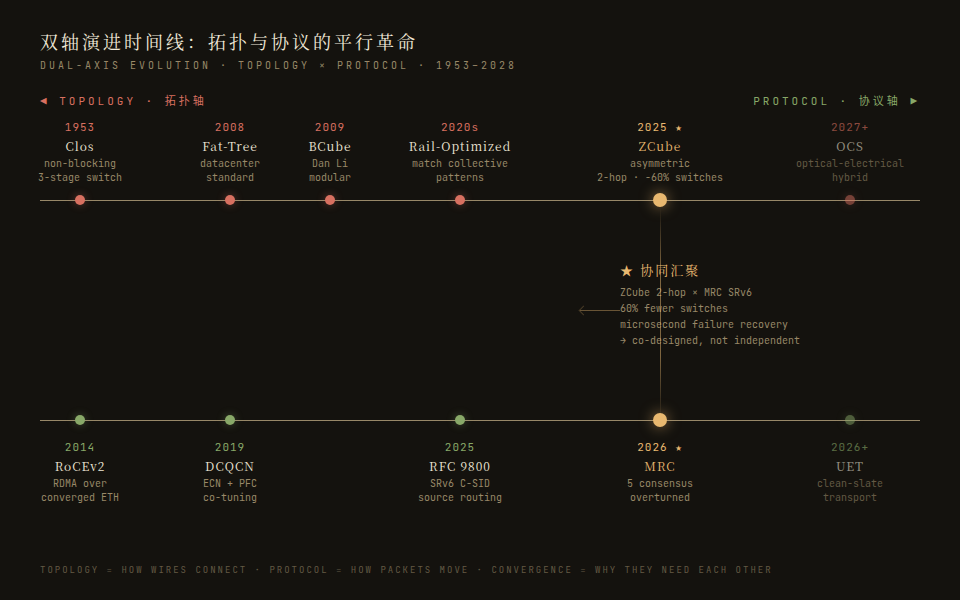
两场革命,一张网络:AI 训练集群的拓扑与协议协同重构
10 万 GPU 规模的 AI 训练网络,正在物理层(拓扑)和逻辑层(协议)同时经历范式重构。ZCube 用非对称拓扑省掉 60% 交换机,MRC 把智能从交换机推到网卡——但真正的故事是:这两场革命互为前提,必须协同设计。本文建立双轴框架,覆盖 RoCEv2→MRC→UET 协议演进、Clos→Rail→ZCube→OCS 拓扑创新、芯片/设备/云厂商格局,最终给出按规模和场景的决策框架。
本文是三篇系列的全景综述。姊妹篇之一「从 CLOS 到 ZCube:智算集群网络拓扑演进」深入分析拓扑设计的物理层创新——ATOP 自动搜索、非对称结构、甜点规模、物理约束。姊妹篇之二「从 RoCE 到 MRC:AI 集群传输协议与芯片重构」深入分析传输协议演进与芯片实现——EV 状态机、SRv6 uSID、NIC/交换机芯片重构、中国产业差距。
一个问题,两个维度
2025 年底,OpenAI 的生产集群跑着 131,072 块 GPU。字节跳动的训练集群达到 16,384 块 GPU。Google、Meta、阿里、微软都在向 10 万 GPU 规模逼近。
在这个规模上,传统数据中心网络的设计假设全面崩塌。但崩塌不是发生在一个地方——而是同时在两个维度上发生:
物理层:线怎么连。 传统三层 Clos 在 10 万 GPU 规模下需要四层交换机,光模块数量爆炸,延迟叠加严重。拓扑设计从"怎么连得多"变成"怎么连得聪明"。
逻辑层:包怎么转。 RoCEv2 的 ECMP 哈希在大规模下必然产生 flow collision,PFC 在多层拓扑里形成连锁风暴,动态路由收敛需要秒级而训练 job 需要微秒级。协议设计从"怎么转得稳"变成"怎么转得快且不怕坏"。
过去三年,这两个维度各自出现了一次范式级突破:
- 拓扑端:字节跳动 2025 SIGCOMM 最佳论文 ZCube,把拓扑设计从"专家直觉"变成"自动搜索",发现非对称结构在 AI 训练场景下始终优于对称结构,在甜点规模省掉 60% 交换机。
- 协议端:OpenAI 联合 NVIDIA/AMD/Broadcom/Cisco/Arista 推出 MRC 协议,同时推翻了数据中心网络三十年的五个共识——从 ECMP 到 PFC 到动态路由全部重写,核心思想是把智能从交换机推到网卡。
但这两场革命不是独立发生的。ZCube 的 2 跳直径大幅简化了 MRC 的故障检测;MRC 的 SRv6 静态源路由让非对称拓扑的路径管理变得可行。 它们是同一个问题的两个面,必须放在一起理解。
拓扑革命:从通用无阻塞到 AI 负载专用
Clos 的三个假设
1953 年 Charles Clos 提出的无阻塞多级交换网络,构成了现代数据中心 Fat-Tree 拓扑的基础。1985 年 Charles Leiserson 将其引入并行计算。它有三个隐含假设:
- 流量模式不可预测——需要"任意输入到任意输出"的全二分带宽
- 大量独立小流——ECMP 哈希在统计上均匀分散
- 交换机同构——同一端口数、同一规格,简化采购和运维
在 AI 训练场景下,这三个假设全部动摇:集合通信模式高度规律(AllReduce/All-to-All 每个 step 重复相同模式,不需要"任意到任意");大象流容易碰撞(ECMP 在少量大流下不均匀);ATOP 的自动搜索发现非对称结构始终优于对称结构。
规模天花板: 三级 64 端口交换机构建的胖树最大支持约 32K 端点;四级可到 ~64K,但延迟和成本急剧上升。三层 Clos 在 10 万 GPU 规模下要么需要四层(更高延迟/成本),要么 oversubscribe(带宽不保证)。
Rail-Optimized:从"通用连接"到"匹配通信模式"
NVIDIA DGX SuperPOD 参考架构采用的 Rail+Global 设计,代表了拓扑演进的第一步——不再追求全连接,而是匹配 AI 训练的实际通信模式。
核心思想:一台 GPU 服务器有 8 个 GPU,每个 GPU 有自己的 NIC。将所有服务器中相同位置的 GPU 连到同一台交换机,形成 8 条独立的 Rail。同 rank GPU 间通信只需单跳,大部分流量被吸收在 Leaf 层,Spine 压力降低。
