Draft v1 | 2026-06-11
At Google I/O in May 2025, Gemini Diffusion quietly appeared in the demo area. No keynote spotlight, no Sundar Pichai introduction. An experimental model, listed dead last among a dozen announcements.
But it did something no autoregressive model could: generate 1,479 tokens per second.
A month later, DiffusionGemma went open source. 26B parameters, Apache 2.0 license, inference speed 3.7× that of the comparable Gemma 4. Inception Labs, a Stanford spinoff, had already launched its commercial product Mercury on AWS Bedrock and Azure AI Foundry. The University of Hong Kong's Dream 7B matched or surpassed top autoregressive models of the same scale on general, math, and coding tasks.
Text diffusion models went from academic papers to commercial deployment in two years.
But Google wrote a line in the DiffusionGemma documentation: "For applications that demand maximum quality, we recommend deploying standard Gemma 4."
Why would Google open-source a model it says isn't good enough?
That sentence contains the question this entire article seeks to answer: is text diffusion a genuine new paradigm, or just a speed-for-quality tradeoff?
Chapter 1: Why Diffusion Can Generate Text
To understand the difference between text diffusion and autoregressive generation, we need to start with a more fundamental question: what is generation actually doing?
The autoregressive answer is "guess one token at a time." Given a prefix, the model predicts the next token; it appends the prediction to the input and predicts the next one, and so on. At each step it can only see tokens to the left, and every decision is irreversible. Once a bad token is generated, there's no going back.
Image diffusion models take an entirely different approach. When Stable Diffusion generates an image, it doesn't start from the top-left corner and paint pixel by pixel. It starts with pure noise and iteratively denoises it — each pass makes the image slightly clearer, until the noise disappears and the image emerges.
Text diffusion borrows the same idea, but must solve one problem: text is discrete. You can add Gaussian noise to a pixel value (3.14 can become 3.67), but the token "hello" has no notion of noisy interpolation. You can't turn "hello" into "hel1o."
The solution for discrete diffusion is masking. The forward process randomly replaces tokens in a text with <mask> at a gradually increasing rate, from 0% to 100%, until the text becomes pure mask. The reverse process trains a model that, given the masked text, predicts what token originally occupied each <mask> position.
During actual generation, the process works like this:
- Initialize a 256-token "canvas," entirely filled with
<mask>. - The model runs one forward pass over the entire canvas, predicting what token should go in each position.
- The positions where the model is most confident are fixed; the rest are re-noised (re-masked).
- Repeat steps 2–3. Each iteration locks in more tokens.
- After 12–48 steps, all tokens are fixed. Generation is complete.
This process enables two things autoregressive models cannot do:
First, parallelism. All 256 tokens are generated simultaneously. There is no bottleneck where you must wait for one token to finish before starting the next. The bottleneck in autoregressive decoding is memory bandwidth: every token generation requires reading the entire model weights from VRAM into the compute units, but only one matrix multiplication is performed — the GPU's compute capacity sits largely idle. Diffusion models shift that bottleneck to compute: each step runs bidirectional attention across all 256 tokens at once, putting GPU compute to full use.
Second, bidirectionality. Every token can attend to all other tokens, including those to its right. This gives diffusion models a structural advantage on tasks that require global consistency — code infilling, inline editing, Sudoku. The causal attention of autoregressive models (looking only leftward) means they can never use future context to correct past output. A wrong token is a wrong token, permanently.
But this mechanism carries costs that autoregressive models don't have. The fixed block size means that even if you only want to generate 10 tokens, you still run the full 256-token denoising pipeline. Each step computes attention over the entire canvas — a 256×256 attention matrix — whereas autoregressive decoding only needs a single vector lookup per step. The "speed" of diffusion models comes from packing many small computations into a few large ones. That strategy has diminishing returns for short texts and high-QPS batched workloads.
