本文是「Token 分发时代」的姊妹篇,聚焦 MaaS 服务的技术优化栈。市场分析与商业解剖见主篇。
DeepSeek 把单 token 推理成本从行业基线 $0.12 降到约 $0.005,降幅 96%。这不是某项单一突破的功劳,而是六个独立技术杠杆叠加的结果。本文逐个拆解每个杠杆的原理、效果、代价,以及它们如何组合成一个完整的推理优化栈。
一、评价框架:效果、效率、体验
讨论 MaaS 技术优化之前,先明确评价维度。
效果(Effectiveness):模型对用户任务的完成度。这是硬门槛。当前旗舰模型的综合差距已经很小:根据 LMSYS Chatbot Arena(人类偏好对战的 ELO 评分)、MMLU(大规模多任务语言理解)、HumanEval(代码生成)等主流评测的综合判断,Claude 4.5、GPT-5.5、Gemini 2.5 Pro、DeepSeek V4 在通用任务上的综合差距已收窄到 5-10% 区间。但分维度看差异仍大:文本摘要差距可能只有 2-3%,数学推理和代码生成差距可达 10-15%,长上下文理解(LongBench、RULER)差距更分散。效果不再是区分胜负的唯一维度,但效果进前 20% 是入场券。
效率(Efficiency):单位成本的输出量。三个子指标:吞吐量(每秒处理多少 token)、首 token 延迟(TTFT,Time To First Token,用户等多久拿到第一个输出)、单 token 成本(每百万 token 花多少钱)。效率是当前 MaaS 竞争的主战场,也是本文的主题。
体验(Experience):API 稳定性(SLA、抖动率)、文档完整度、SDK 易用性、计费透明度、故障恢复速度(failover 时间)。这个维度经常被低估,但对开发者留存影响极大。OpenRouter 在统一 API 格式、实时模型状态面板、自动 failover 上的投入是它 800 万用户持续增长的关键。火山引擎的 Coding Plan 体验(IDE 插件集成、流式输出、长上下文窗口)也显著优于直接调原始 API。
三者的优先级是效果 > 效率 > 体验。效果进前 20% 是硬门槛,效率进前 5% 是主战场,体验持续优化是留存关键。
二、推理优化的六个杠杆
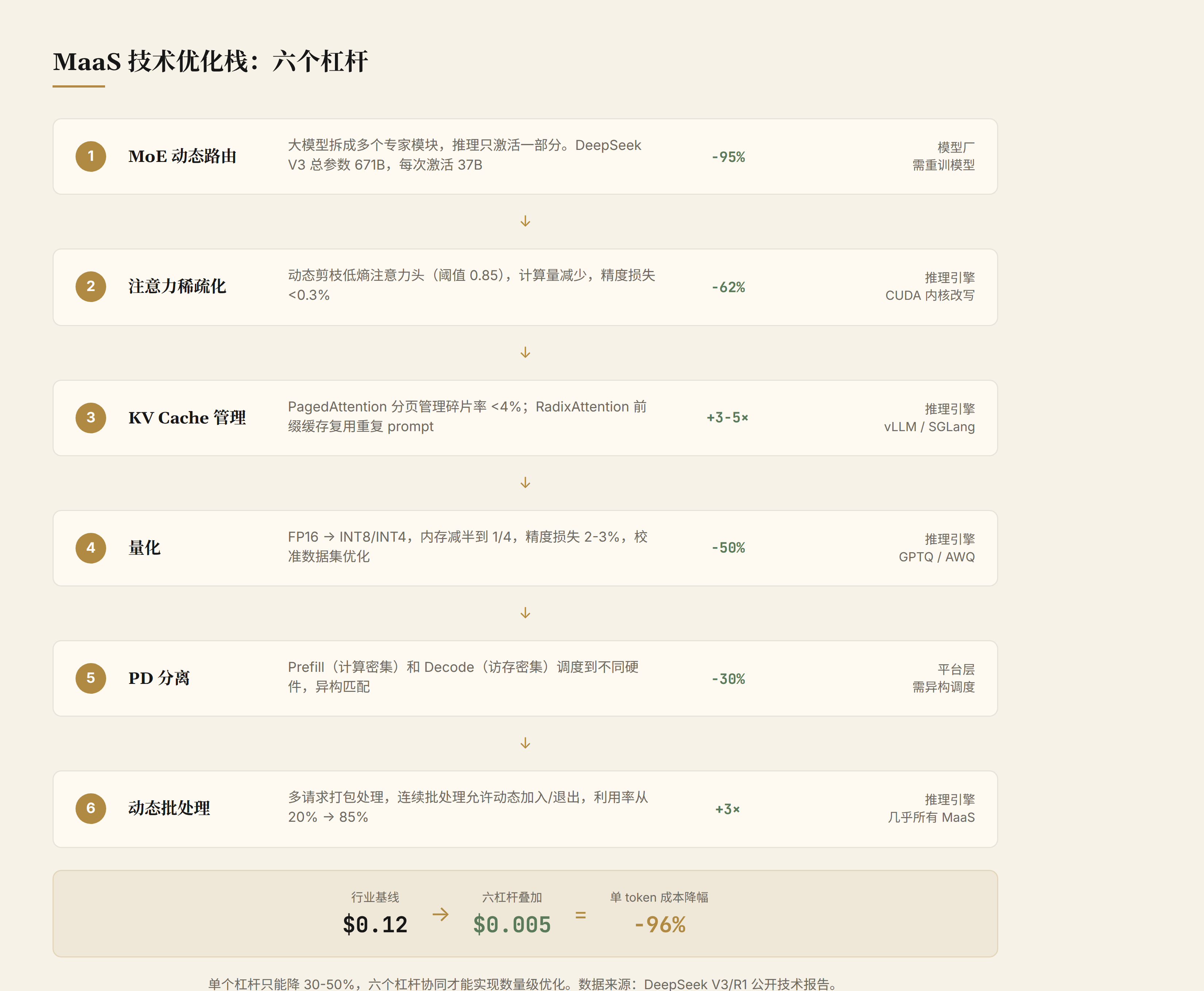
杠杆一:MoE 动态路由
原理。 MoE(Mixture of Experts,混合专家)是一种条件计算架构。传统密集模型(Dense Model)每次推理要跑完所有参数,而 MoE 把模型拆成多个"专家"子网络,由一个路由器(Router/Gating Network)根据当前输入动态选择激活哪几个专家。
DeepSeek V3 的架构是 256 个路由专家 + 1 个共享专家,总参数 671B(6700 亿)。每次推理只激活 8 个路由专家加 1 个共享专家,激活参数约 37B。计算量降到密集模型的 5.5%。从用户视角看,得到的是一个 671B 模型的知识容量,但计算成本只有 37B 模型的水平。
关键设计:共享专家。 DeepSeek V3 引入的共享专家(Shared Expert)是一个始终被激活的全量专家,负责处理通用语义理解。路由专家则负责专业化能力(代码、数学、多语言等)。这种设计解决了一个实际问题:纯路由 MoE 中,某些专家被频繁选中(热门专家),其他专家几乎不用(冷门专家),导致负载不均衡。共享专家吸收了通用计算,路由专家的负载更均匀。
关键设计:负载均衡损失。 MoE 训练时需要加一个辅助损失函数(Auxiliary Loss)来鼓励路由器均匀分配 token 给各专家。如果不加这个损失,路由器会坍缩到只选少数几个专家。DeepSeek V3 使用了一种无辅助损失的负载均衡策略(bias-based routing),通过动态调整路由偏置项来实现均衡,避免了辅助损失对主任务梯度的干扰。
