2026 年 2 月,Panduit 的光纤研发工程师 Jose M. Castro 在 IEEE 802.3 E4AI(Ethernet for AI)研讨会上做了一个不长的报告,标题叫 "Optical Shuffle Architectures for Large AI Networks"。听众不多,但里面有一个精准的数字:32768 GPU 集群中,Optical Shuffle 把收发器总数削减了约 33%,同时把 Spine 交换机从 256 台压回到 64 台——4 倍差距。
两个月后,AWS 公开了 RNG(Resilient Network Graphs),用随机图替代胖树,路由器总数减少 69%。RNG 动的是拓扑——直接拆掉层级结构。Castro 动的是光纤——在胖树的骨架里重新编排光线走的路。
这两件事一个改架构,一个改物理层,看似无关。但放在一起看,它们指向同一个结论:AI 集群的网络成本瓶颈不在交换芯片,在光纤和收发器。谁先在物理层找到突破口,谁就拿到了下一轮规模扩张的入场券。
这篇文章做三件事:拆解 Optical Shuffle 的技术原理和量化收益,分析它与 RNG 的互补和冲突,然后评估 MCF(多芯光纤)和 HCF(空芯光纤)这两条更远的光纤路线对 AI 网络意味着什么。
问题:收发器才是真成本中心
先看一组数字。
一个 8192 GPU 的 AI 集群,典型部署是 1024 个节点(每节点 8 GPU),128 台 Leaf 交换机,64 台 Spine 交换机。所有交换机端口数为 512。这个规模用标准胖树(Spine-Leaf)就能覆盖。
但规模到 32768 GPU 呢?
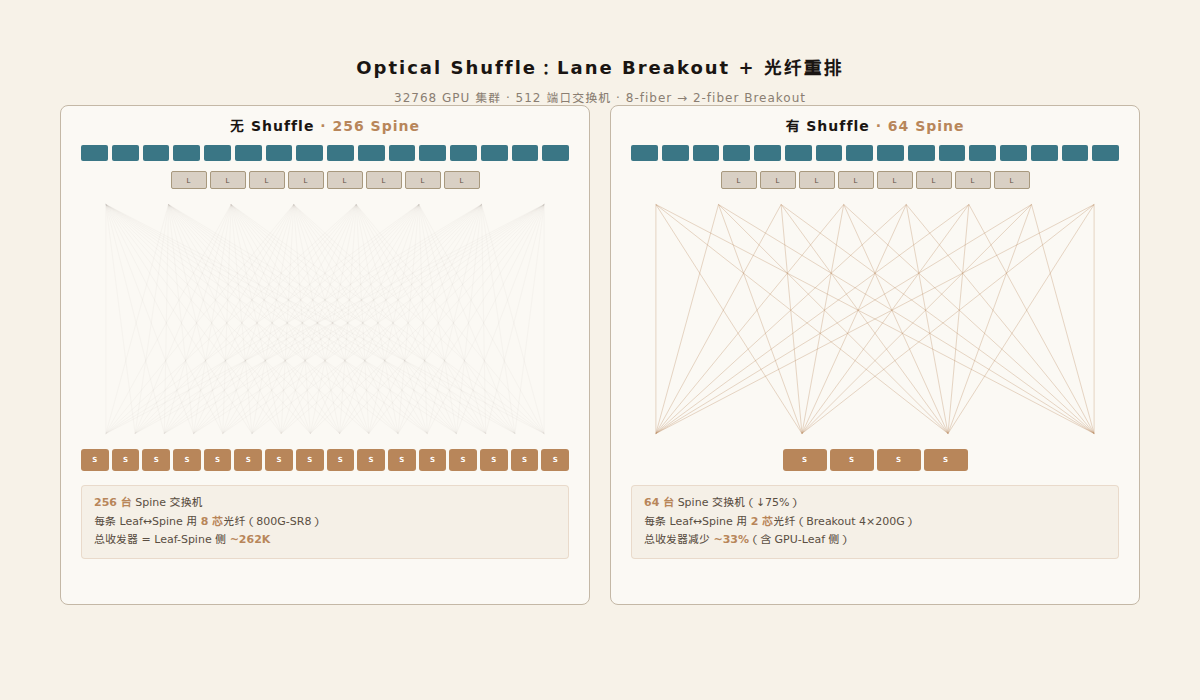
4096 个节点,需要把 8192 集群复制 4 份——64 个 POD。如果用同样的 512 端口交换机,Spine 数量从 64 台跳到 256 台。Leaf 从 128 台跳到 512 台。每台 Leaf 到每台 Spine 都需要一对光模块(收发各一)。
光模块的总数 = Leaf 数 × 每 Leaf 的上行端口数 + GPU 到 Leaf 的连接数。粗算:
- 512 Leaf × 每个 Leaf 连 256 个 Spine = 131,072 个光模块(Leaf-Spine 侧)
- 32768 GPU 以 400G 速率连到 Leaf = 另外一大堆光模块
- 加起来,32768 GPU 集群的光模块总数量在 15-20 万只 的量级
一个 800G OSFP 光模块目前的市场价在 500-800 美元。15 万只就是 7500 万到 1.2 亿美元。交换机本身反而成了小头——一台 512 端口 800G 交换机约 5-10 万美元,256 台 Spine 也就 1300-2500 万美元。
光模块的成本是交换机的 3-5 倍。 这个比例在 400G 时代已经存在,到 800G/1.6T 时代进一步放大——因为每条链路需要更多光纤、更精密的光学器件、更高功率的 DSP。
Castro 的问题很精准:不碰拓扑,不动路由协议,只改光纤的连接方式,能把光模块砍掉多少?
Optical Shuffle 的核心操作:Lane Breakout + 光纤重排
Lane Breakout:一条粗管变四条细管
