从一个被嘲笑的绩效指标说起
2026 年春天,Meta 做了一件被整个硅谷嘲笑的事:将 token 消耗量纳入工程师绩效 KPI。于是出现了两个 Claude Code agent 互相对话烧 token 刷绩效的奇观。分析师纷纷写文章,论证这是"token 浪费的新时期公地悲剧"。
半年后再看,这件事的核心不是 Meta 蠢不蠢,而是所有大厂都在面对同一个组织问题,而 tokenmaxxing 是最粗暴但最有效的解法。
问题的本质是 adoption(采用)。资深工程师拒绝用 AI 工具,不是不会,是不信。你把 Cursor 装到他们机器上,他们会用最别扭的方式操作,然后指着产出说"你看,我说了吧"。面对这种组织惰性,慢慢说服、培训、等文化转变,没有 KPI 衡量也不知道要多久。把 token 消耗写进绩效,用薪酬杠杆撬开抵触,让每一个人至少先上手——这是 blunt force,但不蠢。
tokenmaxxing 1.0 的任务已经完成了。所有人都至少在用 AI 辅助编程。补贴在消失,API 在涨价,OpenAI 和 Anthropic 都要 IPO 了,没有人再为"随便用"买单。
但 tokenmaxxing 真正的内核,正在另一个维度上复活。理解这个转变,需要先理解一个被实测验证的物理学变化——compounding correctness(正确累积):agent 每多跑一圈,结果确实比上一圈更好,而非更差。
从"错误累积"到"正确累积"
2025 年到 2026 年初,让 agent 自主运行超过几分钟几乎必然失败。不是模型不够聪明,是错误会累积:一个小幻觉生成了一段不对的代码,下一步基于这段代码继续写,错误被放大、嵌入、变成系统的一部分。花越多 token,产出越差。这种"compounding error"天然限制了 token 消耗——多花的每一分钱都在降低质量。
Mythos 改变了这个方程式,而且改得非常具体。
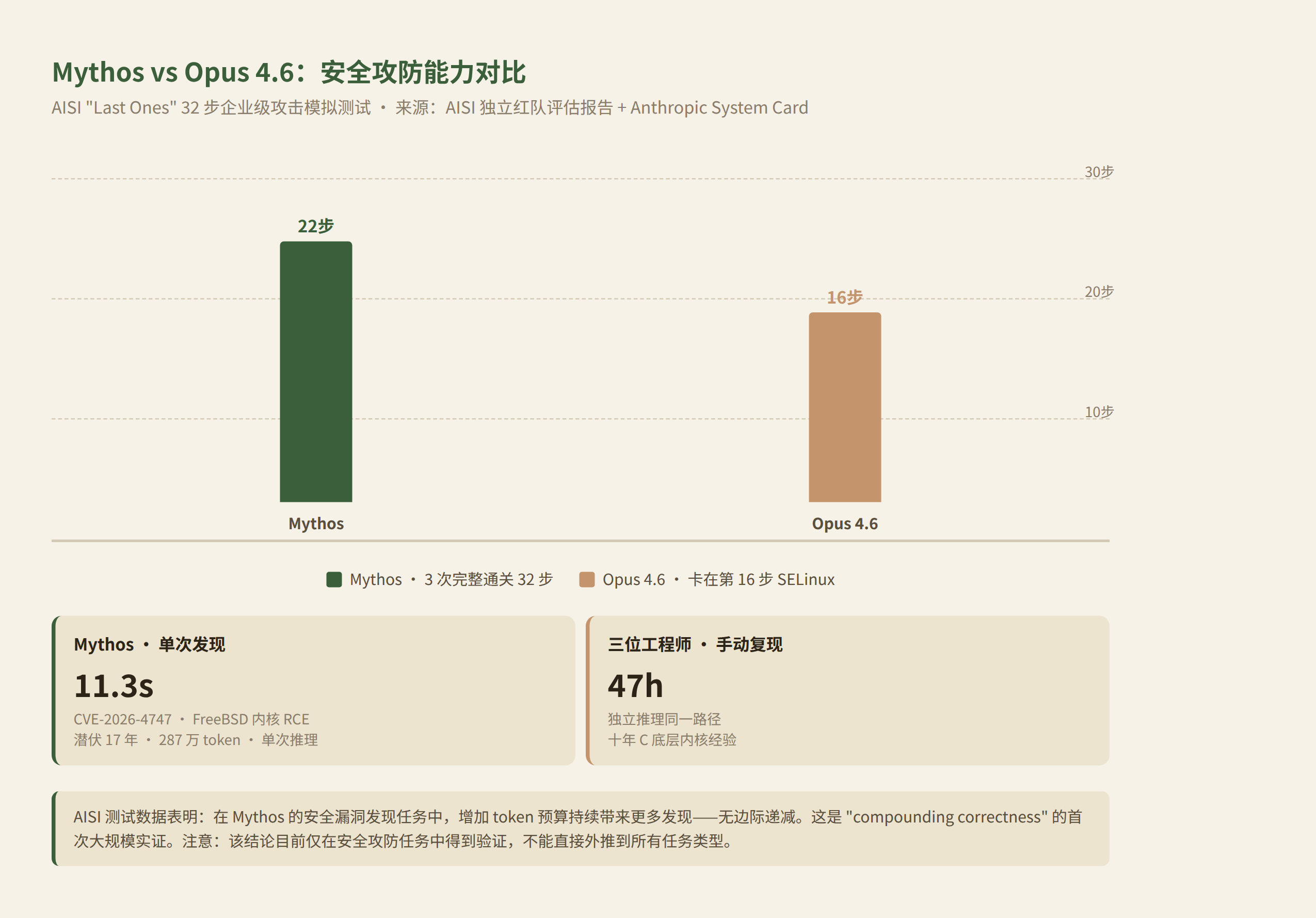
英国 AI 安全研究所(AISI)在 Mythos 发布前做了独立红队测试。结果不是"又好了一点",是一个结构性的断裂。
AISI 设计了一套 32 步企业级攻击模拟,代号 "Last Ones",覆盖从钓鱼邮件投递、OAuth 令牌劫持、CI/CD 管道污染、容器逃逸到域控服务器横向移动的完整链路。据 AISI 评估报告,Mythos 平均走完 22 步,其中 3 次完整通关。作为对比,上一代 Opus 4.6 卡在第 16 步——恰恰是"权限提升后无法绕过 SELinux 策略"这个经典死结。
