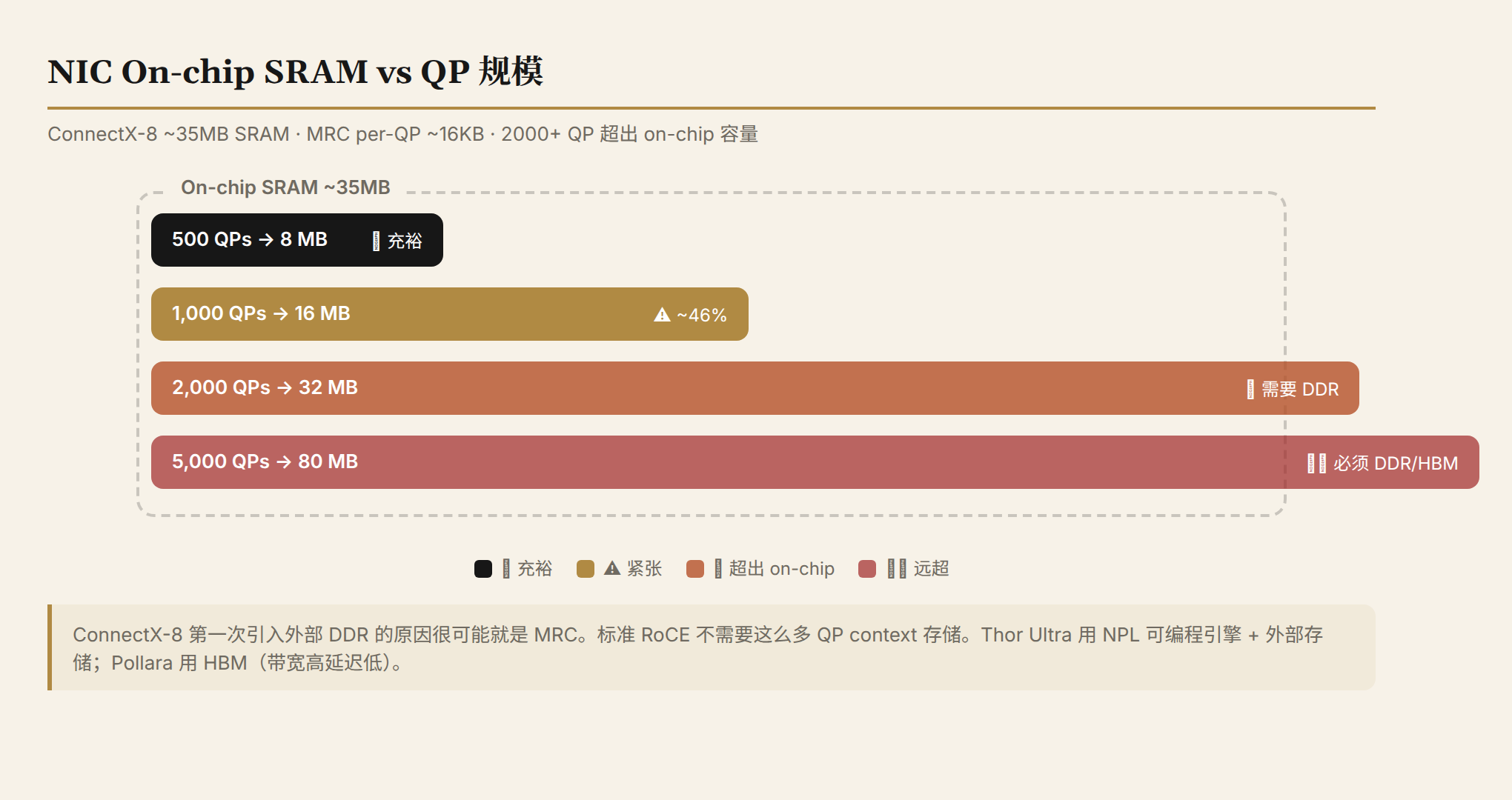
16KB doesn't sound like much. But an 800G NIC at full load may have 1,000–5,000 active QPs:
| Active QPs | MRC Storage | On-chip SRAM (~35MB) | External Storage Needed? |
|---|---|---|---|
| 500 | ~8 MB | ✅ Comfortable | No |
| 1,000 | ~16 MB | ⚠️ ~46% | Tight but feasible |
| 2,000 | ~32 MB | ❌ Exceeded | DDR cache required |
| 5,000 | ~80 MB | ❌ Far exceeded | DDR/HBM mandatory |
A 30–60× increase in per-QP storage directly explains why ConnectX-8 introduces external DDR for the first time. Standard RoCE doesn't need this much storage — 40 QPs × 512B = 20KB, easily fitting in on-chip SRAM. MRC's 1,000 QPs × 16KB = 16MB starts pushing against on-chip limits.
