一、一家没有营收的公司,卖了 40 亿美元
2026 年 6 月,彭博社爆出高通正在和 Modular 谈收购,估值约 40 亿美元。消息出来时,不少财经媒体的第一反应是「高通又买了一家 AI 芯片公司」。
这是个误会。Modular 不造芯片。它做的是 AI 编译器平台和一门叫 Mojo 的编程语言,没有公开营收。新浪财经后来纠正得很直接:这是「一家软件企业把自身包装为芯片标的」。
把数字摆出来看更有意思。Modular 2022 年成立,累计融资 3.8 亿美元,2025 年 9 月的估值是 16 亿。九个月后,高通给出 40 亿,翻了 2.5 倍。一家没有营收的软件公司,凭什么值这个价?
要回答这个问题,得先看清高通在买什么,以及它买的这个东西为什么是 AI 基础设施里最关键、却又最难赚到钱的一层。
二、高通买的不是营收,是一张牌桌的入场券
Modular 这笔收购不能单独看。把高通过去两年的动作连起来,一张拼图就出来了:
| 收购标的 | 补的是什么 | 金额 |
|---|---|---|
| Alphawave | 「连」:芯片间高速互连 | 约 24 亿 |
| NUVIA | 「核」:前苹果 CPU 团队 | 14 亿 |
| Ventana Micro | RISC-V 数据中心 CPU | 未披露 |
| Modular | 「软」:反 CUDA 的编译栈 | 约 40 亿 |
| Tenstorrent(谈判中) | 团队 + 下一代架构 | 80–100 亿 |
高通在拼一套完整的、绕开英伟达的数据中心方案:自己的 CPU 核、自己的互连、自己的编译软件栈。其中最难补、也最贵的,恰恰是软件这一层。
原因很简单。一块 AI 芯片如果没有成熟的软件栈,就是一块砖。英伟达的统治从来不只是硬件,而是 CUDA 这套软件生态,它让全世界的算法工程师习惯了在 NVIDIA 的硬件上写代码。任何想卖非英伟达芯片的厂商,第一道坎不是流片,是软件。
所以高通这 40 亿买的不是 Modular 的现金流,是「有资格在英伟达之外开第二张牌桌」的入场券。这是一笔战略期权,不是现金资产。它贵,但对高通的战略刚需来说,是可承受的溢价。
判断这笔交易划不划算,不能看 Modular 现在赚多少钱,要看编译层这个位置本身值多少钱,以及它的价值最终能不能落到一家独立公司手里。
三、Modular 是谁:一个人造了两代编译器地基
Modular 的核心资产是创始人 Chris Lattner。他的稀缺性,在整个软件行业里都不多见。
他的履历是一条编译器的主线:博士期间做出 LLVM(今天 C++、Rust、Swift 的共同底座),凭此拿了 2012 年 ACM 软件系统奖;进苹果后造了 Clang 和 Swift;之后在谷歌带 TensorFlow 基础设施团队,做出了 XLA(加速线性代数的即时编译器)和 MLIR(一个构建编译器的模块化框架,今天 XLA、IREE、Torch-MLIR 都建在它上面)。
换句话说,Lattner 先后造了两代编译器地基:LLVM 和 MLIR。今天 AI 编译领域几乎所有重要项目,往下挖到底都会碰到这两块石头。他在谷歌把地基打好,出来创业,用同一套地基盖商业楼。过去二十年里,极少数人同时主导过两代编译器基础设施,他是其中之一。
