引言:网络不再是配角
2024 年底,当 Broadcom 宣布 Tomahawk 6(TH6)以 102.4 Tbps 成为业界首个突破 100T 大关的单芯片交换机时,信号已经很明确:AI 网络已从"基础设施"变成"战略武器"。
一年前,NVIDIA 以 Mellanox 遗产为根基,用 Spectrum-X 交钥匙方案迅速占领市场,季度收入突破 20 亿美元。现在,战场全面铺开——从交换芯片到光封装,从 Scale-Up 互连到整机柜交付,从标准组织到客户阵营。
一个核心趋势正在加速:Ethernet 正在吃掉 InfiniBand 的市场。 DriveNets 在 OCP 2025 的总结直截了当——Ethernet 已确定赢得 Scale-Out 和 Scale-Across。下一个战场是 Scale-Up:NVLink(NVIDIA 专有)vs SUE(Broadcom 主导)vs UALink(AMD 主导)。2026 年,这个市场将异常动态。
本文从芯片到系统做一次全栈对标,不回避技术细节,也不忽略商业逻辑。
一、芯片级对标:交换芯片
这是核心战场。三颗芯片,三种策略。
1.1 参数速览
| 参数 | Broadcom TH6 | NVIDIA Spectrum-6 | NVIDIA Quantum-X800 |
|---|---|---|---|
| 交换容量 | 102.4 Tbps | 102.4 Tbps(SN6810) | 115.2 Tbps |
| 架构 | 单芯片 + SerDes chiplet | 单 Spectrum-X CPO 封装 51.2T | 4×Quantum-X CPO 封装 |
| 工艺 | 3nm | 未公开 | 未公开 |
| 端口密度 | 64×1.6T / 128×800G / 512×200G | 128×800G | 144×800G |
| SerDes | 512×200G 或 1024×100G | 未公开 | 未公开 |
| 路由 | Cognitive Routing 2.0 | Spectrum-X 集成 | SHARP v4(14.4 TFLOPS 网内计算) |
| CPO 方案 | Davisson DR 光引擎 | Silicon Photonics(COUPE) | Silicon Photonics |
