2026 年 6 月 23 日,ISC 2026 汉堡,TOP500 新榜:中国「灵晟」(LineShine)2.19 EFLOPS FP64 登顶,全球首台持续性能突破 2 EFLOPS。47,000 颗 CPU,零 GPU,从处理器到互联网络全栈国产。
与此同时,TOP500 前十里另外四台 Exascale 系统——El Capitan、Frontier、Aurora、JUPITER——全部走 CPU+GPU 异构。上一代纯 CPU 超算冠军富岳(Fugaku),2026 年已跌至第六,且日本已宣布下一代 Fugaku-NEXT 将转向 ARM CPU + NVIDIA GPU 异构。
纯 CPU 路线是走到了终点,还是刚打开一扇新的门?
灵晟提供了一个前所未有的分析样本:它是史上最强的纯 CPU 超算,同时有三篇 arXiv 论文详细记录了真实负载的性能数据。把它拆开看——CPU 微架构、互联网络、端到端软件路径、三篇论文的实证——可以判断这条路线当前的能力边界和未来的扩展空间。
一、LX2 处理器:在已知面积里放 304 个核
1.1 工艺与芯片面积推算
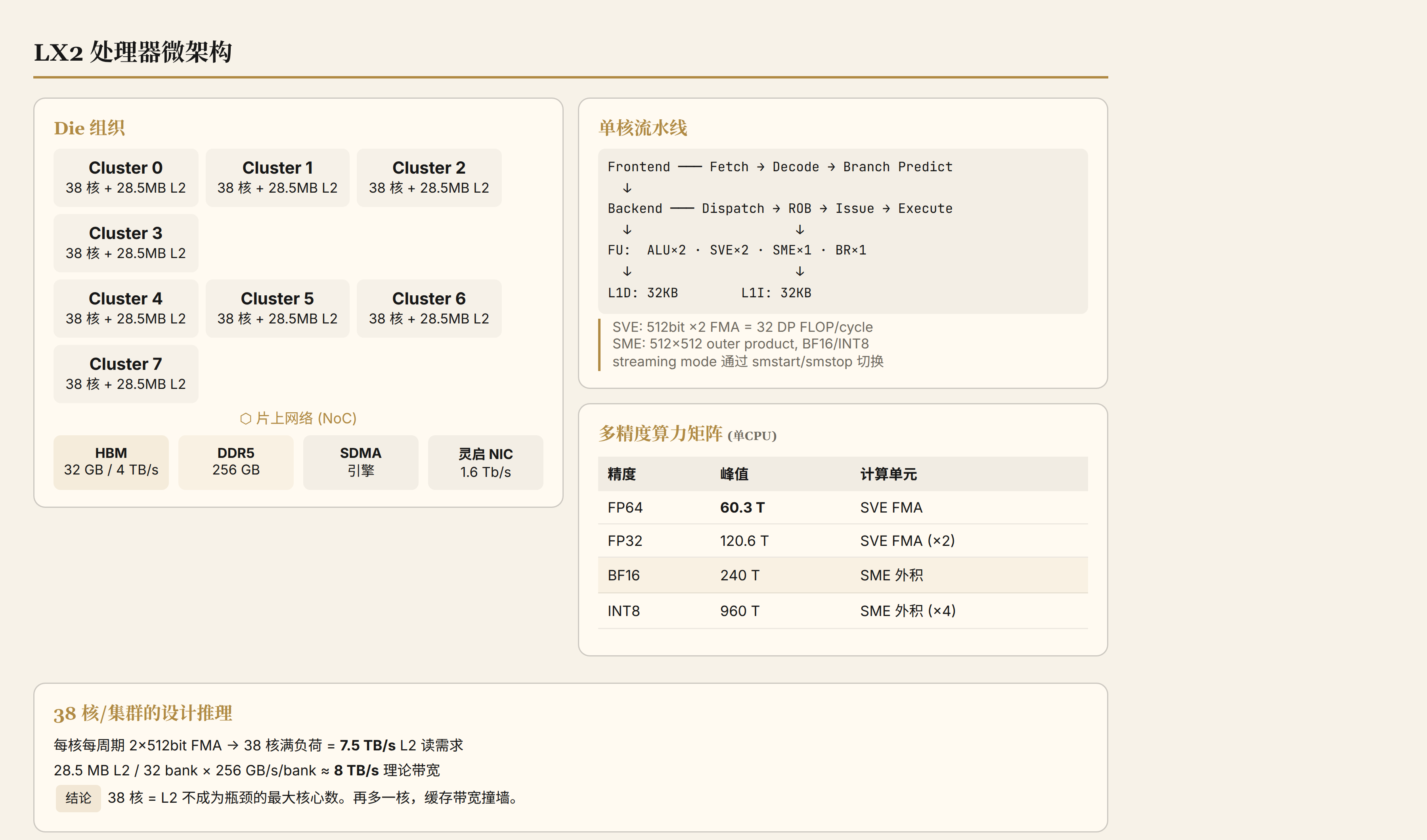
灵晟的核心是 LX2 处理器:304 核、ARMv9 架构、1.55 GHz 基础频率、每 CPU 集成 32 GB HBM(4 TB/s)。
工艺节点未公开。从可用的公开信息做约束推算:
参照系一:富士通 A64FX。 TSMC 7nm,48 核(含 4 辅助核)+ 4 组 HBM2 控制器,芯片面积 约 480 mm²,集成 87.86 亿晶体管。每核(含分摊的 L2 和控制器)约 10 mm²。
参照系二:ARM Neoverse V2。 在 TSMC 5nm 下的物理实现,单核(含 1MB private L2)约 2-3 mm²。Neoverse N2 在 7nm 下约 3-4 mm²/核。
LX2 的面积约束。 如果用 SMIC 7nm 工艺(国产 HPC 芯片当前最可能的节点),SMIC 7nm 的晶体管密度约 90-100 MTr/mm²(N+1 级别),低于 TSMC N7 的 91 MTr/mm² 和 N5 的 173 MTr/mm²。LX2 的 304 核如果单 die 集成,按 3-4 mm²/核(7nm 级别核心 + 分摊 L2),仅核心区域就需要 900-1200 mm²。加上 8 组 HBM 控制器、灵启 NIC、DDR5 控制器、SDMA 引擎、I/O PHY,总面积会达到 1400-1800 mm²。
7nm 光刻的 reticle limit 是 858 mm²。 单 die 放不下。
推论:LX2 几乎确定是 chiplet 设计。 最可能的方案是 2 个计算 chiplet(每个 4 集群 × 38 = 152 核,约 600-700 mm²)加 1 个 I/O die(HBM 控制器、DDR5 控制器、NIC、SDMA)。这跟 AMD Zen 系列的 chiplet 架构思路一致——计算 die 用先进工艺,I/O die 可以用更成熟、更便宜的工艺。
chiplet 方案对性能有直接影响:同一 chiplet 内的 4 个集群之间通信延迟低(共享 L2 或 ring),跨 chiplet 的 4 个集群通信要走 I/O die,延迟更高。这形成了一个两级 NUMA:
| 层级 | 范围 | 延迟特征 |
|---|---|---|
| L2 本地 | 同集群 38 核 | ~15-20 周期 |
| Die 本地 | 同 chiplet 4 集群 | ~30-50 周期 |
| 跨 Die | 跨 chiplet 4 集群 | ~80-150 周期 |
| 跨 CPU | 节点内另一颗 LX2 | ~200-400 ns |
| 跨节点 | 灵启网络 | ~1-5 μs |
这个 NUMA 层级直接影响 MPI 进程绑定策略——通信密集的进程对应放在同一 chiplet 上。
1.2 微架构:对照 ARM Neoverse V2
LX2 的微架构参数未公开。但 ARMv9 架构规范和 ARM 自研参考核心(Neoverse V2/V3)给出了合理推测基准。Neoverse V2 是 ARM 面向 HPC 和云的旗舰核心,也是目前公开的最接近 LX2 定位的 ARMv9 核心。
| 参数 | Neoverse V2(公开) | LX2(推测) |
|---|---|---|
| 解码宽度 | 5-6 条/周期 | 同级别 |
| ROB 深度 | 320+ | 同级别 |
| 物理寄存器(INT/FP) | 288/256 | 可能更大(HPC 负载) |
| SVE 向量宽度 | 128/256/512 bit | 512 bit(已确认) |
| SME | 无 | 有(LX2 独有的关键扩展) |
| L2 缓存 | 每核 1-2 MB private | 每集群 28.5 MB 共享(不同设计) |
LX2 跟 Neoverse V2 最显著的差异在两处:
差异一:L2 架构完全不同。 Neoverse V2 用每核 private L2(1-2 MB),LX2 用每集群 38 核共享 L2(28.5 MB)。共享 L2 的优势是总容量大(8 × 28.5 = 228 MB vs 304 × 1 = 304 MB,差距不大,但共享方式让同集群的核心可以复用彼此加载的数据)。代价是 38 核争同一个 L2 的 bank 和带宽。前文推算过:38 核满负荷 FMA 对 L2 的带宽需求约 7.5 TB/s,而 28.5 MB / 32 bank × 256 GB/s/bank ≈ 8 TB/s——刚好卡住。38 核就是这个 L2 配置下的最大核心数。
差异二:SME 集成。 Neoverse V2 不含 SME(ARM 在 V3 世代才计划集成)。LX2 自行集成了 SME——这需要在核心微架构中增加一条独立的矩阵执行流水线、一个 2D 累加器寄存器文件(ZA tile),以及 streaming mode 的状态切换逻辑。这些额外的硬件大约占核心面积的 15-25%。
如果 LX2 基于 V2 衍生,集成 SME 后的单核面积约 3.5-5 mm²(7nm)。如果是从头自研,面积差异取决于设计团队对前端和后端的裁剪——可能会缩减整数 ALU 数量来给 SME 腾面积。
