$3.1 Billion for Data Infrastructure, Not AI: Schneider's Acquisition of Cognite and the Value Thesis for Vertical AI
June 30, 2026 — Schneider Electric announced the all-cash acquisition of Norwegian industrial AI company Cognite for $3.1 billion. The news spent barely a day in the newsfeed before being buried by the next wave of mega-funding headlines. But if you write this off as just another industrial software acquisition, you'll miss a much more important question — in vertical AI scenarios, what actually holds long-term value, and what might be rapidly neutralized by the relentless progress of general-purpose models?
This article uses the deal as a lens, unfolding across three layers: the facts (what happened), the value (what Cognite's assets are really worth), and the thesis (a moat model for vertical industrial AI).
1. Facts: An Underestimated Deal
Deal Basics
- Acquirer: Schneider Electric (EPA:SU), global leader in energy management and automation, 2025 revenue of €36B+
- Target: Cognite Holding AS, Norwegian industrial AI and data software company
- Amount: $3.1 billion, all cash
- Seller: Aker ASA (Norwegian industrial investment group) and other shareholders
- Integration: To be merged into AVEVA — the industrial software subsidiary Schneider fully acquired in 2023
- Closing: Expected within the coming quarters, subject to regulatory approval
Cognite's Asset Snapshot
Cognite's lifecycle can be understood in three phases:
2016–2020: In-house origins. Cognite was born inside Aker ASA. Aker paired software engineers with domain experts to build a data platform for its EPC company Aker Solutions and oil company Aker BP. Its earliest alpha/beta customers were its own sibling companies — oil platforms in the Norwegian North Sea were Cognite's first testing ground. This "eating your own dogfood" experience gave Cognite real product experience in the high-barrier world of industrial data.
2021–2024: Independent commercialization. In 2021, Cognite became Norway's first unicorn at a $1.6B valuation, bringing in external investment. It reached profitability in 2024. The core product is Cognite Data Fusion (CDF), an industrial DataOps platform.
2025–2026: AI Agent acceleration + workflow platform. Launched Cognite Atlas AI (low-code industrial AI Agent workbench) and Cognite Flows (AI-native industrial workflow platform). 2025 revenue >$170M, ARR bookings growth of 36%.
Core Product: Cognite Data Fusion
What problem does CDF solve? In one sentence: turning messy industrial data into a knowledge graph that AI can understand.
How messy are industrial data sources? A few examples:
- Time-series data (temperature, pressure, flow from sensors captured every few seconds)
- P&ID diagrams (piping and instrumentation diagrams)
- 3D CAD models (digital twins of plant designs)
- Equipment maintenance logs (work orders, inspection records)
- ERP and CMMS data (spare parts inventory, maintenance schedules)
- Laser scan data (point clouds of as-built plants)
This data lives in different systems, with different formats, different timestamp precisions, different naming conventions. The traditional approach: engineers manually find data, manually correlate, manually clean — ARC Advisory Group research shows that 80% of time in industrial AI projects goes to data preparation, with only 20% spent on actually building solutions.
CDF's core value is data contextualization: using AI to automatically connect these fragmented data sources into an industrial knowledge graph. Time-series data is automatically linked to the corresponding equipment ID, P&ID pipe numbers are auto-mapped to physical locations in 3D models, maintenance log equipment IDs are auto-aligned with asset hierarchies in ERP.
On top of this, Cognite Atlas AI provides a low-code industrial AI Agent workbench — letting plant engineers query equipment status, perform root-cause analysis, and optimize production parameters in natural language, without writing a single line of code.
Three Differentiators for Atlas AI
Atlas AI is not tied to any specific model — customers can connect GPT, Claude, DeepSeek, or their own fine-tuned models (LLM-agnostic architecture). Cognite also publishes an independent LLM/SLM Industrial Benchmark Report to help customers evaluate models. Second, it ships pre-configured Agent templates (root-cause analysis, troubleshooting, equipment performance). Aker BP's RCA agent achieved >70% efficiency gains; Celanese's troubleshooting agent drove 50% digital transformation acceleration. Third, the product is aligned with the EU AI Act — a compliance differentiator for European industrial customers.
Cognite Flows: A New "Action Layer"
Flows, launched in 2026, is Cognite's third product line — the "action layer" that sits on top of CDF's data infrastructure and Atlas AI's agentic capabilities to build executable industrial workflows. Its core proposition: let frontline workers build production-grade applications using AI coding tools (Claude, Cursor, etc.). Features include persona-based AI-native dashboards, pre-built industrial applications (Industrial Canvas, InField, Maintain), and custom workflow building with agentic coding tools (claiming 100x acceleration).
Flows already has 50+ customers, with case studies showing 7 weeks from deployment to measurable impact, scaling to 9 facilities within 4 months. Flows transforms Cognite from a "data platform" or "AI Agent platform" into a full-stack industrial software platform covering the entire chain: data layer → Agent layer → action layer.
