2026 年 6 月的 HPE Discover 大会上,CEO Antonio Neri 把一句话说了三遍:
「每一个字节、每一个 Token、每一个决策都经由网络传输。」
这不是一个网络设备厂商的自我推销——HPE 刚花了 140 亿美元收购 Juniper Networks,它需要向业界证明这笔钱花在了对的地方。
Neri 的判断更直白:「网络层将成为下一个重大机遇所在。」理由是:GPU 主导了算力讨论,但网络层的发展速度远没跟上计算能力的提升。万卡训练集群里 30-50% 的耗时不在计算,在等数据。
HPE 的回应是一套完整的网络产品线更新——从机架内到数据中心互联到边缘推理,加上一个把四个运维平台整合到一起的 AI 引擎。这篇文章拆解这个网络赌局的技术细节和竞争格局。

Neri 的延迟算术
在主题演讲中,Neri 用了一段直白的数学解释网络为什么重要:
「在数百万块 GPU 上,将一个微小的网络延迟乘以数周的训练时间,可能意味着训练一个新模型需要 90 天而非 30 天。这是追赶突破与创造突破之间的差距。」
这段话的含义:AI 训练不是「跑得快」的问题,是「不能停下来等」的问题。GPU 的 FLOPS 再高,如果数据到不了,计算单元就在空转。训练集群的有效利用率(MFU)很大程度取决于网络的无拥塞传输率——而不是单卡峰值算力。
这就是为什么 HPE 把网络拔到「控制平面」的位置。在 AI 工厂的叙事里,计算是产线,网络是调度系统——调度系统的效率决定产线的利用率。
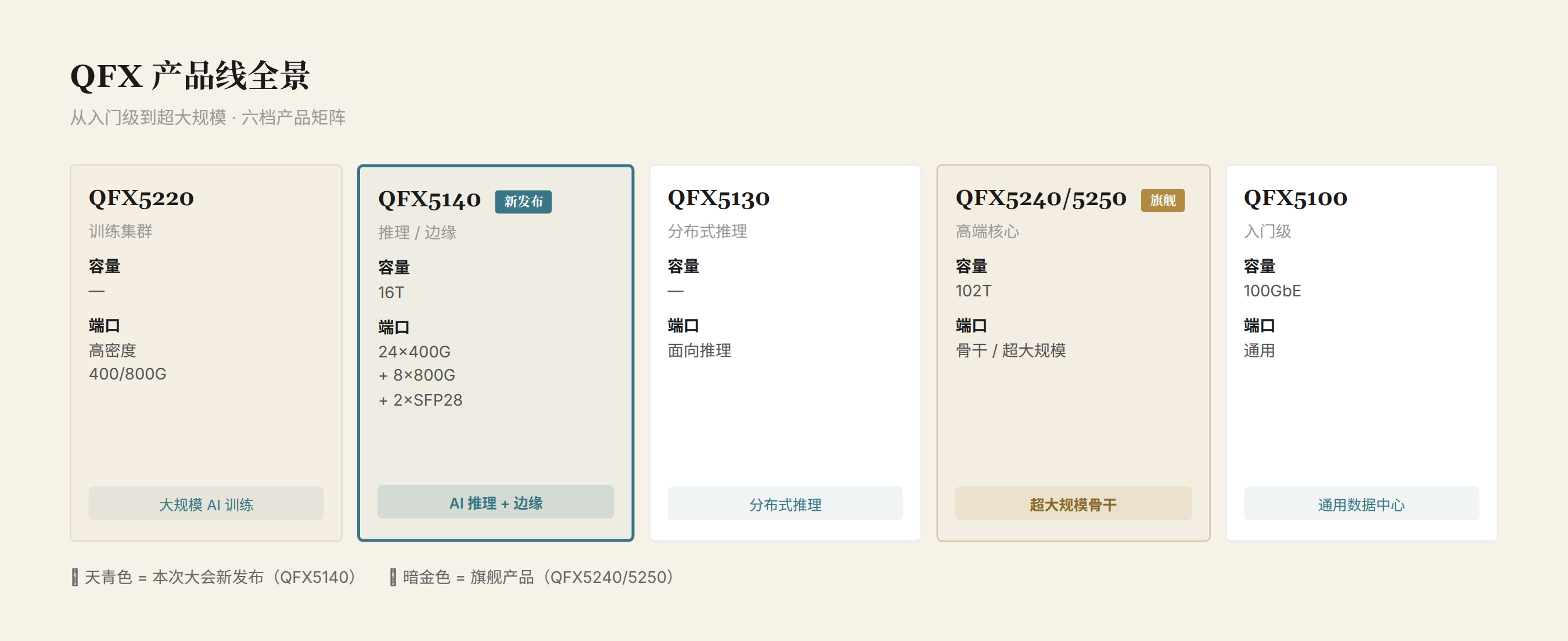
QFX 产品线:六档覆盖
HPE 在 Discover 2026 上展示了完整的 Juniper QFX 数据中心交换机产品线:
| 型号 | 定位 | 容量 | 端口规格 | 关键技术 |
|---|---|---|---|---|
| QFX5220 | AI 训练集群 | 未公开 | 面向大规模组网 | 高密度 400G/800G |
| QFX5140 | AI 推理 / 边缘 | 16T | 24×400G QSFP112 + 8×800G OSFP800 + 2×SFP28 | RoCEv2, PFC, ECN, 动态负载均衡 |
| QFX5130 | 分布式推理 | 未公开 | 面向推理部署 | 中等密度 |
| QFX5240/5250 | 高端核心 | 102T | 骨干 / 超大规模 | 顶级交换容量 |
| QFX5100 | 入门级 | 100GbE | 通用数据中心 | 成熟产品 |
QFX5140:填补中端空白
QFX5140 是本次大会发布的最具体的新产品。1RU 固定配置,16T 交换容量。
