让 K8s 理解超节点:openFuyao 与灵衢的云化突围
篇三 · 灵衢软件深度分析系列
前两篇分析了灵衢的内核层和服务层。内核层让 Linux 看见超节点硬件,服务层让 8192 张卡协同工作。用户不直接操作这两层--他们用的是 Kubernetes。
云化层回答的问题是:怎么把灵衢硬件和服务层的能力,通过 K8s 标准接口暴露给用户。 答案叫 openFuyao。它不是灵衢的一部分,但灵衢能不能走出华为生态圈,很大程度上取决于 openFuyao 做得好不好。
一、openFuyao 的定位:不只是又一个 K8s 发行版
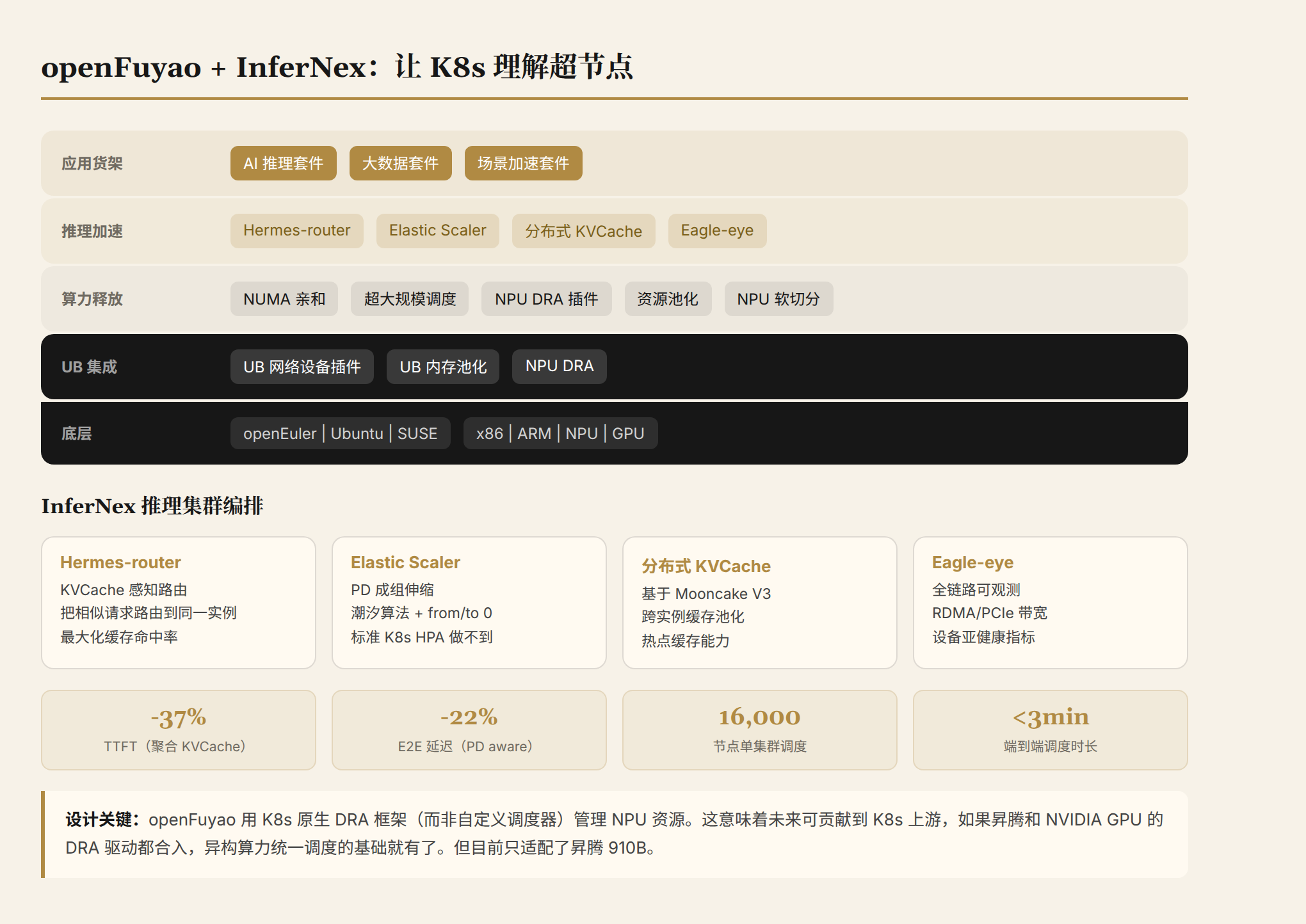
openFuyao 官网(openfuyao.cn)的自我定位是"面向通算和智算集群软件技术创新的开源社区"。翻译成人话:K8s 发行版 + 多样化算力调度增强层。
它的五层架构:
┌────────────────────────────────────────────────────────┐
│ 应用货架:AI 推理套件 / 大数据套件 / 场景加速套件 │
├──────────────┬───────────────────┬─────────────────────┤
│ AI 推理加速 │ 大数据加速 │ 容器平台 │
│ InferNex │ │ Console/认证/监控 │
├──────────────┴───────────────────┴─────────────────────┤
│ 算力释放创新组件 │
│ NUMA 亲和 / 超大规模集群 / 在离线混部 / 分布式作业 │
│ KAE Operator / NPU Operator / 资源池 / NPU 软切分 │
├────────────────────────────────────────────────────────┤
│ 调度组件:容器编排引擎 (K8s) + 容器/网络/存储运行时 │
├────────────────────────────────────────────────────────┤
│ OS: openEuler | SUSE | Ubuntu | ... │
│ 算力: x86 | ARM | CPU | NPU | GPU | ... │
└────────────────────────────────────────────────────────┘
底层声称支持 x86 + ARM + CPU + NPU + GPU。不只是华为的鲲鹏和昇腾。至少在定位上,openFuyao 想做跨硬件的调度层。
版本节奏:半年一个大版本。v25.06 首发,v25.12 首个 LTS(K8s 1.34,16000 节点集群落地),v26.03 当前最新(InferNex 全面升级 + 灵衢 UB 集成 + NPU DRA 插件)。
二、灵衢 UB 集成:把硬件能力翻译成 K8s 语言
v26.03 新增了三个直接对接灵衢硬件的 K8s 原生组件。
2.1 UB 容器网络设备插件
适配灵衢 URMA 设备。容器可以直接使用灵衢通信能力,通信延迟 1.7-2.5μs,比 TCP 低 90%。
用户侧:在 Pod spec 里声明需要 URMA 设备,调度器自动找到有灵衢能力的节点,把设备挂进容器。容器内的应用用 URMA API 做通信,不需要知道底层是灵衢还是 RDMA。
2.2 UB 内存池化
两个能力:
内存借用。 节点内存使用率达到阈值时,自动从其他节点借内存。最佳借用比例 25%,性能损耗 <5%。对应用完全透明--分配器觉得在用本地内存,实际可能来自三个机柜外。
内存共享。 跨节点、跨进程的内存块导入导出。共享内存访问延迟 300-400ns。首次映射耗时 2-5s,后续访问走灵衢硬件路径。
