从 ZCube 谈起:面向 PD 分离推理的网络拓扑设计
当推理取代训练成为 AI 基础设施的主战场,GPU 集群的网络拓扑需要从头重新思考。
这篇文章要回答一个具体问题:当大模型推理把一个请求拆成"理解输入"和"生成输出"两个阶段,分到不同 GPU 上执行时,GPU 之间的数据传输模式会发生根本变化——传统网络拓扑不再适用。2026 年 5 月,ZCube 拓扑(字节跳动 + 清华大学,SIGCOMM 2025 最佳论文)率先在生产集群验证了一种新思路。本文以 ZCube 为起点,分析它的核心价值与局限,推导推理集群应有的 Prefill/Decode 配比与放置策略,然后提出 RailFly——一个覆盖训练+推理混合负载的务实拓扑族,以及其纯推理进阶形态 Rail-Fabric。论述路线:先理解问题(为什么拓扑重要)→ 分析现有方案(ZCube 的优缺点)→ 量化瓶颈(KV Cache 有多大)→ 推导参数(P:D 配比、Cell 规模、放置策略、配对策略)→ 提出新方案(RailFly → Rail-Fabric)。
一、为什么网络拓扑突然变得重要
要理解这篇文章讨论的问题,需要先弄清两个基本概念。训练和推理的区别:训练是用大量数据让模型"学会",推理是让训练好的模型"回答问题"。两者的计算模式完全不同——训练中 GPU 之间的通信模式是规律、可预测的,而推理中通信模式是动态、不可预测的。PD 分离(Prefill-Decode Disaggregation) 是推理领域的一个关键优化:把一个推理请求拆成两个阶段——Prefill(理解输入)和 Decode(生成输出),分别交给不同的 GPU 执行。这样做的好处是 Prefill 和 Decode 可以独立扩缩容,但代价是 Prefill GPU 必须把大量中间数据(KV Cache)通过网络传给 Decode GPU,网络拓扑直接决定了这个传输的效率。
大模型集群从千卡向万卡演进,GPU 算力不再是唯一瓶颈。将算力相连的网络链路,开始直接决定集群的实际吞吐效率。
两个标志性事件几乎同时发生:
- 2026 年 5 月 5 日,OpenAI 联合 NVIDIA、AMD、Intel、Microsoft、Broadcom 发布 MRC(Multipath Reliable Connection)协议——从传输协议层解决超大规模 GPU 集群的网络通信瓶颈。
- 2026 年 5 月 21 日,ZCube 组网架构(字节跳动 + 清华大学,SIGCOMM 2025 最佳论文)在智谱 AI 的 GLM-5.1 千卡推理生产集群完成部署验证——从拓扑架构层解决同样的问题。
两者代表两条互补的技术路径:协议层优化(MRC)与架构层重构(ZCube)。
本文以 ZCube 为基准,分析其核心价值与局限,推导 PD 分离推理下的 P:D 配比与放置策略,然后提出 RailFly——一个覆盖训练+推理混合负载的务实拓扑族,以及其纯推理进阶形态 Rail-Fabric。

ROFT 的设计前提正在失效
当前主流的 GPU 集群组网基于 ROFT(Rail-Optimized Fat-Tree):将 GPU 按 rank 分组到 rail,同 rank GPU 连同一台交换机,训练中的 DP/PP 通信在 rail 内 1 跳完成。这个设计的前提是"同 rank GPU 之间通信最多",流量天然按 rail 对齐。可以把 Clos/ROFT 理解为多层交换机组成的树状结构——数据从底层交换机向上汇聚到中间层(Spine),再由中间层分发到其他底层交换机。ROFT 在这个基础上做了一步优化:让经常需要互相通信的 GPU 优先走同一"轨道"(rail),省去上层的转发开销。
PD 分离推理打破了这个前提。KV Cache(大模型推理中存储"已处理上下文"的中间数据,大小从几百 MB 到十几 GB,需要在 GPU 间传输)从 Prefill 节点跨节点传输到 Decode 节点,流量呈现三个特征:
- 源-目的强不对称: 不同 GPU 承担的 KV Cache 传输负载差异可达几个数量级。
- 动态变化: 哪些 P 节点与哪些 D 节点配对由调度器实时决定,不可预知。
- 突发性: 长上下文请求产生大块 KV Cache 传输,瞬时带宽需求高。
ROFT 的 rail 映射在这种流量模式下失效——流量被集中推向少数交换机和链路,引发 PFC 反压,出现"总带宽充裕、局部频繁拥塞"的结构性问题。
二、ZCube 的核心价值与局限
ZCube 的诞生:从自动搜索到非对称拓扑
ZCube 并非人类专家手工设计的拓扑,而是 ATOP(Automated Topology Optimization Pipeline) 在 256 到 16,384 GPU 的自动搜索中发现的。
ATOP 的核心思路是将拓扑建模为 11 类可搜索超参数——从 CLOS、BCube、Dragonfly 等主流拓扑的专家知识中提炼,将拓扑设计转化为结构化的超参数搜索问题。搜索空间远小于邻接矩阵的 O(2^N²),却覆盖了所有主流拓扑的结构变体。ATOP 使用 NSGA-II 进化算法(在四种候选算法中表现最优),配合自研的流级仿真器(与 NS-3 的平均误差仅 1.5%),在 GPU 训练性能、容错、网络成本三个维度上搜索 Pareto 最优拓扑。
关键发现:在 256、1024、4096、16384 四个 GPU 规模下,Pareto 前沿拐点处(最性价比拓扑)的架构惊人地相似——论文将其形式化定义为 ZCube。ATOP 打破了人类专家的"对称性偏见"——传统拓扑所有交换机端口相同,但 ATOP 发现非对称设计更优。从 BCube(SIGCOMM 2009,通讯作者 Dan Li)到 ZCube(SIGCOMM 2025,同一作者),命名传承意为"the last letter, the ultimate Cube"。
架构设计
ZCube 彻底打破 Clos 的层次化思维,以递归定义的非对称拓扑族为核心重构网络:
递归定义(论文 Figure 8a):
- ZCube(n, 1) = 1 台交换机 + n 个 GPU(最小单元)
- ZCube(n, k+1) = n × ZCube(n, k) + n^k 台交换机
因此 ZCube(n, k) 包含 n^(k+1) 个 GPU、k+1 层交换机(每层 n^k 台),每个 GPU 有 (k+1) 个 NIC 端口。论文证明网络直径 = k(Theorem 1)。