Chapter 2: The Road Covered in Two Years
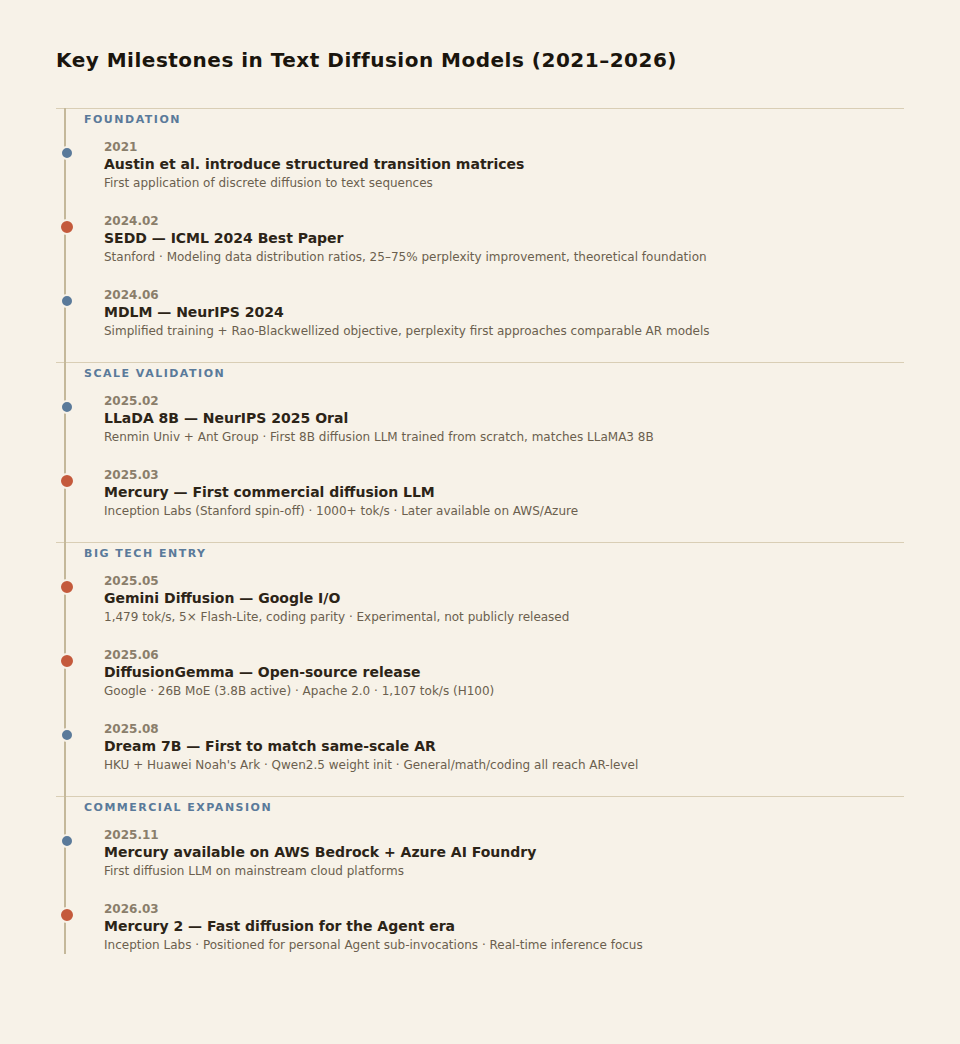
Text diffusion is not a new idea. As early as 2021, Austin et al. explored discrete diffusion using structured transition matrices. But going from academic curiosity to engineering viability took only two years.
SEDD (Score Entropy Discrete Diffusion) was the starting point. Stanford's Aaron Lou, Chenlin Meng, and Stefano Ermon published this work in 2024, winning Best Paper at ICML 2024. The core contribution was establishing the theoretical foundation for discrete diffusion by modeling the ratio of data distributions rather than absolute probabilities, eliminating intractable normalization constants. Perplexity improved 25–75% over prior methods.
SEDD proved that discrete diffusion was theoretically sound. But theoretically sound is not the same as engineering-ready.
MDLM (Masked Diffusion Language Models) followed at NeurIPS 2024. It simplified the training scheme and introduced a Rao-Blackwellized objective function — essentially a more efficient form of masked language modeling loss. MDLM set a new diffusion-model SOTA on language modeling benchmarks, with perplexity approaching that of same-scale autoregressive models for the first time.
LLaDA (Large Language Diffusion with mAsking) was the scaling proof. A joint effort by Renmin University of China and Ant Group, it was the first to train an 8B-parameter diffusion language model from scratch. The method was surprisingly simple: the forward process masks tokens at random ratios, and the reverse process uses a vanilla transformer to predict all masked positions. LLaDA performed comparably to LLaMA3 8B, showed competitive in-context learning, and even resolved the notorious "reversal curse" of autoregressive models (where training on "A is B" fails to generalize to "B is A").