Rail-Only vs Rail+Global: Rail-Only 省去顶层交换机、成本最低,但只支持高度局部化通信(如纯数据并行)。Rail+Global 增加 Spine 层支持 All-to-All 等全局通信,但成本上升。Rail-Optimized 拓扑对 AI 有效,但本质仍是对称拓扑——它没有挑战"交换机必须同构"的假设。
→ Rail-Optimized 拓扑的详细设计和 PD 分离推理场景分析,见姊妹篇之一。
ZCube:把拓扑设计变成超参数搜索
字节跳动联合清华大学的 ATOP(Automated Topology Optimization Pipeline)做了一件简单但从未有人做过的事:把拓扑设计的所有决策编码成 11 类超参数,用 NSGA-II 进化算法搜索 Pareto 前沿。
11 类超参数覆盖层间连接(GPU 数量、层数、每层节点数、分块参数、连接数、带宽因子 200G-800G)和层内连接(维度数、每维节点数、外向连接数、坐标计算因子),将搜索空间从邻接矩阵的 O(2^N²) 压缩到单台 256 核服务器 3 天内可搜索完毕。
14 个优化目标:9 个 DP/PP/Mixed 流量 JCT + 2 个 MoE JCT + ForestColl all-gather + APS 故障容错 + 成本。流级仿真器与 NS-3 包级仿真对比平均误差仅 1.5%。
非对称结构的发现: 在 256/1024/4096/16384 四个 GPU 规模的搜索中,Pareto 前沿拐点处的最优解都呈现相同的非对称特征——首尾层 2n 端口、中间层 3n 端口。论文将其形式化定义为 ZCube。
ZCube(n,k) 递归定义:
- ZCube(n,1) = 1 个交换机 + n 个 GPU
- ZCube(n,k+1) = n × ZCube(n,k) + n^k 个交换机
- GPU 数 = n^(k+1),交换机数 = (k+1) × n^k,每个 GPU 有 k+1 个 NIC 端口
关键参数: 网络直径 = k(ZCube(128,2) 的直径仅 2,vs 三层 Clos 的 5-7 跳)。低直径直接降低 PP 流量完成时间——这是端到端训练加速的主要来源。
16K GPU 定量对比
以 Broadcom Tomahawk 5(51.2T)交换机为例:
| 拓扑 | 交换机数 | 线缆 | 训练迭代时间 | 网络成本 |
|---|---|---|---|---|
| ROFT | 640 | 49,152×400G | 5.19s | $92.93M |
| Rail-only | 384 | 32,768×400G | 5.15s | $76.38M |
| HPN | 384 | 16,384×400G + 32,768×200G | 5.10s | $84.03M |
| ZCube(128,2) | 256 | 49,152×200G | 4.95s | $57.28M |
ZCube 交换机比 ROFT 少 60%,用 200G 线缆(vs 400G)光模块成本减 25-50%,训练速度快 3-7%,网络成本低 26-46%。
甜点规模与生产验证
ZCube(n,k) 要求每个 GPU 有 k 个 NIC 端口。k=2 意味着每 GPU 需 2 个端口(1 张 800G NIC breakout 成 2×400G),这是大多数服务器能支持的。k=3 大多数服务器做不到。
| GPU 规模 | 最优 ZCube | 交换机数 | 值得? |
|---|---|---|---|
| <500 | — | — | ❌ Flat 最优 |
| 512 | ZCube(23,2) | 46 | ⚠️ 优势不大 |
| 1024 | ZCube(32,2) | 64 | ✅ 甜点 |
| 4096 | ZCube(64,2) | 128 | ✅ |
| 16384 | ZCube(128,2) | 256 | ✅ 论文核心案例 |
1024 GPU 的 ZCube(32,2) 是甜点:64 口交换机完美映射 Tomahawk 5 标准配置,零端口浪费。智谱 AI 千卡推理集群从此规模受益——节省 1/3 光模块和交换机,推理吞吐提升 15%。