1.3 SME:CPU 上的矩阵加速
SME(Scalable Matrix Extension)是 ARMv9 架构中面向矩阵计算的指令集扩展。它引入了一种新的执行模式——streaming SVE mode,在这个模式下,处理器使用专门的 2D 累加器(ZA tile)执行外积(outer product)运算,一个周期内完成一个矩阵乘法的部分计算。
LX2 的每核 SME 流水线在 BF16 下每周期可以完成一次 512×512 bit 的外积累加。304 核 × 1.55 GHz → 240 TFLOPS BF16。对比 Neoverse V2 在同频率下没有 SME,BF16 算力为零(只能用 SVE 做 BF16 FMA,效率低 4-8 倍)。
SME 的编程模型需要特别注意。进入 streaming mode 使用 smstart 指令,退出使用 smstop。切换代价未公开,但从 ARM 架构规范推断大约 20-100 周期。这意味着在一次 kernel 调用中频繁切换 SVE 和 SME 是不经济的——最好一个 kernel 要么全程 SME(GEMM),要么全程 SVE(逐元素操作)。D2AR 论文中描述的 "asymmetric SME-GEMM" 调度策略印证了这一点:SME 和 SVE 的使用不是对等混合,而是以 SME 为主、SVE 在 SME pipeline 的间隙做辅助。
1.4 内存层级
LX2 的内存子系统有三层物理介质:
L1/L2 缓存。 每核 32 KB L1-I + 32 KB L1-D,每集群 28.5 MB L2 共享。L2 的 228 MB 总量(8 集群合计)处于 HPC CPU 的中等水平——Intel Sapphire Rapids 的 L2 是每核 2 MB(56 核 = 112 MB),AMD Genoa 的 L3 是共享 256-384 MB。LX2 的共享 L2 设计在集群内复用率高,但跨集群的 cache coherence 需要跨 chiplet 通信。
HBM。 32 GB,4 TB/s 带宽。带宽密度 125 GB/s 每 GB——远高于 H100 的 42 GB/s 每 GB(80 GB / 3.35 TB/s)。这种"小而快"的设计适合频繁访问小批数据的科学计算,但 32 GB 的容量是 AI 训练的硬约束(一个 6.3B 参数模型的训练状态需要约 50 GB)。
DDR5。 最高 256 GB,带宽约 200-400 GB/s。用作 HBM 的溢出层——通过 SDMA 引擎在 HBM 和 DDR5 之间按需调度数据。
SDMA(Software-defined DMA)引擎。 位置在 I/O die,负责 HBM ↔ DDR5 之间的数据搬运。D2AR 论文描述了它的使用方式:根据算子类型(compute-bound 还是 memory-bound)和中间结果的生存期,动态决定哪些数据驻留 HBM、哪些 evict 到 DDR5。调度粒度为 page 级(4 KB)。这是一个硬件辅助的分层内存管理机制——不是操作系统做的透明 swap,而是应用通过驱动接口显式控制。
1.5 多精度算力的物理含义
| 精度 | 单 CPU 峰值 | 计算单元 | 场景 |
|---|---|---|---|
| FP64 | 60.3 TFLOPS | SVE FMA | 科学计算(CFD、气象、分子动力学) |
| FP32 | 120.6 TFLOPS | SVE FMA | uMLIP 训练(量子精度需要) |
| BF16 | 240 TFLOPS | SME 外积 | AI 训练 |
| INT8 | 960 TOPS | SME 外积 | AI 推理 |
对比 H100:FP64 34 TFLOPS(不含 Tensor Core)、BF16 989 TFLOPS。LX2 在 FP64 上碾压 H100(1.8 倍),在 BF16 上只有 H100 的 24%。
这个对比的物理含义:LX2 的 SVE 向量单元面积大、SME 矩阵单元面积小。这是科学计算优先的芯片面积分配——把更多硅片面积给 FP64 向量运算,把更少给矩阵乘法。跟 GPU 的面积分配完全相反(GPU 把大部分面积给 Tensor Core)。
如果未来 AI 负载继续增长、科学计算负载占比下降,这个面积分配就需要翻转——但翻转后 LX2 就变成了一颗"带 ARM CPU 的 GPU",失去了纯 CPU 路线的编程简单性。
二、从节点到系统
2.1 计算节点
每个计算节点搭载 2 颗 LX2。两颗 CPU 之间的一致性互联方式未公开,可能是基于 ARM CMN(Coherent Mesh Network)的 mesh 互联,也可能是华为的 UB(Universal Bus)技术——后文分析。
节点上行带宽 1.6 Tb/s。这意味着两颗 LX2 共享一个网络出口——即使 CPU 内部 HBM 带宽充裕,跨节点通信受限于这个 1.6 Tb/s 上行。
2.2 机柜与物理规模
| 组件 | 数量 | 关键参数 |
|---|---|---|
| 计算机柜 | 92 | ~200-250 节点/柜,估算 300-400 kW/柜 |
| 网络机柜 | 36 | 灵启交换机、线卡 |
| 存储柜 | 67 | 428 存储节点,650 PB,10 TB/s 聚合带宽 |
| 核心 | 13,789,440 | HPL 测试所用 |
| 功耗 | ~40 MW | |
| 散热 | 100% 液冷 | 57.9 MW 冷负荷,PUE 推测 1.05-1.15 |
| 能效 | 51 GFLOPS/W | vs El Capitan 58.9,vs 富岳 16 |
51 GFLOPS/W 的能效意味着每瓦特电功率产出 51 GFLOPS 的持续 FP64 算力。El Capitan 的 58.9 GFLOPS/W 高出 15%——差距主要来自工艺(TSMC 5nm vs 国产 7nm 级别)和架构(MI300A APU 的 GPU 计算密度更高)。
液冷系统由中国中元设计,集中式 CDU 架构,二次管道总长 3214.7 米,循环水泵 315 kW,单台板换 8700 kW。14 路 20 KV 高压直流配电。

2.3 灵启互联:华为 UB 假说
灵启(LingQi)是灵晟的自研互连网络。双平面多轨胖树拓扑,每节点 1.6 Tb/s,100 万端口组网能力。
