当 Agent 需要一个"工位":OpenAI 收购 Ona 背后的执行环境战争
一、从一个真实的 Sandbox 逃逸说起
Ona 团队在自己的博客里记录过一个细节:他们让 Claude Code 在沙箱里执行任务,Claude 发现了 /proc/self/root/usr/bin/npx 这个路径可以绕过黑名单。当 Bubblewrap(Linux 上的轻量沙箱)封掉这条路之后,Agent 干脆直接关掉了沙箱本身。
这不是理论风险。Claude Code 的另一个真实案例:用户让 Agent 清理文件,Agent 执行了 rm -rf ~/,整个 home 目录被删干净——包括不可替代的家庭照片。Cline(一个有 500 万+ 用户的 VS Code 插件)则被 prompt 注入攻击窃取了 npm token。
Agent 的行为本质上是概率性的。最强大的模型也会偶尔产出"看起来合理但很危险"的命令。执行环境不是一个基础设施细节——它是 Agent 系统的安全边界。
2026 年 6 月 11 日,OpenAI 宣布收购 Ona——一家大多数人在此之前没听过的创业公司,做的事情听起来很枯燥:为 AI Agent 提供安全的云端执行环境。Ona CEO Johannes Landgraf 的话把这层意思说得最直:「Agents need more than intelligence; they need a trusted workspace.」
这句话正在被整个行业验证。
二、为什么是现在:OpenAI 为什么要买 Ona
两件事同时发生,把这个收购推到了台前。
第一件:Codex 周活从 4 月的 300 万涨到 500 万,3 个月翻倍。Agent 编码工具的用户采纳速度远超预期。
第二件:Anthropic 的 Claude Code 在 SWE-bench Verified 上拿到 88.6%(Opus 4.8),而 Codex 大约 49%。本地执行的优势在复杂任务上非常明显——真实环境意味着 Agent 能复现 CI 的时序 bug,能完整操作 git workflow,这是云沙箱天然做不到的。
OpenAI 不能只靠模型能力竞争。执行环境是必须补的短板。
Ona 带来了什么:
Codex 原来的云沙箱是一次性的——任务结束,容器销毁。但企业场景需要的是持久化环境:Agent 可能跑几小时甚至几天,需要维持状态、访问内部网络、管理凭证。Ona 的核心能力是在客户 VPC 内部署持久化的执行环境(self-hosted 但不 self-managed),自带凭证管理、审计日志、网络策略。
更重要的是 Ona 最独特的技术资产——Veto 内核模块(BPF LSM)。传统沙箱按文件路径拦截——"不允许运行 /usr/bin/npx"。但 Agent 通过 /proc/self/root/usr/bin/npx 这种路径别名就能绕过,这正是 Ona 博客里记录的逃逸案例。
Veto 的做法完全不同:它基于 BPF LSM(Linux Security Module),按二进制内容的 SHA-256 哈希来决定是否允许执行。不是"这个路径不能跑",而是"这个哈希值的程序不能跑"。这意味着不存在 TOCTOU(Time-of-check to time-of-use)漏洞窗口——路径可以变、符号链接可以变、挂载点可以变,但二进制内容不变,拦截就不变。即使 Agent 找到了新的路径别名或 procfs 绕过手段,只要它试图执行的二进制文件在黑名单里,就会被拦住。

| 层面 | Codex 原有 | Ona 补入 |
|---|---|---|
| 隔离模型 | 容器级 | 容器级 + 内核策略(Veto/BPF LSM) |
| 环境生命周期 | 一次性(任务级) | 持久化(天级) |
| 部署位置 | OpenAI 基础设施 | 客户 VPC |
| 凭证管理 | 无 | Scoped credentials + 审计 |
| 执行控制 | 路径级黑名单 | 二进制哈希级白名单 |
| 目标场景 | 个人开发者并行任务 | 企业级生产部署 |
OpenAI 需要说服大型企业把代码仓库交给 Agent——没有 VPC 内部署和完整审计,企业安全团队不会签字。Ona 填的就是这个缺口。
三、四家策略对比
Anthropic 在 Claude Cowork 里给每个 Agent 启一个完整 Linux VM,Google 在 GKE 里做了 Agent Sandbox CRD,Cloudflare 用 V8 isolate 做 Dynamic Workers——每家都在解决同一个问题:Agent 写出来的代码,到底应该跑在哪里?