核心创新是非对称性:首尾层交换机需要 2n 端口,中间层需要 3n 端口。这与传统拓扑(Fat-Tree、BCube、Dragonfly)所有交换机使用相同端口数的做法截然不同。ATOP 的自动搜索发现,不同层交换机承载的流量模式不同,非对称端口分配能更精确匹配实际需求。
ZCube(128,2) 的具体构造——连接 16,384 GPU,直径仅 2 跳,仅用 256 台交换机。这是论文的核心验证规模,也是智谱 AI GLM-5.1 部署的参考架构:
- 两层交换机,每层 128 台,共 256 台。可以理解为把所有交换机分成奇数组和偶数组。
- 每个 GPU 有 2 个 NIC 端口(400G NIC 可拆为 2×200G),Port 1 连一台奇数层交换机,Port 2 连一台偶数层交换机。
- 两层之间做完全二部图互联——这是 k=2 时的工程实现形式。
全网 GPU 之间 2 跳可达(vs ROFT 的 5 跳)。路由目标是让 GPU pair 走唯一/确定的较优路径,减少 ECMP 或静态 rail 映射导致的局部热点和 PFC 反压。
生产验证数据
GLM-5.1 coding 推理的千卡级生产集群,从 ROFT 改成 ZCube,GPU、软件栈、应用不变:
- 交换机和光模块 CapEx 降低约 33%
- GPU 平均推理吞吐 +15%
- TTFT P99 降低 40.6%
原文还做了一个 32 卡带宽消融:网卡可用带宽从 100Gbps 提到 200Gbps,吞吐约提升 19%,TTFT 约下降 22%。这说明瓶颈不是单纯 GPU 算力,而是 PD 分离下 KV Cache 传输和网络热点在影响有效吞吐。
网络层性价比粗算: 网络硬件花费变为 0.67 倍,吞吐变为 1.15 倍,网络硬件/吞吐成本约 0.67/1.15 ≈ 0.58,即网络层性价比约提升 70%。
论文的 16,384 GPU 定量对比(Table 6):
| 拓扑 | 交换机数 | 线缆 | 网络成本 |
|---|---|---|---|
| ROFT | 640 | 49,152×400G | ~$93M |
| Rail-only | 384 | 32,768×400G | ~$76M |
| HPN | 384 | 16,384×400G + 32,768×200G | ~$84M |
| ZCube(128,2) | 256 | 49,152×200G | ~$57M |
ZCube 相比 ROFT、Rail-only、HPN,端到端训练速度提升 3%–7%,网络硬件成本降低 26%–46%。交换机数量比 ROFT 少 60%(256 vs 640),且使用 200G 线缆(vs ROFT 的 400G),光模块成本进一步降低。
四个核心优势
第一,打散 PD 流量的源端/目的端/规模不对称。 多层交换机 + 多端口接入,比 Clos/ROFT 更能均匀分布动态的 P→D KV Cache 流量。
第二,确定性路由消除结构性拥塞。 拓扑本身不假设特定流量模式,从根源消除拓扑诱导的拥塞热点。
第三,收益不靠加 GPU,靠降低结构性拥塞。 "每单位网络 CapEx 的有效吞吐"提升明显。
第四,结构性容错优势。 ZCube 的容错能力来自其多端口结构本身——每个 GPU 有 (k+1) 个 NIC 端口连到不同层交换机,单台交换机故障时只需切换端口,不需要绕行 NVLink。论文数据(Figure 3b):4K GPU 集群单 ToR 故障,ZCube 性能仅下降 2.8%,而 ROFT 下降 46.9%,HPN 下降 9.0%。此外,ZCube 交换机更少(256 vs ROFT 的 640),故障点更少——16K 集群无故障概率 93% vs ROFT 的 83%。这是比 HPN 的"双 ToR 硬件冗余"更优雅的容错路径:用更优的结构同时提升性能和可靠性。
四个实际局限
1. 物理拓扑重构,不是软件小改。 原文明确说 Clos 下的布线、IP 编址、路由策略、交换机配置都不能直接复用,需要重新设计和自动化校验。
2. 解决的是"可避免拥塞",不是最后一跳 incast。 多个 Prefill 同时给同一个 Decode 组灌 KV 时,仍需调度、拥塞控制、流量整形。
3. 完全二部图对布线和端口数要求高。 规模越大越依赖高 radix 交换机、breakout、自动连线校验和拓扑感知调度。
4. 训练场景 rank 局部性丧失。 同 rank GPU 不再连同一台交换机,训练中 DP/PP 通信从 1 跳变 2 跳。
上面分析了 ZCube 的核心优势和四个实际局限。拓扑优化的核心收益取决于跨节点 KV 传输的规模和模式——接下来先量化 KV Cache 到底有多大,才能推导合理的 P:D 配比。
三、GLM-5.1 的推理服务单元与 KV Cache 瓶颈
在讨论拓扑选择前,需要先搞清楚瓶颈到底在哪。
GLM-5.1 官方规格:744B-A40B,提供 BF16 与 FP8 版本;官方 vLLM/SGLang 示例使用 --tensor-parallel-size 8,工程上以 8 GPU 节点/TP 组作为最小完整推理单元。
官方参数:最大上下文 200K,最大输出 128K;input $1.4/MTok,output $4.4/MTok,output/input 价格比约 3.14。价格不等于真实成本,但它是一个可用的 proxy:每个生成 token 的服务成本/资源压力大约是输入 token 的 3 倍量级。
KV Cache 单 token 估算
按公开 config 粗估,GLM-5.1 的 MLA/DSA 类 KV latent cache 若用 BF16 存储,单 token KV 约为:
78 × (512 + 64) × 2 ≈ 89,856 Bytes/token
78 是层数,512 是 kv_lora_rank,64 是 qk_rope_head_dim,2 是 BF16 字节数。如果实际 KV Cache 做 FP8 量化,大约减半。
| Prompt 长度 | P→D KV 总量/请求 | TP=8 时每卡分摊 |
|---|---|---|
| 32K | ~2.94 GB | ~370 MB |
| 128K | ~11.5 GB | ~1.4 GB |
| 200K | ~18.2 GB | ~2.3 GB |
这就是拓扑优化能影响 TTFT P99 的根本原因: 每次推理请求产生数百 MB 到数 GB 级跨节点传输,网络拓扑决定了这些传输是均匀散开还是集中在少数热点链路上。
有了 KV 量的估算,下一步自然要问:一个推理集群里,应该配多少 Prefill GPU、多少 Decode GPU?