现代 800G 光模块(如 800G-SR8)用 8 根光纤并行传输——8 个通道各跑 100G。模块端是一个 8 芯 MPO 连接器。对面交换机的光模块也是一个 8 芯 MPO。一根 8 芯跳线连过去,8 根光纤一一对应。
Lane Breakout 做的事很简单:把 8 芯 MPO 拆成 4 组 2 芯(收发各一)。 一个 800G-SR8 模块出来的 8 根光纤,不连到对端的一个模块,而是分给 4 个不同的对端模块,每个 2 根光纤跑 200G。
物理上这只是一根 breakout cable——一头是 8 芯 MPO,另一头是 4 个 2 芯 LC 双工连接器。成本极低(十几到几十美元),无源器件,不需要供电。
Shuffle:打乱重连
单纯的 Breakout 只是"一拆四"。Shuffle 是关键步骤——在光纤层重新编排哪些信号送到哪里。
在标准胖树中,一台 Leaf 的上行端口分到 64 台 Spine,每台 Spine 用 8 根光纤(一个 800G 链路)。Castro 的方案是:Leaf 的上行端口用 Breakout 拆成 2 芯一组,每组通过 Shuffle 面板连到不同的 Spine。
效果:每台 Spine 不再需要 8 根光纤的一个完整 800G 端口,只需要 2 根光纤的一个 200G 通道。 同样的 512 端口交换机,每台 Spine 现在可以服务 4 倍的 Leaf——因为每个端口从 8 芯降到 2 芯。
量化收益
Castro 的报告给出了两个规模的对比:
8192 GPU 集群:
| 无 Shuffle | 有 Shuffle | |
|---|---|---|
| GPU | 8192 | 8192 |
| 节点 | 1024 | 1024 |
| Leaf | 128 | 128 |
| Spine | 64 | 64 |
| Leaf-Spine 连接 | 8-fiber | 2-fiber |
| Spine 端口利用率 | 每端口 1 个 Leaf | 每端口 4 个 Leaf |
8192 规模下 Spine 数量不变(64 台),但每台 Spine 的端口利用率提高了 4 倍。
32768 GPU 集群:
| 无 Shuffle | 有 Shuffle | |
|---|---|---|
| GPU | 32768 | 32768 |
| 节点 | 4096 | 4096 |
| POD | 64 | 64 |
| Leaf | 512 | 512 |
| Spine | 256 | 64 |
| Leaf-Spine 连接 | 8-fiber | 2-fiber |
Spine 从 256 台降到 64 台——4 倍差距。 这意味着 192 台 Spine 交换机和上面的所有光模块都不需要了。
收发器总削减量(含 GPU-Leaf 和 Leaf-Spine 两侧):约 33%。
为什么这个方案能行
关键在于 AI 集群的流量模式和通用数据中心不同。
通用数据中心的 Spine-Leaf 连接需要 full-mesh——每台 Leaf 要连到每台 Spine,带宽要够大(800G),因为流量模式不可预测。但 AI 训练集群的流量模式高度规律:all-reduce 操作中,每台 Leaf 需要和所有其他 Leaf 交换梯度数据,但单次交换的带宽需求不一定需要满 800G。200G 的通道如果足够多(ECMP 多路径),也能撑住。
Lane Breakout 把 1 个 800G 链路变成 4 个 200G 链路。总带宽不变(800G),但连接数翻了 4 倍。对于 AI 训练的 all-reduce 模式,多路径的连接数比单条粗管更有价值——负载均衡粒度更细,哈希碰撞更少。