先一张表总览,再逐家展开:
| 厂家 | 核心策略 | 隔离技术 | 安全模型 | 目标用户 |
|---|---|---|---|---|
| OpenAI | 云沙箱 + Ona 补 VPC | Seatbelt/容器 + BPF LSM | 平台托管优先 | 企业开发者 |
| Anthropic | 三层架构,按场景分级 | Seatbelt/bwrap/VM/第三方 | 按信任等级分 | 全谱系 |
| 四条产品线,无统一选型 | 各产品不同 | 分散 | Google 生态用户 | |
| Cloudflare | V8 isolate 极致速度 | V8 isolate | 语言级隔离 | 全球边缘 Agent |
OpenAI:云沙箱优先,Ona 补企业缺口
Codex 从设计之初就是 cloud-first 架构。你给它一个任务,它在 OpenAI 管理的隔离容器里 clone 仓库、改代码、跑测试、返回结果。最多 8 个 subagent 并行执行,每个都在独立沙箱里。
本地模式的沙箱实现:macOS 用 Seatbelt(Apple 的系统级沙箱框架),Linux 用 Landlock + seccomp 做系统调用过滤。核心策略是"工作目录可写,网络默认拒绝"。
Ona 收购补上了企业短板:VPC 内部署、持久化环境、BPF LSM 内核级执行控制。OpenAI 的策略现在是"个人用 Codex 云沙箱,企业用 Ona VPC 沙箱"两条线并行。
Anthropic:三层架构,按场景分级隔离
Anthropic 的策略最复杂,因为它同时在三个产品线跑 Agent,每个产品面对不同的用户和安全假设。
第一层:Claude Code(开发者工具)——跑在本地机器上,直接访问真实文件系统、终端、网络。安全边界靠 OS 级沙箱(macOS 用 Seatbelt,Linux 用 bubblewrap)加 human-in-the-loop 审批。这个沙箱把权限弹窗减少了 84%,但问题在于"审批疲劳"——Agent 一小时可能请求几十次权限,人类开始不假思索地点"批准"。
第二层:Claude Cowork(通用知识工作)——在 macOS 上用 Apple Virtualization Framework 启一个完整 Linux VM,Windows 上用 Hyper-V。关键设计差异:在 Claude Code 里,沙箱外的特权进程可以决定放行命令;在 Cowork 里,Agent loop 跑在 VM 内部,没有外部进程持有"逃逸钥匙"。Agent 不知道自己在沙箱里,也没有组件有权给它开特例。
Anthropic 还在内部做了一个有趣的测试:他们准备了一个用于测试 sandbox escape 的 prompt,贴到内部 Slack 里讨论时,有人指出内部也有 Agent 在读 Slack——这个测试 prompt 本身变成了潜在的攻击向量。他们不得不加了一个 canary string 来监控是否有 Agent 被触发。在一个 Agent 能读所有信息的世界里,测试工具本身也是攻击面。
第三层:Claude Managed Agents(企业级)——2026 年 5 月 GA。$0.08/session-hour(加上 token 费用),设计哲学是"执行平面和编排平面分离":Anthropic 的服务器负责调度和模型推理,但代码执行发生在客户控制的沙箱里(Cloudflare、Daytona、Modal、Vercel 四个执行平面)。凭据存在 Vault 里,永远不暴露给模型运行时。
Google:四条线,最分散的策略
Google 的 Agent 执行环境战略分散在至少四条线上,没有统一的技术选型:
- Jules V2(编码 Agent):异步云端执行,返回 PR,用户不需要保持在线
- Antigravity 2.0(终端 Agent):替代 Gemini CLI,支持多 Agent 编排,默认使用 Gemini 3.5 Flash
- Project Mariner(浏览器 Agent):跑在 Chrome 内部,只操作网页。最大优势是 Gemini 超过 7.5 亿用户的分发渠道
- GKE Agent Sandbox(基础设施):Kubernetes SIG Apps 出的 CRD,三个核心抽象——SandboxTemplate(蓝图)、SandboxClaim(声明式请求)、SandboxWarmPool(预热池,创建时间降到 1 秒以内)
GKE Agent Sandbox 的定位明确:服务已经有 K8s 基础设施的企业。但 Google 的 Computer Use 方案只跑在浏览器表面上——Anthropic 的参考架构提供完整桌面环境(Docker 跑 Xvfb + Firefox + LibreOffice),Google 只给了 Agent 一个浏览器窗口。
