2026 年 5 月 | 基于华为《昇腾 950 NPU 架构白皮书》及公开信息的竞争力分析 本文不是白皮书搬运。白皮书规格数据作为论据嵌入分析,完整规格表见附录。
一、核心论点
昇腾 950 单卡 FP8 算力只有 NVIDIA B300 的 23%(FP4 只有 15%)。
这个数字看起来不值得讨论。但它的互联带宽反超 12%(2016 vs 1800 GB/s),超节点 Scale-Up 上限是 NVL72 的 114 倍(8192 vs 72 卡),集群最大规模超过 128K 卡。
华为不是在追赶 B300。它在赌一件事:AI 模型的瓶颈正在从"单卡算力"转向"卡间通信"。MoE(混合专家)架构让每个 Token 只激活一小部分参数,跨专家的 All-to-All 通信成为训练和推理的真正瓶颈。华为赌的就是这个转折点。
如果赌对了——MoE 和稀疏化继续深化——系统级互联优势的价值会持续放大。如果赌错了——稠密模型回归或算法突破降低了通信需求——单卡算力的结构性差距将长期存在。
本文从五个维度展开论证:华为赌了什么(二章)、怎么实现(三/四章)、值不值(五章)、对手怎么打(六章)、迁移怎么做(七章)。
二、两条路线:华为 vs NVIDIA
2.1 封装创新 vs 制程追赶
950 的核心架构决策是 Chiplet UMA:2 个 AI Die + 2 个 IO Die 合封,通过 D2D Clink 互联,对外呈现为单一地址空间。

这不是临时方案。华为在制程被限制的条件下,选择了一条和 NVIDIA 单 Die + HBM3e 截然不同的路线:
| 维度 | 华为路线 | NVIDIA 路线 |
|---|---|---|
| 核心策略 | 封装创新弥补制程差距 | 制程领先 → 单 Die 极致性能 |
| 芯片架构 | Chiplet: 2×AI Die + 2×IO Die | 单 Die(Blackwell) |
| 内存方案 | 自研 HiBL/HiZQ | HBM3e(三星/SK海力士) |
| 互联策略 | 开放协议 UB 2.0 + 全栈自研 | NVLink 5.0(封闭) |
| 扩展上限 | 8192 卡超节点 | 72 卡 NVL72 |
赌注的本质:封装和互联的进步速度,能否快到弥补制程代差?
封装侧进展可信——Chiplet UMA 的 Die 间延迟足够低,72 Lane HiLink SerDes × 112Gbps 提供 2016 GB/s 双向带宽。但风险同样明显:
- Die 面积利用率:D2D 互联占用 Die 面积,这部分在单 Die 方案中可用于计算
- 合封良率:4-Die 合封良率随 Die 数量指数增长
- 功耗开销:Die 间通信有额外功耗,950 满配 ~600W(vs B300 ~1400W,但算力只有 23%)
判断:封装路线是当前制裁条件下的最优解,但是有天花板的选择。如果制程限制长期存在,华为需要在"天花板到来之前"通过互联和系统级创新建立足够深的护城河。
2.2 互联反超:MoE 时代的结构性转折
2016 GB/s vs 1800 GB/s——这是 950 规格表中最值得关注的数字。
为什么?因为 AI 模型的架构演化正在改变"什么才是瓶颈"。
MoE 之前(GPT-4 稠密模型时代):训练和推理的主要瓶颈是单卡矩阵乘法算力。NVIDIA 的单 Die 极致路线完美匹配这个需求。
MoE 之后(DeepSeek V4、盘古 Ultra MoE):每个 Token 只激活 3-5% 的参数,但需要跨所有专家做 All-to-All 通信。通信量随专家数和并行度急剧上升。在这个场景下:
- UB On Chip Switch:IO Die 内 9 个 Port 可独立转发,不进入计算 Die,不占用 DRAM 带宽
- CCU 硬化集合通信:AllReduce / AllGather / All-to-All 都有专用硬件加速,不占用 AI Core 算力
- UB Memory Load/Store 语义:小规模通信可以直接用同步访存,对 MoE Token 路由特别有利——数据量小但延迟敏感
另一面:NVIDIA 不是没有应对。NVL72 把 72 卡做成一个 NVLink 域,GB300 NVL4 用 Grace CPU + 4 个 B300 组成共享内存节点。NVIDIA 的思路是"系统级也做创新,但不改变单 Die 优先的根本路线"。两者的区别是:华为的 Scale-Up 上限是 8192 卡,NVIDIA 是 72 卡——差了两个数量级。
判断:互联反超不是单点优势,是对 AI 模型演化方向的系统性押注。窗口期有限——NVIDIA 正在通过 NVL72 / NVL576 缩小差距。
2.3 自研 HBM:被逼出来的供应链方案
950 的另一个关键赌注是自研内存:
| 版本 | 模块 | 单卡容量 | 单卡带宽 | 定位 |
|---|---|---|---|---|
| 950PR | 8×HiBL 1.0 | 128 / 112 GB | 1.6 / 1.4 TB/s | 推理优先 |
| 950DT | 4×HiZQ 2.0 | 144 / 96 GB | 4 TB/s | 训练+推理 |
对比 B300 的 288 GB HBM3e / 8 TB/s 带宽,950DT 带宽只有 50%,容量只有 50%。
为什么 950PR 用 8 个模块而 950DT 只用 4 个? HiBL 是低成本方案,单模块带宽低,需要更多模块并行才能达到 1.6 TB/s。HiZQ 是高性能方案,4 个模块就能做到 4 TB/s。
判断:自研 HBM 是出口管制下的被迫选择。短期内是供应链安全方案,但带宽差距(4 vs 8 TB/s)会持续制约单卡性能。华为需要自研 HBM 的迭代速度跟得上 JEDEC 标准,否则差距越拉越大。
2.4 规格对比卡片
| 维度 | Ascend 950DT | NVIDIA B300 | 比值 |
|---|---|---|---|
| FP8 算力 | 1034 TFLOPS | 4500 TFLOPS | 0.23× |
| FP4 算力 | 2007 TFLOPS | 13,125 TFLOPS | 0.15× |
| BF16 算力 | 547 TFLOPS | 2250 TFLOPS | 0.24× |
| HBM 容量 | 144 GB (HiZQ) | 288 GB (HBM3e) | 0.5× |
| 内存带宽 | 4 TB/s | 8 TB/s | 0.5× |
| 互联带宽 | 2016 GB/s | 1800 GB/s | 1.12× |
| L2 Cache | 128 MB | ~32 MB | 4× |
| 功耗 | ~600W | ~1400W | 0.43× |
| FP8/W | ~1.72 TFLOPS/W | ~3.21 TFLOPS/W | 0.54× |
完整规格表见附录 A。
三、950 架构及技术详细分析
本章深入拆解 950 的芯片架构。关注商业判断的读者可以跳过,直接进入第四章。
3.1 Chiplet UMA:2+2 合封的工程实现
950 的物理架构是 2×AI Die + 2×IO Die + Memory 模块,通过 D2D Clink 合封为统一地址空间。
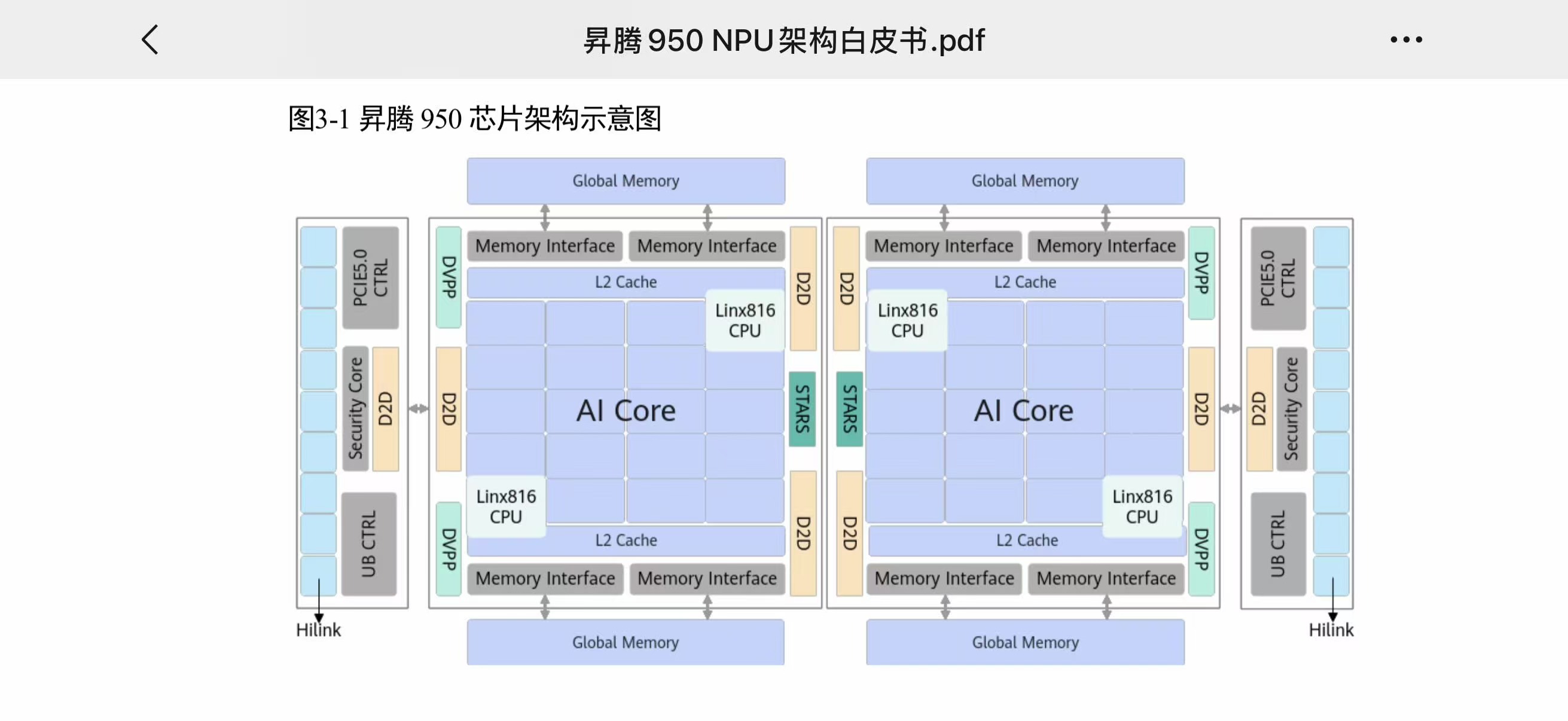
来源:华为《昇腾 950 NPU 架构白皮书》图 3-1
两个 AI Die 各自承载一半的 AI 子系统,通过 IO Die 的 HiLink SerDes 对外通信。IO Die 同时承担 UB 协议处理、On Chip Switch 转发、PCIe 控制器等 IO 功能,不占用 AI Die 的计算资源。