K8s 侧:在 Pod spec 里声明需要 UB 内存池化能力,openFuyao 自动完成内存借用和共享的配置。不需要手动配 NUMA 策略或内存亲和性。
2.3 NPU DRA 插件
基于 K8s 1.26+ 引入的 DRA(Dynamic Resource Allocation) 框架。自动发现昇腾 NPU,采集 ID/内存/网络拓扑信息,用 CEL 表达式精细分配 NPU 资源。
这个设计决策很重要:用 K8s 原生 DRA,而不是自定义调度器。
NVIDIA 的 GPU 分配目前走的是 device-plugin + 自定义调度扩展路线。如果昇腾 NPU 的 DRA 驱动和 NVIDIA GPU 的 DRA 驱动都合入 K8s 上游,异构算力的统一调度就有了基础--一个集群里同时跑昇腾和 NVIDIA GPU,用同一套 K8s 调度框架管理。
但目前只适配了昇腾 910B 系列。NVIDIA GPU 的 DRA 驱动还没有。DRA 路线要真正改变格局,至少需要两家以上芯片厂商的驱动都合入上游。
三、InferNex:推理集群级编排--openFuyao 最有商业价值的组件
3.1 推理优化的主战场已进入集群层面
2026 年推理算力需求远超训练。但推理优化的主战场已经从单卡层面进入了集群层面。
单卡优化做到极致之后,瓶颈变成了:
- 请求怎么路由到最合适的推理实例?(KV Cache 命中率)
- Prefill 和 Decode 实例怎么按需伸缩?(PD 分离架构)
- 多个推理实例之间的 KV Cache 怎么共享?(分布式缓存)
InferNex 解决的就是这三个问题。它不是推理引擎本身,而是推理引擎上层的调度/路由/缓存编排层。
3.2 架构拆解
Hermes-router(智能路由)。 KVCache 感知、分桶策略、Pod 级状态感知。核心思路:把相似请求路由到同一个推理实例,最大化 KV Cache 命中率。
这个思路和 vLLM 的 prefix caching 类似,但做到了集群级别而不是单实例级别。Hermes-router 知道每个推理实例当前缓存了哪些 prefix,新请求进来时,路由到缓存命中概率最高的实例。
Elastic Scaler(弹性伸缩)。 PD 分离场景的专用伸缩器。潮汐算法、成组伸缩、from/to 0 弹性。关键能力:按组(成 Prefill+Decode 组)伸缩--标准 K8s HPA 做不到这个,因为 HPA 不理解 Prefill 和 Decode 的配对关系。
分布式 KVCache。 基于 Mooncake 的跨实例 KVCache 池化存储与传输。热点缓存能力--固定内存总量下,把高频访问的 KV Cache 放在更快的存储层。
Eagle-eye(全链路可观测)。 业务运行态 → 系统运行态 → 硬件健康。采集 RDMA 带宽、PCIe 带宽、设备亚健康指标。
推理后端。 基于 vLLM/vLLM-Ascend 的云原生场景推理引擎一键部署。
3.3 实测性能
v26.03 在昇腾 910B 上的数据:
| 路由策略 | 场景 | E2E 延迟收益 | TTFT 收益 |
|---|---|---|---|
| 聚合 KVCache aware | 同机集群 | 9.15% | 37.35% |
| PD KVCache aware | 同机集群 | 22.08% | 27.73% |
| PD KVCache aware | 跨机集群 | 17.31% | 22.03% |
与 Mooncake 社区合作的 V3 架构:生产环境 TTFT 下降 40%,端到端延迟下降 30%。这些有配套组件版本号(vllm-ascend 0.11~0.14、Hermes-router 0.21.0 等),不是纸面数字。
3.4 InferNex 的竞争格局
推理集群级编排是 2026 年的热门方向。InferNex 的主要竞争者:
| 方案 | 来源 | 特点 |
|---|---|---|