四、PD 分离的 P:D 比例推算
没有真实的 token 分布数据之前,比例只能是工程推算,不是唯一答案。但可以用一阶公式起步:
P/D ≈ (Ī_eff) / (3.14 × Ō) × h
其中 Ī_eff 是未命中缓存的平均输入 token,Ō 是平均生成 token(含 reasoning、tool-call JSON、最终回答),3.14 来自官方 output/input 价格比,h 是 TTFT/SLO 余量(ZCube 下建议 1.1~1.2,ROFT 下要留更高)。
如果有上下文缓存:
Ī_eff = Ī × [(1-H) + H × 0.26/1.4]
H 是 cache hit ratio,0.26/1.4 来自官方 cached input/input 价格比。coding agent 大量复用上下文时,P 池明显变轻,比例从 Prefill-heavy 变成更接近 1:1 甚至 Decode-heavy。
| 负载形态 | 假设平均 token | 公式推算 P:D | 建议起配 |
|---|---|---|---|
| 深度思考/长输出型 | 16K in / 8K out | 0.64:1 | 1:1,或 2:3 |
| 常见 coding agent | 24K in / 6K out | 1.27:1 | 3:2 |
| repo-heavy 长上下文 | 32K in / 4K out | 2.55:1 | 2:1~5:2 |
| 40% cache hit 的 32K/6K | effective input ≈21.6K | 1.15:1 | 4:3~3:2 |
默认建议:先按 P:D ≈ 3:2 建池。 线上观察到 output/reasoning token 很长时降到 1:1;repo ingest、大量长上下文、短输出时升到 2:1。
ZCube 的 15% 吞吐提升不直接改变 P:D 计算公式,但让你少留网络拥塞冗余,能更接近理论配比运行。
D 池不只看算力,还要看 KV Memory
P/D 比例不要只看 prefill/decode FLOPs。Decode 节点的另一个关键职责:长期持有活跃会话的 KV cache。
D 池大小应取三者最大值:
N_D = max(N_D_decode_compute, N_D_KV_memory, N_D_KV_ingress)
如果业务里有大量 64K、100K、200K 上下文会话,即使 token 算力模型显示 P 应该更多,D 池也不能太小。否则 D 端被 KV cache memory 卡住——P 节点空闲、D 节点显存满、请求无法 admit、TTFT 抖动。
工程建议:
- 短输出、长 prompt:可以 5:3,甚至接近 2:1
- 通用 coding:3:2 左右
- 长 reasoning / 多轮 agent:1:1 到 4:3
- 超长上下文高并发:优先保 D memory,宁可少一点 P
确定了 P:D 比例后,需要决定一个 ZCube cell 放多少 GPU、多少交换机——规模直接决定端口需求和布线复杂度。
五、ZCube Cell 规模设计
ZCube 原文公式:总 GPU 数 n,每台交换机连接 k 个 GPU,交换机总数 2n/k,两组之间完全二部图互联;每台交换机逻辑端口约 k + n/k。端口利用最优时 k ≈ n/k ≈ √n。
注意:上述端口公式是对 ZCube(n,2) 特例的简化描述。根据论文,ZCube(n,k) 的精确端口分配是非对称的——首尾层交换机需要 2n 端口,中间层需要 3n 端口(k>2 时)。下表的"逻辑端口"列按简化公式计算,与实际 ZCube 的非对称端口分配会略有差异。
按 8 GPU 节点、P:D ≈ 3:2 起配:
| ZCube Cell 规模 | 8-GPU 节点数 | 平衡参数 k | 每交换机逻辑端口 | 交换机数 | 建议 P/D 节点起配 | 等效 ROFT GPU 吞吐 |
|---|---|---|---|---|---|---|
| 1024 GPU | 128 | 32 | 64 | 64 | 80P / 48D | ~1178 |
| 4096 GPU | 512 | 64 | 128 | 128 | 320P / 192D | ~4710 |
| 16,384 GPU | 2048 | 128 | 256 | 256 | 1280P / 768D | ~18,842 |
"等效 ROFT GPU 吞吐"按 +15% 算。反过来,达到同等 ROFT 集群吞吐,ZCube 所需 GPU 约为 N_roft/1.15。
16,384 的端口问题
原文说 51.2T、128×400G 交换机可到 16,384 张 400Gbps NIC。按端口公式,16,384 对应 256 个逻辑端口/交换机。工程上更合理的理解是 400G NIC 拆成 2×200G 逻辑端口,交换机按 256×200G breakout 计算。如果坚持每个逻辑端口都是完整 400G 且交换机只有 128 个逻辑端口,单平面更干净的规模是 4096 GPU,16K 需要多平面或更高 radix 交换机。
规模定了,但 GPU 物理放在哪里——Prefill 集中放还是分散放——会直接影响 ZCube 的效果。
六、Cell 内 P/D 放置:均匀撒点,不要物理分区
ZCube 的意义在于把 PD 分离下动态、不对称的 KV cache 传输打散。cell 内策略的核心是:不要再人为制造一个 P 区到 D 区的大流量切面。
错误做法:
Rack/Zone A: 全部 Prefill
Rack/Zone B: 全部 Decode
这样会把所有 KV cache transfer 压到 A→B 的若干链路上,直接违背 ZCube 的设计初衷。
正确做法: 每个拓扑小片区里同时有 P 和 D,每个奇数/偶数交换机维度上 P/D 密度都接近全局比例。
Affinity Tile 分片
