草稿 v1 | 2026-06-11
2025 年 5 月的 Google I/O,Gemini Diffusion 悄悄上了 demo 区。没有 keynote 主场时段,没有 Sundar Pichai 亲自介绍。一个实验模型,排在十几个发布的最末尾。
但它做了一件所有自回归模型做不到的事:每秒生成 1,479 个 token。
一个月后,DiffusionGemma 开源。26B 参数,Apache 2.0 许可,推理速度是同级别 Gemma 4 的 3.7 倍。斯坦福衍生公司 Inception Labs 的商业产品 Mercury 已经上线 AWS Bedrock 和 Azure AI Foundry。香港大学的 Dream 7B 在通用、数学、编码任务上匹敌甚至超越了同规模顶级自回归模型。
文本扩散模型两年内从学术论文走到了商业部署。
但 Google 在 DiffusionGemma 文档里写了一句话:"For applications that demand maximum quality, we recommend deploying standard Gemma 4." 如果追求最高质量,推荐标准版。
Google 为什么要开源一个自己都说质量不够好的模型?
这句话藏着这整篇文章要回答的问题:文本扩散到底是一个新范式,还是一个用速度换质量的权宜之计?

第一章:扩散为什么能生成文字
要理解文本扩散和自回归的区别,先回到一个更根本的问题:生成到底在做什么?
自回归模型的回答是"逐字猜"。给模型一段前文,它预测下一个 token;把预测结果拼回输入,再预测下一个,如此反复。每一步只能看到左边的 token,每一步的决策都是不可逆的。一旦生成错了,无法回头修正。
图像扩散模型的做法完全不同。Stable Diffusion 生成一张图,不是从左上角开始逐像素画。它从一张纯噪声图开始,反复去噪,每次让画面更清晰一点,最后噪声消失,图像浮现。
文本扩散借用了同样的思路,但必须解决一个问题:文字是离散的。像素值可以加高斯噪声(3.14 可以变成 3.67),但 token "hello" 没有加噪声的概念。你不能把 "hello" 变成 "hel1o"。
离散扩散的解法是掩码(masking)。前向过程把一段文字中的 token 按比例随机替换成 [MASK],比例从 0% 逐步到 100%,文字变成纯掩码。反向过程是训练一个模型,看到被掩码的文字,预测每个 [MASK] 位置原来是什么。
实际生成时,流程是这样的:
- 初始化一个 256 token 的"画布",全部填
[MASK] - 模型对整个画布做一次前向传播,预测每个位置应该是什么 token
- 选出最有把握的那些位置,固定下来;其余位置重新加噪(重新掩码)
- 重复步骤 2-3,每一步让更多 token 确定下来
- 12-48 步后,全部 token 确定,生成完成
这个过程有两个自回归做不到的事:
**第一,并行。**256 个 token 同时生成,不存在"等前一个 token 生成完才能开始下一个"的瓶颈。自回归解码阶段的瓶颈是内存带宽:每生成一个 token 都要把整个模型权重从显存读到计算单元,但实际只做了一次矩阵乘法,GPU 的算力大量闲置。扩散模型把这个瓶颈转移到了计算上,每一步对 256 个 token 同时做双向注意力,GPU 的算力被充分利用。
**第二,双向。**每个 token 可以看到所有其他 token,包括右边的。这让扩散模型在代码填充、内联编辑、Sudoku 这类需要全局一致性的任务上有结构性优势。自回归模型的因果注意力(只看左边)意味着它永远无法利用后文信息来修正前文,一个 token 生错了就是错了。
但这套机制也有自回归没有的代价。固定块大小意味着即使只想生成 10 个 token,也要走完 256 token 的去噪流程。每一步都要对整个画布做注意力计算,256 token 的注意力矩阵是 256×256,而自回归每步只需要 1 次向量查询。扩散模型的"快",是靠把多次小计算打包成少数几次大计算实现的,这个策略在短文本和高 QPS 批处理场景下收益递减。
第二章:两年走完的路
文本扩散不是新想法。2021 年就有 Austin et al. 用结构化转移矩阵做离散扩散。但真正让它从学术好奇变成工程可行,只花了两年。
SEDD(Score Entropy Discrete Diffusion)是起点。Stanford 的 Aaron Lou、Chenlin Meng 和 Stefano Ermon 在 2024 年发表了这项工作,拿了 ICML 2024 最佳论文。核心贡献是解决了离散扩散的理论基础,建模数据分布的比率而非绝对概率,消除了不可处理的归一化常数。困惑度相比前序方法提升 25-75%。
