Agent 是怎么走歪的
当 AI Agent 在第 7 步选错了工具,后面 13 步全是浪费——传统监控为什么看不到
Deep Dive 3 / 3 · 本文是 AI 可观测性的三层盲区 的第三篇深入分析,聚焦 Agent 决策路径观测。
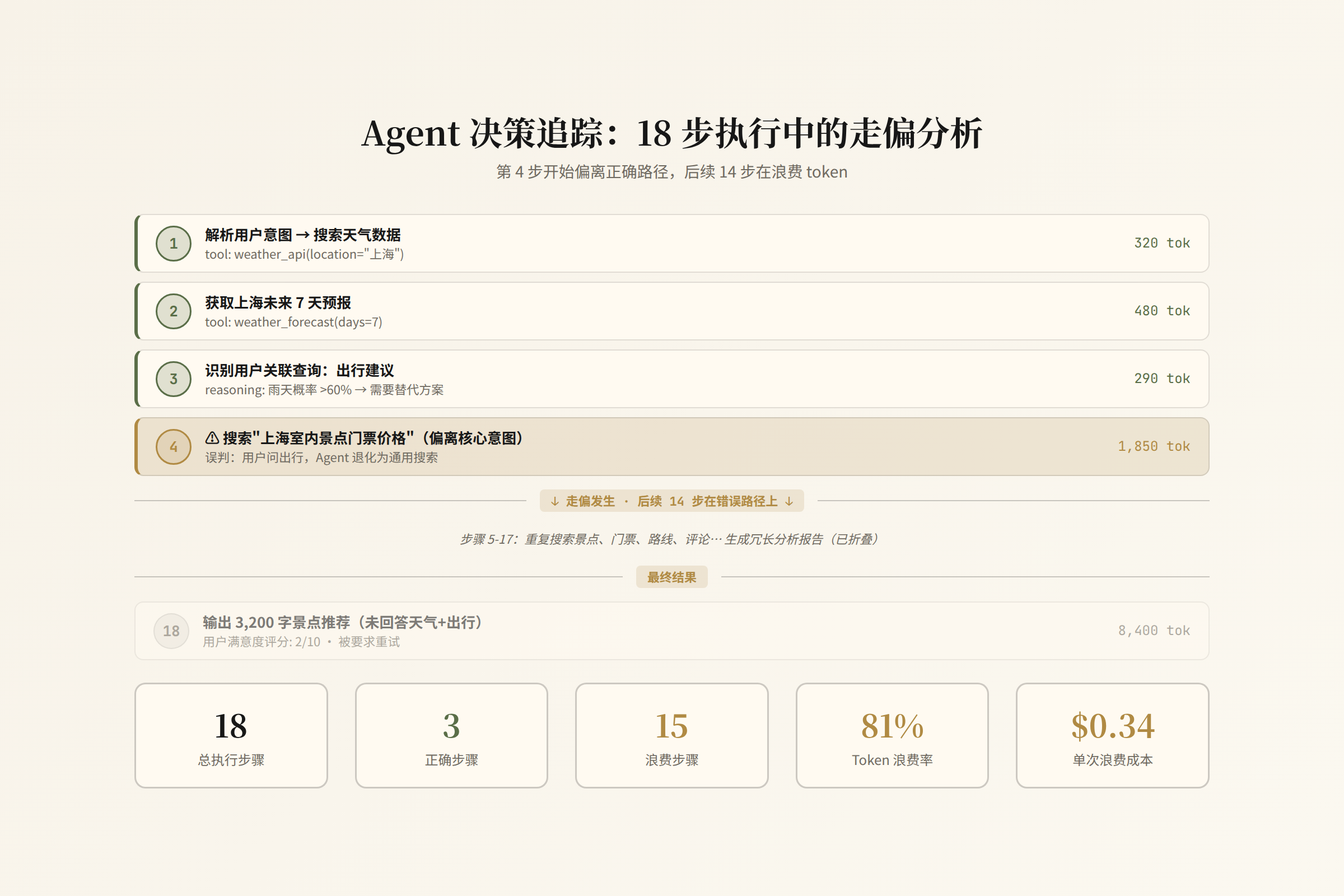
一个数据分析 Agent 的 18 步任务
想象一个企业内部的数据分析 Agent,接到任务:"分析过去 30 天我们的三个主要竞品的定价变化,找出谁在调价、调了多少、可能的原因。"
Agent 开始执行。18 步之后,它输出了一份报告。
这份报告看起来专业、结构清晰、数据详实。但它是错的——因为 Agent 在第 4 步把 "Company A" 和 "Company B" 的产品线搞混了,后面 14 步全部基于错误的对比在做分析。
我们用一个理想化的 Agent trace 把这 18 步拆开,看看每一步发生了什么、为什么传统监控看不到问题、以及什么样的观测能力才能发现它。
Trace 总览
Run #agent-20260620-001
Goal: 分析竞品定价变化
Duration: 4分32秒
Steps: 18
Tokens: input 187,000 / output 12,400
Cost: $1.72(按 Claude Opus 定价估算,含 prompt caching:80% input 命中缓存按 10% 计费)
Status: ✅ Completed (但结果是错的)
传统监控看到的是:Status = Completed,Duration = 272s,Cost = $1.72。一切正常。
逐步分解
Step 1 [Thought] 理解任务:分析三个竞品30天定价变化
Tool: web_search("Company A pricing 2026")
Result: 返回 10 条搜索结果
✅ 正确
Step 2 [Thought] 先从 Company A 开始
Tool: web_search("Company A product line pricing page")
Result: 返回 Company A 官网定价页面链接
✅ 正确
Step 3 [Thought] 获取 Company A 定价详情
Tool: web_fetch("https://company-a.com/pricing")
Result: 返回定价页面 HTML,包含 3 个产品线
✅ 正确
Step 4 [Thought] Company A 的 Enterprise 产品线从 $49/user/mo 涨到 $59
❌ 走偏:把 Company A 的 Team 产品线($49)和
Company B 的 Pro 产品线($49)搞混了。
原因:Step 3 返回的定价页面中,Company A 的
产品线命名为 "Team"、"Business"、"Enterprise",
但 Agent 把第二步搜索时看到的 Company B 广告
中的 "Pro $49" 错误关联了过来。
Tool: execute_sql("INSERT INTO pricing_data VALUES...")
Result: 写入了错误的数据
⚠️ 没有报错,写入成功
从 Step 4 开始,Agent 的一切分析都基于错误的前提。
Step 5 [Thought] Company A 涨价了 20.4%,记录这个发现
Tool: web_search("Company A price increase news")
Result: 没有找到相关新闻
❌ Agent 把没有找到新闻解读为"悄悄涨价"
Step 6 [Thought] 搜索 Company B 的定价
