OpenAI 的 Jalapeño 推理芯片,从设计到流片用了 9 个月(据 OpenAI 官方公告)。Broadcom 帮客户定制一颗 ASIC,周期通常是 12-18 个月。这些数字在今天已经是"奇迹速度"。但芯片行业正在出现一组变化,暗示下一个阶段的周期单位可能不是月,而是周。
变化的信号来自三个方向:商业 EDA 工具商在产品里嵌入 AI、AI 公司用自己的模型加速自研芯片、以及学术界发布了把整个设计流程变成 agent 驱动的开源框架。第三件事的最新样本,是 UC Berkeley ADEPT 实验室的 CHIA 框架。
芯片设计的 AI 化:三条路线
理解 CHIA 之前,需要先看清芯片设计 AI 化的全景。目前有三条平行的路线在推进:
路线一:EDA 厂商内嵌 AI
Synopsys 的 Synopsys.ai 平台声称在芯片全生命周期实现 30% 生产力提升、5 倍开发周期加速(均为厂商宣传数据)。核心产品 DSO.ai 用 AI 搜索优化 PPA(功耗-性能-面积)目标空间。Cadence 的 Cerebrus 自动并行运行 Innovus 流程,通过 AI 调节参数实现 PPA 优化,官方称部分客户在 RTL 和验证任务上取得最高 10 倍生产率提升(厂商声称的 best case)。2025 年底 ICCAD 上,Cadence 正式提出"代理式 AI 驱动芯片设计"概念和 L5 级自主 IC 设计愿景。
这是对旧流程的渐进增强。AI 帮人做参数搜索、布局布线优化、时序收敛、验证用例生成,但人在循环里做关键决策。工具链没变,工作方式在变。Google DeepMind 的 AlphaChip 是另一个代表:用 AI 做芯片布局(floorplanning)优化,把过去人类专家花数周完成的物理设计压缩到几小时。它属于路线一的一个特例——在物理设计阶段而非前端设计阶段使用 AI。
路线二:AI 公司自研芯片
OpenAI 的 Jalapeño(联合 Broadcom,9 个月设计到流片)、Google 的 TPU、Amazon 的 Trainium、Meta 的 MTIA。这些公司的 AI 能力本身就是芯片设计工具——OpenAI 明确说"开发过程由自身模型辅助加速"。但具体加速了哪些环节、加速了多少,没有公开数据。
路线三:Agentic 芯片设计
这是 CHIA 代表的方向。不是 AI 辅助人设计,而是 AI 驱动设计循环本身。人从"执行者"变成"质量守门人"和"目标定义者"。
三条路线不是互斥的。Synopsys 和 Cadence 正在把路线一的 copilot 能力往路线三的 agentic 方向延伸。CHIA 则从学术侧提供一个完全开源的、可组合的框架,让任何研究者都可以实验路线三。

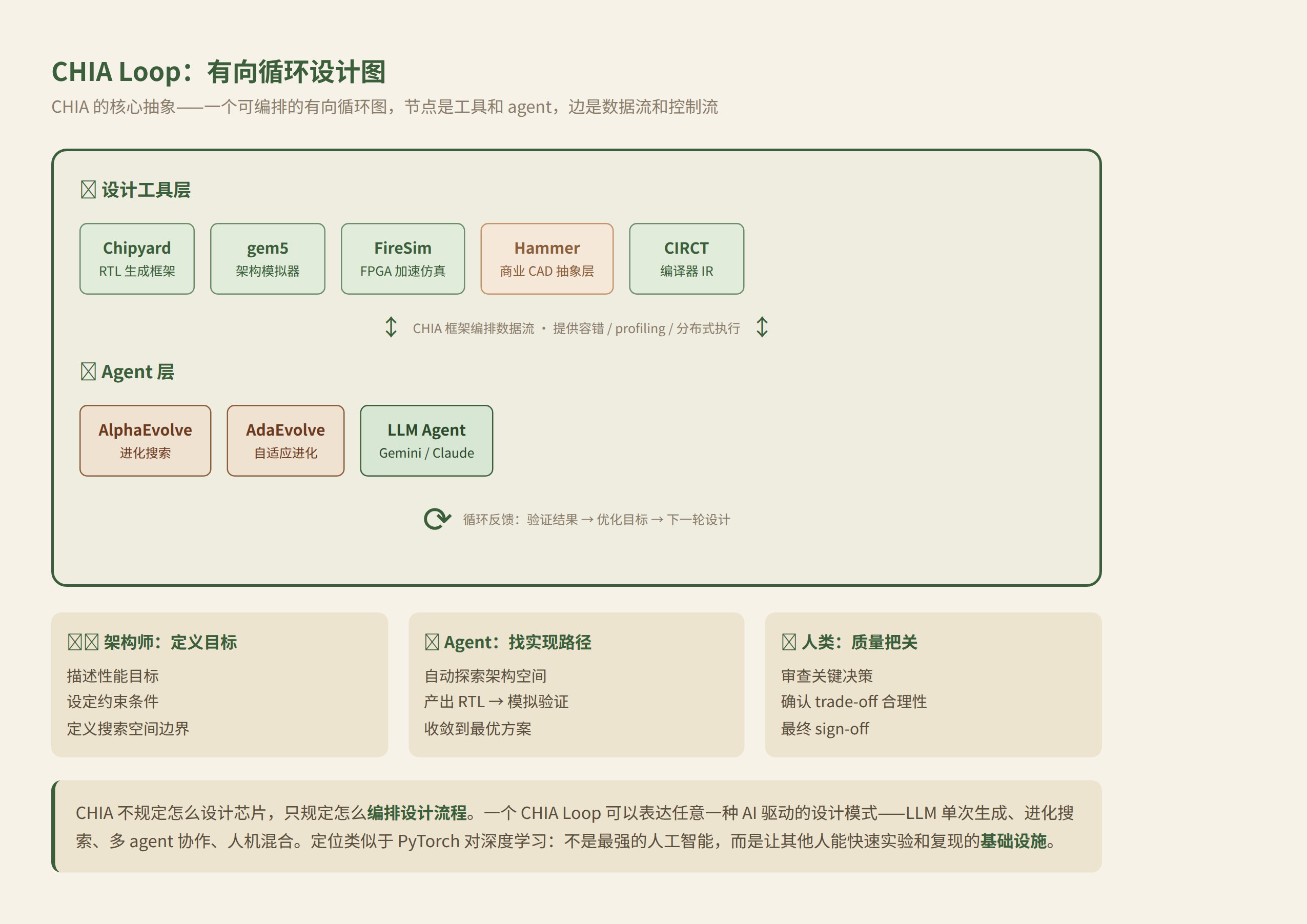
CHIA 的核心抽象:Loop 即设计流程
CHIA 全称 "Co-designing Hardware/software with Intelligent Agents"。作者团队是 Berkeley ADEPT 的核心人员:Yakun Sophia Shao、Borivoje Nikolić、Christopher Fletcher、Sagar Karandikar——Chipyard、FireSim、gem5 这些基础设施就是他们造的。
CHIA 的核心抽象叫 CHIA Loop:一个有向循环图,节点是芯片设计工具(Chipyard、gem5、FireSim)、商业 CAD 抽象层(Hammer)、进化搜索 agent(AlphaEvolve、AdaEvolve)、以及 LLM。框架负责编排这些节点之间的数据流和控制流,提供容错、profiling、分布式执行。
