一张推理账单的解剖
你的 AI 账单里 85% 是基础设施税,只有 15% 在创造价值
Deep Dive 1 / 3 · 本文是 AI 可观测性的三层盲区 的第一篇深入分析,聚焦 Token 经济学盲区。
一个月花了 $47,000
先看一张真实的账单。
某 SaaS 公司,300 人团队,使用 GPT-5.5 API 做内部工具(代码助手 + 文档搜索 + 数据分析)。月度 API 支出 $47,000。CFO 要求"优化成本"。
团队的第一反应是:找更便宜的模型。把 GPT-5.5 换成 DeepSeek V4,定价只有 1/20。但这只是最表层的优化。真正的问题藏在这 $47,000 花在了哪里。
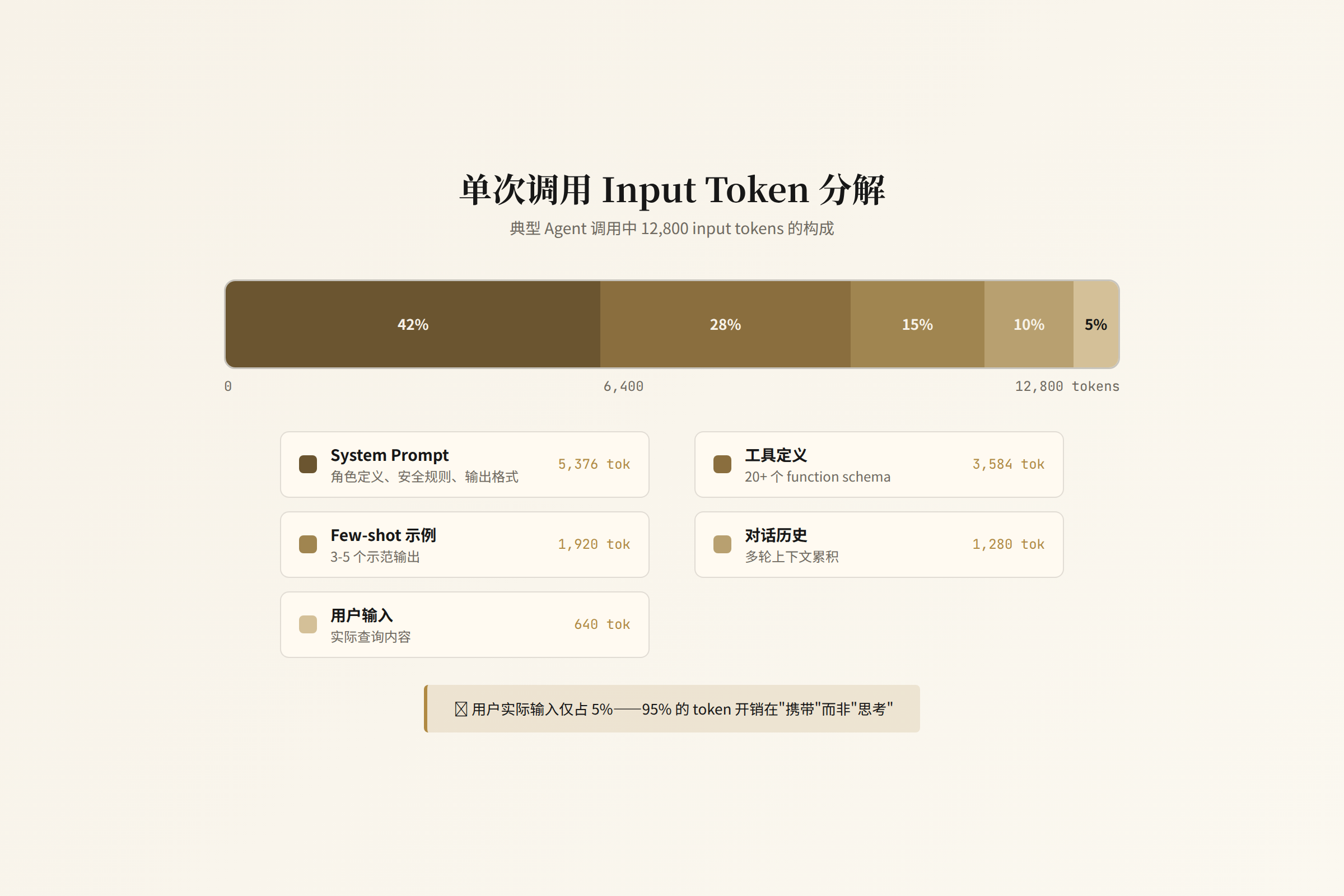
Token 账单的 X 光片
把一个月的 API 调用按 token 类型拆解:
| Token 类别 | 占输入 Token 比例 | 作用 | 是否每次调用都必需 |
|---|---|---|---|
| System Prompt | 42% | 定义 Agent 角色、行为规范、输出格式 | ✅ 每次调用完全相同 |
| 工具定义 (Tool/MCP Schema) | 28% | 描述可用工具的参数和返回格式 | ✅ 大部分调用完全相同 |
| Few-shot 示例 | 15% | 给模型展示期望的输出格式 | ⚠️ 可缓存或压缩 |
| 历史步骤 (History) | 10% | Agent 前面几步的推理和工具返回 | ⚠️ 可截断或摘要 |
| 用户实际输入 | 5% | 用户真正想问的问题 | ✅ 核心价值 |
上表基于典型 Coding Agent 工作负载的经验分布[1],不同 Agent 架构比例会有差异。
也就是说,95% 的 input token 是“基础设施”——每次 API 调用都在重复发送几乎完全相同的内容。这就是为什么 prompt caching(提示缓存)在 2025-2026 年成为所有主流推理引擎的标配功能:如果 system prompt + 工具定义每次都一样,为什么不让模型记住它?
但 prompt caching 只解决了部分问题。更深层的问题在下面。
Prompt 的隐含成本
一个 Agent 的 system prompt 通常长这样:
你是一个数据分析助手。你的职责是:
1. 理解用户的数据分析需求
2. 选择合适的工具获取数据
3. 对数据进行分析和可视化
4. 生成清晰的报告
## 可用工具
### web_search
描述:搜索互联网获取最新信息
参数:
- query (string, required): 搜索关键词
- max_results (int, optional): 最大返回数量,默认 10
### read_file
描述:读取本地文件内容
参数:
- path (string, required): 文件路径