这就是 Castro 方案的数学基础:不是减少总带宽,而是用更细的粒度重新分配带宽,让同样的交换芯片服务更多的连接。
与 RNG 的对照:一个改拓扑,一个改光纤
现在把 Castro 的 Optical Shuffle 和 AWS 的 RNG 放在一起看。
正交维度
| RNG(AWS) | Optical Shuffle(Castro/Panduit) | |
|---|---|---|
| 改什么 | 网络拓扑——从胖树变随机图 | 光纤连接方式——Breakout + 重排 |
| 核心操作 | Spraypoint 路由 + ShuffleBox 布线 | Lane Breakout cable + Shuffle 面板 |
| 目标对象 | 交换机和路由 | 光模块和光纤 |
| 成本节省来源 | 路由器总数 -69% | 光模块总数 -33%,Spine -75% |
| 前提 | 必须换拓扑和路由协议 | 不碰拓扑,在胖树内操作 |
| 适用场景 | 多租户通用计算 | AI GPU 训练集群 |
| 工程风险 | 需要重建运维工具链 | 光纤布线变更,运维习惯微调 |
| 兼容性 | 替代胖树 | 与胖树共存 |
最关键的区别:RNG 是替代方案,Shuffle 是优化方案。 RNG 说"胖树是错的",Shuffle 说"胖树的光纤没排好"。两者不矛盾,理论上可以叠加——用 RNG 的 flat topology 做架构,再用 Shuffle 做 Lane Breakout 进一步压缩光纤成本。
能不能叠加?
理论上可以,但有一个约束:RNG 的 ShuffleBox 和 Shuffle 的 Breakout 面板在物理层会争夺同一个光纤端点。
RNG 的 ShuffleBox 是无源光纤交叉连接器——把路由器的 uplink 随机打散到不同远端。Castro 的 Shuffle 面板也是无源器件——把 8 芯拆成 4×2 芯再重排。两者如果串联,信号要经过两次面板,连接器损耗叠加。
RNG 文章里已经讨论过光衰约束:路径超过 7 个连接器就被截断。加一个 Shuffle 面板就多 2 个连接器(进出各一)。如果 RNG 的 ShuffleBox 已经用了 4-6 个连接器,再加 Shuffle 面板就可能超过光功率预算。
叠加可行但有物理上限——取决于具体的光模块功率预算和链路长度。 短距(<100m OM4 多模光纤)余量大,可以叠加。长距(>500m 单模)余量紧,可能只能选一个。
对收发器成本的影响对比
RNG 减少的是交换机数量——69% 的路由器被砍掉。但每台保留的路由器仍然需要光模块。总光模块数量减少的比例取决于路由器减少的比例和每台路由器端口密度的变化。
Shuffle 减少的是每条链路的光模块数量——不是砍交换机,是让同样的交换机用更少的光模块服务更多的连接。33% 的光模块削减直接就是成本削减。
如果两个方案叠加:RNG 先砍 69% 的交换机(对应砍掉大部分光模块),然后剩下的交换机上再用 Shuffle 把光模块再砍 33%。但这里的数学不是简单相乘——RNG 砍掉交换机的同时也砍掉了它们上面的光模块,剩下需要 Shuffle 优化的比例变小了。