Modular 有两条产品线:
- Mojo:一门 Python 超集语言,号称有 C++ 的性能。早期靠「比 Python 快几万倍」的标题博眼球,2024 年已开源标准库核心组件。但 Modular 的商业重心已明晰地压在 MAX 推理引擎上,Mojo 更像一个技术阵地,而不是收入产品。
- MAX:跨硬件推理引擎,让同一个模型在 NVIDIA、AMD 和各类 NPU 上直接部署,不用为每种硬件重写。这才是商业模式真正所在。
Lattner 通过 Modular 的博客发表了《Democratizing AI Compute》系列长文(至少九篇),深入拆解 CUDA 成功的逻辑、替代方案的困境以及如何打破锁定的路径。明牌。
理解了 Lattner 的血统,也就理解了为什么这是一笔「人才 + 技术」的收购,而不是产品收购。高通买的是全球少数几个能从零搭出反 CUDA 软件栈的团队,外加一个领跑了几年的起点。
四、编译层为什么是「咽喉」
要理解后面所有的价值判断,得先明白编译层在 AI 技术栈里站在哪个位置。
往上,它对接前端框架(PyTorch、TensorFlow);往下,它对接硬件(GPU、NPU、各类加速器)。它的工作是把高层的计算图,翻译成具体芯片上能跑得飞快的机器指令。
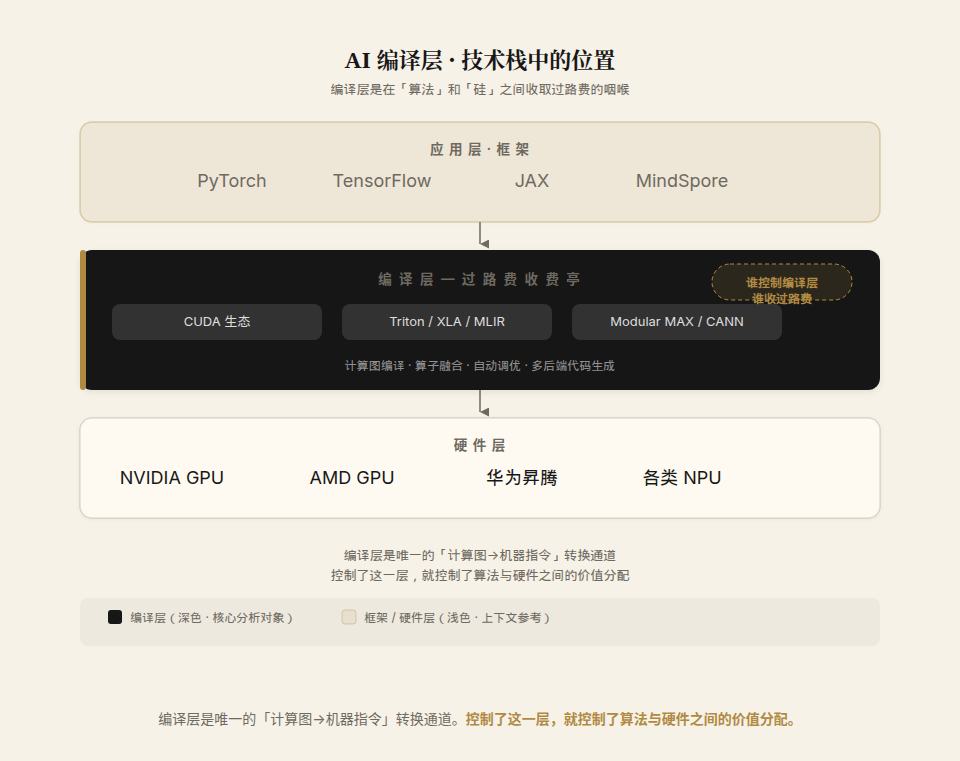
关键在于:同一块芯片,编译做得好与坏,性能能差几倍到几十倍。一块四万美元的 GPU,编译器让它的有效算力利用率停在 30% 还是冲到 90%,是实打实的钱。
谁控制了编译层,谁就站在「算法」和「硅」之间。这正是 CUDA 的位置。它是 NVIDIA 硬件和全世界 AI 代码之间唯一的、被习惯了的通道。控制了通道,就有资格收过路费。
这一层之所以难,是因为它把几个本质上互相矛盾的目标压在了一起。下面六个技术卡点,每一个都是真问题,也每一个都最终会回到「钱归谁」这个问题上。
五、六个技术卡点
卡点一:性能可移植性,这一层最深的诅咒
这是整个领域的元问题。每个跨硬件编译器的卖点都是「一次编写,到处高性能运行」。但行业里有个少有人明说的事实:正确性的可移植早就解决了,性能的可移植性基本无解。
原因在硬件微架构的不可抽象。要榨出峰值性能,必须吃透具体芯片的细节:内存层级(寄存器文件、SRAM 容量、L2 行为)、矩阵乘累加指令的 M×N×K 操作数形状(NVIDIA Ampere 的 mma.m16n8k16/Hopper 的 wgmma、AMD CDNA 的 matrix core、昇腾 Cube 的 16×16×16 模式)、算力与带宽的比例。这些东西每块芯片都不一样。
矛盾是结构性的:抽象层级越高,越可移植,但离峰值越远,性能损失可以到 30% 到 70%;越贴近硬件,性能越好,但越不可移植。
CUDA 真正赢的地方,恰恰不是「可移植」。相反,它允许你一路捅到金属层,同时 NVIDIA 用 cuBLAS、cuDNN、CUTLASS 这些手调好的库把高性能内核喂给你,让大多数人永远不需要自己下去。Modular 的 MAX 声称破解了这个诅咒,但拿得出的证据还很薄。这是它 40 亿估值里最大的一个问号。
卡点二:长尾算子,时间和生态的函数
