2026 年春天,内存行业出现了一个极端场景:DRAM 合约价在一个季度内暴涨 90-95%。
这不是供应链断链,也不是自然灾害。这是 AI 数据中心把全球高端内存产能吃干榨净的结果。
行业给这个场景取了一个名字:RAMageddon——RAM + Armageddon,内存末日。
SK Hynix 的 Q1 2026 财报浓缩了这场风暴的全貌:收入 52.6 万亿韩元(约 360 亿美元),同比 +198%,营业利润率 72%——超过 NVIDIA 和 TSMC。市值首次突破 1 万亿美元,年内涨幅 235%。
另一边,从西部数据拆分出来的 SanDisk,股价从 52 周低点 36 美元涨到 1590 美元。一年涨了 4400%。NAND Flash 数据中心收入同比增长 645%,毛利率从 22.5% 飙到 78.4%。
存储行业历来以残酷的周期性著称——暴涨之后必有暴跌。但这一次,一个问题悬在所有人头上:AI 的需求是不是大到足以打破这个周期?
- AI 到底消耗了多少内存和存储? 需求的结构到底是什么形状?
- 谁在赚真钱? HBM、DRAM、NAND、CXL,哪个环节利润最厚、护城河最深?
- 超级周期还是超级泡沫? 什么条件下这个判断会错?
一、需求侧:AI 的内存消耗结构
1.1 GPU 不是瓶颈,内存才是
一个 NVIDIA Rubin GPU 配备 288GB HBM4,带宽约 22 TB/s(NVIDIA GTC 2026 发布数据)。这是当前单芯片内存带宽的天花板,作为对比,上一代 Hopper H100 的 HBM3 带宽为 3.35 TB/s,Rubin 是它的 6.5 倍。
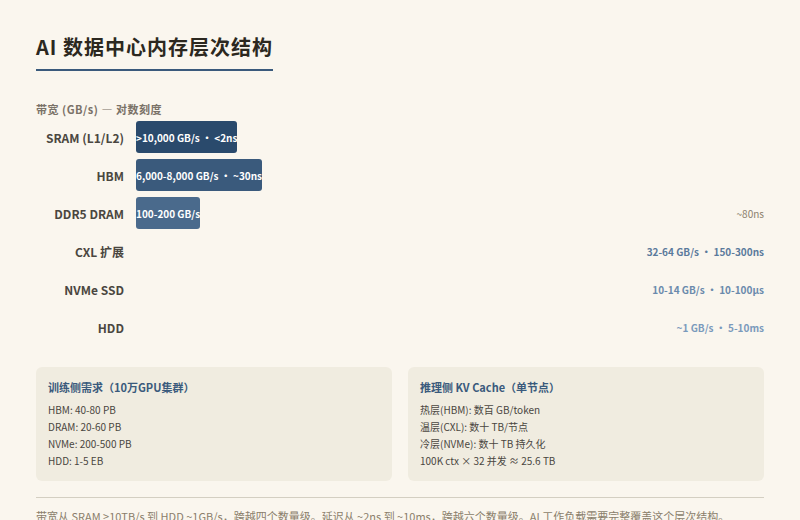
但 HBM 只是 AI 内存需求的冰山一角。完整的 AI 数据中心内存层次结构是这样的:
| 层级 | 媒介 | 容量/节点 | 带宽 | 延迟 | 用途 |
|---|---|---|---|---|---|
| L1/L2 Cache | SRAM(片内) | 数十 MB | >10 TB/s | <2 ns | 权重热数据、激活值 |
| HBM | 3D 堆叠 DRAM | 288 GB/GPU | ~22 TB/s | ~30 ns | 模型权重、KV Cache 热层 |
| DDR5 DRAM | 服务器内存 | 1-4 TB/服务器 | 100-200 GB/s | ~80 ns | 推理批处理缓冲、RAG 索引 |
| CXL 扩展内存 | DDR5/CXL | 按需扩展 | 32-64 GB/s | ~150-300 ns | 内存池化、KV Cache 温层 |
| NVMe SSD | NAND Flash | 数十 TB/服务器 | 10-14 GB/s | ~10-100 μs | 训练 Checkpoint、KV Cache 冷层、数据集 |
| HDD | 磁盘 | 数百 TB/节点 | ~1 GB/s | ~5-10 ms | 归档、训练数据源 |
关键数字: 一个大型 AI 训练集群(如 10 万 GPU 规模)运行一次 GPT-5 级别的训练,需要的内存和存储总量大致如下:
- HBM:约 40-80 PB(取决于模型大小和并行策略)
- 服务器 DRAM:约 20-60 PB(数据预处理、通信缓冲)
- NVMe SSD:约 200-500 PB(Checkpoint 每 15-30 分钟写一次,每次数百 TB;训练数据集数十 PB)
- HDD 归档:约 1-5 EB(训练数据生命周期管理)
1.2 推理侧的内存爆炸
训练是一次性的,推理是持续的。推理对内存的压力有两个特征容易被低估:
KV Cache 的内存消耗。 大语言模型推理时,每个 token 需要存储 Key 和 Value 向量。以 Llama 4 Maverick(400B MoE,128 层)为例,假设 KV cache 使用 FP8 量化:
- 每个 token 的 KV cache ≈ 128 层 × 2 (K+V) × 256 heads × 128 dim × 1 byte (FP8) ≈ 8 MB/token
- 一个 100K context 的请求 ≈ 800 GB KV cache
- 一个推理节点同时服务 32 个并发请求 ≈ 25.6 TB
这个数字意味着:单节点的 KV cache 就能吃掉数十 TB 内存。 这不可能全放 HBM。实际部署中,KV cache 被分成热/温/冷三层:
- 热(最近 N 个 token):HBM,延迟 <30ns
- 温(较远的 context):DDR5/CXL,延迟 80-300ns
- 冷(历史 session):NVMe SSD,延迟 10-100μs
这就是为什么 AI 推理不仅消耗 HBM,还同时消耗 DRAM、CXL 扩展内存和 NVMe SSD。存储需求不是"GPU 配套",而是从热到冷的完整层次结构。
1.3 训练 Checkpoint 的存储风暴
大型模型训练每 15-30 分钟做一次 Checkpoint,把模型状态写入持久存储,防止硬件故障导致从头重训。
以一个 10T 参数模型的训练为例:
- 单次 Checkpoint 大小 ≈ 20 TB(参数 + 优化器状态,FP16 + FP32 副本)
- 每 15 分钟写一次 → 每小时 80 TB 写入
- 24 小时 → 1.92 PB
- 一次训练周期(假设 60 天)→ 约 115 PB 的 Checkpoint 写入
这些写入必须在短时间内完成(通常 <5 分钟),否则影响训练效率。这意味着存储系统需要承受 瞬时 80 GB/s 以上的写入带宽,且必须持久化,NVMe SSD 是唯一选择。
二、供给侧:谁在赚真钱
HBM(High Bandwidth Memory)是 AI GPU 的核心组件,也是当前内存行业利润最厚的环节。
市场格局: 全球只有三家公司能生产 HBM,SK Hynix、Samsung、Micron。SK Hynix 占据了约 60-70% 的 HBM 市场份额,尤其是 NVIDIA 的高端产品线。
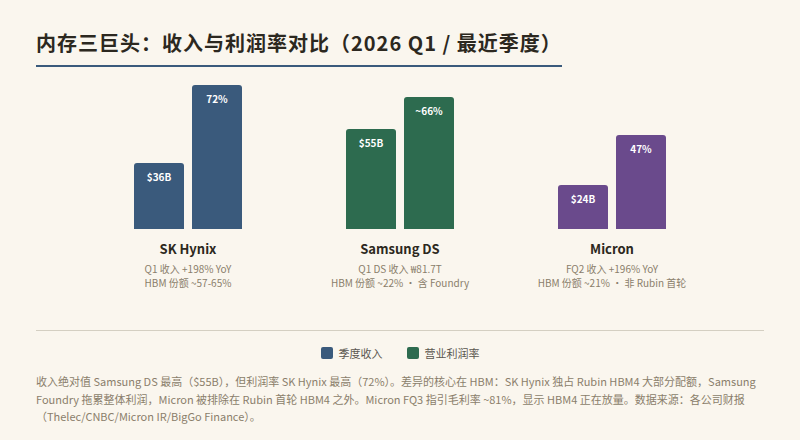
利润对比(Q1 2026):
| 公司 | 收入 | 同比 | 营业利润率 | HBM 份额 |
|---|---|---|---|---|
| SK Hynix | ₩52.6T(~$36B) | +198% | 72% | ~57-65% |
| Samsung DS | ₩81.7T(~$55B) | +69%(整体) | ~66% | ~22% |
| Micron(FQ2) | $23.86B | +196% | 47% | ~21% |
几个值得注意的数字:
- SK Hynix 的 72% 营业利润率超过了同期 NVIDIA。这不是技术代差的反映,而是 HBM 产能稀缺性 + NVIDIA 长约锁定的结果。SK Hynix 拿到了 Rubin HBM4 配额的 60-70%。
- Samsung DS 收入最高(~$55B)但利润率低于 SK Hynix。原因是 Samsung 的半导体部门包含 Foundry(代工),拖累了整体利润率。纯内存业务的利润率更高。Samsung 的 HBM4 DRAM 良率仍低于 60%(量产门槛 70%),拖慢了追赶进度。
- Micron 收入增速最高(+196%)但利润率最低(47%)。原因是 Micron 被排除在 Rubin 首轮 HBM4 供应名单之外,它的 HBM4 验证节奏滞后,高利润的 HBM 收入占比低于 SK Hynix 和 Samsung。Micron FQ3 指引显示毛利率可能跳升至 ~81%,说明 HBM4 正在放量。