Tool: web_search("Company B pricing")
Result: 返回 Company B 定价页面
Step 7 [Thought] 获取 Company B 定价详情
Tool: web_fetch("https://company-b.com/pricing")
Result: 返回定价页面
Step 8 [Thought] Company B 的 Pro 产品线保持 $39 不变
✅ 对 Company B 的分析本身是正确的
但因为 Step 4 的混淆,后续比较都建立在错误基线上
Step 9 [Thought] 比较 Company A 和 Company B
Tool: execute_sql("SELECT ... FROM pricing_data")
Result: 返回错误数据(Step 4 写入的)
❌ 比较结果完全错误
Step 10 [Thought] Company A 涨价 20% vs Company B 不变,
Company A 在提价抢占利润
❌ 基于错误数据的错误结论
Step 11-15 [Thought] 继续分析 Company C、生成图表、写分析报告
全部基于 Step 4 的错误数据
Step 16 [Thought] 检查数据质量
Tool: execute_sql("SELECT COUNT(*) FROM pricing_data")
Result: 3 条记录
Agent 判断:数据完整 ✅
❌ 没有检查数据的正确性,只检查了完整性
Step 17 [Thought] 生成最终报告
Tool: generate_report(...)
Result: 一份格式完美但内容错误的报告
Step 18 [Thought] 任务完成
Output: "分析完成。Company A Enterprise 从 $49 涨到 $59..."
浪费量化
总 token 消耗:199,400
有效 token(Step 1-3 正确的探索):38,000(19%)
浪费 token(Step 4-18 错误路径):161,400(81%)
总成本:$1.72
浪费成本:$1.39(81%)
这次任务的 $1.72 里,$1.39 是在错误方向上烧掉的。 传统监控完全看不到这个浪费——每个 API 调用都返回了 200 OK。
Agent Trace 的数据模型
上面的 18 步拆解揭示了一个根本问题:Agent 的执行不是线性的请求链,而是一棵决策树——每一步都有多个可能的分支,Agent 的"选择"决定了路径。
传统 Trace vs Agent Trace
传统分布式 trace:
HTTP Request → Service A → Service B → DB Query → Service C → HTTP Response
这是一条线性链。每个 span 有 start_time、duration、service_name。OpenTelemetry 的数据模型完美表达。
Agent trace:
Goal → Thought ("我应该先搜 Company A")
→ Tool Call (web_search) → Result
→ Thought ("看起来 Company A 有 3 个产品线")
→ Tool Call (web_fetch) → Result
→ Thought ("Enterprise 从 $49 涨到 $59") ← 错误推断
→ Tool Call (SQL INSERT) → Result ← 错误数据写入
→ Thought ("Company A 涨了 20%") ← 基于错误前提
→ Thought ("没有新闻报道,可能是悄悄涨价") ← 错误归因
→ ...
