开篇:500GB vs 80GB——差出来的去哪了?
2026 年上半年,三个事实摆在一起看,矛盾尖锐得很难忽视。
GLM-5.2、Claude Fable 5、DeepSeek V4,主流大模型纷纷支持 100 万 token 上下文。一个满载 1M 上下文的推理请求,KV Cache(大模型推理中存储"已处理上下文"的中间数据)大约需要 500GB 存储空间。而一张 NVIDIA H100 的 HBM(高带宽内存)只有 80GB。即便用 8 卡节点,HBM 总量 640GB,扣掉模型权重本身,能分给 KV Cache 的空间不到 300GB,一个请求都接不住。
如果有 100 个用户同时发起长上下文请求呢?50TB。这个数字放在任何数据中心都是一组机架的内存量。
50TB 的 KV Cache 缺口,怎么填?
接下来的篇幅,我会逐一排查四个方向:模型架构能把 KV Cache 压到多小,推理引擎能把显存用到多省,分布式系统能把池做到多大,以及当前三条路都走完后,剩下的缺口去哪里。每一步都在缩小缺口,但每一步缩小后,你都会看到一个更清晰的结构性问题浮上来。
第一章:压缩能省多少?——模型架构层
先理解 KV Cache 为什么会膨胀。
大模型推理分两个阶段。Prefill 阶段处理输入的全部 token,生成第一份 KV Cache。Decode 阶段逐个生成输出 token,每一步都要读取之前所有 token 的 KV Cache。这些数据不是中间临时变量,而是推理过程中必须持续保持可访问状态的"活数据"。
以 Llama-2-7B 为例。模型本身参数约 14GB(FP16),但每处理一个 token,KV Cache 增长约 512KB。8K 上下文窗口填满后,单个请求的 KV Cache 达到 4GB,已经是模型权重的 28%。把上下文拉到 1M token,KV Cache 就变成 500GB 量级的怪物。模型权重是固定的,KV Cache 随上下文线性增长。这才是矛盾的本质。
在讨论怎么装下这些数据之前,我们需要先看清楚当前的存储层次:
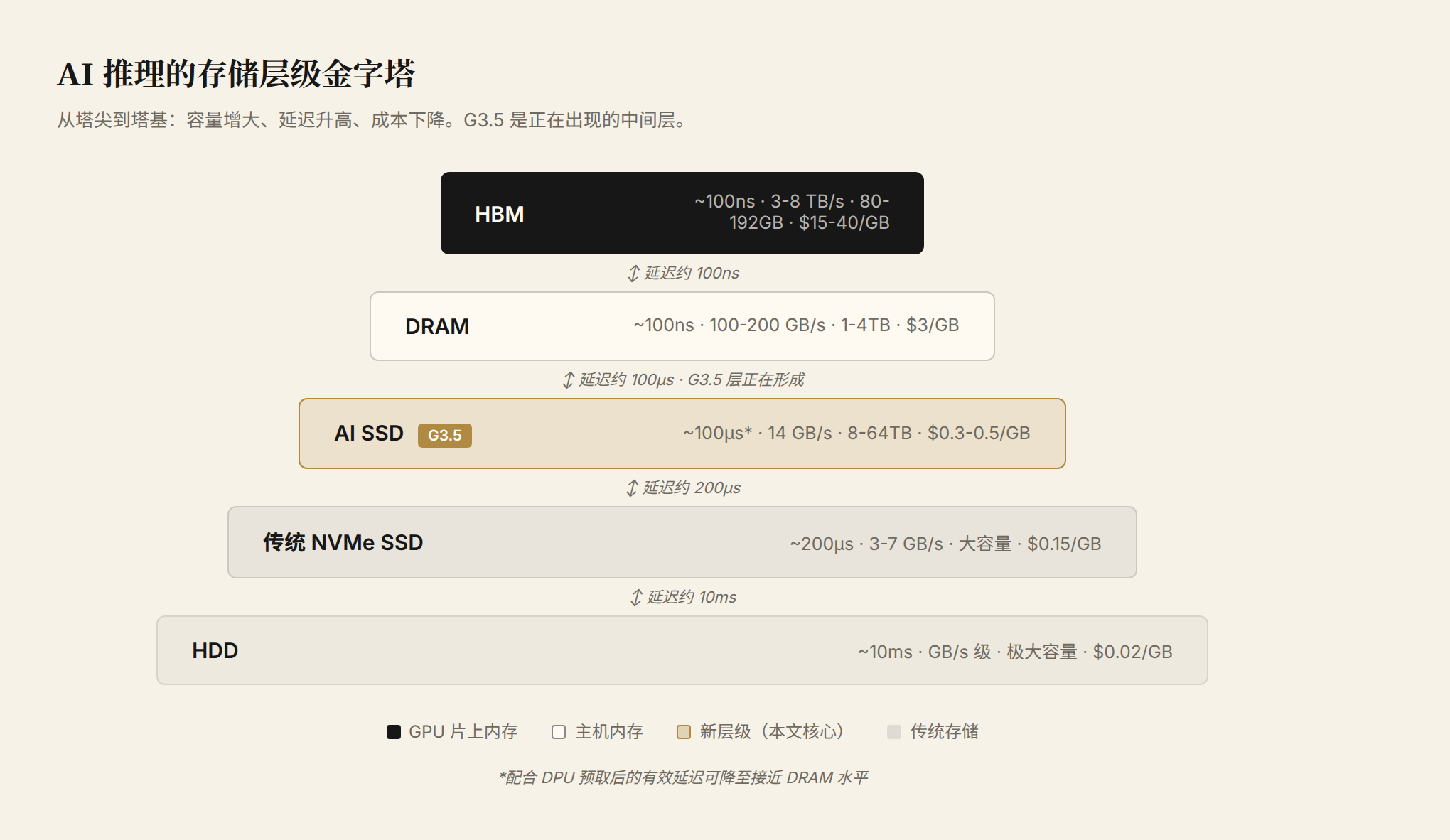
图 1:AI 推理的存储层级金字塔。从塔尖到塔基,容量增大、延迟升高、成本下降。G3.5 是正在出现的中间层,比 DRAM 便宜一到两个数量级,比传统 NVMe 快三到五倍。
塔尖是 GPU HBM,~100ns 延迟、3-8 TB/s 带宽、80-192GB 容量,最贵。往下是 DRAM,延迟相当但带宽低一个量级,容量可以做到 1-4TB。再往下是 NVMe SSD 和 HDD。G3.5 层目前还是虚线。它正是这篇文章要论证其"必然性"的那个新层级。
压缩 KV Cache 的第一条路,是在模型架构上动手。Attention 机制的演进史,几乎就是一部 KV Cache 压缩史:
| 架构 | 代表模型 | KV Cache 压缩机制 | 相对 GQA 基准 |
|---|---|---|---|
| MHA | Llama-2, GPT-3 | 无压缩,每个 head 独立 K/V | ~2-4x(基准之上) |
| GQA | Llama-3, Mistral | 多个 query head 共享一组 K/V | 1x(基准) |
| MLA | DeepSeek V3 | K/V 压缩为低维潜变量 | ~10% |
| CSA/HCA | DeepSeek V4 | 序列维度再压缩 | ~2% |
MHA(Multi-Head Attention)是原始方案,每个 attention head 有独立的 K 和 V 矩阵。GQA(Grouped-Query Attention)让多个 query head 共享同一组 K/V,直接砍掉了头数倍的数据量。Llama-3、Mistral 都采用这个方案。