950PR 和 950DT 的差异仅在 Memory 模块:PR 配 8 个 HiBL 1.0(低成本、高容量),DT 配 4 个 HiZQ 2.0(高带宽)。
3.2 第三代 DaVinci:AI Core 架构
每个 AI 子系统包含 1 个 Cube Core + 2 个 Vector Core。
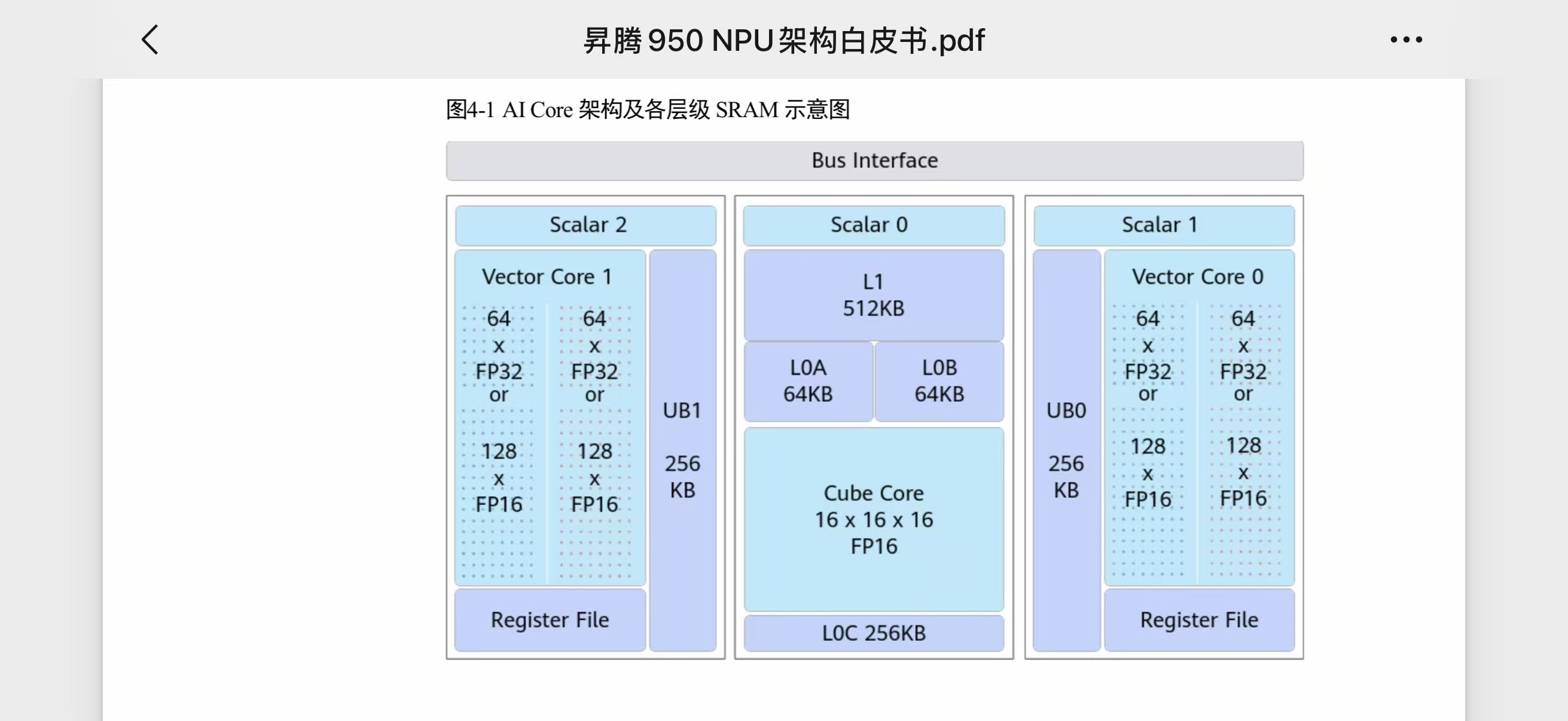
来源:华为《昇腾 950 NPU 架构白皮书》图 4-1
3.2.1 Cube Core(张量计算)
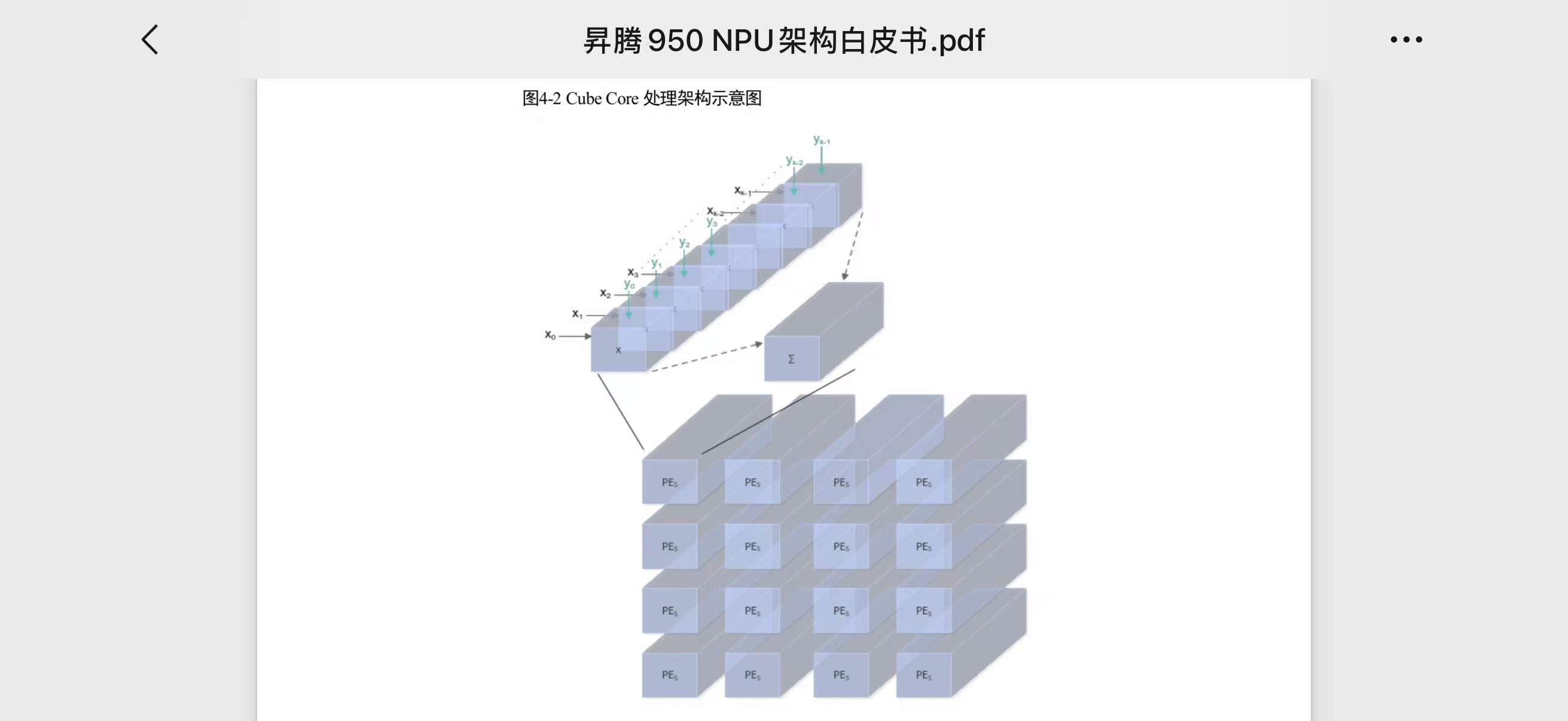
来源:华为《昇腾 950 NPU 架构白皮书》图 4-2
新增精度格式:
| 格式 | 相对 BF16 算力 | 说明 |
|---|---|---|
| MXFP4 | 4× | 算力跃升最大 |
| HiF8 / MXFP8 / FP8 | 2× | 三种 8-bit 格式共享同一算力档位 |
| INT8 | 2× | 整数张量计算 |
| BF16 / FP16 | 1×(基准) | 传统浮点 |
| TF32 | 0.5× | 兼容性格式 |

来源:华为《昇腾 950 NPU 架构白皮书》图 4-3
Cube Core 独有能力:
- 随路量化:L0C Buffer → Unified Buffer 回写阶段,直接完成 FP32/INT32 → BF16/FP16/FP8/INT8 的量化 + 排布转换
- 更大 L0C Buffer(256KB):支持 256×256 tile,提高数据复用率
- 针对 GEMM / FlashAttention 等关键算子优化缓存复用
3.2.2 Vector Core(向量计算)
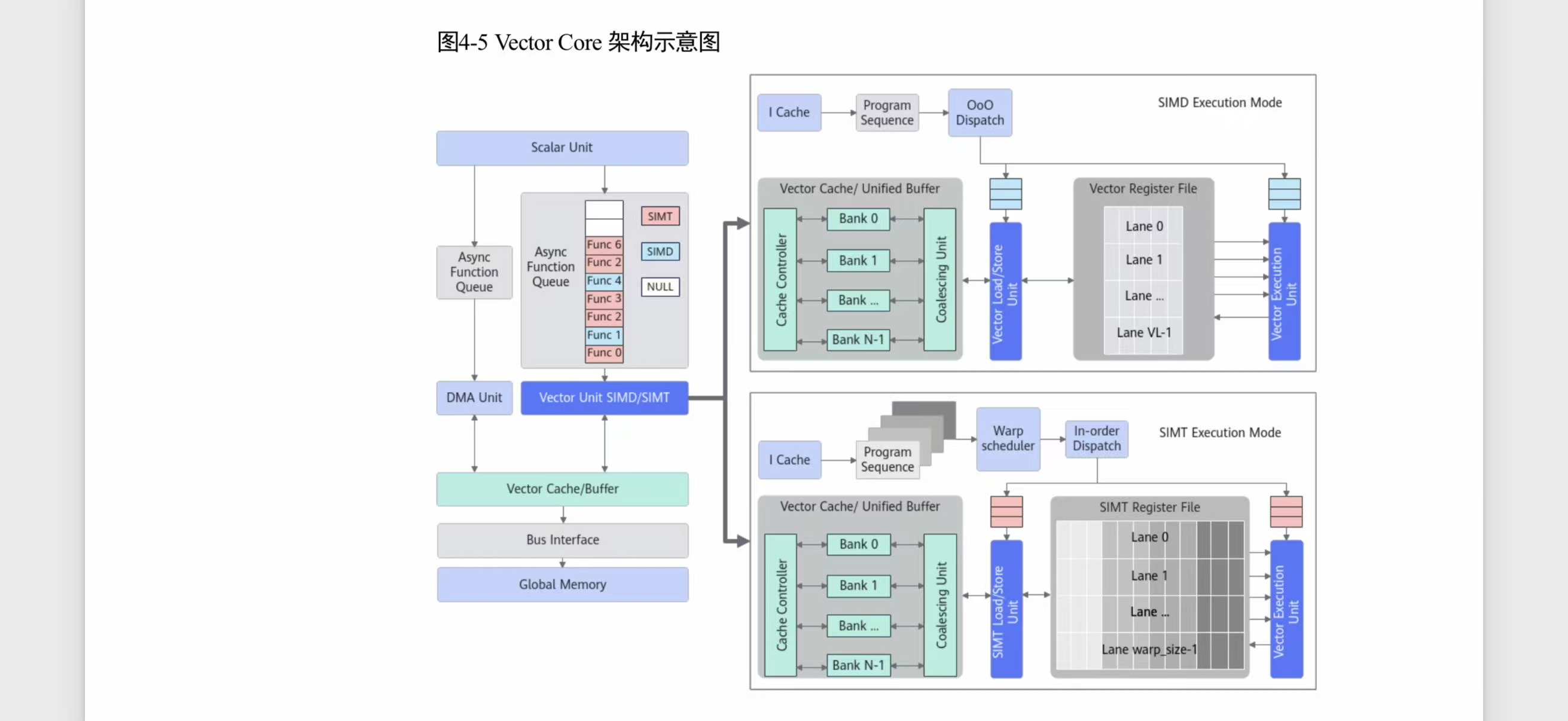
来源:华为《昇腾 950 NPU 架构白皮书》图 4-5
Vector Core 处理非矩阵运算:激活函数、归一化、类型转换、元素级运算。950DT 满配 Vector FP16/BF16 算力为 60 TFLOPS,与 Cube Core 的 486 TFLOPS (BF16) 之比约为 1:8。
3.3 HiF8:自研锥形精度格式
华为自研的 HiF8 是 950 值得关注的技术选择:
- 38 个阶码(vs FP8 E4M3 的 18 个),动态范围 [-22, 15],接近 FP16
- 变长尾数:靠近 1 的数值精度高,远离 1 渐低——"锥形精度"
- 不需要 MX 缩放因子:简化量化流程

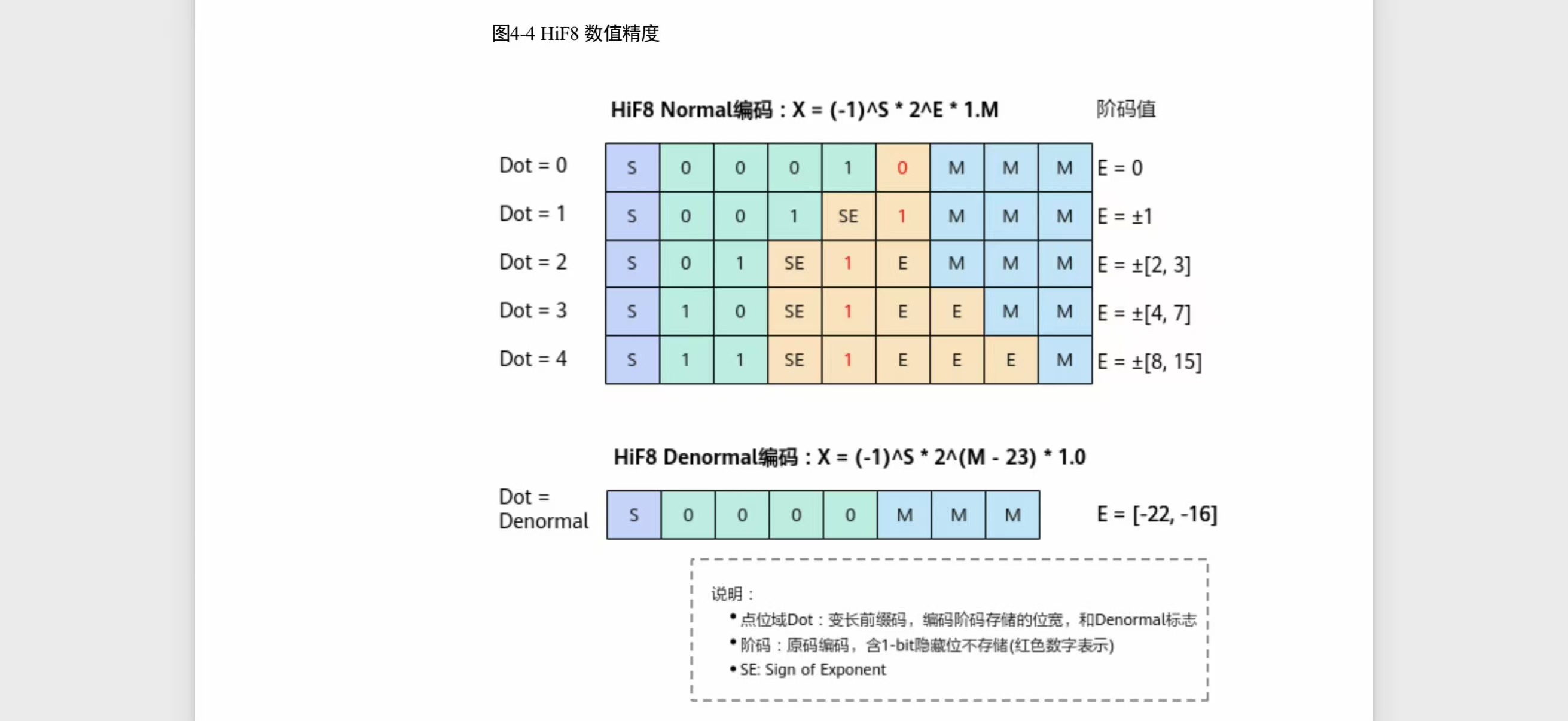
来源:华为《昇腾 950 NPU 架构白皮书》图 4-4
设计上的优势:38 个阶码意味着 HiF8 的动态范围几乎是 FP8 E4M3 的两倍,不需要额外的缩放因子就能覆盖训练中的梯度分布。
生态上的风险:PyTorch、TensorFlow、vLLM 都不认识 HiF8。需要 CANN 编译器做格式转换。在没有第三方验证的情况下,客户更可能选择"已知可用"的 FP8/MXFP8,而不是"理论更好"的 HiF8。
3.4 SIMT 双模:降低 CUDA 迁移门槛
910C 时代的问题:纯 SIMD 架构。CUDA 的 SIMT 编程模型不能直接映射,大量 CUDA 自定义优化无法移植。
950 的变化:SIMD + SIMT 双执行模式。SIMD 处理结构化计算(GEMM、卷积),SIMT 支持线程级并行,CUDA 的线程组织模型(Thread / Warp / Block)可以更直接映射。
注意:SIMT 不是 CUDA 兼容层。它提供了更接近 CUDA 的执行模型,但编译器优化、算子库适配、调试工具都需要时间成熟。
3.5 CV 融合通路
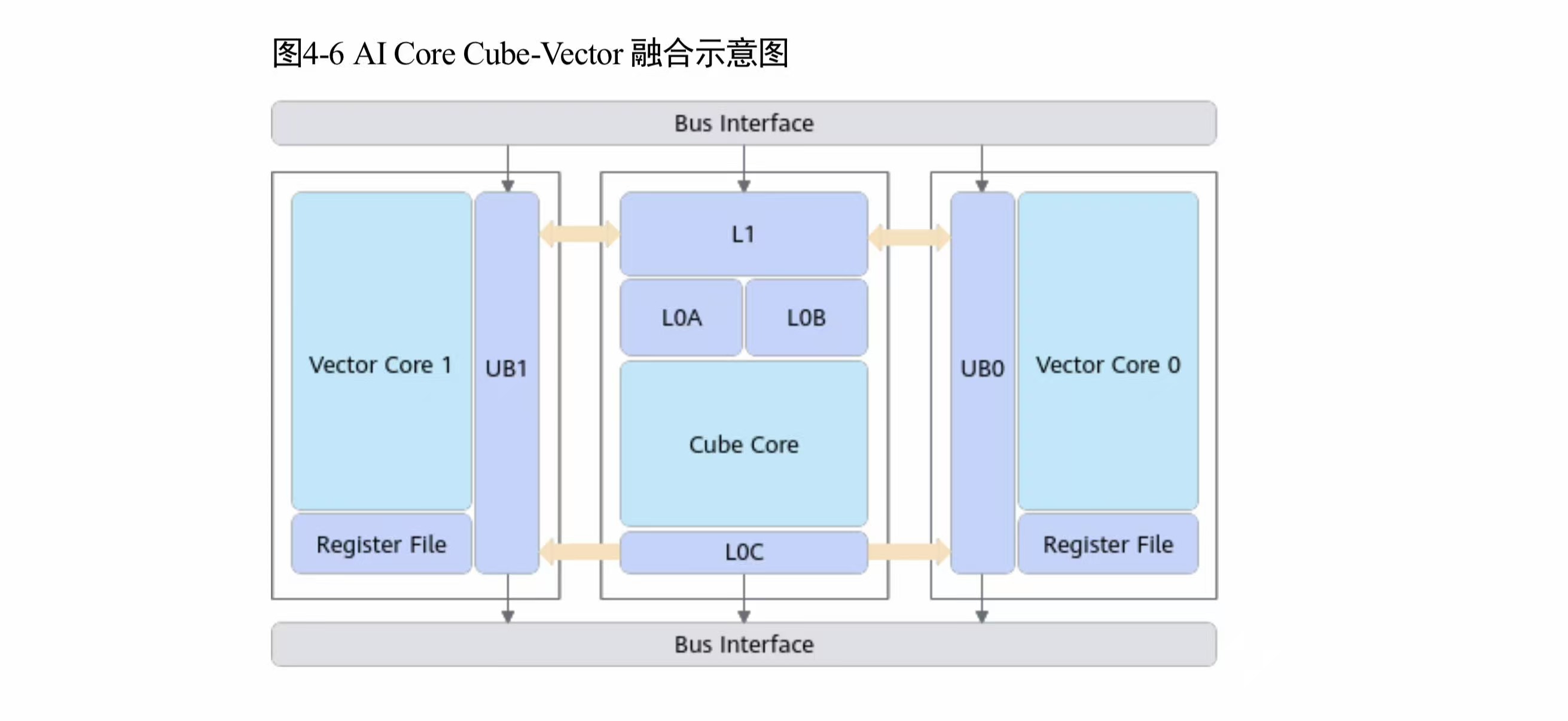
来源:华为《昇腾 950 NPU 架构白皮书》图 4-6
Cube Core 和 Vector Core 之间的直连数据通路。FlashAttention 等 Cube-Vector 混合算子不需要中间 Buffer,减少一次数据搬移。对注意力机制的计算效率有直接提升。
3.6 NDDMA 与随路量化

来源:华为《昇腾 950 NPU 架构白皮书》图 4-7
- NDDMA:硬件层面完成 reshape / transpose / 数据排布转换,替代 CUDA 中的独立 kernel
- 随路量化:L0C → UB 回写时直接完成 FP32→FP8/INT8 量化,不需要额外 kernel
- 两者结合,减少了 kernel launch 开销和数据搬移次数
3.7 内存层级
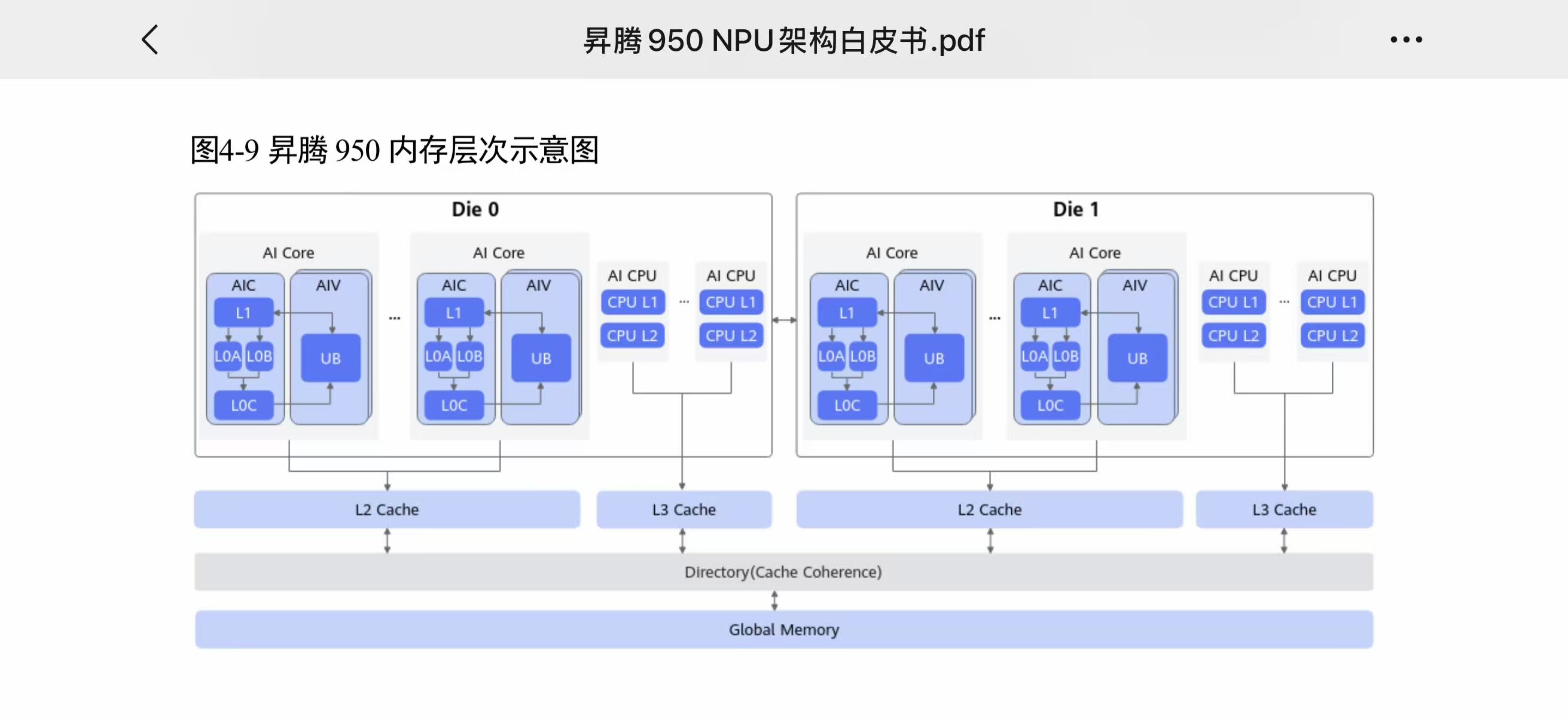
来源:华为《昇腾 950 NPU 架构白皮书》图 4-9
L0A / L0B (Cube 输入) → L0C (Cube 输出, 256KB) → UB (Unified Buffer)
→ L1 Cache → L2 Cache (128MB, 512B line + 128B Sector) → HBM (HiBL/HiZQ) → UB Memory (跨卡)
128B Sector-Cache 是针对 MoE 的关键设计:MoE 稀疏激活和 KV Cache 压缩场景下,带宽效率比 910C 的 512B 颗粒度提升 4 倍。
3.8 同步机制与调度

来源:华为《昇腾 950 NPU 架构白皮书》图 4-8
- BufferID 同步:替代传统的事件同步,开销更低
- STARS2.0 硬件调度器:支持 2048 条任务流下沉到 Device,减少 CPU-GPU 同步开销
3.9 AI CPU 与 DVPP
- Linx816 CPU:自研 ARMv8-A 双线程,950PR 8C16T / 950DT 8C16T
- DVPP:4×VPC + 8×JPEGD + 4×JPEGE,支持 STARS 直接硬件调度
四、SuperPoD:华为系统工程的极致表达
4.1 互联详细设计:从 Die 到百万卡
华为的互联不是"加交换机连更多卡"。它是一套从 Die 内部延伸到机房级别的完整架构,白皮书花了两章详细描述——华为自己也认为这是 950 最核心的差异化。
五层互联架构
第一层:Die 内部
- 2×AI Die + 2×IO Die 通过 D2D Clink 互联,统一地址空间
- 72 Lane HiLink SerDes × 112Gbps = 18 个 x4 Port
- UB On Chip Switch:IO Die 内 9 Port 独立转发,经 NoC 完成,不进入计算 Die,不占用 DRAM 带宽
- 对外总双向带宽 2016 GB/s
第二层:节点内(2 CPU + 8 NPU)
- 2 个 Host CPU + 8 个 NPU = 1 个 OS 节点(CPU 支持鲲鹏及 x86)
- 计算板:每板出 7×x4 UB 端口,FullMesh 连接
- 交换板:L2 Switch 配置,每板 4 或 8 端口
第三层:柜内 Scale-Up(64 NPU / 8 节点)
- 8 节点(64 NPU + 16 CPU)= 1 个计算柜
- 2D-FullMesh 铜缆直连 + UB Switch 芯片
- 单柜功率密度 >120 kW,液冷
64 张 950DT 提供 66 PFLOPS FP8 算力——已超出 8×B300 的 36 PFLOPS。这是 950 最小的"完整作战单元"。