- encoding (string, optional): 编码格式,默认 utf-8
### execute_sql
描述:执行 SQL 查询
参数:
- query (string, required): SQL 语句
- database (string, optional): 数据库名,默认 main
- timeout (int, optional): 超时秒数,默认 30
### generate_chart
描述:生成数据可视化图表
参数:
- data (array, required): 数据点
- chart_type (string, optional): 图表类型,默认 bar
- title (string, optional): 图表标题
[... 更多工具 ...]
## 输出规范
- 分析结果用 markdown 表格呈现
- 数值保留两位小数
- 图表使用暖色系配色
- 结论部分不超过 200 字
## 注意事项
- 不要执行未经确认的写操作
- SQL 查询结果超过 1000 行时自动截断
- 对于敏感数据(手机号、身份证号)做脱敏处理
这段 prompt 大约 1,500 token。加上 8 个工具的 schema 定义(每个工具约 200 token),总输入约 3,100 token。这看起来不多--但每次 API 调用都要发送全部内容。
如果一个 Agent 做 15 步任务,每步都带完整的 system prompt + 工具定义 + 历史步骤:
Step 1: 3,100 (prompt) + 200 (用户输入) = 3,300 input token
Step 2: 3,100 (prompt) + 3,300 (历史) + 200 (新输入) = 6,600 input token
Step 3: 3,100 + 6,600 + 200 = 9,900 input token
...
Step 15: 3,100 + 45,800 + 200 = 49,100 input token
15 步总计:~400,000 input token
其中 system prompt + 工具定义重复发送:3,100 × 15 = 46,500 token(占 12%)
历史步骤累积:~340,000 token(占 85%)
用户实际输入:~200 × 15 = 3,000 token(占 0.75%)
一次 15 步的 Agent 任务,用户实际贡献的信息量不到总 token 的 1%。 其余 99% 是结构性的基础设施成本。
这就是 prompt caching 的价值所在--如果 system prompt + 工具定义可以被缓存,46,500 token 就不需要每次重新计算。但历史步骤的累积膨胀是更难解决的问题。
Context Window 的边际成本
为什么从 4K 到 32K context 的价格增长相对温和,但从 128K 到 1M 却是指数级跳升?