粗估:RNG 单独砍 69% 交换机 → 光模块减少约 50-60%(因为路由器间链路大幅减少,但 GPU-Leaf 链路不变)。在此基础上加 Shuffle,剩余光模块再砍 33% → 总光模块减少约 65-70%。
但这是理论推算,没有实际验证。 RNG 和 Shuffle 的组合部署目前在公开资料中没有先例。
光纤的两条远路:MCF 和 HCF

Castro 在同一研讨会上还有第二篇报告:"Scaling AI Networks with Multicore and Hollow-Core Fiber"。他把目光放得更远——不只是怎么连线,而是线本身要变了。
MCF(多芯光纤):一根光纤当四根用
MCF 的概念不新——在一根 125µm 包层的光纤里放 4 个独立的纤芯,每个纤芯传输独立的光信号。物理外径和标准 G.657 光纤一样,可以塞进同样的管道和连接器。
Castro 给出的设计参数:
| 参数 | 值 |
|---|---|
| 纤芯数 | 4 |
| 包层直径 | 125 µm |
| 涂覆层直径 | 200/250 µm |
| 衰减 | < 0.4 dB/km(1310nm),< 0.20 dB/km(1550nm) |
| 模场直径 | 8.6-9.2 µm |
| 串扰 | ≤ -40 dB(@1310nm 或 @1550nm,10km) |
| 弯曲损耗 | ≈ 常规 G.657.A1 |
关键信号:和 G.657 兼容。 这意味着 MCF 可以在现有的光纤管道里铺设,不需要改造基础设施。连接器、熔接机、测试设备需要适配,但物理通道不变。
Corning 在 OFC 2026(2026 年 3 月)发布了面向 AI 数据中心的 MCF 产品线,给出了更具体的收益数字:
- 光缆和连接器减少 75%
- 光缆质量减少 70%
- 安装速度提升 60%
为什么这些数字重要?因为 AI 数据中心的光纤用量正在爆炸式增长。AFL Hyperscale 的分析指出:AI 数据中心需要的光纤数量是传统数据中心的 10 倍以上。 一个 32768 GPU 集群,GPU 到 Leaf 就需要数万条光纤跳线,Leaf 到 Spine 又是数万条。如果没有密度提升,机房的光纤管理会成为物理瓶颈——不是带宽不够,而是线太多放不下。
MCF 的另一个隐藏收益:它可以让 400G-PAM4 在 1310nm 波长上跑更远的距离。ITU 的分析显示,标准单模光纤上 400G-PAM4 在 CWDM 配置下受色散限制只能跑 <1km,但用 MCF 做 PSM(并行单模),每个纤芯独立跑 1310nm 附近的一个波长,可以把 400G 的有效传输距离拉到 ~3km。这个距离正好覆盖园区级 AI 数据中心的跨楼宇互联。
MCF 的代价:
- 熔接需要旋转对准——4 个纤芯的位置必须精确匹配。常规光纤熔接机做不到,需要专用设备。现场施工时间增加
- Fan-in/Fan-out 器件是必需的——MCF 到常规单模光纤的转换需要专门的光学器件,每个器件引入约 0.3-0.5dB 的插入损耗
- 故障定位更复杂——一根光纤断了一芯,其他三芯可能还活着。测试设备需要能区分纤芯
- 标准化还在进行中——ITU-T G.650.x 系列正在补充 MCF 的测试方法和参数定义
判断:MCF 不是可选的未来,是必需的未来。 当 AI 集群从万卡走向十万卡,光纤密度是物理硬约束。MCF 的 4 倍密度提升是目前唯一成熟的路径。代价主要在运维侧——施工工具和测试流程的适配。这个适配成本远小于新建一个机房的物理空间成本。