第四层:柜间 Scale-Up(8192 NPU)
- 128 计算柜 + 32 互联柜 = 160 柜
- 全光互联 + OCS(光路交换)
- 总互联带宽 16.3 PB/s
- 跨柜时延 2.1 μs
8192 卡的 Scale-Up 域是 NVL72 的 114 倍。在一个共享内存域内,8192 张卡可以直接 Load/Store 互相访问——不需要消息传递,不需要协议转换。

第五层:Scale-Out(>128K 卡)
- 支持 UBoE 和 RoCE 两种协议
- 基于 UB Switch 或 UBoE 搭载以太 Switch 组网扩展
- 集群规模支持超过 128K 卡
带宽端到端分析
一个 Token 的数据从 Die A 的 AI Core 发到 Die B 的 AI Core,完整路径:
| 段 | 路径 | 带宽 | 延迟 |
|---|---|---|---|
| AI Core → L2 | 片内总线 | ~8 TB/s | ~10 ns |
| L2 → HBM | DDR-like 接口 | 4 TB/s | ~100 ns |
| AI Die → IO Die | D2D Clink | ~1 TB/s | ~20 ns |
| IO Die → IO Die(片内转发) | UB On Chip Switch (NoC) | 数 Tbps 级 | ~50 ns |
| 芯片 → 芯片(节点内) | HiLink × 7 Port | ~1.75 TB/s | ~200 ns |
| 节点 → 节点(柜内) | UB Switch + 铜缆 | ~数百 GB/s | ~1 μs |
| 柜 → 柜(光互联) | OCS + 光纤 | 16.3 PB/s 总量 | ~2.1 μs |
关键发现:单跳通信时延从片内的 200ns 到跨柜的 2.1μs,只差一个数量级。这意味着在 8192 卡的 Scale-Up 域内,MoE 的 All-to-All 延迟是可控的——这是华为互联设计的核心价值。
超节点组网能力
白皮书 4.7 节确认了多种组网形态:
- 超大内存池:NPU 可通过 UB 端口直接访问 CPU 的超大内存池(高带宽低延迟)
- 超大存储资源池:NPU 通过 UB 端口直接访问存储资源池,不需要中间存储协议转换
- 以太互通:通过 UB Switch 提供 UB→Ethernet 转换;950 芯片可直接通过 UBoE 接入以太网
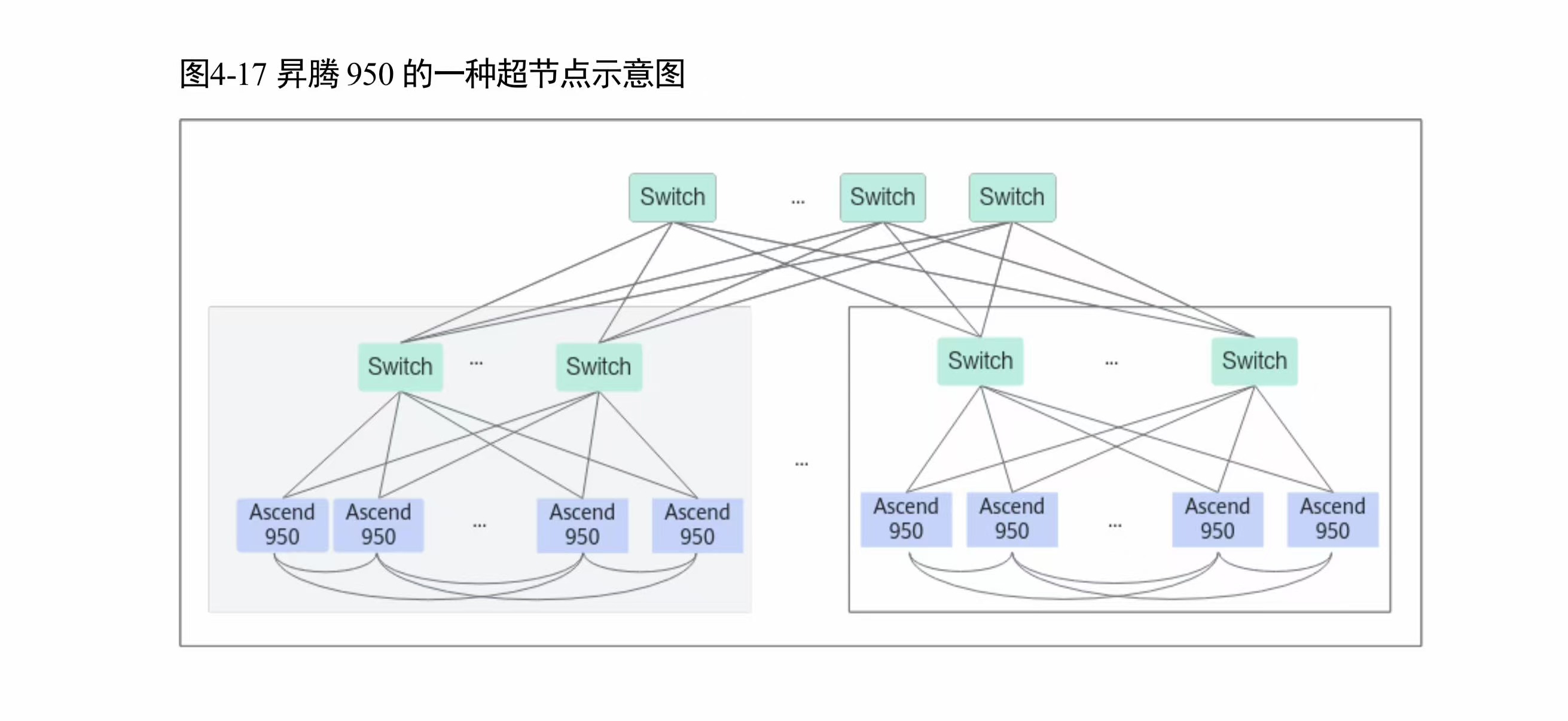
来源:华为《昇腾 950 NPU 架构白皮书》图 4-17

4.2 整机柜创新
互联架构决定"能连多少卡",SuperPoD 的竞争力不止于此。从芯片到机柜的工程创新决定了 8192 卡集群能否真正跑起来。
机柜架构:"计算柜 + 互联柜"分离
- 128 计算柜 + 32 互联柜 = 160 柜,共 8192 张 950DT
- 每计算柜:16 台 1U 服务器,64 张 NPU(8 节点 × 8 卡)
- 互联柜:部署 UB Switch + OCS 光交换设备
- 分离设计使计算柜可独立维护,互联柜按需扩展
散热:全液冷强制,无风冷选项
单柜 >120 kW,风冷压不住。华为的液冷方案:
- 分布式独立冷板:每颗 NPU 单独冷板,精细化散热
- 机柜式 CDU:集中分配冷却液,减少机柜空间占用
- EPDM 材质液冷软管 + 浮动接头:缓解热膨胀和振动应力,"零漏液"
- iCooling 智能温控:NPU 核心温度稳定在 45°C 以下,PUE 1.12
| 方案 | 散热方式 | PUE | 规模 |
|---|---|---|---|
| Atlas 950 SuperPoD | 冷板式全液冷 | 1.12 | 8192 卡 |
| NVIDIA NVL72 | 全液冷 | ~1.15 | 72 卡 |
| 超聚变 FusionPod | 冷板 + 液冷背门 | 1.06 | 64 卡 |
| 中科曙光 ScaleX640 | 浸没相变液冷 | — | 640 卡 |
华为的 PUE 1.12 不是最低(超聚变 1.06),但 8192 卡规模的工程难度和 64 卡完全不同。
供电:HVDC + 预制化交付
- 高压直流(HVDC)减少 AC-DC 转换损耗
- 智能功耗管理:根据负载动态调整芯片频率和电压
- 整机柜预制化交付:现场仅连接冷却管路和电源母线,部署周期缩短 80%+
可靠性:99.99% 可用性目标
万卡集群面临"木桶效应"——单卡故障导致全集群停摆不可接受:
- 硬件层:片上 ECC + 巡检 + 行失效隔离;UB 链路层重传 + 端到端可靠重传
- 系统层:故障预测、快速隔离、任务迁移,单点故障影响域约束在最小子集
- 关键部件支持在线热插拔
内存:1152TB 统一内存池
- 任意 NPU 可透明访问其他 NPU 的 HBM + CPU DDR(统一编址)
- HBM → DDR → SSD 三级层次:热数据 HBM,温数据 DDR,冷数据 SSD
- 总容量 1152TB(vs NVL72 的 30.5TB)——38 倍
4.3 全球超节点竞品定位
当前全球超节点方案分三个层级:
| 层级 | 方案 | 规模 | 定位 | 关键特征 |
|---|---|---|---|---|
| 超大规模 | 华为 Atlas SuperPoD A5 | 8192 卡 | 国家级智算中心 | UB-Mesh + OCS + 可私有化 |
| 谷歌 TPU v7 Pod | 9216 卡 | 云端 AI 基础设施 | 3D Torus + OCS + 仅云服务 | |
| 大规模 | 阿里磐久 AL128 | 128 卡 | 云服务商 | 一云多芯,开放架构 |
| 中科曙光 ScaleX640 | 640 卡 | HPC+AI | 浸没相变液冷 | |
| 百度天池 512 | 512 卡 | 大模型训练 | 自研 CDU | |
| 中型 | NVIDIA NVL72 | 72 卡 | 企业级 | 单 Die 极致算力 |
| AMD Helios 72 | 72 卡 | 开放替代 | UALink 开放生态 | |
| 腾讯 ETH-X 64 | 64 卡 | 开源方案 | RoCEv2 开放协议 |
华为和谷歌是仅有的两个做到 8000+ 卡 Scale-Up 的方案。 但两者有根本区别:
- 华为:支持私有化部署,开放灵衢协议,面向全球销售硬件
- 谷歌:仅通过 Google Cloud 提供服务,不支持私有化,生态封闭(JAX/TensorFlow only)
华为的"开放 + 可私有化"定位在中国市场有独特优势——政府和大型国企的数据安全要求决定了不可能把训练数据放在 Google Cloud 上。
产品路线图:

| 产品 | 代号 | 芯片 | 卡数 | 机柜 | 上市 |
|---|---|---|---|---|---|
| Atlas 900 A3 | A3 | 910C | 384 | 16 | 2025.3(已部署 300+) |
| Atlas 950 | A5 | 950DT | 8,192 | 160 | 2026 Q4 |
| Atlas 960 | A6 | 960 | 15,488 | 220 | 2027 Q4 |
五、客户视角:推理/训练的真实经济性
5.1 SIMT 对开发体验的改变
这是 950 对开发者最重要的变化。
910C 时代:纯 SIMD,CUDA 的 SIMT 编程模型不能直接映射。开发者要么用 AscendC 重写算子,要么等 CANN 官方库覆盖。