这不是 provider 故意宰客。成本增长来自 Attention 计算的数学本质。
Transformer 的 Self-Attention 机制要求序列中每个 token 与所有其他 token 计算注意力分数。对于长度为 $n$ 的序列:
注意力矩阵大小:n × n
计算复杂度:O(n2·d),其中 d 是 head 维度
KV Cache 大小:O(n·L·H·d),其中 L 是层数,H 是 head 数
以一个 128 层、128 head、head 维度 128 的模型为例:
| Context 长度 | KV Cache 大小 | Attention 计算量 | 相对成本 |
|---|---|---|---|
| 4K | 4 GB | 16M | 1x |
| 32K | 32 GB | 1B | 64x |
| 128K | 128 GB | 16B | 1,000x |
| 1M | 1 TB | 1T | 65,000x |
从 4K 到 1M,计算量增长 65,000 倍。实测更残酷:上下文从 4K 扩到 128K 时,推理吞吐暴跌约 50 倍。Chroma 的 Context Rot 研究(2025.07,测试 18 款模型)发现超过 32,000 tokens 后准确率即开始衰减--即便最简单的单词重复任务。但 API 定价不可能涨 65,000 倍--所以 provider 在用短上下文请求的利润补贴长上下文请求的亏损。
这意味着长上下文请求在定价上是"被补贴"的。 一旦 provider 开始按真实成本定价(趋势正在发生),用 1M context 跑 Agent 任务的成本会让人重新审视架构设计。
Flash Attention 缓解了一部分问题--通过 tiling 和 recomputation 把 HBM 访问从 O(n2) 降到 O(n2/M),其中 M 是 SRAM 大小。但这只是推迟了指数增长的拐角,没有改变趋势。
MoE 定价悖论
Mixture of Experts 模型打破了定价的简单线性关系。
一个 dense 模型(如 GPT-4o)每次推理激活全部参数。定价逻辑直观:参数越多 → 计算越多 → 价格越高。
MoE 模型每次推理只激活一小部分专家。以下是主流 MoE 模型的激活比例:
| 模型 | 总参数 | 激活参数 | 激活比 | 输入价/MTok |
|---|---|---|---|---|
| DeepSeek V3 | 671B | 37B | 5.5% | ¥2.00 |
| GLM-4.5 | 355B | 32B | 9.0% | ¥0.80 |
| GLM-5.2 | 744B | ~40B | 5.4% | ¥8.00 |
| Mixtral 8×7B | 46.7B | 12.9B | 27.6% | 按 provider |
90% 以上的参数在每次推理中是"睡觉"的--但它们占着显存。 DeepSeek V3 激活比仅 5.5%,意味着 94.5% 的参数完全不参与计算但仍消耗 HBM 容量。
这导致了一个定价两难:
- 按总参数定价(传统逻辑):DeepSeek V4 400B 参数,应该和 400B dense 模型一个价位
- 按激活参数定价(DeepSeek 的选择):只算 40B 的计算成本,定价是 400B 的 1/10
- 按显存占用定价(provider 的真实成本):不管激不激活,400B 的权重都要放在显存里,显存成本是固定的
DeepSeek 选择了按激活参数定价--DeepSeek V4 Pro 定价 ¥3/M input(约 $0.41),¥6/M output(约 $0.82)。对比 GPT-4o 的 $2.50/$10.00 和 Claude Opus 4.7 的 $5.00/$25.00,输入价格差约 6-12 倍。中国市场日均 token 调用从 1000 亿增长到 140 万亿(两年千倍),这个增速背后就是 MoE 定价的商品化效应。
这个定价策略正在重塑市场。FT 报道企业开始收紧 AI 使用,Cisco 公开承认 AI 预算超支,微软开始评估自托管 DeepSeek--都是这个定价差的直接后果。
但 MoE 定价有一个隐含风险:显存成本不会因为只激活 10% 的参数而降低。 400B 的权重仍然需要约 800GB 显存(FP16),相当于 10 张 H100。provider 的硬件投入没有减少,只是计算成本减少了。如果 MoE 模型的定价继续下探,provider 的毛利率会被挤压--除非推理效率优化(KV Cache 共享、expert offloading、quantization)能弥补差额。
