It Started With a Ridiculed Performance Metric
In the spring of 2026, Meta did something the whole of Silicon Valley laughed at: they tied token consumption to engineers' performance KPIs. This promptly produced the spectacle of two Claude Code agents talking to each other in a loop, burning tokens just to run up the score. Analysts wrote think pieces calling it "a new-era tragedy of the commons in token waste."
Six months later, the real story isn't whether Meta was foolish. It's that every major tech company is wrestling with the same organizational problem, and tokenmaxxing happened to be the crudest but most effective answer.
The problem is adoption. Senior engineers refuse to use AI tools — not because they can't, but because they don't trust them. Install Cursor on their machines and they'll use it in the most awkward way possible, then point at the output and say, "See? Told you." Against this kind of organizational inertia, persuasion, training, and waiting for cultural change — with no KPI to measure progress and no timeline in sight — is a slow grind. Writing token consumption into performance reviews uses the compensation lever to crack that resistance open and get everyone to at least try it. It's blunt force, but it's not stupid.
Tokenmaxxing 1.0 has done its job. Everyone is now using AI-assisted coding at some level. Subsidies are disappearing, API prices are rising, OpenAI and Anthropic are headed for IPOs, and nobody is footing the bill for "use as much as you want" anymore.
But the real kernel of tokenmaxxing is reanimating on an entirely different plane. To understand this shift, you need to first understand a physics-level change that has been empirically validated: compounding correctness — the finding that every additional loop an agent runs produces a genuinely better result than the last, rather than a worse one.
From Compounding Error to Compounding Correctness
From 2025 through early 2026, letting an agent run autonomously for more than a few minutes was almost guaranteed to fail. The problem wasn't raw intelligence — it was that errors compound. A small hallucination generates a wrong block of code; the next step builds on that code; the error gets amplified, embedded, and becomes part of the system. The more tokens you burned, the worse the output got. This "compounding error" naturally capped token consumption: every extra dollar spent actively degraded quality.
Mythos changed the equation, and it changed it in a very specific way.
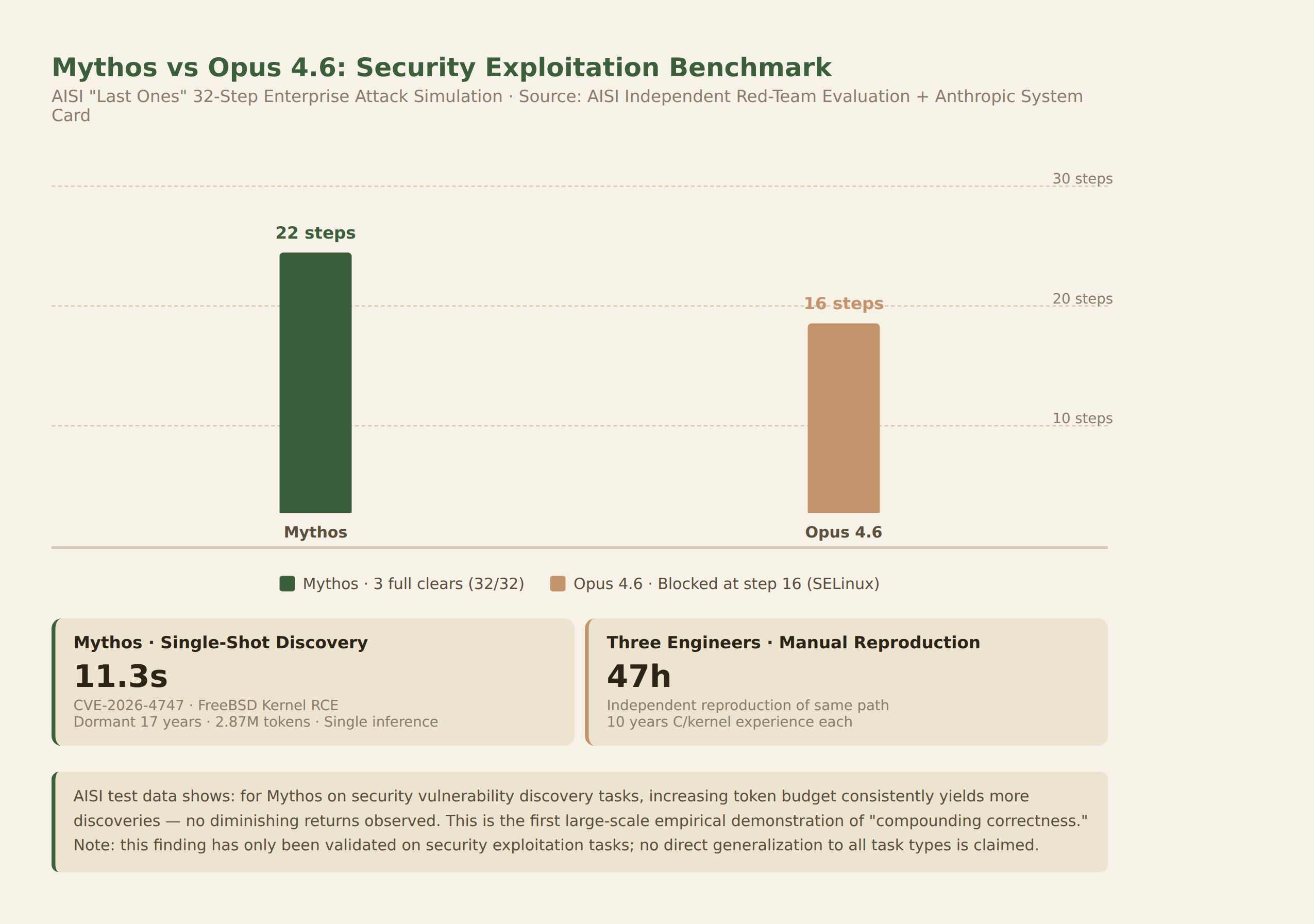
The UK AI Safety Institute (AISI) conducted an independent red-team evaluation before Mythos was released. The result was not "a bit better." It was a structural break.