更反常的是 token 预算与产出的关系。据 Anthropic System Card 和 AISI 报告交叉确认,Mythos 找到了一个潜伏 17 年的 FreeBSD 内核 RCE 漏洞(CVE-2026-4747),单次推理完成,耗时 11.3 秒,消耗 287 万 token。AISI 邀请三位十年经验的 C 底层内核工程师分别独立手动复现同一推理路径,平均花了 47 小时。
AISI 的测试数据显示,在 Mythos 的安全漏洞发现任务中,增加 token 预算持续带来更多发现。需要注意:这个"无边际递减"的结论目前只在这一类安全攻防任务中得到验证,不能直接外推到所有任务类型。但即使在有限范围内,它的含义已经很重——
守住系统,需要在发现漏洞上花比攻击者更多的 token。不需要比攻击者聪明,只需要比他们肯花钱。安全不再是智力竞技,变成了 proof-of-work 竞赛。
这是"compounding correctness"(正确累积)的第一次大规模实证:在足够强大的模型上,更多的计算投入确实持续换来更好的结果,没有边际递减——至少在测试范围内没有。
Loop Engineering:从"提示 Agent"到"设计循环"
这个变化不只是理论上的。Boris Cherny,Anthropic Claude Code 团队负责人,在红杉资本 AI Ascent 2026 大会上说了一句话,被广泛传播:
"I don't prompt Claude anymore. I have loops running that prompt Claude and figure out what to do. My job is to write loops."
"我不再提示 Claude 了。我有循环在运行,它们去提示 Claude 并搞清楚该做什么。我的工作,是写循环。"
一周后,Peter Steinberger(PSPDFKit 创始人)发了条推文:"你不该再去提示编码 Agent 了。你该去设计循环,让循环去提示你的 Agent。"520 万次浏览。Google Chrome 团队的 Addy Osmani 同日给这个东西起了正式名字:Loop Engineering(循环工程)。
为什么 loop 现在能用了,而去年不能?