以 1024 GPU / 128 节点为例,通用 3:2 方案:
- 25 个 tile,每个 tile = 3P + 2D
- 3 个 flex 节点跨拓扑均匀放置
- 合计 75P + 50D + 3 flex
tile 不是物理连续的一排机器,而是跨 ZCube 的两个交换机维度做均匀散列。目标是让每个 switch 看到的 P/D 端口数都接近全局比例。
| 方案 | Tile 组成 | Tile 数 | Flex | 适用场景 |
|---|---|---|---|---|
| 通用 3:2 | 3P + 2D | 25 | 3 | 通用 coding agent |
| 偏 P-heavy 5:3 | 5P + 3D | 16 | 0 | 长输入、短输出 |
| 均衡 1:1 | 4P + 4D | 16 | 0 | 长 reasoning、多轮 agent |
Flex Pool 弹性机制
3 个 flex 节点的默认角色按实时负载动态切换:
- 长 prompt 高峰:转 P
- 长 output / D cache 高峰:转 D
- 故障时:补损坏节点角色
如果确认业务偏长输入,可以把 flex 默认放 P,变成 78P/50D 或 80P/48D。
什么时候改 P/D 比例,什么时候只改配对策略
应该增加 P 的信号: Prefill queue P95/P99 高、P GPU 利用率高 D 低、KV transfer 不拥塞、D memory 充足、TTFT 主要卡在 prefill wait。
应该增加 D 的信号: Decode queue 高、D KV memory 接近上限、活跃 session admit 失败、output token backlog 高、P 节点经常等 D lease。
不应该改比例,应该改配对/路由的信号: P 和 D GPU 都没满,但 KV transfer P99 很高、某些 inter-switch edge 热、某些 D ingress 爆、TTFT 偶发长尾。这说明问题不在数量,在配对和路由——先调度,不要先加机器。
确定了 P 和 D 的数量和位置,还有一个关键问题:当一个推理请求到来时,选哪个 P 来处理输入、哪个 D 来生成输出?这个"配对"决策直接影响网络拥塞。
七、P/D 配对:亲和组 + 动态选择,不要固定绑定
不要固定 P-D pair
固定绑定(P1 永远配 D1)简单但有三个问题:某个 D 慢了会拖累绑定的 P;长 prompt 和短 prompt 无法动态错峰;D 端 KV memory 容易碎片化,局部满、全局空。
更好的方式是 affinity tile + 动态选择:
Tile-17:
P: P17-0, P17-1, P17-2
D: D17-0, D17-1
P 候选 D 优先级:
primary: same tile D
secondary: adjacent topology tile D
tertiary: any D in same cell
last: cross-cell overflow
新会话 vs 老会话:配对方向不同
新会话:P/D 联合选择。 没有历史 KV,先估算 prompt tokens / output tokens / KV bytes,联合选择 (p,d) pair:
score(p,d) = α·Qp + β·Qd + γ·Tkv(p,d) + δ·Hpath(p,d) + ε·Md − ζ·Acache
选分数最低的 (p,d)。
老会话:D 粘滞,P 反向选择。 多轮 agent 或 coding session 已在某个 D 上有 KV cache,不要随便换 D,否则要搬历史 KV,成本很高。老会话优先继续使用 D_home,选择离 D_home 拓扑上更合适的 P 做增量 prefill,只传新增 KV。
这对 coding agent 很关键——它经常是多轮长上下文,不是一次性 prompt。
KV Transfer Credit:先 Lease,再传 KV
PD 分离最危险的场景:多个 Prefill 同时完成,调度器发现某个 D 空闲,多个 P 同时把 GB 级 KV 打给同一个 D,D ingress、最后一跳、D NIC、D KV allocator 同时爆,TTFT P99 抖动。
解决方案:D 端维护 KV ingress credit。 只有当 D 和路径都有 credit,P 才能开始发 KV。建议每个 D 同时接收大 KV stream 控制在 2~4 条,长 prompt 必须提前 reserve path credit,短 prompt 可走 best-effort。
利用 ZCube 的双路径做负载感知选路
ZCube cell 内,每个节点有两个拓扑坐标:P = (A_p, B_p),D = (A_d, B_d)。P 到 D 通常有两条两跳路径:
path 1: P → A_p → B_d → D
path 2: P → B_p → A_d → D
调度器不只看 D 有没有空,还要看哪条路径更空。不建议细粒度 per-packet ECMP(KV transfer 通常很大,乱序影响 RDMA/TCP 效率),建议按 TP rank 分流或按请求级别选路。例如 8-GPU TP 组:rank 0,2,4,6 走 path1,rank 1,3,5,7 走 path2。
TP Rank 一致性
GLM-5.1 这种大模型推理,P 和 D 都是 TP=8 时,建议强制 Prefill TP rank i → Decode TP rank i。不要 P rank i → D rank j,除非明确要做 KV reshape,否则多出一次 all-to-all 或 KV 重排,直接抵消 ZCube 的网络收益。
ZCube 是一个很好的方案,但它需要重建整个物理网络,而且完全二部图的互联复杂度随规模增长很快。一个自然的问题是:能不能找到一个更务实的方案,不要求重建网络,也能支持 PD 分离推理?