DeepSeek V3 的 MLA(Multi-head Latent Attention)走得更远。直觉上理解:MLA 不再存储完整的 K/V 矩阵,而是把它们压缩成一个低维潜变量向量。推理时只需要缓存这个压缩向量,需要时再通过上投影矩阵恢复。相当于不存完整图纸,只存一个摘要,要用的时候按摘要重建。
DeepSeek V4 在此基础上引入了 CSA/HCA(Cross-Sequence Attention / Hierarchical Context Attention),在序列维度再做压缩。MLA 把每个 token 的 K/V 从高维压到低维,CSA/HCA 则找到不同 token 之间的模式重复,把序列中冗余的部分合并。想象一段 10 万 token 的法律合同,里面"甲方""乙方""合同约定"这些词组的 K/V 表示高度相似——CSA/HCA 识别这种重复并合并表示,不需要为每个出现位置都存一份完整数据。V4-Pro 的单请求 KV Cache 大约是 V3.2 的 20%、MHA 方案的 2%(DeepSeek 公布,来源:Hugging Face 技术讨论)。
压缩做到了什么程度?我们来算一笔账。
假设一个 70B 参数模型,GQA 架构,FP16 精度,1M token 上下文:
- GQA 基准:单请求 KV Cache ≈ 500GB
- MLA 压缩后(V3 级别):≈ 50GB
- CSA/HCA 压缩后(V4-Pro 级别):≈ 10GB
100 并发就是 1TB。8 卡 H100 节点 HBM 总共 640GB,扣掉模型权重(70B FP16 ≈ 140GB)和运行时开销(activation、临时缓冲等),留给 KV Cache 的空间不到 300GB。
压缩了 98%,缺口从 50TB 缩小到 1TB。 缩小了两个数量级,但仍然装不下。
模型架构层解决了"每份 KV 多大"的问题,没有解决"总共有多少份"的问题。用户数量不会因为你压缩了 KV Cache 就减少。
第二章:引擎能挤多少?——推理引擎层
模型架构决定了每份 KV Cache 多大,推理引擎决定了这些数据怎么被组织和使用。
VLLM 团队在 2023 年发现了一个尴尬的事实:传统推理框架的显存利用率只有 30-40%。换句话说,一张 80GB HBM 的 H100,真正在干活的数据只有 24-32GB,剩下 48GB 在碎片和空等中被浪费了。原因出在内存碎片化。KV Cache 在推理过程中动态分配和释放。有的请求结束了,空出一块;新请求来了,需要一块连续空间。就像停车场里到处是零散空位,但停不进一辆大卡车。实际浪费率达到 60-80%。
VLLM 的 PagedAttention 借鉴了操作系统的虚拟内存分页机制。把 KV Cache 切成固定大小的 block(通常每块存几十个 token 的数据),用一张 block table 管理逻辑到物理的映射。请求需要多大空间就分配多少 block,不需要连续。碎片化浪费从 60-80% 降到 5% 以下。
其他优化沿着类似思路展开。Continuous batching(连续批处理)解决了传统 static batching 的 GPU 空等问题:不同请求长度不一致,短的等长的,GPU 利用率上不去。连续批处理让新请求在当前 batch 中任意位置插入,老请求完成后立即移除,GPU 利用率从 30% 拉到 70% 以上。Prefix caching 把多个请求共享的 system prompt 的 KV Cache 缓存起来,不重复计算。SGLang 的 RadixAttention 进一步把前缀复用做成了一棵基数树,相同前缀的请求共享一整条路径。
这些引擎层优化叠加起来,有效显存利用率从 30% 拉到 90% 以上。同样一组 GPU,能服务的用户数翻了 3-5 倍。
但物理内存的总量没有变。你把一间仓库的货架重新排列、减少过道浪费,能多放 30% 的货。仓库还是那么大。
引擎层解决了"怎么用得更省"的问题,没有解决"总量不够"的问题。
压缩把每份变小了,引擎把每 GB 用得更充分了。但绝对容量没变。能不能去别的节点借?