Model Routing 的经济模型
Model routing--把简单请求路由到便宜模型,复杂请求才用旗舰--是企业降本的标准动作。RouteLLM(LMSYS, 2024, arXiv:2410.02062)给出了最权威的数字:GPT-4 + Mixtral 8x7B 组合在 MT-Bench 上成本降低 85%,仍达 GPT-4 95% 的性能。AgentConductor(上交大, 2026, arXiv:2602.17100)在多 Agent 编排中实现 68% token 节省,准确率反升 14.6%。但 model routing 有它自己的隐性成本。
路由准确性的经济学:如果路由器把一个复杂请求错误地发给了便宜模型,便宜模型的输出不够好,需要重试--用旗舰模型重新跑一遍。这次请求的总成本 = 便宜模型费用 + 旗舰模型费用 + 额外延迟。如果误路由率超过 20%,"省钱"就变成了"烧钱"。
OpenRouter Fusion 的实测数据(2026.06,OpenRouter 官方公告):预算组合(Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro)在 DRACO 基准上得分 64.7%,超过 GPT-5.5 单体(60.0%)和 Opus 4.8 单体(58.8%),成本约 Fable 5 单体的 50%。但 Fusion 默认 3 模型并行的单次成本是单体 4-5 倍--只有当融合质量显著超过旗舰单体时才合理。
路由器的 token 成本:路由器本身也是一个 LLM 调用。它需要读取用户请求,判断复杂度,选择模型。如果路由器用了 500 token 来做决策,而用户请求本身只有 50 token,路由器的成本是请求的 10 倍。对于短请求,routing 的开销可能超过它省下的钱。
真正的 model routing 降本来自一个更朴素的洞察:大多数企业 AI 请求是"简单"的--文本摘要、格式转换、简单问答。这些不需要 GPT-5.5 级别的能力。把它们路由到 glm-4.5-air 或 DeepSeek Flash,质量差异用户感知不到,成本降一个数量级。
但"大多数"不等于"所有"。关键是要知道哪些请求属于"大多数",哪些是少数需要旗舰的。这又回到了可观测性的问题--没有 token 级别的成本追踪和按请求类型的成本分解,model routing 的降本效果是盲猜的。
企业实践:从 $47K 到 $14K
回到开头那张 $47,000 的账单。优化做了三件事:
1. Prompt Caching(省 $18,800/月,40%)
System prompt 和工具定义在所有调用中完全相同。启用 prompt caching 后,这部分 token 从"每次重新计算"变成"首次计算后缓存"。Anthropic 的 prompt caching 对缓存部分降价 90%,OpenAI 也有类似机制。
效果:输入 token 费用降 40%。
2. Model Routing(省 $14,100/月,30%)
把请求分成三档:
- 简单(格式转换、简单问答)→ GLM-4.5-Air,¥0.80/M(~$0.11)
- 中等(代码补全、文档搜索)→ DeepSeek V4 Flash,¥3/M(~$0.41)
- 复杂(多步推理、创意生成)→ 保留 GPT-4o,$2.50/M
70% 的请求被路由到前两档。误路由率控制在 5% 以内(用一段标注数据做基准测试)。
3. Context 压缩 + 历史截断(省 $9,400/月,20%)
Agent 的历史步骤超过 10 步后,只保留最近 5 步 + 第一步的摘要。工具返回结果超过 2,000 token 自动摘要到 500 token。
效果:平均每次调用的 input token 从 45K 降到 18K。
总计:$47,000 → $14,700。降 69%。

但没有第三层可观测性——token 级别的成本追踪——这些优化无法验证效果。你看到的只是"月度账单从 $47K 变成了 $15K"。哪些优化贡献了多少?哪些请求类型成本最高?有没有优化反而降低了质量?这些问题没有 token 级别的数据就无法回答。
Token 与 API 观测体系:从账单到归因
上面三层优化(caching、routing、context compression)能落地的前提,是你有一套足够细粒度的观测体系,知道每一次 API 调用的 token 去了哪里、钱花在了谁身上。这一节把观测体系拆开讲:四个下钻层级、六个关键观测点、一套埋点方案,以及它和系列后续两篇文章的连接点。