Six New Hardware IP Cores
MRC requires NIC chips to include the following hardware IP cores, which traditional RoCE NICs lack:
- RDMA OOO write engine — Traditional RDMA assumes in-order delivery; the IP core doesn't support out-of-order writes. A new design is needed.
- EV state machine — 256 per QP, with microsecond-level state transitions. Requires dedicated SRAM + control logic.
- SRv6 uSID encap/decap — Sender maps EVs to IPv6 destination addresses (combinatorial logic); receiver strips them.
- SACK bitmap + selective retransmit — Per-QP bitmap precisely tracks received/missing packets, with a hardware retransmit queue.
- ECN-to-EV mapper — Rather than doing rate control, it does path selection. Upon receiving an ECN mark, it identifies the specific EV and marks it as congested.
- Probe engine — Background path probing with hardware timers + packet generation/parsing.
Rough silicon estimate: ~20–30% additional die area vs. same-generation RoCE NICs. The main increase comes from EV state SRAM (256 × 16KB = 4MB per QP set × N QPs). At 5nm process, this translates to roughly $10–20 additional die cost.
Three NIC Vendors, Three Strategies
NVIDIA ConnectX-8, AMD Pollara, and Broadcom Thor Ultra all claim MRC support, but their implementation paths differ:
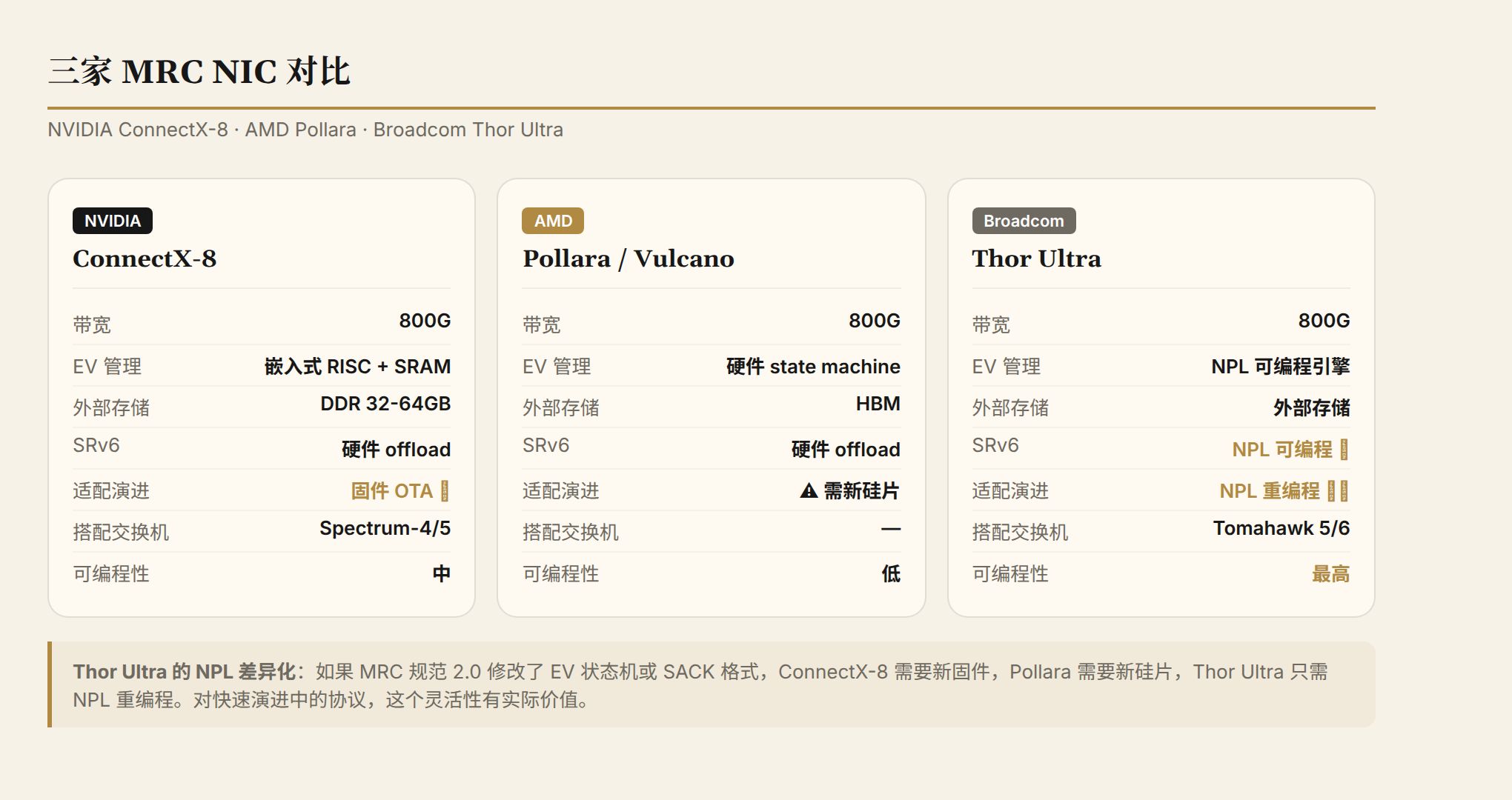
ConnectX-8 uses embedded RISC cores + dedicated SRAM to manage EV state. Hot QPs are kept on-chip; cold QPs spill over to external DDR. Firmware OTA can update MRC logic to adapt to spec evolution.
AMD Pollara burns the EV state machine into fixed hardware logic, with state storage placed in HBM (high bandwidth, low latency). Performance may be the best, but if MRC spec v2.0 changes the EV state machine, a new generation of silicon would be required.