| 出货状态 | 已开始出货(含 CPO 版) | 预计 2026H2 | 预计 2026 年初 |
关键观察:
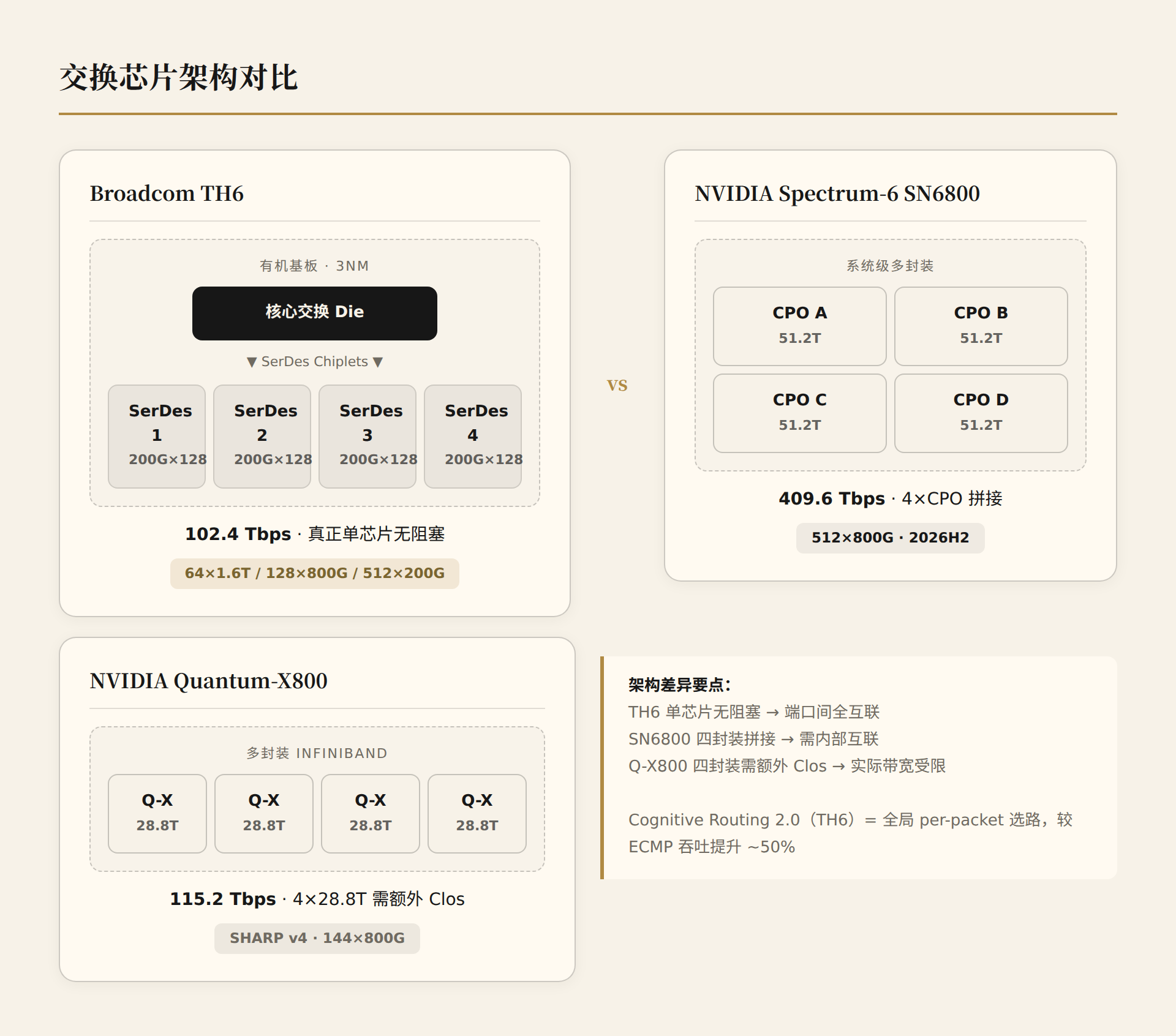
- TH6 是真正的单芯片 102.4T,核心交换 die + SerDes chiplet 在有机基板上封装。这意味着所有端口之间是无阻塞交换,不需要额外 Clos 层。
- NVIDIA Spectrum-6 SN6810 也是 102.4T,但 SN6800 的 409.6T 是 4 个 CPO 封装拼出来的——这是一个多芯片系统,不是单芯片。
- Quantum-X800 的 115.2T 来自 4 个 28.8T 的 Quantum-X CPO 封装。4 个 28.8T 芯片不构成真正的 115.2T 无阻塞交换,需要更多 Clos 层来实现全互联。这是一个架构限制,不是 marketing 问题——但它影响了实际可用带宽。
1.2 架构对比
1.3 Cognitive Routing 2.0:TH6 的秘密武器
TH6 不仅仅是带宽大。Cognitive Routing 2.0 是 Broadcom 在软件定义路由上的重大升级:
- 全局负载均衡:每个数据包(per-packet)选路,基于全网拥塞信息实时调整
- 对比传统 ECMP(等价多路径)静态哈希选路,吞吐提升约 50%
- 这意味着在同样的物理网络上,TH6 能搬运更多有效数据
NVIDIA 在 Spectrum-X 中也集成了拥塞控制,但方式不同——它更多依赖端到端的拥塞信号和直通路由,而非交换机侧的全局选路。两种方案各有取舍:TH6 的方案需要全网状态同步,但一旦就位效果更直接;NVIDIA 的方案更依赖 NIC 侧的智能。
二、NIC 对标:数据通路的起点
NIC 是 XPU 到网络的第一跳,直接影响 AI 训练的实际吞吐。
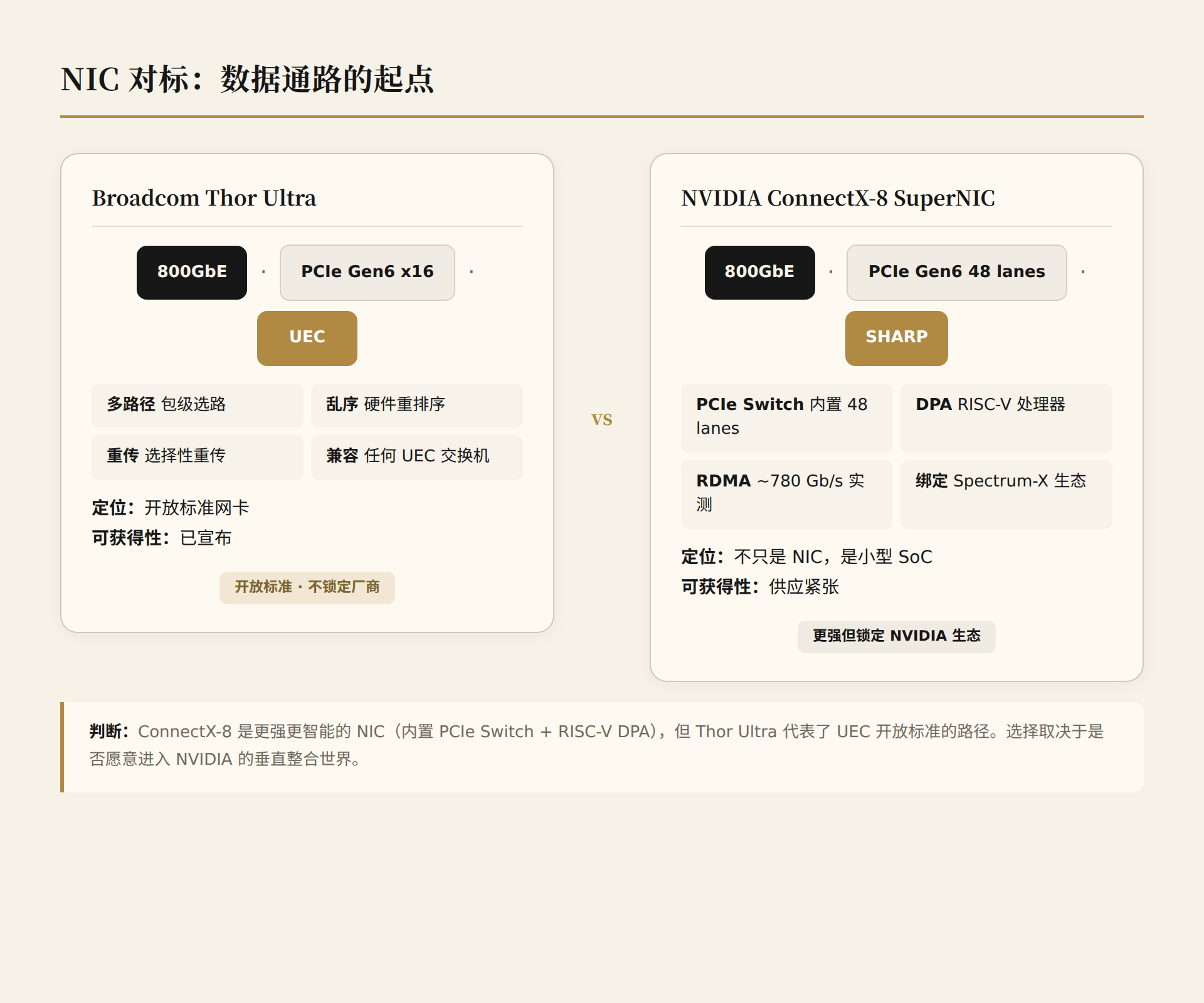
| 参数 | Broadcom Thor Ultra | NVIDIA ConnectX-8 SuperNIC |
|---|---|---|
| 带宽 | 800GbE | 800GbE |
| PCIe | Gen6 x16 | Gen6(内部 48 lanes Switch!) |
| UEC 支持 | 完全符合 UEC 规范 | 不适用(Spectrum-X/Quantum-X) |