八、RailFly:训练+推理混合负载的务实选择
设计出发点
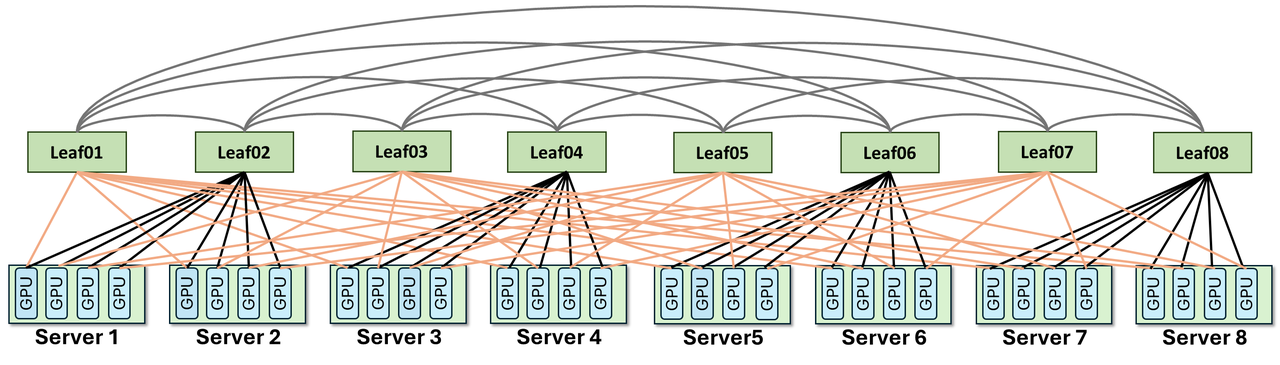
Rail-Only(MIT CSAIL + Meta, 2023)的核心洞察:LLM 训练中 99%+ 跨节点通信发生在同 rank GPU 之间,Spine 大部分时间空转,可以去掉。可以理解为"去掉上层交换机,只保留每条 rail 的独立交换机"——最省钱,但跨组通信要靠软件转发。训练最优(同 rank 1 跳),成本极低(比 Clos 省 38–77%)。但 PD 分离推理基本不可用:跨 rail GPU 软件转发延迟不稳定,P99 恶化严重。
问题在于:P→D 的 KV Cache 流不是稳定同 rail 通信,而是动态、非对称、源目的变化大。 纯 Rail-only 更依赖 NVLink/HB domain 转发,容易把 TTFT 尾延迟转移到别处。
RailFly 的思路:在 Rail-Only 基础上,以最小改动获得跨 rail 硬件转发能力。
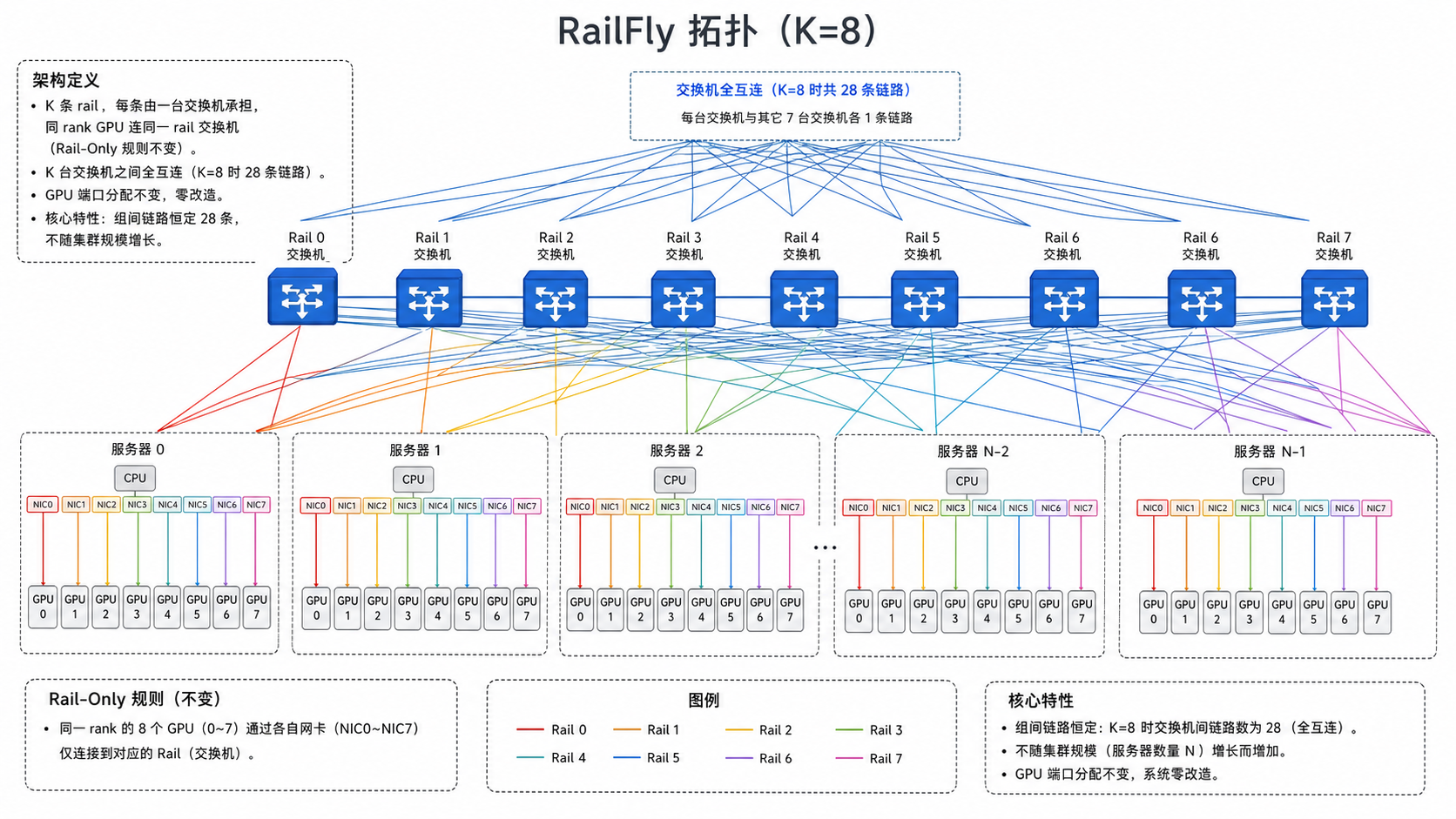
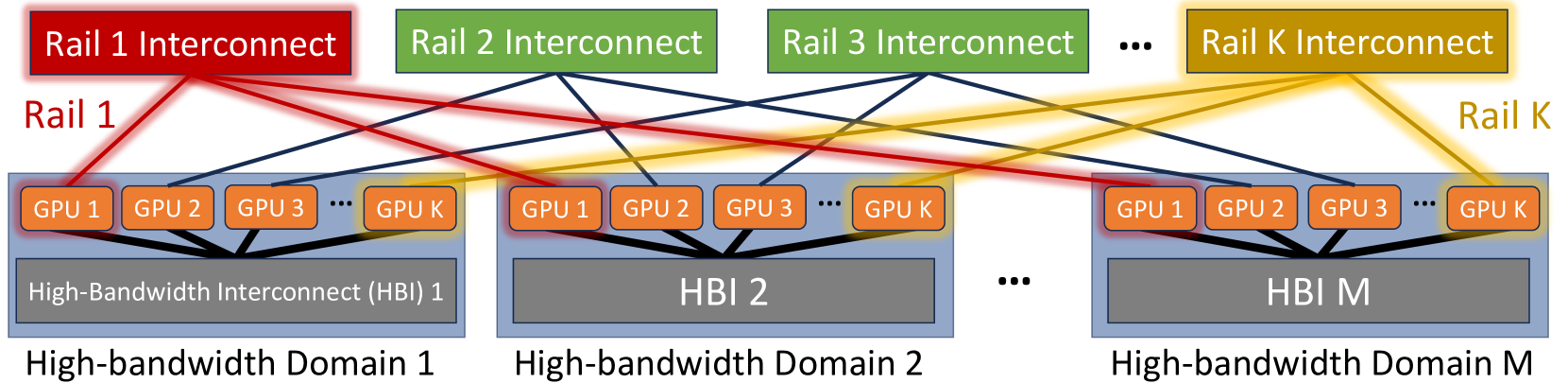
架构定义
- K 条 rail,每条由一台交换机承担,同 rank GPU 连同一 rail 交换机(Rail-Only 规则不变)。
- K 台交换机之间全互连(K=8 时 28 条链路)。
- GPU 端口分配不变,零改造。
核心特性:组间链路恒定 28 条,不随集群规模增长。
规模与收敛比
| 方案 | 每 rail 端口 | 总 GPU 数 | 组间链路 |
|---|---|---|---|
| 8× 盒式 51.2T | 121 | 968 | 28 条 |
| 8× 框式 Arista 7800R3 | 569 | 4,552 | 28 条 |
| 8× 框式 H3C S12500R | 761 | 6,088 | 28 条 |
对比 ZCube 的扩展复杂度:
| GPU 数 | RailFly 组间链路 | ZCube 二部图链路 |
|---|---|---|
| 1,000 | 28 | 15,876 |
| 4,000 | 28 | 250,000 |
| 8,000 | 28 | 1,000,000 |
收敛比 = 下行 GPU 带宽 / 上行组间带宽。高收敛比不意味着拥塞——如果 rail-aware 调度器做到 90% PD 配对在 rail 内,跨 rail 仅 10%,10:1 收敛比足够。收敛比不是纯网络参数,而是网络与调度器的联合优化问题。
同等 128 台交换机下,RailFly 每 GPU 占 1 端口、互联占比 5.5%,可连接约 15,488 GPU;ZCube 每 GPU 占 2 端口、互联占比 50%,上限 4,096 GPU。同等硬件预算下,RailFly 可连接约 3.8 倍 GPU。