效果。 相比同等总参数的密集模型,MoE 的推理计算量降到 5.5%。这相当于在同等硬件上把吞吐量提升约 18 倍。这是六个杠杆中效果最大的一个。
代价。 MoE 不能在已有密集模型上 retrofit。必须从预训练阶段就使用 MoE 架构,训练配置、数据配比、路由策略都需要专门设计。MoE 的训练也更具挑战性:专家间通信开销大(需要 All-to-All 通信),对网络拓扑要求高;训练稳定性更难控制(路由坍缩、专家死锁)。此外,MoE 模型的显存占用仍然是全量的(671B 参数全部需要加载到显存),只是计算量减少了。这意味着 MoE 推理需要大显存配置,是 HBM(高带宽内存)消耗大户。
谁在用。 DeepSeek V3/V4(256+1 专家)、Mixtral 8x22B(8 专家)、Qwen-MoE 系列、Switch Transformer(Google,最早的大规模 MoE 之一)。GPT-4 据报道也使用了 MoE 架构(未官方确认)。
杠杆二:注意力稀疏化
原理。 Transformer 的自注意力机制(Self-Attention)让序列中每个 token 都和所有其他 token 计算注意力权重。序列长度为 N 时,注意力矩阵大小是 N×N,计算复杂度随序列长度二次增长。对于 128K 上下文的模型,这意味着每次推理要计算 128,000 × 128,000 = 164 亿个注意力对。
稀疏化的核心思想是:并非所有注意力对都有意义。通过分析注意力权重的分布,可以发现大部分权重集中在少数几个 token 上(局部注意力),长距离注意力权重很小但覆盖面大。如果能在推理时动态跳过低贡献的注意力计算,就能大幅减少计算量。
方法。 DeepSpeed 和 vLLM 都实现了不同形式的注意力稀疏化。一种典型方法是熵基剪枝(Entropy-based Pruning):计算每个注意力头的注意力分布熵,熵低(分布集中)的头保留,熵高(分布均匀、信息量低)的头关闭。不同实现使用的阈值有差异,业界经验值在 0.8-0.9 区间(归一化熵)。
另一种方法是局部-全局分离(Local-Global Separation):把注意力拆成局部窗口(只看相邻 1024 个 token)和全局采样(从全序列稀疏采样若干 token),跳过大部分中距离注意力。Longformer、Big Bird 等模型采用了这种策略。
效果。 据工程实践经验值,注意力稀疏化可将注意力计算量减少约 60%,整体推理速度提升 30-40%。精度损失约 0.3%(在 MMLU 等评测上),对于大多数应用场景可接受。
代价。 需要对推理引擎做 CUDA 内核级别的改写。标准 FlashAttention 内核不支持稀疏模式,需要自定义 Triton 或 CUDA kernel。目前这个领域还在快速演进,没有像 PagedAttention 那样的成熟标准方案。稀疏化策略对不同任务的效果差异也较大:长文本摘要效果好,短对话几乎无效。
谁在用。 DeepSeek 自研推理引擎内置了注意力稀疏化。vLLM 和 SGLang 在实验分支中有不同实现。商业 MaaS 服务大多不公开是否使用此技术,但从性能数据推测,头部厂商的推理引擎都有类似优化。
杠杆三:KV Cache 内存管理
问题。 KV Cache 是大模型推理中最吃内存的组件。在自回归生成中,每个 token 需要存储一对 Key-Value 向量用于后续 token 的注意力计算。以 70B 模型、80 层、隐藏维度 8192 为例,单个 token 的 KV Cache 约 2.6MB(FP16)。一个 4K 上下文的请求需要约 10GB,一个 128K 长上下文请求需要约 340GB。
