2026 年 6 月的 HPE Discover 大会上,最被低估的发布不是 QFX 交换机。
CEO Antonio Neri 在主题演讲中说了这样一段话:
「智能体现在可以跨数据、应用程序、模型和工作流进行推理,帮助企业做出决策、自动化流程,并越来越多地代表用户采取行动。IT 部门将负责管理数千个作为企业劳动力组成部分的智能体。」
这句话的核心判断是:AI Agent 不再只是「对话工具」,它正在变成一种新的工作负载类型——跟 Web 服务器、数据库、微服务一样,需要基础设施来承载。
HPE 是第一家给 Agent 搭全套基础设施的传统厂商。这篇文章拆解它的 Agent 基础设施蓝图,以及这个方向意味着什么。
Agent 从应用变成工作负载
要理解 HPE 在做什么,先要看清楚 Agent 的定位变化。
2024 年,AI Agent 是应用层的概念——一个跑在云上的对话机器人,调几个 API,回答问题。它的基础设施需求跟一个普通的 Web 应用差不多:一台服务器、一个模型 API、一个向量数据库。
2026 年,Agent 正在变成分布式系统。一个企业里的 Agent 可能同时:
- 调用多个大模型(GPT 做推理、Claude 做分析、开源模型做 embedding)
- 检索企业的文件存储、数据库、知识库
- 通过 MCP 协议跟其他 Agent 通信
- 执行实际操作(发邮件、改数据库、调 API)
- 跨多个服务器甚至跨数据中心运行
这种复杂度已经不是「应用」了,是「工作负载」。它需要:计算资源(长上下文推理很耗内存)、存储访问(Agent 要检索数据)、网络通信(Agent 之间互相调用)、安全隔离(一个出错的 Agent 不能搞垮整个系统)、生命周期管理(Agent 要注册、监控、回滚)。
Anthropic 推出 MCP 协议、OpenAI 发布 Agents SDK、微软推 Copilot 生态——这些都是在定义 Agent 的上层架构。但谁来承载这些 Agent?谁来管它们的身份和权限?谁在 Agent 出错时回滚?
这就是 HPE 想要回答的问题。
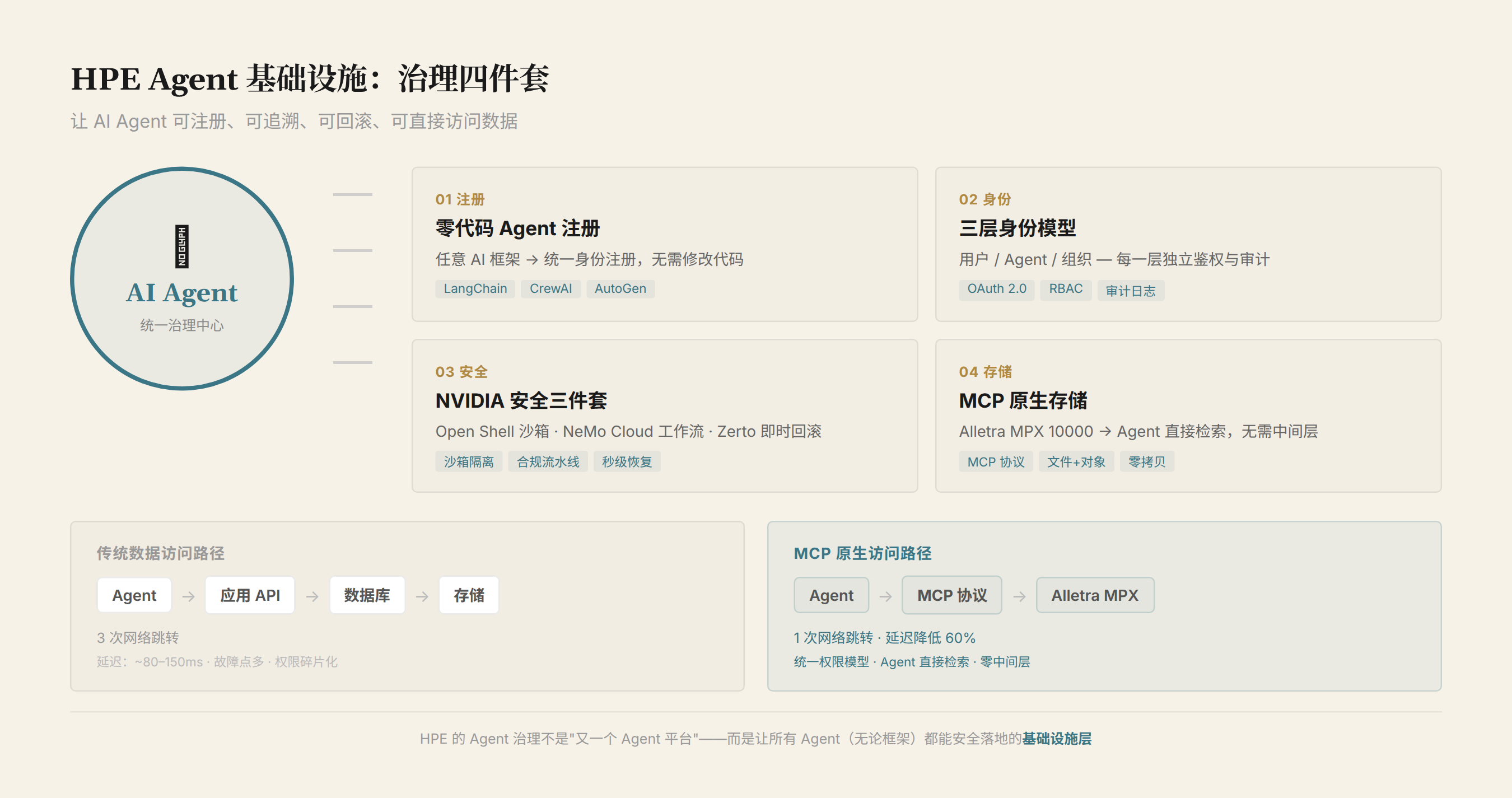
HPE 的 Agent 基础设施四件套
第一件:零代码 Agent 注册
HPE 在私有云 AI 平台中新增了 Agent 注册功能。企业可以基于任意框架(LangChain、CrewAI、OpenAI Agents SDK、Anthropic MCP 等)构建 Agent,注册时不需要修改任何代码。
注册过程中 Agent 自动获得:
- API 调用凭证
- 身份验证密钥
- 数据加密通道
这意味着:不管 Agent 用什么框架开发,到 HPE 的平台上都是统一的身份和权限模型。
第二件:三层身份模型