RailFly 是一个拓扑族,可以根据需求做不同深度的改造——从最简的交换机全互连,到更精细的 Hybrid ZRail 和 Sparse-ZCube。
九、从 Rail-Only 到 Hybrid ZRail / Sparse-ZCube
Rail-only 加交换机直连,会逐步变成 ZCube 或 Sparse-ZCube,而不是传统 Rail-only。更优的改法是做 PD-aware Hybrid ZRail:
1. Cell 内 ZCube/full-bipartite: 1024~4096 GPU cell 内,完整二部图保证任意 P→D 两跳、路径确定、负载打散。
2. Cell 间 sparse expander/dragonfly-like 直连: 超过 4K 不必全局 full-bipartite,调度尽量把 P 和 D 放在同 cell,跨 cell 只做 overflow。
3. 双轨 QoS 隔离: 一条 rail 走传统 rail/local collective,一条走 ZCube/expander,QoS 隔离 KV transfer、control、collective。
4. 拓扑感知调度: Decode 选择不只看 GPU 空闲,还要看 P switch 到 D switch 的边负载、D 池队列和最后一跳 incast。
5. Sparse 直连度数 d 按流量定: 端口预算 R = k + d,full ZCube 是 d = S;PD 流量有局部性时,用 d << S 的 expander 可能更省成本。
判断标准: 最强鲁棒性、随机 P→D、多租户混跑用 ZCube/full-bipartite;能控制 P/D placement、缓存局部性高、业务 trace 稳定用 Sparse-ZCube / Hybrid ZRail。纯 Rail-only 不建议直接用于 PD 分离推理主网。
前面所有方案都把 KV 传输当作"公平对待的流量"。但 PD 推理的 KV 传输有特殊性——大小可预知、方向是 P→D 单向、D 端容易被打爆。如果能利用这些特殊性,设计一个"专门为 KV 传输优化"的网络层,效果可以超过 ZCube。
十、RailFly 的纯推理进阶:Rail-Fabric
ZCube 是一个很好的静态拓扑。但 PD 推理并不完全是任意流量——它有四个可以被更强架构利用的特征:
- P→D KV 流很大,且在 prefill 开始时就能估算大小;
- D 是状态驻留点,多轮 session 通常应该粘在同一个 D 或 D group;
- warm prefix / repo cache 有明显局部性;
- D 端容易出现 ingress incast,而不是普通均匀 all-to-all。
所以,更强架构不应该只问"任意两点几跳到达",而应该问:
- 大 KV 流是否可以预约无拥塞路径?
- D 端 ingress 是否被过度共享?