现代模型早就不是矩阵乘加注意力那么简单。算子的表面积在爆炸式增长:每出一个新架构(Mamba 这类状态空间模型、MoE 的路由、FlashAttention 的各种变体、DeepSeek 的 MLA),就引入一批新的融合内核。
CUDA 护城河的一半,是 NVIDIA 加社区用十八年写了数千个优化好的内核。一个新芯片、新编译器,是从零开始的。AMD 的 ROCm「能跑但慢」,根子就在内核库太薄。
这个卡点有个要命的性质:算子库的厚度是时间乘生态的积分,没法靠一次技术突破追平,至少在 AI 自己学会写内核之前是这样。这个伏笔后面会回来。
卡点三:自动调优的组合爆炸,撞上动态形状
就算只在一块芯片上,找到最优的执行方案(tile 大小、循环顺序、向量化、内存布局、流水线深度)也是个巨大的搜索空间。TVM 的 Ansor、Triton 的自动调优器都在跟组合爆炸搏斗,搜一个算子的一种形状可能要花几个小时。
更麻烦的是,大模型推理是高度动态形状的:batch 在变,序列长度在变,KV cache 在持续增长。静态编译假设形状固定,运行时的灵活性要拿性能去换。优化重心因此从纯编译层迁向运行时调度和服务层。vLLM 大量使用 Triton 编译的融合注意力内核,本质是「运行时调度 + 编译内核」混合。编译层面对动态形状时,单独无法完美解决。
卡点四:PyTorch 前端的绑定力
PyTorch 赢了框架战,大约九成的研究跑在上面。而 PyTorch 2.0 的默认编译后端,选了 TorchInductor 加 Triton。
这件事的后果极深:Triton 事实上成了 CUDA 之后 AI 世界的「第二中间语言」。任何想要 PyTorch 用户的硬件厂商,都必须让 Triton 在自己的芯片上跑通。2024 年中期以来,Triton 的治理权逐步转移到 PyTorch Foundation 多方共治框架下,但 OpenAI 作为最初设计者和最大贡献者之一,仍然拥有深厚的技术影响力。
对新玩家来说,这是一道入场税:你必须接入 PyTorch,而默认路径已经被 Triton 占住了。要么骑在 Triton 上(接受它抽象层的天花板),要么自建一套 torch.compile 后端(巨大的工程量,外加一台永远停不下来的维护跑步机)。
卡点五:MLIR 的「未完成」
MLIR 是 Lattner 留下的天才设计,但它是一套构建编译器的框架,本身不是一个编译器。它把最硬的活,写方言、写下降通路、写各种翻译,全摊派给了每一个采用者。所以业界有一大堆基于 MLIR 的项目,却没有一个 MLIR 做的、跨硬件「开箱即用」的统治级编译器。连 Lattner 自己的 Modular,也要在 MLIR 上盖好几年楼。
卡点六:数值一致性的隐形税
融合和重排会改变浮点运算的结果,因为浮点加法不满足结合律。在训练里,这可能影响收敛;在推理里,这可能改变输出。验证一个优化过的内核和参考实现数值等价(在容差范围内),很难,常常要靠手工。这是压在每一个优化动作上的隐形成本,没人爱提,但人人都在付。
六、价值创造 ≠ 价值捕获
把上面六个卡点翻过来看,就是钱的归属问题。这是理解整个领域的钥匙。
编译层创造的价值毫无疑问是巨大的,它是同一块硬件跑出 30% 还是 90% 利用率的差别。但创造的价值,绝大部分不归编译层自己。
谁捕获了这些价值?