SEDD 证明了离散扩散在理论上站得住。但理论可行不等于工程可用。
MDLM(Masked Diffusion Language Models)紧接着在 NeurIPS 2024 出现。简化了训练方案,引入 Rao-Blackwellized 目标函数,本质上是一种更高效的掩码语言建模损失。MDLM 在语言建模 benchmark 上达到扩散模型的新 SOTA,困惑度第一次接近同规模自回归模型。
LLaDA(Large Language Diffusion with mAsking)是规模验证。中国人民大学和蚂蚁集团联合,首次从头训练了 8B 参数的扩散语言模型。方法出人意料地简单:前向过程按随机比例掩码 token,反向过程用 vanilla transformer 预测所有掩码位置。LLaDA 与 LLaMA3 8B 性能相当,在 in-context learning 上有竞争力,还解决了自回归模型著名的"反转诅咒"(训练数据 "A is B" 无法泛化到 "B is A")。
LLaDA 证明了一件事:扩散模型的 scaling 不是纸上谈兵。
Mercury 把它变成了产品。Inception Labs(Stefano Ermon 联合创办的 Stanford 衍生公司)在 2025 年 3 月推出了首个商业级扩散 LLM。Mercury Coder 专注于代码生成,推理速度超过 1,000 tok/s。到 2025 年 11 月上线 AWS Bedrock 和 Azure AI Foundry,2026 年 3 月发布 Mercury 2,定位"个人 Agent 时代的快速扩散模型"。
Gemini Diffusion 是大厂入场的信号。2025 年 5 月 Google I/O 上以实验模型亮相,速度约为 Gemini 2.0 Flash-Lite 的 5 倍,编程性能持平。Google DeepMind 首席科学家 Jack Rae 称之为该领域的 "landmark moment"。但 Google 没有公开 Gemini Diffusion 的任何技术细节,也没有开放使用,只提供了一个 waitlist。
DiffusionGemma 是开源落地。2025 年 6 月,Google 基于 Gemma 4 MoE 架构开源了 DiffusionGemma。26B 总参数,3.8B 活跃参数,Apache 2.0 许可。推理速度 1,107 tok/s(H100),是 Gemma 4 26B 的 3.7 倍。核心创新是一个专门的 Diffusion Head,配合自适应早停,简单任务 12 步就能完成,复杂任务最多 48 步。
Dream 7B 是质量追赶。香港大学和华为诺亚方舟实验室联合,用 Qwen2.5 7B 的 AR 权重初始化扩散模型,不是从头训练,而是把已有的 AR 模型"转化"为扩散范式。这在两个层面有突破:训练成本大幅降低,且输出质量在通用、数学、编码任务上匹敌或超越同规模顶级 AR 模型。这是扩散模型第一次在质量上和同级 AR 打平。
两年时间,从理论到产品到开源。速度快得反常。但每一步进展都在暴露同一个问题:速度上来了,质量呢?
第三章:速度之外,扩散到底赢在哪
如果文本扩散只是"更快但更差的自回归",这个故事不够有趣。它有趣在几个自回归结构性做不到的事。
**代码填充。**开发者写了一半的函数,需要 AI 补全中间缺失的部分。自回归模型只能从左到右生成。它要么从缺口左侧续写到右侧(看不到右侧的代码约束),要么把左右两侧作为上下文重新生成整段。扩散模型天然支持任意位置的填充:初始画布的已知 token 保持不变,只去噪掩码位置。Dream 7B 的论文明确展示了这项能力。
**自我修正。**自回归模型一旦生成一个 token,就再也改不了。如果前半段走偏了,后半段只能将错就错,或者用外部的 rejection sampling / best-of-N 来弥补。扩散模型的迭代去噪天然包含了错误纠正:每一步都可以修正上一步的错误判断,整个文本块的一致性随着去噪步数增加而提升。Google 对 DiffusionGemma 的描述是:"The model iteratively refines its own output, allowing it to evaluate the entire text block at once to fix mistakes in real time."