端口配置灵活:24 个 400G QSFP112 可以拆分成更低速端口,8 个 800G OSFP800 面向下一代高速互联。支持 RoCEv2(基于融合以太网的 RDMA),这意味着 GPU 之间的数据传输可以绕过操作系统内核,直接从一块 GPU 的显存传到另一块——延迟大幅降低。
HPE CTO Fidelma Russo 特别强调了三个跟 GPU 通信效率直接相关的特性:
- 优先流控(PFC):高优先级流量(如 GPU 训练数据)不会被低优先级流量阻塞
- 显式拥塞通知(ECN):交换机在拥塞发生前通知发送端降速,避免丢包重传
- 动态负载均衡:不像传统 ECMP 那样静态哈希,而是根据链路实时负载动态分配流量路径——显著减少「尾延迟」(少数慢链路拖垮整体训练性能的现象)
QFX5140 填补的是 QFX 产品线中最大的空白:高端的 QFX5240/5250(102T)对多数 AI 推理场景过于昂贵,入门的 QFX5100(100GbE)的带宽又不够。16T 的 QFX5140 正好卡在 AI 推理和边缘 AI 工作负载的甜点区。
QFX5220:训练集群的主力
QFX5220 是面向大规模 AI 训练集群的型号。HPE 在 Discover 上没有公布详细规格,但从产品定位推断,它应该是 QFX5240(102T)的精简版——足够组建千卡级训练集群的脊层(Spine)和叶层(Leaf),但不需要 102T 那种超大规模场景的顶级吞吐。
训练集群的网络设计有特殊要求:GPU 之间的 AllReduce 操作(梯度同步)会产生大量的东西向流量,峰值带宽高、持续时间短、对延迟敏感。如果网络不能及时处理,GPU 就在空等——这就是 Neri 说的「30-50% 耗时在等数据」的来源。
端到端网络架构:从机架到边缘
QFX 不是全部。HPE 在 Discover 2026 上展示了一个四层端到端 AI 网络架构:
| 层级 | 设备 | 职责 |
|---|---|---|
| 机架内 | QFX5220/5140 | GPU 之间的东西向互联(训练 + 推理) |
| 集群间 | QFX5240/5250 | 多个 GPU 集群的横向扩展 |
| 数据中心互联 | PTX 12000 | 跨数据中心高速路由,支持 800G |
| 边缘推理 | MX 301 | 基于 Juniper 第六代 Trio 芯片,把网络能力延伸到推理边缘 |
PTX 12000 是核心路由器,负责跨数据中心的大流量互联——典型场景是一个训练集群在 A 数据中心,存储在 B 数据中心,推理服务在 C 数据中心。PTX 12000 在中间做高速转发。