| 主体 | 捕获方式 | 捕获量 |
|---|---|---|
| 硬件厂商(NVIDIA / 华为) | CUDA、CANN 免费,但护住硬件的高毛利 | 绝大部分 |
| 云厂商(Google / neocloud) | 更好的编译 → 更高利用率 → 云租金毛利 | 一部分 |
| OpenAI(Triton) | 中立中间层的战略杠杆,非直接收入 | 战略权力 |
| 独立编译层公司 | 几乎收不到过路费 | 极少 |
独立的编译层公司为什么收不到税?因为它被夹在两座大山之间,两头都不给它留收税的空间。当然也有反例:Anaconda、JetBrains 以及 MathWorks(MATLAB 编译栈)说明编译器相关软件并非完全不能独立商业化。但它们的共同点是绑定了特定的运行时生态或开发流程,而不是独立跨硬件的纯编译层,后一条路目前还没跑出来。
往上,框架层是免费的。PyTorch 是 Meta 补贴的公共品,没人会为它付钱。往下,硬件厂商一定会自建软件栈,这层软件是护住硬件毛利的命门,绝不可能外包。而终端用户,则把编译器当成「本该免费」的基础设施,就像没人会为 GCC 这个 C 编译器付费一样。
三个并购案例已经把这条路钉死了:
| 公司 | 结局 | 被谁收 |
|---|---|---|
| OctoAI(TVM 团队) | 2024.10,约 2.5 亿 | NVIDIA |
| CentML | 2025.7,约 4 亿 | NVIDIA |
| Modular | 谈判中,约 40 亿 | 高通 |
规律很清楚:编译层公司的终局,不是被硬件厂商收编,就是被大模型公司当基建收编。它创造价值,但困住价值。
打个比方,编译层像一个杰出的造桥人,站在一条河上。但两岸都被巨头占着,他们要么雇你,要么自己造一座。你的桥造得越好,他们越想把你整个买下来,而不是付你过桥费。位置不等于独立公司的价值。高通赌的也不是编译层独立赚钱,而是它绑死硬件后通过硬件捕获价值。
七、收益甜点在中段,护城河在最后一段
编译器改进带来的经济价值不是线性的,是一条边际递减的曲线。
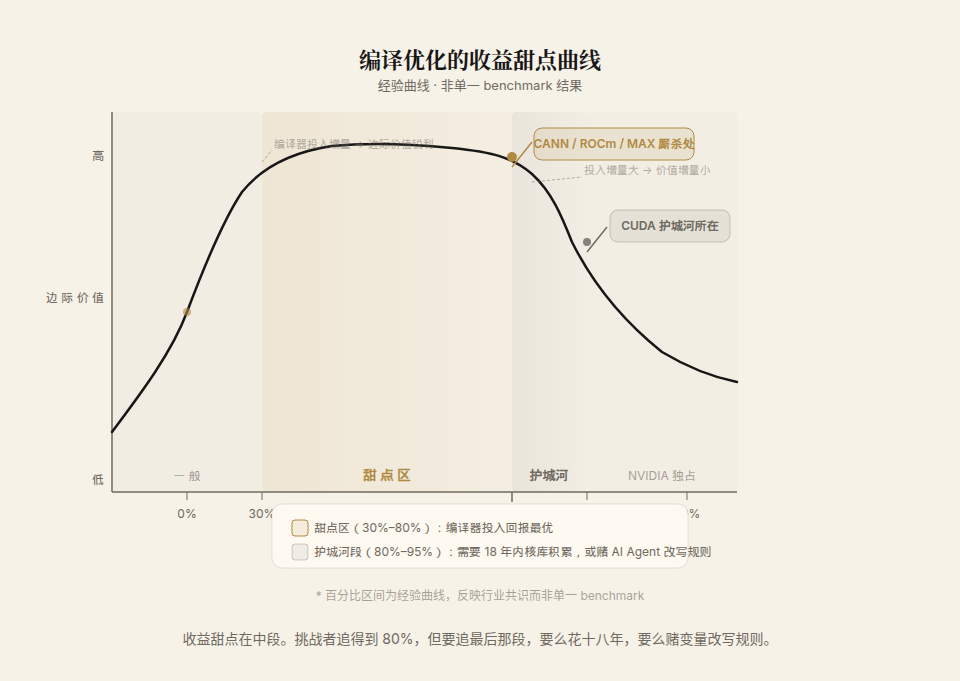
- 从 10% 抬到 50% 利用率:价值巨大,等于同样的硬件多挤出几倍有效算力。
- 从 50% 到 80%:价值显著。
- 从 80% 到 95%:开始递减,要靠手工调优,只有超大规模的场景才值得做。
- 从 95% 到 99%:只有 hyperscaler 和 NVIDIA 自己会去碰。
所以收益的甜点在中段,把一块新芯片从「勉强能跑」(naive 编译只有 10% 到 30% 利用率)抬到「有竞争力」(60% 到 80%)。Modular 的 MAX、华为的 CANN、AMD 的 ROCm,全都在这一段厮杀。注:此百分比区间为经验曲线,非单一 benchmark 结果。