LLaDA proved one thing: scaling diffusion models is not just theory on paper.
Mercury turned it into a product. Inception Labs (co-founded by Stefano Ermon out of Stanford) launched the first commercial-grade diffusion LLM in March 2025. Mercury Coder focused on code generation with inference speeds exceeding 1,000 tok/s. By November 2025 it was available on AWS Bedrock and Azure AI Foundry. In March 2026, Mercury 2 was released, positioned as "the fast diffusion model for the personal agent era."
Gemini Diffusion signaled big-tech entry. Debuted as an experimental model at Google I/O in May 2025, it ran at roughly 5× the speed of Gemini 2.0 Flash-Lite with comparable coding performance. Google DeepMind chief scientist Jack Rae called it a "landmark moment" for the field. But Google disclosed no technical details about Gemini Diffusion, did not open it for use, and only offered a waitlist.
DiffusionGemma brought it to open source. In June 2025, Google open-sourced DiffusionGemma, built on the Gemma 4 MoE architecture. 26B total parameters, 3.8B active parameters, Apache 2.0 license. Inference speed of 1,107 tok/s on H100 — 3.7× that of Gemma 4 26B. The core innovation was a dedicated Diffusion Head with adaptive early stopping: simple tasks complete in as few as 12 steps, complex tasks need at most 48.
Dream 7B was the quality catch-up. A joint project by the University of Hong Kong and Huawei Noah's Ark Lab, it initialized a diffusion model with Qwen2.5 7B's AR weights — not training from scratch, but "converting" an existing AR model into the diffusion paradigm. This was a breakthrough on two levels: training costs dropped dramatically, and output quality on general, math, and coding tasks matched or surpassed top AR models of the same scale. This was the first time a diffusion model achieved parity with same-class AR on quality.
Two years, from theory to product to open source. Unusually fast. But every step of progress exposed the same question: speed is here. What about quality?
Chapter 3: Beyond Speed — What Diffusion Actually Wins
If text diffusion were merely "a faster but worse autoregressive," the story wouldn't be very interesting. What makes it interesting is that diffusion can do several things that autoregressive models are structurally incapable of.
Code infilling. A developer writes half a function and needs AI to fill in the missing middle. Autoregressive models can only generate left-to-right. They either continue from the left edge of the gap (blind to the code constraints on the right), or regenerate the entire passage using both sides as context. Diffusion models natively support infilling at arbitrary positions: known tokens on the initial canvas stay fixed, and only masked positions get denoised. The Dream 7B paper explicitly demonstrates this capability.
Self-correction. Once an autoregressive model generates a token, it can never go back and change it. If the first half goes off track, the second half has to live with the mistake — or rely on external techniques like rejection sampling or best-of-N to compensate. Diffusion's iterative denoising inherently includes error correction: each step can revise the previous step's misjudgments, and the coherence of the entire text block improves as denoising steps increase. Google's description of DiffusionGemma puts it this way: "The model iteratively refines its own output, allowing it to evaluate the entire text block at once to fix mistakes in real time."
The reversal curse. An autoregressive model trained on "Paris is the capital of France" cannot reliably answer "What is France's capital?", because it has only learned left-to-right conditional probabilities. LLaDA's bidirectional attention lets the model see token relationships from both sides during training, structurally eliminating this problem. For knowledge tasks that require bidirectional reasoning, this is a genuine advantage.
Adjustable quality-speed tradeoff. An autoregressive model's inference speed is determined by output length; it is difficult to accelerate without degrading quality. Diffusion models have a "knob" that autoregressive lacks: denoising steps. Simple tasks (formatting, short-text completion) need as few as 12 steps; complex tasks (long-form generation, reasoning) can be dialed up to 48. Users can tune the latency-quality balance on demand.
But the applicable scenarios for these advantages are narrower than they appear. Code infilling and inline editing are real pain points, but they are not the primary workloads of LLMs. The vast majority of calls follow the pattern: "given a prompt, generate a long response." Self-correction is nice in principle, but if the model's underlying judgment is weak, no number of correction rounds will produce the right answer. The reversal curse is an academically interesting problem, but how much it improves real-world applications remains unsupported by data.
Core judgment: Diffusion models' unique advantages are real and structural, but they primarily serve specific scenarios rather than acting as a universal replacement.