| 关键特性 | 包级多路径、乱序传输、硬件选择性重传 | 内置 PCIe Switch、DPA(RISC-V)、SHARP |
| 兼容性 | 兼容所有 UEC 标准交换机 | 绑定 Spectrum-X 或 Quantum-X |
| 加密 | 嵌入式加密加速 | 集成安全引擎 |
| 可获得性 | 已宣布 | 供应紧张,媒体难获测试样品 |
关键发现:ConnectX-8 不只是 NIC。
ConnectX-8 最被低估的特性是内置的 PCIe Gen6 Switch(48 lanes)。在 GB300 NVL72 平台上,这个 Switch 同时连接 Grace CPU(Gen5 x16)、B300 GPU(Gen6 x16)和 SSD(Gen5 x4)。它本质上是一个小型 SoC,不仅仅是网络接口。
Dell 实测数据显示,ConnectX-8 在不同消息大小的 RDMA 下都能接近 800G 线速——每接口约 390 Gb/s,双接口聚合约 780 Gb/s。这是很强的实际性能。
但 Thor Ultra 的优势在于 UEC 开放标准。它支持包级多路径、乱序传输、硬件选择性重传——这些是 UEC 规范的核心能力。Thor Ultra 可以和任何 UEC 标准交换机配合,不锁定特定厂商。
判断: ConnectX-8 是更强更智能的 NIC,但 Thor Ultra 代表了开放标准的路径。选择取决于你是否愿意进入 NVIDIA 的垂直整合世界。
三、CPO 光学方案:两种封装哲学
CPO(Co-Packaged Optics)是 102.4T 时代的必选项——传统可插拔光模块在功耗和密度上已经力不从心。但 Broadcom 和 NVIDIA 选择了截然不同的封装策略。

3.1 Broadcom Davisson:简单、紧凑、不可更换
- 在有机基板上将光引擎永久键合到交换芯片旁
- Edge-coupled 光纤直接从光引擎引出
- 16 个 Davisson DR 光引擎,每个 6.4 Tbps
- 功耗优势显著:Meta 数据显示,800G 2×FR4 可插拔约 15W,而 CPO 光引擎+激光源仅约 5.4W/800G——节省约 65%
- 劣势:光引擎故障不可现场更换,端口降级运行
3.2 NVIDIA Silicon Photonics:模块化、可维护、更复杂
- 采用 TSMC COUPE 工艺,EIC+PIC 3D 堆叠