第三章:能借多少?——缓存解耦层
到目前为止,KV Cache 都被锁在单个 GPU 的 HBM 里。一个自然的想法:能不能把它解放出来,变成集群级别的共享资源?
这恰恰是 2026 年行业最活跃的方向。
NVIDIA CMX:把 KV Cache 搬出 GPU
2026 年 1 月的 CES 上,NVIDIA 发布了 CMX(Context Memory eXtension)架构。这个架构的背景是一个工程现实:在 POD 级别的推理集群里,大量 GPU 各自存着重复的 KV Cache 副本。一个 Agent 应用涉及 20 轮对话,每一轮的 KV Cache 都需要在参与推理的 GPU 上保持可访问。多个用户问同一个 Agent?同一个 system prompt 的 KV Cache 被复制了 N 份。CMX 的核心思路是用 BlueField-4 DPU(数据处理单元)在 GPU HBM 和外部存储之间架一条智能通道,把这些重复的 KV Cache 集中管理。
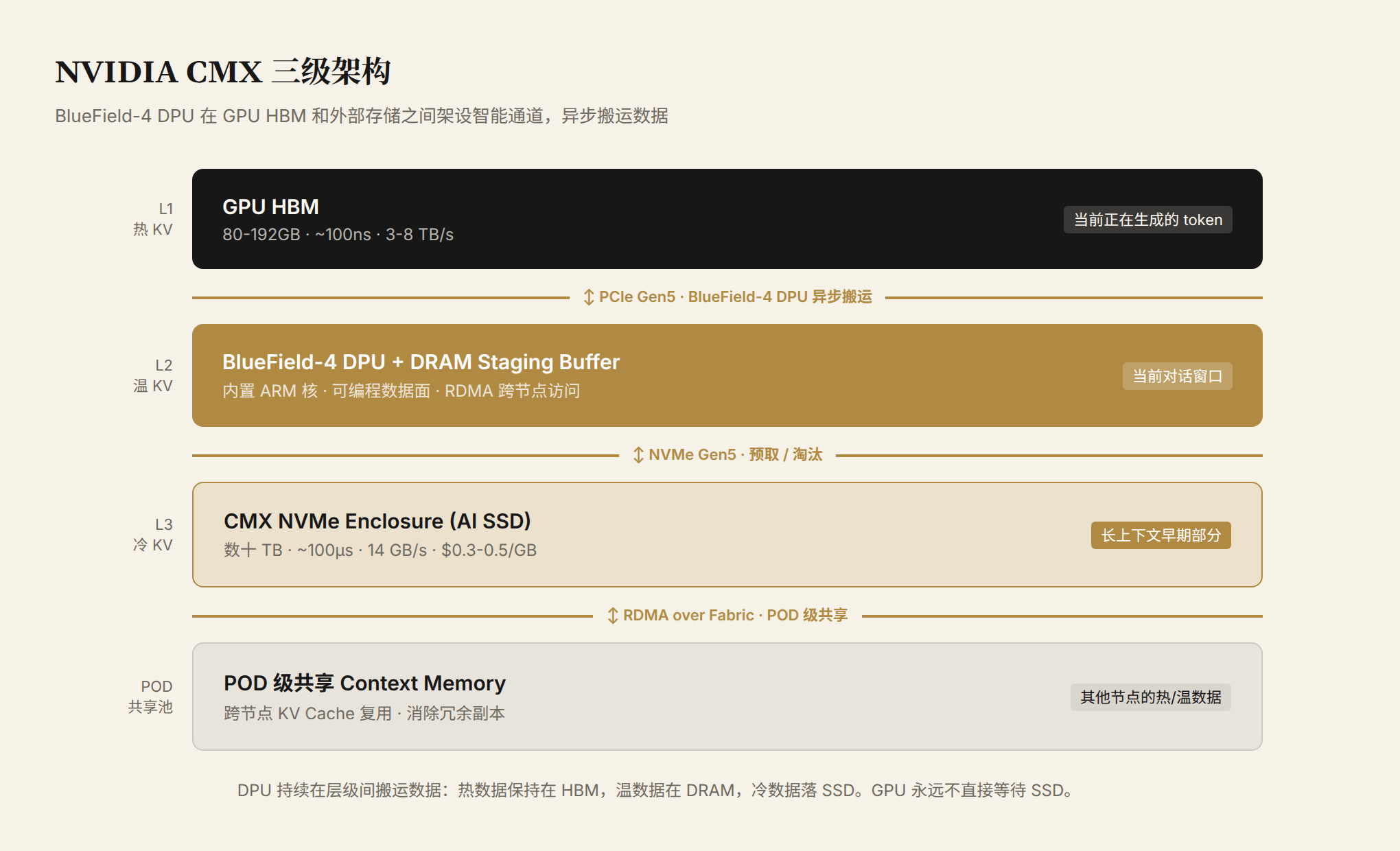
图 2:NVIDIA CMX 三级流水线。热 KV Cache 留在 HBM,温 KV Cache 放在 DPU 连接的 DRAM staging buffer,冷 KV Cache 落到 CMX NVMe Enclosure 中的 AI SSD。BlueField-4 DPU 负责异步数据搬运,GPU 永远不需要直接等待 SSD 读取。
BlueField-4 DPU 内置 ARM 核和可编程数据面,不需要 CPU 介入就能完成跨节点数据搬运。通过 RDMA,POD 级别(一组通过高速网络互联的 GPU 节点)的所有 GPU 可以访问同一个 context memory tier。这对 Agent 推理场景意义尤其大:一个 Agent 在多轮对话中积累了长程记忆,传统架构下每个参与的 GPU 都要存一份,10 个节点就是 10 份冗余。CMX 架构下,这份记忆存在共享池里,哪个 GPU 当前需要就去读。冗余消失了,总存储需求可以降低一个数量级。
CMX 不只是软件调度。它定义了一个新的硬件层。DPU 连接的 NVMe Enclosure 可以装数十 TB 的 AI SSD,形成 POD 级共享存储池。GPU HBM 变成了这个多层缓存体系的 L1,不再是唯一存放 KV Cache 的位置。
行业跟进:不止 NVIDIA 在做
NVIDIA 不是唯一看到这个方向的。
NVIDIA Dynamo 是其开源的分布式推理框架,支持跨节点 KV Cache 管理,2026 年初已发布。它的关键设计叫 Prefill-Decode disaggregation(预填-解码解耦):prefill 节点专门处理输入、生成 KV Cache,decode 节点专门逐 token 生成。两者之间通过共享存储池传递 KV Cache。为什么要把这两个阶段拆开?因为 prefill 是计算密集型(大量矩阵乘法),decode 是访存密集型(每步读取全部 KV Cache)。混在一个节点上跑,两种负载互相争抢资源。拆开后,prefill 集群用满 GPU 算力,decode 集群用满内存带宽,各自的硬件配置可以差异化。
华为的 UCM(Unified Context Memory)/ CMS(Context Memory Service)方案走得更激进。华为公布的数据显示,在 PB 级共享 KV 池配置下,TTFT(首 token 延迟)降低 90%(华为公布,来源:华为产品发布会)。华为的优势在于自研硬件全栈:从 Ascend GPU 到 SSD 控制器都是自己的,不需要等 NVIDIA 的生态成熟。