Chapter 4: The Quality Gap
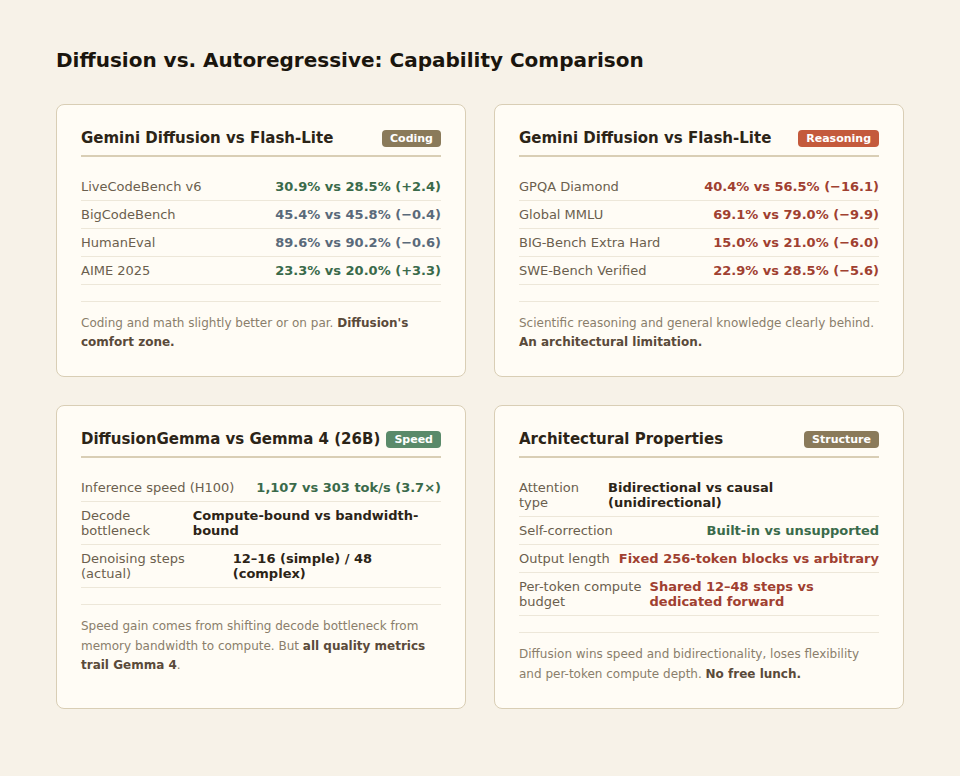
The benchmark comparison between Gemini Diffusion and Gemini 2.0 Flash-Lite is the most persuasive data available, because both come from Google, keeping test conditions relatively fair.
On coding tasks, Gemini Diffusion holds its own: LiveCodeBench 30.9% vs 28.5% (slightly ahead), BigCodeBench 45.4% vs 45.8% (par), HumanEval 89.6% vs 90.2% (par). Code generation is indeed diffusion's comfort zone.
But look at reasoning and knowledge tasks: GPQA Diamond 40.4% vs 56.5% (16 points behind), Global MMLU 69.1% vs 79.0% (10 points behind), BIG-Bench Extra Hard 15.0% vs 21.0% (6 points behind). These gaps cannot be closed through fine-tuning — they are architectural limitations.
DiffusionGemma tells a similar story. In Google's own comparison table, DiffusionGemma trails standard Gemma 4 across every benchmark: MMMLU, MMLU Pro, AIME 2026, LiveCodeBench v6, GPQA Diamond, and tau2-bench. Speed is 1,107 vs 303 tok/s, but quality falls behind across the board.
Why?
Every token an autoregressive model generates triggers a full forward pass through the model, with all layers and all attention heads participating in the computation. A 70B-parameter autoregressive model expends roughly 70B floating-point operations per generated token. Chain-of-thought reasoning works, at its core, precisely because it lets the model perform more computation across more tokens — a larger "thinking space."
A diffusion model denoising a 256-token canvas across 12–48 steps may seem like a substantial amount of computation. But these computations are parallel: each step applies attention to all 256 tokens simultaneously, meaning each individual token receives far less "thinking" than in the autoregressive case. An intuition: autoregressive gives each token a "dedicated" forward pass; diffusion gives 256 tokens "shared" access to 12–48 forward passes. When a task demands deep reasoning (as opposed to pattern matching), the compute budget per token may simply be insufficient.