MX 301 是边缘路由器,基于 Juniper 自研的第六代 Trio 芯片。它的设计目标是把 AI 推理的路由能力下沉到边缘节点——分支机构、工厂、门店——让推理结果可以快速回传到核心。
加上 SRX 4700 量子安全防火墙(单机架单元 1.44 Tbps 吞吐,具备抗量子计算攻击的加密能力),HPE 构建了一个从 GPU 机架到企业边缘的完整网络产品栈。
SRX 4700:量子安全的提前布局
SRX 4700 在 Discover 2026 上的亮相值得多看一眼。「量子安全」听起来像未来概念——量子计算机目前还无法破解 RSA/ECC 加密。但 HPE 的逻辑是:攻击者可以「现在截获、将来破解」(store-now-decrypt-later)。对于需要长期保密的数据(医疗、金融、国防),量子安全加密现在就需要部署。
SRX 4700 的 1.44 Tbps 吞吐意味着它可以在不成为网络瓶颈的前提下执行后量子加密算法——传统防火墙跑加密算法会严重降速。
GreenLake Intelligence:四个运维入口整合到一个引擎
QFX 和 PTX 是硬件。HPE 真正想讲的故事是软件:把网络运维交给 AI。
四个入口
HPE 目前有四个网络运维平台,来自三次不同收购:
| 平台 | 来源 | 定位 |
|---|---|---|
| Marvis AI | Juniper(Mist 2019 年收购) | 虚拟网络助手,自然语言交互 |
| Mist AI | Juniper(2019 年收购 Mist Systems) | AI 驱动的无线/有线运维 |
| Aruba Central | HPE(2015 年收购 Aruba) | 园区网络管理 |
| Apstra | Juniper(2021 年收购 Apstra) | 数据中心网络自动化 |
四个平台各自成熟、各自有客户基础。但它们来自三家不同的公司(Juniper、Mist、Aruba),技术栈不同、数据模型不同、API 不同。
GreenLake Intelligence 的整合目标
HPE 想做的事:把这四个平台的遥测数据汇聚到一个 AI 引擎(GreenLake Intelligence),由 AI 引擎统一分析、建议、执行。运维人员面对的不是四个控制台,而是一个 AI 助手(Marvis)。
理想场景:运维人员在 Marvis 里输入「为什么推理集群的延迟高了 30%」,Marvis 自动分析网络拓扑、流量模式、设备状态、应用日志,定位问题(比如某个叶交换机的上行链路拥塞),给出修复建议,甚至自动执行(调整流量路径、增加带宽预留)。
目前做到哪一步?