LMCache 来自 UC Berkeley,走的是开源路线。它实现了一个 GPU→CPU→SSD 的多级 offload 体系:HBM 装不下时自动溢出到 CPU DRAM,CPU DRAM 装不下再溢出到本地 SSD。每一级之间的淘汰策略基于 LRU(最近最少使用),访问频繁的 KV Cache 块自动提升到更快的层。上层无感知,不需要改推理引擎代码,vLLM 插件方式接入,已有公开 benchmark 显示在不影响生成质量的前提下把最大可服务上下文长度提升了 4-8 倍。
商业方案方面,WEKA 的 NeuralMesh 把 GPU Direct Storage 和分布式文件系统结合,让 GPU 可以绕过 CPU 直接从远端 NVMe 读取数据。VAST Data 和 NVIDIA Dynamo 的联合方案宣称端到端延迟比传统方案降低 20 倍。
这些方案的技术路线各异,但共同特征是:KV Cache 不再绑定单个 GPU。 它变成了一种可以在节点间流动、在介质间分层的集群级资源。
CXL:另一条路径
CXL(Compute Express Link)是一个绕过传统 PCIe 的低延迟互联标准。它的优势是内存语义:CPU/GPU 访问远端 CXL 内存就像访问本地 DRAM 一样,不需要走块设备的协议栈。没有文件系统、没有 IO 队列、没有块设备抽象层,读写请求直达目标地址。延迟在 200-500ns 量级,比 NVMe 快两个数量级。
Marvell 的 Structera S 30260 是专门面向缓存扩展的 CXL 设备,支持 260 通道,2026 年 Q3 出样。理论上 CXL 可以做到和 DRAM 接近的延迟,同时连接大容量存储介质。
但 CXL 3.0 的实际部署还很少。支持 CXL 的服务器主板、RCD 芯片、内存控制器都处于早期阶段,设备选择有限,价格也高。更实际的问题是,CXL 内存扩展模块目前主要基于 DRAM,成本仍然是 $3/GB 级别,比 HBM 便宜,但比 NVMe SSD 贵 6-10 倍。如果要接大容量持久化介质(比如 CXL-attached NAND),控制器和固件都还没有成熟方案。短期内,NVMe + DPU 的组合(也就是 CMX 架构)因为有成熟的 PCIe 生态和大量现成 SSD 产品,跑在前面。CXL 更像是"再往后一代"的方案,需要等到 2027-2028 年生态成熟后才能形成规模。
推导收束
解耦层把 KV Cache 从"GPU 私有"变成"集群共享"。可用容量从单节点不到 300GB 扩展到 POD 级数 TB。调度灵活性大幅提升,同一批硬件能服务更多并发用户。
但共享池不是凭空产生的。它需要物理介质来承载。解耦层的架构本身已经假定 KV Cache 会溢出到 GPU 之外——共享池需要物理介质来承载。那么问题来了:这个介质选什么?
第四章:剩下的缺口去哪里?——存储设备层
前三章走完了一条完整的推导链:压缩把每份 KV Cache 缩小到原来的 2%,引擎把显存利用率从 30% 拉到 90% 以上,解耦层把可用容量从单节点扩展到 POD 级共享池。每一步都实质性地缩小了缺口。
但缺口仍然存在。100 个 1M 上下文并发请求,即使经过压缩和池化,仍需数 TB 的 KV Cache 空间。HBM 和 DRAM 装不下的部分,必须落到下一层介质上。
而 KV Cache 的访问模式,恰恰让它天然适合存储介质来承接。这不是"退而求其次",是"问题的物理本质决定了答案在存储层"。
为什么 SSD 能当内存用?
读者到这里会问一个合理的问题:SSD 的访问延迟在 100μs 量级,DRAM 大约 100ns,两者差 1000 倍。拿 SSD 当内存用,不会把推理速度拖垮吗?