容错方面:16K GPU 单 ToR 故障时 ZCube 性能仅下降 2.8%(vs ROFT 的 46.9%)。无故障概率 ZCube 93%(vs ROFT 83%),交换机少本身就是更高可靠性的来源。
→ ZCube 的完整分析(ATOP 方法论、NVLink 域扩展、容错分析、生产验证细节、OCS 对比),见姊妹篇之一。
OCS:拓扑演进的另一条路线
ZCube 是"在电交换框架内优化拓扑"。还有一条路线:用光路交换(OCS)替代 Spine 层电交换机。
Google Apollo 从 2022 年起大规模部署 OCS(3D MEMS 微镜阵列),SemiAnalysis 估计节省超过 30 亿美元。SIGCOMM 2025 的 InfiniteHBD 更进一步——在光收发器级别集成动态连接能力。
| 维度 | 电交换 | OCS |
|---|---|---|
| 切换粒度 | 包级(μs) | 电路级(ms) |
| 延迟 | 多跳累积 | 全光路径,极低 |
| 功耗 | 每跳电处理 | 光路直通 |
| 适用场景 | 通用 | 粗粒度、可预测流量 |
OCS 的胜利条件:大流量、可预测模式、规模足够大使得 Spine 层成为瓶颈。AI 训练的集合通信正好满足。ZCube 和 OCS 不是竞争关系——ZCube 省电交换机,OCS 替 Spine 层,两者可以在不同规模点互补。
拓扑演进小结
四条演进方向并行:
- 从对称到非对称(ZCube)——ATOP 搜索证明非对称更优
- 从三层到两层(MRC 多平面 Clos)——OpenAI/Microsoft 压缩到两层
- 从电交换到光电混合(Google Apollo OCS)——Spine 层用光替代电
- 从交换机智能到端点智能(MRC)——路由决策权从交换机转移到 NIC
→ 拓扑的完整演进路径、定量对比、NVLink 域扩展、容错分析、物理约束(光模块成本、机柜功率、连线距离对拓扑选择的硬限制),见姊妹篇之一。
协议革命:从交换机智能到网卡智能
RoCEv2:现状与局限
RoCEv2(RDMA over Converged Ethernet v2)是当前 AI 训练网络的事实标准。延迟 2-5μs,运维成熟,跟 InfiniBand 性能差距仅 0.5%-3%。Meta 在超过 30K GPU 上大规模部署 RoCEv2 + DCQCN + ECN,是业界标杆。
但规模继续扩大,三重瓶颈连锁爆发:
ECMP 哈希冲突。 每条流被哈希到一条路径。AI 训练产生少量大象流(集合通信),两个大流撞到同一条链路就拥塞。规模越大,碰撞概率越高。
PFC 风暴。 RoCEv2 依赖 PFC 实现无损传输——接收端 buffer 快满了发 pause frame 让发送端停下。在多层拓扑里 pause frame 沿上游传播形成 head-of-line blocking,不同优先级的 pause frame 甚至可以互相死锁。
动态路由收敛。 BGP/OSPF 在链路故障后重新计算路由表,需要几十毫秒到几百毫秒。训练 job 对延迟极其敏感,一次收敛就可能导致 AllReduce 超时。
Meta 的 Ghost 论文(SIGCOMM 2024)揭示了更深层的问题:链路抖动导致拓扑知识失效,产生"幽灵"节点。这不是"修修 RoCEv2 就好"的问题——是设计假设在大规模下系统性崩塌。
RFC 9800:SRv6 源路由的基础设施
RFC 9800(2025 年 6 月发布)定义了 Compressed SRv6 Segment List Encoding(C-SID/uSID/micro-SID)。SRv6 每个标准 SID 占 128 bit,10 段路径需要 160 字节开销,在大规模数据中心不可接受。C-SID 将多个 16-32 bit 压缩 SID 打包进一个 128-bit 容器,SRH 开销降低 50%+。
两种实现路线:NEXT-C-SID(Cisco/F5 主推,shift-and-lookup)和 REPLACE-C-SID(中国移动 2022 年云骨干网大规模部署,10+ 厂商互操作测试)。
对 AI 网络的意义:源路由实现多路径——发送端在包头编码完整路径,交换机无需运行动态路由。C-SID 压缩使编码开销可控。微秒级故障绕行——路径信息在包头而非转发表中,NIC 检测到故障后立即切换备用路径。