- cache 命中请求是否避免跨 cell 搬 KV?
- 调度器是否能在 prefill 之前确定 D,并提前布好路径?
Rail-Fabric 是 RailFly 在纯推理场景的进阶形态:保留标准以太网交换机的基础,通过稀疏 expander 底座 + KV Fast Lane + Cache/Home 逻辑平面,在不引入 OCS 或专用硬件的前提下,获得比 ZCube 更强的 P99 TTFT 和 D 端 incast 控制。
三层能力
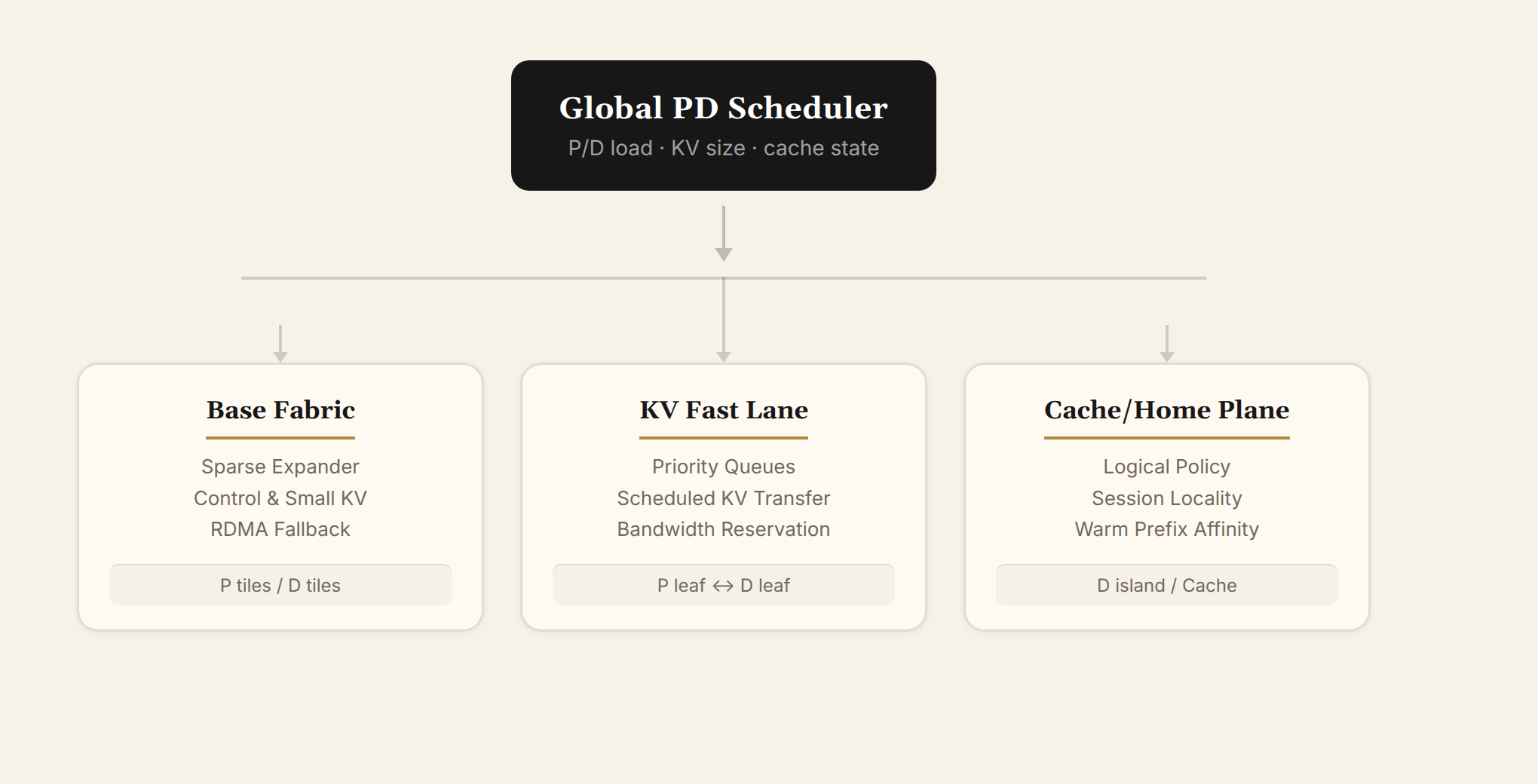
基础平面(Sparse-ZCube / Expander): 负责控制流、小 KV、故障兜底、普通 RDMA。不追求完整二部图,每个 switch 用 k 个 GPU downlink + d 条电分组 expander link + q 条 KV fast lane 专用链路。expander 是一种"稀疏但高连通"的互联结构——每台交换机只需连少数几条跨组链路,就能让全网任意两点低跳数到达。与完全二部图相比,expander 用更少的链路就能实现近似的全网可达性。
KV Fast Lane(纯以太网 QoS + 专用链路): 负责 GB 级 P→D KV cache 迁移。不引入 OCS,而是通过专用以太网链路 + 优先级队列 + 调度器预约实现大 KV 流的无拥塞传输。每个 switch 预留 8~12 条高优先级链路专门服务 KV burst,与基础平面的 expander link 做物理隔离或严格 QoS 隔离。调度器在 prefill 开始前按 KV size 预约 D ingress credit 和链路带宽配额。
Cache/Home 逻辑平面: 让长会话、warm prefix、共享 repo cache 尽量留在同一个 D island。warm session 优先回到原 D island,cold long prompt 才走全局 KV fast lane。
为什么 Rail-Fabric 比 ZCube 更强
P99 TTFT 更强。 ZCube 降低的是拓扑性拥塞概率;Rail-Fabric 进一步减少大 KV 流的排队和冲突。调度器在 prefill 开始前就知道大致 KV size,提前预约 D buffer、D ingress 和链路带宽配额。
D 端 incast 更强。 Rail-Fabric 可以把 D 侧设计成非对称——D-bearing switch 有更多 inter-switch link、更高 ingress credit、更多专用 KV fast lane 链路。这更符合 PD 分离的真实流量特征。
16K 以上扩展性更强。 ZCube 完全二部图在 16K 时需要 256 逻辑端口/交换机。Rail-Fabric 的 expander degree d ≈ 8~16,KV fast lane q ≈ 8~24,规模增加时近似常数或缓慢增长。代价是必须依赖调度器和流量局部性。
Cache-heavy coding agent 更强。 ZCube 优化"传得更顺",Rail-Fabric 还优化"少传、近传、只传 delta"。对多轮 coding session,同一 session 留在同一 D group、同一 repo cache 留在同一 cache island、Prefill 反向选择离 D/cache 近的 P。
1024 GPU Cell 落地
沿用 128 个 8-GPU 节点、75P/50D/3 flex、25 个 3P+2D affinity tile 的基础配置:
64 台以太 switch
每台 switch:
32 个 GPU/NIC downlink
8 条 expander inter-switch link(基础平面)
8~12 条 KV fast lane 专用链路(QoS 隔离)
ZCube 对比: 32 downlink + 32 inter-switch = 64
Rail-Fabric: 32 downlink + 8 expander + 8~12 KV fast lane = 48~52
请求调度流程:
- Warm session: D-first,优先 D_home,选离 D_home 近且空闲的 P,只传 delta KV
- Cold long prompt: P/D joint select,预约 D ingress credit,预约 KV fast lane 带宽配额,P write-mode 推 KV 到 D
- Short prompt: 走基础 expander 平面,不占 KV fast lane
核心:大 KV 走预约的 KV fast lane,小 KV 走基础 expander,warm KV 尽量不跨远距离,D ingress 必须有 credit。
简化版:D-centric Asymmetric Expander
如果不想做 KV fast lane + QoS 隔离的复杂度,可以做更简化的纯以太方案:
- 取消 spine,switch 之间不是完整二部图而是高质量 expander
- D-bearing switch 的 inter-switch 度数高于 P-bearing switch
