2026 年 6 月,中国 MaaS(Model as a Service,模型即服务)市场出现了一个看似矛盾的现象:几乎所有主流厂商都在降价,有的直接跌穿成本线,但 token 消耗量反而暴涨。
豆包(字节跳动)2024 年 5 月上线时日均处理 token 约 1200 亿。到 2026 年 3 月,这个数字突破了 120 万亿(来源:QuestMobile、鳌头财经报道)。两年约 1000 倍。与此同时,字节 2025 年算力相关开支超过 300 亿元,净利润同比下跌 70%。
2026 年端午节前后,DeepSeek、阿里 qwen、字节豆包、智谱 GLM、百度文心、讯飞星火几乎同步宣布新一轮降价或限时低价套餐。智谱 GLM-4-Flash 直接免费,qwen-plus 从 4 元降到 2 元,豆包 pro 部分模型降价超过 80%。
降价越狠,用得越多。经济学家管这叫杰文斯悖论(Jevons Paradox):当资源使用效率提高时,总消耗量不降反升,因为更低的单价释放了此前被价格压制的需求。MaaS 正在重演这一幕。理解这个悖论,是理解整个 MaaS 市场所有参与者的生存策略的钥匙。
一个关键问题随之浮现:5-7 元/百万 token 的保本线面前,MaaS 厂商如何生存?什么样的服务模式能扛住价格战?
一、保本线经济学
1.1 算账:1 亿 token 的真实成本
先拆一笔账。以一个 700 亿参数级别的大模型(如 DeepSeek V3、qwen-max)为例,部署在 H100 80GB 集群上,处理 1 亿个 token 的真实成本:
| 成本项 | 明细 | 元/亿 token |
|---|---|---|
| 算力(GPU 租赁) | H100 80GB 单卡约 3 元/h(2026 年 6 月内部成本价),8 卡推理节点处理约 50K token/s | 140-180 |
| 硬件折旧 | 自建集群按 3 年折旧,含 HBM(高带宽内存)、NVMe、网络 | 150-200 |
| 运维(电力+网络+人力) | 液冷 PUE(Power Usage Effectiveness,能效比)1.15、网络带宽、运维团队 | 100-150 |
| 销售与平台 | 客户获取、API 网关、监控计费 | 40-60 |
| 合计 | 430-590 |
换算成每百万 token:4.3-5.9 元。加上品牌溢价、研发分摊、安全合规,保守估计保本线在 5-7 元/百万 token。
这个数字的前提条件是:自建集群、70-100B 参数模型、连续批处理利用率 70% 以上。如果用云上 GPU 按需租用,成本会再涨 30-50%。
关键变量有几个:输入输出比(输出 token 消耗的计算量是输入的 3-5 倍)、KV Cache 命中率(缓存命中则无需重复 Prefill)、模型规模(MoE 即 Mixture of Experts,混合专家架构的激活参数远小于总参数)。这些变量是 MaaS 成本优化的核心战场,后文会展开。
1.2 六月定价分布
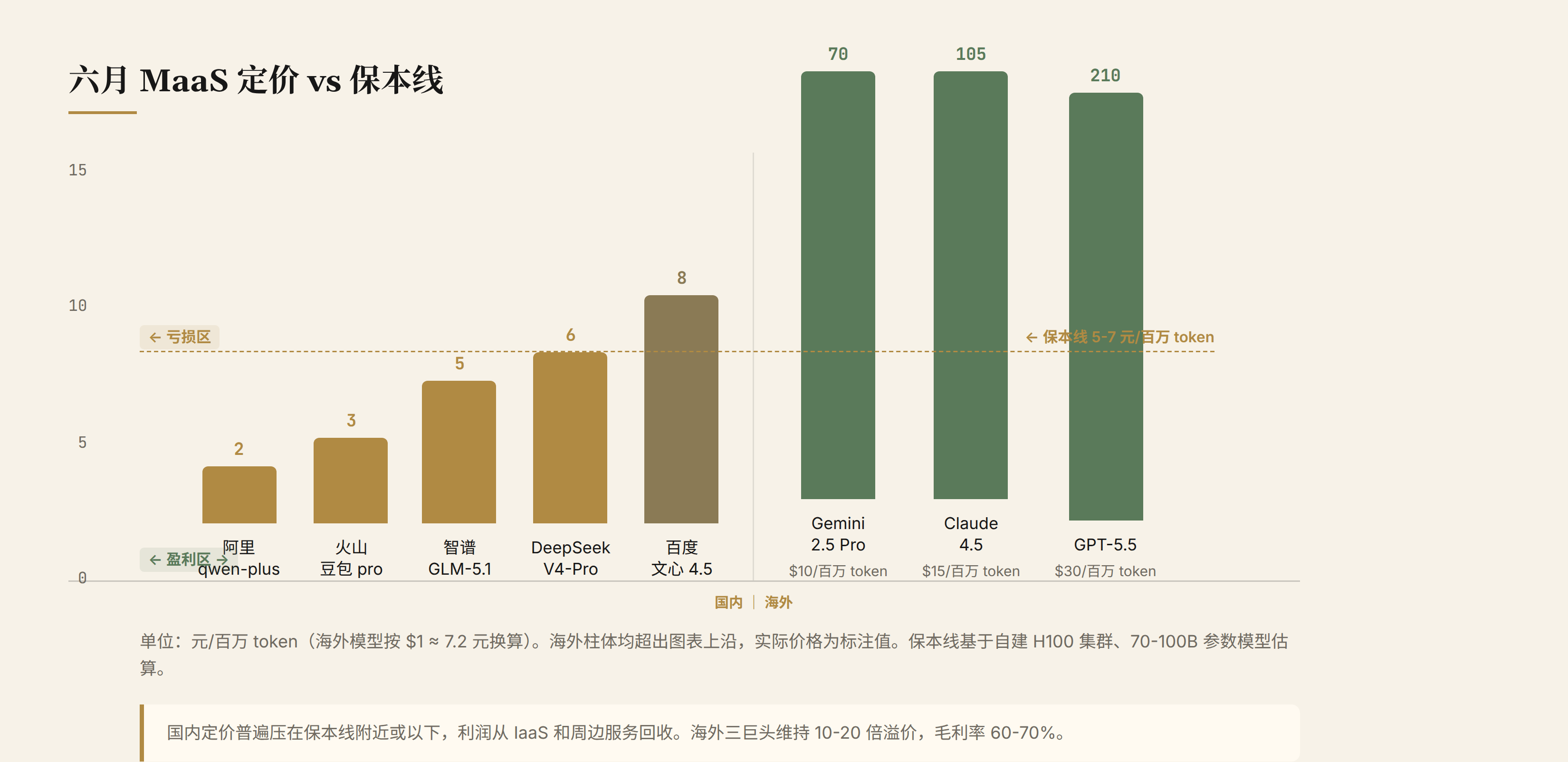
2026 年 6 月主流模型的定价分布:
| 模型 | 定价(元/百万 token) | 与保本线关系 |
|---|---|---|
| 阿里 qwen-plus | 2 | 远低于保本线 |
| 火山豆包 pro | 2-4 | 低于保本线 |
| 智谱 GLM-5.1 | 5 | 接近保本线 |