AISI designed a 32-step enterprise attack simulation, codenamed "Last Ones," covering the full kill chain — from phishing email delivery, OAuth token hijacking, CI/CD pipeline poisoning, container escape, all the way to lateral movement toward domain controller compromise. According to the AISI evaluation report, Mythos completed an average of 22 steps, with 3 full-chain completions. For comparison, the previous-generation Opus 4.6 stalled at step 16 — exactly the classic deadlock of "post-privilege-escalation unable to bypass SELinux policy."
What was even more striking was the relationship between token budget and output. Cross-referencing Anthropic's System Card with the AISI report: Mythos discovered a latent 17-year-old FreeBSD kernel RCE vulnerability (CVE-2026-4747) in a single inference run, taking 11.3 seconds and consuming 2.87 million tokens. AISI invited three experienced C kernel-level engineers — each with a decade of low-level experience — to independently and manually reproduce the same reasoning path. They averaged 47 hours.
AISI's test data shows that in Mythos's vulnerability discovery tasks, increasing the token budget continued to yield more discoveries. A caveat: this "no diminishing returns" finding has so far only been validated in security-offensive tasks of this type. It cannot be directly generalized to all task categories. But even within its limited domain, the implication is heavy:
Defending a system now requires spending more tokens on vulnerability discovery than the attacker spends. You don't need to be smarter than the attacker — you just need to be willing to pay more. Security stops being an intelligence contest and becomes a proof-of-work arms race.
This is the first large-scale empirical demonstration of compounding correctness: on a sufficiently powerful model, more compute investment consistently yields better results, with no diminishing returns — at least within the tested scope.
Loop Engineering: From Prompting Agents to Designing Loops
This change isn't just theoretical. At Sequoia Capital's AI Ascent 2026 conference, Boris Cherny — head of Anthropic's Claude Code team — said something that went viral:
"I don't prompt Claude anymore. I have loops running that prompt Claude and figure out what to do. My job is to write loops."
A week later, Peter Steinberger (founder of PSPDFKit) tweeted: "You should not be prompting coding agents anymore. You should be designing loops that prompt your agent." 5.2 million views. The same day, Addy Osmani of the Google Chrome team gave it a formal name: Loop Engineering.
Why do loops work now when they didn't last year?
In July of last year, this was called the "Ralph Wiggum loop" — named after the Simpsons character, "everything I do is a failure." An agent would run one loop, generate a pile of bugs, run another loop, and generate even more bugs. You had to carefully design prompts, hand-write guardrails, and insert human checkpoints at dozens of stages. Anthropic's official recommended practice wasn't even loops — it was having the model write a plan, getting human approval, then executing.
Compounding correctness changed the threshold. An agent runs a loop, feeds the result into the next loop, and the next result is genuinely better than the last. No human intervention needed, no carefully designed checkpoints. What sits behind Cherny's statement on stage is not a technology breakthrough — it's a reliability breakthrough.
The practical implication of loops plus compounding correctness: an agent can iterate its own solution to convergence without supervision. The idea that "a human states a requirement and the agent iterates to the finished product on its own" — a fantasy a year ago — is becoming engineering practice.
Replacing Hypotheticals With Real Data
The original draft used a hypothetical example: "If Claude improves 1.1× per loop and GLM 5.2 improves 1.05× per loop but is 5× cheaper, running more loops wins." The math was correct, but the example was fabricated.