HCF(空芯光纤):光在空气中跑得更快
HCF 的原理不同——光信号不是在玻璃中传播,而是在光纤内部的空气孔中传播。因为光在空气中的速度比在二氧化硅玻璃中快约 30%,传播延迟直接降低。
谁最在意这 30% 的延迟降低?跨楼宇、跨园区的分布式 AI 训练。
当一个 AI 训练集群分布在两栋楼之间(典型距离 2-10km),光信号的往返延迟:
| 链路长度 | 常规 SMF 往返延迟 | HCF 往返延迟 | 差值 |
|---|---|---|---|
| 2 km | ~20 µs | ~14 µs | 6 µs |
| 10 km | ~100 µs | ~70 µs | 30 µs |
| 40 km | ~400 µs | ~280 µs | 120 µs |
在大模型训练中,每次 all-reduce 操作需要所有 GPU 同步。同步的粒度是微秒级的。如果跨楼宇链路的往返延迟差 30 µs(10km 场景),在每次迭代中都会累积。万卡规模的训练,每秒可能有数百次跨集群同步,延迟差异会显著影响训练效率。
但 HCF 的代价比 MCF 高得多:
- 制造工艺完全不同于常规光纤——需要精确控制内部微结构。目前产量低,成本高
- 熔接风险大——热量控制不精确会导致空心结构坍塌
- 与常规光纤的接口需要特殊器件——玻璃到空气的边界会引入反射
- Ribbon HCF 和高芯数 HCF 光缆尚未商用
- 微软在 Azure 中有部署案例,但规模有限
AFL Hyperscale 的判断很清醒:"Neither technology is expected to broadly replace conventional SMF. Adoption will depend on whether the performance advantages justify both the operational complexity and the TCO."
判断:HCF 的适用场景非常窄——仅限跨楼宇/跨园区的 AI 集群互联(Scale-Across 层)。 在 Scale-Out(机房内)和 Scale-Up(机架内)层级,延迟差不够大,不值得承担 HCF 的运维复杂度。但在 10km+ 的分布式训练场景下,30% 的延迟降低是有真金白银价值的——意味着同样的训练任务可以更快完成,或者同样的 GPU 算力可以支撑更大规模的模型。
产业链:谁在做什么
Panduit:标准制定者 + 连接器厂商
Castro 本人是 Panduit 的杰出光纤研发工程师(Distinguished Fiber Optic R&D Engineer)。Panduit 是结构化布线领域的头部厂商——不做交换芯片,不做光模块,做的是 MPO 连接器、光纤跳线、配线架这些"管道"。
Panduit 在这个生态里的角色很独特:它没有硬件产品需要保护(不卖交换机,不卖光模块),所以它可以提出"减少光模块"的方案而不会和自己的产品线冲突。Optical Shuffle 的核心器件(breakout cable + shuffle 面板)恰恰是 Panduit 的强项——无源光纤器件。
Panduit 还有一份 AI 网络布线性能测试白皮书,用 NVIDIA 光模块和自家的 OM4 光纤做 800G-SR8 的 BER 测试。数据表明:50m OM4 光纤在最坏情况下的接收功率是 -4.7 dBm(在 FEC 限制边缘),MMF 色散惩罚约 0.4 dB。这为 Shuffle 方案的光功率预算提供了实测依据。