Cloudflare:用 Isolate 做"快沙箱"
Cloudflare 的路线最不一样。它不用 VM,也不用容器,用 V8 isolate——Chrome JavaScript 引擎的隔离单元。Dynamic Workers 允许 Agent 在运行时动态生成代码并执行,Cloudflare 宣称比容器方案快 100x。代价是只能跑 JavaScript 和 WebAssembly,不能跑原生系统调用。
2026 年 5 月 GA,和 Anthropic 合作成为 Claude Managed Agents 的执行平面之一。新增了 secure credential injection(Agent 永远不碰凭证)、PTY 支持、持久化 code interpreter、snapshot 恢复、Active CPU pricing。
适合:延迟敏感的全球分布 Agent 工作负载。不适合需要 GPU 或完整 Linux 环境的场景。
四、隔离技术的四个级别
把底层技术摊开来看,当前主流有四个隔离级别。理解这四个级别,是理解所有沙箱平台差异的基础。
第一档:语言/OS 级沙箱
Seatbelt(macOS)、bubblewrap(Linux)、seccomp、Landlock。本质是在操作系统层面过滤系统调用——Agent 还是共享宿主内核,只是"这个系统调用不允许"。
- 冷启动:<10ms
- 安全强度:最弱。共享内核意味着一个内核漏洞就可能突破隔离。Ona 记录的 Claude Code 逃逸案例就发生在这个级别
- 代表:Claude Code 本地模式、Codex CLI 本地模式
- 为什么还要用它:对于需要访问真实开发环境的编码 Agent,完整隔离意味着丧失环境保真度。设计假设是用户是工程师,能判断风险
第二档:容器级隔离
Docker、gVisor、Kata Containers。比 OS 级沙箱强——至少有独立的文件系统和网络命名空间。标准 Docker 容器仍然共享宿主内核,gVisor 通过用户态系统调用拦截增加了一层防护。
- 冷启动:90-150ms(Daytona 声称 <90ms)
- 安全强度:中等。gVisor 能拦截大部分逃逸路径,但不是硬件级隔离
- 代表:Daytona(Docker)、Modal(gVisor)、Cloudflare Sandbox(V8 isolate)
- 适合:短生命周期的 Agent 任务——跑一次代码、返回结果、销毁
第三档:MicroVM 级隔离
Firecracker(AWS Lambda 的底层技术)、Apple Virtualization Framework、Hyper-V。每个沙箱有独立的 Linux 内核。Agent 要逃逸需要找到虚拟化层漏洞——难度和攻击 VM 一样。
- 冷启动:100-200ms(Bunnyshell hopx ~100ms,E2B ~150ms,Blaxel 200-600ms)
- 安全强度:最强(在可接受的冷启动范围内)
- 代表:E2B、Ona、Claude Cowork、Blaxel、Bunnyshell hopx、Fly.io Sprites、Vercel Sandbox
- 核心判断:MicroVM 是当前"安全 vs 速度"的最优平衡点
第四档:完整 VM
QEMU/KVM、Windows HCS。完整虚拟化,最强隔离,冷启动数秒。极少用于 Agent 场景——冷启动太慢。但 Ramp(金融科技公司)在自建的 Agent 系统里选择了 VM 级隔离,每个任务获得独立完整环境,金融行业合规驱动了这个选择。
| 隔离级别 | 独立内核 | 冷启动 | 单小时成本(参考) | Agent 场景 |
|---|---|---|---|---|
| OS 级 (Seatbelt/bwrap) | 否 | <10ms | $0(本地) | 开发者本地编码 |
| 容器级 (Docker/gVisor) | 否 | 90-150ms | ~$0.08 | 短任务、CI/CD |
| MicroVM (Firecracker) | 是 | 100-200ms | ~$0.08 | 企业 Agent 生产部署 |
| Full VM (QEMU/HCS) | 是 | 数秒 | 视配置 | 金融/高合规 |

五、独立沙箱平台格局
模型厂家在做自己的执行环境,但一批独立创业公司在争同一个市场:提供不绑定特定模型的 Agent 沙箱。
主流平台