这不是线性链,是一棵有分支的树。每个节点有:
- Thought:LLM 的推理过程(free text)
- Tool Call:工具名、参数、返回值
- Decision:为什么选择了这条路而不是另一条
- Assumption:Agent 在这一步做了什么假设
- Error:显性错误(异常、超时)
- Semantic Drift:隐性走偏(没有报错但方向偏了)
传统 OTel span 无法表达 Thought 和 Decision——它们是语义信息,不是结构化字段。这就是为什么需要专门的 Agent trace 数据模型。
OpenInference 的扩展
OpenInference(Arize 主导)在 OpenTelemetry 的 semantic conventions 上扩展了 AI 专用字段:
# 传统 OTel span
span.set_attribute("http.method", "POST")
span.set_attribute("http.url", "/api/chat")
span.set_attribute("http.status_code", 200)
# OpenInference span
span.set_attribute("llm.model", "glm-5.2")
span.set_attribute("llm.token_count.prompt", 45000)
span.set_attribute("llm.token_count.completion", 3200)
span.set_attribute("llm.cost", 0.064)
span.set_attribute("llm.tools_called", ["web_search", "execute_sql"])
span.set_attribute("llm.decision_path", "search → fetch → analyze")
span.set_attribute("llm.retrieval.context", "...")
这些字段让 trace 不仅能看到"调用了什么",还能看到"消耗了什么"和"选择了什么"。
agent-run:Agent 专用标准
agent-run(builderz-labs)更进一步,定义了 Agent 观测的原子单元:
Run
id: string
goal: string
status: running | completed | failed | abandoned
started_at: timestamp
finished_at: timestamp
total_cost: float
total_tokens: int
Step[]
id: string
type: thought | tool_call | error | handoff
content: string
result: string
duration_ms: int
cost: float
parent_step_id: string
这个结构比 OTel span 更适合 Agent 场景——它原生支持决策树、thought 文本、tool call 参数和返回值。但它还没有被主流 OTel 后端(Jaeger、Tempo、Datadog)支持,目前主要用于专用 Agent 观测工具(Atla、Langfuse 的 Agent 模式)。
"走偏"的检测
Agent 最难的观测问题不是检测错误——错误有异常、有错误码,传统方法能抓。最难的是检测"走偏":Agent 没有报错,但方向偏了。
三种检测方法
UC Berkeley 等团队的 MASFT 研究(2025) 对多 Agent 系统的失败模式做了系统分类:14 种故障模式,分 3 大类(规范/系统设计故障、Agent 间错位、任务验证和终止)。在 AppWorld 测试中,多 Agent 系统故障率高达 86.7%[1]。
方法一:语义偏移检测
在每一步 Agent thought 之后,用一个轻量评估模型判断"当前思考是否偏离原始目标":
评估模型输入:
Goal: "分析三个竞品的定价变化"
Current Step (Step 4): "Company A 的 Enterprise 产品线从 $49 涨到 $59"
评估模型输出:
relevance_score: 0.85(仍然相关)
confidence: 0.9
→ Step 4 不被认为是偏移
问题:语义偏移检测本身是一个 LLM 调用,有成本和延迟。如果每步都做,成本可能翻倍。而且像 Step 4 这种"错误但看似相关"的步骤,评估模型也很难识别——因为 Agent 的描述本身是连贯的,只是底层事实错了。
方法二:输出质量回归
在关键步骤设置 checkpoint——Agent 完成数据收集后、开始分析前,用一个验证器检查数据质量:
Checkpoint (Step 9 之后):
验证器检查: pricing_data 表中的数据是否合理?
- Company A Enterprise $59 ← 在合理范围内
- Company B Pro $39 ← 在合理范围内
- Company C ... ← 在合理范围内
验证器无法发现: Company A 的 Team 产品线被误标为 Enterprise
→ Checkpoint 通过,没有拦截
数据级的 checkpoint 能抓结构性异常(空值、格式错误、范围越界),但抓不了语义错误——数据看起来完全正常,只是对应错了对象。
方法三:行为模式异常
不检测单步的正确性,而是检测整个执行序列的模式是否异常:
正常 Agent 执行模式:
search → fetch → extract → store → search → fetch → ...