- 可拆卸 OSA(Optical Sub-Assembly)模块
- 优势:光模块可更换,维护性好
- 声称 10x 可靠性提升(减少光学组件数量)和 3.5x 功效提升
- 劣势:封装工艺更复杂,成本更高
3.3 第三条路:LPO
Andy Bechtolsheim(Arista 联合创始人)仍在推动 LPO(Linear Pluggable Optics) 而非 CPO。逻辑是:如果可插拔光模块的功耗能继续优化(线性直驱,无需 DSP),那么 CPO 的主要优势就消失了。这条路还没有定论,但 Arista 的市场份额和 Bechtolsheim 的行业影响力让这个选项不容忽视。
判断: Davisson 的简单性在超大规模数据中心部署中有实际优势——故障率低、功耗低、密度高。NVIDIA 的可拆卸方案在运维友好性上更好,但增加了封装复杂度。如果 LPO 在 1.6T 时代能跟上功耗要求,整个 CPO 路线可能需要重新评估。
四、Scale-Up 之争:AI 训练的决胜局
Scale-Up 网络连接同一个计算节点内的多个 XPU,是 AI 训练性能的关键瓶颈。这是目前竞争最激烈的战场。
4.1 三条技术路线
| 参数 | NVIDIA NVLink/NVL576 | Broadcom SUE (Tomahawk Ultra) | UALink |
|---|---|---|---|
| 带宽 | 1.8 TB/s/GPU(NVLink 5) | 51.2 Tbps 交换容量 | 未最终定标 |
| 延迟 | 极低(直连) | 250ns(交换式) | 待定 |
| 规模 | NVL72 机柜 / 576 GPU 逻辑单元 | 1024 加速器 | 1024 加速器目标 |
| 协议 | NVIDIA 专有 | Scale-Up Ethernet(优化帧头 46B→10B) | 开放标准 |
| 可靠性 | 链路层重传 | LLR + CBFC | 待定 |
| 集合通信 | NVLink SHARP | In-Network Collectives (INC) | 待定 |
| 成熟度 | 已大规模部署(GB200/GB300) | 已出货(TH5 引脚兼容) | 标准制定中 |
| 标准组织 | 无(NVIDIA 专有) | ESUN(OCP) | UALink Consortium |

