AI 可观测性的三层盲区
当监控系统说"一切正常"时,AI 系统正在悄悄烧钱、走偏、失控
传统 APM 告诉你"200 OK,延迟 250ms"。 但它没告诉你的是:这次请求花了 $1.74 的 token、推理引擎的 KV Cache 命中率不到 20%、Agent 早在中段就走偏了后面全是浪费。更残酷的现实是,UC Berkeley 等团队的研究发现多 Agent 系统在 AppWorld 测试中故障率高达 86.7%[1]--而传统监控对此完全不知情。
一个悖论
2026 年,企业 AI 支出突破万亿美元,其中网络基础设施占比持续攀升。但行业调研显示,多数 AI 业务的性能瓶颈最终定位在网络层而非算力层--而传统监控工具对此视而不见。
Salesforce 的工程师团队遇到了同样的问题:他们的 Agentforce 平台有 60 多个 AI 功能、600 名用户、超过 4 亿条记录。当 Agent 出错时,工程师需要两周才能定位问题。不是因为问题复杂,而是因为他们看不到 Agent 内部发生了什么。后来他们建了专门的 Query-Driven Observability 平台,调试时间从两周缩到一天。
这不是 Salesforce 的个别问题。这是整个 AI 行业的基础设施缺口。
传统 APM 的 "200 OK 综合征"
传统应用性能监控(APM)--Datadog、New Relic、Grafana--是为请求-响应模型设计的:
请求进来 → 服务处理 → 响应发出
监控:延迟、错误率、吞吐、CPU/内存利用率
这套模型在 Web 服务时代完美工作。但 AI 系统完全不符合这个模型:
一次 AI 请求不是一个操作,是一条决策链。 一个 Agent 收到"帮我分析竞品的定价策略",它需要:搜索竞品信息 → 读取定价页面 → 提取数据 → 分析模式 → 生成报告。每一步都可能失败、走偏、或产生幻觉。传统 APM 看到的是"200 OK,总耗时 45 秒"--一切正常。
但正常吗?
- 那 45 秒里,Agent 的实际推理用了 8 秒,剩下 37 秒在等 API 返回和重试失败的搜索
- 它消耗了 100,000 个 input token 和 3,200 个 output token,按 Claude Opus 定价($15/$75 per M tokens)计算成本 $1.74
- 其中约 80,000 个 input token 是 system prompt 和工具定义--真正有价值的用户 prompt 只有 800 token
- 推理引擎的 KV Cache 命中率不到 20%,大部分推理在重新计算已经算过的东西
- Agent 在第 4 步搜错了竞品名字,后面 6 步全在分析一个错误的对象
传统 APM 看不到这些。 这不是工具的缺陷,是观测模型的代际差。
三层盲区
AI 系统的可观测性缺口可以分成三层,每一层对应传统监控完全看不到的一个维度:
第一层:Token 经济学盲区——你不知道花了多少钱

大多数企业用 AI API 时只看月度账单总额。但这个总额背后的分解是黑箱:
- Prompt 成本膨胀:FutureAGI 的分析显示,在典型 Coding Agent 工作负载中(12 工程师 / 8 个 MCP server / 每天 22 会话),MCP 协议开销(工具定义 + 响应序列化)占总 token 支出的 41-58%[2]。真正来自用户的 prompt 只占 15-20%。但你按 100% 的 token 付费。
- Context 窗口的边际成本:从 4K 到 32K context 的成本增长相对温和,但从 128K 到 1M 是指数级的。Chroma 的 Context Rot 研究发现超过 32K token 后准确率即开始衰减。且 Attention O(n2) 复杂度意味着上下文翻倍、计算量变四倍--实测长上下文吞吐可暴跌 50 倍。
- MoE 定价悖论:DeepSeek V3 总参数 671B 但每次推理只激活 37B(5.5%)。它按激活参数定价(¥2/M input,约 GPT-4o 的 1/12)。这正在系统性压低前沿模型的定价权。
- Model routing 的意外代价:RouteLLM(LMSYS, 2024)显示 MT-Bench 上可省 85% 成本而保留 95% 性能--但在 MMLU 上只能省 45%[3]。路由收益高度依赖任务类型。
Token 经济学盲区的现实:你为 token 付费,但你不知道每个 token 的价值。在典型 Agent 工作负载中,约 85% 的 input token 是"基础设施成本"(prompt 模板、工具定义),只有 15% 是"价值创造成本"(用户实际需求和模型实际生成)。没有 token 级别的成本追踪,企业的 AI 支出优化只能靠猜。
第二层:推理引擎黑盒--200 OK 但慢了 3 倍
当推理服务变慢时,传统监控告诉你的是"GPU 利用率 95%"。但 GPU 利用率 95% 意味着什么?是计算密集型操作在吃满 Tensor Core,还是 memory-bound 操作在等 HBM 带宽?