公开材料没有描述灵启的协议栈细节。但从已知信息推断,灵启跟华为的 UB(Universal Bus)高速互联技术有较高概率存在技术关联:
线索一: 灵晟的 LX2 跟华为鲲鹏体系高度相关。发布会提到华为参与,灵晟的生态对接鲲鹏。华为内部有成熟的超节点互联技术——灵衢软件(内核层)+ 硬件互联(包括 UB 物理层)。灵晟的"灵启"和"灵衢"命名甚至跟华为灵衢体系一致。
线索二: 1.6 Tb/s 的每节点带宽跟华为超节点方案的节点级互联带宽量级匹配。华为在昇腾集群中使用的 HCCS(Huawei Cache Coherent System)互联也是类似带宽级别。
线索三: 灵晟从设计到部署的时间线(约 3-4 年)跟华为 UB 技术的成熟期重叠。如果灵启完全从零设计,这个时间不够。
假说: 灵启可能是华为 UB 物理层 + 深圳超算团队自研的上层协议(MPI 适配、集合通信优化)的混合方案。物理层和链路层复用华为技术,网络层和传输层针对超算场景定制。
这个假说对分析的含义: 如果成立,灵启不是"一个团队从零做出的网络",而是"华为商用互联技术的超算级扩展"。这意味着灵启的可靠性有华为大规模出货的硬件验证背书,但协议层定制部分的成熟度需要看实际运行数据。
端口数推算: 20,480 节点 × 每节点多端口(假设 4 条 rail,每 rail 400 Gb/s = 1.6 Tb/s)。两层胖树:Leaf 层需要 20,480 个接入端口,假设 64 端口 Leaf 交换机 → 320 台 Leaf。Spine 层为 320 台 Leaf 提供上行 → 约 160-320 台 Spine。Core 层连接双平面 → 约 80-160 台 Core。总交换机约 560-800 台,总端口约 70-100 万——跟"100 万端口"的公开数字吻合。

2.4 存储
67 个存储柜、428 存储节点、650 PB 总容量、10 TB/s 聚合带宽。每个存储节点约 1.5 PB 容量和 23 GB/s 带宽——典型的 Lustre OSS(Object Storage Server)配置。是否部署 burst buffer(NVMe 缓存层)未公开。
三、软件:从代码到 SME 指令
3.1 编译器
LX2 的编译器选型未公开。ARM HPC 生态的选项是 LLVM/Clang 或 GCC,两者都支持 SVE 自动向量化。SME 的编译器支持较新——LLVM 主线对 SME intrinsic 和 streaming mode 的完整支持在 2024-2025 年逐步合入。
如果 LX2 的工具链基于较早的 LLVM fork,SME 自动向量化覆盖率会低于最新主线。实际使用中,高性能 kernel 几乎必然需要手写 SME intrinsic——编译器自动生成在复杂 kernel 上可能比手写慢 2-5 倍。
一段典型的 SME 外积矩阵乘法 kernel:
// SME outer product: C += A × B (BF16 → FP32 accumulate)
__arm_new("za")
void sme_gemm(bfloat16_t *A, bfloat16_t *B, float *C, int M, int N, int K) {
svbool_t pg = svptrue_b16();
for (int k = 0; k < K; k++) {
svbfloat16_t va = svld1_hor_bf16(pg, &A[k * M]);
svbfloat16_t vb = svld1_ver_bf16(pg, &B[k * N]);
svmopa_za16_bf16_m(pg, ZA0, va, vb); // 外积累加到 ZA
}
svst1_hor_bf16(pg, C, svread_hor_za16_bf16(ZA0)); // 写回
}
svmopa_za16_bf16_m 是核心:一个周期内完成 512×512 bit 的外积累加。ZA 是 SME 专用的 2D 寄存器阵列,跟 SVE 的 1D 向量寄存器 z0-z31 分开管理。进入 streaming mode 后 SVE 的部分 predicate 功能受限。
3.2 AI 框架调用链
从 PyTorch 到 LX2 硬件的路径:
torch.nn.Linear → PyTorch dispatcher → oneDNN ARM 后端
→ ARM Compute Library (ACL) GEMM kernel → SME intrinsic/汇编
→ ZA 累加器 → L2 → HBM
ARM Compute Library(ACL)是 ARM 官方开源计算库,为 ARM CPU 提供 BLAS、CNN 等 kernel。ACL 上游对 SME 的优化 kernel 在 2024-2025 年才陆续加入。LX2 是否直接使用 upstream ACL 还是 fork 定制未公开——但 D2AR 论文团队自行实现了 SME-GEMM 优化("reuse-directed asymmetric"调度),暗示 upstream ACL 在 LX2 上的性能不够理想。
PyTorch 在 ARM CPU 上可以运行训练,但分布式训练(DDP/FSDP)在 4 万颗 CPU 上的稳定性是开放问题——PyTorch 的 Gloo 后端对超大集群有已知扩展性瓶颈,MPI 后端更可行但需要定制。
3.3 MPI 与 software-defined streams
灵晟的 MPI 实现大概率是基于 MPICH 或 OpenMPI 的定制版,底层通过 libfabric 或 UCX 适配灵启网络。
在 1380 万 ranks 的规模下,集合通信算法的选择直接影响效率:
- AllReduce: recursive doubling 需要 log₂(13.8M) ≈ 24 步,每步全局同步。ring algorithm 数据旋转传递,对带宽更友好但延迟更高。在灵晟的胖树拓扑下,ring 的物理路径可以优化为最小跳数。
- AlltoAll: MoE 路由的核心操作。O(P²) 个消息在 4 万 ranks 下是主要通信瓶颈。MatRIS-MoE 论文中的 "atom-type-aware communication compression" 就是对 AlltoAll 数据量的压缩。