4.2 关键分析
NVLink 的护城河是延迟和成熟度。 直连互连的延迟天然低于交换式方案。NVLink 在 GB200/GB300 上已大规模部署,NVL72 机柜已是行业标准配置。
Tomahawk Ultra 的杀手锏是规模。 250ns 延迟虽然高于 NVLink 直连,但对于 1024 加速器的 Scale-Up 域来说已经足够。更重要的是,它使用优化后的 Ethernet 帧(帧头从 46B 压缩到 10B),配合 LLR 和 CBFC,让 Ethernet 在 Scale-Up 场景下的效率大幅提升。与 TH5 引脚兼容意味着已有设计可以快速迁移。
UALink 还在跑。 AMD 主导的开放标准,目标是让非 NVIDIA 的 XPU 也能有高性能 Scale-Up 互连。但标准还在制定中,距离大规模部署还有距离。
ESUN 是新变量。 OCP 2025 全球峰会宣布成立 ESUN 工作组,参与者包括 AMD、NVIDIA、Cisco、HPE/Juniper,聚焦 L2/L3 Ethernet 帧和交换。值得注意的是,Broadcom 退出 UALink 董事会后转向 ESUN——这暗示 Broadcom 更倾向于在 Ethernet 框架内解决 Scale-Up 问题,而不是创建全新的协议。
五、系统级对标:整机柜到交钥匙
芯片是弹药,系统是战场。客户最终购买的是可部署的系统。
5.1 Broadcom 阵营:开放生态
Broadcom 不卖交换机。它卖芯片,然后让 Arista、Juniper、Wistron、Wiwynn、Delta 等厂商基于 TH6 构建交换机。这意味着:
- Arista 基于 TH6 的高密度 800G/1.6T 交换机
- Juniper(HPE)基于 TH6 的数据中心交换机
- Wistron、Wiwynn、Delta 的 ODM 交换机方案
- 客户自由选择 NOS(Arista EOS、Juniper Junos、FBOSS 等)
- 灵活性高,但集成工作在客户侧
5.2 NVIDIA 阵营:垂直整合
NVIDIA 的 Spectrum-X 是 交钥匙方案:
- 交换机(SN6810/SN6800)+ NIC(ConnectX-8)+ 软件(Cumulus Linux/DOCA)一体化
- 从芯片到驱动到协议栈全部优化
- 客户不需要做集成,但必须接受 NVIDIA 的完整技术栈