| DeepSeek V4-Pro | 6 | 贴保本线 |
| 百度文心 4.5 | 8 | 略高于保本线 |
| OpenAI GPT-5.5 | ~210($30) | 远高于保本线 |
| Anthropic Claude 4.5 | ~105($15) | 远高于保本线 |
| Google Gemini 2.5 Pro | ~70($10) | 远高于保本线 |
国内定价普遍压在保本线附近或以下,海外三巨头维持 10-20 倍溢价。
这组数据的直接含义:国内 MaaS 如果只靠 token 差价赚钱,绝大部分厂商是亏损的。qwen-plus 2 元/百万 token 的定价,距离保本线差 3-5 元,意味着阿里每处理 1 亿 token 亏 300-500 元。
但阿里不会真的亏。原因在于 MaaS 的收入结构远不只是 token 差价。IaaS 云服务器、数据库、数据湖、安全产品、企业定制服务,这些才是真正的利润来源。qwen-plus 的低价是流量入口,把开发者拉进阿里云生态,再通过 IaaS 变现。
1.3 Token 末日的数学
理解 MaaS 商业逻辑,需要拆解 token 消耗的乘数效应。
一个用户直接对话场景:输入 1000 token,输出 500 token,单次消耗 1500 token。
一个 AI 智能体(Agent)场景:用户发一条指令,Agent 拆解为 3-5 个子任务,每个子任务需要 1-3 轮工具调用,每轮调用平均 2000-5000 token。单条指令的典型消耗在 2 万到 5 万 token 之间,极端情况下可超 7 万。比直接对话高 10-30 倍。
豆包的 120 万亿日 token,大量来自字节系产品(抖音、飞书、今日头条)的 AI 功能调用。这些调用的 token 消耗量巨大,但单 token 对字节的商业价值也很高:AI 摘要提升了内容消费效率,AI 搜索提升了广告匹配精度。
杰文斯悖论之所以成立,是因为 AI 的边际效用不是线性下降的。每多处理一批 token,就多一个可以被智能体完成的任务,多一个可以被优化的业务流程。需求的天花板远没有触及。正因如此,聚合路由和平台模式才有了存在的基础:总需求在膨胀,但单价在下降,碎片化的调用需要中间层来消化。
二、四种服务模式
理解 MaaS 市场,关键不是看谁降价最狠,而是看不同的服务模式如何共存。目前市场上有四种清晰可辨的模式。
2.1 直营型
典型玩家:DeepSeek、字节豆包、阿里 qwen、OpenAI、Anthropic。
核心特征是自有模型、自有品牌、直接触达终端用户或开发者。定价权完全掌握在自己手里,模型迭代的节奏和方向由内部决定。
DeepSeek 是直营型里最特殊的一个。它的策略是用工程优化替代规模摊薄:通过 MoE 动态路由、注意力稀疏化、PD 分离、INT4 量化等自研技术栈,把单 token 成本从行业基线的 $0.12 降到约 $0.005(来源:DeepSeek V3 技术报告,降幅 96%)。这使得 DeepSeek 能在 6 元/百万 token 的价位上接近保本线,同时维持模型质量。DeepSeek 不需要云生态来补贴亏损,但它缺乏分发渠道,开发者需要主动去找 DeepSeek API,而不是被云平台裹挟进来。
OpenAI 和 Anthropic 是海外直营型的代表,走的是完全相反的路:高定价维持 60-70% 的毛利,靠模型效果和品牌溢价赚钱。GPT-5.5 定价 $30/百万 token,是 DeepSeek 的 35 倍。这个价差能维持多久,取决于模型效果的差距能维持多久。