| InferNex | 华为 / openFuyao | KVCache 路由 + PD 成组伸缩 + Mooncake 集成 |
| vLLM serving | vLLM 社区 | 单实例级 prefix caching,集群级靠外部负载均衡 |
| SGLang router | SGLang 社区 | 类似思路,但更偏单集群 |
| NVIDIA NIM | NVIDIA | 商业方案,深度绑定 Triton + TensorRT |
InferNex 的差异化在于 PD 分离架构的成组伸缩 和 Mooncake 分布式 KVCache 的深度集成。这两个能力在开源方案中比较少见。
但 InferNex 目前绑定昇腾 NPU。如果它能在非昇腾硬件上提供降级但可用的体验(比如标准 NVIDIA GPU + 以太网),它的用户群会大得多。目前看不到这个方向的进展。
四、超大规模集群调度:16000 节点的工程挑战
4.1 已验证的规模
v25.12 落地了中国移动云 2 万卡超节点集群:16000 节点单集群,端到端调度时长 <3 分钟。
关键工程手段:
- API Server 多实例 + IPVS 负载均衡
- APF(API Priority and Fairness)流控
- Informer 预加载
- 三层拓扑感知调度(超节点 → 计算柜 → 物理服务器)
- 逻辑超节点抽象
- 自动故障感知隔离 + 断点续训
16000 节点在 K8s 社区里算什么水平?标准 K8s 官方支持的上限是 5000 节点。阿里云、字节跳动、Google 内部有万级节点集群的定制方案,但都没有开源。openFuyao 的 16000 节点调度能力如果真的能通用化,对 K8s 社区是有贡献的。
4.2 Aether 弹性调度框架
京东联合共创。Brain 全局决策 + Driver 运行态感知 + Executor 进程级执行。训练有效时间占比提升至 97%,资源成本降低 30%。
97% 意味着只有 3% 的时间花在调度、通信、同步等非计算开销上。作为参考,A5000 集群训练 GPT-3 175B 的公开数据显示,非计算开销通常占 5-15%(取决于模型并行策略和集群规模)。Aether 的 3% 如果是在大规模 MoE 模型上测到的,含金量很高。但测试条件和模型类型没有公开--不同模型结构的通信/计算比差异很大,MoE 的 All-to-All 通信远多于 Dense 模型的 AllReduce。没有这些信息,97% 只能作为方向性参考。
五、生态伙伴与社区状态
5.1 伙伴名单
| 伙伴 | 角色 | 进展 |
|---|---|---|
| 天翼云(中国电信) | 运营商云 | 社区筹备委员会,2 万卡集群落地 |
| 统信软件 | 国产 OS | 适配 openFuyao,1100 万套覆盖 |
| 广电五舟 | 服务器厂商 | PentaPleiades HPC+AI 双栈 |
| 灵雀云 | 云平台 | ACP + openFuyao 深度适配 |
| 京东 | 互联网 | Aether 弹性调度框架共创 |
| Mooncake 社区 | 开源项目 | KVCache V3 架构合作 |
5.2 社区活跃度
openFuyao 社区 2025.12-2026.2 运作报告显示的社区治理结构:筹备委员会 + SIG(Special Interest Group)。伙伴名单以华为生态圈内的企业为主。没有 NVIDIA、AMD、Intel 等海外芯片厂商,没有 AWS/Azure/GCP 等海外云厂商。
国产化生态的构建需要时间和持续投入。openFuyao 目前仍然是以华为为核心的生态圈,距离"多样化算力的统一调度层"还有很长的路。
六、灵衢软件栈的判断

三篇文章分析了灵衢从内核到云化的完整软件栈。回到最根本的问题:灵衢软件栈的战略价值在哪里,边界又在哪里?