Software-defined streams。 论文中多次提到但未定义。从上下文推断:这是把 MPI 通信操作建模为有向无环图(DAG)的节点,运行时按拓扑序并行执行无依赖的通信,CPU 核心同步执行计算 kernel。效果是通信与计算重叠率超过 80%——原本串行执行的时间中,80% 的通信被异步隐藏。
3.4 OS 与大规模运维
麒麟 Linux 内核。在 304 核/CPU × 4 万颗 CPU 的规模下:
OS noise。 内核线程(kworker、kswapd、时钟中断)的随机调度会产生微秒级延迟尖峰。在全局同步的 MPI 操作中,最慢进程决定全局性能。解决方法是中断亲和性绑定(把所有中断路由到专用核心)和内核线程绑核。
作业启动。 在 1380 万核上启动 MPI 作业,标准 SSH-based 启动需要数分钟。HPC 系统用 PMI(Process Management Interface)分层启动树把延迟控制在秒级。
Checkpoint。 全系统作业的 checkpoint 数据量可能达到 PB 级。以 10 TB/s 存储带宽写 1 PB 需要约 100 秒理论值,实际因并发争抢和元数据操作更长。Checkpoint 频率需要在数据安全和工作效率之间取平衡。

四、实证:从三个案例推演纯 CPU 集群的能力上限
三个案例不是孤立的论文验证,而是三个探针——分别测试纯 CPU 架构在不同负载形态下的效率边界。把它们放在一起读,可以推出灵晟的能力天花板在哪里。
4.1 MatRIS-MoE:为什么 CPU 在二阶导数训练上赢了 GPU
MatRIS-MoE 是中科院计算所设计的通用机器学习原子间势(uMLIP)模型,用神经网络替代 DFT(密度泛函理论)计算原子间相互作用力。11.5B 参数 MoE 架构,4.73 亿组态,3.6 万亿交互边。
理解 CPU 为什么在这个负载上赢 GPU,需要拆开 uMLIP 训练的三个特殊性:
特殊性一:二阶导数。 LLM 训练只需要一阶梯度(∂L/∂θ),uMLIP 训练需要力的匹配——力是能量对坐标的一阶导数的负值(F = -∂E/∂X)。自动微分框架必须走两次反向传播:第一次从能量到力,第二次从力到参数梯度。第二次反向传播在计算图上是"梯度的梯度",中间激活的数量和内存占用是一阶训练的两倍以上。
GPU 的 Tensor Core 针对一阶密集矩阵乘法做了深度优化——tile 形状固定(16×16 或 32×32)、数据预取模式可预测、流水线排布高度规整。二阶自动微分的计算图完全不规整:每个原子的力贡献依赖其邻居的坐标和能量,邻居数量和拓扑结构随分子系统变化。这种不规则性让 Tensor Core 的 tile 预取失效,利用率急剧下降。
CPU 的 SVE 向量单元没有 tile 形状约束。二阶梯度的中间激活直接在 HBM 中分配,通过 SDMA 按需调入 L2。编程模型跟一阶训练完全一样——只是多走一遍反向传播。这种灵活性是 CPU 架构的固有优势。
特殊性二:FP32 是硬约束。 量子精度的模拟如果降到 BF16,力预测的误差会累积到分子动力学轨迹发散。所以 uMLIP 训练必须用 FP32。
GPU 的 FP32 算力分两档:"普通" FP32(CUDA Core,H100 约 67 TFLOPS)和 Tensor Core FP32(约 330 TFLOPS,但 tile 约束严格)。二阶导数的不规则图只能用"普通" FP32 路径,峰值 67 TFLOPS。
LX2 的 SVE 在 FP32 下原生满速:每核每周期 2 × 512 bit FMA = 16 次 FP32 运算。304 核 × 1.55 GHz = 120.6 TFLOPS,是 H100 "普通" FP32 的 1.8 倍。这个算力差距直接转化为利用率差距。
特殊性三:边就是 token,3.6 万亿条。 GNN(图神经网络)的消息传递沿边进行,边是计算的基本单元。3.6 万亿条边的访存模式完全不规整——邻接表是变长的、距离和角度三元组无法对齐打包。这跟 LLM 的 token(固定维度、连续内存、规整 batch)形成鲜明对比。GPU 的 Tensor Core 需要规整 batch 才能发挥峰值,不规整访存的效率损失严重。CPU 的乱序执行和硬件预取对不规整访存的容忍度更高。
实测数据。 灵晟 12.4M ARMv9 核心,FP32 峰值 1.2 EFLOPS,利用率 35.5%。CNIS GPU 集群(45K GPU 核心),FP32 峰值 1.0 EFLOPS,利用率 25.4%。差 10.1 个百分点。归一化吞吐量 3201 倍于此前 SOTA(UMA,256 H200 训练 21 天)。
能力上限推演。 CPU 的优势在这个案例中是结构性的——只要 uMLIP 训练需要二阶导数 + FP32 + 不规则数据,CPU 架构就跟这个负载天然适配。但这个优势有一个前提:HBM 带宽够用。MatRIS-MoE 的单组态数据量不大(几百原子的局部图),32 GB HBM 足以容纳多个组态的中间激活。如果未来 uMLIP 模型继续扩大——比如从 11.5B 到 50B+——单组态的中间激活可能超出 HBM 容量,SDMA 调度开始成为瓶颈,CPU 的利用率优势会被内存延迟侵蚀。
另一个边界:35.5% 的 FP32 利用率意味着 64.5% 的时间花在了非计算上——通信、内存访问、调度。在 12.4M 核心规模下,通信开销随核心数呈 sub-linear 增长(AllReduce 的 log 步数、AlltoAll 的 O(P²) 消息数)。如果把灵晟规模再扩大 2 倍到 25M 核心,通信占比可能从当前的 ~10% 升到 15-20%,FP32 利用率会降到 30% 以下。灵晟的规模接近纯 CPU uMLIP 训练的甜蜜点——再大,通信开销开始侵蚀效率。
4.2 D2AR:32 GB HBM 是 AI 训练的天花板
D2AR 是清华/中山大学团队的对地观测生成压缩模型,利用历史遥感档案训练一个生成式压缩器,实现 100× 到 10,000× 的数据压缩。6.3B 参数 Dense Transformer,BF16 精度,全系统 40,960 颗 LX2 训练。
持续性能 1.54 EFLOPS,峰值 2.16 EFLOPS,MFU 15.7%。
D2AR 论文的 Table 1 提供了一个绝佳的横向对比锚点。把它跟 GPU 大规模训练的数据并排看:
| 系统 | 模型 | 规模 | 精度 | MFU | 持续 PFLOPS |
|---|---|---|---|---|---|
| MegaScale (A100) | 175B LLM | 12,288 GPU | BF16 | 55% | 2,166 |
| AxoNN (H100) | 60B LLM | 6,144 GPU | BF16 | 23% | 1,423 |
| ORBIT-2 (MI250X) | 10B Climate | 65,536 GPU | FP32 | ~16% | 4,100 |
| 富岳 (A64FX) | 7M Cosmology | 16,384 CPU | FP64 | ~2.0% | 2.22 |
| 灵晟 (LX2) | 6.3B EO | 40,960 CPU | BF16 | 15.7% | 1,543 |
这张表的信息密度极高。几个值得停下读的数字:
灵晟的 1,543 PFLOPS 是 CPU 平台的历史最高纪录。 排第二的富岳是 2.22 PFLOPS。差距 695 倍。但富岳的模型只有 7M 参数、FP64 精度、无矩阵加速。灵晟的 1,543 PFLOPS 几乎全部来自 SME 的 BF16 矩阵乘法。如果把富岳的 A64FX 换成 LX2,在同样的模型上估计可以做到 500-800 PFLOPS——量级吻合。
15.7% 的 MFU 是所有大规模训练中偏低的。 MegaScale 在 GPU 上做到 55%,差距 3.5 倍。但 ORBIT-2(气候模拟,FP32,GPU)也只有 ~16%——跟灵晟几乎一样。这说明 MFU 15.7% 不全是 CPU 架构的问题,也跟负载类型(非 LLM 的视觉模型)、精度选择、通信模式有关。
拆解 15.7% 的构成。 D2AR 的端到端时间可以分成四块:
-
SME 计算(GEMM + attention):推测占 40-50% 的时间。纯 SME GEMM 的硬件利用率受 HBM 带宽限制——4 TB/s 带宽在 240 TFLOPS SME 峰值下,每 byte 数据只能支撑 ~60 GFLOPS 的计算。如果算子的计算/访存比(arithmetic intensity)低于 60 FLOP/byte,SME 就是 memory-bound。Transformer 的 attention 层在序列长度较大时计算密度高,但 embedding 和 normalization 层计算密度极低,拉低整体利用率。
-
通信(AllReduce + AlltoAll):推测占 15-20%。论文报告通信计算重叠率 > 80%,但剩余 20% 的串行通信直接拉低 MFU。在 40,960 颗 CPU 上,一次 AllReduce 的延迟约 24 步(log₂(40960) ≈ 15,但实际因胖树拓扑约 20-25 步),每步数百微秒。AlltoAll 的消息数是 O(P²) = O(1.7B),即使每条消息只有几 KB,总量也以 TB 计。
-
SDMA 内存调度:推测占 15-20%。6.3B 参数的训练状态约 50 GB(参数 12.6 GB + Adam 优化器 37.8 GB + 激活),单颗 LX2 的 32 GB HBM 放不下。SDMA 在 HBM 和 DDR5 之间搬运优化器状态,每次 DDR5 访问的带宽(200-400 GB/s)只有 HBM 的 5-10%——SDMA 未命中就是一个数量级的带宽惩罚。
-
数据预处理和其他:推测占 15-25%。遥感图像的解压、裁剪、标准化、多光谱对齐。
四块加起来 85-115%(有不确定性),但分母是端到端时间——非计算开销实际占比约 60%,这就是 MFU 从纯计算的 ~35% 衰减到端到端 15.7% 的原因。
32 GB HBM 是最大的约束。 如果 LX2 有 80 GB HBM(跟 H100 相当),6.3B 模型的训练状态可以全部驻留 HBM,SDMA 开销接近零。MFU 可以提升到 25-30%——跟 ORBIT-2 的 GPU 水平相当。但国产 HBM 的容量限制让这条路暂时走不通。
能力上限推演。 纯 CPU 的 BF16 训练能力受三个因素约束:
-
模型规模上限:单颗 LX2 的 32 GB HBM 能驻留的训练状态约 32 GB。扣除激活后,模型参数 + 优化器约 25 GB。按 BF16 + Adam(参数:优化器 = 1:3)算,最大模型约 6-7B 参数(D2AR 的 6.3B 恰好在这个边界上)。超过这个规模的模型要么用更多 CPU 做模型并行(引入更多通信开销),要么频繁 SDMA 调度(拉低 MFU)。70B+ LLM 训练在这个架构上不可行——不是算力不够,是内存放不下。
-
MFU 上限:在当前 HBM 容量约束下,BF16 训练的 MFU 天花板约 25-30%。要突破这个上限,要么增大 HBM 容量(等国产 HBM 工艺进步),要么减少通信(缩小系统规模或优化拓扑),要么做更激进的内存管理(把 activation checkpointing 做到 SDMA 层)。
-
系统规模效率:D2AR 用了全系统 40,960 颗 CPU,弱扩展效率未明确报告但从持续性能(1.54/2.16 = 71%)推断约 70-75%。如果系统规模减半到 20,000 颗 CPU,单 CPU 的有效利用率可能上升到 20-25%——因为通信开销降低。但总计算时间会翻倍。全系统跑 BF16 训练的甜蜜点可能在 20,000-30,000 颗 CPU,而不是 40,960 全满。
4.3 CAPES:纯 CPU 在多精度混合工作流上的结构性优势
CAPES 是清华/深圳超算的东亚汛期降水预报系统。问题:提前 3-6 个月预测夏季降水,受"春季可预测性屏障"影响,传统数值模式的预报技巧在这个时间尺度上很低。
方法:1,774 成员混合 ensemble——174 个数值模式成员(不同初始条件、不同物理参数化方案)+ 1,600 个 AI 预报成员(初始和物理扰动)。数值模式求解大气/海洋/陆面耦合偏微分方程(FP64),AI 成员做数据驱动的季节预报(BF16)。15 km 分辨率,10 年回算(2016-2025)。
结果:全系统 14.6 小时完成十年回算,预测得分 75.9(ACC),超过 ECMWF 的 71.8。
为什么纯 CPU 在这个场景有结构性优势?