每步的 tool call 类型交替变化
异常模式示例:
1. 循环: search → fetch → search → fetch(同样的 query)
→ 可能陷入了信息检索循环
2. 过长链: thought → thought → thought → thought → ...(无 tool call)
→ 可能陷入推理幻觉,没有实际验证
3. 跳跃: search → skip_validation → skip_analysis → generate_report
→ 跳过了关键步骤直接出结论
行为模式检测不需要理解 Agent 的语义,只需要分析 tool call 序列的统计特征。这种方法成本低(不需要额外 LLM 调用),但精度有限——它只能检测结构化异常,不能判断每一步是否在正确方向上。
现状:没有银弹
三种方法各有局限:
| 方法 | 能检测什么 | 不能检测什么 | 成本 |
|---|---|---|---|
| 语义偏移检测 | 话题层面的偏移 | 事实层面的错误 | 高(每步一次 LLM 调用) |
| 输出质量回归 | 结构化数据异常 | 语义正确性 | 中(关键节点验证) |
| 行为模式异常 | 执行模式偏离 | 单步的正确性 | 低(纯统计分析) |
现实中的最佳实践是三者组合: 用行为模式检测做粗筛(成本低),用输出质量回归做关键节点验证,用语义偏移检测做高价值任务的全链路审核。

循环死锁
现象
Agent 陷入"搜索 → 读 → 搜索同一个东西 → 再读"的循环。每一步都成功执行(200 OK),但整个链条在空转。
近期行业探索(如 AgentDoG 类安全诊断工具)从 Risk Source、Failure Mode、Real-world Harm 三个维度分析完整 Agent 轨迹——不只是看最终输出,而是分析整个执行路径。AgentConductor(上交大 i-WiN + 美团, 2026)的发现同样有力:通过 RL 训练的 3B 参数指挥 Agent 动态生成交互拓扑,在竞赛级编程任务上实现准确率提升 14.6% 同时降低 68% token 成本[2]——这间接证明固定拓扑下多 Agent 通信中存在大量冗余信息传递。
一个真实模式的简化版:
Step 1: search("Company A pricing")
Step 2: fetch(company-a.com/pricing)
Step 3: search("Company A price change 2026")
Step 4: fetch(company-a.com/pricing) ← 重复
Step 5: search("Company A pricing plans") ← 和 Step 1 几乎相同
Step 6: fetch(company-a.com/pricing) ← 再次重复
Step 7: search("why Company A pricing") ← 再次近似
Step 8: fetch(company-a.com/pricing) ← 第三次重复
传统 APM:每个 API 都返回 200,每个页面都成功获取。没有异常。
Agent trace:search query 和 fetch URL 在语义空间中高度聚集。步骤间的信息增量趋近于零。
检测方法
Query 嵌入相似度: 把每一步的 search query 转成 embedding,计算与之前所有 query 的余弦相似度。如果连续 3 步的 query 相似度 >0.85,判定为循环。
工具返回信息增益: 比较当前步骤工具返回内容与历史返回内容的重叠度。如果 fetch 同一个 URL 的返回内容完全相同(页面没变),信息增益 = 0。
上下文增长率分析: 正常 Agent 执行中,context 长度应该持续增长(每步新增信息)。如果 context 增长率突然趋近于零——每步的净新增信息 <100 token——说明 Agent 在原地踏步。
自动干预
检测到循环后可以自动干预:
- 注入提示:在 Agent 的下一步输入中加入
"你似乎在重复搜索相同的信息。请尝试不同的搜索关键词或换一个方向。" - 强制换路:禁止 Agent 再次使用相同或语义相似的 query
- 人工升级:如果循环持续超过 5 步,暂停 Agent 并通知人类
上下文膨胀与推理质量衰减
问题
Agent 每一步都把工具返回结果加到 context 里。到第 15 步,context 可能已经 200K token——大部分是历史步骤的工具返回值(搜索结果、SQL 输出、API 响应)。