6.1 核心价值:编程模型的统一
灵衢软件栈最有价值的创新不是任何单个组件,而是 URMA 编程模型--用 load/store 指令直接访问超节点内任意内存。
这个编程模型的价值链:
- 内核层的 UMMU 提供硬件级地址翻译(300-400ns)
- 服务层的 MemFabric 把分散的内存编织成统一地址空间
- 云化层的 openFuyao 通过 K8s 原生接口暴露给用户
三层叠加的结果:一个运行在机柜 A 的推理实例,可以用标准内存操作读取机柜 Z 的 NPU HBM 上的 KV Cache,延迟 300-400ns,对应用几乎透明。
这是灵衢真正不可替代的地方。CXL 覆盖范围不够(机柜内),RDMA 延迟不够低(微秒级),没有其他方案能在亚微秒延迟下提供跨百机柜的统一内存访问。
6.2 核心风险:封闭生态的自我强化
灵衢的每一个组件都只跑在华为硬件上。UB OS Component 绑定灵衢控制器,MemFabric 绑定灵衢互联,HCCL 绑定昇腾 NPU,openFuyao 深度集成绑定灵衢 UB。
NVIDIA 的 CUDA 也封闭,但 CUDA 封闭的前提是 NVIDIA GPU 占了数据中心 AI 算力的 80%+。灵衢封闭的前提是昇腾在国内 AI 加速器市场的份额,目前估计在 10-20% 之间(主要来自政府和运营商订单)。封闭本身不是错,但 10-20% 的市场份额撑不起一个全栈封闭生态。
封闭的真正风险是自我强化:
- 硬件封闭 → 只有华为的芯片能跑灵衢软件
- 软件封闭 → 只有灵衢软件能发挥灵衢硬件的全部能力
- 生态封闭 → 第三方芯片厂商没有动力适配灵衢,第三方软件厂商没有动力适配昇腾
打破这个循环需要的不是更多的技术投入,而是商业模式的变化--把灵衢协议做成真正的行业标准(不只是公开规范文档,而是有第三方芯片厂商参与制定),把 UBS Core 做成真正开放的社区项目(有非华为的维护者、贡献者、决策权),把 openFuyao 做成真正的跨硬件平台(有 NVIDIA/AMD GPU 的适配,有海外用户的采用)。
更基本的问题是:架构蓝图能让集群跑起来,让集群持续跑下去靠的是可观测性、版本兼容性、CVE 响应这些不性感的工程细节。篇一推演的 FR、篇二推演的 SL、本篇推演的 SR,三篇合计推演 88 条功能需求,合并去重后 41 条系统级规格,其中 51% 未公开。这些缺口不在架构图上,在生产运维的工单里。
如果不做这些转变,灵衢就只是一个更好的 NVLink--有用,但不改变格局。
6.3 InferNex 是当前最值得关注的商业机会
推理是 2026 年最急迫的算力需求。推理优化已经从单卡层面进入集群层面。InferNex 的 KVCache 感知路由 + PD 成组伸缩 + Mooncake 分布式缓存,是目前市场上少数真正做推理集群级编排的开源方案。
但 InferNex 目前绑定昇腾 NPU。它的价值最大化路径是:先在昇腾生态内证明效果(已初步验证),然后逐步解耦--Hermes-router 的路由逻辑理论上不依赖灵衢硬件,Mooncake 本身是独立开源项目。如果 InferNex 能在标准 NVIDIA GPU + 以太网环境下提供降级但可用的体验,它的用户群会从"使用昇腾的国内客户"扩展到"所有需要推理集群编排的团队"。
6.4 跟踪信号
判断灵衢软件栈未来 12-24 个月的发展方向,跟踪这五个信号:
1. UBS Core 的非华为贡献者占比。 24 个 commit 全部来自华为。如果开放一年后仍然如此,"开源"就是象征性的。真正的拐点是第三方提交 UBPU 驱动。
2. 第三方芯片厂商是否采纳灵衢协议。 灵衢互联社区(unifiedbus.com)的成员变化。有没有任何非华为芯片宣布支持 UB。
3. openFuyao 的硬件适配范围。 v26.03 只适配了昇腾 910B。下一个版本是否加入 NVIDIA GPU 或其他国产 NPU 的支持?