2.2 云生态型
典型玩家:火山引擎(字节)、阿里云百炼、百度智能云、华为云 MaaS。
这是中国 MaaS 市场份额最大的模式。IDC 2025 年数据:火山引擎占 49.5%,阿里云 28%,百度 10%。三者合计 87.5%。
云生态型的核心逻辑是"总包":不只卖 token,而是卖一整套 AI 基础设施,包括算力、存储、数据库、模型服务、数据治理、安全合规、企业定制。MaaS 定价可以低于保本线,因为利润从 IaaS 和周边服务回收。
这种模式的优势在于生态粘性。一个企业把 AI 模型部署在火山引擎上,它的数据、工作流、监控体系都绑定了火山引擎,迁移成本极高。劣势是 MaaS 与 IaaS 的内部左右互搏:MaaS 降价越多,IaaS 的 GPU 消耗越大,但 MaaS 本身亏得也越多,需要 IaaS 利润来填。
华为云 MaaS 是一个值得关注的变体。它走"模型中立"路线,不只用盘古模型,还集成 DeepSeek、GLM、qwen、Llama 等第三方模型。2026 年 4 月出海东南亚 9 国,同时支持盘古和 DeepSeek V4、GLM-5.1 等第三方模型。华为的筹码是昇腾芯片加 CloudMatrix 超节点架构,用自有硬件绑定模型服务,跟 NVIDIA 生态做区隔。在政企市场,华为的合规能力和私有化部署经验是额外的护城河,这不是纯技术维度能衡量的。
2.3 聚合路由型
典型玩家:OpenRouter、硅基流动(SiliconFlow)、302.AI、CatRouter、诗云 API。
核心特征是模型中立、统一 API、智能路由。不拥有模型,而是做模型之间的"调度器"。
OpenRouter 是这个模式的标杆案例。2026 年 5 月完成 B 轮融资 1.13 亿美元(CapitalG 领投,NVentures 跟投),估值 13 亿美元(半年翻倍)。年化收入约 5000 万美元,半年涨 5 倍。周处理 25 万亿 token,月度约 100 万亿,用户超 800 万,抽佣约 5.5%(来源:OpenRouter B 轮融资公告,2026 年 5 月)。
硅基流动是中国版的聚合路由型。2026 年 6 月完成 20 亿元+融资,日 token 处理量达万亿级别,营收同比增长 10 倍。它同时是 OpenRouter 上中国模型的通道(中国模型占 OpenRouter 周调用量的 41.3%)和国内开发者的模型聚合入口。
聚合型的核心价值来自四个能力:多模型 failover(单模型宕机自动切换)、智能路由(按任务类型、成本、性能自动选最优模型)、跨供应商计费对账(企业一张发票管所有模型)、跨境通道(中国模型出海、海外模型进中国)。
风险同样清晰。上游模型厂在推行"去中间层"策略,OpenAI 和 Anthropic 直接给企业大客户签约,绕过聚合层。模型厂自建聚合(Anthropic Console、Google Vertex AI Model Garden)也在蚕食聚合型的生态位。如果模型效果差距缩小,"按效果路由"的价值就会下降,聚合型只剩"按价格路由"这层薄利。但杰文斯悖论在这里提供了一个反向支撑:总需求膨胀速度远快于效果收敛速度,碎片化的调用场景(Agent 工作流、多模型协作)反而更需要路由层来消化复杂性。
2.4 平台型