推理引擎内部的性能瓶颈分布在多个层面:
Prefill 与 Decode 的不对称。一次推理请求分两个阶段:prefill(处理输入 prompt,一次性消化所有 input token)和 decode(逐个生成 output token)。Prefill 是 compute-bound--GPU 的 Tensor Core 在全速运转。Decode 是 memory-bound--每个 token 生成都需要从 HBM 读取整个模型权重,但计算量很小。这意味着同样一个 GPU,prefill 阶段的吞吐可能是 decode 阶段的 10-50 倍。
KV Cache 的存储困境。Transformer 架构需要缓存之前所有 token 的 Key/Value 矩阵。一个 128 层、128 head 的模型,在 128K context 下,KV Cache 占用约 128GB--超过单张 H100 的 80GB 显存。这就是为什么 Agent 工作负载(动辄 100K+ token 上下文)会成为推理引擎的噩梦。
MoE Expert Routing 的通信开销。MoE 模型每次推理只激活一小部分"专家",但所有专家的权重都需要在线。在多 GPU 部署中,不同 GPU 持有不同专家,每次推理可能需要跨 GPU 取权重。这个 All-to-All 通信开销在极端情况下可以占推理总时间的 30-40%。
Speculative Decoding 的 accept rate 波动。用小模型先猜几个 token 再让大模型验证--猜对了 2-4 倍加速,猜错了回退重来。但 accept rate(猜对率)在不同任务上差异巨大:代码生成可能 70-85%,开放域创意写作可能只有 30-40%。传统监控只看到"平均加速 2x",看不到具体哪类请求在拖低平均值。
推理引擎黑盒的根源:推理不是单一操作,而是 prefill、decode、KV Cache 访问、expert routing、attention 计算的复杂交织。传统 APM 停留在"请求级"粒度,但推理优化的收益在"kernel 级"--GPU 上每个 CUDA kernel 的执行时间和资源利用率。这之间的粒度差距大约是 1000 倍。
第三层:Agent 决策路径--第 7 步就走偏了
这是最深也最不成熟的一层。
一个 Agent 做任务不是一次 API 调用,是一条包含多个推理步骤和工具调用的决策链。每个步骤的输出成为下一步的输入。链条中任何一步出错,错误都会向后传播并放大。
Agent 的失败模式完全不同于传统软件:
"走偏"而非"报错"。传统软件失败时返回 500 错误码。Agent 失败时返回一段看起来合理的文字--它选错了工具,但调用成功了;它误解了返回值,但生成了一个"自信但不正确"的结论。没有错误码,没有异常。传统 APM 看到 200 OK,但实际上方向已经偏了。
循环死锁。Agent 可能陷入"搜索 → 读 → 搜索同一个东西 → 再读"的循环。每一步都成功执行(200 OK),但整个链条在空转。这类问题在传统系统中不存在--传统服务不会"决定"再调一次已经调过的 API。
上下文膨胀。Agent 每一步都把工具返回结果加到 context 里。到第 15 步,context 可能已经 200K token--推理质量随上下文增长显著衰减("Lost in the Middle"现象)。更长的上下文不仅增加成本,还降低质量。
多 Agent handoff 的信息丢失。Agent A 完成自己的部分后把结果交给 Agent B。但 B 的 context 里没有 A 的推理过程--只有 A 的最终输出。A 在推理中考虑但最终放弃的备选方案、A 对数据质量的判断、A 对边界条件的顾虑--这些全部丢失。B 拿着一个被压缩过的结果做下一步决策,信息量远不如 A 完整。
Agent 决策路径盲区的根源:Agent 的观测需求从"请求追踪"变成了"推理追踪"--不是"这个请求经过了哪些服务",而是"这个 Agent 在想什么、为什么做了这个选择、它考虑过但放弃的选项是什么"。传统 APM 的分布式 trace 无法表达这种语义级别的决策路径。