Corning:光纤制造巨头
Corning 在 OFC 2026 发布了面向 AI 数据中心的 MCF 产品线。这是 MCF 从实验室走向商用的标志性事件。
Corning 的优势是光纤制造能力和全球供应链。MCF 的主要挑战不在技术(4 芯 125µm 已经被充分验证),而在产业链配套——连接器、熔接机、测试设备、施工流程都需要适配。Corning 的做法是提供端到端方案(光纤 + 电缆 + 连接器),降低客户的使用门槛。
AFL Hyperscale:清醒的分析者
AFL 的分析文章是目前看到的最务实的 HCF/MCF 评估。它没有回避任何代价——串扰、熔接难度、标准化滞后、TCO 不确定性。核心结论:"两种技术都不会广泛替代常规 SMF。采用取决于性能优势是否值得运维复杂度。"
这个结论和我对 Optical Shuffle 的判断一致:不是替代,是分层选用。 MCF 解决密度(Scale-Out 层),HCF 解决延迟(Scale-Across 层),常规 SMF 继续服务 Scale-Up 层。三种光纤在同一网络中并存。
国内供应链
国内在 MCF 方面有制造能力但缺需求驱动。长飞光纤(YOFC)在 2023 年已经展示了 4 芯 MCF 样品,参数和 Castro 报告中的规格一致。中利集团、亨通光电在特种光纤领域也有积累。
但国内 AI 集群的当前规模(万卡级)还没有碰到光纤密度的物理上限。32768 GPU 以上的集群在国内还在规划阶段。需求没有规模化之前,MCF 的产业链不会启动。 这和 RNG 的 ShuffleBox 面临的问题一样——技术可行,但需要足够大的部署规模来分摊产业链适配成本。
HCF 方面,国内跟进更慢。Lumen Innovation(英国)和 Corning 在 HCF 制造上领先,微软 Azure 是目前唯一的规模部署者。国内在 HCF 上主要是学术研究(清华大学、北京邮电大学),距离商用还有 2-3 年。
回到 RNG 的视角
把 Optical Shuffle 和 MCF 放回 RNG 那篇文章的框架里,可以看到一个更完整的图景。
RNG 解决的是拓扑层的效率问题——胖树的层级结构导致带宽浪费,flat topology 通过随机性恢复容量可复用性。但 RNG 没有解决物理层的效率问题——每条链路仍然是一个光模块 + 一组光纤。
Castro 的 Optical Shuffle 解决的是物理层效率——同样的带宽,用更少的光模块和更细的粒度。MCF 进一步提升密度——同样的物理空间,塞进 4 倍的光纤。
三层叠加的理论极限:
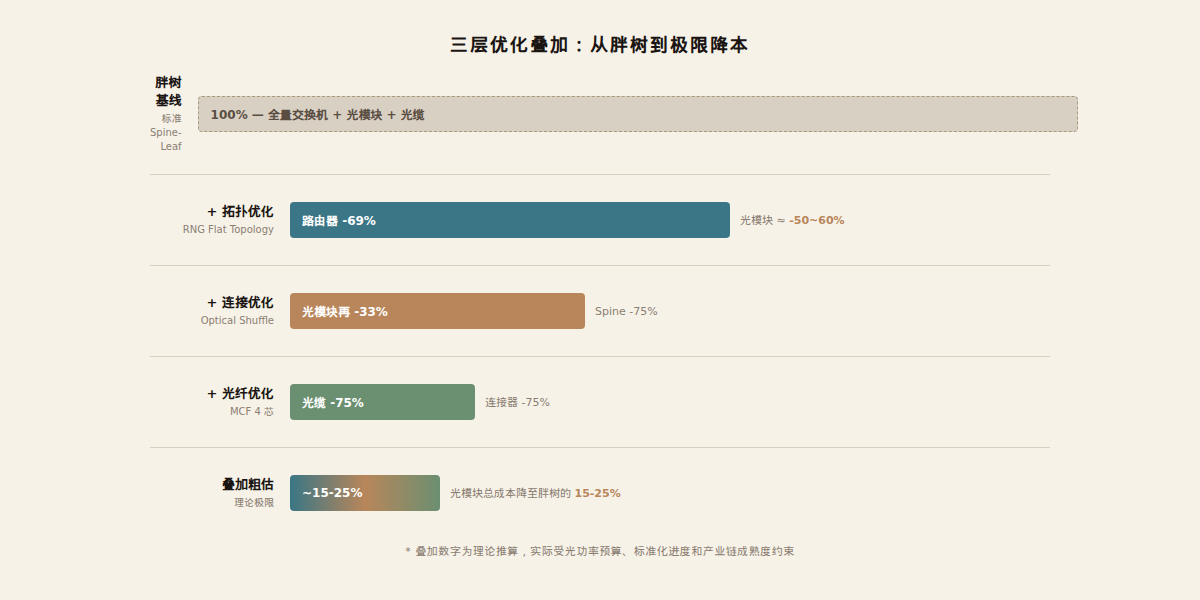
| 优化层 | 方案 | 效果 |
|---|---|---|
| 拓扑 | RNG flat topology | 路由器 -69%,光模块 -50~60% |
| 连接 | Optical Shuffle | 光模块 -33%(剩余部分) |
| 光纤 | MCF 4 芯 | 光缆 -75%,连接器 -75% |
| 叠加粗估 | 三层全部叠加 | 光模块总成本可能降至胖树的 15-25% |
这个数字当然是理论推算,实际部署中会有光功率预算、标准化进度、产业链成熟度等各种约束。但方向是清晰的:拓扑优化 + 连接优化 + 光纤优化,三层叠加的降本空间远大于任何单层优化。
什么时候能看到组合部署?