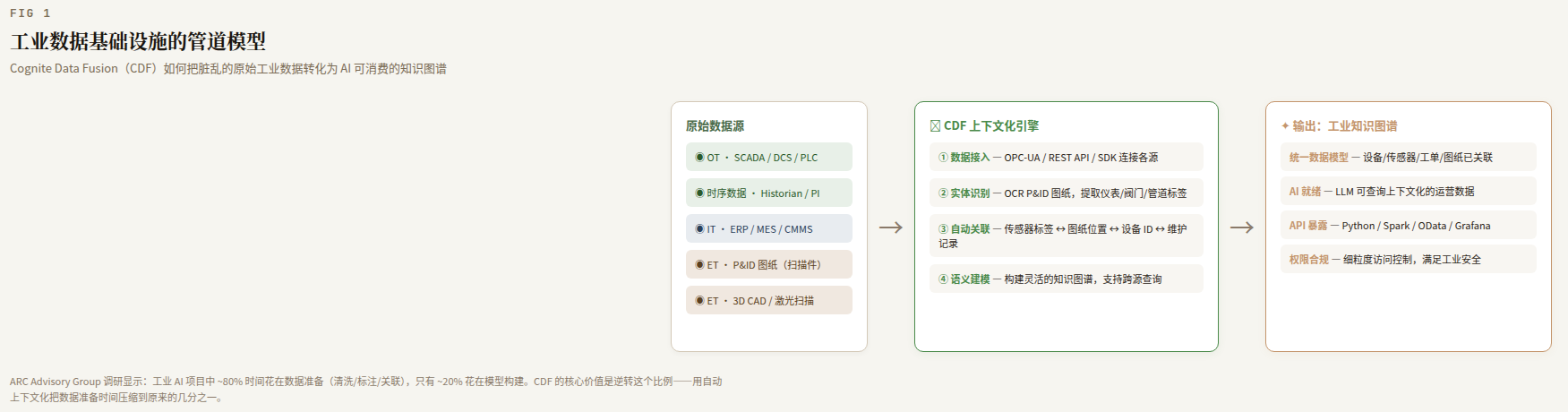
CDF core logic: OT/IT/ET raw data → contextualization engine → industrial knowledge graph → AI-ready output
Deal Context
The timing isn't accidental. In May 2026, Autodesk acquired MaintainX (asset maintenance management) for $3.6 billion. Industrial AI deal activity has clearly accelerated through 2025–2026. After Cognite reached profitability in 2024, Aker faced a strategic choice: keep funding growth, or let someone else do it. The decision to sell was partly driven by Aker's need to redeploy capital into new directions — Aker's roughly $1.5 billion proceeds will go to Nscale (a joint venture with British AI supercomputing company Nscale) and Aize (a cloud-native digital twin platform).
Schneider's logic for folding Cognite into AVEVA is straightforward: AVEVA excels at traditional predictive analytics and industrial visualization; Cognite excels at data contextualization and AI Agents. The former needs the latter's data layer to make AI actually work.
2. Value Analysis: What $3.1 Billion Actually Bought
Cognite's Asset Breakdown
Deconstructing Cognite's asset package reveals three layers:
Layer 1: Revenue Assets (quantifiable)
- 2025 revenue approximately $170M (exact figure undisclosed; estimated range $150–190M)
- ARR bookings growth of 36%
- $3.1B / $170M ≈ 18x revenue multiple (at lower bound $150M ≈ 21x, upper bound $190M ≈ 16x; midpoint ≈ 18x)
- Comparison: Autodesk acquired MaintainX ($3.6B / ~$100M ≈ 36x revenue)
- Industry benchmark: median ARR multiple for industrial SaaS strategic acquisitions is typically 5–10x; Cognite's 18x is significantly above that, incorporating an "AI premium" and the scarcity premium on data infrastructure
Layer 2: Technology Assets
- Cognite Data Fusion platform (industrial DataOps)
- Cognite Atlas AI (industrial AI Agent workbench)
- Industrial knowledge graph engine (data contextualization AI)
- Verdantix Green Quadrant 2025 Leader in industrial data management — perfect score for "data modeling"
- IDC MarketScape 2025 Leader in Industrial DataOps Platforms — recognized for "diverse partner ecosystem, strong implementation and customer success support"
Layer 3: Data Assets (hardest to quantify, most debated)
- Accumulated experience from datasets spanning dozens of industrial customers
- Data model templates for oil & gas, chemicals, power, manufacturing, and other verticals
- Cross-data-type contextualization rule libraries (time-series, CAD, P&ID, logs, etc.)
- Deep product feedback loops with core customers like Aker BP
Cognite's Specific Competitiveness
Cognite's edge isn't algorithmic sophistication; it's the "last mile" capability in industrial data. This is reflected in its partner ecosystem: Microsoft, AWS, SLB (Schlumberger), Rockwell, NVIDIA — covering cloud infrastructure, industrial automation, simulation, and AI compute — but no foundation model vendors. Cognite stays in the data and action layers, leaving the model layer to partners.