传统的内存分配方式(为每个请求预分配连续的最大长度空间)有两个严重问题。一是内部碎片:请求实际使用的长度通常远小于最大长度,预分配空间大量浪费。二是外部碎片:请求频繁创建和释放不同大小的缓存块,导致内存空间破碎,新请求可能因为找不到足够大的连续块而等待,即使总剩余内存充足。
PagedAttention(vLLM)。 借鉴操作系统的虚拟内存分页机制,把 KV Cache 切分成固定大小的"页"(block),每页存放固定数量 token 的 KV 向量。请求的 KV Cache 不需要物理连续,通过页表映射到分散的物理块。碎片率从 60%+ 降到 4% 以下。
更关键的是,PagedAttention 启用了灵活的内存共享。同一 prompt 的不同请求(如 beam search 的多条候选)可以共享相同的 KV Cache 页,只在输出分叉时复制新页。在并行采样(一次生成多个回答)场景下,内存占用可减少 55%。
RadixAttention(SGLang)。 在分页管理的基础上,引入了基数树(Radix Tree)结构来管理和复用前缀。多个请求如果共享相同的前缀(如系统 prompt、few-shot 示例、工具描述),它们的 KV Cache 在基数树上共享同一路径,只在内容分叉时创建新分支。配合 LRU(Least Recently Used)缓存淘汰策略,高频前缀的缓存命中率可达 80%+。
效果。 KV Cache 管理是所有六个杠杆中工程成熟度最高的。PagedAttention 让 vLLM 的吞吐量比 HuggingFace Transformers 提升了 3-5 倍(在不同负载模式下)。RadixAttention 在有大量前缀复用的场景(如 Agent 工作流)下还能再提升 2-3 倍。
代价。 页表管理有约 4% 的额外 CPU 开销。基数树的维护和查询在高并发场景下有延迟开销。但这些代价远小于收益。
谁在用。 vLLM(PagedAttention)、SGLang(RadixAttention)、TensorRT-LLM(NVIDIA 自有 KV Cache 管理方案)、DeepSeek 自研引擎。火山引擎和阿里云百炼的推理服务底层都基于 vLLM 或其衍生分支。
杠杆四:量化
原理。 大模型的权重默认使用 FP16(16 位浮点数)存储。量化(Quantization)把权重从高精度压缩到低精度:INT8(8 位整数)或 INT4(4 位整数)。70B 模型在 FP16 下需要约 140GB 显存,INT8 需要约 70GB,INT4 只需要约 35GB。显存占用减半到 1/4,推理速度也相应提升(GPU 的 INT8/INT4 计算吞吐量远高于 FP16)。
主流方案对比。
| 方案 | 原理 | 优势 | 劣势 |
|---|---|---|---|
| GPTQ | 基于二阶信息的逐层量化 | 精度保持好,支持 group-wise 量化 | 量化过程需要校准数据集,耗时较长 |
| AWQ | 激活感知的权重量化 | 保护对激活值敏感的权重通道,精度好 | 需要少量校准数据 |
| SmoothQuant | 将激活值的离群点"平滑"到权重 | INT8 精度极佳,支持 W8A8(权重和激活都量化) | INT4 效果一般 |
| GGUF (llama.cpp) | 面向 CPU/边缘的量化格式 | 部署门槛低,CPU 可跑 | GPU 推理速度不如其他方案 |
DeepSeek 的做法。 DeepSeek V3 在发布时直接提供 INT4 量化版本。原始 FP16 权重约 1.3TB(671B 参数),INT4 量化后约 340GB。这是让 671B 模型能在合理硬件配置上运行的关键。DeepSeek 使用的量化方案结合了 group-wise 量化(每 128 个权重一组独立量化)和 FP8 激活(激活值用 8 位浮点而非整数),在精度和速度之间取得了好的平衡。