短期(2026-2027):Optical Shuffle 单独部署在 32K+ GPU 集群中。Panduit 已经在推动 shuffle cable 和面板的标准化,AI 集群客户(NVIDIA 参考设计的大客户)是自然的第一批采用者。
中期(2027-2028):MCF 开始在新建 AI 数据中心的 Scale-Out 层部署。Corning 的产品线已经上市,标准化的缺口在 ITU-T 进程中逐步补齐。关键催化剂是 100K+ GPU 集群的光纤密度瓶颈。
长期(2028+):HCF 在跨楼宇 Scale-Across 层的特定场景部署。微软的先例 + 制造成本的逐步下降会打开这个市场。但规模有限。
RNG + Shuffle + MCF 的组合部署需要更长时间,因为涉及拓扑和物理层的同时变更。最可能的路径是:先用 Shuffle + MCF 在胖树框架内优化(不改拓扑),等 RNG 类 flat topology 在非 GPU 场景积累了足够的运维经验后,再考虑在 GPU 推理集群中做组合部署。
结论
Castro 的 Optical Shuffle 报告表面上是一个光纤布线方案,实质上是在回答一个更大的问题:当 AI 集群规模从万卡走向十万卡,网络的成本瓶颈到底在哪?
答案不在交换芯片——芯片的成本随摩尔定律持续下降。不在拓扑——RNG 已经证明改拓扑可以砍掉 69% 的路由器。答案在物理层——光模块、光纤、连接器。这些器件的成本不遵循摩尔定律,制造工艺的改进速度远慢于芯片。
Optical Shuffle 的 33% 收发器削减不是一个孤立的数字。它和 RNG 的 69% 路由器削减、Corning MCF 的 75% 光缆削减一起,构成了一条完整的降本路径——从拓扑到连接到光纤,每一层都有自己的优化空间。
这条路径目前还没有人在做组合部署。但 AWS 的 RNG 已经在非 GPU 数据中心验证了拓扑层优化的可行性,Castro 的 Shuffle 和 Corning 的 MCF 正在验证连接层和光纤层优化的可行性。当这三个层面的优化同时成熟,AI 集群的网络成本结构会发生质变——从"光模块比交换机贵 3-5 倍"变成"网络不再是 GPU 算力的主要成本约束"。
对国内的意义:短期内跟进 Optical Shuffle 的性价比最高——不改拓扑、不改路由、只换光纤跳线和面板,运维改动最小。MCF 需要产业链配套,HCF 需要更长时间。RNG 类的 flat topology 是最激进的路线,但也是收益最大的——不过那是另一篇文章的话题了。
声明: 本文基于 Panduit 工程师 Jose M. Castro 在 IEEE 802.3 E4AI 研讨会(2026 年 2 月 24 日)的两份公开报告 Optical Shuffle Architectures for Large AI Networks 和 Scaling AI Networks with Multicore and Hollow-Core Fiber,结合 AFL Hyperscale、Corning OFC 2026 发布、ITU-T MCF 标准化进程、Panduit AI 网络布线白皮书等公开信息撰写。RNG 部分引用自 arXiv:2604.15261v3。不构成投资建议。文中数据截至 2026 年 6 月 7 日。