数据来源:Samsung Q1 2026 财报(Thelec/CNBC/DCD 多源交叉验证)、Micron FQ2 FY2026 财报(Micron IR/Yahoo Finance)、SK Hynix Q1 2026 财报(多源一致)。
产能瓶颈在哪里? 不在晶圆制造,而在封装。HBM 需要 TSMC 的 CoWoS(Chip on Wafer on Substrate)先进封装。TSMC 的 CoWoS 产能虽然持续扩张,但 HBM 的良率和堆叠层数(从 8 层到 16 层)也在不断推高封装难度。SK Hynix 2026 年投资 19 万亿韩元新建 M15X 厂,专门用于先进 DRAM 和 HBM 生产。
护城河的持久性: HBM 的护城河来自三点,制造技术(TSV 硅通孔 + 3D 堆叠)、封装产能(绑定 TSMC CoWoS)、客户关系(NVIDIA 长约锁定了 SK Hynix 大部分产能)。这三点在 2-3 年内很难被颠覆。
2.2 DRAM:涨价的传导效应
HBM 产能挤占了标准 DRAM 的晶圆 allocation。三家供应商在 2025-2026 年间把大量产能转向 HBM,导致标准 DDR5 服务器 DRAM 供应紧张。
价格数据:
- Q1 2026 DRAM 合约价环比上涨 90-95%(TrendForce)
- Q2 2026 预计再涨 58-63%
- 2025 年 DRAM 总收入 $1657 亿,同比 +73%

谁受损? 传统服务器、PC、手机厂商。他们的 DRAM 成本翻倍,但终端产品无法同步涨价。这是一个零和博弈,AI 数据中心的收益,部分来自对非 AI 领域的挤占。
2.3 NAND Flash:SanDisk 的涅槃
如果说 HBM 是高端精密武器,NAND Flash 就是存储行业的大宗商品。但 AI 改变了 NAND 的需求结构。
SanDisk 的数据说明了什么(Q3 FY2026 实际):
- 总收入 $5.95B,同比 +251%,比指引上限 $4.8B 高出 $1.15B
- 数据中心收入 $1.47B,环比 +233%,同比 +645%
- 非 GAAP 毛利率:78.4%(实际),从一年前的 22.5% 飙升。此前 Q3 指引为 65-67%,实际远超指引
- 非 GAAP EPS $23.41,远超指引的 $12-14
- 多年供应合约积压订单 $420 亿
- 股价一年内从 $36 涨到 ~$1600,市值 $2370 亿
数据来源:SanDisk Q3 FY2026 财报(TradingKey/Motley Fool/Yahoo Finance 交叉验证)。
毛利率从 22.5% 到 78.4% 的飞跃,本质上反映了两个变化:
- AI 训练和推理对 NVMe SSD 的需求从"可选"变成了"必选"。 Checkpoint 存储、KV Cache 冷层、训练数据高速读取,这些场景需要的是企业级 NVMe SSD 的大容量和高耐久度,而不是消费级产品。
- 供应从过剩转为短缺。 NAND 行业在 2023-2024 年经历了惨烈的产能过剩,供应商被迫减产。当 AI 需求突然爆发时,产能恢复的速度跟不上。
NAND Top 5 Q1 2026 环比增长 83.7%(TrendForce),这在 NAND 历史上也是极端数据。
2.4 CXL:还在等风来
CXL(Compute Express Link)是服务器内存扩展的新标准,理论上可以让多台服务器共享一个内存池。
技术状态:
- CXL 2.0 支持内存池化(多主机访问独立分区)
- CXL 3.0 支持真正的内存共享(多主机同时访问同一段)
- CXL 4.0(2025.11 发布)带宽翻倍,x16 链路双向最高 1.536 TB/s