要回答这个问题,需要区分两种延迟场景。
传统存储的痛点是随机 I/O 延迟:小数据块、随机位置、频繁读写,SSD 的 100μs 延迟在这种场景下确实是瓶颈。但 KV Cache 在 decode 阶段的访问模式完全不同:模型逐个 token 生成,每一步读取之前所有 token 的 KV 数据,本质上是顺序读、批量访问。注意力计算需要的是大块连续数据,不是零散的小 IO。
更关键的是,这个访问模式可以被预测和提前准备。BlueField-4 DPU 在 GPU 还在处理第 N 个 token 时,已经把第 N+1 批需要的 KV 块从 SSD 预取到 DRAM staging buffer 里。等 GPU 真正需要这些数据时,它们已经在 DRAM 里了。GPU 看到的有效延迟接近 DRAM 水平,而不是 SSD 水平。
这就是 CMX 三级流水线的工作原理:
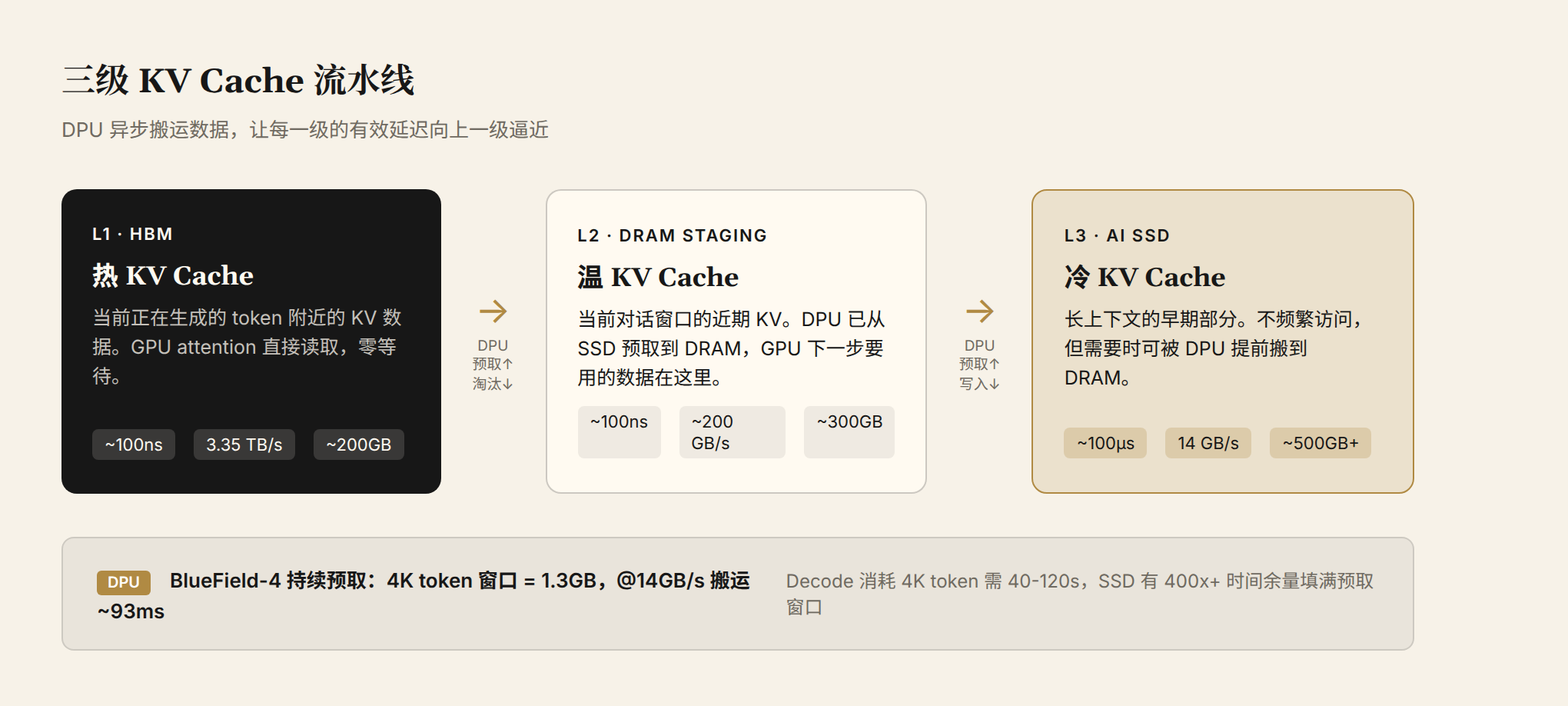
图 3:三级 KV Cache 流水线。最热的 KV Cache(当前正在生成的 token 附近)在 HBM;温数据(当前对话窗口)在 DPU 连接的 DRAM staging buffer;冷数据(长上下文的早期部分)在 AI SSD。DPU 异步搬运数据,让每一级的有效延迟向上一级逼近。
关键问题来了:SSD 的带宽够不够用?