抽象的巧妙之处在于:它不规定你怎么设计芯片,只规定你怎么编排设计流程。一个 CHIA Loop 可以表达任意一种 AI 驱动的设计模式——LLM 单次生成、进化搜索、多 agent 协作、人机混合。
这解决了目前 AI 芯片设计研究中最麻烦的问题:每个实验室都在自己写胶水脚本串联各种工具,不可复现、难以扩展。CHIA 的定位类似于 PyTorch 对深度学习——不是最强的人工智能,而是让其他人能快速实验和复现的基础设施。
5 个验证用例:从理解到创造
论文用 5 个 case study 证明 CHIA Loop 里的 agent 能产出工业级 RTL——通过 25+ 万亿条 SPEC CPU2006 指令验证(相当于一台 BOOM 处理器跑全套 SPEC CPU2006 benchmark 超过 200 轮的量,比典型工业级验证覆盖更深一个量级),在开源和商业工艺库上都满足频率和面积约束。
五个 case 构成一条递进链,每个 case 解决芯片设计中的一个长期痛点:
- 理解已有 RTL:agent 从 BOOM 处理器 RTL 源码自动生成 gem5 模拟器模型。gem5 模拟器模型与 RTL 不同步是芯片验证里的经典痛点——RTL 改了,模拟器没跟上,通常一个工程师要花两周手动对齐。agent 自动完成这个对齐,解决了"一个设计两套描述"的问题。
- 修改 RTL:agent 在 BOOM 乱序超标量 RISC-V 处理器中实现新微架构特性,通过完整 SPEC CPU2006 验证且改善频率/面积。困难在于:在几万行 RTL 里插一个新特性,改错一行整个流水线崩溃,SPEC 跑不过就重来。agent 做到了。
- 优化性能:agent 分析 IPC(每周期指令数)瓶颈,识别关键路径,跨微架构层级推理生成优化方案。这相当于让 agent 自己当性能架构师——不是对着 profile 报告找热点,而是理解为什么这个热点存在、跨哪几个层级去修。
- 发现新组合:基于 AlphaEvolve 进化搜索,在 CHIA 框架内并行探索架构设计空间,复现了 2025 年一项 SOTA 缓存替换策略的研究。需要注意的是,这里的"新"是在已知设计空间内的新组合,而非范式级突破。
- 融入协作:agent 自动处理 CIRCT 编译器项目的 GitHub issue,理解编译器 IR 基础设施后做正确修改并以维护者可接受方式提交。这步验证的不是技术能力,是协作能力——agent 产出的 patch 能不能被人类社区接受。
这五个 case 的排列不是随机的——从理解到修改、从修改到优化、从优化到发现、从发现到协作。每一步都比上一步需要更高的自主性。
商业 AI-EDA 已经走到哪里了?
CHIA 是学术框架,但商业 EDA 厂商不是在等。Synopsys 和 Cadence 已经在产品里部署了 AI 能力,而且有客户数据。
Synopsys.ai 的产品矩阵覆盖数字设计(DSO.ai 做实现搜索优化)、验证(自动生成测试、回归分析、根因定位)、测试(优化测试 pattern 生成)。2026 年与 NVIDIA 战略合作,用 GPU 加速工程计算。官方声称的数字是"全生命周期 30% 生产力提升"和"5 倍开发周期加速"。这些数字来自厂商,需要按宣传口径理解,但方向清晰:AI 不再是辅助写 Verilog 的 copilot,开始进入完整的工程 workflow。