MRC:推翻五个共识
2026 年 5 月,OpenAI 联合 AMD/Broadcom/Intel/Microsoft/NVIDIA 在 OCP 发布 MRC(Multipath Reliable Connection)。不是修补 RoCEv2,是逐条推翻:
| 共识 | 传统做法 | MRC 做法 | 核心变化 |
|---|---|---|---|
| 负载均衡 | ECMP 哈希(流级别) | Entropy Value 包喷射(包级别) | 消除 flow collision |
| 无损传输 | PFC(pause frame) | 禁用 PFC + 选择性重传 | 消除 head-of-line blocking |
| 有序交付 | 单路径有序 | 乱序直写(每包携带虚拟地址) | 消除排序延迟 |
| 路由 | 动态路由(BGP/OSPF) | SRv6 uSID 静态源路由 | 消除收敛延迟 |
| 拥塞控制 | 交换机+主机协同 | 交换机只做 ECN 标记 | 消除控制平面冲突 |
设计哲学:把智能从交换机推到网卡,让交换机回归无状态转发。
MRC 是对 RoCEv2 RC 传输层的最小化扩展,仅保留 RDMA Write 和 Write-with-Immediate(AI 工作负载只需子集功能),复用现有 RDMA Verbs/QP 体系。MRC 明确"借鉴了 UET 的多项技术"(论文原文)。
多平面两层 Clos: 每个 800G NIC breakout 为 8×100G 连 8 台 T0 交换机。51.2T 交换机从 64×800G 变为 512×100G,单平面容纳 131,072 GPU。与三层拓扑相比:光模块只需 2/3,交换机只需 3/5,最长路径仅 3 跳。
生产部署: OpenAI 最大 NVIDIA GB200 超算(包括 Oracle/OCI 德州 Abilene 站点)、Microsoft Fairwater(Atlanta + Wisconsin)。训练过程中热重启 4 台 T1 交换机,无需协调训练团队,任务继续运行。
UET:并行演进
UEC(Ultra Ethernet Consortium,120+ 成员,Linux Foundation 历史上增长最快的工作组)2025 年 6 月发布 UET Specification 1.0。技术根基约 75% 来源于 HPE Slingshot 传输协议。
UET 与 MRC 共享多项核心概念:包喷射、乱序放置、选择性重传、packet trimming。关键差异:
| 维度 | MRC | UET |
|---|---|---|
| 设计路径 | RoCEv2 RC 最小扩展 | 全新传输栈 |
| 软件接口 | RDMA Verbs(Write+WriteImm) | libfabric v2.0 |
| 流控 | 禁用 PFC | Credit-based |
| 源路由 | SRv6 uSID | 无(依赖交换机路由) |
| 部署门槛 | 中(MRC NIC + SRv6 交换机) | 高(全新软件栈) |
| 生产验证 | OpenAI/MS 131K GPU | 规范刚发布 |
AMD 贡献的 NSCC 拥塞控制算法同时成为 UEC 拥塞控制规范的一部分。MRC 和 UET 是互补而非竞争——MRC 走实用主义快速部署,UET 走全新传输栈长期演进。
InfiniBand:封闭生态的最后堡垒
NVIDIA 通过收购 Mellanox 主导 IB 生态。XDR(800 Gb/s)正在部署(Quantum-X800 + ConnectX-8),GDR(1600 Gb/s)在路线图上。
IB 的技术优势:原生无损(credit-based,无 PFC 风暴)、原生多路径、超低延迟(1-2μs)、NVIDIA 全栈保证兼容性。劣势:成本高、供应商锁定(实质只有 NVIDIA)、运维人才稀缺、生态封闭。
趋势判断: IB 在 2026 年仍占高端市场,但中长期被 Ethernet(MRC/UET)蚕食是大概率事件。NVIDIA 自身也同时支持两条路线(ConnectX-8 同时支持 RoCEv2 和 MRC)。Gartner 预测到 2029 年 >65% 生成式 AI 集群将基于以太网。