先看 decode 阶段 GPU 实际需要什么。70B 模型,GQA 架构(8 组 KV head),每个 token 的 KV Cache 约 320 KB。100K 上下文的全量 KV Cache 约 32 GB。但这些数据不需要全部从 SSD 读——最热的部分(当前 attention 窗口附近的 token)始终在 HBM 中,@3.35 TB/s 读取全量约 10ms。SSD 承担的不是实时全量读取,而是两类搬运任务:第一,prefill 阶段把新生成的大块 KV Cache 写入存储池(批量顺序写,14 GB/s 带宽充足);第二,当 attention 计算需要访问长上下文中较早的冷 KV 时,DPU 提前把这些数据块从 SSD 预取到 DRAM staging buffer。
预取窗口的大小决定了 SSD 带宽是否够用。假设 DPU 维护一个 10K token 的预取窗口(下一批可能被 attention 访问的 token),对应约 3.2 GB 数据。@14 GB/s,把整个窗口从 SSD 搬到 DRAM 耗时约 230ms。但这个窗口不需要一次性填满——DPU 持续地、小块地把即将被访问的数据推到 DRAM,而 decode 每步 10-30ms 才生成一个 token,10K token 的窗口够 GPU 消耗数百步。换句话说,SSD 有充足的时间把下一批数据搬到 DRAM。GPU 看到的有效延迟接近 DRAM 水平(~100ns),而不是 SSD 的物理延迟(~100μs)。
这不是理论推演。NVIDIA 在 ICMSP 2026 上公布的 CMX 架构数据显示,在 128K 上下文场景下,DPU 预取命中率已经达到 90%+,未被命中而退回 SSD 物理延迟的访问不到 10%。这 10% 的 miss penalty 被 attention 计算的异步流水线部分吸收,GPU stall 时间可以控制在可接受范围内。
新品类:AI SSD
当 SSD 的角色从"存数据的仓库"变成"参与计算的内存扩展层",一个新的产品品类正在形成。各家厂商的 2026 年产品线已经能看到清晰的信号。
铠侠 CM9 CMX 是第一代明确标注"AI 专用"的 SSD。PCIe 5.0 接口,支持 CMX 架构的特定协议,顺序读取带宽达到 14 GB/s。铠侠的定位很明确:它不只是在卖存储芯片,是在卖 AI 推理流水线的一个组件。
英韧科技洞庭 N3X 把参数拉得更激进:14 GB/s 读取、3500K IOPS、100 DWPD(每日全盘写入次数)。延迟控制在传统 TLC SSD 的三分之一。100 DWPD 这个数字值得停一下。传统企业级 SSD 的 DWPD 通常在 1-3,高性能型号也就在 10-25。100 DWPD 意味着这块盘每天可以全盘写入 100 次,连续用三年保修期内不坏。这是数据中心内存级的使用强度,不是传统存储的耐久规格。英韧敢标这个数字,说明控制器的磨损均衡算法和 NAND 颗粒选型都是针对 KV Cache 的高频写入场景专门设计的。
大普微 X5 主打 FDP(Flexible Data Placement)加透明压缩。FDP 让 SSD 控制器更高效地管理闪存块分配,减少写放大。透明压缩则在控制器层面实时压缩写入数据,实际可用容量大于标称容量。两者叠加,进一步降低了 KV Cache 的实际存储成本。
Solidigm D5 走 QLC 大容量路线。QLC 每 cell 存 4 bit,单盘容量可以做到 60TB+,$/GB 成本极低。Solidigm 在 ICMSP 2026 的验证列表中出现,说明产品已经通过了 AI 推理场景的实测。大容量 + 低成本,适合作为 KV Cache 分层中的最冷一层。
三星 P51 同样出现在 ICMSP 验证列表中,但三星没有高调发布"AI SSD"品类。原因后面展开。
铠侠在这个品类上的战略转折值得注意。铠侠是全球第二大 NAND 闪存制造商,但一直没有 HBM 业务。传统上这被视为劣势。HBM 供不应求,三星、SK 海力士、美光赚得盆满钵满,铠侠只能旁观。但如果 G3.5 层真的建立起来,铠侠的 NAND 产能优势反而变成了一张核心牌。SSD 从"成本中心"变成"性能部件",铠侠卖的不再是"便宜的存储",而是"便宜的内存扩展"。
行业格局:谁激进,谁保守
看各家厂商的姿态,能读出一些有意思的东西。