- D 节点有更多上联/更高 credit
- P/D placement 严格 cache-aware 和 tile-aware
普通 P switch: 32 downlink + 8 expander links
D-heavy switch: 24~28 downlink + 12~16 expander links
比 ZCube 少一些静态 inter-switch link,比 Rail-only 更支持跨 rail P→D,比普通 expander 更照顾 Decode ingress。但如果 P→D 完全随机且 cache locality 低,稳定性弱于 ZCube。适合成本敏感、但调度器可控的场景。
十一、三种纯以太架构的定位
| 架构 | 适合场景 | 相比 ZCube 的优势 | 主要风险 |
|---|---|---|---|
| ZCube | 通用、随机 P→D | 简单、稳、静态拓扑强;容错优势(单 ToR 故障仅降 2.8%);ATOP 自动搜索发现 | 不利用 cache locality;大 KV 和小流量共享链路 |
| RailFly | 训练+推理混合、万卡扩展 | 组间复杂度不增长;同等硬件 3.8× GPU 容量 | 跨 rail 带宽依赖调度器配对质量 |
| Rail-Fabric(RailFly 纯推理进阶) | 长上下文、GB 级 KV、多轮 agent | P99 TTFT、D incast、16K 扩展性更强 | 控制面复杂;QoS 隔离需要交换机支持 |
十二、场景推荐与部署建议
从最简到最强,三条路径对应不同的起点和目标。
| 场景 | 推荐 | 原因 |
|---|---|---|
| 纯 PD 分离推理(千卡级) | ZCube cell | 负载均衡最优,+15% 吞吐 |
| 纯训练 | Rail-Only | rail 局部性是关键 |
| 训练+推理混合 | RailFly | 两者兼顾,扩展简单 |
| 万卡以上混合负载 | RailFly + Hybrid ZRail | 组间复杂度不随规模增长 |
| 长 KV + 多轮 agent + 可控调度 | Rail-Fabric | 大 KV 走 KV fast lane,cache-aware 少搬 KV |
三档部署建议
第一档,千卡生产验证: 1024 GPU,128 个 8 卡节点,ZCube cell,75P/50D/3 flex,25 个 affinity tile。最稳的起手方案。
第二档,规模化生产: 4096 GPU,512 个 8 卡节点,单 cell 或 4 个 1024-GPU cell,默认 320P/192D。16K GPU 建议拆成 4×4096 cell。
第三档,下一代专用推理集群: Rail-Fabric = Sparse expander + 以太网 KV fast lane + cache-aware D island + D-centric endpoint oversubscription。全部基于标准以太网交换机,适合长上下文 coding agent 的 GB 级 KV 场景。
一句话总结
ZCube 是"更好的静态以太网";比 ZCube 更强的纯以太 PD 推理网络应该是"稀疏 expander 底座 + KV fast lane 专用链路 + cache-aware 调度"——全部基于标准以太交换机,不依赖 OCS 或 scale-up 专用硬件。而 RailFly 在这个谱系中找到了训练+推理混合负载的务实落点:组间链路恒定 28 条,跨 rail 硬件转发,同等硬件 3.8 倍 GPU 容量。
参考文献
- Yan, Z., et al. From ATOP to ZCube. ACM SIGCOMM 2025.
- Ghobadi, M., et al. Rail-only: A Low-Cost High-Performance Network for Training LLMs with Trillion Parameters. arXiv:2307.12169, 2023.
- Araujo, J., et al. Resilient AI Supercomputer Networking using MRC and SRv6. OpenAI, 2026.
- 智谱 AI 技术博客. 下一代大模型推理网络架构:ZCube 如何有效破解网络瓶颈? z.ai/blog/zcube (智谱 AI 是 ZCube 的部署验证用户,在 GLM-5.1 千卡推理集群上验证了 ZCube 拓扑)
- Wang, Z., et al. Opus: An Elastic, Reconfigurable Optical Interconnect for Compute Pods. NSDI 2026.
- Together AI. Chunked Prefill-Decode Disaggregation for Long-Context Serving. 2026.
- FlowKV: Global KV Cache Management for Disaggregated LLM Serving. 2026.