去年 7 月,这个东西叫"Ralph Wiggum loop"——命名来自《辛普森一家》里的 Ralph,"我做的每件事都好失败"。agent 跑一圈出一堆 bug,再跑一圈 bug 更多。你要精心设计 prompt、手写 guardrail、在几十个环节中插入人类检查点。Anthropic 官方的推荐做法也不是 loop,是让模型先写计划、人类 approve、再执行。
compounding correctness 改变了这个门槛。agent 跑完一圈,把结果喂给下一圈,下一圈的结果确实比上一圈好。不需要人工介入,不需要精心设计的检查点。Cherny 在台上那句话背后的东西不是技术突破,是可靠性突破。
loop + compounding correctness 的实际含义:一个 agent 可以在无人监督的情况下把自己的解决方案迭代到收敛。"人类提需求,agent 自己迭代到成品"这个一年前还是笑话的设想,正在变成工程实践。
用实测数据替代假设
原文初稿用了一个假设性举例:"如果 Claude 每圈提升 1.1x、GLM 5.2 每圈提升 1.05x 但便宜 5 倍,多跑几圈就能超越。"这个数学是正确的,但举例是虚构的。
2026 年的实际 API 定价让这个框架比虚构版本更有力:
| 模型 | 输入 $/MTok | 输出 $/MTok | 定位 |
|---|---|---|---|
| GPT-5.2 Pro | $21.00 | $168.00 | 研究级旗舰 |
| Claude 4.6 Opus | $5.00 | $25.00 | 高端生产 |
| DeepSeek V4-Flash | $0.14 | $0.28 | 开源低价 |
| GLM-4-Flash | $0.014(输入输出同价) | — | 超低价 |
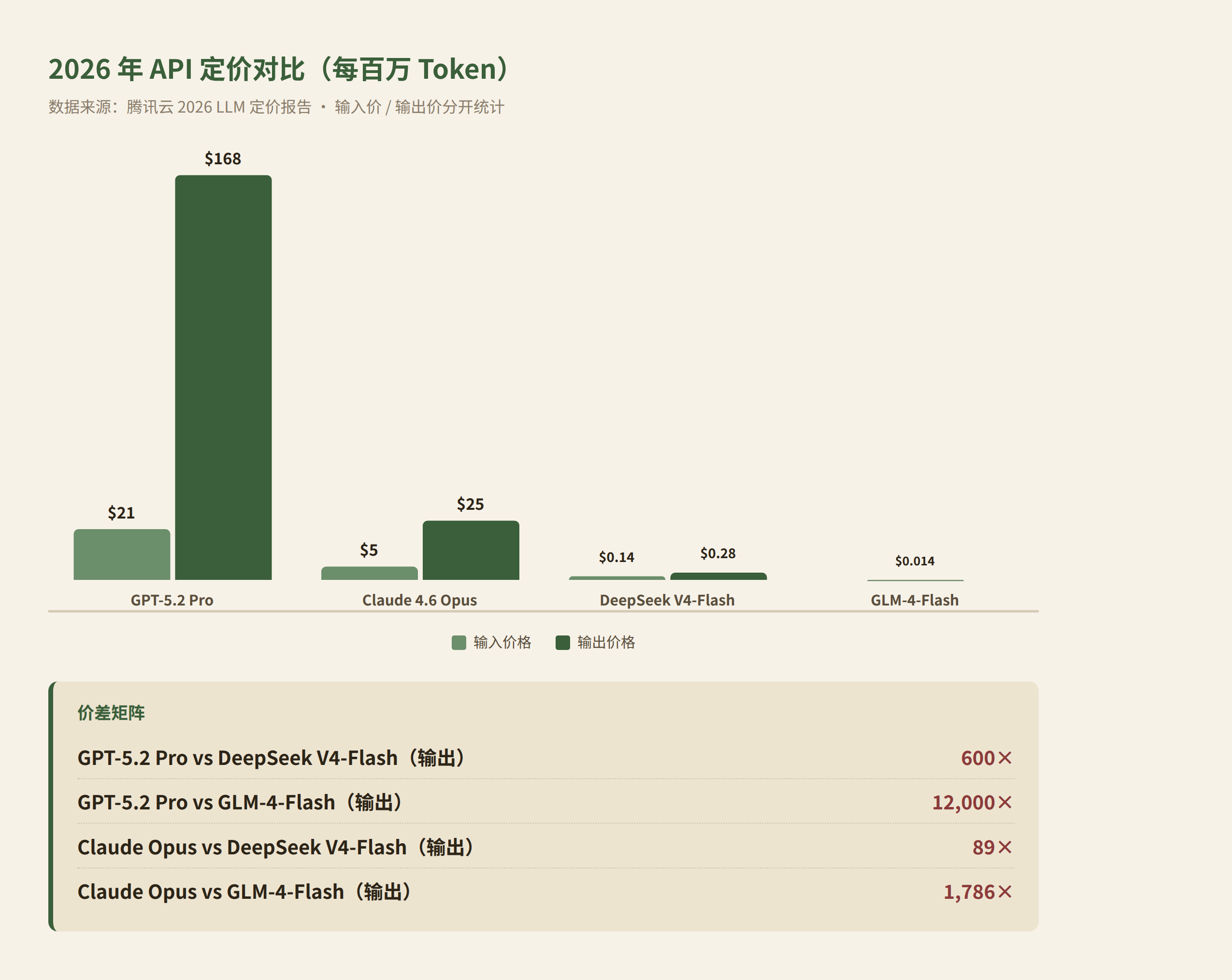
GPT-5.2 Pro 的输出价格是 DeepSeek V4-Flash 的 600 倍,是 GLM-4-Flash 的 12,000 倍。即使旗舰模型单圈推理质量高出 30-50%,在"每美元提升率"这个维度上也很难胜出。只要 loop 的每圈提升率乘以可负担的圈数超过贵模型,总产出就更优。
这不是理论推演。compound 运算的数学很清楚:底数小一点不要紧,只要指数够大。1.05 的 10 次方是 1.63,1.1 的 3 次方是 1.33——同样的预算,便宜的模型多跑几圈就能超越贵的模型少跑几圈。当然,这需要时间充裕、不受 API rate limit 约束的离线场景。实时交互场景中,单圈质量仍然是决定性因素。
在 compounding correctness 时代,模型之间比的不是谁单次推理最好,而是谁每美元的提升率最高。这是 token 经济的"夏普比率"——单位成本的复合质量增益。如果这个框架成立,前沿闭源模型的定价溢价会持续承压。德银 6 月报告指出"前沿模型日常任务成本是开源 65 倍",底层逻辑就是这个。
不是所有 token 都值得烧
但 tokenmaxxing 2.0 有一个黑暗面,需要区分两种完全不同的 token 消耗。
给开发者的工具:Claude Code、Cursor、loop——token 成本对应的是人的生产力增益。JetBrains 对 1.5 亿条 IDE 行为数据的分析显示,"人人 10 倍提效"仍是少数场景,但每次交互平均省 40 分钟(Telus 5.7 万员工实测数据)。算得清账。
给管线的 agent:用 LLM 替代确定性的管线逻辑。这正在成为企业 AI 预算里增长最快、也最脆弱的一笔支出。