HPE 设计了一个三层身份架构来管理 Agent 的权限:
| 层级 | 对象 | 验证什么 |
|---|---|---|
| 第一层 | 用户 | 「你是谁」——验证使用 AI Agent 的人 |
| 第二层 | Agent | 「Agent 能做什么」——管控 Agent 的行为权限 |
| 第三层 | 组织 | 「什么操作需要人审批」——对敏感操作强制人工确认 |
关键设计:敏感操作不是由 Agent 自动执行,需要人工审批。例如 Agent 要修改客户数据库、发送对外邮件、执行金额超过某个阈值的交易——这些操作会被拦下来,推送给对应的人审批。
这解决了一个企业级的核心担忧:如果 Agent 可以自主执行操作,出了事谁负责?三层模型把「Agent 可以做」和「Agent 被允许做」分开,让企业可以在拥抱自动化的同时保持控制力。
第三件:NVIDIA 三项集成
HPE 没有自己从零构建 Agent 运行时,而是深度集成了 NVIDIA 的三套技术:
NVIDIA Open Shell——提供策略隔离的 Agent 运行环境。每个 Agent(或每组 Agent)跑在自己的沙箱里,资源隔离、权限隔离。一个 Agent 出错或被攻击,不会影响其他 Agent 或底层基础设施。这相当于容器化技术(Docker/Kubernetes)在 Agent 领域的对应物。
NVIDIA NeMo Cloud——提供受治理的 Agent 工作流蓝图。企业可以在 NeMo Cloud 里定义标准化的 Agent 工作流(比如「客户投诉处理流程」),然后让多个 Agent 按照蓝图协作执行。这解决的是 Agent 之间协作的标准化问题——不是每个企业都要自己设计 Agent 编排逻辑。
Zerto 集成——Agent 出错时实现干净状态回滚。Zerto 是 HPE 在 2022 年收购的灾备公司。这里它的能力被用在 Agent 上:如果 Agent 执行了一系列操作然后出错,Zerto 可以把系统状态回滚到出错前的干净状态。相当于给 Agent 操作按了一个「撤回」键。
这三项集成说明 HPE 在 Agent 基础设施上走的是「借 NVIDIA 生态」的路线,不是自研全套。好处是起步快——NVIDIA 的技术成熟度高。风险是 HPE 对 Agent 运行时的核心技术没有自主权——NVIDIA 自己也有 DGX Cloud 和全栈 AI 解决方案,两家公司在 Agent 基础设施上是合作伙伴,但长期看也是竞争者。
第四件:Alletra MPX 10000 + MCP
Alletra MPX 10000 存储原生支持 MCP 协议。这意味着 Agent 可以直接从存储层检索数据,不需要经过应用层。
传统路径:Agent → 应用 API → 数据库 → 存储 MCP 路径:Agent → MCP → 存储