Cadence 在 ICCAD 2025 上正式提出 L5 级自主 IC 设计概念。Cerebrus 做数字实现优化,Verisium 做验证。Cadence 与 NVIDIA 合作扩大到了 agentic AI 和数字孪生。Semiconductor Engineering 组织了一场有 Cadence、Synopsys、Siemens EDA、Baya Systems、ChipAgents 参与的行业讨论,共识是:大家谈的不是单点 copilot,而是覆盖 spec → RTL → 验证 → 物理设计 → sign-off 全链条的 agentic workflow。
CHIA 与商业工具的关键差异:Synopsys 和 Cadence 的 AI 能力嵌入在自家闭源工具链里,客户只能通过厂商提供的接口使用。CHIA 是完全开源的,基于 RISC-V 生态(BOOM + Chipyard + CIRCT),研究者可以自由修改任何环节。这意味着 CHIA 更适合做前沿探索(比如让 agent 自由修改指令集做 trade-off),而商业工具更适合生产环境中的渐进优化。
这条分界线在 2-3 年内可能会模糊。如果 Synopsys/Cadence 开放更多 API 接口让外部 agent 调用,或者 CHIA 的学术成果被商业化包装,两条路线会收敛。
中国视角:国产 EDA 的窗口
中国芯片设计 AI 化的节奏与全球不同步,但有自己的窗口。
东方证券 2026 年 6 月 29 日的研报指出:国产 EDA 在成熟节点、模拟全流程、制造端 EDA、器件建模、良率分析和数字验证方向已形成较清晰突破路径。先进节点全流程工具仍由 Synopsys、Cadence、Siemens EDA 主导,短期难以全面替代。
AI 对国产 EDA 来说不是弯道超车的捷径,但是一个新的价值层。东方证券的判断是:AI 进入 EDA 后不会简单替代传统工具,反而通过自动生成验证用例、PPA 搜索、错误定位和多轮优化,带来更高的工具调用频次和算力消耗,从而强化平台粘性。这意味着 EDA 的商业模式会从"卖工具许可证"向"卖 AI 优化服务"迁移。
对华为海思、紫光展锐等自研芯片的国内厂商来说,CHIA 这样的开源框架有一个额外价值:在美国出口管制限制获取先进商业 EDA 工具的背景下,基于 RISC-V 开源生态的 agentic 设计框架提供了一个不依赖 Synopsys/Cadence 的技术路线。目前这条路线还停留在学术阶段,但战略储备价值已经显现。
冷静的边界
CHIA 不是魔法。几个边界条件需要说清楚:
功能验证 ≠ 物理验证。 agent 产出的 RTL 通过了 25 万亿条 SPEC 指令的功能验证,但功能正确不等于流片后能用。电源完整性、信号完整性、热分布、制造变异——这些 physical signoff(物理签核,流片前确认芯片在功耗、时序、制造变异等物理维度通过工艺厂验收标准的最终检查)环节仍然需要传统 EDA 工具和人类工程师的判断。CHIA 目前覆盖的是设计的前端(RTL 级),不是后端(物理设计级)。
进化搜索 ≠ 架构突破。 进化算法擅长在已知架构空间的 Pareto 前沿上做局部优化。但如果下一个突破需要跳出当前搜索空间——比如从传统缓存层级跳到近存计算——agent 无法自己"发明"新范式。它们擅长在已知框架内做 trade-off,不擅长做范式重构。Case Study 4 的"新组合"是在已知设计空间内重新组合缓存替换策略参数,不是发明了新的缓存架构范式。