而最后那 15% 到 20%,才是护城河真正所在。CUDA 积累了十八年的内核库,在这一段仍然碾压一切。这解释了一个反直觉的现象:挑战者能相对快地追到 80%,但要追最后那 20%,要么再花十八年,要么赌 AI Agent 改写规则,要么等新计算范式(光子、模拟计算、近存计算)让现有软件栈整套作废。
八、国内格局:两条路线的分叉
中国在这一层的处境,比毛利问题更复杂。它还叠加了一个绕不开的现实:出口管制下,能不能在国产芯片上跑 AI,是一个生存问题,不只是经济问题。
国内大致分成两条路线。
华为 CANN 走的是全栈自研:CANN 对标 CUDA,MindSpore 对标 PyTorch,Ascend C 对标 CUDA 内核。2025 年 8 月 5 日,华为轮值董事长徐直军在昇腾峰会上宣布 CANN 全面开源开放(涵盖算子库、图引擎、Mind 系列工具链),承诺 12 月 30 日前完成。这是一步聪明棋,用开放去对抗英伟达的封闭,争夺开发者心智。一个原本由硬件厂商自上而下封闭主导的软件栈,主动打开,本质是承认:生态不是靠一家公司关起门来建成的。
国产其他芯片则分成两派。一派做 CUDA 兼容(海光、沐曦、摩尔线程、壁仞),好处是蹭现成生态,代价是移植有损耗、性能打折,而且永远跟在英伟达后面。另一派赌自研非兼容(燧原、寒武纪),赌的是差异化,代价是生态从零做起。
真正值得关注的,是智源研究院牵头的 FlagOS。它走的是 Triton 路线,已经做出一个支持十二家国产芯片的统一编译器 FlagTree。它的理念是用一个开放标准,把南向的国产芯片统一起来,这是后发者唯一可能赢的打法。与其让十二家芯片各自去追英伟达的封闭标准,不如用一个开放标准把它们攒成一股。
把 CANN 开源和 FlagOS 放在一起看,会发现中国这一层的最优解正在浮现:不是逐家去做 CUDA 兼容,而是用开放标准对抗封闭标准。
九、两个会重新洗牌的变量
前面的判断,都建立在「内核库厚度无法快速追平」「编译层赚不到钱」这两个前提上。但有两个变量,可能把这两个前提都掀翻。
变量一:AI Agent 自己写内核
这是整个领域最重要的二阶动态。如果大模型能自动生成、自动调优、自动验证内核,那么:
CUDA 那十八年的内核库优势会被急剧压缩。「性能可移植性」这个卡点,会被换一个角度攻击:不再追求一个能跑遍所有硬件的可移植内核,而是为每一块硬件、每一种形状,当场自动生成一个专用内核。人类编译器专家会贬值,自动调优和自动验证的框架会升值。
2026 年 1 月,一位代号 johnnytshi 的开发者用 Claude Code 在三十分钟内把一个完整的 CUDA 后端(国际象棋 AI 项目 Leela Chess Zero)移植到了 AMD ROCm 上,移植后的代码达到可用性能(Strix Halo 平台 FP16 >2000 nodes/s)。AMD 软件副总裁 Anush Elangovan 公开回应称「GPU 编程的未来,属于 AI Agent」。国内智源的 KernelGen、FlagOS 也在同一方向上。