950 时代:SIMD + SIMT 双模。SIMT 模式支持线程级并行,CUDA 代码结构可以更直接映射。
| 迁移场景 | 910C(SIMD only) | 950(SIMD + SIMT) |
|---|---|---|
| 标准算子 | CANN 直接覆盖 | 同左 |
| 自定义融合算子 | 必须用 AscendC 重写 | SIMT 可移植 CUDA 代码结构 |
| FlashAttention 类优化 | 需专门适配 | CV 融合 + SIMT 降低适配难度 |
| Warp-level 操作 | 无法映射 | SIMT 支持线程级同步 |
CV 融合通路、NDDMA 指令、随路量化、128B Sector-Cache 这些硬件特性进一步降低了软件适配成本。但要注意:SIMT 不是 CUDA 兼容层,它降低的是"移植门槛"而非"运行成本"。
5.2 推理测算:PDC 分离架构的完整推导
本章给出完整的推理测算。核心修正:30/100/400 tok/s 是单会话输出速度(不是集群吞吐),P/D 比例由上下文长度 L、平均输出长度 O、prefix cache 命中率 h 共同决定。校准锚点:CloudMatrix384 论文 [arXiv:2506.12708] + DeepSeek V3/R1 生产数据。
5.2.1 模型参数(V4 技术报告确认)
| 参数 | 符号 | 值 | 推导/来源 |
|---|---|---|---|
| 总参数 | P_total | 1.6T | V4 技术报告 |
| 激活参数/token | P_active | 49B | V4 技术报告 |
| 路由专家数 | E | 384 | V4 技术报告 |
| 共享专家数 | E_s | 1 | V4 技术报告 |
| 激活专家/token | topK | 6 | V4 技术报告 |
| Transformer 层数 | L_layers | 61 | V4 技术报告 |
| Hidden dim | d | 7,168 | V4 技术报告 |
| 每路由专家参数 | P_e | 66M/层,4.03B 总计 | 3 × d × 3072 × L_layers |
| 稠密参数 | P_dense | 24.5B | P_total - E × P_e |
| KV Cache | kv_per_tok | 12.2 KB/token | CSA 4× + HCA 128× 加权 |
| 上下文长度 | L_max | 1M tokens | V4 技术报告 |
验证:384 × 4.03B + 24.5B = 1,568B ≈ 1.6T ✓;6 × 4.03B + 24.5B = 48.7B ≈ 49B ✓
每路由专家只有 66M 参数/层,稠密部分(注意力 + 共享专家)占每卡工作量的 99.7%。MoE 路由专家虽然多,但单个极小。
5.2.2 每.token 计算量:Attention 随上下文增长
推理中每个 token 的 FLOPs 不只是 2 × P_active——attention 计算量随上下文长度 L 增长:
F_decode(L) = 2 × P_active + 4 × d² × L / L_layers
≈ 0.098 + 0.202 × L_M TFLOP/output token
F_prefill(L) = 2 × P_active + 2 × d² × L / L_layers
≈ 0.098 + 0.101 × L_M TFLOP/input token
注:prefill 的 attention 从 0 到 L 累积,平均 attention 长度约为 decode 的一半,所以 attention 项取 decode 的一半。L_M = L/10⁶。
| 上下文 | F_decode (TFLOP/token) | F_prefill (TFLOP/token) | Attention 占比 |
|---|---|---|---|
| 4K | 0.099 | 0.098 | <1% |
| 32K | 0.105 | 0.101 | 5-7% |
| 128K | 0.124 | 0.111 | 18-21% |
| 256K | 0.150 | 0.124 | 31-35% |
| 1M | 0.300 | 0.199 | 51-67% |
1M 上下文时 attention 占 decode 计算量的 67%。这使得 prefill 的 FLOPs 随 L² 增长(prefill 处理整个序列),长上下文的 prefill 成本急剧上升。
5.2.3 硬件效率校准
η 不能用理论峰值。 从 DeepSeek V3/R1 生产系统校准:
DeepSeek 披露的 V3/R1 H800 系统:EP32 prefill + EP144 decode,24 小时平均 KV 长度 4989,平均输出速度 20-22 tok/s,单 8×H800 节点平均 decode 吞吐 ~14.8K output tok/s。
校准后的硬件参数:
| 参数 | B300 | 950DT | 说明 |
|---|---|---|---|
| 8卡节点 dense FP8 | 36 PFLOPS | 8 PFLOPS | B300: DGX B300 官方 FP8 72 PFLOPS sparse → dense 约一半 = 36;950DT: ~1 PFLOP × 8 |
| η_prefill | 0.45 | 0.45 | 生产系统校准 |
| η_decode | 0.14 | 0.12 | decode 效率更低(batch 调度、MoE 路由开销、通信) |
| HBM 容量 | 288 GB | 144 GB (可用 ~130GB) | |
| HBM 带宽 | 8 TB/s | 4 TB/s | |
| $/GPU-hour | $5.00 | $2.00 | 规划假设,非市场报价 |
注:950DT $2/NPU-hour 是规划值。实际成本取决于华为内部折旧/电力/运维。如能压到 $1/NPU-hour,长上下文竞争力显著提升。
5.2.4 单节点吞吐
8 卡节点的有效吞吐:
S_P(L) = 8 × η_P × C_FP8 × 1000 / F_prefill(L) (K input tok/s)
S_D(L) = 8 × η_D × C_FP8 × 1000 / F_decode(L) (K output tok/s)
| 上下文 | B300 P (K tok/s) | B300 D (K tok/s) | 950DT P (K tok/s) | 950DT D (K tok/s) |
|---|---|---|---|---|
| 4K | 164.6 | 51.0 | 36.6 | 9.7 |
| 32K | 159.9 | 48.2 | 35.5 | 9.2 |
| 128K | 145.6 | 40.5 | 32.4 | 7.7 |
| 256K | 130.1 | 33.4 | 28.9 | 6.4 |
| 1M | 79.4 | 16.3 | 17.7 | 3.1 |
B300 的 prefill 吞吐是 950DT 的 ~4.5×,decode 吞吐约 ~5.2×。1M 时吞吐普遍下降——attention 计算量暴涨。
5.2.5 P/D 配比:单会话速度下的正确推导
问题:单会话输出速度为 r(tok/s),同时 C 个活跃会话,平均输出 O 个 token,上下文长度 L,prefix cache 命中率 h。
D 端总吞吐 = C × r ← 每个会话每秒生成 r 个 token