但模型的有效注意力不是均匀分布的。"Lost in the Middle"现象(Liu et al., 2023, arXiv:2307.03172)给出了令人不安的发现:GPT-3.5-Turbo 在关键文档位于中间位置时准确率约 54%,低于不提供上下文的闭卷准确率 56.1%[3]。Chroma 的 Context Rot 报告(2025.07,测试 18 款模型)进一步发现超过 32,000 tokens 后准确率即开始衰减[4]。
- 开头(system prompt、早期步骤):高注意力
- 中间(历史步骤的工具返回):低注意力——"盲区"
- 结尾(最新步骤的输入):高注意力
量化影响
研究表明,当 context 从 4K 增长到 128K:
- 开头和结尾的信息检索准确率下降 <5%
- 中间位置的信息检索准确率下降 20-40%
对 Agent 的影响:Agent 在 Step 3 获取的关键信息(Company A 的产品线命名为 "Team"、"Business"、"Enterprise"),到了 Step 10 做比较时,已经沉到 context 的中间位置——模型的注意力降低了。更糟的是,Liu et al.(2023)的经典研究发现 GPT-3.5-Turbo 在关键文档位于中间时的准确率(54%)甚至低于完全不提供上下文的闭卷准确率(56.1%)。**提供上下文反而有害——这对 Agent 架构的挑战是根本性的。**这正是 Step 4 混淆产品线的认知基础。
Context 管理
解决上下文膨胀的三种策略:
策略一:滑动窗口
- 只保留最近 N 步的完整记录
- 更早的步骤被摘要替代
- 缺点:摘要过程可能丢失关键细节
策略二:选择性保留
- 每步记录一个 "importance score"
- 重要性低的步骤被丢弃
- 缺点:如何判断重要性本身就是难题
策略三:外部记忆
- 工具返回结果存在外部存储(向量数据库)
- 每步从外部存储检索相关信息
- Context 只保留系统 prompt + 检索结果 + 最近 2-3 步
- 缺点:检索质量依赖 embedding 和索引
多 Agent Handoff 的信息丢失
场景
在一个多 Agent 系统中:
Agent A (数据收集) → Agent B (数据分析) → Agent C (报告生成)
Agent A 花了 10 步收集数据,中途:
- 考虑过但放弃了 2 个数据源(因为质量不够)
- 对数据的可靠性做了内部判断(Company B 的数据可能过时)
- 注意到一个异常但决定暂不处理(Company C 的价格突然翻倍,可能是爬虫错误)
Agent A 完成后,把"结果"交给 Agent B。但"结果"是什么?
通常 Agent A 交给 Agent B 的只是一个结构化数据集或一段总结文字。Agent A 在推理过程中考虑的备选方案、数据质量判断、观察到的异常——这些全部丢失。Agent B 拿着一个被极度压缩的信息做下一步分析。
信息丢失量化
Agent A 的完整认知状态:
- 事实数据: ~5,000 token
- 探索过程: ~15,000 token
- 数据质量判断: ~2,000 token
- 异常观察: ~1,000 token
- 被放弃的备选: ~3,000 token
总计: ~26,000 token
Agent A 传递给 Agent B 的内容:
- 结构化数据集: ~5,000 token
- 一段总结: ~500 token
总计: ~5,500 token
信息保留率: 5,500 / 26,000 ≈ 21%
Agent B 只拿到了 Agent A 21% 的认知状态。 那 79% 的丢失信息——质量判断、异常观察、被放弃的路径——可能在后续证明是关键的。
解法方向
Rich Handoff:不只传结果,传完整的推理 trace。Agent B 可以访问 Agent A 的所有 thought 和 tool call 历史。但这会让 Agent B 的 context 暴涨,触发上下文膨胀问题。
结构化元数据传递:Agent A 在传结果的同时,附带结构化元数据——数据质量评分、已知异常列表、被放弃路径的简述。这比完整 trace 更紧凑,但需要 Agent A 主动生成这些元数据。
共享记忆层:Agent A 和 Agent B 共享一个外部记忆存储。Agent B 在需要时从记忆中检索 Agent A 的推理细节。这避免了 context 膨胀,但引入了检索延迟和检索准确性问题。
安全观测:Agent 的审计需求
Agent 不是只读系统——它们调用 API、花钱、修改文件、发送消息。每一步操作都需要审计。
Deconvolute:MCP 防火墙
Deconvolute 是一个 client-side runtime 防火墙,包裹在 MCP(Model Context Protocol)工具调用之上:
Agent 决定调用 execute_sql("DELETE FROM users WHERE...")