少了一层中间件。延迟更低,架构更简单。Agent 访问数据的效率直接决定了它的响应速度——特别是长上下文场景下,Agent 需要频繁检索大量背景数据。
Alletra MPX 的「内联数据智能」也在这个场景里发挥作用:数据写入时实时提取元数据(标签、分类、实体),Agent 检索时可以直接用这些元数据做过滤,不需要自己建索引。
这是 HPE 在 Agent 基础设施上少有的自研差异化——NVIDIA 的技术提供运行时和治理,但数据访问层是 HPE 自己的存储产品。
ProLiant DL 394 Gen 12:为 Agent 负载设计的服务器
DL 394 Gen 12 是 Discover 2026 上唯一全新发布的计算产品。HPE 定位是「专为智能体 AI 和长上下文工作负载设计」。
为什么 Agent 需要专用服务器?因为 Agent 的负载特征跟传统推理不同:
- 长上下文:Agent 可能需要处理几十万 Token 的对话历史,内存带宽要求远高于短对话推理
- 多模型协同:一个 Agent 可能同时调三个模型(主推理 + 工具调用 + embedding),需要更高的 GPU 并发能力
- 频繁向量检索:Agent 每次决策前都要检索知识库,存储 I/O 延迟敏感
- 持续运行:Agent 是 7×24 小时运行的,不像批处理推理可以排队
DL 394 Gen 12 的「394」是 ProLiant 家族的新序列——现有的 DL 360(1U)、DL 380(2U)、DL 580(4U)都没有这个型号。HPE 开了一个新产线专供 Agent 负载。
不过详细规格(GPU 槽位、内存、功耗、液冷支持)在 Discover 2026 上未公开披露。这是一个信息缺口——客户无法直接对标 Dell 的 XE9680 或 Supermicro 的 GPU Server。
影子智能体危机
Neri 在 keynote 里点了一个很真实的行业痛点:
「智能体正在企业中快速扩散,往往由开发者和小团队在正式 IT 监管之外自行部署。」
这就是「影子智能体」(Shadow AI Agents)——跟「影子 IT」一个逻辑。开发者在自己的工位上跑一个 Agent,连着公司的数据库和邮件系统,没有 IT 部门审批,没有安全审查,没有权限管控。如果 Agent 出错——比如给所有客户发了错误的价格信息,或者误删了数据库表——IT 部门甚至不知道有这个 Agent 存在。
HPE 的解法是:把 Agent 纳入私有云 AI 的治理体系——注册、身份、权限、审计、回滚。用统一的平台管住所有 Agent。
但这里有一个悖论。
影子智能体之所以是「影子」,恰恰是因为开发者想绕过 IT 审批。你让 IT 部门搭一个 Agent 治理平台,要求所有 Agent 都注册——那些本来就绕过 IT 的开发者会主动来注册吗?