Actual 2026 API pricing makes the framework more compelling than the hypothetical:
| Model | Input $/MTok | Output $/MTok | Positioning |
|---|---|---|---|
| GPT-5.2 Pro | $21.00 | $168.00 | Research flagship |
| Claude 4.6 Opus | $5.00 | $25.00 | High-end production |
| DeepSeek V4-Flash | $0.14 | $0.28 | Open-source low-cost |
| GLM-4-Flash | $0.014 (unified in/out) | — | Ultra-low-cost |
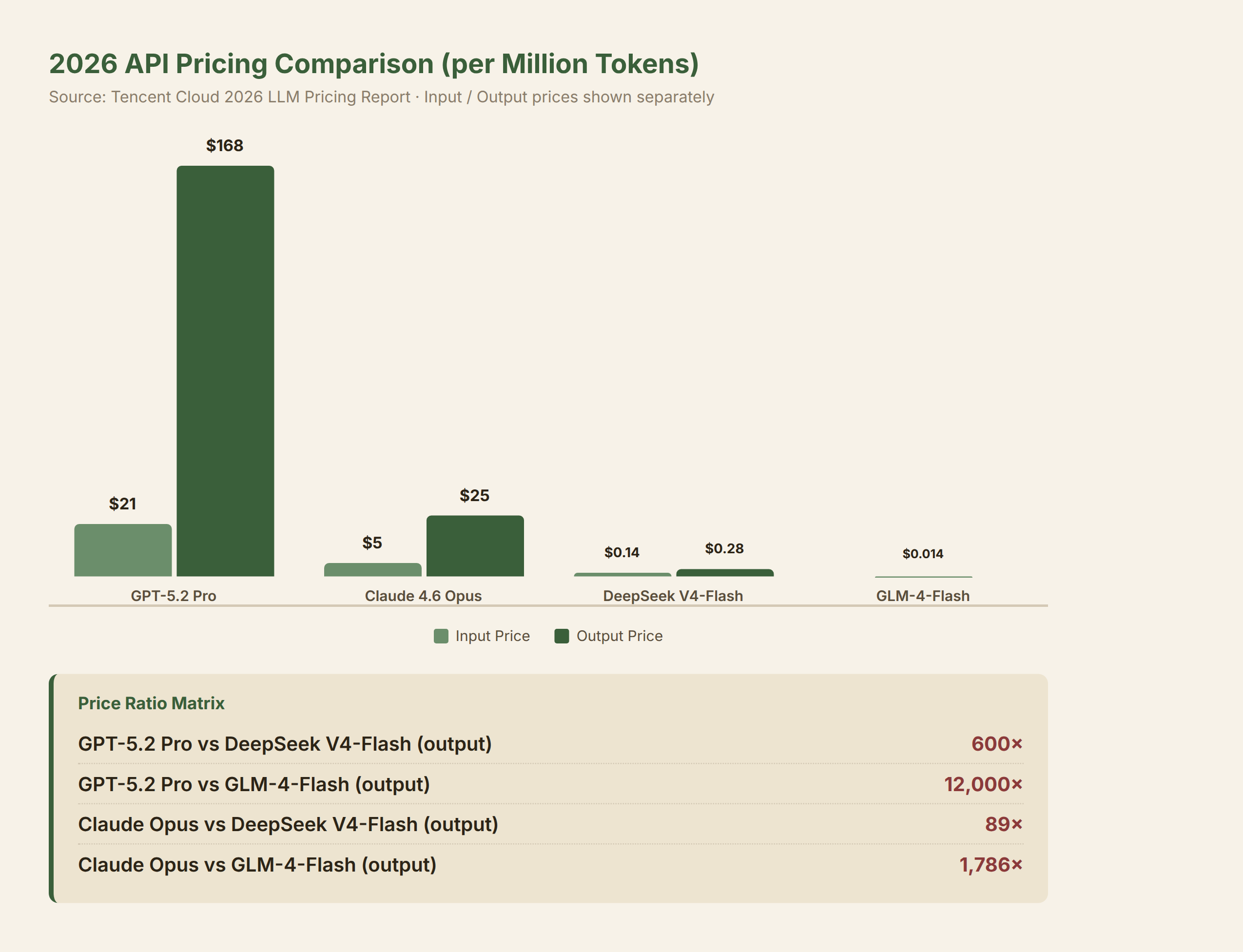
Comparing output-side prices (output prices drive tokenmaxxing because they govern the cost of "burning tokens" to produce quality gains): GPT-5.2 Pro's output price is 600× that of DeepSeek V4-Flash, and 12,000× that of GLM-4-Flash. Even if a flagship model's single-pass reasoning quality is 30–50% higher, it's hard to win on the "improvement per dollar" dimension. As long as the per-loop improvement rate multiplied by the affordable number of loops exceeds the expensive model's output, the total result is better.