协议对比矩阵
| 维度 | RoCEv2 | MRC | UET | InfiniBand |
|---|---|---|---|---|
| 多路径 | 无(ECMP 流级) | ✅ 包喷射 128-256 路径 | ✅ 包喷射 | ✅ 自适应路由 |
| 丢包恢复 | Go-Back-N/选择性重传 | 选择性重传 + trimming | 选择性重传 + trimming | 链路级+传输级重传 |
| 流控 | PFC(无损) | 禁用 PFC | Credit-based | Credit-based |
| 源路由 | 无 | SRv6 C-SID | 无 | 无 |
| 故障恢复 | 秒级(路由收敛) | 微秒级(NIC 绕行) | 毫秒级(待验证) | 秒级(Subnet Manager) |
| 部署复杂度 | 中 | 中高 | 高 | 中(NVIDIA 一体化) |
| 成本 | 低 | 中 | 中 | 高 |
| 适用规模 | ≤64K GPU | 100K+ GPU | 100K+ GPU | ≤64K GPU(经济规模) |
标准化格局
三条路线并行:IETF(SRv6/RFC 9800)提供底层源路由基础设施;OCP(MRC)走实用主义,最小化修改 RoCEv2 快速部署;UEC(UET/UEC 1.0)走全新传输栈。三者不互斥:MRC 借鉴 UET 技术,SRv6 服务于 MRC 源路由需求。
→ 协议核心机制(EV 状态机细节、SRv6 uSID 转发流程、Packet Trimming、NIC/交换机芯片定量分析)、协议对比矩阵和标准化进展(IETF/OCP/UEC/IEEE/IBTA)的详细分析,见姊妹篇之二。
为什么这两场革命互为前提
这是本文最核心的论点:拓扑和协议的这两场革命是深度耦合的协同设计,不能独立选择。

协同效应一:短直径降低协议复杂度
ZCube 的 2 跳直径不只是降低延迟——它直接简化了传输协议的所有关键环节:
- 故障检测更快: MRC 的 EV 四状态机(active → congested → suspected_failed → confirmed_failed)在每 RTT 内判断路径是否存活。2 跳拓扑的 RTT 远短于 5-7 跳的三层 Clos,收敛更快、置信度更高
- SRv6 开销更小: 2 跳只需 2-3 个 uSID 段,包头压缩后几乎无开销。5-7 跳需要更多段,累积开销挤占有效载荷
- 乱序重排更简单: 包经过的中间节点越少,乱序程度越低,NIC 端 reorder buffer 和 SACK 逻辑越轻
反过来说,MRC 在传统三层 Clos 中也能工作,但 5-7 跳路径削弱了包喷射优势,SRv6 开销更大,故障检测更慢。
协同效应二:源路由让非对称拓扑变得可行
传统 ECMP 要求多条等价路径——这隐含了对称拓扑假设。非对称拓扑(ZCube 首尾层 2n vs 中间层 3n)在 ECMP 下路径数量不等,某些链路可能被过度使用或闲置。
MRC 的 SRv6 静态源路由绕开了这个约束:NIC 在发包时编码完整路径,交换机只需按 SRv6 头转发,不需要理解拓扑结构。 路径管理从"交换机需要复杂路由协议"变成"NIC 端预计算 + 静态编码"。
没有 MRC(或类似源路由机制),ZCube 的非对称结构在生产环境中的路径管理会复杂得多。反过来,没有 ZCube 这类短直径拓扑,MRC 的包喷射和快速故障检测优势也被削弱。
协同效应三:交换机简化与拓扑成本的双重节省
| 维度 | 传统三层 Clos + RoCEv2 | ZCube + MRC |
|---|---|---|
| 交换机数量 | 基准 | -60% |
| 单交换机复杂度 | 需大量 TCAM/Buffer/PFC | 净减 ~50MB buffer,无动态路由 |
| 光模块数量 | 基准 | -40%(更短路径 = 更少光模块) |
| 故障恢复 | ~100ms(路由收敛) | ~10μs(NIC 自主绕行) |
| 每流路径数 | 1 | 128-256 |
| NIC 端开销 | 基准 | +16KB/QP(EV/SRv6/SACK/重传/OOO) |
网络成本下降不是只靠拓扑或只靠协议,而是两者协同。 交换机变简单了所以数量减少不牺牲可靠性;拓扑变浅了所以协议故障检测窗口缩短。