Broadcom Thor Ultra implements MRC logic using NPL (Network Programming Language). NPL can be reprogrammed after the chip ships — if the MRC spec evolves, only an NPL microcode update is needed, not new silicon. This flexibility has real value for a rapidly evolving protocol like MRC.
At the Chip Level: Switches Actually Get Simpler
MRC's impact on switches is counterintuitive: it adds a little, but removes a lot.
Additions
| Feature | Hardware Requirement | Difficulty |
|---|---|---|
| SRv6 uSID line-rate forwarding | 48-bit prefix match + 128-bit left-shift + SRAM lookup = 2–3 pipeline stages | Medium |
| Static routing table | 512 entries × 8 bytes ≈ 4KB | Low |
| ECN per-port toggle | 512 bits | Low |
| Packet trimming | Ingress buffer truncation + priority forwarding, ~1–2MB | Medium |
Removals
| Traditional Feature | Still Needed for MRC? | Resources Freed |
|---|---|---|
| BGP/OSPF/IS-IS FIB | ❌ No | Several MB of TCAM + control plane CPU |
| Large ECMP groups (256+ members) | ❌ No | Significant TCAM |
| PFC pause frame processing | ❌ Disabled | ~50MB buffer + pipeline logic |
| Link-layer retransmission | ❌ No | Ingress pipeline simplification |
| PFC deadlock detection | ❌ No | Control logic simplification |

Taking Spectrum-4 (51.2T, ~256MB buffer) as an example:
MRC's new consumption is roughly 4–5MB (trimming temp storage + SRv6 header overhead). But disabling PFC frees up approximately 50MB of buffer, plus eliminating the need for LPM TCAM and ECMP group TCAM. The net effect is more available buffer and reduced TCAM pressure.