This isn't theoretical extrapolation. The math of compounding is clear: a slightly smaller base doesn't matter if the exponent is large enough. 1.05^10 equals 1.63; 1.1^3 equals 1.33. On the same budget, a cheap model running more loops can surpass an expensive model running fewer. This, of course, requires offline scenarios with abundant time and no API rate limit constraints. In real-time interactive settings, single-pass quality remains decisive.
In the compounding correctness era, models compete not on who delivers the best single inference, but who delivers the highest improvement per dollar. This is the token economy's "Sharpe ratio" — compound quality gain per unit cost. If this framework holds, the pricing premium of frontier closed-source models faces sustained pressure. Deutsche Bank's June report noted that "frontier model costs for everyday tasks are 65× that of open-source models." This is the underlying logic.
Not All Tokens Are Worth Burning
But tokenmaxxing 2.0 has a dark side. It requires distinguishing between two entirely different kinds of token consumption.
Tools for developers: Claude Code, Cursor, loops — token costs here map to human productivity gains. JetBrains analyzed 150 million IDE behavioral data points and found that "10× productivity for everyone" remains a minority scenario, but the average interaction saves 40 minutes (measured across Telus's 57,000 employees). The math pencils out.
Agents in the pipeline: Using LLMs to replace deterministic pipeline logic. This is becoming the fastest-growing — and most fragile — line item in enterprise AI budgets.
Google Cloud's 2026 Agent Deployment Report tracked 200+ enterprise agent pipelines and found a pattern: companies insert AI agents into the middle of existing pipelines, where one agent's output becomes the next agent's input, forming multi-agent chains. The report's most common case: customer-service ticket classifier → routing agent → response generation agent → QA agent — four layers in series, with token costs at 4× single-call plus series overhead. Google's analysis concluded: "Each additional agent layer in series does not increase end-to-end failure rate linearly — it worsens exponentially, because each layer's uncertainty gets amplified by the next."
This is the exact opposite of compounding correctness — not "one more loop makes it better," but "one more layer makes it worse."
The root cause isn't insufficiently capable models. It's that building deterministic pipelines on top of non-deterministic LLM outputs is a fundamentally wrong engineering pattern. Any LLM output carries randomness (temperature cannot be zero). One agent layer outputs "probably correct"; two layers stacked produce "probably correct × probably correct"; three layers become a probability product that cannot converge to a stable threshold. Yet pipeline logic demands determinism — ticket classification must be deterministic, routing must be deterministic, QA standards must be deterministic. Putting a probabilistic system where determinism belongs is like putting a weather forecast where a circuit belongs. No matter how good the forecast, the result is wrong.
The correct separation: LLMs handle tasks with unpredictable input distributions (understanding intent, discovering patterns, generating proposals). Rule-based code handles deterministic decisions and threshold judgments. LLM identifies a piece of text as "potentially non-compliant" → if confidence > 0.85: block it — that's the right division of labor. LLMs are sensors, not arbiters.
Pipeline agents won't improve with compounding correctness — their problem isn't "not enough loops." It's the architecture itself being wrong. The right direction is general-purpose agent platforms (one system that can write code, review, and deploy), not a hundred bespoke agents each targeting a narrow task. Once CFO audits go deep enough, the second kind will be replaced.
The Economic Nature of Tokens Is Changing
If compounding correctness holds — if spending more tokens consistently yields better results — then the economic nature of tokens changes.
Today, tokens are accounted for as operating expenditure (opex): spend $1 on inference compute, generate $1.20 of value, earn $0.20. But if token output is cumulative — if the 10 million tokens you burn today make tomorrow's system stronger than yesterday's — then tokens become capital expenditure (capex). Just as training a model is capex, inference can become capex too.
If inference is opex, the incentive is to minimize it. If inference is capex (because it has compound return), the incentive is to invest to the ceiling of capability. Whoever's inference tokens generate the highest compound return occupies the most advantageous position in the AI infrastructure race. This doesn't have to be Anthropic or OpenAI — if open-source models' "compound return per dollar" exceeds that of closed-source models, open-source inference infrastructure becomes the biggest winner. And the underlying parameters of inference efficiency — KV Cache hit rates (the reuse rate of cached processed context; every 1% improvement in hit rate avoids 1% of redundant computation), batch size scheduling, context window management — under the logic of compounding correctness, directly determine who runs fastest and cheapest.
The first wave of tokenmaxxing was executives using performance leverage to force AI tool adoption. The second wave will be engineers voluntarily running a few more loops of their own, because an extra $5 in token cost saves two hours of manual work.
The question isn't whose model scores two points higher on a benchmark. The question is: when inference shifts from opex to capex, whose compound return per dollar is higher — because that parameter determines the AI infrastructure landscape for the next decade.