4. Atlas 950 SuperPoD 的生产数据。 8192 卡规模下的 URMA 延迟分布、HCCL AllReduce 带宽利用率、UBS Engine 故障恢复时间。目前一个公开数据点都没有。
5. InferNex 的硬件解耦进度。 能否在非灵衢硬件上跑起来?哪怕降级到标准 RDMA 模式。
七、从推演还原系统软件功能规格
篇一从内核层推演了 32 条 FR(Functional Requirement),发现 34% 已实现、66% 未知。篇二从服务层推演了 15 条 SL(Service Layer),全部未公开。本篇分析了云化层。现在把三篇的推演收拢,按功能域而不是按软件层,还原一份超节点系统软件的功能规格书。
SR(System Requirement)不重复 FR 和 SL,而是从全栈视角重新组织。FR 中的关键条目(如 UMMU 地址翻译、UBM 心跳收敛)以更高粒度出现在 SR 中,并标注与 FR/SL 的对应关系。这样三篇连读时可以看到从层内需求到系统需求的递进,单读篇三也不需要回翻篇一。
7.1 规格编写原则
每条规格(SR)必须满足:
- 有推演来源:不是凭空想象,而是前面某个技术分析或边界推敲的结论
- 有验证标准:能用"已实现/未实现/部分实现/未公开"来判断
- 有优先级判断:对超节点可用性的影响程度
7.2 互联与拓扑管理
超节点首先是一张网。这张网的管理能力决定了一切上限。
| ID | 功能规格 | 推演来源 | 状态 |
|---|---|---|---|
| SR-1 | 路由表支持可编程拓扑(胖树/Mesh/自定义),按通信模式动态调优 | 篇一 FR-2:8192 卡集群不是单一负载,训练和推理的通信模式不同 | ❓ |
| SR-2 | 路由表聚合到可管理规模:全互联 O(n2) 6700 万条不可行,交换拓扑聚合到 ~8192 条 + ECMP 多路径 | 篇一路由表规模推算:O(n2) 全互联 160 机柜 = 6700 万条,必须拓扑聚合 | ✅ 部署实现 |
| SR-3 | UBM 心跳探测在 8192 UBPU 规模下单轮完成时间 <5s | 篇一推算:千卡秒级→8192 卡可能十秒级,运维 SLA 要求收敛更快 | ❓ |
| SR-4 | 拓扑变更事件通知 HostOS,触发应用层重路由 | 篇一 FR-28:拓扑收敛期间应用需要知道哪些路径不可用 | ❓ |
| SR-5 | 故障隔离粒度可配置:单设备隔离 vs 机柜级隔离,按 SLA 选择 | 篇一 FR-26:训练可接受精确隔离,推理可能需要快速隔离 | ❓ |
SR-3 是规模天花板。 心跳探测时间决定故障检测窗口。如果 8192 卡需要 >10s 才能完成一轮拓扑探测,那初始化、故障恢复、拓扑重计算的延迟都跟着膨胀。这个数字直接决定灵衢超节点能做多大。
7.3 跨节点内存系统
灵衢的核心价值--统一内存地址空间。但从"能编址"到"好用"之间有一系列规格要求。
| ID | 功能规格 | 推演来源 | 状态 |
|---|---|---|---|
| SR-6 | UMMU 硬件地址翻译:虚拟地址 → {NodeID, UASID, VA},延迟 300-400ns |
篇一 §2.2 UMMU 分析 | ✅ |
| SR-7 | UMMU TLB 容量与 miss penalty 可观测 | 篇一推算:8192 UBPU × N 并发 UASID,TLB miss 可能是延迟尖刺来源 | ❓ |
| SR-8 | 借用比例可调(非固定 25%),支持局部性检测和加权延迟估算 | 篇一推演:均匀分布假设下 25% 是最优,但实际负载局部性差异大 | ✅ 框架存在 |
| SR-9 | 借用内存的 NUMA distance 精确标注(区分远端 HBM 和远端 DRAM) | 篇一 FR-9:不同介质延迟不同,distance 不能一刀切 | ❓ |
| SR-10 | 数据位置感知 API:应用可查询虚拟地址的物理位置,可主动触发迁移 | 篇一 FR-12:"单机语义是编程简化不是性能等价"--性能路径需要感知位置 | ❓ |
| SR-11 | 共享内存批量 owner 转移:一次调用转移 N 个区域的写入权 | 篇一推演:gradient accumulation 涉及数百区域交替写入,逐个 set_ownership 开销叠加 | ❓ |
| SR-12 | 跨节点内存 cgroup 限额:限制单个容器/进程的远端内存借用总量 | 篇一 FR-13:多租户场景防止内存饥饿 | ❓ |
| SR-13 | 页迁移粒度与延迟可配置(4KB/2MB/1GB),大页迁移走硬件加速路径 | 篇二存储语义 vs 内存语义推敲:4KB 页迁移粒度在跨节点场景下延迟开销大 | ❓ |