P 端总吞吐 = C × r × L/O × (1-h) ← 每完成一个会话需处理 L 个 input token
P/D 节点比:
N_P / N_D = [C×r×L(1-h)/O] / S_P(L) ÷ [C×r] / S_D(L)
= (L/O) × (1-h) × S_D(L) / S_P(L)
关键洞察:r(单会话速度)同时放大 P 和 D 的需求,但不改变 P/D 比例。真正决定 P/D 比的是:
- L/O:上下文越长、输出越短 → P 端越重
- h:cache 命中率越高 → P 端越轻
- S_D/S_P:decode 相对 prefill 的吞吐比
P/D 比例表(O=512, h=0):
| 上下文 | B300 P:D | 950DT P:D | 说明 |
|---|---|---|---|
| 4K | 2.3 : 1 | 2.1 : 1 | P 和 D 接近 |
| 32K | 17 : 1 | 16 : 1 | P 开始膨胀 |
| 128K | 65 : 1 | 57 : 1 | P 远超 D |
| 256K | 119 : 1 | 105 : 1 | |
| 1M | 382 : 1 | 327 : 1 | P 完全主导 |
没有 cache 的 1M 服务:每生成 512 个 output token 要处理 100 万个 input token——P 端需要 359 个节点来喂 1 个 D 节点。这不是 950DT 的问题,是所有 1M 服务的共同挑战。
有 prefix cache(h=0.56)时:
| 上下文 | B300 P:D | 950DT P:D |
|---|---|---|
| 4K | 1.0 : 1 | 0.9 : 1 |
| 32K | 8.3 : 1 | 7.1 : 1 |
| 128K | 31 : 1 | 27 : 1 |
| 256K | 57 : 1 | 50 : 1 |
| 1M | 177 : 1 | 152 : 1 |
Cache 使 P:D 降了一半,但 1M 仍然是 158:1。
平均输出长度对 P/D 的影响(h=0.56):
| O | 1M P:D (950DT) | 说明 |
|---|---|---|
| 512 | 158 : 1 | 短输出,P 爆炸 |
| 2048 | 40 : 1 | 中等输出,P 仍重 |
| 4096 | 20 : 1 | 长输出,P 可控 |
结论:1M 服务必须在 cache 命中率高(>80%)+ 输出较长(>2048 token)的条件下才经济。短输出 + 长上下文 + 冷 cache 是最差的组合。
5.2.6 KV Cache 容量
KV/sequence ≈ 5.3 × L_M GB
| 上下文 | KV/sequence | 950DT 并发 (130GB) | B300 并发 (260GB) |
|---|---|---|---|
| 4K | 0.021 GB | 6,190 | 12,381 |
| 32K | 0.170 GB | 765 | 1,529 |
| 128K | 0.678 GB | 192 | 383 |
| 256K | 1.357 GB | 96 | 192 |
| 1M | 5.300 GB | 25 | 49 |
注:这是 compressed CSA/HCA KV。如全量缓存 SWA(滑动窗口),体积约 8× 放大,并发容量相应降低。
C 层(Cache)的传输带宽需求:
B_C = (C × r / O) × KV(L)
| 场景 | C=100, r=100, O=512, L=1M | C 层 KV 流量 |
|---|---|---|
| 压缩 KV | 5.3 GB/seq | 103 GB/s |
| 全量 SWA | ~42 GB/seq | ~824 GB/s |
1M 场景下 C 层带宽压力巨大。这是为什么 V4 技术报告区分了 full/periodic/zero SWA caching 策略。
5.2.7 TTFT:冷 prefill 延迟
单 8 卡 P 节点,冷 prefill,无排队:
| 上下文 | B300 TTFT | 950DT TTFT |
|---|---|---|
| 4K | 22 ms | 112 ms |
| 32K | 184 ms | 922 ms |
| 128K | 810 ms | 4.05 s |
| 256K | 1.81 s | 9.06 s |
| 1M | 11.9 s | 59.4 s |
要达到冷前缀 TTFT ≤ 1s 需要多少 P 节点:
| 上下文 | B300 P 节点 | 950DT P 节点 |
|---|---|---|
| 4K | 1 | 1 |
| 32K | 1 | 1 |
| 128K | 1 | 5 |
| 256K | 2 | 10 |
| 1M | 12 | 60 |
950DT 不适合独立承担长上下文 prefill。华为官方把 950PR 定位为 prefill、950DT 定位为 decode/训练,正是这个原因。推荐 PDC 架构是 950PR-P + 950DT-D + Cache 层。
如果只能用 950DT 做 P,需要 supernode 级 context parallel 才能压下 128K+ 的 TTFT。
5.2.8 校准锚点:CloudMatrix384
华为论文实测数据是吞吐校准的独立验证:
| 维度 | CM384 实测 |
|---|---|
| 硬件 | 384×910C (310T, 1.2 TB/s BW, 64GB HBM) |
| 模型 | DeepSeek-R1 671B (256专家, topK=8, MLA) |
| Decode | 1,943 tok/s/NPU → 总计 621,760 tok/s |
| Prefill | 6,688 tok/s/NPU |
| 架构 | EP320, PDC 分离 |
CM384 的 decode 吞吐 1,943 tok/s/NPU 对应 η_decode ≈ 0.12(与我们的校准值一致),验证了效率假设的合理性。
5.2.9 PDC 部署三要素
① P/D 配比 = (L/O) × (1-h) × S_D/S_P
不再是简单的"吞吐匹配"。P/D 比例由业务参数(L, O, h)和硬件能力(S_D/S_P)共同决定。
② GPU 卡数分配
D 端节点数(60% 利用率留 p90 余量):
N_D = ⌈C × r / (0.6 × S_D(L))⌉
P 端节点数:
N_P = ⌈C × r × L × (1-h) / (O × S_P(L))⌉
③ 并行策略
| Prefill | Decode | |
|---|---|---|
| 主策略 | TP(计算瓶颈) | EP + TP(带宽瓶颈) |
| EP | 可用(大 batch 下 EP 减少 AllReduce) | 拆分路由专家 → 释放 KV 空间 |
| TP | 拆分算力 → 线性提速 | 拆分稠密权重 → 降低 TPOT |
| PP | 不用 | 不用 |
| 推荐 | B300: EP64/96; 950DT: EP64/128 | 30t: EP128-192; 100t: EP192+MTP; 400t: EP384+MTP |
EP 建议与 DeepSeek 生产实践:DeepSeek V3/R1 线上用 EP32 prefill + EP144 decode + 32 redundant experts。对 V4-Pro 384 专家,等比例放大建议 decode EP192-384 + 48 redundant experts。