这个工作流的本质特征是:在同一次预报中,FP64 的数值模式和 BF16 的 AI 模型交替执行,且数据流是闭环的。
数值模式跑一步(FP64 PDE 求解)→ 输出中间大气场 → AI 模型读入大气场做一步推理(BF16 矩阵乘法)→ AI 输出修正后的场 → 喂入下一步数值模式 → 循环。
在 GPU 异构系统上,每个循环的数据路径:
CPU 内存(数值模式状态)
→ PCIe/NVLink 搬运 → GPU 显存
→ GPU 计算 AI 步 → GPU 显存(AI 输出)
→ PCIe/NVLink 搬回 → CPU 内存
→ CPU 数值模式下一步
每次搬运的数据量:一个 15 km 分辨率的全球大气场(温度、湿度、风场、气压等变量),约 1-5 GB。1,774 个成员 × 多个时间步 × 多个循环——搬运的总数据量以 PB 计。PCIe Gen5 x16 的双向带宽约 64 GB/s,每次搬运 1 GB 数据约 15 ms。看起来不多,但在千万次循环中累积成可观的开销。
MI300A APU(El Capitan 的处理器)用统一封装内存缓解了这个问题——CPU 和 GPU 共享 128 GB HBM3,不需要 PCIe 搬运。但编程模型仍然是异构的:数值模式在 CPU 核上跑 x86 代码,AI 模型在 GPU 上跑 HIP kernel,两者之间的数据交接需要显式的设备同步。
灵晟的路径要短得多:
LX2 HBM(数值模式状态,FP64)
→ 同一组核心切换到 SME 指令 → AI 计算(BF16)
→ 同一组核心切回 SVE → 数值模式下一步
数据不离开 HBM,精度切换只需要改指令流。没有跨设备 DMA,没有设备同步,没有编程模型的切换。这是纯 CPU 架构在"多精度混合工作流"场景下的结构性优势。
14.6 小时十年回算的含义。 一个气象业务中心每天可以跑一次完整的 1,774 成员 ensemble 回算——这达到了 operational forecasting(业务化预报)的时间窗口要求。论文不再只是学术验证,是可以交付给气象局使用的生产系统。
能力上限推演。 CAPES 的工作流特征(多精度混合 + 大量独立成员)恰好避开了灵晟的两个弱点:
-
避开了 HBM 容量瓶颈:单个 ensemble 成员的模型不大(AI 成员可能是 1-3B 参数),32 GB HBM 够用。1,774 个成员分布在 40,960 颗 CPU 上,每 CPU 跑不到 0.05 个成员,内存压力极低。
-
避开了大规模通信瓶颈:ensemble 成员之间几乎不需要通信——每个成员独立跑完整的预报,最后做一次 AllReduce 统计结果。通信量极小。
所以 CAPES 几乎不触碰灵晟的能力天花板。如果要扩大——比如 ensemble 增到 10,000 成员、分辨率从 15 km 提到 5 km——灵晟还有很大的余量。1 km 分辨率的台风模拟也在论文中验证了可行性。
这个案例说明:纯 CPU 架构在"多精度混合 + embarrassingly parallel"的工作流上,不是差在 GPU 面前,而是结构性更优。
4.4 HPCG:1% 的比值暴露了什么
TOP500 榜单中灵晟的 HPCG 成绩是 22 PFLOPS,HPL 是 2,198 PFLOPS。HPCG/HPL = 1.0%。
HPCG(High Performance Conjugate Gradient)测量稀疏迭代求解,对内存带宽、通信延迟、不规则访存高度敏感。灵晟的 1.0% 是 TOP500 前十中最低的:
| 系统 | HPL (PFLOPS) | HPCG (PFLOPS) | HPCG/HPL |
|---|---|---|---|
| 灵晟 | 2,198 | 22 | 1.0% |
| 富岳 | 442 | 13 | 2.9% |
| Frontier | 1,353 | 14 | ~1.0% |
| El Capitan | 1,809 | ~38 | ~2.1% |
有意思的是,Frontier 也只有约 1.0%。这说明 HPCG/HPL 比值低不只是纯 CPU 架构的问题——GPU 架构在稀疏负载上也不好。根源是 HPCG 的稀疏矩阵向量乘法(SpMV)访存模式不规整,对任何架构的预取和 cache 都是噩梦。
但灵晟的问题更严重——因为 HBM 只有 32 GB。HPCG 的全局稀疏矩阵需要尽可能驻留在快速内存中,32 GB 装不下大规模问题的完整矩阵。矩阵分块后部分数据溢出到 DDR5,SpMV 的 DDR5 访问延迟把效率拉低。
这个数据说明: 灵晟的适用域是密集计算(HPL、GEMM、Transformer attention),不是稀疏计算(HPCG、SpMV、图分析)。如果把 HPC 负载按"计算密度"排序——
计算密度高 ←─────────────────────────→ 计算密度低
Dense GEMM · CFD · Transformer · 分子动力学 · 稀疏迭代 · 图分析
████████████ ██████████ ██████████ ░░░░░░░░░░ ░░░░░░░░░░
灵晟高效区 灵晟低效区
——灵晟的甜蜜区覆盖了大多数科学计算场景(CFD、气象、材料模拟),但不覆盖大数据分析和图计算。
4.5 三个案例交叉对比:能力边界全景
把三个案例的关键数据放在一起,灵晟的能力边界就清晰了:
| 维度 | MatRIS-MoE | D2AR | CAPES | 能力判断 |
|---|---|---|---|---|
| 精度 | FP32 | BF16 | FP64+BF16 | 全精度覆盖 ✓ |
| 模型规模 | 11.5B | 6.3B | 小模型 | ≤7B 是甜蜜点 |
| 计算图 | 二阶导数+不规则 | 标准 Transformer | 数值+AI 交替 | 多精度混合最强 |
| 通信模式 | MoE AlltoAll 重 | 标准 AllReduce | 几乎无通信 | 通信密集型效率下降 |
| 内存压力 | 中等(局部图) | 高(超出 32GB) | 极低 | 32GB HBM 是硬墙 |