**反转诅咒。**自回归模型训练数据 "Paris is the capital of France" 无法可靠地回答 "What is France's capital?",因为它只学了从左到右的条件概率。LLaDA 的双向注意力让模型在训练时同时看到 token 的两侧关系,从结构上消除了这个问题。对于需要双向推理的知识任务,这是一个真实的优势。
**质量-速度可调节。**自回归模型的推理速度取决于输出长度,很难在不影响质量的前提下加速。扩散模型有一个自回归没有的"旋钮":去噪步数。简单任务(格式化、短文本补全)12 步就够,复杂任务(长文生成、推理)可以开到 48 步。用户可以在延迟和质量之间按需调节。
但这些优势的适用场景比想象中窄。代码填充和内联编辑是真实的痛点,但它们不是 LLM 的主要工作负载。绝大多数调用场景是"给 prompt,生成长回复"。自我修正很好,但如果模型的底层判断力不够,修正多少次也修正不出正确答案。反转诅咒是学术上有意思的问题,但对实际应用的提升有多大,目前缺乏数据。
核心判断:扩散模型的独特优势是真实的、结构性的,但它们主要服务于特定场景而非通用替代。
第四章:质量差距
Gemini Diffusion vs Gemini 2.0 Flash-Lite 的 benchmark 对比是最有说服力的数据,因为两者都来自 Google,测试条件相对公平。
编码任务上,Gemini Diffusion 表现不差:LiveCodeBench 30.9% vs 28.5%(略优),BigCodeBench 45.4% vs 45.8%(持平),HumanEval 89.6% vs 90.2%(持平)。代码生成确实是扩散模型的舒适区。
但看看推理和知识任务:GPQA Diamond 40.4% vs 56.5%(落后 16 个百分点),Global MMLU 69.1% vs 79.0%(落后 10 个百分点),BIG-Bench Extra Hard 15.0% vs 21.0%(落后 6 个百分点)。这些差距不是微调能追上的——它是架构层面的局限。
DiffusionGemma 的情况类似。Google 自己的对比表里,DiffusionGemma 在 MMMLU、MMLU Pro、AIME 2026、LiveCodeBench v6、GPQA Diamond、tau2-bench 上全部低于标准 Gemma 4。速度是 1,107 vs 303 tok/s,但质量全面落后。
为什么?
自回归模型生成每个 token 时,要做一次完整的模型前向传播,所有层、所有注意力头都参与计算。一个 70B 参数的自回归模型,生成一个 token 的计算量约等于 70B 次浮点运算。链式思维(chain-of-thought)之所以有效,本质上就是让模型在更多 token 上做更多计算,"思考空间"更大。
扩散模型在 256 token 的画布上做 12-48 步去噪,看起来总计算量不小。但这些计算是并行的,每一步对 256 个 token 同时做注意力,每个 token 分到的"思考"比自回归少得多。一个直觉:自回归模型给每个 token 一个"专属"的前向传播,扩散模型给 256 个 token "共享" 12-48 次前向传播。当任务需要深度推理(而不是模式匹配)时,每个 token 分到的计算量可能不够。
这不是工程优化能解决的问题。要提升扩散模型的推理质量,要么增加去噪步数(但那会抵消速度优势),要么增加模型规模(但那会增加每步的计算成本),要么改变架构(比如混合 AR+扩散)。每种方案都有代价。
另外两个实际问题:
**固定长度生成。**DiffusionGemma 每次 256 token。如果用户需要 50 个 token,剩下的 206 个被浪费。需要 300 个 token,要跑两次 256 块,第一次生成的尾巴和第二次的开头如何衔接?自回归没有这个问题,它按需生成,长度完全灵活。
**高 QPS 云部署。**扩散模型在单请求低延迟场景优势明显,但在云端批处理场景下,自回归的 KV cache 和连续批处理(continuous batching)技术已经非常成熟。多个请求可以共享 GPU 时间片,GPU 利用率高。扩散模型每一步要对整个画布做注意力,多个请求并行时显存开销和计算调度复杂得多。Sean Goedecke 的分析指出:在高 QPS 工作负载下,扩散模型的并行解码收益会递减。

核心判断:扩散模型的推理质量差距是 2026 年最大的悬念。Dream 7B 的结果表明差距在缩小,但 GPQA 和 BIG-Bench Extra Hard 的数据表明,深度推理仍是扩散的软肋。如果这个差距在 2027 年仍然存在,扩散模型的角色会从"范式竞争者"降级为"场景特化工具"。