典型玩家:Hugging Face、Replicate、Cloudflare Workers AI、Dify。
核心特征是开发者生态驱动。Hugging Face 不只提供模型推理,更是一个模型仓库、数据集平台和社区。开发者可以自选模型、自调参数、自行部署。Cloudflare Workers AI 把推理直接嵌在边缘网络里,延迟低到极致。
平台型的商业化路径最窄。Hugging Face 靠企业版订阅和推理托管收费,但大量开发者只使用免费层。Replicate 按 token 计费,但单价高于直营型。Dify 定位在 Agent 开发平台,通过工作流编排和模型路由收费,但规模远小于聚合型。
平台型的长期价值在于长尾覆盖。当模型数量从几十个膨胀到几百个,企业不可能和每家模型厂逐一对接。平台型在这个位置提供了"逛模型超市"的体验。此外,开源模型(Llama、Qwen 开源版、DeepSeek 开源权重)的快速发展正在扩大平台型的价值:越来越多的企业选择在 Hugging Face 或 Dify 上自建推理,绕过 MaaS 直接使用开源权重。这对直营型和云生态型的中低端市场构成了长期侵蚀。
2.5 四种模式的竞合关系

这四种模式不是彼此替代的,而是嵌套的。一个典型企业的 AI 技术栈可能是这样的:用阿里云的 IaaS 做算力底座(云生态型),通过硅基流动统一 API 接入多个模型(聚合路由型),在 Dify 上编排 Agent 工作流(平台型),同时对核心任务直连 DeepSeek 或 GPT-5.5(直营型)。
谁吃掉谁?短期不会。每种模式在各自的位置上提供了不可替代的价值:算力、路由、编排、模型。但利润分配的方向是明确的:越靠近算力底层(云生态型),利润越厚;越靠近模型层(直营型),定价权越强;中间层(聚合型、平台型)活得最辛苦。
还有一个容易被忽略的变量:大企业自建推理。银行、保险、政务等对数据安全和合规有刚性要求的行业,倾向于自建 GPU 集群、部署开源模型或购买私有化部署服务,而不是使用公共 MaaS。这直接限制了 MaaS 市场的潜在规模。IDC 估计,中国企业 AI 推理支出中,自建和私有化部署占比超过 40%,且在政务和金融领域超过 60%。华为云在这个层面有天然优势,因为它同时卖芯片和私有化方案。
三、三条路径:谁在怎么赢
MaaS 市场的竞争不只是价格战,而是三条路径的赛跑。

DeepSeek 走技术硬核路线。自研全栈推理引擎,把 MoE 动态路由、注意力稀疏化、PD 分离、INT4 量化全部做到极致,单 token 成本从行业基线 $0.12 打到约 $0.005,降幅 96%(来源:DeepSeek V3 技术报告)。用工程优势抵消规模劣势,靠单 token 成本低维持定价竞争力。但它的天花板在分发渠道:没有云生态,开发者需要主动来找它。
火山引擎走规模加生态路线。十万卡级别的集群规模把单位 GPU 成本压到行业最低,叠加字节系产品(抖音、飞书、今日头条)的内部调用量构建数据飞轮,再通过 IaaS 粘性锁定企业客户。MaaS 定价低到可以白送,只要 IaaS 和周边服务赚回来。它还有一张牌:订阅与按量混合计费。Coding Plan 从 40 元/月降到 9.9 元/月(首两月 2.5 折),经典的 SaaS 漏斗逻辑。火山的天花板在工程深度,核心推理引擎依赖开源的 vLLM/SGLang。
OpenRouter 走轻资产聚合路线。不持有算力、不做推理优化,专注在统一 API、智能路由、跨厂计费和跨境通道。800 万用户、月处理 100 万亿 token,抽佣 5.5% 贡献了超过 5000 万美元的年化收入。它的天花板在上游模型厂的"去中间层"策略。