从 Discover 2026 的公开信息看,HPE 目前的整合进度是:
已完成:Aruba CX 交换机接入 Mist 平台;Marvis Actions 功能引入 Aruba Central。这是 UI 层面的对接——一个界面可以查看两个平台的数据。
进行中:四个平台的数据层统一。遥测数据格式标准化、告警逻辑统一、自动化工作流跨平台执行。
未完成:真正的统一 AI 引擎——一个模型理解所有四个平台的数据并做决策。这需要数据层的深度整合,工程周期至少 2-3 年。
CTO Fidelma Russo 在演讲中说「GreenLake Intelligence 将生成式 AI 嵌入基础设施运营」,但演示的功能主要还是「问题识别 + 操作建议」——自动执行的案例有限。这说明目前阶段是「AI 辅助」而非「AI 自主」。
自动驾驶网络:HPE vs Nile
HPE 的「自动驾驶网络」叙事跟一家公司直接竞争:Nile。
Nile 是一家专注企业级 NaaS(Network as a Service)的公司,它的模式是从零构建一个完全自动化的网络——硬件、软件、运维全包,客户按月付费,不操心任何配置。
两者的关键差异:
| 维度 | HPE | Nile |
|---|---|---|
| 起步方式 | 在现有四个平台上做整合 | 从零设计一体化系统 |
| 硬件 | QFX/Aruba 全线产品(成熟) | 自有硬件(产品线窄) |
| AI 引擎 | GreenLake Intelligence(整合中) | 原生 AI 引擎(Day 1 设计) |
| 客户 | 现有 HPE/Aruba/Juniper 客户(存量巨大) | 新客户为主(增量有限) |
| 消费模式 | GreenLake 按需付费 | NaaS 订阅 |
| 劣势 | 整合四个平台的工程难度 | 产品线窄,大规模 AI 集群能力弱 |
Nile 的优势是「从零构建」——没有历史包袱,架构一致性更好。HPE 的优势是「存量客户 + 全线产品」——已经有大量企业用 Aruba 和 Juniper 的设备,GreenLake 的消费模式也成熟。
Nile 的劣势是规模:它做不了万卡 AI 训练集群的网络。那需要 QFX5240 级别的 102T 交换机,Nile 没有这种产品。
HPE 的劣势是整合难度:四个平台不是一个代码库,做到真正的统一 AI 引擎需要大量的工程投入,而且 Juniper 和 Aruba 的团队之前是竞争对手——组织协同本身就是一个挑战。
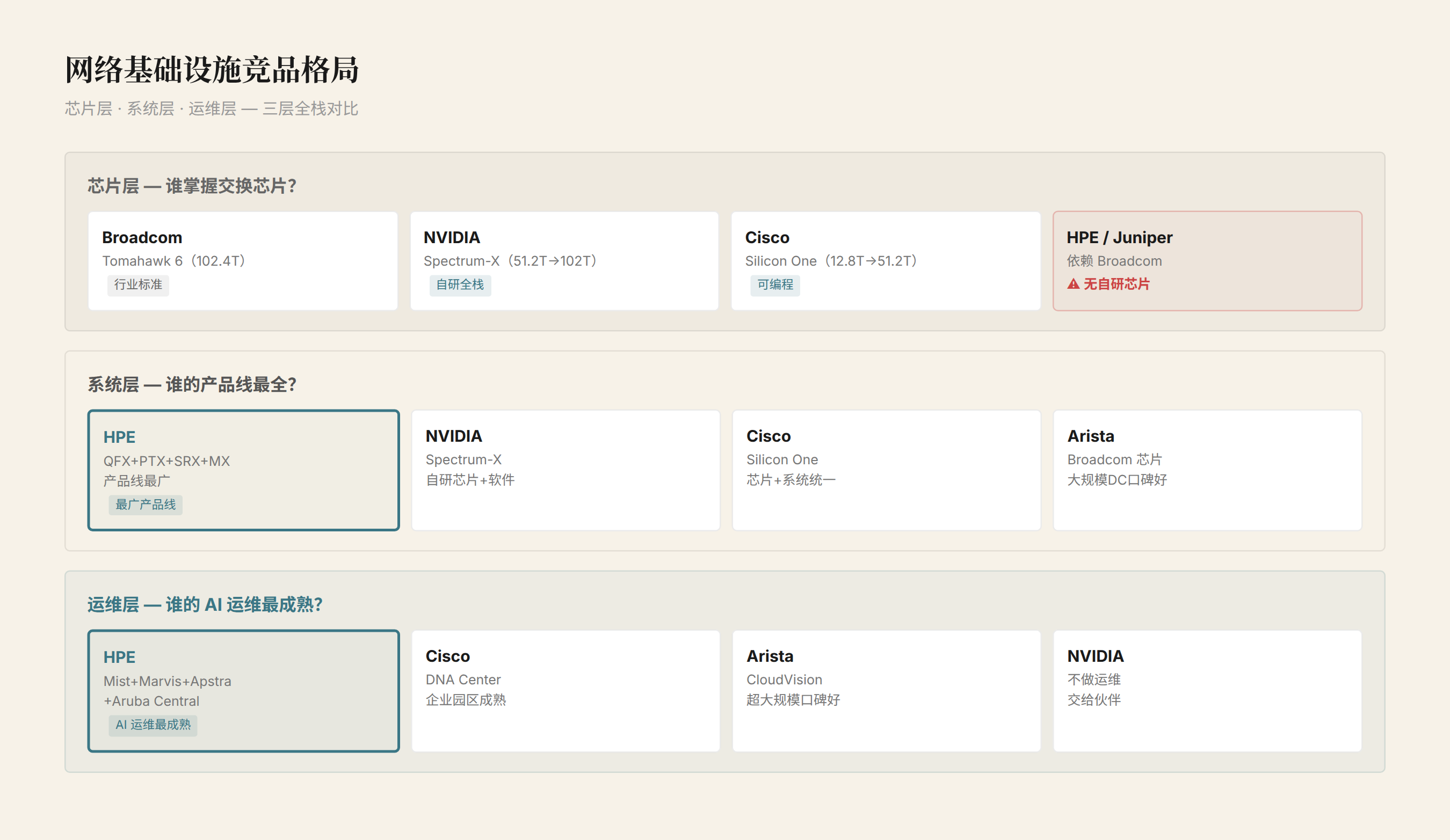
竞品格局:三层对比
数据中心网络目前有三条技术路线:
芯片层:谁能造交换芯片
| 厂商 | 芯片 | 容量 | 特点 |
|---|---|---|---|
| Broadcom | Tomahawk 6 | 102.4T | 行业标准,多数交换机厂商用 |
| NVIDIA | Spectrum-X | 51.2T → 102T | 自研芯片 + 自研网络软件栈 |
| Cisco | Silicon One | 12.8T → 51.2T | 可编程数据平面,统一路由+交换 |