学术框架 ≠ 生产线。 CHIA 即将开源,但从学术框架到 TSMC 产线之间还有大量工程工作:与商业 PDK 的深度集成、与 foundry 工艺参数对接、physical design 复杂性。论文本身承认 case studies 不是详尽的展示。
CHIA 没有覆盖的方向:AI 正在设计人类无法想象的射频芯片
CHIA 的边界目前停在数字芯片的 RTL 级。但这不意味着 AI 芯片设计的边界也停在这里。在 CHIA 尚未涉足的领域——模拟和射频芯片设计——一件更激进的事正在发生。
2026 年 6 月 24 日,普林斯顿大学电机工程系副教授 Kaushik Sengupta 在 IEEE Spectrum 发表了一篇题为《AI Is Designing Radio Chips That Humans Couldn't Even Imagine》的系统性总结,回顾其团队过去三年的研究:AI 从零设计射频集成电路(RFIC),不依赖任何人类模板,产出的芯片版图看起来像二维码,但性能碾压同时代最优手工设计。
射频设计为什么比数字 RTL 更难自动化。 数字芯片的设计流程已经高度标准化——从 RTL 到门级网表到物理布局,每一步都有成熟的算法工具。但射频设计完全不同:它是一场跨越多物理域的工程博弈。麦克斯韦方程组在不同空间和时间尺度上支配着电磁场与有源/无源器件的相互作用;热力学定律决定芯片的产热和散热;热胀冷缩的力学原理决定封装可靠性。同时把所有物理约束纳入考量,设计空间大得几乎无法处理。任何一个决策都会触发连锁反应——按下一个葫芦,浮起多个瓢。
这就是为什么几十年来,芯片行业一直有一个共识:"数字设计是科学,射频设计是艺术"——一门需要多年经验积累的"暗黑艺术"(dark art)。一个资深射频设计师花数年时间、耗资数千万到数亿美元才能完成一颗新芯片的设计。如果任何一步不达标——阻抗不匹配、热密度过高、某个无源结构偏离设计——就得回到起点重新来。
AI 怎么做到不用模板就能设计射频芯片。 Sengupta 团队的做法分为两个阶段。第一阶段:强化学习框架。让 agent 从零开始探索电路架构、拓扑结构、器件参数、甚至电磁接口特性——不依赖人类设计师提供的任何电路模板。训练方式是让 agent 不断尝试组合、观察性能结果、改进策略,类似于 AlphaGo Zero 不和人类对弈而只和自己下棋来学习。训练需数天到一周,一旦训练完成,agent 可以在几分钟内生成一个新的完整电路设计。第二阶段:基于 CNN 的 AI 电磁模拟器替代传统电磁求解器。传统 EM 仿真软件从头求解麦克斯韦方程组,一次迭代可能几十分钟到几小时;CNN 模拟器直接从结构图像预测散射参数,跳过底层物理计算,耗时从几十分钟降到几毫秒。两个阶段串联,构成一个端到端的 AI 射频芯片设计师。
结果有多激进。 2023 年,团队发布了概念验证——一款面向 30-100 GHz(覆盖 5G 毫米波和雷达频段)的功率放大器。最终设计实现了当时硅基 PA 中最佳的带宽、输出功率和效率组合。2024 年,团队进一步证明该方法适用于多端口 IC:传统上 4 端口设计的 16 个散射参数需要数天数周的仿真,AI 方法几分钟即可完成。而最具冲击力的发现是:没有证据表明人类设计的模板是现代设计目标的最优解。 AI 生成的版图完全不像传统 RFIC 的对称几何结构——看起来更像像素化的二维码或随机图案——但实物原型在性能上多次碾压当时的最先进水平。
这个信号对芯片设计意味着什么。 如果说 CHIA 证明了数字芯片的 RTL 可以从手工编写变成 agent 驱动的自动生成,那么 Princeton 的 RFIC 研究证明了一件事:即使是芯片设计中被认为最不可能自动化的领域——模拟/射频的"暗黑艺术"——也已经被 AI 攻破,而且不是渐进优化,是从零生成。