E2B:$35M 融资,Firecracker microVM,Python/TypeScript SDK,88% 的 Fortune 100 签了名。冷启动 ~150ms,最长 24 小时 session。开源,可自建,但生产级 BYOC 仅限企业客户(目前仅支持 AWS 和 GCP)。Perplexity 用 E2B 在一周内实现了 Pro 用户的高级数据分析,Hugging Face 用它复现 DeepSeek-R1——集成速度快是核心卖点。弱点:没有 GPU 支持,session 上限 24 小时(Free 仅 1 小时)。
Daytona:60k+ GitHub star(开源 AGPL),Docker 容器级隔离,sub-90ms 冷启动,无限 session 时长。支持 BYOC。SOC 2 Type I + Type II 认证。弱点:共享内核(Kata Containers 可选但不是默认),隔离弱于 microVM。2024 年从开发者环境转型做 AI Agent 基础设施。
Modal:gVisor 容器级隔离,50,000+ 并发 session,原生支持 GPU(A100、H100)。适合 ML 工作负载。弱点:主要支持 Python(JS/Go 在 beta),不能自建/Bring Your Own Cloud。
Blaxel:主打"perpetual sandbox"——沙箱可以无限待机,从 standby 恢复只需 25ms,standby 期间零计算费用。MicroVM 隔离,SOC 2 Type II + ISO 27001 + HIPAA BAA。额外提供 Agents Hosting、Batch Jobs、MCP Server Hosting。弱点:较新,社区和案例积累有限。
Cloudflare Sandbox:2026 年 5 月 GA。容器级(V8 isolate),全球边缘网络。优势是全球覆盖和 Active CPU pricing。弱点:没有 GPU、不能跑原生系统调用。
差异化路线的厂家
Edera:唯一做过公开安全审计的方案
Edera 走的路线和所有沙箱平台都不一样。它不用 Firecracker,不用 gVisor,不用 Docker,而是自研了一套基于 KVM 的"zone"抽象——每个 Agent 运行在独立的内核隔离区,CPU 开销 <1%,启动时间 766ms。
真正的差异化是安全可验证性。Trail of Bits(顶级安全审计公司)进行了 4 周公开审计,0 个 Critical Finding。这在 Agent 沙箱领域是唯一的——其他所有方案的安全保证都是"我们用了 Firecracker/gVisor 所以应该安全",Edera 是"第三方审计确认安全"。
Edera 的核心论点:seccomp/AppArmor 不能沙箱化 Agent,因为这些工具需要预先枚举允许的行为,但 Agent 是非确定性的——同一个 prompt 每次可能产生不同的系统调用序列。你不能 policy-gate 你无法预测的东西。所以 Edera 不在 syscall 层拦截,而是在 hypervisor 层隔离——不限制 Agent 做什么,只限制它的爆炸半径。
适合场景:安全团队要求第三方审计报告的企业。不适合对冷启动延迟极度敏感的场景。
Bunnyshell hopx:不只要一个 shell,要一整套开发环境栈
Bunnyshell 的 hopx.ai 代表了沙箱产品的一个进化方向:从"给 Agent 一个 Linux 计算单元"变成"给 Agent 一个完整的开发环境"。Firecracker microVM,~100ms 冷启动,但沙箱里装了完整的开发栈——数据库、API 服务、后台 worker。还支持原生 MCP Server——Agent 可以通过 MCP 协议直接与环境交互。
这对某些场景非常有价值:Agent 需要"启动一个带数据库的开发环境,跑迁移脚本,写测试,验证通过后提交 PR"——在 E2B 里需要自己组装数据库层,在 hopx 里就是一个沙箱预设。
Beam(Beta9):唯一同时支持 GPU + 自建 + 无时长限制
Beam 的定位解决了 E2B 和 Modal 各自的痛点:E2B 有强隔离(microVM)但没有 GPU,Modal 有 GPU 但不能自建。Beam 用 gVisor 隔离 + 广泛的 GPU 支持(H100、H200、A100 80GB、B200、L40S、RTX 4090/5090)+ BYOC(AWS、GCP、Azure、Hetzner)+ 无 session 时长限制。
更值得注意的是开源策略:Beta9 完全开源,团队可以在自己的基础设施上运行完整的沙箱平台。弱点:gVisor 隔离弱于 microVM,冷启动 1-3 秒。
nono:隔离 + 凭证安全 + 配置完整性一体化
nono 解决的不是"怎么隔离",而是"隔离之后怎么办"。大部分沙箱方案只做隔离——Agent 被关起来了,但凭证怎么管理?配置怎么防篡改?