- Intel/AMD 最新服务器 CPU 已集成 CXL 控制器
实际部署:
- Microsoft 2025.11 宣布业界首个 CXL 云实例,并在 2026.4 发表了 NSDI 论文《Octopus》描述其 CXL 内存池化拓扑
- AWS 和 Google 尚未有公开的 CXL 生产实例
- CXL 内存模块市场 2025 年约 $28 亿,预计 2034 年 $286 亿(CAGR 29.4%)
核心问题: CXL 的延迟(~150-300ns)是本地 DRAM(~80ns)的 2-4 倍。对于延迟敏感的 AI 推理(如 KV Cache 热层),这个差距不可接受。CXL 的价值在于容量扩展而非性能提升,它适合放"不太热但又不想写到 SSD"的数据。
我的判断是:CXL 在 2026-2027 年仍然是小众配置,主要面向内存密集型工作负载(大型 RAG 索引、向量数据库、内存分析)。它不会像 HBM 那样成为 AI 基础设施的核心瓶颈,但会稳步吃掉传统 DRAM 的增量空间。
三、核心判断:结构性变化还是超级周期?
3.1 支持"结构性变化"的论据
-
AI 推理的内存消耗是持续性的。 与训练不同,推理一旦上线就 7×24 运行。每一个用户请求都在消耗内存,尤其是 KV Cache。随着模型参数量从千亿到万亿、context 从 32K 到 1M,推理的内存需求只会加速增长。
-
HBM 的产能门槛极高。 三巨头垄断、绑定 TSMC CoWoS 封装、2-3 年的新厂建设周期。即使需求见顶回落,HBM 的价格也不会崩到成本线,因为产能根本无法快速扩张。
3. AI 数据中心的内存配比在结构性提升。 传统服务器的 DRAM/CPU 比约 4-8 GB/core。AI 推理服务器的 DRAM/GPU 比约 512-2048 GB/GPU。一个 GPU 服务器需要的内存量是传统 CPU 服务器的数十倍。这种配比变化不会逆转。
3.2 支持"还是周期"的论据
-
内存行业的历史周期极度残酷。 2000 年、2008 年、2019 年都发生过暴跌。每一次涨价周期都刺激了产能扩张,最终导致供过于求。SK Hynix 2026 年 capex 超过 30 万亿韩元,Samsung 和 Micron 也在大幅扩产。当这些新产能释放时,供需天平会反转。
-
替代技术可能在 3-5 年内改变格局。 Samsung 在推进 LPDDR 宽 I/O 方案作为 HBM 的低成本替代;CXL 内存池化可能减少每台服务器的独占内存需求;存内计算(Processing-in-Memory)可能减少数据搬运量。
-
AI 模型效率在持续提升。 量化(INT8/FP8/INT4)、稀疏化(MoE)、蒸馏都在降低每 token 的内存消耗。如果模型效率的提升速度超过需求增长,内存压力会缓解。
-
3-5x forward P/E 的市场定价。 有意思的是,尽管 SK Hynix 和 Samsung 的利润创历史新高,forward P/E 仍然只有 3-5 倍。市场在用真金白银投票:"我们不认为这些利润是可持续的。" 这可能是内存行业历史上 forward P/E 最低的时刻,不是因为股价没涨,而是因为利润涨得太快。

短期(2026-2027):确定性极高。 HBM 产能全sold out,DRAM 涨价趋势未止,NAND 短缺持续。AI 基建投资没有减速迹象。
中期(2028-2029):需要警惕。 三巨头的新产能开始释放,HBM4E/HBM5 的良率提升带来更多供应。如果 AI 推理需求增速放缓(模型效率提升或应用场景不及预期),可能出现供需拐点。
判断的核心锚点: 不看 GPU 出货量,看推理 token 量的增速。如果全球 AI 推理 token 量保持 3-5 倍年增长,内存需求就是结构性的。如果增速降到 50% 以下,周期性回落的概率就很大。
什么条件下这个判断会错?