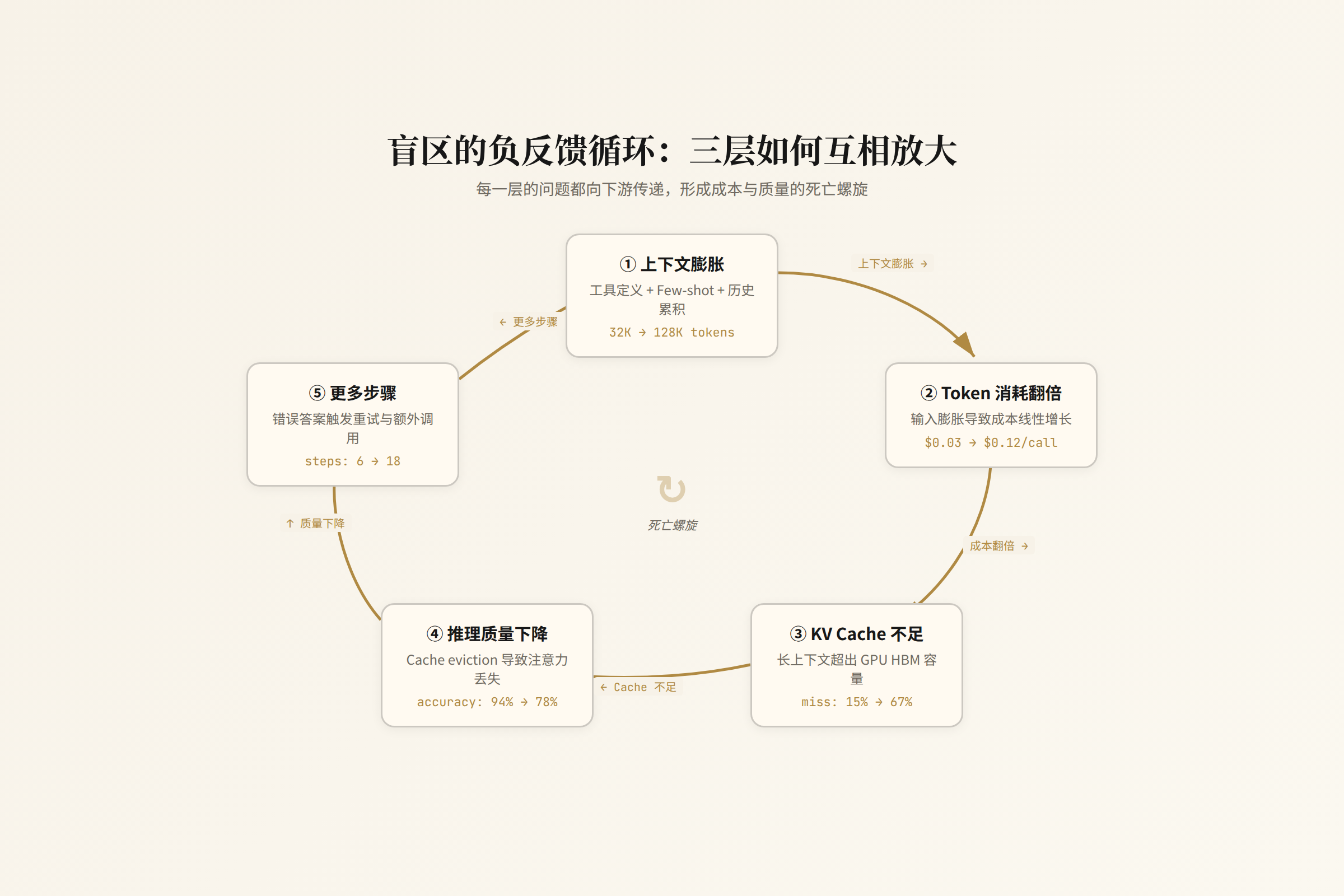
三层不是独立的,是叠加的
这三层盲区在实际系统中同时存在,而且互相放大:
- 一个 Agent 因为上下文膨胀(第三层)导致每次推理的 token 消耗翻倍(第一层)
- 推理引擎因为 KV Cache 容量不足(第二层)开始做 KV Cache eviction,导致推理质量下降
- 推理质量下降让 Agent 需要更多步骤才能完成任务(第三层),进一步增加 token 消耗(第一层)
这是一个负反馈循环。传统监控看不到这个循环的存在——它只看到“请求成功了,耗时较长,GPU 利用率高”。
谁在做什么
LLM 应用观测(Layer 1-2):Langfuse(开源,ClickHouse 后端)是目前最成熟的选择。Arize Phoenix 在 ML 工程师群体中有优势。两者都基于 OpenInference 的 OpenTelemetry 语义约定--这是让不同工具之间数据互通的基础。
推理引擎 Profiling(Layer 2):Graphsignal 做连续高分辨率 profiling,把推理过程拆成 prefill / decode / KV Cache / expert routing 的细粒度时间线。vLLM 和 SGLang 自身也在增强内置 metrics。更激进的方向是 autodebug--一个自主 agent,部署推理服务 → 收集 telemetry → 分析瓶颈 → 自动调整配置 → 重新部署,无限循环。
Agent 观测(Layer 3):这是最不成熟也最有价值的方向。agent-run 在试图定义 Agent 观测的开放标准。Atla 做 Agent thought / tool call 的实时可视化。Deconvolute 从安全角度做 MCP tool call 的 policy-as-code 防火墙。但这个领域还没有出现"Langfuse 级别"的事实标准。
端到端观测体系建设:全局把握,阶段细化
三层盲区的分析揭示了观测对象,但真正的挑战是:一个组织应该如何系统性地建设 AI 观测能力?不是东打一耙西打一耙地装工具,而是从全局架构出发,分阶段细化。
三层各观测什么
| 层级 | 观测核心 | 关键问题 | 典型观测对象 |
|---|---|---|---|
| 第一层:Token 与 API | 成本与用量 | "钱花在哪了?值不值?" | API 调用、token 构成、模型路由、prompt caching |
| 第二层:推理引擎 | 性能与效率 | "GPU 在干什么?为什么慢?" | Prefill/decode 延迟、KV Cache、attention kernel、MoE 调度 |
| 第三层:Agent 决策 | 质量与正确性 | "Agent 走对了吗?哪一步偏了?" | 步骤 trace、工具调用、走偏检测、handoff 质量 |
每层的详细观测矩阵见各 Deep Dive 文章。但三层不是独立的选择题——它们是同一个请求在不同粒度上的投影。
端到端:一个请求穿越三层
想象一个用户发送"帮我分析竞品定价"的请求。这个请求从进入到完成,穿越了所有三层:
用户请求
|
|- 第一层:API Gateway 记录 HTTP 请求
| -> token_count、model、cost、latency
| -> "这次调用花了 $0.03,用了 GPT-4o"
|
|- 第一层:应用中间件分解 token
| -> system_prompt: 3000 / tools: 1500 / history: 8000 / user: 200
| -> "95% 是基础设施 token"
|
|- 第二层:推理引擎处理请求
| -> prefill: 320ms (compute-bound) / decode: 3850ms (memory-bound)