This is not a problem that engineering optimization can solve. To improve diffusion models' reasoning quality, you either increase denoising steps (which erodes the speed advantage), scale up the model (which increases per-step compute cost), or change the architecture (e.g., hybrid AR + diffusion). Every option comes with a tradeoff.
Two additional practical issues:
Fixed-length generation. DiffusionGemma generates 256 tokens at a time. If the user needs 50 tokens, the remaining 206 are wasted. If they need 300, the model has to run two 256-token blocks — and how do you smoothly connect the tail of the first block with the head of the second? Autoregressive has no such problem: it generates on demand with fully flexible length.
High-QPS cloud deployment. Diffusion models shine in single-request, low-latency scenarios, but in cloud batch-processing environments, autoregressive KV caching and continuous batching techniques are already highly mature. Multiple requests can share GPU time slices, keeping utilization high. Diffusion models, which must attend to the entire canvas at every step, face much more complex memory overhead and compute scheduling when multiple requests run in parallel. Sean Goedecke's analysis notes that under high-QPS workloads, the parallel-decoding gains of diffusion models exhibit diminishing returns.
Core judgment: The reasoning quality gap is the biggest open question of 2026 for diffusion models. Dream 7B's results show the gap narrowing, but GPQA and BIG-Bench Extra Hard data indicate that deep reasoning remains diffusion's weak spot. If this gap persists into 2027, diffusion models will be downgraded from "paradigm contender" to "scenario-specialized tool."
Chapter 5: The Real Landscape of Three Routes
The 2026 frontier model architecture landscape isn't a two-horse race. It's three.
Autoregressive Transformers (GPT, Gemini, Llama, Claude) remain the default choice. Nearly a decade of iterative development has built the training pipelines, alignment methods (RLHF/DPO), and inference optimizations (KV cache, speculative decoding, continuous batching) around this paradigm. Scaling laws have been validated through training runs on hundreds of billions of tokens. The ecosystem moat is formidable.
But AR has two structural bottlenecks. Inference is memory-bandwidth bound: every generated token requires reading the full model weights from VRAM into compute units, while the actual computation is minimal. Under long contexts, KV cache bloats severely—a 128K context can require several gigabytes of KV cache storage. Both bottlenecks intensify as models grow larger and contexts grow longer.
Text diffusion models (DiffusionGemma, Mercury, Dream) bypass AR's inference bottleneck through parallel generation. The speed gains are real—4–10× over comparable AR models. But so is the quality gap, particularly on deep reasoning tasks. Diffusion proponents argue that reasoning capability can be recovered through more denoising steps and larger models, while critics counter that parallel generation inherently allocates insufficient compute per token—an architectural ceiling.
SSM/hybrid architectures (Mamba, Nemotron-H, Bamba, Phi-4-mini-flash) take a third path. State space models replace attention's quadratic complexity with linear time complexity, dramatically improving long-context efficiency. NVIDIA's Nemotron-H replaces 92% of attention layers with Mamba2, achieving 3× throughput with no accuracy loss. IBM's Bamba 9B matches LLaMA-3.1-8B using 7× less data. Microsoft's Phi-4-mini-flash uses the SambaY architecture to achieve 10× throughput gains.
SSM's limitation is that reasoning capability falls short of pure Transformers. Mamba author Albert Gu's own analysis notes: SSM hidden state dimensions need to be larger than input/output dimensions. For information-dense language modalities, the model needs a sufficiently large state to store information required for later access. Pure SSMs underperform attention on complex relational reasoning—which is why all practical hybrid designs retain some attention layers. Nemotron-H keeps 8%; Bamba uses a hybrid block design.
Each route's advantage scenarios are clear:
| Scenario | Optimal Route | Reason |
|---|---|---|
| Deep reasoning / complex analysis | AR Transformer | Most compute per token, deepest thinking space |
| Code completion / inline editing | Diffusion | Bidirectional attention + parallel generation + self-correction |
| Long-context processing | SSM/hybrid | Linear complexity, no KV cache bloat |
| High-QPS cloud serving | AR + batching optimizations | KV cache reuse, mature continuous batching |
| Agent sub-invocations (low latency) | Diffusion | Latency multiplier effect, completes in 12 steps |
| General dialogue (quality-first) | AR Transformer | Quality benchmark |
The 2026 landscape isn't about "who wins"—it's about a clear trend toward hybridization: AR + diffusion (PLANNER uses diffusion for high-level planning, AR for token decoding), SSM + Transformer (Nemotron-H replaces most attention with Mamba2), and even diffusion + SSM (DiffuMamba uses bidirectional Mamba for diffusion denoising). Once the three paradigms validate in their respective sweet spots, they will ultimately converge into a single model architecture.