| 维度 | DeepSeek | 火山引擎 | OpenRouter |
|---|---|---|---|
| 核心优势 | 自研推理引擎,单 token 成本行业最低 | 十万卡规模 + 字节生态绑定 | 轻资产,800 万用户,统一 API |
| 商务模式 | 纯 token 定价 | 订阅 + 按量 + 生态绑定 + IaaS 变现 | 5.5% 抽佣 + 跨境通道 |
| 天花板 | 缺分发渠道 | 依赖开源推理引擎 | 上游模型厂自建聚合 |
技术优化的细节(六个杠杆如何叠加实现 96% 的成本下降)是另一篇文章的容量。这里只需记住一个判断:杰文斯悖论意味着技术优化把成本压低了 96%,但总 token 消耗量涨了上千倍。整个行业的算力支出不是减少了,而是增加了。字节 2025 年 300 亿+ 的算力账就是证据。
四、中国 MaaS 市场格局

回顾中国 MaaS 市场过去两年的演变。
2024 年初,格局分散,百度、阿里、字节、华为各有阵地,没有明显的头部。到 2025 年底,火山引擎凭借豆包的爆发式增长和字节系产品的内部调用量,以 49.5% 的份额坐稳第一。阿里依靠通义系列和阿里云 IaaS 的庞大客户基础占 28%,百度占 10%。
2026 年上半年的主要变量有三个。
第一,DeepSeek V4 的发布。DeepSeek 在技术圈建立了"性价比之王"的口碑,V4-Pro 在多个主流评测(MMLU、HumanEval、Chatbot Arena)中与海外旗舰模型的综合差距收窄到 5-10%。但 DeepSeek 不做云生态,直接收入份额有限,更多是通过硅基流动等聚合平台间接渗透市场。它的真正影响在于锚定了行业的价格底线:只要有 DeepSeek 在,其他厂商就很难把定价拉高。
第二,硅基流动的崛起。以聚合路由切入,同时拿下国内开发者和 OpenRouter 通道,日 token 处理量达万亿级别。2026 年 6 月完成 20 亿元+融资,营收同比增长 10 倍。硅基流动的商业模式能成立,恰恰是杰文斯悖论的间接验证:总需求膨胀到一定规模后,碎片化调用的路由需求本身就是一门大生意。这个增速意味着它可能在 2027 年挑战百度的第三位置。但风险也很清晰:一旦火山或阿里在聚合路由上发力,硅基流动的生态位会被直接挤压。
第三,华为云 MaaS 出海。2026 年 4 月在新加坡发布,覆盖东南亚 9 国,集成盘古、GLM-5.1、DeepSeek 等多源模型。华为的策略是用昇腾芯片加 CloudMatrix 超节点做差异化,跟 NVIDIA 生态做区隔。为什么选东南亚而不是中东或拉美?因为东南亚的 AI 需求增长最快(印尼、越南的 AI 采用率年增速超过 200%),且对中国芯片的监管阻力最小。在东南亚和"一带一路"市场,华为的政企关系优势和合规能力可能比模型效果更有说服力。
还有一个结构性变量不容忽视:监管。中国的模型备案制、内容审核要求、数据出境限制,构成了 MaaS 市场实打实的准入门槛。火山引擎在消费端份额最大,但华为云在政企市场的优势很大程度上来自合规能力,而不仅仅是硬件。百度的份额虽然下滑,但它在搜索和教育领域的合规积累让它不会轻易出局。监管壁垒让中国 MaaS 市场的竞争格局不会简单演化为"赢家通吃"。
五、风险与展望
近期压力(6-12 个月)