四层下钻:从单次调用到全组织
Token 成本观测不是单一粒度的事。不同角色关心不同层级的数字:
| 层级 | 观测目标 | 典型问题 | 主要受众 |
|---|---|---|---|
| 请求级 | 单次 API 调用的 token 构成与成本 | 这次调用为什么花了 $0.03? | 工程师 |
| 会话级 | 一个用户会话的累积消耗 | 这个用户的一个对话花了多少钱? | 产品经理 |
| 任务级 | 一个 Agent 任务的端到端成本 | 这个 15 步任务的 ROI 是多少? | Agent 架构师 |
| 月度级 | 全组织的 AI 支出分解 | 哪些部门/应用/模型在烧钱? | CTO / CFO |
四个层级不是独立的看板,而是一条可下钻的链路。月度报表发现异常 → 下钻到某个应用 → 下钻到某个任务类型 → 下钻到具体会话 → 最终定位到某次 API 调用的 token 构成问题。这条链路如果任何一层断开,归因就停在「某个月花了挺多钱」的粒度。
六个关键观测点 × 指标 × 工具
① Prompt 构成追踪
观测什么:每次 API 调用的 input token 按来源分解——system prompt、tool schema、对话历史、few-shot 示例、用户实际输入各占多少。
核心指标:
input_token_breakdown_ratio:各组成部分占 input token 的百分比prompt_template_drift:同一模板的 token 数随时间的变化(检测 prompt 是否被悄悄改了)
工具:Langfuse prompt tracking、自定义 API middleware。Langfuse 的 generations 表自动记录 prompt 内容和 token 数,可按 prompt template 分桶统计。
埋点位置:API client wrapper 层。在请求发送前,用 tokenizer(如 tiktoken for OpenAI / transformers tokenizer for others)分解 prompt 各部分,写入 span attributes。
② Prompt Caching 命中率
观测什么:prompt cache 有没有命中?命中了多少?没命中的原因是什么?
核心指标:
cache_hit_rate:cached_tokens / total_input_tokens,按 prompt 模板分桶cache_miss_reason:模板变更 / 前缀不匹配 / 缓存过期 / 超出缓存窗口cache_savings_ratio:因缓存节省的费用占原始费用的百分比
工具:直接解析 API response 的 usage 字段——Anthropic 返回 usage.cache_read_input_tokens 和 usage.cache_creation_input_tokens;OpenAI 返回 usage.prompt_tokens_details.cached_tokens。Langfuse 可将这些字段自动关联到 cost 计算。Arize Phoenix 的 LLM tracing 也提供 caching 指标面板。
埋点位置:API response 解析层。response 返回后立即提取 caching 相关字段,计算命中率,写入 trace span。
③ Model Routing 决策追踪
观测什么:路由器为什么选了这个模型?路由准确率如何?误路由导致的重试成本是多少?
核心指标:
routing_accuracy:路由决策与标注基准的一致率misrouting_rate:被误路由的请求占比retry_cost_from_misrouting:因误路由导致的重试额外成本router_overhead_ratio:路由器自身消耗的 token 占请求 token 的比例
工具:RouteLLM 自带决策日志(记录每条请求的特征、选择的模型、置信度分数);自定义路由器建议在决策点写 structured log(JSON 格式,包含 request_features、selected_model、confidence_score、routing_reason)。Langfuse 的 metadata 字段可以承载路由决策上下文。
埋点位置:路由器决策函数。在 route(request) -> model 返回前,记录请求特征向量、候选模型列表、选择结果、置信度。
④ 按应用 / 部门 / 用户的成本归因
观测什么:哪个应用在烧钱?哪个用户的 token 消耗异常?哪个任务类型的单位成本最高?