5.3 完整配置表:单会话速度 + 并发
默认业务负载:C=100 活跃会话, O=512 output tokens, h=0.56, D 端 60% 利用率
百万 output token 成本:
$/M_out = 8(N_P + N_D) × c_GPU / (C × r × 3600/10⁶)
5.3.1 B300 容量下界($/GPU-hour = $5)
| ctx | 30 tok/s | 100 tok/s | 400 tok/s |
|---|---|---|---|
| 4K | P1/D1, 16 GPU, $7.4/M | P1/D1, 16 GPU, $2.2/M | P1/D2, 24 GPU, $0.8/M |
| 32K | P1/D1, 16 GPU, $7.4/M | P2/D1, 24 GPU, $3.3/M | P7/D2, 72 GPU, $2.5/M |
| 128K | P3/D1, 32 GPU, $14.8/M | P8/D1, 72 GPU, $10.0/M | P31/D2, 264 GPU, $9.2/M |
| 256K | P6/D1, 56 GPU, $25.9/M | P17/D1, 144 GPU, $20.0/M | P68/D2, 560 GPU, $19.4/M |
| 1M | P32/D1, 264 GPU, $122.2/M | P106/D1, 856 GPU, $118.9/M | P423/D4, 3416 GPU, $118.6/M |
B300 1M 特征:成本几乎不随速度档变化(30/100/400 的 $/M 差距 <3%),因为成本由 P 端主导。
5.3.2 B300 SLA-safe 生产配置
容量下界是数学最小值,生产中为满足 TPOT p90 < 50ms 需要 EP 最小粒度约束:
- P 层:最小 EP64(= 8 个 8卡节点 = 64 GPU)
- D 层 30 tok/s:EP128(= 16 节点)
- D 层 100 tok/s:EP192(= 24 节点)
- D 层 400 tok/s:EP384(= 48 节点)
| ctx | 30 tok/s | 100 tok/s | 400 tok/s |
|---|---|---|---|
| 4K | P8/D16, 192 GPU, $88.9/M | P8/D24, 256 GPU, $35.6/M | P8/D48, 448 GPU, $15.6/M |
| 32K | P8/D16, 192 GPU, $88.9/M | P8/D24, 256 GPU, $35.6/M | P8/D48, 448 GPU, $15.6/M |
| 128K | P8/D16, 192 GPU, $88.9/M | P8/D24, 256 GPU, $35.6/M | P32/D48, 640 GPU, $22.2/M |
| 256K | P8/D16, 192 GPU, $88.9/M | P24/D24, 384 GPU, $53.3/M | P72/D48, 960 GPU, $33.3/M |
| 1M | P32/D16, 384 GPU, $177.8/M | P112/D24, 1088 GPU, $151.1/M | P424/D48, 3776 GPU, $131.1/M |
注:SLA-safe 配置向上取整到 EP 粒度。短上下文时 P 端有较多余量(EP64 最小约束),但确保 TPOT p90。长上下文时 P 端主导成本,与容量下界接近。
5.3.3 950DT 容量下界($/NPU-hour = $2)
| ctx | 30 tok/s | 100 tok/s | 400 tok/s |
|---|---|---|---|
| 4K | P1/D1, 16 NPU, $3.0/M | P1/D2, 24 NPU, $1.3/M | P4/D7, 88 NPU, $1.2/M |
| 32K | P3/D1, 32 NPU, $5.9/M | P8/D2, 80 NPU, $4.4/M | P31/D8, 312 NPU, $4.3/M |
| 128K | P11/D1, 96 NPU, $17.8/M | P34/D3, 296 NPU, $16.4/M | P136/D9, 1160 NPU, $16.1/M |
| 256K | P23/D1, 192 NPU, $35.6/M | P76/D3, 632 NPU, $35.1/M | P303/D11, 2512 NPU, $34.9/M |
| 1M | P143/D2, 1160 NPU, $214.8/M | P476/D6, 3856 NPU, $214.2/M | P1901/D21, 15376 NPU, $213.6/M |
5.3.4 950DT SLA-safe 生产配置(Supernode)
- P 层:最小 EP128(= 16 个 8-NPU 节点)
- D 层 30 tok/s:EP192(= 24 节点)
- D 层 100/400 tok/s:EP384(= 48 节点)
| ctx | 30 tok/s | 100 tok/s | 400 tok/s |
|---|---|---|---|
| 4K | P16/D24, 320 NPU, $59.3/M | P16/D48, 512 NPU, $28.4/M | P16/D48, 512 NPU, $7.1/M |
| 32K | P16/D24, 320 NPU, $59.3/M | P16/D48, 512 NPU, $28.4/M | P32/D48, 640 NPU, $8.9/M |
| 128K | P16/D24, 320 NPU, $59.3/M | P32/D48, 640 NPU, $23.7/M | P128/D48, 1408 NPU, $15.6/M |
| 256K | P32/D24, 448 NPU, $82.9/M | P96/D48, 1152 NPU, $42.5/M | P384/D48, 3456 NPU, $30.2/M |
| 1M | P160/D24, 1472 NPU, $272.7/M | P480/D48, 4224 NPU, $234.7/M | P1920/D48, 15744 NPU, $173.7/M |
注:950DT SLA-safe 配置需要更大 EP 度。Supernode 的价值在此体现:EP384 D unit 内 UB 全互联,延迟可控。
5.3.5 成本对比
容量下界 vs SLA-safe 的区别:容量下界是数学最小值,适用于 sizing 理解;SLA-safe 是生产配置,向上取整到 EP 粒度确保 TPOT。
高利用率吞吐匹配下(架构师校准),B300 在所有上下文都是成本最低:
| ctx | 速度 | B300 $/M | 950DT $/M | B300 优胜 |
|---|---|---|---|---|
| 4K | 100 | $35.6 | $28.4 | 950DT 便宜 20% |
| 32K | 100 | $35.6 | $28.4 | 950DT 便宜 20% |
| 128K | 100 | $35.6 | $23.7 | 950DT 便宜 33% |
| 256K | 100 | $53.3 | $42.5 | 950DT 便宜 20% |
| 1M | 100 | $151.1 | $234.7 | B300 便宜 36% |