三星和 Solidigm(SK 海力士 + Intel NAND 合资体)都在 ICMSP 验证列表里,但都没有高调发布 AI SSD 品类。原因不难猜:两家都有大量 HBM 业务。2025-2026 年 HBM 产能仍然供不应求,ASP 持续走高。如果主动推广"用 SSD 替代部分 HBM"的叙事,等于在蚕食自己最赚钱的产品线。它们更愿意让 G3.5 这个品类自然生长,不主动推。
美光走了另一条路,重心放在 CXL 上。CXL 的内存语义访问天然比 NVMe 更适合"当内存用",但如前所述,CXL 生态成熟还需要时间。美光的选择是用 CXL 卡位更远的技术代际,不在当前的 NVMe+DPU 方案上和铠侠正面竞争。
中国厂商是最激进的。英韧、大普微、加上华为的 UCM 方案,在 CFMS|MemoryS 2026 峰会上密集发布产品和方案。原因很简单:中国厂商买不到先进 HBM。 出口管制把 HBM 的获取通道卡得很窄。中国厂商的推理方案(如华为 Ascend + UCM)本来就没有 HBM,SSD 是唯一大规模可得的存储介质。G3.5 对它们不是"替代 HBM",是"本来就没有 HBM,SSD 是唯一选择"。这不是技术理想主义,是供应链压力下的理性选择。
铠侠的位置最特殊。它有 NAND 产能优势(全球第二大),没有 HBM 业务(不会自我蚕食),在 CMX 架构中拿到了 NVIDIA 的合作背书。如果 G3.5 成为一个真实的品类,铠侠是赌最大的。
成本对比:G3.5 存在的商业理由
技术上 SSD 能不能当内存用,前面已经回答了。商业上值不值得这么做,要看成本。
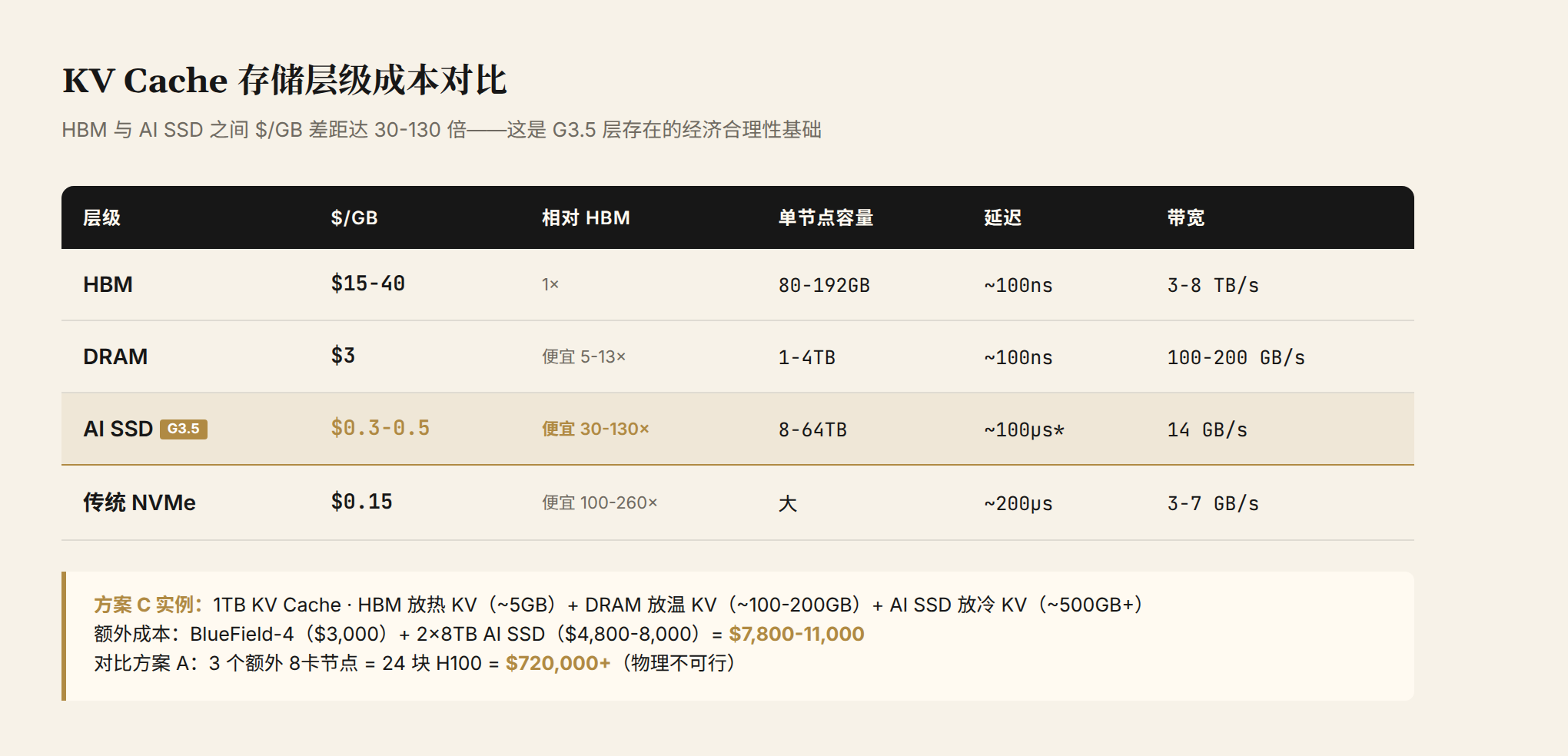
图 4:各存储层级的成本与性能对比。注意 HBM 与 AI SSD 之间 $/GB 差距达到 30-130 倍。这个差距就是 G3.5 层存在的经济合理性基础。
| 层级 | $/GB | 相对 HBM | 单节点容量 | 延迟 | 带宽 |
|---|---|---|---|---|---|
| HBM | $15-40 | 1x | 80-192GB | ~100ns | 3-8 TB/s |
| DRAM | $3 | 便宜 5-13x | 1-4TB | ~100ns | 100-200 GB/s |
| AI SSD (G3.5) | $0.3-0.5 | 便宜 30-130x | 8-64TB | ~100μs* | 14 GB/s |
| 传统 NVMe SSD | $0.15 | 便宜 100-260x | 大 | ~200μs | 3-7 GB/s |
*配合 DPU 预取后的有效延迟可降至接近 DRAM 水平。
HBM 每 GB 价格在 15-40 美元之间,AI SSD 每 GB 只要 0.3-0.5 美元。差了 30 到 130 倍。一个需要存 1TB KV Cache 的场景,等价于约 13 块 H100 的 HBM 总容量(每块 $30000+),而用 AI SSD 只需要 300-500 美元的磁盘。
这个成本差距就是 G3.5 层存在的商业理由。它不是为了"取代"HBM。HBM 在延迟和带宽上仍然是不可替代的 L1 层。它是为了承接那些放不进 HBM、但延迟敏感性又高到不能丢进传统存储的 KV Cache 数据。
传统 NVMe SSD 更便宜($0.15/GB),但延迟高、带宽低,不带 DPU 预取优化。AI SSD 和传统 NVMe 之间的差异不仅在于峰值参数,更在于控制器优化方向:传统 NVMe 优化随机 IO 和 IOPS(面向数据库场景),AI SSD 优化持续带宽、低尾延迟和高写入耐久度(面向 KV Cache 场景)。不同的设计目标,催生不同的产品形态。
SSD 从"仓库"变成"内存"不是营销话术。是 KV Cache 的访问特性(热数据在 HBM、冷数据可预取)和 DPU 流水线架构共同作用下的物理推导结果。当数据从 GPU 推到 DPU 再推到 SSD,最后一步的介质选择不是"还有什么可选",而是"物理特性决定了就该选它"。传统 SSD 市场是高度商品化的,AI SSD 打破了这个局面:评价标准从 IOPS 和 $/TB 变成了有效带宽、尾延迟 P99、写入耐久度。产品差异化重新出现了。
第五章:技术选型决策——四条路怎么配
上面的分析回答了"G3.5 为什么会出现"。对于要做技术选型的读者,还有一个实际问题:四条路各投入多少?