效果。 INT8 量化的精度损失通常在 1-2%(MMLU 基准),INT4 损失 2-3%。推理速度提升方面,INT8 比 FP16 快约 2 倍,INT4 比 FP16 快约 3-4 倍(受限于 GPU 的低精度计算单元数量)。
代价。 量化是不可逆的有损压缩。精度损失虽然不大,但在极端场景(长链推理、代码生成边界条件、数学竞赛题)可能放大。量化后的模型也需要重新做评测验证,不能假设精度不变。
杠杆五:PD 分离(Prefill-Decode Disaggregation)
原理。 大模型推理分为两个阶段,两者的计算特征截然不同:
Prefill 阶段:理解输入 prompt,做大量矩阵乘法,生成 KV Cache。这是计算密集型(compute-bound),GPU 的计算单元满载,但访存利用率低。输入 4000 token,Prefill 可能在 200ms 内完成。
Decode 阶段:逐 token 生成输出,每生成一个 token 都要读取全部 KV Cache 做注意力计算。这是访存密集型(memory-bound),GPU 的计算单元大量空闲,但 HBM 带宽满载。输出 500 token,Decode 可能要 5-10 秒。
传统做法是把 Prefill 和 Decode 放在同一批 GPU 上。问题是两个阶段的资源利用互补但无法同时满足:Prefill 期间访存闲置,Decode 期间计算闲置。GPU 一半时间在等待。
PD 分离把两个阶段调度到不同的硬件池上。Prefill 池用计算能力强的 GPU(如 H200,FP16 算力高),Decode 汅用访存带宽大的 GPU(如 H100 NVL,HBM 带宽大),甚至可以用成本更低的硬件(如 L40S 甚至 CPU/FPGA)处理低优先级 Decode 请求。两个池独立扩缩容,各自保持高利用率。
工程挑战。 PD 分离引入了跨节点通信开销:Prefill 生成的 KV Cache 需要传输到 Decode 节点。一个 4K 上下文请求的 KV Cache 约 10GB,如果用 RDMA/InfiniBand 传输,延迟约 5-10ms;如果用以太网,可能 50-100ms。这个延迟是否可接受取决于场景:对 TTFT 敏感型场景(实时对话)影响大,对吞吐优先型场景(批量处理)可忽略。
调度系统也比统一调度复杂得多。需要预测 Prefill 完成时间、评估 Decode 池负载、决定请求路由。Mooncake(月之暗面/Kimi)、Splitwise(Microsoft Research)、DistServe 等系统都是在这个方向上的探索。
效果。 资源利用率提升 30-40%。在 Kimi 的实践中,PD 分离让长上下文请求(128K+)的 TTFT 降低 60%,同时整体吞吐量提升 40%。
代价。 需要异构硬件池和高带宽网络互联。调度系统的开发维护成本高。跨节点 KV Cache 传输对网络延迟敏感。
谁在用。 DeepSeek(自研调度系统)、Kimi/Moonshot(Mooncake 系统)、火山引擎(部分 PD 分离)、阿里云(PD 分离试验中)。
杠杆六:动态批处理(Continuous Batching)
原理。 GPU 的计算效率高度依赖批大小(Batch Size)。批大小为 1 时,GPU 利用率可能只有 20-30%;批大小为 32 时,利用率可达 70-85%。MaaS 服务需要同时处理大量用户的请求,把这些请求打包成一个 batch 同时计算,是提升效率的基础手段。