- 收入已经证明了市场接受度:季度 20 亿美元
5.3 对比
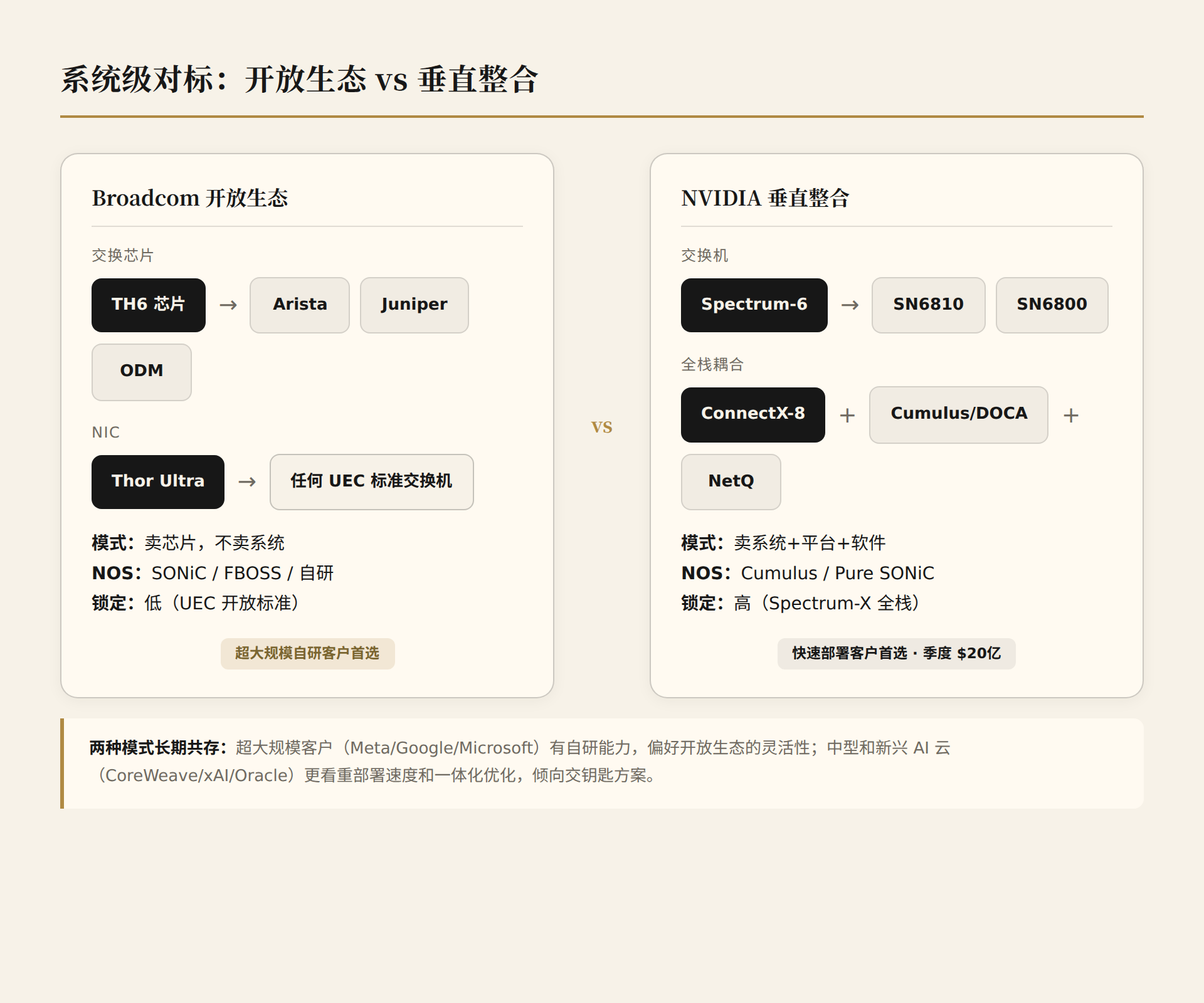
判断: 大型超大规模客户(Meta、Google、Microsoft)偏好 Broadcom 的开放生态——他们有足够的技术能力做集成,而且不愿意被单一供应商锁定。中型和新兴 AI 云(CoreWeave、xAI、Oracle)更倾向 NVIDIA 的交钥匙方案——速度和简单性更重要。
两种模式不是谁打败谁的问题,而是服务不同的客户群体。
六、部署案例分析
6.1 Meta:从自研到混合
Meta 是超大规模客户中最值得观察的案例。
- 传统路径:自研 FBOSS 网络操作系统 + 自研 Minipack 系列交换机(基于 Broadcom 芯片)
- 新动向:OCP 2025 宣布采用 Spectrum-X,集成到 FBOSS + Minipack3N 交换机
- 这意味着 Meta 在保持自研 NOS 的同时,引入了 NVIDIA 的交换芯片
- Meta 同时是 TH6 CPO 功耗数据(15W vs 5.4W)的公开来源——暗示他们也在评估 Davisson 方案
解读: Meta 不是在 Broadcom 和 NVIDIA 之间做非此即彼的选择。它在构建一个多供应商策略,用 FBOSS 作为统一抽象层,底层芯片按需选择。这是超大规模客户的典型做法。
6.2 Oracle:NVIDIA 的标杆客户
Oracle 用 Spectrum-X 构建 giga-scale AI factory,基于 Vera Rubin 架构。这是 NVIDIA 交钥匙方案在超大规模场景的展示窗口。
Oracle 的选择逻辑清晰:快速上市、一体化优化、与 NVIDIA GPU 的深度集成。对于 Oracle 来说,AI 基础设施是卖云服务的手段,网络本身的差异化不是核心竞争力。
6.3 CoreWeave 和 xAI:速度优先
CoreWeave 和 xAI 都是 NVIDIA 的大客户。CoreWeave 专门做 GPU 云,xAI 的 Colossus 集群规模惊人。这些客户的核心诉求是快速部署、最大化 GPU 利用率——这正是 Spectrum-X 交钥匙方案的优势场景。
6.4 超大规模客户的 TH6 部署