↓
Deconvolute 拦截:
1. 检查 execute_sql 是否在允许的工具列表中 ✅
2. 检查参数是否匹配基线定义 ✅
3. 检查 SQL 类型是否被策略允许:
- SELECT ✅
- INSERT ⚠️ 需要确认
- DELETE ❌ 被策略禁止
- DROP ❌ 被策略禁止
4. 拦截,记录审计日志,返回错误给 Agent
每次工具调用被:
- 加密签名验证:确保工具定义未被篡改
- 策略匹配:与预定义的 policy baseline 对比
- 审计记录:调用参数、返回值、决策(允许/拒绝)全部写入不可篡改的日志
这不是观测——这是拦截。但从可观测性角度看,Deconvolute 的审计日志是最可靠的 Agent 行为记录:因为它是从工具调用层捕获的,不受 Agent 的自我报告影响。 Agent 可能会在 thought 中说"我在检查数据质量",但如果它的 tool call 是 DELETE FROM pricing_data,审计日志会忠实地记录这一点。
工具生态全景
| 工具 | 定位 | 优势 | 局限 |
|---|---|---|---|
| Langfuse | 开源 LLM 工程平台 | Trace + Prompt 管理 + Evaluation,ClickHouse 后端,框架无关 | Agent 层面的 thought/decision 追踪需要手动埋点 |
| Arize Phoenix | ML 工程导向 | OpenInference 原生支持,embedding 分析强 | 偏 ML 而非 Agent |
| Atla | Agent 专用 | 实时 thought/tool call 可视化,走偏检测 | 新产品,生态小 |
| agent-run | Agent trace 开放标准 | 定义了 Agent 观测的原子单元 | 标准阶段,无成熟实现 |
| Deconvolute | MCP 安全防火墙 | 工具调用级别的拦截和审计 | 只覆盖 MCP 工具 |
| Pydantic AI + Logfire | Python Agent + 观测 | 类型安全的 Agent 定义 + 原生 tracing | 绑定 Pydantic AI 框架 |
| LangSmith (LangChain) | LangChain 生态 | 与 LangChain/LangGraph 深度集成 | 绑定 LangChain 生态 |
| Salesforce Query-Driven Observability | 企业级 Agent 观测 | Spark-based,600 用户/4 亿记录验证 | 内部系统,不对外 |
Salesforce 的实践:从两周到一天
Salesforce 的 Agentforce 平台遇到了 Agent 可观测性的终极挑战:60+ AI 功能、600 名用户、4 亿条记录、800GB 数据。当 Agent 出错时,工程师需要两周才能定位问题。
他们的解决方案叫 Query-Driven Observability——不是预定义 dashboard,而是让工程师用 SQL 直接查询 production agent 行为数据:
-- 找出所有在 Step 5 之后 token 消耗突然增加的 Agent 运行
SELECT run_id, step_num, token_count, tool_called
FROM agent_traces
WHERE step_num > 5
AND token_count > avg_token_count * 3
ORDER BY token_count DESC;
-- 找出循环死锁的模式
SELECT run_id, tool_called, COUNT(*) as call_count
FROM agent_traces
GROUP BY run_id, tool_called
HAVING call_count > 5
ORDER BY call_count DESC;
-- 找出 handoff 后质量下降的案例
SELECT a.run_id, a.agent_name, b.agent_name,
a.quality_score, b.quality_score
FROM agent_results a
JOIN agent_results b ON a.run_id = b.run_id
WHERE a.step_type = 'handoff'
AND b.quality_score < a.quality_score * 0.7;
核心架构:Spark-based query engine + Notebook 环境 + 400M records 的 agent trace 数据。工程师可以在 Notebook 里交互式探索 Agent 行为模式。
效果:调试时间从两周缩到一天。 关键不是工具多复杂,而是给了工程师直接查询 Agent 行为数据的能力——从"看预定义 dashboard"到"自由提问"。
Agent 运行观测体系:从集群到个体
前面的章节分别拆解了 Agent 的决策路径、走偏检测、循环死锁、上下文膨胀和 handoff 信息丢失。但如果把这些观测点拼到一起,需要一个分层体系来组织——否则 14 种故障模式散落在不同工具里,没有统一的观测面板。
下面按三个层级组织观测体系:全局层(Agent 集群)、协同层(多 Agent 交互)、个体层(单 Agent 执行)。每层列出关键观测点、指标、推荐工具和埋点位置。
全局层:Agent 集群管理与资源调度
| 观测点 | 指标 | 工具 | 埋点位置 |
|---|---|---|---|
| Agent 实例健康度 | active / queued / failed_agents | Prometheus | 调度器 |
| 资源消耗 | CPU / mem / GPU 利用率 | cAdvisor | 容器 runtime |
| 任务分配公平性 | per_agent_task_count | 自定义分析 | 分发器日志 |
| 全局 token 消耗速率 | tokens/sec、burn_rate vs budget | Langfuse | API client 聚合 |
| 故障传播 | cascade_depth、blast_radius | OTel trace | Agent 间调用链 |
全局层回答的问题:整个 Agent 集群是否健康?有没有 Agent 在空转?token 预算是否在按预期消耗?一个 Agent 的故障是否在向其他 Agent 传播?