| SR-14 | UCM(统一缓存管理)显式管理层:区分热数据自动驻留和温数据按需加载 | 篇二推敲:page migration 的延迟问题暗示 UCM 可能需要显式缓存策略而非纯页错误驱动 | ❓ |
SR-10 和 SR-13 是"统一内存"能不能从概念变成工程的关键。 SR-10 让应用有能力做数据布局优化--不是所有数据都需要跨节点访问,热数据放本地、温数据放远端是基本策略,但前提是应用能感知位置。SR-13 解决页迁移粒度问题--4KB 粒度在跨节点场景下意味着频繁的小数据搬运,延迟放大;如果提供大页迁移的硬件加速路径,跨节点大块数据传输效率可以大幅提升。
SR-14 是一个从边界推敲推出的隐性需求。灵衢宣称"单机内存语义",但 page migration 的延迟(缺页中断 → UMMU 翻译 → 跨节点 DMA → 页填充)不可能和真正的本地内存一样。如果 UCM 有显式缓存管理层(类似 CPU cache 的 prefetch/evict hint),应用可以在做 checkpoint 或 gradient sync 等可预测操作时,预取需要的远端数据,避免运行时缺页。这个能力目前没有任何公开信息,但从性能要求推算是刚需。
7.4 集合通信与兼容层
通信是训练和推理的基础设施。灵衢在通信层有两条线:原生 URMA 和兼容层。
| ID | 功能规格 | 推演来源 | 状态 |
|---|---|---|---|
| SR-15 | HCCL 集合通信库:AllReduce/AllGather/ReduceScatter 等,适配灵衢拓扑 | 篇二 §3.1 HCCL 分析 | ✅ |
| SR-16 | RoUB 兼容层:libibverbs 接口兼容 | 篇一 §2.3 零修改迁移 | ✅ |
| SR-17 | Socket over UB 兼容层 | 篇一 §2.3 TCP 应用无感加速 | ✅ |
| SR-18 | 通信性能全链路可观测:延迟分布、带宽利用率、URMA/UDMA 队列深度 | 篇一 FR-17:三级适配路径收益需要实测验证 | ❓ |
| SR-19 | RDMA 应用兼容性认证矩阵:主流 RDMA 框架在 RoUB 上的验证状态 | 篇一 FR-18:冷启动需要迁移路径 | ❓ |
| SR-20 | URMA → UCX 适配层,让 UCX 应用跑在灵衢硬件上 | 篇一开源替代分析:UCX 是最接近的跨平台通信框架 | ❓ |
SR-19 决定了冷启动能不能发生。 用户迁移的第一步不是"灵衢比 RDMA 快多少",而是"我现有的 NCCL/MPI/oneCCL 应用能不能直接跑"。没有兼容性矩阵,迁移决策卡在第一步。
7.5 虚拟化与多租户
超节点的算力需要被切片分配。
| ID | 功能规格 | 推演来源 | 状态 |
|---|---|---|---|
| SR-21 | UB 设备 vfio 直通,虚机可直接使用灵衢通信和内存能力 | 篇一 §2.4 合规场景 | ✅ |
| SR-22 | vfio + UMMU 协同实现为 vfio_iommu_ub 独立类型,不修改 vfio 核心代码 |
篇一推演:修改 vfio 核心增加上游兼容风险 | ❓ |
| SR-23 | 虚机跨节点内存映射 + live migration,迁移延迟 <100ms | 篇一 §2.4 超级 VM | ✅ |
| SR-24 | 超级 VM 的远端内存限额:限制单个 VM 可使用的跨节点内存总量 | 篇一 FR-23:多租户隔离 | ❓ |
| SR-25 | 硬件 CC(cache coherence)不可行时的替代方案:软件级一致性协议 + 选择性 snoop | 篇一推算:snoop filter 规模 O(n2)、invalidation ack 最慢节点决定延迟 → 硬件 CC 在 8192 卡规模不可行 | N/A 确认不可行 |
SR-25 的意义是:这个规格不应该存在,但推演表明它必须存在。8192 UBPU 的硬件 cache coherence 在物理上不可行--snoop filter 容量、coherence traffic 的 O(n2) 增长、invalidation ack 的最慢节点瓶颈,三重限制。灵衢选择 load/store 语义而非 cache coherence 是对的。但这意味着:跨节点写入后的可见性保证需要软件层来补。灵衢的 UMMU 提供地址翻译但不提供 cache 一致性--那一致性协议在哪?URMA 的同步模式?显式 flush?还是依赖应用的通信原语(barrier)?这个问题的答案决定了跨节点内存的编程模型的真正复杂度。
7.6 推理集群编排
InferNex 是灵衢软件栈在推理场景的核心出口。
| ID | 功能规格 | 推演来源 | 状态 |
|---|---|---|---|
| SR-26 | KVCache 感知路由:请求路由到缓存命中概率最高的实例 | 篇三 §3.2 Hermes-router | ✅ |