这不是两个独立选择的组合
- 选了 ZCube 但用 RoCEv2:非对称拓扑在 ECMP 下路径管理困难,PFC 连锁反应没有消除
- 选了 MRC 但用传统三层 Clos:5-7 跳削弱包喷射,SRv6 开销更大,故障检测更慢
- 只有两者配合,才能实现 2 跳 + 源路由 + 无 PFC + 微秒级故障恢复
→ 更详细的技术分析:姊妹篇之一「从 CLOS 到 ZCube」中的「ZCube 与 MRC 的协同」节(2 跳直径对 EV 状态机的简化、非对称拓扑对源路由的需求、k 端口与多路径的关系),以及姊妹篇之二「从 RoCE 到 MRC」中的「MRC 与非对称拓扑的协同」节(源路由让非对称可行、短路径放大包喷射效果、未探索的联合优化空间)。
芯片产业格局
NIC:从配件变成核心
传统 NIC 是服务器附属品,功能简单。MRC 让 NIC 变成网络智能的核心——EV 状态机、SRv6 编码、包喷射调度、乱序重排全部在 NIC 端完成。Per-QP 状态从 512 字节膨胀到约 16KB(EV set 2KB + SRv6 映射 4KB + SACK 0.5KB + 重传 8KB + OOO tracker 1.5KB),2000+ QP 规模下 on-chip SRAM 不够用,需要 DDR 或 HBM。
| 厂商 | 产品 | 策略 | SRv6 | MRC |
|---|---|---|---|---|
| NVIDIA | ConnectX-8 | 固件实现 + DDR 缓存 | ✅ | ✅ |
| AMD | Pollara 400 | 硬件实现 + HBM 缓存 | ✅(通过 UEC) | ✅(首款兼容) |
| Broadcom | Thor Ultra | NPL 可编程 | ✅ 原生 | ✅ 原生 |
NIC die cost 上升趋势明显:MRC 功能占 die 面积约 15-20%。对 NVIDIA/Broadcom 可接受,对后来者是更高门槛。
交换机:变简单但不变便宜
MRC 让交换机回归无状态转发——净减 ~50MB buffer + 大量 TCAM。但带宽需求指数增长:102.4T → 204.8T,需要更先进的 SerDes(200G→400G/lane)和 CPO(共封装光学)。
| 芯片 | 世代 | 带宽 | MRC 支持 | 关键特性 |
|---|---|---|---|---|
| Broadcom TH6 | 102.4T | 64×800G / 128×400G / 512×100G | ✅ 硬件支持 | Cognitive Routing 2.0, Packet Trimming (CSIG) |
| Cisco G300 | 102.4T | 64×800G | ✅ P4 实现 | uSID 加速,可编程性强 |
| NVIDIA Spectrum-6 | 102.4T | 64×800G | 有限/路线图 | 与 IB 统一运维栈 |
| Marvell Teralynx 10 | 51.2T | 64×800G | - | 当前不支持多路径 |
| 华为 CloudEngine | — | — | - | 中国市场主导 |
芯片×协议矩阵: Broadcom 凭 TH6 + Thor Ultra 端到端方案在 MRC 支持上领先;Cisco 通过 P4 可编程保持灵活性(不换硬件支持新协议);NVIDIA 在 IB 生态保持独家。MRC/UET 支持是 102.4T 世代的关键差异化——不支持多路径可靠传输的交换芯片将在 AI 市场被边缘化。
路径到 204.8T: 200G/lane SerDes 设计难度指数增长,CPO 从"可选"变为"必需",chiplet 架构的跨 die 一致性是未解决问题。
竞争格局
| 路线 | 参与者 | 优势 | 劣势 |
|---|---|---|---|
| 封闭全栈 | NVIDIA(IB+ETH+GPU)、Google(TPU+ICI+OCS) | 极致性能、紧耦合 | 高成本、供应商锁定 |
| 芯片+设备 | Cisco(Silicon One+Nexus)、华为(自研+CloudEngine) | 差异化+可控性 | 生态面窄 |
| 设备+软件 | Arista(Broadcom芯片+EOS) | 软件差异化 | 芯片依赖 Broadcom |