注:SLA-safe 配置下,4K-256K 因 EP 粒度约束固定了 P/D 节点数,950DT NPU-hour 单价优势 ($2 vs $5) 使其短上下文更便宜。但 1M 时 P 端需求暴增,B300 算力优势摊薄固定成本。
950DT 在 1M 打平 B300 的条件:
$5 × 1088/4224 ≈ $1.3/NPU-hour (SLA-safe)
$5 × 856/3856 ≈ $1.1/NPU-hour (容量下界)
950DT 全栈成本需压到 $1.1-1.3/NPU-hour 以下,1M 推理才能与 B300 竞争。
5.3.4 输出长度对成本的影响
以 1M 上下文、100 tok/s、B300 为例:
| O | h | P:D | P 节点 | 总 GPU | $/M |
|---|---|---|---|---|---|
| 512 | 0.56 | 185:1 | 103 | 832 | $115.6 |
| 2048 | 0.56 | 46:1 | 26 | 216 | $30.0 |
| 4096 | 0.56 | 23:1 | 13 | 120 | $16.7 |
| 512 | 0.90 | 37:1 | 21 | 176 | $24.4 |
| 4096 | 0.90 | 5:1 | 3 | 32 | $4.4 |
长输出 + 高 cache 命中 = 成本降 26 倍($115 → $4.4 /M)。1M 服务的经济性高度依赖业务场景。
5.4 华为推荐 PDC 架构
5.4.1 为什么不能用纯 950DT 做 P+D
950DT 的 prefill 效率是 B300 的 1/5(FP8 算力 1 PFLOPS vs 5 PFLOPS)。1M 冷前缀 TTFT = 59.4 秒(vs B300 11.9 秒)。要压到 ≤1 秒需要 60 个 8-NPU 节点做 P。
华为自己也把 950PR 定位为 prefill,950DT 定位为 decode/训练。正确架构是异构 PDC。
5.4.2 推荐:950PR-P + 950DT-D + Cache
P 层:950PR supernode slice → 长上下文 prefill, chunked prefill, context parallel
D 层:950DT EP384 → decode, large EP, MTP/speculative decoding
C 层:Kunpeng + NVMe + NPU memory pool + UB/RDMA → compressed KV, prefix cache, routing affinity
CloudMatrix384 已经验证了 prefill/decode/cache 解耦 + UB all-to-all + 超大 EP 的思路。对 V4-Pro 384 路由专家,EP384 是 decode 的天然切分点:理想情况下一颗 NPU 管一个路由专家。
5.4.3 Supernode 下的 P/D 比例限制
即使有 supernode,P/D 的数学关系不会消失。以 950DT, O=512, h=0.56:
| 上下文 | P:D | D 端 1 个 EP384 unit 需要的 P 节点 |
|---|---|---|
| 32K | 7.1 : 1 | 7 个 8-NPU 节点 |
| 128K | 27 : 1 | 27 个 8-NPU 节点 |
| 256K | 50 : 1 | 50 个 8-NPU 节点 |
| 1M | 152 : 1 | 7,296 个 8-NPU 节点(不现实) |
1M、短输出、半冷前缀下,把 EP384 D unit 完全喂满需要 ~7600 个 P 节点——不可能。
正确做法:
- 1M 场景不追求 D 满载,优先 TTFT 和 SLA
- 提高 cache 命中率(h=0.90 时 P:D 降到 ~18:1)
- 将长输出业务与 1M 上下文绑定(O=4096 时 P:D 降到 ~20:1)
- P 层用 950PR(prefill 专用),不用 950DT
- C 层做强 cache affinity,避免重复 prefill
如果 O=4096 且 h=0.90:950DT 1M 的 P:D ≈ 4.5 : 1——这才是 supernode 上健康的 1M 服务状态。
5.5 训练场景
950PR 定位推理,训练需等 2026 Q4 的 950DT。
训练内存需求(V4-Pro 1.6T FP8):
- 权重 + 梯度 + 优化器 ≈ 4.8 TB
- 最低 37 张卡装下
- 训练通信更密集(All-to-All + AllReduce 交替),需更多并行度
- 512-1024 卡(8-16 柜)是训练甜点:UB 全光互联 + CCU 硬化 + 足够的 pipeline 并行度
V4 技术报告确认 V4-Pro 用 32T+ tokens 预训练,Muon 优化器。华为内部已用 6000+ 卡 950DT 训练盘古 Ultra MoE 718B,但未经外部客户验证。
5.6 客户分层
| 客户类型 | 是否适合 950 | 原因 |
|---|---|---|
| 供应链安全需求(政府/国企) | ✅ 适合 | 不受出口管制,数据不出境 |
| 短上下文推理(≤4K) | ✅ 适合 | NPU-hour 成本低,SLA-safe 下 EP 粒度使 950DT 有优势 |
| 长上下文 MoE 推理(128K+) | ⚠️ 需 950PR-P | 纯 950DT 做 P 成本过高,需异构 PDC |
| 大规模 MoE 训练 | ⚠️ 等 950DT | 512+ 卡区间优势最大,但需等 2026 Q4 |
| 成本敏感推理服务 | ⚠️ 有条件 | 仅限短上下文 + 长 output 场景 |
| 单卡延迟敏感推理 | ❌ 不适合 | FP8 算力只有 B300 的 23% |
| 小规模部署(<64 卡) | ❌ 不适合 | 系统级优势需要 64+ 卡才能发挥 |
| 1M 上下文推理(短输出) | ❌ 不经济 | P:D >158:1,P 端成本爆炸 |
六、薄弱点:对手会怎么打
6.1 单卡算力差距是结构性现实
FP8 算力只有 B300 的 23%。这不是"优化一下就能追上"的差距,是制程和架构路线决定的。
Prefill 端的差距最为致命。 950DT 单 8-NPU 节点 prefill 吞吐只有 B300 的 1/4.5。128K 上下文冷 prefill 需 4 秒(vs B300 0.9 秒),1M 需 55 秒(vs B300 12 秒)。在 P/D 比例公式中,S_P 越低 → N_P 越大 → 总成本越高。SLA-safe 配置下,1M 场景 B300 成本比 950DT 低 36%。
NVIDIA 会怎么说:"你的 decode 吞吐和我相当(都是 HBM 带宽瓶颈),但 prefill 慢 4.5 倍。实际服务中 prefill 开销不能忽略——尤其 128K+ 上下文,你的 P 端节点数是我的 5 倍。用户等 55 秒 prefill 1M token,体验远不如 B300 的 12 秒。软件生态、运维成熟度、社区支持都是额外成本。"
6.2 HiF8:设计精巧但生态孤立
- 没有框架原生支持(PyTorch/TensorFlow/vLLM 都不认识)
- 没有量化工具链
- 训练精度未经第三方验证
- 客户会选择"已知可用"的 FP8/MXFP8
NVIDIA 会怎么说:"FP8 是行业标准。HiF8 是华为自己的格式,你想锁死在他的生态里吗?"