两件事合在一起,指向一个更大的判断:AI 芯片设计不是一个领域一个领域地渗透——它是同时对数字和模拟两端进行突破。 这不是"EDA 工具变聪明了",而是"芯片设计的抽象层级从 RTL/电路级上移到了意图级"——无论是 CHIA 的"人定义目标,agent 找 RTL 实现",还是 Princeton 的"人给 S 参数,AI 生成电磁结构",本质是同一个范式:设计师从执行者变成目标定义者和验证者。
当然,Princeton 的方法同样有边界。AI 会产生错误的电路设计,仍然需要人工验证——和 CHIA 的"功能验证 ≠ 物理验证"一样,这不是零人工系统。Sengupta 自己也指出,数据量仍然是瓶颈:在拥有"ImageNet 时刻"级别的大规模训练数据之前,AI 射频设计的泛化能力仍然受限。但这改变不了一个基本事实:连"暗黑艺术"都能自动化,芯片设计领域已经没有哪个角落是 AI 够不到的。
设计周期压缩的产业含义
如果 agentic 芯片设计在 2-3 年内变得实用,几个判断值得提前想。
定制芯片门槛下降。 Broadcom 的 AI 芯片定制业务 2025 财年营收约 200 亿美元(据 Broadcom 财报),核心价值是"帮你定制 ASIC"。如果 agent 自动化了大部分定制工作,门槛从"雇 200 个 ASIC 工程师"降到"部署一套 agentic 设计流程 + 付算力账单"。Broadcom 的客户关系和工艺经验不会消失,但 200 亿美元这门生意的成本结构优势会被压缩——定制一颗 AI 芯片不再需要定制两百个人。
RISC-V 的结构性利好,以及架构师角色的重定义。 这是两个相关的变化。CHIA 的 5 个 case 全部基于 RISC-V——开源 ISA 和模块化设计天然适配 agent 驱动的设计探索,agent 可以自由修改指令集做 trade-off,而 x86 和 ARM 的封闭 ISA 限制了探索空间。与此同时,过去十年芯片设计的抽象层级不断上升——从晶体管到门级到 RTL 到 HLS。CHIA 把抽象提升到"意图级":描述性能目标,agent 找实现路径。CHIA 论文中 agent 自主完成一个完整 case study 的端到端时间可以压缩到小时级,而同样工作在传统设计流程中通常需要数周——未来最抢手的芯片设计师不是最会写 Verilog 的人,而是最会用 agent 探索架构空间的人。
从人才结构的角度看,按 Synopsys 的"30% 生产力提升"反推:一个 50 人的芯片设计团队在 AI 辅助后可能只需要 35 人——但不是均匀减产,而是砍掉 15 个写 RTL 的初级工程师、新增 1-2 个懂 agent 编排的架构师。金字塔底收缩,塔尖变得更高。
架构师不写 RTL,架构师设计 Loop。 当设计循环可以在几百台机器上并行运行、agent 在几小时内产出完整 RTL 并经过 25 万亿条指令验证时,芯片架构师的技能栈应该怎么重写?
Synopsys 和 Cadence 已经在卖渐变版的答案——"30% 生产力提升",意味着同样的团队无需太多改变,产出更多。CHIA 指向一个更激进的答案——商业 EDA 做渐进优化,开源学术框架做激进重构。哪个先到生产线,取决于未来两年 agent 在 physical design 和 sign-off 环节能走多远。但无论是渐变还是激进,方向都是同一个:芯片设计能力的瓶颈,正在从"有多少人"变成"设计了多少个好 Loop"。