协同层:多 Agent 交互观测
| 观测点 | 指标 | 工具 | 埋点位置 |
|---|---|---|---|
| Handoff 质量 | information_retention_ratio | 自定义 logger | handoff 点 |
| 通信效率 | messages_per_task、redundant_ratio | OTel spans | 消息通道 |
| 拓扑有效性 | 实际 vs 最优通信路径 | 编排器日志 | 编排器决策 |
| 冲突检测 | contradiction_rate | LLM-as-judge | handoff 后 checkpoint |
| 循环死锁检测 | repeat_query_similarity > 0.85 | embedding 相似度 | 每次 tool call 前 |
协同层回答的问题:Agent 之间的信息传递是否保真?通信是否冗余?编排拓扑是否有效?有没有 Agent 在互相矛盾?有没有 Agent 在重复调用相同的工具?
个体层:单 Agent 任务执行观测
| 观测点 | 指标 | 工具 | 埋点位置 |
|---|---|---|---|
| 步骤级 trace | step_count / duration / type | Langfuse / agent-run | ReAct 循环 |
| 决策质量 | tool_selection_accuracy | 人工标注 + LLM 评估 | thought 后 |
| 走偏检测 | drift_score | 行为模式分析 | 每 N 步 |
| 工具调用审计 | tool / params / result / duration | Deconvolute / OTel | 工具拦截层 |
| Token 消耗分布 | tokens_by_step | Langfuse | LLM usage 字段 |
| 错误与恢复 | error_type / retry / recovery_success | 错误日志 | catch 块 |
个体层回答的问题:单个 Agent 的每一步是否在正确方向?工具选择是否合理?token 消耗是否集中在某几步?出错后能否自动恢复?
埋点代码示例
以 OpenTelemetry + OpenInference 风格埋点为例,展示个体层的步骤级 trace 和走偏检测如何落地:
@trace("agent.step")
async def execute_step(agent_id, step):
span = trace.current_span()
span.set_attribute("agent.id", agent_id)
span.set_attribute("agent.step_num", step.num)
span.set_attribute("agent.step_type", step.type)
if step.type == "tool_call":
span.set_attribute("tool.name", step.tool_name)
span.set_attribute("tool.duration_ms", step.duration_ms)
span.set_attribute("tool.success", step.success)
if step.num % 5 == 0:
drift = await assess_drift(step.task_goal, agent_history)
span.set_attribute("agent.drift_score", drift.score)
if drift.score < 0.5:
span.add_event("drift_warning", {"step": step.num})
关键设计:每一步都记录基础属性(agent id、步号、类型),tool call 额外记录工具名和耗时,走偏检测每 5 步触发一次——频率可调,是成本与精度的权衡点。
与 DD1 / DD2 的关联
这三层观测不是孤立的,它们与系列前两篇文章形成闭环:
- Agent 层「步数异常增加」→ DD1 成本告警:当个体层的 step_count 突然飙升,直接映射到 DD1 描述的 token 成本异常。观测体系的个体层是 DD1 成本告警的先行指标。
- Agent 层「推理质量下降」→ DD2 引擎 profiling:当 drift_score 持续恶化,可能是底层推理引擎的 KV cache 命中率下降或 batch 调度异常。DD2 的引擎级 metrics(GPU 利用率、cache hit rate)提供了 Agent 质量下降的根因解释。
- Agent 层「handoff 信息丢失」→ 架构改进信号:协同层的 information_retention_ratio 如果持续低于 30%,说明多 Agent 架构本身需要重新设计——这不是调参能解决的,是架构层面的决策。
从 DD1 的「钱花在哪」到 DD2 的「引擎为什么慢」,再到 DD3 的「Agent 为什么走歪」,三层观测拼在一起才是完整的 AI 可观测性体系。
工具现状与挑战
现状:Langfuse 支持基础的 Agent trace——thought 和 tool call 可以通过手动埋点记录,配合 ClickHouse 后端做查询。agent-run 定义了 Agent 专用的 trace schema(Run → Step → Thought/ToolCall/Handoff),但还停留在标准阶段,没有成熟的工程实现。Deconvolute 从安全角度做 MCP 工具调用的 policy-as-code 审计,是工具调用层最可靠的拦截和日志来源。Atla 做 Agent thought 的实时可视化,在走偏检测方向有探索。但大多数 Agent 框架(LangChain/AutoGen/CrewAI)自带的可测性非常薄——基本只提供"日志打印"级别的 trace,缺少结构化的 span 和语义属性。
挑战:
-