Token 消耗增速快于成本下降速度。杰文斯悖论意味着降价越多、烧钱越狠。字节 2025 年算力开支 300 亿+、净利润 -70%,其他厂商的情况类似。如果融资环境收紧或母公司战略调整,MaaS 部门可能面临预算压缩。但这里有一个反直觉的缓冲:杰文斯悖论也意味着 token 消耗量暴涨带来的总盘子在扩大,即使单 token 亏损,总营收仍在增长。只要现金流能转,MaaS 就能继续烧。
模型同质化是更现实的压力。当 Claude、GPT、Gemini、DeepSeek、qwen 之间的效果差距缩小到 5-10%,"用最好的模型"不再是刚需,"用最便宜的模型"成为默认选项。这对直营型里成本控制好的玩家(DeepSeek)是利好,对聚合型是中性(路由价值从效果路由转向价格路由),对高定价的海外厂商是真正的威胁。
开源模型的角色在这个阶段变得关键。Llama 4、Qwen 开源版、DeepSeek 开源权重让任何人都能自建推理。Hugging Face 上的开源模型下载量在 2026 年 Q1 同比增长 340%。这对 MaaS 的中低端市场构成直接侵蚀:如果开发者可以免费跑一个效果达到旗舰模型 85% 的开源模型,为什么要付 API 费?这不是远期威胁,而是正在发生的事实。
中期分化(12-24 个月)
分层定价会从"可选"变成"标配"。输入/输出/缓存的三档定价将覆盖主流 MaaS 服务,高精度推理(如数学、代码)和低精度推理(如闲聊、摘要)的价差会拉大到 10 倍以上。这意味着 MaaS 的收入结构会更复杂,也更健康。
聚合层可能出现分化。顶层 2-3 家吃掉 70% 以上的路由流量(OpenRouter 和硅基流动最有希望),垂直领域聚合(代码、视频、医疗、金融)占 20%,剩下的被云厂和模型厂自建聚合吞掉。底层聚合型的生存空间会持续收窄。
远期变量(24 个月以上)
NVIDIA 收购 Groq 是一个信号。Groq 的 LPU(Language Processing Unit)用确定性执行替代 GPU 的动态调度,在延迟敏感型推理场景有独特优势。NVIDIA 把 LPU 技术整合进 CUDA 生态后,PD 分离的硬件基础会更成熟,推理成本可能再降一个台阶。如果推理硬件从 GPU 切换到专用加速器,整个 MaaS 的成本结构会被重写。
新推理范式可能在文本领域重现。Diffusion 模型在图像生成领域已经展示了自回归的替代方案。Google 的 DiffusionGemma 在文本生成上的实验表明,扩散范式在某些场景下可以实现更高的吞吐量。如果这个方向成熟,推理引擎的技术栈需要重构。
国产芯片的临界点也在逼近。华为昇腾 950 已经在华为云 MaaS 上商用,阿里含光在做推理优化。如果国产芯片在 2027-2028 年突破 H100 的性价比拐点,中国 MaaS 的成本结构会被根本性改写。到那时,杰文斯悖论的下一轮循环又会开始:成本更低,需求更大,总支出继续涨。
声明: 本文基于公开信息撰写,综合参考了 IDC《中国企业级 MaaS 市场报告》(2025)、QuestMobile 豆包 token 数据报道(2026)、DeepSeek V3 技术报告、OpenRouter B 轮融资官方公告(2026 年 5 月)、百度百科 OpenRouter 词条、财联社/华尔街见闻硅基流动融资报道、LMSYS Chatbot Arena 评测数据,以及各厂商官网定价页面。不构成投资建议。文中数据截至 2026 年 6 月 16 日。