第五章:三条路线的真正格局
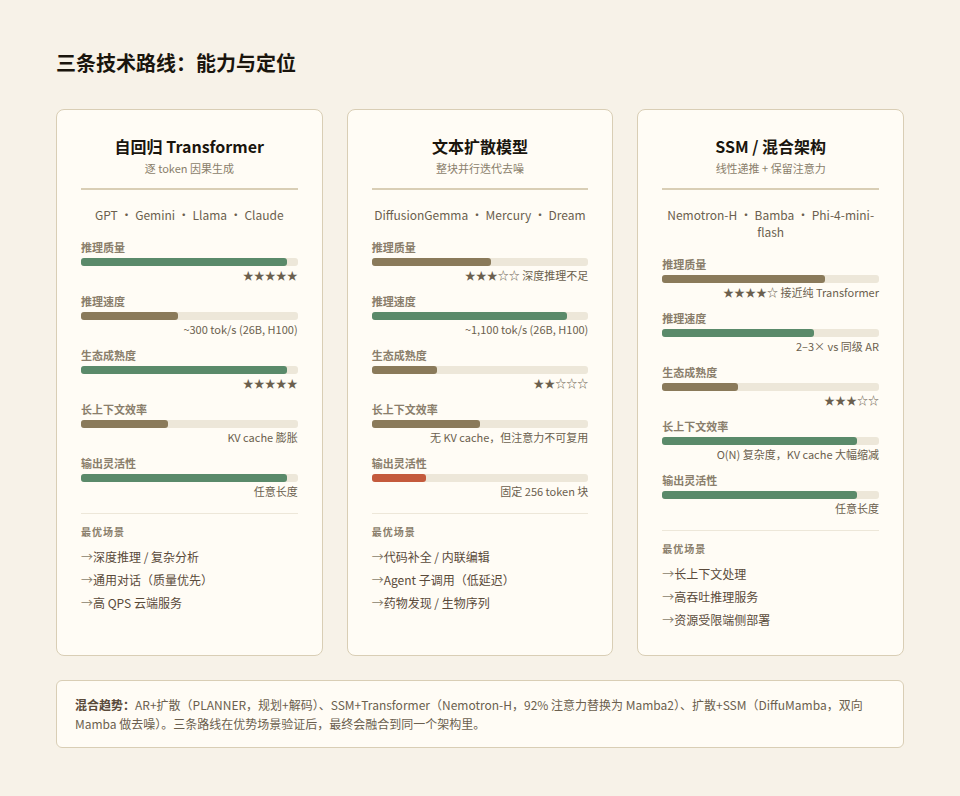
2026 年的大模型架构不是两条路线之争,是三条。
自回归 Transformer(GPT、Gemini、Llama、Claude)是当前的默认选项。近十年的技术迭代,训练 pipeline、对齐方法(RLHF/DPO)、推理优化(KV cache、speculative decoding、continuous batching)都围绕它构建。scaling law 经过千亿 token 训练验证。生态壁垒极高。
但 AR 有两个结构性瓶颈。推理阶段是 memory-bandwidth bound:每生成一个 token 都要把模型权重从显存读到计算单元,而实际计算量很小。长上下文下 KV cache 膨胀严重,128K 上下文可能需要数 GB 的 KV cache 存储。这两个瓶颈在模型继续变大、上下文继续变长时会越来越突出。
文本扩散模型(DiffusionGemma、Mercury、Dream)用并行生成绕过了 AR 的推理瓶颈。速度是真实的,4-10 倍于同级 AR 模型。但质量差距也是真实的,特别是在深度推理任务上。扩散模型的支持者指出推理能力可以通过更多去噪步骤和更大模型来弥补,但批评者认为并行生成的每个 token 分到的计算量天然不足,这是架构层面的天花板。
SSM/混合架构(Mamba、Nemotron-H、Bamba、Phi-4-mini-flash)走了第三条路。状态空间模型用线性时间复杂度替代注意力的二次复杂度,长上下文效率大幅提升。NVIDIA 的 Nemotron-H 把 92% 的注意力层替换为 Mamba2,吞吐提升 3 倍,精度不降。IBM 的 Bamba 9B 用 7 倍少的数据匹配了 LLaMA-3.1-8B。Microsoft 的 Phi-4-mini-flash 用 SambaY 架构实现了 10 倍吞吐提升。
SSM 的局限是推理能力不如纯 Transformer。Mamba 作者 Albert Gu 本人的分析指出:SSM 的隐藏状态维度需要比输入输出更大,对于信息密集的语言模态,模型需要足够大的状态来存储后续需要访问的信息。纯 SSM 在复杂关系推理上不如注意力,这就是为什么所有实用的混合方案都保留了部分注意力层。Nemotron-H 保留了 8%,Bamba 用了混合块设计。
三条路线各自的优势场景很清楚:
| 场景 | 最优路线 | 原因 |
|---|---|---|
| 深度推理/复杂分析 | AR Transformer | 每token计算量最大,思考空间最深 |
| 代码补全/内联编辑 | 扩散 | 双向注意力+并行生成+自我修正 |
| 长上下文处理 | SSM/混合 | 线性复杂度,无KV cache膨胀 |
| 高QPS云端服务 | AR + 批处理优化 | KV cache复用,continuous batching成熟 |
| Agent子调用(低延迟) | 扩散 | 延迟乘数效应,12步即可完成 |
| 通用对话(质量优先) | AR Transformer | 质量标杆 |
2026 年的格局不是"谁赢",而是混合趋势明显:AR+扩散(PLANNER 用扩散做高层规划、AR 做 token 解码)、SSM+Transformer(Nemotron-H 用 Mamba2 替代大部分注意力)、甚至扩散+SSM(DiffuMamba 用双向 Mamba 做扩散去噪)。三种范式在各自的优势场景验证后,最终会融合到同一个模型架构里。
Stefano Ermon 预测"几年内所有前沿模型都将使用扩散"。Nathan Lambert(AI2)的评价更克制:"It's the biggest endorsement yet of the model, but we have no details so can't compare well." Google 进来了是好事,但细节不够,不好下结论。