| SR-27 | PD 分离的成组伸缩:Prefill 和 Decode 实例配对管理,标准 HPA 不支持 | 篇三 §3.2 Elastic Scaler | ✅ |
| SR-28 | 分布式 KVCache 三级存储:HBM / DRAM / NVMe 分层,热点自动晋升 | 篇二 ICMSP 分析:HBM ~$20/GB / DRAM ~$3/GB / NVMe ~$0.3/GB | ✅ |
| SR-29 | KVCache 三级存储的延迟/成本可配置:每层容量、晋升/降级策略可调 | 篇二推演:三级成本差 70 倍,不同场景的冷热分布不同 | ❓ |
| SR-30 | 硬件解耦模式:InferNex 可在非灵衢硬件上降级运行(标准 RDMA 模式) | 篇三 §6.3 价值最大化路径 | ❌ |
| SR-31 | 全链路可观测:业务指标 + 系统指标 + 硬件亚健康,三层联动 | 篇三 §3.2 Eagle-eye | ✅ |
SR-30 是 InferNex 能不能走出昇腾生态的关键。 目前 InferNex 深度绑定昇腾 NPU 和灵衢通信。Hermes-router 的路由逻辑理论上不依赖灵衢硬件,Mooncake 是独立开源项目。如果 InferNex 能提供一个 RDMA 降级模式--用标准 RoCEv2 替代 URMA,用标准 GPU 替代昇腾 NPU--它的潜在用户群从"使用昇腾的国内客户"扩展到"所有需要推理集群编排的团队"。目前没有任何公开进展。
7.7 调度与资源管理
超节点的算力调度需要理解超节点的拓扑。
| ID | 功能规格 | 推演来源 | 状态 |
|---|---|---|---|
| SR-32 | 三层拓扑感知调度:超节点 → 计算柜 → 物理服务器 | 篇三 §4.1 16000 节点集群 | ✅ |
| SR-33 | NPU DRA(Dynamic Resource Allocation)插件,用 K8s 原生框架而非自定义调度器 | 篇三 §2.3 架构决策分析 | ✅ |
| SR-34 | 逻辑超节点抽象:应用可声明"需要 64 卡超节点",调度器自动分配物理资源 | 篇三 §4.1 超大规模集群 | ✅ |
| SR-35 | 异构算力统一调度:同一集群同时管理昇腾 NPU 和 NVIDIA GPU | 篇三 §2.3 DRA 路线分析:需要两家以上芯片厂商的 DRA 驱动都合入上游 | ❌ |
| SR-36 | 训练有效时间占比的可观测性:97% 这个数字的测量方法需要透明 | 篇三 §4.2 Aether 数据:测试条件和模型类型未公开 | ❓ |
SR-35 是 openFuyao 定位"多样化算力调度层"的终极检验。目前只适配了昇腾 910B。DRA 路线如果成功,异构算力的统一调度有了技术基础。但 DRA 路线需要的不只是华为一家--需要 NVIDIA 的 DRA 驱动也合入 K8s 上游。这取决于 NVIDIA 的战略决策,不取决于 openFuyao。
7.8 版本管理与运维
128 机柜、三层软件栈、8192 张卡的运维复杂度。
| ID | 功能规格 | 推演来源 | 状态 |
|---|---|---|---|
| SR-37 | 三层版本兼容性矩阵自动检查:DeviceOS / UBM / HostOS 任意组合的兼容性 | 篇一推演:三层版本 × 多个型号 = O(n3) 兼容性矩阵,人工检查不可行 | ❓ |
| SR-38 | 三层独立升级/回滚:任意层升级不影响其他层,失败可回滚 | 篇一推演:openEuler fork 的隐性税--升级 UBM 固件不应要求重启 HostOS | ❓ |
| SR-39 | 内核模块 ABI 跨版本稳定:UB OS Component 的用户态-内核态 ABI 不随版本变化 | 篇一 FR-32:ABI 不稳定则用户态工具链要跟着改 | ❓ |
| SR-40 | openEuler fork 的 CVE 窗口期可量化:从上游发 CVE 到 fork 修复合并,最长延迟多少天 | 篇一推演:fork 的隐性税--CVE 响应延迟是安全风险 | ❓ |
| SR-41 | CXL 子系统冲突检测:UB OS Component 的修改不能阻塞未来主线 CXL 代码合并 | 篇一推演:fork 修改了总线模型和内存管理扩展,与主线 CXL 子系统可能冲突 | ❓ |
SR-37 到 SR-41 是"128 机柜能不能运维"的问题。 灵衢的公开材料展示的是架构蓝图和性能亮点。但运维 128 机柜、三层软件栈、8192 张卡的人面对的是:升级一个 UBM 固件要不要停业务?一个 CVE 出来,从上游修复到灵衢 fork 合并要几天?内核模块升级会不会破坏用户态工具?这些问题的答案不在架构图上,在生产运维的工单里。