传统静态批处理(Static Batching)把请求攒到一批再一起计算。问题是:同一批中最先完成的请求要等最慢的请求算完才能返回结果,响应延迟被最慢请求拖累。
连续批处理(Continuous Batching,也叫 In-flight Batching 或 Iteration-level Batching)解决了这个问题。它在 token 级别做调度:每个 Decode 迭代步检查是否有新请求可以加入当前 batch、是否有已完成请求可以退出。请求不需要等一批齐才开始,也不用等其他请求完成才返回。
效果。 GPU 利用率从 20-30%(单请求)提升到 70-85%(多请求连续批处理)。吞吐量提升 3-4 倍。这是所有六个杠杆中工程代价最小的:不需要改模型、不需要异构硬件,只需要推理引擎支持 token 级调度。
代价。 几乎没有。连续批处理是现代推理引擎的标配功能。唯一需要注意的是 QoS(服务质量):高优先级请求和低优先级请求混在同一个 batch 中时,需要调度策略保证高优先级请求的延迟不受低优先级请求影响。
谁在用。 所有现代推理引擎都支持:vLLM、SGLang、TensorRT-LLM、DeepSeek 自研引擎。
三、推理引擎对比
六个杠杆不是各自独立运行的,需要被集成到一个推理引擎(Inference Engine)中协调工作。当前主流的推理引擎:
| 引擎 | 开发方 | 特点 | 主要用户 |
|---|---|---|---|
| vLLM | UC Berkeley / 社区 | PagedAttention 原生支持,生态最广,易部署 | 硅基流动、302.AI、大量中小 MaaS |
| SGLang | LMSYS / 社区 | RadixAttention + 结构化生成,Agent 场景强 | DeepSeek API(部分)、研究机构 |
| TensorRT-LLM | NVIDIA | 与 CUDA 深度优化,NVIDIA 硬件上最快 | 大型企业、云厂商(百度、腾讯) |
| DeepSeek 推理引擎 | DeepSeek | 自研全栈,六个杠杆全部内置,行业标杆 | DeepSeek 自有服务 |
| Mooncake | Moonshot AI | PD 分离专精,长上下文优化 | Kimi |
| LMDeploy | OpenMMLab/上海 AI Lab | 国产开源,昇腾兼容 | 部分昇腾生态用户 |
一个值得注意的趋势是推理引擎的"趋同进化"。vLLM 正在加入 SGLang 的前缀缓存能力,SGLang 也在借鉴 vLLM 的连续批处理实现。TensorRT-LLM 在 NVIDIA GPU 上有硬件级优势(直接调用 CUTLASS 内核),但跨硬件兼容性差。DeepSeek 的自研引擎在效果上领先,但不开源,其他厂商无法直接使用。
引擎选择对 MaaS 服务的影响巨大。火山引擎的核心推理引擎依赖 vLLM 和 SGLang,工程深度受限于开源社区的迭代速度。DeepSeek 自研引擎是它能做到 $0.005/token 的关键护城河。硅基流动需要在多个引擎之间适配(不同模型可能需要不同引擎),工程复杂度很高。
四、叠加效果与边际收益
| 杠杆 | 单独成本降幅 | 叠加后贡献 | 成熟度 |
|---|---|---|---|
| MoE 动态路由 | ~95% (计算量) | 最大单项贡献 | 生产成熟 |
| 注意力稀疏化 | ~60% (注意力计算) | 中等,依赖场景 | 实验到生产 |
| KV Cache 管理 | 吞吐 3-5x | 大,工程必做 | 生产标配 |
| 量化 | 内存 50-75% | 大,降低硬件门槛 | 生产成熟 |
| PD 分离 | 利用率 +30-40% | 中等,需异构硬件 | 头部厂商在用 |