核心指标:
cost_per_app:按 application_id 聚合的日/周/月成本cost_per_user:按 user_id 聚合的成本,配合 z-score 或 IQR 检测异常用户cost_per_task_type:按 task_type 聚合的成本(如「代码补全」vs「文档搜索」vs「数据分析」)cost_trend_slope:各维度成本的 7 日移动平均斜率,检测突发增长
工具:API gateway 日志(Kong / APISIX / 自定义 proxy)+ 计费系统。Langfuse 的 cost tracking 支持按 session、user、metadata 自定义维度聚合。Helicone 作为 OpenAI proxy 自带 per-user / per-tag 成本统计。Cloudflare AI Gateway 提供 per-endpoint cost breakdown。
埋点位置:API 请求 header 中注入归因标签。遵循 OpenInference semantic conventions:
llm.application_id:应用标识enduser.id:用户标识llm.task_id/ 自定义task_type:任务标识
这些 header 在 proxy 层被提取并写入 trace context,贯穿整条观测链路。
⑤ Token 效率比
观测什么:在所有消耗的 token 中,有多少在创造实际价值?
核心指标:
token_efficiency_ratio= (用户实际输入 token + 模型实际输出 token) / 总 token
这个指标的典型值在 5%-20% 之间。低于 5% 意味着 95% 以上的 token 消耗在结构性开销上——这种情况在 Agent 任务中很常见(前面的计算已经展示过),但如果比率持续下降,说明 prompt 膨胀或历史截断策略失效。
工具:自定义分析脚本。在 API client wrapper 层标记每段 token 的类型(system / tool / history / user / output),然后按时间窗口聚合计算比率。Langfuse 的 custom dimensions 可以存储 token 类型标签。
埋点位置:API client wrapper 层,与 ① Prompt 构成追踪复用同一套 token 分解逻辑。
⑥ API 健康度
观测什么:LLM API 的延迟分布、错误率、重试行为。这是成本观测的底层依赖——一次 500 错误后的重试意味着双倍 token 消耗。
核心指标:
api_latency_p50 / p95 / p99:按模型和 endpoint 分桶的延迟分布error_rate:按 status code 分类的错误率(重点监控 429 rate limit 和 500 server error)retry_count:平均每个请求的重试次数fallback_rate:触发 model fallback 的请求占比rate_limit_utilization:当前 RPM / TPM 占 quota 的百分比
工具:API gateway(Kong / APISIX)标准指标 + Prometheus + Grafana 看板。OpenTelemetry 的 HTTP semantic conventions 可以标准化 LLM API 的 trace/metrics。Datadog LLM Observability 或 New Relic AI Monitoring 提供开箱即用的 API 健康度面板。
埋点位置:API proxy 层标准 HTTP 指标(latency、status code、request size)。proxy 层是最适合做统一埋点的位置——不管上游有多少个应用调用 LLM,所有请求都经过 proxy。
埋点方案:API Client Wrapper 层
六个观测点的埋点不是分散在各处的。它们可以统一收敛到 API client wrapper 层——所有 LLM 调用的必经之路。下面是一个可落地的埋点方案:
import tiktoken
from opentelemetry import trace
tracer = trace.get_tracer("llm.observability")
def count_tokens(messages: list[dict], model: str) -> dict:
"""分解 token 来源,返回各部分的 token 计数。"""
enc = tiktoken.encoding_for_model(model)
breakdown = {"system": 0, "tools": 0, "history": 0, "user": 0}
for msg in messages:
role = msg.get("role", "user")
tokens = len(enc.encode(msg.get("content", "")))
if role == "system":
breakdown["system"] += tokens
elif role == "tool":
breakdown["tools"] += tokens
elif role in ("assistant", "function"):
breakdown["history"] += tokens
else:
breakdown["user"] += tokens
breakdown["total_input"] = sum(breakdown.values())
return breakdown
async def traced_llm_call(request: LLMRequest) -> LLMResponse:
"""包裹所有 LLM 调用的可观测 wrapper。"""
with tracer.start_as_current_span("llm.call") as span:
# ━━ 请求前:Token 构成分析 (观测点 ①)
token_breakdown = count_tokens(request.messages, request.model)