2026 年的事实是:三条路线都在快速迭代,没有任何一条被证明是死路,也没有任何一条成为公认的最优解。
第六章:谁先赢,哪里先赢
扩散模型不会替代自回归。但它会在特定场景率先成为首选。
代码生成是最确定的场景。Mercury Coder 已经在 AWS 和 Azure 上商用。代码有强结构约束(语法、类型系统),需要快速迭代(自动补全、apply-edit),天然适合扩散的并行生成和自我修正。Inception Labs 声称 Mercury Coder 的 Apply-Edit 能力"远超领先模型",这个说法需要独立验证,但代码场景的产品市场匹配度是清楚的。
Agent 子调用是第二个高潜力场景。一个 Agent 完成一次任务可能需要 5-20 次 LLM 调用,每次调用的延迟被放大 5-20 倍。如果每次调用从 300 tok/s 的 AR 模型切换到 1,100 tok/s 的扩散模型,整体响应时间可能缩短 60-70%。Mercury 2 发布时就定位为"个人 Agent 时代的快速扩散模型"。
药物发现和生物信息是第三。氨基酸序列、蛋白质结构不是自然语言,不需要"从左到右"的逻辑。它们更适合双向建模,一个氨基酸的性质取决于它在整个序列中的位置,而不是只取决于左边的序列。DiffusionGemma 的文档已经提到这个方向。
实时对话在理论上是好场景,低延迟对用户体验至关重要。但实际部署挑战很大:对话的输出长度高度不确定,扩散模型的固定块大小会浪费算力;高并发的实时对话服务需要批处理优化,而扩散在这方面的成熟度远不如 AR。短期内不太可能突破。
国泰海通证券 2025 年 7 月的研报判断得比较准确:"dLLM 不会完全替代 AR 模型,而是与 AR 模型优势互补,共同构成一个更多元、更繁荣的 AI 技术生态。"它的定位更像是 GPU 生态里的 ASIC——通用计算用 GPU,特定任务用专用芯片。
对开发者的实际建议:如果工作负载是代码辅助、Agent 子调用、或者需要快速迭代的结构化生成,扩散模型值得测试。如果工作负载是复杂推理、长文分析、或者需要最高质量的通用对话,自回归模型仍然是更好的选择。不要追范式,看场景选模型。
收尾
Google 的策略是这整件事最好的注脚。Gemini 系列旗舰仍然是自回归。Gemini Diffusion 是实验项目。DiffusionGemma 是开源探索。Google 没有把扩散放在主线上,它把扩散放在侧线上验证,成功了就融合,不成功也不影响主业务。
这个策略很 Google:在搜索时代就用过同样的打法(Google+、Glass、Wave——大量探索,少数存活)。文本扩散能否成为主线技术,取决于一个 2027 年才能回答的问题:推理质量能不能追上自回归。
Google DeepMind 的 Sander Dieleman 在 2023 年写过一篇博客,标题本身就是一个好问题:"Diffusion models have completely taken over generative modelling of perceptual signals — why is autoregression still the name of the game for language modelling? And can we do anything about that?"
扩散已经接管了图像和视频。文字是最后一块阵地。2024-2026 的进展表明这个阵地可能不是铁板一块,但要说已经被攻破,还太早。
声明: 本文基于公开信息撰写,参考了 Google 官方博客和开发者文档、Google DeepMind 产品页、Inception Labs 官网和博客、HuggingFace 博客、The Decoder、Fortune、Sean Goedecke 的技术分析、国泰海通证券研报,以及 SEDD(ICML 2024)、MDLM(NeurIPS 2024)、LLaDA(NeurIPS 2025)、Dream 7B、Mercury、DiffuMamba 等论文。本文不构成投资建议。数据截止 2026 年 6 月 11 日。