| 动态批处理 | 利用率 +50-60% | 基础,必做 | 生产标配 |
六个杠杆叠加:DeepSeek V3/R1 系列单 token 成本从行业基线 $0.12 降至约 $0.005,降幅 96%(来源:DeepSeek V3 技术报告)。如果只做一个杠杆(比如只做量化),成本只能降 30-50%。两个杠杆叠加(量化 + KV Cache 管理)能降 70-80%。真正突破性的成本下降需要四个以上杠杆协同。
但杠杆之间有交互效应,不是简单乘法。MoE 减少了计算量,但增加了显存需求(全部专家参数都要加载)。量化减少了显存,可能影响 PD 分离的 KV Cache 传输策略。注意力稀疏化在不同 MoE 专家上的效果不同。这些交互意味着推理引擎需要做全局联合优化,而不是逐个杠杆独立调参。
杰文斯悖论在这里再次生效。技术优化把成本压低了 96%,但总 token 消耗量涨了上千倍。整个行业的算力支出不是减少了,而是增加了。字节 2025 年 300 亿+ 的算力账就是证据。这意味着推理优化的天花板不是"成本降到零",而是"每次优化释放的新需求空间又被杰文斯悖论吃掉,需要继续优化"。
五、前沿方向
推理优化仍在快速演进。几个值得关注的方向:
投机解码(Speculative Decoding)。 用一个小模型(draft model)快速生成几个候选 token,再用大模型(target model)并行验证。如果小模型的猜测正确,等于用小模型的成本生成了大模型的输出。Llama 3 和 DeepSeek 都在探索这个方向。实测吞吐量提升 2-3 倍,但需要找到与目标模型分布匹配的 draft model。
FP8 推理。 FP8(8 位浮点)介于 FP16 和 INT8 之间,精度损失极小但速度接近 INT8。NVIDIA H100/H200 原生支持 FP8 计算。TensorRT-LLM 和 vLLM 都在加入 FP8 支持。这可能成为下一代推理引擎的标准配置。
多级缓存(Multi-tier Caching)。 把 KV Cache 分层存储在 HBM、DRAM、SSD 上,用 LRU 策略在层间迁移。对于超长上下文(128K-1M)场景,单 GPU 的 HBM 放不下完整 KV Cache,多级缓存让长上下文推理成为可能。Mooncake 系统在这个方向上做了深入探索。
编译器优化。 AI 编译器(如 TorchInductor、TensorRT、OpenAI Triton)可以把计算图做全局优化:算子融合(把多个小算子合成一个大 kernel)、内存复用、自动混合精度。推理引擎和编译器的深度集成是下一代优化的方向。DeepSeek 的自研引擎据报告大量使用 Triton 自定义 kernel,而不是依赖框架自带的 CUDA kernel。
端侧推理。 随着模型量化和小模型(7B-14B)能力提升,越来越多的推理可以在端侧(手机、PC、边缘设备)完成。Apple Neural Engine、高通 AI Engine、Intel AI PC 都在推动这个方向。端侧推理的延迟(<10ms)远优于云端(50-200ms),但模型能力受限。端云协同(简单任务端侧、复杂任务云端)是长期方向。
声明: 本文基于公开信息撰写,技术数据主要参考 DeepSeek V3 技术报告(arXiv:2412.19437)、vLLM 论文(PagedAttention, SIGGRAPH 2023)、SGLang 论文(RadixAttention, ICML 2024)、Mooncake 技术报告、Longformer/Big Bird 论文,以及各推理引擎的官方文档和 GitHub 仓库。成本数据为工程估算,实际数值因部署条件差异较大。不构成投资建议。文中数据截至 2026 年 6 月。