| -> KV Cache 命中率: 60% / batch_size: 24
| -> "KV Cache 够用,decode 是瓶颈"
|
|- 第三层:Agent 执行 15 步任务
| -> Step 1-3: 正确探索 / Step 4: 混淆竞品产品线
| -> 后续 11 步基于错误前提 / token 浪费率: 81%
| -> "Agent 在第 4 步就走偏了"
|
`- 返回结果(看起来正确,实际错误)
关键洞察:传统监控只看到最后一步——"请求成功,耗时 45 秒"。三层观测告诉你的是:这次请求花了 $1.74(第一层),其中 81% 的 token 浪费在错误路径上(第三层),推理引擎本身没有瓶颈(第二层)。
统一 Trace ID:把三层串起来
三层观测数据分散在不同工具里——Langfuse 记 token 成本、vLLM Prometheus 记引擎 metrics、agent-run 记步骤 trace。如果没有关联,你只能分别看三个 dashboard,人工拼接因果关系。
解决方案是统一 Trace ID 贯穿三层:
HTTP Request (trace_id: abc123)
|
|- OTel Span: llm.call (trace_id: abc123, span_id: 001)
| attributes: model=gpt-4o, tokens=87000, cost=$1.74
|
|- OTel Span: inference.prefill (trace_id: abc123, span_id: 002, parent: 001)
| attributes: duration=320ms, input_tokens=35200
|
|- OTel Span: inference.decode (trace_id: abc123, span_id: 003, parent: 001)
| attributes: duration=3850ms, output_tokens=800, kv_cache_hit=60%
|
|- OTel Span: agent.step.4 (trace_id: abc123, span_id: 004, parent: 001)
| attributes: type=tool_call, tool=web_search, drift_score=0.3
|
`- OTel Span: agent.step.5-15 (trace_id: abc123, span_id: 005-015)
attributes: wasted_tokens=161400, drift_detected=true
OpenTelemetry + OpenInference 正在推动这个关联标准。一旦三层共享 trace_id,你就能做到:
- 账单异常 → 自动定位到是哪个 trace 的哪个 step 烧了 token
- 推理延迟异常 → 自动找到对应的 Agent 步骤是否在空转
- Agent 走偏 → 自动查看当时的推理引擎是否 KV Cache 不足
建设节奏:三阶段渐进
不要试图一次性建成所有观测能力。按以下节奏推进:
阶段一(第 1-2 周):成本可见
- 部署 API client wrapper,记录每次调用的 token 构成和成本
- 接入 Langfuse(或 Phoenix),建立基础 LLM call tracing
- 输出:月度账单按应用/部门/用户分解,知道钱花在哪
- 对应第一层的基础能力
阶段二(第 3-6 周):引擎透明
- 启用 vLLM Prometheus exporter,收集 TTFT/TPOT/KV Cache metrics
- 部署 DCGM exporter,收集 GPU 利用率/功耗/带宽
- 建立 Grafana dashboard,把请求级和引擎级指标并排展示
- 输出:能回答"为什么这次请求慢了 3 倍"
- 对应第二层的基础能力
阶段三(第 7-12 周):决策可追溯