CRN 报道,多个超 10 万加速器规模的 TH6 部署正在规划中。Arista、Juniper、Wistron、Wiwynn、Delta 已展示基于 TH6 的交换机。
这些客户是谁?大概率是拥有自研网络能力的超大规模云厂商——他们有能力在 TH6 芯片上构建自己的网络栈,而且 102.4T 的端口密度(512×200GbE)意味着更少的交换层和更低的延迟。
七、生态与战略:开放 vs 封闭的永恒命题
7.1 标准组织博弈
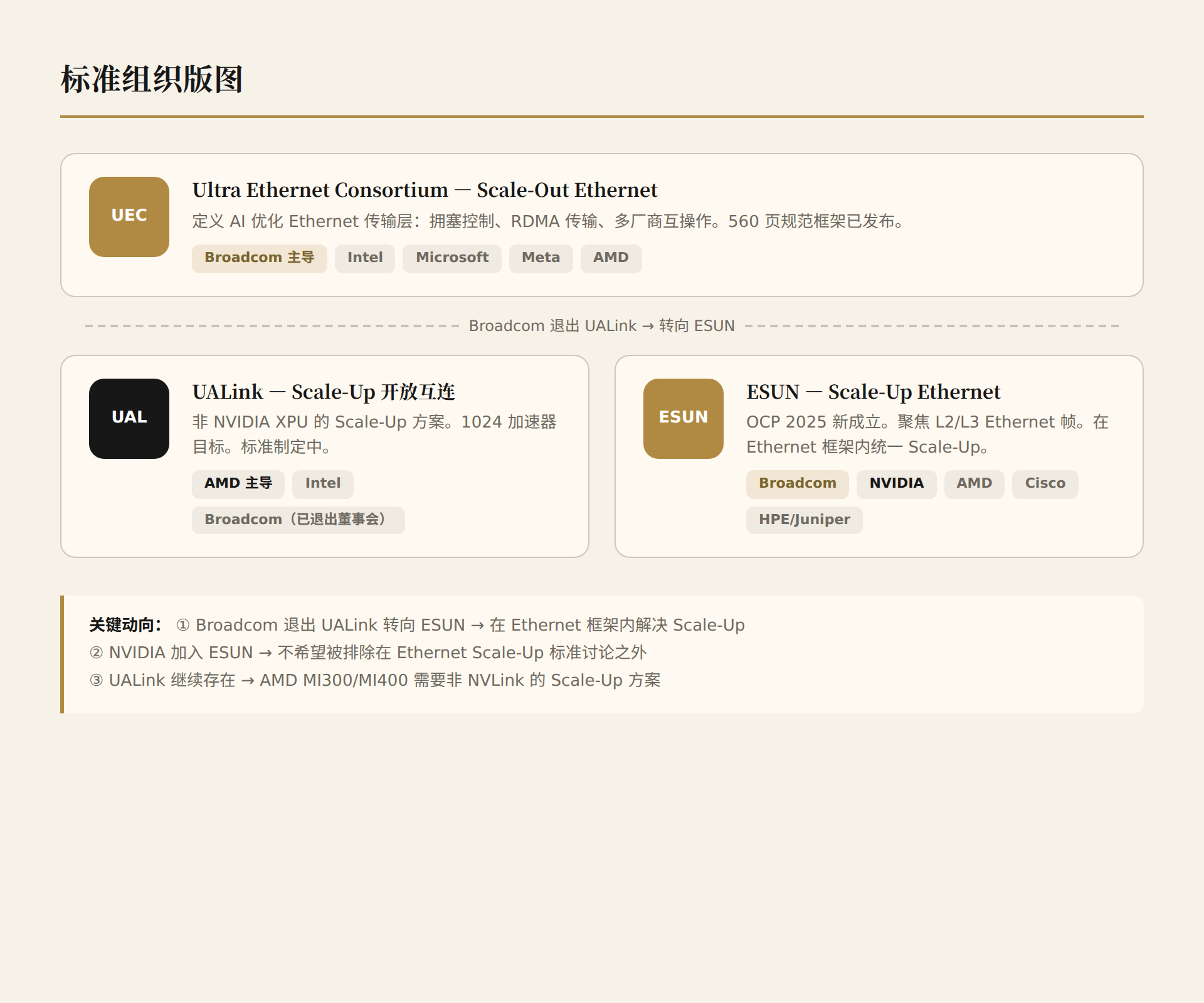
值得注意的动向:
- Broadcom 退出 UALink 董事会,转向 ESUN——这表明 Broadcom 的策略是在 Ethernet 框架内统一 Scale-Up 和 Scale-Out,而不是创建一个独立的 Scale-Up 协议
- NVIDIA 加入 ESUN——即使 NVIDIA 有 NVLink,加入 ESUN 意味着它不希望被排除在 Ethernet Scale-Up 的标准讨论之外
- UALink 继续存在——AMD 的 MI300/MI400 需要一个不是 NVLink 的 Scale-Up 方案
7.2 商业模式差异
| 维度 | Broadcom | NVIDIA |
|---|---|---|
| 核心业务 | 卖芯片 | 卖系统+平台 |
| 客户关系 | 芯片厂商→OEM/ODM→终端 | 直接面向终端用户 |
| 生态策略 | 开放标准,多厂商 | 垂直整合,单一供应商 |
| 锁定程度 | 低(UEC 标准) | 高(Spectrum-X 全栈) |
| 利润模式 | 芯片毛利 | 系统毛利+软件订阅 |
| 客户画像 | 超大规模自研客户 | 快速部署客户 |
这两种模式都有其合理性和市场空间。NVIDIA 的垂直整合在速度和优化深度上有优势,Broadcom 的开放生态在灵活性和成本上有优势。
八、结论与判断:2026 年 AI 网络市场格局
8.1 六个核心判断
1. Ethernet 赢了 Scale-Out,InfiniBand 退守高性能计算。
InfiniBand 在传统 HPC 场景仍有优势(低延迟、SHARP 集合通信),但在 AI 训练的 Scale-Out 场景中,Ethernet 的成本、生态和灵活性优势已经不可逆转。NVIDIA 自己也在大力投入 Spectrum-X Ethernet,这本身就是信号。