SR-41 尤其值得注意。灵衢内核层修改了 Linux 总线模型(新增 ub_bus_type)、内存管理扩展(跨节点统一编址)、PCIe 子系统交互。这些修改基于 openEuler fork。如果未来 Linux 主线的 CXL 子系统做了不兼容变更,灵衢 fork 的合并成本会随时间累积。这不是当前问题,但 3-5 年后可能变成结构性风险。
7.9 功能规格全景总结
| 功能域 | 规格数 | ✅ 已实现 | ❓ 未公开 | ❌ 缺失 |
|---|---|---|---|---|
| 互联与拓扑管理 | 5 | 1 | 3 | 1 |
| 跨节点内存系统 | 9 | 1 | 7 | 1 |
| 集合通信与兼容 | 6 | 3 | 2 | 1 |
| 虚拟化与多租户 | 5 | 2 | 2 | 0 (1 不可行) |
| 推理集群编排 | 6 | 4 | 1 | 1 |
| 调度与资源管理 | 5 | 3 | 1 | 1 |
| 版本管理与运维 | 5 | 0 | 5 | 0 |
| 合计 | 41 | 14 (34%) | 21 (51%) | 5 (12%) + 1 不可行 |
加上篇一内核层的 32 条 FR(11 已实现 + 21 未知),三篇总共推演了 73 条功能需求。合并去重后 41 条系统级规格。
几个结构性结论:
1. "已实现"集中在可见层。 URMA 通信、vfio 直通、拓扑发现、InferNex 路由--这些是部署就能演示的能力。"未公开"集中在不可见层:TLB 可观测性、页迁移粒度、版本兼容性矩阵、CVE 响应延迟--这些是运行三个月后才会暴露的问题。
2. 可观测性是最大的系统性缺口。 SR-7(TLB miss)、SR-10(数据位置)、SR-18(通信全链路)、SR-36(训练有效时间测量方法)、SR-37(版本兼容性检查)--跨功能域的共性缺口是无法观测系统内部状态。灵衢提供了 Eagle-eye 做硬件健康监控,但软件层的内部可观测性(UMMU 翻译效率、内存借用局部性、通信路径选择逻辑)几乎没有公开信息。
3. 多租户隔离规格几乎空白。 SR-12(内存借用限额)、SR-24(虚机远端内存限额)、SR-25(跨节点一致性替代方案)--这些在超节点被多个业务共享时是刚需。灵衢目前的公开材料假设超节点跑单一业务(训练一个大模型或部署一个推理服务),但实际生产中 8192 卡不可能只跑一个任务。
4. 运维规格是真空地带。 SR-37 到 SR-41 全部未公开。升级、回滚、CVE 响应、主线兼容--这些在 128 机柜规模下不是锦上添花,是能不能持续运行的底线。
7.10 如果从这份规格书看灵衢的优先级
如果我是灵衢的产品负责人,拿到这份规格书,优先级排序:
P0(不做就不能用):
- SR-3(UBM 心跳收敛 <5s)--决定规模上限
- SR-37(三层版本兼容性自动检查)--决定能不能部署
- SR-40(CVE 窗口期可量化)--决定能不能过安全审计
P1(不做就不好用):
- SR-10(数据位置感知 API)--应用性能优化的前提
- SR-7(UMMU TLB 可观测)--延迟问题诊断的前提
- SR-19(RDMA 兼容性矩阵)--冷启动的前提
- SR-13(页迁移粒度可配置)--跨节点内存效率的前提
- SR-12/SR-24(多租户内存限额)--共享超节点的前提
P2(不做就限制天花板):
- SR-1(路由可编程)--训练/推理分时复用的前提
- SR-30(InferNex 硬件解耦)--走出昇腾生态的前提
- SR-35(异构算力统一调度)--openFuyao 定位兑现的前提
- SR-41(CXL 主线冲突检测)--长期技术债管理
P0 不解决,8192 卡的超节点只是演示环境。P1 不解决,生产环境运行三个月后会有一堆无法诊断的性能问题和安全工单。P2 不解决,灵衢永远是一个封闭的全栈系统,走不出华为生态圈。
素材来源:灵衢系统软件架构&部署公开课 PPT(牛涛)、openEuler UB Service Core 白皮书 2.0、APNet'21 "Huawei UB: Towards Compute-Native Networking" 技术报告(Bojie Li)、华为全联接大会 2025 徐直军主题演讲、灵衢互联社区(unifiedbus.com)规范文档、openEuler SIG-Long 异构融合 SIG 资料、KADC 2026 openFuyao 分论坛、openFuyao 官网(openfuyao.cn)、openFuyao v26.03 Release Notes、openFuyao 社区 2025.12-2026.2 运作报告、CLK 2025 技术演讲、comentropy 超节点产业链分析、ubs-core GitHub 仓库(atomgit.com)、Mooncake 项目文档