The 102.4T-generation Tomahawk 6 is even more interesting — its buffer is only 267MB (11MB more than Spectrum-4, but double the bandwidth, meaning buffer per bit dropped 34%). The PFC buffer saved by MRC exactly fills this gap. Moreover, Tomahawk 6 natively supports Cognitive Routing 2.0 (intelligent load balancing) and Packet Trimming (CSIG module). These features weren't added as an afterthought for MRC — they were built into the chip design from the start.
Real Topology of a 131K GPU Cluster
OpenAI's production cluster deploys 8 parallel network planes using 51.2T devices (128×400G switches):

Key parameters:
| Tier | Per Plane | 8 Planes |
|---|---|---|
| T0 (access, 128×400G) | 64 switches | 512 switches |
| T1 (aggregation, 128×400G) | 32 switches | 256 switches |
| Total | 96 switches | 768 switches |
| 100G optical modules | ~49K | ~393K |
Topology details: Each GPU is equipped with one 800G NIC, broken out into 8×100G — each 100G link connects to one plane. T0 switches' 128×400G breakout into 512×100G, with 256 downlinks connecting to NICs and 256 uplinks connecting to T1.
Failure Recovery
The paper reports several production failure recovery scenarios:
| Failure | Recovery Behavior |
|---|---|
| T0 switch reboot | Training job briefly slows for 1–2 seconds; no restart needed |
| 4 links flapping simultaneously | Training briefly slows, then self-heals |
| T1 switch reboot | NICs in the affected plane retire corresponding EVs; other planes unaffected |
A T0 switch reboot doesn't require restarting the training job — this would be unthinkable in a traditional RoCE network. In traditional networking, a switch reboot means all flows traversing it are interrupted, AllReduce times out, and the job restarts from a checkpoint. In MRC, the NIC detects the path failure, retires the corresponding EV, automatically switches to other paths, and the upper layer is barely affected.
O(N) Scaling
Extending from 131K to 500K GPUs:
| 131K | 500K | Change | |
|---|---|---|---|
| Number of switches | 768 | ~3,000 | Linear |
| Per-switch routing table | 512 entries | 512 entries | No change |
| Per-switch buffer requirement | Same | Same | No change |
Each switch only cares about its local port's static routing table. Doubling the cluster means just adding more switches — no need to change routing protocols or replan the topology. This O(N) scaling property is a direct result of static routing — no BGP convergence delay, no ECMP hash redistribution.
China's Industry: Where the Gap Lies
Hardware Gap
Switch chips: Centec's GoldenGate series reaches 25.6T, while NVIDIA Spectrum-4 and Broadcom Tomahawk 5 are already at 51.2T, and Tomahawk 6 reaches 102.4T. Chinese switch chips lag by a generation in capacity.
NIC chips: There are no products comparable to ConnectX-8, Pollara, or Thor Ultra. 800G smart NICs (with MRC support) remain a blank space.
Software Gap
NOS (Network Operating System): No domestic NOS has done MRC adaptation. The 16-bit compressed format of SRv6 uSID follows a different parser path from standard SRv6 — even if hardware supports SRv6, uSID line-rate forwarding needs dedicated validation.
Core Barrier
The gap isn't in the protocol — MRC's paper is public, and the OCP spec is undergoing standardization. The real barrier is validation at scale. OpenAI has run production data on 131,072 GPUs for months, proving MRC's viability at large scale. Latecomers need equally large-scale validation; otherwise, no one would gamble a new protocol on a 100K-GPU cluster.
This isn't a technology problem. It's a trust problem.