- AI 应用场景突然萎缩(监管、安全事件、ROI 质疑导致企业削减 AI 支出)
- 新的内存架构大幅降低单位 token 内存消耗(如 1-bit 量化或全新的注意力机制)
- 中国大规模扩产打破三巨头垄断格局(可能性低,但不为零)
四、中国视角:缺芯之痛
4.1 长鑫存储(CXMT)与长江存储(YMTC)
中国在 DRAM 和 NAND 领域各有代表企业:长鑫存储(DRAM)和长江存储(NAND)。
- 长江存储的 Xtacking 架构在 NAND 领域有一定技术竞争力,128 层和 232 层产品已量产。但受美国出口管制影响,先进设备(EUV 光刻机、先进蚀刻设备)供应受限,进一步的技术迭代面临挑战。
- 长鑫存储在标准 DRAM 领域正在追赶,已有 DDR4/DDR5 产品。但距离 HBM 还有较大差距,HBM 需要 TSV 硅通孔和 3D 堆叠技术,这些都需要先进制造和封装能力。
4.2 HBM 管制与华为昇腾
HBM 已经被纳入美国的出口管制范围。这对华为昇腾 AI 芯片是一个实质性打击,昇腾 910B/950 系列 AI 芯片需要大容量高带宽内存,但无法获得 SK Hynix/Samsung/Micron 的 HBM 供应。
昇腾的应对策略包括:
- 使用标准 DDR5 + 更大的片内 SRAM 作为替代(带宽和能效会显著低于 HBM 方案)
- 探索国内 HBM 替代方案(但离量产还有相当距离)
- 在软件层面做更多优化,减少内存带宽需求
这个局面意味着:中国在 AI 算力上的瓶颈不仅仅是 GPU 芯片本身,还延伸到了内存供应链。 存储管制可能是比 GPU 管制更隐蔽但也更持久的制约因素。
五、投资视角:如何理解存储行业的价值
这不是投资建议,但存储行业的投资逻辑有一些独特的结构性特征值得分析:
存储公司的利润率是前瞻性指标,不是滞后指标。 在典型的半导体周期中,利润率见顶通常是周期见顶的领先信号。但这次有所不同:AI 数据中心的内存需求增长速度可能超过产能释放速度,利润率维持高位的时间可能比历史更长。
HBM 是"卖铲子的卖铲子"。 NVIDIA 卖 GPU 是给 AI 训练和推理提供算力;SK Hynix 卖 HBM 是给 NVIDIA 提供 GPU 的核心组件。HBM 的利润率甚至超过 GPU 本身,这是一个值得注意的产业利润分配格局。
NAND 的弹性最大。 NAND 的价格波动历来比 DRAM 更剧烈(因为更容易扩产/减产)。SanDisk 的毛利率从 22% 到 78% 的飞跃既是机会也是风险,如果 AI 需求放缓,NAND 的回落速度也会最快。
声明: 本文基于公开信息撰写,综合参考了 SK Hynix Q1 2026 财报、TrendForce 市场报告、SanDisk FY2026 季度财报、Microsoft NSDI 2026 CXL 论文、以及 Motley Fool / Yahoo Finance 等多源市场分析。不构成投资建议。文中数据截至 2026 年 6 月 12 日。