| Juniper(HPE) | 自研 Broadcom 采购混合 | 16T(QFX5140)/ 102T(QFX5240) | 依赖 Broadcom 芯片,自研系统软件 |
关键问题:HPE/Juniper 不自研交换芯片。QFX5140 和 QFX5240 的核心交换芯片来自 Broadcom。这意味着在芯片层 HPE 没有差异化——任何用 Broadcom 芯片的厂商(Arista、Dell、Extreme)都能做到类似的端口规格。
NVIDIA 的 Spectrum-X 走的是自研芯片 + 自研网络软件栈的路线——芯片到软件全自研,优化链路从硅片到应用贯通。Cisco 的 Silicon One 也类似。这两家在芯片层有 HPE 没有的控制力。
HPE 的差异化在系统软件层:Juniper 的 Junos OS + Mist AI + Apstra 的运维能力。但这也是其他厂商可以追赶的——Arista 在 AI 运维方面也在快速进步。
系统层:谁的网络方案更完整
| 维度 | HPE/Juniper | NVIDIA | Cisco | Arista |
|---|---|---|---|---|
| AI 训练交换机 | QFX5220/5240 | Spectrum-X SN5600 | Silicon One G200 | 7800R3 |
| AI 推理交换机 | QFX5140/5130 | Spectrum-X SN5610 | Silicon One G100 | 7060X5 |
| 数据中心互联 | PTX 12000 | 不涉及 | ASR 9923 | 7280R3 |
| 边缘路由 | MX 301 | 不涉及 | Catalyst 8500 | 不涉及 |
| 量子安全防火墙 | SRX 4700 | 不涉及 | Secure Firewall 4250 | 不涉及 |
| AI 运维 | Mist + Marvis + Apstra + Aruba Central | 不涉及(交给伙伴) | DNA Center | CloudVision |
| 交换芯片 | Broadcom(采购) | 自研 | 自研 | Broadcom(采购) |
HPE 在产品覆盖面上最广(训练+推理+互联+边缘+安全+运维),但芯片层依赖 Broadcom。NVIDIA 和 Cisco 在芯片层有自主权但产品线窄。Arista 跟 HPE 一样依赖 Broadcom,运维软件也在进步。
运维层:谁的 AI 引擎更强
Mist AI(Juniper 2019 年收购)是目前行业里最成熟的 AI 网络运维引擎之一。Marvis 的自然语言交互能力——运维人员可以用人话问网络问题——比多数竞品成熟。
但 Mist 的强项在无线和园区网络。数据中心场景的 AI 运维(大规模 RoCEv2 参数调优、GPU 通信路径优化)还在早期阶段。Apstra 补充了一部分数据中心自动化能力,但两者的深度整合还没完成。
Cisco 的 DNA Center 在企业园区场景成熟,数据中心场景跟 NVIDIA 的伙伴关系更紧密。Arista 的 CloudVision 在大规模数据中心运维方面口碑很好——很多超大规模云厂商用 Arista + CloudVision。