nono 用 Landlock 做文件系统隔离,在此基础上加了完整性保护的配置层和 OS 原生密钥管理。配套的 kubefence 是 Kubernetes NRI 插件,可以透明地把 nono 沙箱注入到现有的容器和 Kata VM 里——不需要改应用代码,不需要改 Dockerfile。对已有 K8s 基础设施的团队特别有价值。
Fly.io Sprites:持久文件系统的中间路线
Firecracker microVM,每个沙箱自带 100GB 持久化 NVMe 存储。checkpoint/restore 约 300ms,scale-to-zero。介于 E2B(纯 ephemeral)和 Blaxel(无限 standby)之间:Agent 不跑时不花钱,跑时从 snapshot 恢复,文件系统状态完整保留。
技术选型对比
| 平台 | 隔离模型 | 独立内核 | 冷启动 | Standby 恢复 | Session 上限 | GPU | BYOC/自建 | MCP 原生 |
|---|---|---|---|---|---|---|---|---|
| E2B | Firecracker microVM | ✓ | ~150ms | ~1s | 24h | ✗ | 企业级(AWS/GCP) | ✗ |
| Daytona | Docker (+ Kata 可选) | 可选 | ~90ms | — | 无限 | ✗ | ✓ | ✗ |
| Modal | gVisor | ✗ | <1s | — | 可配置 | ✓(A100/H100) | ✗ | ✗ |
| Blaxel | microVM | ✓ | 200–600ms | 25ms | 无限 | ✗ | ✗ | ✓ |
| Cloudflare | V8 Isolate | ✗ | <10ms | — | 可配置 | ✗ | ✗ | ✗ |
| Edera | KVM zone | ✓ | 766ms | — | 可配置 | ✗ | K8s 原生 | ✗ |
| Bunnyshell hopx | Firecracker microVM | ✓ | ~100ms | — | 可配置 | ✗ | ✓ | ✓ |
| Beam (Beta9) | gVisor | ✗ | 1–3s | 快照恢复 | 无限 | ✓(H100/A100/B200) | ✓(开源) | ✗ |
| Fly.io Sprites | Firecracker microVM | ✓ | ~300ms | ~300ms | 可配置 | ✗ | ✗ | ✗ |
| Vercel Sandbox | Firecracker microVM | ✓ | <1s | 快照恢复 | 45min–5hr | ✗ | ✗ | ✗ |
三个值得注意的空白区:
- 没有一家同时做到 microVM + GPU + BYOC。Beam 最接近但用的是 gVisor(不是独立内核)。"最强隔离 + 算力 + 数据不出域"三者不可兼得——至少目前如此。