6.3 软件生态的真实差距
这不是"差多少"的问题,是"差多少年"的问题。
| 维度 | CUDA | CANN | 差距本质 |
|---|---|---|---|
| 自定义算子 | 20 年积累 | SIMT 刚起步 | 大 |
| 算子库覆盖 | 全面 | 主流已覆盖 | 中 |
| 性能调优 | Nsight 完整 | msprof 完善中 | 中 |
| 社区 | 全球百万级 | 中国为主 | 中 |
| 调试 | cuda-gdb 成熟 | 改善中 | 中 |
CUDA 20 年积累的隐性知识(StackOverflow 上的每一个回答、每一个踩坑经验)不可能在 2-3 年内追平。
6.4 未验证的不确定性
| 风险项 | 状态 | 影响 |
|---|---|---|
| HiF8 实际训练精度 | 未验证 | 如验证失败,自研精度格式价值归零 |
| 自研 HBM 量产能力 | 未验证 | 决定交付节奏 |
| 超节点 8192 卡线性加速比 | 仅华为内部数据 | 外部客户验证前不能确信 |
| 950DT 上市时间 | 2026 Q4 | NVIDIA 下一代可能也快了 |
| 950DT 96GB 低配版定位 | 可能导致客户混乱 | 训练卡显存比推理卡少 |
| 950DT $/NPU-hour 能否压到 $1 | 未验证 | 决定 32K+ 场景能否与 B300 竞争 |
七、迁移地图:哪些要重写
7.1 三层迁移难度
第一层:直接跑(0-1 天)
- API 调用 → 无感知
- PyTorch 标准推理 →
device="npu"+ torch_npu - vLLM/HuggingFace 标准 → vLLM-Ascend
第二层:需要适配(1-2 周)
| 场景 | 950 的缓解 |
|---|---|
| 自定义融合算子 | SIMT 降低移植门槛 |
| FlashAttention 类优化 | CV 融合通路加速 |
| MoE All-to-All | CCU 硬化 + HCCL |
| 数据排布转换 | NDDMA 硬件完成 |
| KV Cache 量化 | 随路量化硬件完成 |
第三层:需要重写(2-4 周+)
| 场景 | 难度 |
|---|---|
| Warp-level primitives | 高 — SIMT 不完全覆盖 |
| 三级异构注意力(V4) | 中高 — 需要 CANN 专门适配 |
| 自定义通信 kernel | 高 — HCCL vs NCCL 差异 |
| 训练框架全量迁移 | 很高(1-3 月) |
7.2 V4-Pro 迁移走一遍真实路径
-
KV Cache 管理:三级压缩需要统一内存管理。950 的 128B Sector-Cache 带宽效率提升 4×,但需重写 Cache 管理逻辑。→ 1-2 周
-
注意力算子重写:Compressor → RMSNorm → RoPE → Cache Insert 融合链,需 CV 融合 + SIMT 重写。→ 1-2 周
-
MoE All-to-All:HCCL 替代 NCCL,CCU 硬化加速。V4 动态路由需额外调优。→ 1 周
-
FP4 兼容:V4 使用 FP4 量化感知训练(QAT)+ FP4 索引器。950 支持 MXFP4(OCP 标准格式),如 V4 用 NVIDIA FP4 E2M1 则需格式转换。→ 1-3 天
-
部署规模:V4-Pro 384 专家 → EP=384 是甜点(384 张 950DT,每卡 1 专家)。8×B300 的 EP=8 只有 6.8K tok/s,远低于 384×950DT 的 74.6K tok/s。→ 部署规模完全不同
总迁移时间:4-6 周(不含训练)
7.3 迁移总结
┌─────────────────────────────────────────────────────┐
│ CUDA → 昇腾 950 迁移地图 │
├───────────────┬─────────────┬───────────────────────┤
│ 直接跑 │ 需要适配 │ 需要重写 │
│ (0-1 天) │ (1-2 周) │ (2-4 周+) │
├───────────────┼─────────────┼───────────────────────┤
│ · API 调用 │ · 融合算子 │ · Warp-level 操作 │
│ · PyTorch │ · FlashAttn │ · 三级异构注意力 │
│ · vLLM 标准 │ · MoE A2A │ · 自定义通信 kernel │
│ │ · 数据排布 │ · 训练框架全量迁移 │
│ │ · KV Cache │ · FP4 格式转换(待确认) │
└───────────────┴─────────────┴───────────────────────┘
关键判断:标准推理迁移门槛已很低。MoE 推理需 4-6 周适配。训练迁移需 1-3 个月,建议等 950DT 上市后由华为 FAE 配合。
八、判断汇总
8.1 确定性最高的判断
-
Chiplet UMA 是制裁条件下的最优解,但有天花板。 如果制程限制长期存在,封装路线的性能上限最终会被单 Die 方案拉开。
-
互联反超是真实的系统性优势。 2016 GB/s + UB On Chip Switch + CCU + 8192 卡超节点,是一整套系统级通信设计。MoE 场景下价值最大。
-
SIMT 是降低 CUDA 迁移门槛的关键一步。 但 SIMT 不是 CUDA 兼容层,降低的是“移植门槛”而非“运行成本”。
-
950DT 在 SLA-safe 配置下,4K-256K 因 EP 粒度固定有成本优势(NPU-hour 单价低,$2 vs $5)。但 1M 时 P 端需求暴增,B300 算力优势使其成本反而低 36%。高利用率吞吐匹配下 B300 全面更优。
-
长上下文 (128K+) P 端成本是核心瓶颈——这对所有硬件都成立。 1M 上下文 P:D >152:1(h=0.56),成本由 P 端主导。Cache 命中率 + 输出长度是长上下文服务经济性的关键变量,不是 decode 速度。
-
推荐华为 PDC 架构为 950PR-P + 950DT-D + Cache 层。 纯 950DT 做 P+D 在 32K+ 场景不经济,因为 950DT prefill 效率只有 B300 的 1/5。
8.2 最大的不确定性
-
950DT $/NPU-hour。 决定 32K+ 场景能否与 B300 竞争的临界值是 $1/NPU-hour。高于此值,1M 推理成本约为 B300 的 2 倍。
-
HiF8 实际训练精度。 设计优于 FP8 E4M3,但无第三方验证。
-
自研 HBM 量产能力。 HiBL/HiZQ 良率直接决定交付。
-
超节点 8192 卡实际训练效率。 华为内部数据好看,但外部客户的模型、数据、调度策略都不同。
-
950DT 上市时间与 NPU-hour 成本。 2026 Q4 上市,实际 $/NPU-hour 是否能压到 $1 以下,决定长上下文场景的竞争力。
8.3 观察时间线
| 时间 | 关键事件 | 验证什么 |
|---|---|---|
| 2026 Q1 | 950PR 量产 + Atlas 350 上市 | ✅ 已完成 |
| 2026 Q2-Q3 | 外部客户 950PR 推理部署 | 推理迁移真实成本 |
| 2026 Q4 | 950DT 量产 + Atlas 950 SuperPoD | 训练能力、HBM 产能、超节点效率 |
| 2027 H1 | 外部客户大规模训练案例 | HCCL 在 MoE 训练中的实际表现 |
| 2027 Q4 | Atlas 960 / Ascend 970 | 封装路线的代际进步速度 |
附录 A:完整规格表
| 规格项 | 昇腾 950PR | 昇腾 950DT |
|---|---|---|
| 芯片物理架构 | 2×AI Die + 2×IO Die + 8×Memory 模块 | 2×AI Die + 2×IO Die + 4×Memory 模块 |
| AI 子系统 | 32/28 | 36/32/28 |
| Cube Core 数量 | 32/28 | 36/32/28 |
| Vector Core 数量 | 64/56 | 72/64/56 |
| Cube+Vector 总算力 | ||
| MXFP4 (TFLOPS) | 1784 / 1561 | 2007 / 1784 / 1561 |
| HiF8/MXFP8/FP8 (TFLOPS) | 919 / 804 | 1034 / 919 / 804 |
| INT8 (TOPS) | 919 / 804 | 1034 / 919 / 804 |
| BF16/FP16 (TFLOPS) | 486 / 425 | 547 / 486 / 425 |
| TF32 (TFLOPS) | 243 / 212 | 273 / 243 / 212 |
| Cube 独立算力 | ||
| MXFP4 (TFLOPS) | 1730 / 1513 | 1946 / 1730 / 1513 |
| HiF8/MXFP8/FP8 (TFLOPS) | 865 / 756 | 973 / 865 / 756 |
| BF16/FP16 (TFLOPS) | 432 / 378 | 486 / 432 / 378 |
| Vector 独立算力 | ||
| FP16/BF16 (TFLOPS) | 54 / 47 | 60 / 54 / 47 |
| FP32 (TFLOPS) | 27 / 23 | 30 / 27 / 23 |
| INT8 (TOPS) | 54 / 47 | 60 / 54 / 47 |
| Memory | ||
| 容量 (GB) | 128 / 112 | 144 / 96 |
| 带宽 (TB/s) | 1.6 / 1.4 | 4 |
| AI CPU | Linx816 8C16T / 6C12T / 4C8T | Linx816 8C16T / 6C12T |
| DVPP | VPC 4/2 Core; JPEGD 8 Core; JPEGE 4/2 Core | VPC 4/2 Core; JPEGD 8 Core; JPEGE 4/2 Core |
| L2 Cache | 128 / 112 MB | 128 MB |
| IO 规格 | ||
| UB 带宽 | 18 Port × 112Gbps,2016 GB/s 双向 | 同 950PR |
| UBoE | 2×400Gbps | 同 950PR |
| PCIe | PCIe 5.0 x16,128GB/s 双向 | 同 950PR |
数据来源:华为《昇腾 950 NPU 架构白皮书》表 3-1
附录 B:芯片架构关键图
B.1 芯片物理架构
B.2 AI Core 架构
B.3 Cube Core
B.4 Vector Core
B.5 HiF8 数值精度
B.6 CV 融合
B.7 NDDMA 与同步
B.8 内存层次
附录 C:信息来源
主要来源:
- 华为《昇腾 950 NPU 架构白皮书》(2026) — 全部精确规格的第一来源
- 华为 HC 2025 徐直军 / 杨超斌主题演讲
- 华为 CloudMatrix384 论文 [arXiv:2506.12708](2025-06)— CloudMatrix384 超节点 + DeepSeek-R1 实测性能数据
补充来源:
- 昇腾 CANN 官方公众号《CANN NEXT 系列干货:面向 Ascend 950 的架构详解》(2026)
- 共熵产业与标准创新服务中心 (comentropy.org) 超节点算力革命系列
- 华源证券研报《关注 26 年起国产超节点液冷新增量》(2026-04)
- 华金证券研报 2026-04-13
- 华西证券研报 2025-09-22
- 观察者网 2026-02-10 采访张爱军
- vLLM 官方博客 DeepSeek V4 架构文档
本文分析基于华为《昇腾 950 NPU 架构白皮书》及公开信息。白皮书架构参数为官方确认数据。性能 TPS 数据来自 HC 2025 演讲,未经第三方独立验证。灵衢 2.0 大规模部署(8192 卡)的实际可靠性尚需 2026 Q4 上市后验证。成本估算基于公开定价信息和行业经验值,实际成本因部署规模、利用率、运维模式等因素会有显著差异。