历史上「影子 IT」的解法不是「更好的 IT 管控平台」,而是「让 IT 管控足够轻量,开发者不觉得是负担」。AWS 之所以赢了企业 IT,不是因为它做了更好的 IT 管理平台,是因为它让开发者可以绕过 IT 直接刷信用卡开服务器。
HPE 的 Agent 治理平台能否做到足够轻量、足够友好,让开发者自愿使用?这是一个产品设计问题,不只是技术能力问题。从 Discover 2026 的公开信息看,HPE 更偏「企业级管控」而非「开发者自助」——这跟它的客户画像(大企业 CIO)一致,但限制了平台在开发者社区的传播。
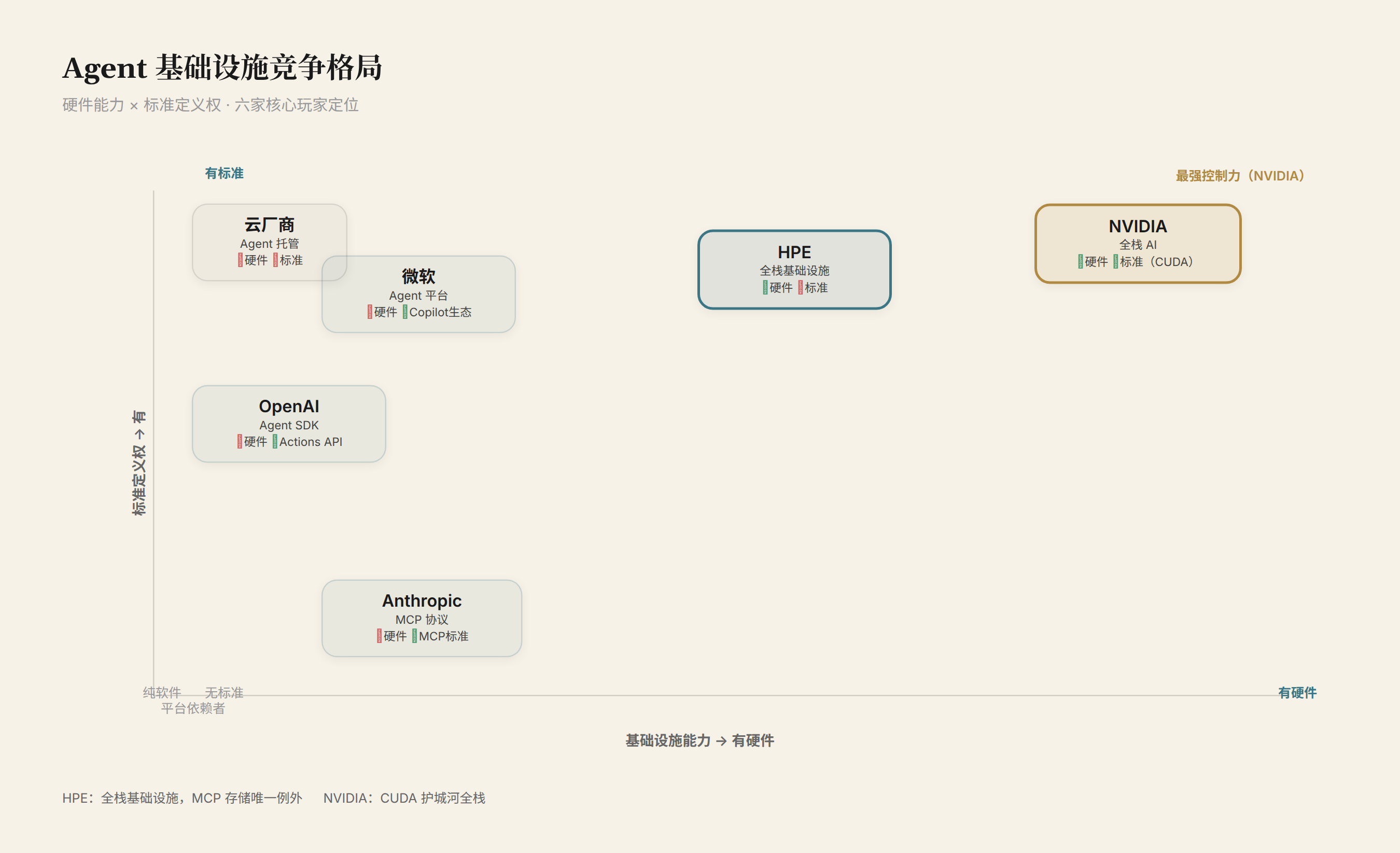
Agent 基础设施的竞争格局
HPE 不是唯一看到这个方向的公司。Agent 基础设施正在成为新战场:
| 玩家 | 定位 | 优势 | 弱势 |
|---|---|---|---|
| HPE | 全栈基础设施(计算+网络+存储+治理) | 硬件全栈、GreenLake 消费模式、企业客户 | 对 Agent 生态没有定义权、依赖 NVIDIA |
| NVIDIA | 全栈 AI(GPU+网络+DGX Cloud+软件) | 芯片定义权、CUDA 生态、最强技术 | 不是企业 IT 供应商、跟客户竞争 |
| 微软 | Agent 平台(Copilot + Azure + Fabric) | 企业客户关系、Office 生态、Azure 算力 | 硬件弱、私有化部署能力不足 |
| OpenAI | Agent SDK + ChatGPT Enterprise | 最大的模型平台、Agents SDK 先发 | 没有基础设施、靠 Azure |
| Anthropic | MCP 协议定义者 + Claude | 定义了 Agent 数据访问标准 | 纯软件公司、无基础设施 |
| 云厂商 | Agent 托管服务(AWS Bedrock Agents、Vertex AI Agent Builder) | 弹性算力、按需付费 | 私有化部署弱、大企业合规担忧 |
关键问题:谁定义 Agent 的架构标准?
目前看,Agent 的架构标准主要在软件层被定义:
- Anthropic 的 MCP 协议——Agent 如何访问外部数据
- OpenAI 的 Actions API——Agent 如何执行操作
- LangChain/CrewAI——Agent 如何编排和协作
HPE 在这些标准里没有任何一个的主导权。它做的是「Agent 的服务器和网络」——硬件层和运维层的承载。这跟它在云计算时代的角色一样:不定义操作系统,只卖承载操作系统的服务器。
但 Agent 时代有一个跟云时代不同的变量:MCP 协议。Anthropic 定义了 MCP,但 HPE 是第一个在硬件层(存储)原生支持 MCP 的厂商。如果 MCP 成为行业标准,HPE 的「MCP 原生存储」就是先发优势。
结语:基础设施者的机会和天花板
HPE 在 Discover 2026 上做了一件有意思的事:它把 AI Agent 从「应用层概念」变成了「基础设施工作负载」。这个重新定义如果成立——Agent 确实需要专用服务器、专用存储、专用网络、专用治理——那 HPE 作为基础设施供应商就有了新的市场。
但天花板也很明显。Agent 的核心技术栈(模型、框架、协议、编排)不在 HPE 手里。HPE 做的是承载层——把别人定义的 Agent 架构跑在自己的硬件上。这跟它在云计算时代的角色没有本质区别。
唯一的不同是 MCP。如果 HPE 能把「MCP 原生基础设施」做成一个品类——从存储开始,扩展到网络和计算——它就有可能在 Agent 时代建立一个属于自己的技术壁垒。
这个赌注值不值得下?答案取决于 MCP 协议能走多远。如果 MCP 成为 AI Agent 访问数据的世界标准(类似 HTTP 之于 Web),那 HPE 的先发优势就有长期价值。如果 MCP 被其他协议替代,HPE 的赌注就白下了。
从 Discover 2026 的信息看,HPE 已经把筹码放上桌了。
声明: 本文基于 HPE Discover 2026 公开报道撰写,综合参考了至顶科技、腾讯新闻等媒体报道。文中涉及的 NVIDIA Open Shell、NeMo Cloud、Zerto 等产品能力描述以 HPE 和 NVIDIA 官方发布为准。不构成投资建议。