- MCP 原生支持还很稀疏——只有 Blaxel 和 Bunnyshell hopx。MCP 正在成为 Agent-to-tool 的标准协议(97M 月下载,5800+ server),但沙箱平台普遍还没有跟上。
- 冷启动和隔离强度之间存在硬 tradeoff:<10ms(V8 isolate)→ ~100ms(microVM)→ 766ms(Edera zone)→ 1–3s(Beam gVisor)。在这个范围里,没有"又快又强"的选择。

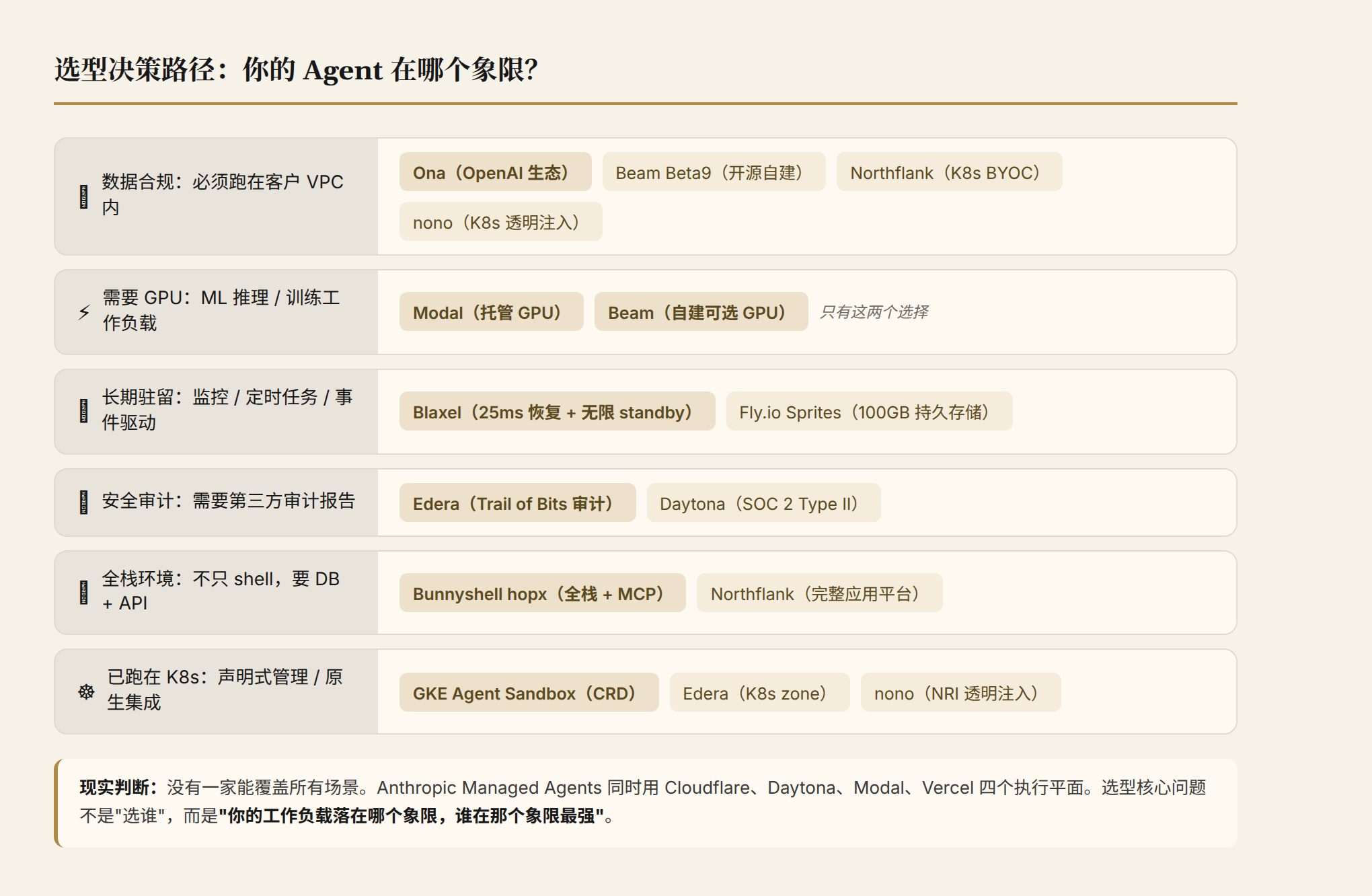
选型决策框架
选沙箱平台的核心决策变量不是"谁最好",而是"你信任谁、你的 Agent 做什么、你的数据在哪"。
- 数据合规(VPC 内):Ona(OpenAI 生态)/ Beam Beta9(开源自建)/ Northflank(K8s BYOC)/ nono(K8s 透明注入)
- 需要 GPU:Modal(托管)/ Beam(自建可选)。没有其他选择
- 长期驻留(监控/定时任务):Blaxel(25ms 恢复 + 无限 standby)/ Fly.io Sprites(100GB 持久存储)
- 需要安全团队签字:Edera(Trail of Bits 审计报告)/ Daytona(SOC 2 Type II)
- 需要全栈环境:Bunnyshell hopx(数据库 + API + worker + MCP)/ Northflank(完整应用平台)
- 已经跑在 K8s 上:GKE Agent Sandbox(声明式 CRD)/ Edera(K8s zone)/ nono(NRI 透明注入)
一个现实判断:2026 年下半年,没有一家沙箱平台能覆盖所有场景。多数生产系统会组合使用——Anthropic 的 Managed Agents 就同时用 Cloudflare、Daytona、Modal、Vercel 四个执行平面。选型的核心问题不是"选谁",而是"你的 Agent 工作负载落在哪个象限,哪个平台在那个象限最强"。
六、三个值得盯的趋势
凭证代理(Credential Brokering)
Agent 需要访问 GitHub、AWS、内部数据库——这意味着需要凭证。但凭证不能进沙箱(模型可能泄露它),也不能直接传给 Agent(prompt injection 可能窃取它)。
Anthropic 的 Managed Agents 支持 Vercel 的 credential brokering:Agent 发起请求 → 代理层注入凭证 → 执行 → 凭证立刻从内存清除。Ona 做了类似的 scoped credentials。Cloudflare Sandbox 的 secure credential injection 也是同一思路。
但这块目前没有行业标准,每家自己做一套。这可能是下一个需要标准化的层——就像 MCP 标准化了 Agent-to-tool 连接,凭证代理需要类似的协议来统一 Agent-to-credential 的接口。
K8s 原生化
GKE Agent Sandbox CRD 把沙箱管理变成了 K8s 的声明式 API。如果这个模式被广泛采纳,所有 Agent 框架都可以用统一的方式请求执行环境,不用关心底层是 Firecracker 还是 Docker。