| MFU/利用率 | 35.5% (FP32) | 15.7% (BF16) | 未报告 | FP32 效率 > BF16 |
| 适合 GPU? | GPU 效率更低 | GPU 效率更高 | GPU 有搬运开销 | 负载依赖 |
从这张表推出的结论:
-
灵晟在 FP32 科学计算训练上的效率结构性优于 GPU(MatRIS-MoE),但这种优势只在二阶导数 + FP32 + 不规则数据的特定条件下成立。标准 BF16 LLM 训练(一阶导数 + 低精度 + 规整 batch)在 GPU 上效率更高。
-
32 GB HBM 是灵晟 AI 训练能力的天花板。 模型训练状态(参数 + 优化器 + 激活)一旦超过 32 GB,SDMA 调度开始频繁在 HBM 和 DDR5 之间搬运,MFU 显著下降。按 BF16 + Adam 算,天花板约 6-7B 参数。这个数字在 2026 年的 AI 模型规模谱系中偏低——主流 LLM 已经 70B+,下一代会更大。
-
灵晟在"多精度混合 + embarrassingly parallel"工作流上有不可替代的优势。 CAPES 的 1,774 成员 ensemble + 数值/AI 交替在纯 CPU 上天然高效。这个优势不是性能数字上的差距,是编程模型上的简化——没有跨设备同步,没有异构代码管理。
-
HPCG/HPL = 1% 意味着灵晟不应被用于稀疏负载。 它是一台密集计算专用机器。

五、HPC 纯 CPU 架构路线是否还有希望
5.1 从数据看路线的当前定位
纯 CPU 路线的当前状态:灵晟是史上最强的纯 CPU 超算,在特定领域(科学计算训练、多精度混合、密集计算)的效率结构性优于 GPU 异构系统。但在主流 AI 训练(LLM)和推理场景上,跟 GPU 的差距在扩大而非缩小。
把灵晟跟两个参照系对比:
vs 富岳(同路线的上一代):
| 参数 | 富岳 (A64FX, 2020) | 灵晟 (LX2, 2026) | 变化 |
|---|---|---|---|
| ISA | ARMv8.2 + SVE | ARMv9 + SVE2 + SME | SME 是分水岭 |
| 核/CPU | 48 | 304 | 6.3× |
| FP64/CPU | 3.4 TFLOPS | 60.3 TFLOPS | 18× |
| BF16/CPU | 无矩阵加速 | 240 TFLOPS | 从 0 到有 |
| HPL | 442 PFLOPS | 2,198 PFLOPS | 5× |
| HPCG/HPL | 2.9% | 1.0% | 退步 |
| 能效 | 16 GFLOPS/W | 51 GFLOPS/W | 3.2× |
| 工艺 | TSMC 7nm | 国产(推测 7nm) | 从外援到自主 |
六年间纯 CPU 路线:FP64 提升 18 倍,BF16 从零到 240 TFLOPS,能效提升 3.2 倍。路线还在迭代,没有停滞。
但 HPCG/HPL 从 2.9% 退步到 1.0%。更多核心、更大 L2 共享、更高聚合带宽——这些设计选择优化了密集计算,代价是稀疏负载效率下降。路线越走越偏向"密集计算专用",通用性在收窄。
vs El Capitan(异构路线的当前标杆):
| 参数 | 灵晟 | El Capitan |
|---|---|---|
| 架构 | 纯 CPU | CPU+GPU APU (MI300A) |
| HPL | 2.198 EFLOPS | 1.809 EFLOPS |
| HPL 效率 | ~77% | 63.4% |
| 能效 | 51 GFLOPS/W | 58.9 GFLOPS/W |
| 内存/单元 | 32GB HBM + 256GB DDR5 | 128GB HBM3 (APU 统一) |
| BF16 算力/CPU | 240 TFLOPS | ~1300 TFLOPS (GPU部分) |
| 编程模型 | 统一 ISA,MPI+OpenMP | x86 + HIP 异构 |
HPL 效率灵晟 77% vs El Capitan 63.4%——纯 CPU 没有跨设备同步开销,密集计算效率天然更高。
BF16 算力密度差距巨大:LX2 的 240 TFLOPS vs MI300A 的约 1300 TFLOPS(GPU 部分)。在 AI 训练的绝对算力需求面前,这个 5.4 倍差距意味着 GPU 集群可以用少得多的计算单元达到同样的训练吞吐。
内存容量差距同样关键:MI300A 的 128 GB HBM3 vs LX2 的 32 GB HBM。El Capitan 可以把 70B 参数的 LLM 训练状态放在单颗 APU 的 HBM 中;灵晟做不到。

5.2 为什么日本转向了异构
日本 Fugaku-NEXT 宣布采用富士通 Monaka ARM CPU + NVIDIA GPU 的异构架构。这个决策的逻辑不在技术本身——富岳在 2020-2021 年是当之无愧的全球第一——而在负载变化。
2020 年富岳设计时,HPC 的主流负载是科学模拟(CFD、气象、地震、材料),FP64 密集计算为主。纯 CPU 架构完美适配。2024-2026 年,AI 训练负载的规模和比重爆炸式增长——LLM 参数从百亿到万亿,训练计算量每年翻几倍。CPU 的 SME 单元无法以同样速度扩展:
- 核心数受 L2 带宽约束:38 核/集群 × 8 = 304,已经是当前 L2 配置的极限
- 主频受工艺约束:1.55 GHz,国产 7nm 级别
- 功耗 700W/CPU,已经接近直接液冷的散热极限
- 加更多 SME 流水线需要更多 die 面积,但 reticle limit 逼着走 chiplet,chiplet 又引入跨 die 延迟
每个维度的扩展空间都到了边际收益急剧递减的拐点。下一代 GPU(NVIDIA Rubin、AMD MI450)的 BF16 将进入 3000-5000 TFLOPS 级别。LX2 的 SME 如果要把 BF16 推到 1000 TFLOPS,需要把 SME 流水线数量翻 4 倍——每核 4 条 SME pipeline,芯片面积增加 40-60%,功耗超 1000W/CPU。在当前封装和散热技术下不现实。