| 组件供应 | Broadcom、Marvell | 横向平台 | 利润率低 |
开放生态(MRC/OCP + UEC,120+ 成员)正在系统性挑战封闭生态。大部分超大规模客户选择混合策略:核心训练用 NVIDIA IB,Scale-out 和推理用开放以太网。
谁在用什么
| 云厂商 | 网络方案 | 规模 | 关键特征 |
|---|---|---|---|
| OpenAI/MS | MRC + 多平面两层 Clos | 131K GPU | MRC 最大生产部署 |
| OCS + ICI + Virgo | TPU 全栈自研 | 唯一完全自研路径 | |
| Meta | RoCEv2 + 大规模调优 | >30K GPU | RoCEv2 + ECN/DCQCN 最大规模部署;Ghost 论文揭示可靠性风险 |
| 字节 | ZCube + Rail-Optimized | 16K GPU | ZCube 论文来源 |
| 阿里 | HPN + Stellar | >15K GPU | SIGCOMM 2025 论文贡献最多(11 篇) |
| AWS | EFA/SRD | 自研 | 不走主流路线 |
| xAI | 以太网 | — | Arista + Broadcom |
软件侧共同趋势:
- AI 驱动的网络运维(AgenticOps/意图驱动网络)成为管理平台新战场
- 从"手动调 PFC/ECN 参数"走向"AI 自适应调优"
- 可观测性投入急剧增加——10 万 GPU 的网络状态无法人工巡检
中国市场的特殊性:
- 国产替代不可逆,华为 + 新华三 + 锐捷主导
- 2025 年国内 800G 交换机出货量从 2023 年 1.5 万台增长到 6 万台(CAGR >100%)
- DeepSeek 等国产大模型带动推理侧 200G/400G 交换机需求
- SIGCOMM 2025 中国机构贡献极为突出(阿里 11 篇、字节 2 篇最佳论文、清华/北大/HKUST)——超大规模实践需求驱动系统性学术创新
决策框架

按规模选拓扑 × 按场景选协议
| GPU 规模 | 推荐拓扑 | 推荐协议 | 理由 |
|---|---|---|---|
| >50K | Multi-Plane 两层 Clos | MRC + SRv6 | 故障恢复和包喷射是刚需 |
| 10K-50K | Multi-Plane 或 Rail+Global | MRC 或 RoCEv2+调优 | 过渡区间 |
| 1K-10K | ZCube / Rail-Optimized | RoCEv2 或 MRC | ZCube 甜点区间 |
| <1K | 1x1 / 扁平 | RoCEv2 | 协议选择不敏感 |
按场景的差异
大规模同步预训练(>10K GPU): 对尾延迟和故障恢复最敏感。MRC 的包喷射和微秒级故障绕行是最佳选择。Multi-Plane 两层 Clos 提供最短路径。
中等规模训练(1K-10K): RoCEv2 + DCQCN + ECN 调优在当前规模下可管理。ZCube 提供更高成本效率。
推理服务: 对成本和吞吐更敏感,对尾延迟要求低。ZCube 在推理场景优势最显著(智谱 AI 15% 吞吐提升 + 1/3 硬件节省)。
混合负载(训练+推理+通用): 考虑 RoCEv2 + UET 演进路线,或分区域部署(训练区 MRC + 推理区 ZCube)。
中国产业:差距与机会
→ 完整分析见姊妹篇之二「从 RoCE 到 MRC」中国产业章节。核心判断:
- 硬件差距: 国产 NIC 芯片在 MRC 支持上落后 1-2 代,短期无法生产 ConnectX-8/Thor Ultra 等价产品
- 软件差距: MRC 的开源实现(OCP)给追赶窗口,但需要深度参与标准制定
- 机会: 中国超大规模部署的实践需求正在驱动原创学术贡献。ZCube 本身就是字节+清华的工作
关键判断与风险
核心判断
判断一:以太网将在 3-5 年内成为 AI 后端网络的主流。 RoCEv2 + MRC/UET 系统性解决以太网在 AI 场景的三个核心短板(单路径、PFC 风暴、慢故障恢复)。InfiniBand 不消失,但从主流退守到对延迟极端敏感的高端细分。