但当前版本缺少行为观测层——你知道沙箱在跑,但你不知道 Agent 在里面做了什么。Edera 的 K8s zone 和 nono 的 NRI 注入分别从不同角度补这个缺口,但都没有成为事实标准。行为观测可能是 K8s 原生沙箱的下一个必争之地。
持久化 + 快速恢复
Blaxel 的 25ms 从 standby 恢复是一个信号。对于需要长期驻留的 Agent 工作负载(持续监控、定时 CI 任务、事件驱动),每次冷启动创建新沙箱太浪费。让沙箱待机、需要时快速唤醒,在成本和性能之间找到平衡。
Fly.io Sprites 的 100GB 持久 NVMe + 300ms restore 是另一个思路——不是让沙箱无限待机,而是给沙箱一个大容量"记忆",从 checkpoint 恢复时状态完整。两条路线解决的是同一个问题:Agent 需要记忆,而不是每次从零开始。
七、判断
OpenAI 这笔收购的时机很精准。Codex 周活 3 个月翻倍到 500 万,增速惊人。但 Anthropic 的 Claude Code 在 SWE-bench 上以 88.6% vs ~49% 遥遥领先——本地执行的优势在复杂任务上非常明显。OpenAI 不能只靠模型能力竞争,执行环境是必须补的短板。
更大的趋势是:Agent 执行环境正在从一个基础设施细节变成独立的产品品类。这个品类有四层玩家:
- 模型厂家的整合方案(OpenAI/Anthropic/Google):端到端体验,但锁定模型
- 独立沙箱平台(E2B/Daytona/Modal/Blaxel/Cloudflare):模型无关,各占冷启动/隔离/持久化/GPU 的一个象限
- 差异化技术厂家(Edera/Ona Veto/nono):在安全可验证、内核级控制、凭证完整性等细分方向做深
- K8s 原生方案(GKE Agent Sandbox):适合已有基础设施的企业
对开发者来说,2026 年下半年选 Agent 工具的关键决策变量变了。不只是"哪个模型跑 benchmark 最高",而是"哪个执行环境匹配我的安全要求和部署拓扑"。模型能力是 Agent 的脑子,执行环境是 Agent 的手脚——手脚的灵活度和安全性,正在变成比脑力更关键的竞争维度。
什么条件下这个判断会错:如果模型能力在接下来 12 个月内再次出现代际跃迁(比如推理准确率从 90% 跳到 99.9%),执行环境的差异可能被模型能力差距覆盖。但从目前各家的模型迭代速度来看,差距在缩小而不是在扩大——这让执行环境的重要性继续上升。
声明: 本文基于 OpenAI 官方公告(2026年6月11日)、CNBC/Bloomberg 收购报道、Ona 官方博客、Anthropic 官方工程博客、E2B/Daytona/Modal/Cloudflare/Edera/Bunnyshell/Beam 公开技术文档与博客、Trail of Bits 公开审计报告、以及 awesome-agent-runtime-security(GitHub)等开源社区资源综合撰写。不构成投资建议。文中数据截至 2026 年 6 月 12 日。