Stefano Ermon predicts that "within a few years, all frontier models will use diffusion." Nathan Lambert (AI2) is more measured: "It's the biggest endorsement yet of the model, but we have no details so can't compare well." Google entering the space is good news, but without details, conclusions are premature.
The 2026 reality: all three routes are iterating rapidly. None has been proven a dead end, and none has become the consensus optimal choice.

Chapter 6: Where It Wins First
Diffusion models won't replace autoregression. But they will become the preferred choice in specific scenarios first.
Code generation is the most certain use case. Mercury Coder is already commercially available on AWS and Azure. Code has strong structural constraints (syntax, type systems), demands rapid iteration (autocomplete, apply-edit), and is naturally suited to diffusion's parallel generation and self-correction. Inception Labs claims Mercury Coder's Apply-Edit capability "far exceeds leading models"—a claim that needs independent verification—but the product-market fit for code scenarios is clear.
Agent sub-invocations are the second high-potential scenario. A single agent task may require 5–20 LLM calls, and each call's latency is multiplied 5–20×. Switching each call from a 300 tok/s AR model to a 1,100 tok/s diffusion model could reduce overall response time by 60–70%. Mercury 2 was positioned at launch as "a fast diffusion model for the personal Agent era."
Drug discovery and bioinformatics are third. Amino acid sequences and protein structures aren't natural language—they don't require left-to-right logic. They're better suited to bidirectional modeling: an amino acid's properties depend on its position within the entire sequence, not just the sequence to its left. DiffusionGemma's documentation already points to this direction.
Real-time conversation is theoretically attractive—low latency is critical for user experience. But deployment challenges are substantial: output length is highly unpredictable, and diffusion's fixed block sizes waste compute; high-concurrency real-time dialogue services require batching optimizations where diffusion's maturity falls far short of AR. A near-term breakthrough is unlikely.
Guotai Haitong Securities' July 2025 research report got it right: "dLLMs will not completely replace AR models, but rather complement them, together forming a more diverse and prosperous AI technology ecosystem." Its positioning is more like ASICs within the GPU ecosystem—GPUs for general compute, specialized chips for specific tasks.
Practical advice for developers: if your workload involves code assistance, agent sub-invocations, or structured generation requiring rapid iteration, diffusion models are worth testing. If your workload involves complex reasoning, long-document analysis, or general dialogue demanding the highest quality, autoregressive models remain the better choice. Don't chase paradigms—choose models based on scenarios.
Closing Thoughts
Google's strategy is the best footnote to this entire story. The Gemini flagship series remains autoregressive. Gemini Diffusion is an experimental project. DiffusionGemma is an open-source exploration. Google hasn't placed diffusion on the main line—it's placed diffusion on a side track for validation. If it succeeds, it gets integrated; if it doesn't, the core business is unaffected.
This strategy is very Google: they used the same playbook in the search era (Google+, Glass, Wave—explore broadly, let the few survivors stick). Whether text diffusion can become a mainline technology depends on a question that can only be answered in 2027: can its reasoning quality catch up with autoregression?
Google DeepMind's Sander Dieleman wrote a blog post in 2023 whose title itself poses the right question: "Diffusion models have completely taken over generative modelling of perceptual signals — why is autoregression still the name of the game for language modelling? And can we do anything about that?"
Diffusion has already taken over images and video. Text is the last stronghold. The progress of 2024–2026 suggests this stronghold may not be monolithic—but to say it has been breached would be premature.
Disclosure: This article is based on publicly available information, drawing on Google's official blog and developer documentation, Google DeepMind product pages, Inception Labs' website and blog, HuggingFace blog posts, The Decoder, Fortune, technical analysis by Sean Goedecke, Guotai Haitong Securities research, and papers including SEDD (ICML 2024), MDLM (NeurIPS 2024), LLaDA (NeurIPS 2025), Dream 7B, Mercury, and DiffuMamba. This article does not constitute investment advice. Data current as of June 11, 2026.