判断二:MRC 是当前最激进的以太网方案。 MRC + SRv6 + 多平面 Clos 代表最前沿设计:消除动态路由、用源路由替代、用包喷射替代 ECMP、用多平面替代多层。OpenAI 和 Microsoft 的生产验证提供最强实践背书。
判断三:拓扑设计从"工程直觉"走向"自动搜索"。 ATOP 的方法论贡献大于 ZCube 本身——可重复使用、消除认知偏差、支持多目标。当新硬件/新模型出现时重新运行即可,无需从零设计。
判断四:开放生态正在系统挑战封闭生态。 MRC(OCP 开源)、UET(UEC 120+ 成员)、P4 可编程芯片、多供应商设备——正在构建不需要绑定 NVIDIA 的高性能 AI 网络。但 NVIDIA 最高端全栈优化仍不可替代。
判断五:中国机构在 AI 网络学术研究中已全球领先。 不是偶然——超大规模实践需求驱动系统性创新。
关键风险
- MRC 互操作性: 在多厂商异构环境中尚未充分验证。UET 仍早期,从规范到大规模部署需 1-2 年
- PFC 替代方案的不确定性: MRC 禁用 PFC、UET 用 credit-based、SIGCOMM 2025 DCP 提出第三条路——哪种能在最广场景稳定运行需更多验证
- Ghost 问题: 链路抖动导致拓扑知识失效,10 万 GPU 规模可能成为系统性风险,仅靠更快故障检测无法根本解决
- 1.6T 物理层: 200G/lane SerDes 难度指数增长,CPO 可维修性和供应链未解决,204.8T chiplet 跨 die 一致性是未知数
- 供应链地缘政治: 出口管制和国产替代要求影响设备可获得性和成本
三年路线图
2026: MRC 在 OpenAI/MS 外开始小规模部署。ZCube 在字节/智谱外被其他厂商尝试。UEC 1.0 互操作测试启动。102.4T 交换芯片量产。
2027: 800V 配电 + 102.4T + MRC 的"黄金组合"成为新建超大规模训练集群默认方案。OCS 在非 Google 环境试点。1.6T 端口和 CPO 小规模部署。
2028: UET 生态成熟,与 MRC 互补。204.8T 芯片量产。拓扑-协议协同设计成为主流方法论——ATOP 类工具集成 MRC 约束做联合搜索。
对不同角色的建议
AI 基础设施决策者:
- 短期(2026):新建训练集群优先考虑以太网 + RoCEv2,选择支持 MRC 升级路径的设备;1K-10K 规模考虑 ZCube
- 中期(2027-2028):MRC/UET 生态成熟后评估迁移;关注 1.6T 和 OCS 部署时机
- 避免锁定:选择 P4 可编程交换芯片为协议演进留空间
网络设备厂商:
- 差异化从"速率竞争"转向"架构竞争"——Buffer 管理、可编程性、负载均衡策略
- 软件价值:AI 驱动网络运维(AgenticOps)、意图驱动网络(IBN)是新战场
- 中国厂商:国产替代窗口加速,华为全栈 + 新华三 DDC 创新有差异化空间
芯片厂商:
- MRC/UET 支持是 102.4T 世代的关键差异化
- CPO 能力是 204.8T 世代入场券
- P4 可编程性为客户提供"标准未定,芯片先行"的保险
研究者和投资者:
- 关注信号:MRC 采纳速度、UEC 互操作结果、ZCube 64K+ 验证、OCS 非 Google 部署
- 投资方向:光互联(CPO/DSP/硅光子)、开放以太网生态(UEC/MRC)、AI 网络管理、中国国产替代
附录:论文与标准追踪
SIGCOMM/NSDI 论文
SIGCOMM 2025(AI 网络核心论文):
- ZCube / ATOP(字节+清华)——最佳论文,拓扑自动搜索
- InfiniteHBD(OCS 光路交换新方案)
- DCP(去 PFC 拥塞控制新方案)
SIGCOMM 2024:
- Ghost in the Datacenter(Meta)——链路抖动导致拓扑知识失效
- MegaScale / ByteScale(字节)——大规模训练系统工程
IETF / OCP / UEC / IEEE / IBTA 标准
→ 详见姊妹篇之二「从 RoCE 到 MRC」中的标准化格局节。核心标准:RFC 9800(SRv6 C-SID)、MRC 1.0(OCP)、UET 1.0(UEC)、802.3dj(1.6T 以太网推进中)、XDR(IBTA)。