- 在 Agent runtime 中植入 OTel spans(每个 thought/tool call/error 一个 span)
- 实现走偏检测(先从行为模式异常开始,成本低)
- 部署 Deconvolute 或类似工具做工具调用审计
- 输出:能回答"Agent 在哪一步走偏了,浪费了多少 token"
- 对应第三层的基础能力
持续迭代:
- 三个阶段建完后,再反向打通三层关联(统一 trace ID)
- 加入语义偏移检测(成本高,放在最后)
- 探索自动调优方向(AVO、自适应 batching)
观测不是目的,干预才是
观测体系的终局不是三个漂亮的 dashboard,而是一个闭环控制系统:
观测 → 诊断 → 决策 → 执行 → 验证
- 观测:三层 metrics + trace + log
- 诊断:异常检测 + 根因分析(三层关联)
- 决策:自动或人工确定优化策略
- 执行:调整路由、扩缩容、修改 prompt、纠正 Agent
- 验证:观测指标是否改善
这个闭环的运转速度决定了 AI 系统的运营效率。在传统软件中,这个闭环的周期是"天"(告警 → 排查 → 修复 → 部署)。在 AI 系统中,目标是压缩到"分钟"甚至"秒"——这就是 autodebug 方向的终极价值。
最大的缺口
可观测性工具在涌现,但有一个结构性缺口没人填:三层之间的关联。
当 Agent 任务的月度账单异常升高时(第一层异常),你无法自动定位到是因为推理引擎的 KV Cache 命中率下降(第二层),导致 Agent 需要更多步骤才能完成任务(第三层)。三层的观测数据分散在不同工具里,没有统一的 trace ID 把它们串起来。
OpenTelemetry + OpenInference 在试图建立这个关联--从 HTTP 请求到 LLM call 到推理引擎 metrics 到 Agent step--但目前的实现还远不够完整。这可能是 2026-2027 年 AI 基础设施领域最大的产品机会。
终局:从"看问题"到"自动修问题"
可观测性的终极目标不是事后分析,而是实时干预。
当系统检测到 Agent 在循环死锁 → 自动注入"你似乎在重复搜索同一信息,请换个方向"的提示。当推理引擎的 KV Cache 命中率低于阈值 → 自动调整 batch 策略或启用跨节点 KV Cache 共享。当 token 成本异常升高 → 自动路由到更便宜的模型或压缩 prompt。
这就是 autodebug 方向的终局--可观测性不再是独立于系统的观测层,而是系统自我优化的反馈回路。推理引擎从"配置后运行"变成"运行中自优化"。Agent 从"人工调试"变成"自动检测走偏并纠正"。
在那一天到来之前,当前绝大多数 AI 系统仍在缺少这三层观测能力的情况下运行--不是没有监控,而是监控的维度对不上 AI 的工作方式。
引用
[1] Berger et al., "Why Do Multi-Agent LLM Systems Fail?" arXiv:2503.13657 (2025). UC Berkeley & Intesa Sanpaolo. 提出 MASFT(Multi-Agent System Failure Taxonomy),识别 14 种故障模式,3 大类。
[2] FutureAGI, MCP Token Overhead Analysis. 见 Codex vs Claude Code: MCP 工程化 引用。代表性工作负载:12 工程师 / 8 MCP server / 每天 22 会话 / 每会话 30 轮。
[3] Osmulski et al., "RouteLLM: Learning to Route LLMs with Preference Data", arXiv:2410.02062 (2024). LMSYS Org.
本文是 AI 可观测性系列的主文。后续三篇 Deep Dive 将分别深入 Token 经济学、推理引擎内部机制(到 CUDA kernel 级别)、以及 Agent 决策路径观测。