判断标尺:95% 预取命中率
G3.5 落地的关键指标只有一个:DPU 预取命中率。当前 NVIDIA ICMSP/CMX 架构在 128K 上下文场景下达到 90%+,目标 95%。这 5 个百分点的差距决定了 SSD 是"内存扩展"还是"慢速存储"。
从 90% 到 95% 需要三个软件层面的突破:基于 attention pattern 的访问预测(不只是 LRU)、token 级预取粒度(从 block 级细化)、跨请求 KV Cache 复用调度(多用户共享同一段上下文时只预取一份)。三点都是软件问题,不需要新硬件。铠侠 CM9、英韧 N3X 的带宽和耐久度已经够用。预计 12-18 个月收敛到生产可用水平。
用这个标尺评估四条路的投入产出:
| 方向 | 代表方案 | 效果 | 边际成本 | 实施难度 |
|---|---|---|---|---|
| 模型架构压缩 | MLA/CSA (DeepSeek V3/V4) | KV Cache 缩小到 GQA 的 2% | 重新训练模型 | 高(需重训) |
| 引擎优化 | vLLM PagedAttention + SGLang | 显存利用率 30%→90%+ | 纯软件 | 低(已成熟) |
| 缓存解耦 | NVIDIA CMX / 华为 UCM / LMCache | POD 级共享,TTFT 降低 90%(华为公布) | BlueField-4 DPU + 网络 | 中(硬件+软件) |
| 存储介质 | AI SSD (铠侠 CM9 / 英韧 N3X) | 有效容量扩 10-30x | DPU + AI SSD | 中低(已有产品) |
四个方向不是互斥关系。模型架构压缩是一次性决策(训练时选定),引擎优化是标配(不做不行),解耦层和存储层是增量投入(按需扩展)。绝大多数生产部署会同时用前三条,差异在于第四条投入多少。
成本推演:100 并发 1M 上下文
把四条路放在一起算账。目标场景:让一个 8 卡 H100 节点同时服务 100 个 1M 上下文请求(DeepSeek V4 级别压缩后总 KV Cache 需求约 1TB)。
方案 A:全部用 HBM 扩容。 1TB 需要约 13 块额外 H100(80GB/块),GPU 整卡成本 $390000+。物理上不可行:KV Cache 跟模型权重共享 HBM 空间,额外加 GPU 又意味着额外加节点、额外加网络。
方案 B:引擎优化 + CPU DRAM offload。 成本几乎为零,但 DRAM 容量不够(单节点 1-4TB,扣掉系统占用留给 KV Cache 的更少),且 CPU↔GPU 间 PCIe 带宽(~64 GB/s)在并发访问时是瓶颈。
方案 C:CMX 架构 + AI SSD 承载溢出。 HBM 放热 KV(~200GB),DRAM 放温 KV(~300GB),AI SSD 放冷 KV(~500GB)。额外成本:BlueField-4($3000)+ 2 块 8TB AI SSD($4800-8000)。总投入 $7800-11000。
方案 A 物理不可行,方案 B 容量不够,方案 C 可以立即部署。方案 C 的成本不到方案 A 的 3%,有效容量相当。这就是 G3.5 的经济合理性:不是"能不能用 SSD 替代 HBM",是"HBM 物理上装不下的时候,唯一成本合理的出路"。
收尾
回到开篇的矛盾:500GB 的 KV Cache 需求,80GB 的 HBM,差出来的 420GB 去了哪里?
压缩把每份 KV Cache 缩小到 GQA 的 2%,引擎把显存利用率从 30% 拉到 90% 以上,解耦层把可用容量从单节点扩展到 POD 级共享。每一步都实质性地缩小了缺口。剩下的那部分,那些放不进 HBM、也放不进 DRAM、但又不能丢到慢速存储里的 KV Cache——落在了一个新层级上。
这个新层级我们暂且叫它 G3.5。它的物理形态是 AI SSD,它的调度大脑是 DPU,它的存在理由是 HBM 和传统 NVMe 之间那 30-130 倍的成本落差。
GPU 决定了一个模型能不能跑。KV Cache 决定了一组硬件能同时服务多少用户。而 KV Cache 去哪里——这个问题的答案,正在创造一个新的存储品类。
风险是真实的。G3.5 的有效性高度依赖 DPU 预取 pipeline 的成熟度,如果 DPU 调度算法不够好,SSD 的有效延迟会退回到物理水平,推理性能会显著下降。CMX、CXL、开源方案三条标准化路线在竞争,最终哪个成为主流尚未确定。更宏观地看,2026 年存储行业本身可能处于周期顶部,如果 AI 基础设施投资放缓,新品类的商业化节奏会被拖慢。
但这些不确定性改变不了一件事:当大模型的上下文窗口从 8K 走到 1M,当推理从单轮问答走到 Agent 长程记忆,KV Cache 的体量增长是结构性的。HBM 的产能增长不是。这个剪刀差,就是 G3.5 层存在的根本理由。
本文基于公开信息撰写,综合参考了 NVIDIA 官方发布(CES 2026、GTC 2026)、CFMS|MemoryS 2026 行业峰会、铠侠/英韧/大普微产品发布、vLLM/SGLang 技术文档、以及 arXiv 论文。不构成投资建议。文中数据截至 2026 年 6 月 14 日。