2. TH6 的 102.4T 单芯片是真正的技术领先。
不是 marketing 数字。真正的单芯片无阻塞 102.4T 交换,配合 Cognitive Routing 2.0,在实际部署中的端口利用率和有效吞吐都优于多芯片拼凑方案。这是 Broadcom 在交换芯片设计上的硬实力体现。
3. Scale-Up 是 2026 年最值得关注的战场。
NVLink 有先发优势和成熟度,但 SUE 的 1024 加速器规模和以太网兼容性是实打实的差异化。ESUN 标准的进展将直接影响 Broadcom 和 NVIDIA 在这个领域的博弈。
4. CPO 将成为 100T+ 交换机的标配,但封装路线未定。
Davisson 的简单性在超大规模部署中有优势,NVIDIA 的可拆卸方案在运维友好性上更好。LPO 能否在 1.6T 时代保持竞争力是未知数。2026 年会是三种方案并存的验证期。
5. 开放生态和垂直整合将长期共存。
这不是零和游戏。超大规模客户选择 Broadcom 的开放生态,中型客户和新兴 AI 云选择 NVIDIA 的交钥匙方案。两种模式服务不同需求。
6. 供应能力是隐性竞争维度。
ConnectX-8 供应紧张到连 ServeTheHome 都拿不到测试样品——这不仅仅是产能问题,更是 NVIDIA 在需求激增时能否保证交付的问题。Broadcom 的芯片供应渠道(通过 Arista、Juniper 等)更分散,弹性可能更好。
8.2 2026 年市场格局预测

8.3 给决策者的建议
- 如果你是超大规模云厂商:TH6 + Thor Ultra + UEC 是最灵活的组合。你可以选择自己的 NOS、ODM 和光模块方案。Cognitive Routing 2.0 在大规模部署中的吞吐优势是实打实的。
- 如果你是 AI 云创业公司:NVIDIA Spectrum-X 交钥匙方案让你最快上线。不要在网络上花太多时间优化——把精力放在模型和客户上。
- 如果你是网络设备厂商:TH6 是你必须支持的平台。102.4T 单芯片的端口密度和路由能力是 2026 年的基准。
- 如果你在做投资判断:关注 ESUN 标准的进展和 Broadcom 在 Scale-Up Ethernet 上的落地速度。这比单颗芯片的参数更重要。
本文基于公开技术资料、OCP 2025 全球峰会信息、厂商发布会数据及行业分析报告编写。所有数据截至 2025 年 5 月。