Agent trace 没有事实标准。每个框架用自己的格式:LangChain 的 LangSmith trace、AutoGen 的 conversation log、CrewAI 的 execution log 结构互不兼容。数据不互通意味着你不能用 Langfuse 同时看 LangChain Agent 和 AutoGen Agent 的 trace——除非手动适配。
-
Thought 是非结构化文本,现有工具只能记录不能分析。一个 18 步的 Agent 任务产生 18 段 thought 文本,共约 3,000-5,000 token。自动评估 thought 质量(是否相关、是否准确、是否有逻辑跳跃)需要额外的 LLM 调用——成本和延迟都很高。结果是 thought 分析只在事后审计中偶尔发生,不是实时监控。
-
走偏检测的召回率太低。行为模式异常只能检测结构性问题——循环(search → fetch → search 重复)、空转(连续 thought 无 tool call)、跳跃(跳过验证直接出结论)。但语义层面的走偏——比如 Step 4 把 Company A 和 Company B 的产品线搞混——行为模式完全正常(tool call 类型和频率没异常),只有理解 Agent 的语义才能发现。这类走偏仍需人工审查。
-
多 Agent handoff 的信息丢失没有被任何现有工具量化。当一个 Agent 把结果交给下一个 Agent 时,当前工具只记录"handoff 发生了"和"传递了什么数据"——不记录"Agent A 的认知状态有多大比例传到了 Agent B"。没有 information_retention_ratio 的自动度量,信息丢失是一个看不见的问题。
对工具体系的要求:
- 需要 Agent trace 的 OTel 兼容标准——让 Agent trace 能进入现有的可观测性基础设施(Jaeger/Tempo/Datadog),而不是只能在专用工具里看。OpenInference 正在推动这个方向,但 Agent-specific 的 thought/decision/handoff 字段仍未标准化
- 需要低成本的 thought quality 评估——用轻量模型(如 1-3B 参数的 classifier)做实时 thought 质量打分,而不是每次都调用完整 LLM。这需要在准确率和成本之间找到合适的平衡点
- 需要 handoff 信息保真度的自动度量——自动计算 Agent A 到 Agent B 的 information_retention_ratio,让信息丢失从"看不见的问题"变成"可追踪的指标"
判断:2026 年最大的空白市场
Agent 可观测性是 AI 基础设施领域中需求最迫切、供给最不足的方向。
LLM 应用观测(Langfuse/Phoenix)已经相对成熟。推理引擎 profiling(Graphsignal/vLLM metrics)在快速完善。但 Agent 观测——thought 追踪、走偏检测、循环死锁发现、handoff 信息丢失——还在非常早期的阶段。
标准之争是核心战役。 OpenInference 试图把 Agent trace 纳入 OpenTelemetry 体系。agent-run 在定义自己的 Agent 专用 schema。Langfuse 在用自有的 trace 格式。如果标准统一,数据可以互通,工具可以组合。如果碎片化,每个 Agent 框架造自己的观测孤岛——就像微服务时代每个公司造自己的 RPC tracing。
谁会赢? 判断:
- 短期(6 个月):Langfuse 凭开源 + 框架无关 + 先发优势,成为 LLM/Agent 观测的事实标准。类似微服务时代的 Jaeger。
- 中期(1 年):OpenTelemetry + OpenInference 会推动标准化。大厂(Datadog/New Relic)通过收购进入。
- 长期:Agent 观测从"事后分析"变成"实时干预"——检测到走偏自动纠正、检测到循环自动注入提示、检测到 handoff 信息丢失自动补充上下文。可观测性和执行不再分离。
对于构建 AI Agent 的团队:现在就用 Langfuse(或 Phoenix)做基础 tracing,在关键节点设 checkpoint,关注 agent-run 标准的进展。不要等到 Agent 在生产环境大规模出问题才开始建观测能力。
引用
[1] Berger et al., "Why Do Multi-Agent LLM Systems Fail?" arXiv:2503.13657 (2025). UC Berkeley & Intesa Sanpaolo.
[2] Wang et al., "AgentConductor: Topology Evolution for Multi-Agent Competition-Level Code Generation", arXiv:2602.17100 (2026). 上海交通大学 i-WiN & 美团。
[3] Liu et al., "Lost in the Middle: How Language Models Use Long Contexts", arXiv:2307.03172 (2023). Stanford, UC Berkeley, Samaya AI.
[4] Chroma, "Context Rot: How Language Models Lose Accuracy Over Long Contexts", 2025. 见 chromaDB research。
[5] Salesforce Engineering, "Query-Driven Observability for Agentforce", 2025. 见 Salesforce Engineering Blog。Spark-based query engine + Notebook 环境,处理 400M agent trace records。
本文是 AI 可观测性系列的最后一篇。系列全文:主文:三层盲区 · DD1:推理账单解剖 · DD2:推理引擎内部 · DD3:Agent 决策路径