span.set_attribute("llm.token_count.system", token_breakdown["system"])
span.set_attribute("llm.token_count.tools", token_breakdown["tools"])
span.set_attribute("llm.token_count.history", token_breakdown["history"])
span.set_attribute("llm.token_count.user", token_breakdown["user"])
span.set_attribute("llm.token_count.total_input", token_breakdown["total_input"])
# ━━ 归因标签 (观测点 ④)
span.set_attribute("llm.application_id", request.app_id)
span.set_attribute("enduser.id", request.user_id)
span.set_attribute("llm.task_id", request.task_id)
span.set_attribute("llm.task_type", request.task_type)
span.set_attribute("llm.model", request.model)
# ━━ 路由决策上下文 (观测点 ③)
if hasattr(request, "routing_meta"):
span.set_attribute("llm.routing.confidence", request.routing_meta.confidence)
span.set_attribute("llm.routing.alternatives", str(request.routing_meta.candidates))
# ━━ 调用 API
response = await llm_client.call(request)
# ━━ 响应后:成本与缓存 (观测点 ② ⑤ ⑥)
span.set_attribute("llm.token_count.output", response.usage.output_tokens)
span.set_attribute("llm.cached_tokens", response.usage.get("cached_tokens", 0))
cache_hit_rate = (
response.usage.get("cached_tokens", 0)
/ max(token_breakdown["total_input"], 1)
)
span.set_attribute("llm.cache_hit_rate", cache_hit_rate)
span.set_attribute("llm.cost", calculate_cost(request.model, response.usage))
span.set_attribute("llm.latency_ms", response.latency_ms)
span.set_attribute("llm.status_code", response.status_code)
# Token 效率比 (观测点 ⑤)
value_tokens = token_breakdown["user"] + response.usage.output_tokens
total_tokens = token_breakdown["total_input"] + response.usage.output_tokens
span.set_attribute("llm.token_efficiency_ratio", value_tokens / max(total_tokens, 1))
return response
这套方案的精髓不在于代码本身,而在于 六个观测点共用一次 span——请求前记录 token 构成和归因标签,请求后记录成本和缓存指标。一次 API 调用产生一条完整的 trace,下游的分析系统(Langfuse / Grafana / Datadog)按不同维度聚合即可得到四个层级的报表。
与系列后续文章的关联
这一节的观测体系不是孤立的。它的输出直接喂给系列的 DD2 和 DD3:
-
按模型分桶的 token 消耗异常 → 触发 DD2(推理引擎)的深度 profiling。如果某个模型的
cost_per_task_type突然上升 3 倍,不是 token 变贵了,更可能是 prefill 阶段的 KV Cache 命中率下降,或者 decode 阶段的 batch 效率劣化。Token 观测提供「症状」,推理引擎 profiling 提供「病因」。 -
按任务类型的成本效率下降 → 触发 DD3(Agent 决策)的走偏检测。如果一个「数据查询」任务的平均 token 消耗从 5K 涨到 20K,最可能的原因是 Agent 在循环调用工具,每轮把前一步的返回结果塞进 context。成本观测的
cost_per_task_type斜率变化是最早的预警信号——比 Agent 输出质量下降更早被检测到。 -
Prompt 构成比例变化 → 直接的 prompt 工程优化。
input_token_breakdown_ratio从 system:42% 变成 system:60%,意味着有人在 system prompt 里堆了新规则。history占比从 10% 涨到 40%,说明 context truncation 策略失效或被绕过了。这些变化在 token 级别的观测下一目了然。
一条完整的归因链路是这样的:
月度报表:GPT-5.5 成本月环比 +27%
→ 下钻应用:code-assistant 占增量的 80%
→ 下钻任务类型:multi-file-refactor 平均成本从 $0.08 → $0.15
→ 下钻会话:发现 Agent 步数从 12 步涨到 28 步