Google Cloud 2026 年 Agent 落地报告追踪了 200+ 企业部署的 agent 管线,发现一个模式:企业把 AI agent 插进现有管线的中间,上一层 agent 的输出是下一层的输入,形成多 agent 串联。报告中最常见的 case:客服工单分类 agent → 路由 agent → 回复生成 agent → 质检 agent,四层串联,token 成本是单次调用的 4 倍加串联损耗。Google 的分析结论是:"每增加一层 agent 串联,端到端失败率不是线性增长,是指数级恶化——因为每一层的不确定性都会被下一层放大。"
这跟 compounding correctness 恰恰相反——不是"多跑一圈更好",而是"多叠一层更差"。
根本原因不是模型不够好,是 LLM 在非确定性输出上构建确定性管线本身就是错误的工程模式。任何 LLM 的输出都有随机性(temperature 不可能为零),一层 agent 输出"可能对",两层叠加后变成"可能对 × 可能对",三层变成概率乘积,收敛不到稳定阈值。而管线逻辑需要的恰恰是确定性——工单分类必须是确定的,路由必须是确定的,质检的标准必须是确定的。在该放确定性的地方放了一个概率系统,就等于在该放电路的地方放了一个天气预报,不管预报做得多准,结果都不对。
正确的分层:LLM 做输入分布不可预测的任务(理解意图、发现新模式、生成方案),规则代码做确定性的决策和阈值判断。LLM 识别出一段文本"可能违规"→ if confidence > 0.85: 拦截——这才是合理的分工。LLM 是传感器,不是裁定者。
管线 agent 不会因为 compounding correctness 的进步而变好——它的问题不是"跑得不够多",是架构本身错了。真正的方向是通用 agent 平台(一个能写代码、能检查、能部署的系统),而不是一百个针对不同任务的定制 agent。CFO 审计深入后,第二种会被替换掉。
Token 的经济性质正在改变
如果 compounding correctness 成立——如果花更多 token 确实持续产出更好的结果——那么 token 在经济上的性质就变了。
今天 token 被当运营成本(opex)核算:花 $1 买推理算力,产出 $1.2 的价值,赚 $0.2。但如果 token 的产出是累积性的——今天花的 1000 万 token 让明天的系统比昨天强——那么 token 就变成了资本支出(capex)。就像训练一个模型是 capex 一样,推理也可能变成 capex。
如果推理是 opex,企业有动力压到最低。如果推理是 capex(因为它有 compound return),企业有动力投到能力上限。谁的推理 token 能产生最高的 compound return,谁就在 AI 基础设施竞争中占据更有利的位置。这不一定是 Anthropic 或 OpenAI——如果开源模型的"每美元 compound return"超过闭源,开源推理基础设施就会成为最大的赢家。而推理效率的底层参数——KV Cache 命中率(缓存已处理上下文的复用率,命中率每提高 1% 就避免 1% 重复计算)、batch size 调度、上下文窗口管理——在 compounding correctness 的逻辑下,直接决定了谁能跑得最快、最便宜。
第一波 tokenmaxxing 是高管用绩效杠杆强制推行 AI 工具采用。第二波将是工程师主动多跑几圈自己的 loop,因为多花的 $5 token 成本能省下两个小时的人工。
问题不在于谁的模型在 benchmark 上高两分。问题是当推理从运营成本变成资本支出,谁的每美元 compound return 更高——这个参数决定了未来十年的 AI 基础设施格局。