三个挑战
挑战一:芯片层没有差异化
HPE/Juniper 不自研交换芯片。QFX 产品线的核心交换芯片来自 Broadcom。这意味着:
- QFX5140 的 16T/800G 规格,Arista 用同样的 Broadcom 芯片也能做到
- NVIDIA Spectrum-X 的芯片到软件全栈优化,HPE 匹配不了
- 芯片迭代节奏由 Broadcom 决定,不由 HPE 决定
HPE 能做的是在系统软件层(Junos OS)和运维层(Mist/Apstra)建立差异化。但这两层的壁垒低于芯片层——软件可以被复制,芯片不行。
挑战二:四个平台整合是工程地狱
把 Marvis、Mist、Aruba Central、Apstra 四个平台整合到 GreenLake Intelligence 一个 AI 引擎——每个平台有自己的数据格式、API 设计、告警逻辑、自动化工作流。统一数据层是整个整合的瓶颈。
HPE 历史上没有成功整合过这个量级的软件平台。Autonomy 失败了。Juniper 和 Aruba 的工程团队之前是竞争对手,在一个代码库里合作需要组织协同——这不是技术问题,是管理问题。
挑战三:QFX5140 出货节奏
QFX5140 在 Discover 2026 上发布,但实际出货可能要到 2026 年底或 2027 年初。同期 Broadcom Tomahawk 6 已经在 Cisco、Arista 的产品中交付。NVIDIA Spectrum-X 的下一代也在路上。
HPE 的窗口期很短——如果 QFX5140 延迟到 2027 年中,客户可能已经买了竞品的 800G 方案。
结语
HPE 把网络拔到「AI 控制平面」的位置——这个判断方向是对的。GPU 的算力再强,网络跟不上就是浪费算力。万卡集群的有效利用率取决于网络的无拥塞传输率,不取决于单卡 FLOPS。
但判断对和做对是两件事。
HPE 的网络产品线(QFX + PTX + SRX + MX)在覆盖面上是行业最广的。运维软件(Mist + Marvis + Apstra + Aruba Central)在成熟度上也是第一梯队。但两个结构性弱点限制了它的天花板:芯片层依赖 Broadcom,软件整合还在进行中。
过去五年,数据中心网络的定义权在向 NVIDIA(Spectrum-X)和 Broadcom(Tomahawk 路线)转移——这两家在芯片层有控制权。HPE 的角色更像系统整合商:拿别人的芯片、自己的软件、加上 Juniper 的运维能力,打包成一个完整方案。
这个方案有市场——不是每个客户都愿意自己拼芯片+软件+运维。但「整合商」的利润率和战略空间,永远不如「芯片定义者」。HPE 知道这一点。Neri 说「网络层将成为下一个重大机遇」,但他心里也清楚:那个机遇的最大赢家可能不是 HPE,是 NVIDIA 和 Broadcom。
声明: 本文基于 HPE Discover 2026 公开报道撰写,综合参考了至顶科技、腾讯新闻、企鹅号等媒体报道。产品规格以 HPE 和 Juniper 官方发布为准。竞品信息基于各厂商公开资料。不构成投资建议。