值得想清楚的是:编译层可能不是被一个更好的编译器吃掉,而是被「让写快内核变便宜」的 AI Agent 吃掉。需要谨慎的是,CUDA 的护城河不只是内核代码量——它还包括工具链、调试器、profiler、大量第三方库的依赖网络,以及全球 400 万以上开发者的习惯。AI Agent 自动写内核主要压缩的是「内核库厚度」这一维度的差距,其他维度不会同步消失。但如果这条成立,高通这 40 亿买的「跨硬件免重写」卖点,至少会在内核层面被从下面掏空。
变量二:收益重心从训练编译迁向推理经济学
推理的需求已经是训练的十到十五倍,日均 token 调用量突破一百四十万亿(国家数据局局长刘烈宏 2026 年 3 月在国新办新闻发布会上披露)。东吴证券同期研报指出,算力需求重心已「由训练主导转向推理主导」,2025 年推理数据量首次超过训练。编译层的价值,正在从「训练时优化」迁移到「推理成本优化」。谁能把推理编译到最低的每 token 成本,谁就赢下推理经济学。
这正是博通用 ASIC 路线挑战英伟达的底层逻辑,也是真金白银正在移动的方向。它意味着未来编译层的赢家,可能不是最通用的那一个,而是和某一类推理芯片绑死、把推理成本压到极致的那一个。
十、终局判断
把技术卡点和价值捕获两面合起来看,能得出五条判断。
第一,技术卡点的根,是性能可移植性的结构性无解。 所有跨硬件编译器都在用不同方式绕这个诅咒,没人真正破了它。Modular 声称破了,这是它估值里最大的问号。
第二,最难的技术点,恰好是最赚不到钱的位置。 编译层夹在免费的框架和自建的硬件软件之间,价值创造巨大,价值捕获稀薄。三个并购案例已经证明,它独立成不了大生意。
第三,收益甜点在中段,护城河在最后一段。 挑战者追得到 80% 利用率,但追最后那一段,要么花十八年,要么赌 AI Agent 改写规则,要么等新计算范式重塑底层。
第四,唯一能持续捕获价值的编译层,是绑死硬件的那一个。 价值通过硬件捕获,编译器只是收费亭,硬件才拥有那条路。CUDA、CANN、XLA 都是这个模式。独立的中立栈,比如 Modular、TVM、Triton,终局是被收编。
第五,这一轮并购潮的本质,是硬件厂商用现金买断「去英伟达化」的软件期权。 买的不是营收,是入场第二张牌桌的资格。而 AI Agent 自动生成内核,可能让这张昂贵的入场券在三五年内大幅贬值——这才是高通这笔赌注真正的风险敞口。
收费亭立在咽喉上,这个位置极其关键。但收费亭的主人,从来都不是修亭子的人。 -e
数据截止:2026 年 6 月 23 日。本文为技术分析文章,不构成投资建议。部分数据引用国家数据局、东吴证券研报及公开市场报道。