MRC and Asymmetric Topology Synergy: Source Routing Frees Topology
MRC's design assumes a multi-plane two-tier Clos — OpenAI's actual deployment topology. But MRC's core mechanisms (SRv6 static source routing + packet spraying + no PFC) are topology-agnostic: as long as multiple paths exist between every GPU pair, MRC works.
This means MRC can combine with asymmetric topologies (like ZCube) with natural advantages.
ECMP Requires Symmetry; Source Routing Doesn't
Traditional RoCEv2 + ECMP implicitly requires multiple "equal-cost" paths for hash-based even distribution. Symmetric topologies (like traditional Fat-Tree) naturally satisfy this, but asymmetric topologies (like ZCube with 2n ports at first/last layers vs 3n at middle layers) may have unequal path counts and bandwidth.
MRC's SRv6 source routing bypasses this constraint: paths aren't "assigned" — they're "encoded." The NIC knows each path's complete information (bandwidth, latency, current state) and can schedule at packet level with precision — paths don't need to be "equal-cost."
Short Paths Amplify Packet Spraying Effectiveness
MRC's packet spraying works better on short paths: shorter paths mean narrower packet arrival time windows, less out-of-order extent, and simpler NIC reorder buffer and SACK logic. ZCube's 2-hop diameter (vs 5-7 hops for three-tier Clos) is the optimal match in this dimension.
Path Diversity Requires k≥2
MRC's EV packet spraying needs at least 2 independent paths per flow to be effective (1 path = no spraying needed). ZCube's k=2 configuration (each GPU with 2 NIC ports connecting 2 different switches)provides exactly the minimum workable configuration. At k=3 or higher, MRC's path diversity is richer, but hardware cost also rises — this is a topology-protocol joint optimization problem that ATOP's current search space doesn't yet include (MRC packet spraying efficiency isn't in the objective function).
Unexplored Joint Optimization Space
The ZCube + MRC combination opens an unexplored optimization space: if ATOP simultaneously considered MRC's EV state machine parameters (path count, EV set size, failure detection thresholds) during topology search, could it find better joint topology-protocol solutions than independent optimization? This is a clear gap in current research.
→ Complete topology evolution analysis in Companion Piece One, "From CLOS to ZCube".
Assessment
Will MRC Become the Standard for AI Cluster Networking?
Most likely yes, but not in the short term.
Favorable factors:
- OpenAI is already running 131K GPUs in production with real data
- NVIDIA, AMD, and Broadcom — three NIC giants — all support it simultaneously; ecosystem coverage is sufficient
- Incremental cost on the switch side is nearly zero (even a net reduction), so deployment resistance is low
- O(N) scaling makes managing ultra-large-scale cluster networking go from a nightmare to linear growth
What to watch:
- MRC currently has only OpenAI validating it in production. More large-scale deployment cases are needed
- The management plane for SRv6 uSID (path computation, uSID allocation) is non-trivial in complexity; mature orchestration tools are needed
- Standard RoCEv2 with fine-tuning is still adequate for small-to-medium clusters. At what scale does MRC's advantage become indispensable?
Impact on the Networking Chip Industry
NIC vendors: MRC increases NIC complexity and die cost by 20–30%. This is acceptable for NVIDIA and Broadcom (they already have margin headroom in the high-end NIC market), but it means a higher technical barrier and investment for new entrants.
Switch vendors: Short-term impact is small (MRC even simplifies switches). The long-term question is: as NICs take on more and more network intelligence, will switches be further "dumb-piped"? If all network intelligence concentrates in NICs, and switches only need to do stateless line-rate forwarding, where is the value-add?
Disclaimer: This article is based on cross-verification of the arXiv paper 2605.04333 (OpenAI MRC protocol specification), the official OpenAI blog, vendor blogs from NVIDIA/AMD/Broadcom, and product documentation from Edgecore/STORDIS. It does not constitute investment advice. Data cited is current as of June 1, 2026.