→ 下钻请求:history token 占比从 10% 涨到 55%
→ 根因:新加的 3 个 MCP 工具定义增加了 4,200 token/步
→ 修复:启用 prompt caching + 工具定义懒加载
没有这套观测体系,你看到的只是「AI 账单涨了」。有了它,你看到的是「新增 3 个 MCP 工具定义导致 multi-file-refactor 任务成本翻倍,建议启用 prompt caching 和工具定义懒加载」。从账单到归因——这就是这一节标题的含义。
工具现状与挑战
现状:Langfuse 在 token/cost tracking 方面最为成熟——开源、ClickHouse 后端、按 prompt template 分桶的细粒度成本归因在同类工具中没有对手。Arize Phoenix 在 ML 工程师群体中有优势,尤其是 embedding 分析和 OpenInference 原生支持。OpenInference 定义了 LLM 语义约定(semantic conventions),是让不同工具之间数据互通的基础层。然而,大多数企业仍在用 API provider 的月度账单做成本管理——只看到总价,看不到构成。
挑战:
-
跨 provider 的 token 计数不统一。OpenAI(tiktoken)、Anthropic(专用 tokenizer)、DeepSeek(BBPE tokenizer)各有各的分词器,同一个 prompt 在不同 provider 下 token 数差异可达 15-20%。跨 provider 的成本对比和路由决策因此建立在不一致的计量基础上。
-
Prompt caching 的成本归因复杂。缓存命中和未命中的定价不同——Anthropic 缓存命中按 10% 计费、缓存写入按 125% 计费。但现有工具很少区分这两者,往往只记录一个总成本数字。当缓存策略改变时,"成本下降 40%" 可能掩盖了"实际调用量增加了 20%、只是缓存补偿了"的事实。
-
实时成本告警缺失。大多数工具只做事后分析——T+1 的成本报表、按天的趋势图。不能在 token 消耗异常时(比如某个 Agent 陷入循环死锁,每分钟烧 $5)实时干预。这意味着一个午休期间失控的 Agent 可以在没人发现时烧掉一个月的预算。
-
Model routing 的决策成本本身没有被追踪。路由器是额外的一次 LLM 调用——它消耗 token、产生延迟、还可能误判。但大多数实现把路由器成本混入"系统开销",不单独计量。对于短请求,路由器成本可能占请求总成本的 50%+,这个比例从未被审视。
对工具体系的要求:
- 需要统一的 token 计费标准——跨 provider 的归一化 token 计数(如定义 "standard token = 4 characters"),让成本对比有意义
- 需要实时成本流(streaming cost metrics),不是 batch 处理的 T+1 账单,而是每秒更新的 per-request 成本事件流,支持基于阈值的实时告警和自动熔断
- 需要按 application/user/task 的多维成本归因——这要求所有 LLM 调用携带结构化的归因标签(如 OpenInference 的
llm.application_id),且归因链路在 Agent 多步调用中不被截断
三个趋势
趋势一:Token 定价的商品化。 DeepSeek 的定价已经是 OpenAI 的 1/20-1/30。当推理优化技术(spec decoding + KV Cache 共享 + 2-bit 量化)成熟后,边际推理成本会逼近电力 + 折旧的物理底线。前沿模型的定价溢价只能来自"独家能力"--一旦能力被复制,定价就会塌方。
趋势二:从"按 token 付费"到"按结果付费"。 当 token 成本足够低、Agent 能力足够强时,用户不再关心用了多少 token--他们关心"这个任务完成了吗"。API 计费正在从 per-token 向 per-task / per-outcome 演进。Anthropic 的 Programmatic Tool Calling (PTC) 展示了一个极端案例:让 Agent 通过代码编排工具而非逐次 API 调用,token 消耗从 15 万降至 2 千--98.7% 降幅。FutureAGI 的分析更直接:在 12 工程师 / 8 MCP server / 每天 22 会话的代表性工作负载中,MCP 协议开销(工具定义 + 响应序列化)占总 token 支出的 41-58%[2]--每花 $1 在模型推理上,约 $0.50 花在协议开销上。
趋势三:成本可观测性成为 AI 平台的基础设施。 Langfuse 的 token/cost tracking、OpenInference 的 semantic conventions、每一家 AI cloud 的 cost dashboard--这些不是"nice to have",是"must have"。没有成本可观测性的 AI 平台,等于没有账单系统的云服务。
引用
[1] Token 分布比例综合自 FutureAGI MCP 分析和多个 Coding Agent trajectory 研究(如 OpenHands/SWE-bench 分析 arXiv:2604.22750)。不同 Agent 框架和任务类型分布差异较大。
[2] FutureAGI, MCP Token Overhead Analysis. 见 CSDN: Codex vs Claude Code MCP 工程化 引用。
[3] OpenRouter, "Fusion: Compound Intelligence API", 2026.06. 见 OpenRouter 官方公告。DRACO 基准数据来自 OpenRouter 官方测试,Fable 5 因内容过滤完成 93/100 任务。
下一篇 Deep Dive 将打开推理引擎的黑盒:从 prefill/decode 的不对称性到 CUDA kernel 级别的 profiling,看看 "200 OK" 背后 GPU 上真正发生了什么。