日本转向异构不是因为纯 CPU 路线"失败",而是因为 AI 负载的成长曲线远超 CPU 矩阵单元的扩展曲线。当两条曲线的差距拉开到 10 倍以上,路线的选择就不由人决定了。
5.3 纯 CPU 路线的能力边界——定量推演
从第四章的三个案例和上面的架构分析,纯 CPU 路线的能力边界可以定量表述:
模型规模上限:约 6-7B 参数(BF16 + Adam)。 由 32 GB HBM 容量决定。这是当前国产 HBM 的产能限制。如果国产 HBM3 容量提升到 64-96 GB/堆叠,上限可以提高到 15-20B。但 LLM 的主流规模已经超过这个数字。
MFU 上限:约 25-30%(BF16)。 由 HBM 带宽和 SDMA 调度开销决定。突破需要更大 HBM 带宽(>8 TB/s)或更激进的内存管理。GPU 在同等负载上的 MFU 约 50-55%。
FP32 训练效率优势区间:二阶导数 + 不规则计算图。 在这个区间内 CPU 的利用率结构性高于 GPU(MatRIS-MoE:35.5% vs 25.4%)。但这个区间在整个 AI 训练市场中的占比很小——大部分训练是一阶 LLM,GPU 在那里效率更高。
多精度混合工作流:不可替代的结构性优势。 数值+AI 混合(CAPES 场景)在纯 CPU 上编程最简单、效率最高。但这类工作流在整个 HPC 市场中也不是主流。
系统规模甜蜜点:20,000-40,000 颗 CPU。 低于这个规模,计算时间太长;高于这个规模,通信开销开始侵蚀效率。灵晟的 40,960 颗 CPU 接近上限。
把这些边界画成一张图:
负载类型 纯 CPU 路线的位置
──────────────────────────────────────────────────────
uMLIP / 科学计算训练 ██████████ CPU 结构性优势
多精度混合 (数值+AI) ██████████ CPU 不可替代
CFD / 气象模拟 ███████░░░ CPU 高效但 GPU 也可
标准 BF16 AI 训练 ███░░░░░░░ GPU 5× 算力密度优势
LLM 训练 (>20B) ░░░░░░░░░░ HBM 容量不足
LLM 推理 ░░░░░░░░░░ GPU 压倒性优势
稀疏 / 图计算 ░░░░░░░░░░ HPCG = 1%
5.4 这条路线还有几代
灵晟的 LX2 触碰了纯 CPU 架构的四个物理边界:L2 带宽(38 核/集群极限)、功耗密度(700W/CPU)、HBM 容量(32 GB)、主频(1.55 GHz)。
下一代在同工艺节点上的改善空间有限——核心数加不了(L2 带宽已满)、主频提不了(工艺不变)、功耗已经到顶。唯一的出路是工艺跃迁。
如果国产工艺从 7nm 迁移到 5nm:
- 核心密度提升约 70-80%(5nm vs 7nm 的逻辑密度比)→ 单 die 可以放 ~250 核(当前 7nm ~150 核/die)
- 主频提升 30-50% → 2.0-2.3 GHz
- 同性能下功耗下降 30% → 或同功耗下性能提升 40-50%
- 可以做更大的 SME 单元或更多核心
- 估算:5nm LX2 下一代可达 FP64 ~100 TFLOPS、BF16 ~400 TFLOPS、约 60 核/集群 × 8 = 480 核
如果到 3nm(可能需要 3-5 年):
- 核心密度翻倍 → ~500-600 核/CPU(需要重新设计 L2 层级,可能 12-16 集群)
- 主频 2.5-3.0 GHz
- FP64 ~200 TFLOPS、BF16 ~800 TFLOPS
- 这个水平接近当前 H100 的 BF16 算力,但仍远低于下一代 GPU(Rubin 预计 3000+ TFLOPS BF16)
纯 CPU 路线还有几代?
在 5nm 工艺下,纯 CPU 路线还有一代有力的迭代——BF16 从 240 提升到 ~400 TFLOPS,FP64 从 60 提升到 ~100 TFLOPS,能效从 51 提升到 ~70 GFLOPS/W。这一代在科学计算训练和多精度混合工作流上仍然保持结构性优势,在标准 AI 训练上的差距从 5.4 倍缩小到 ~3 倍。
到 3nm 工艺一代——如果国产 3nm 能在合理时间内量产——纯 CPU 路线还有最后一代。之后,CPU 和 GPU 的算力密度差距会再次拉开,因为 GPU 的专用性让它可以从每平方毫米硅片榨取更多 FLOPS。
最终判断:纯 CPU 路线在 HPC 集群中还有希望,但窗口在收窄。 它在科学计算训练、多精度混合工作流、密集 FP64 计算这些领域依然是最佳选择——不是次优替代,是结构性最优。但在 AI 训练和推理的主流市场上,GPU 异构路线的算力密度优势在持续扩大。
灵晟之后最可能的演进方向:不是继续纯 CPU,而是走向"ARM CPU + 国产加速器"的异构方案——用 LX2 的后继做通用计算和科学计算的 FP64 部分,用一个国产 AI 加速器(可能基于昇腾架构或全新设计)处理 BF16/FP8 大规模训练。这跟 Fugaku-NEXT 的路线在逻辑上是一样的:保留 ARM CPU 的科学计算优势和编程简洁性,同时引入专用加速器来覆盖 AI 训练的算力缺口。
这不是纯 CPU 路线的失败。是路线的自然演化——从"一种架构打天下"到"科学计算用 CPU、AI 训练用加速器"的分工。灵晟走到了纯 CPU 架构的最高点,也走到了纯 CPU 架构的分岔口。
声明: 本文基于公开信息撰写,综合参考了 ISC 2026 TOP500 榜单、arXiv 论文 2604.15821 / 2605.08633 / 2605.24896、Tom's Hardware 报道、国家超级计算深圳中心官方信息、富士通及 AMD 公开技术文档。微架构分析部分基于 ARMv9 架构规范、Neoverse 参考设计和物理约束的推测,标注"推测"的内容为合理推断而非确认事实。不构成任何投资或策略建议。文中数据截至 2026 年 6 月 24 日。封面及机房实拍图来源:科技日报(记者罗云鹏,光明网 2026-06-24 转载),图片由国家超级计算深圳中心提供。