A general-purpose AI model can understand an article about an oil refinery, but it won't understand:
- Why pressure transmitter PID-1234's readings drift above 85°C
- What "TIC-8901.SP" in the DCS system is, where it lives, and which equipment it's tied to
- What operational risk a historical maintenance record saying "replaced gasket on pump P-4702" implies
What Cognite does isn't training a better model — it's using data engineering to feed industrial context to the model. Architecturally, it's standard RAG (Retrieval-Augmented Generation) — but not general-purpose RAG, vertically specialized RAG: it retrieves not web snippets, but entities and relationships from an industrial knowledge graph.
Cognite's competitiveness boils down to three elements:
-
Breadth of connectors: Ready-made connectors for dozens of industrial data sources (historian databases, IoT platforms, MES, ERP, CMMS, PLM, etc.). This isn't technical depth — it's engineering accumulation. Every connector has to adapt to a different vendor's API and data model. There are no shortcuts.
-
Depth of data model templates: Pre-built data models for different industrial verticals (oil & gas, chemicals, power, manufacturing). These models encode industry-specific knowledge — how a refinery's equipment hierarchy is organized, how a power system's SCADA point list is correlated. This is what Cognite has honed over a decade with core customers like Aker BP.
-
Product closed-loop: The credibility of industrial AI Agents. Atlas AI includes industrial-domain LLM/SLM benchmarks, providing industry-specific evaluation for customers choosing large models. This isn't a technology moat — it's a product moat: every verification step that makes industrial customers trust AI output.
Strategic Value to Schneider
A quote from Schneider CEO Olivier Blum in the announcement is worth reading in full:
"Cognite has built something genuinely scarce — a real industrial-grade AI platform that turns the complexity of operational data into competitive advantage. … At Schneider, we have always believed that the energy transition requires intelligence, intelligence requires data, and unlocking the full value of data requires AI."
The causal chain — "energy → intelligence → data → AI" — is clearly articulated. But a more grounded assessment comes from industry analyst Monica Schnitger:
"AVEVA's current technology is strong on traditional predictive analytics — but the kind of agentic, actionable industrial AI that's coming requires the specialized data contextualization layer that Cognite has been building for the past decade."
That's the core of what $3.1 billion buys: not an AI model, but the industrial data infrastructure that makes AI models useful.
Industry Benchmarking
Schneider's acquisition of Cognite isn't an isolated event. The 2025–2026 industrial AI acquisition wave follows a clear pattern:
| Deal | Amount | Target | Purpose |
|---|---|---|---|
| Schneider → Cognite | $3.1B | Industrial data platform + AI Agent | Fill AVEVA's data layer gap |
| Autodesk → MaintainX | $3.6B | Asset maintenance management | Fill Autodesk's maintenance workflow gap |
| Siemens → (ongoing M&A)* | Multiple deals* | Industrial software / digital twin | Build Xcelerator ecosystem |
| PTC → continued investment** | —** | ThingWorx / Vuforia | Industrial IoT + AR |
* Siemens' recent M&A includes low-code (Mendix), EDA positioning, etc. Individual deal sizes vary widely with no single disclosed figure. ** PTC has focused on internal product development recently; M&A has been smaller and not separately reported.
Common thread: All the majors are buying "data entry points" and "data orchestration layers," not AI models themselves. Because models can be rented, fine-tuned, and composed — but industrial data infrastructure — connectors, data models, knowledge graphs — takes years to build from scratch.
3. Analysis & Reasoning: A Value Framework for Vertical Industrial AI
This is the core of the article. Setting aside the specific Schneider/Cognite deal, let's return to a more fundamental question:
In vertical AI scenarios, which assets have durable value? Which assets might be rapidly obsoleted by the accelerating progress of general-purpose large models?
3.1 What General-Purpose Models Lack in Vertical Domains
By mid-2026, frontier models (GPT-5 / Gemini 3.5 / Claude Fable 5 / DeepSeek V4) already possess:
- Multimodal understanding (reading images, documents, audio)
- Tool calling and agentic behavior
- Ultra-long context windows (1M+ tokens)
- Code generation and data analysis
Yet they have a structural gap on a critical dimension: native access to domain-specific data streams.
It's not that the models "don't understand oil" — ask GPT-5 how an oil refinery works and you'll get a textbook-quality answer. The problem is that it doesn't know your refinery:
- Which historian database holds your sensor data?
- What's the mapping between your P&ID diagrams and your 3D models?
- Why don't your maintenance record equipment IDs match your ERP asset IDs?
- Which combinations of operating parameters caused downtime over the past three years?
These aren't questions of "insufficient model intelligence" — they're questions of the model having no channel to access your private operational data. This isn't a capability gap, it's a structural data-access problem. And this is the central contradiction of vertical industrial AI: not that AI capability is insufficient, but that the data layer is blocked.
3.2 The Layered Moat Model
The Stanford Law School paper "Defensible Moats for Vertical AI Application Companies" (June 2026) [1] proposes a five-layer moat model for vertical AI, from weakest to strongest:
- Workflow and UX (weakest) — replicable with a better frontend
- Vertical toolset and customization — modest technical barriers
- Built-in compliance capabilities — a regulatory moat
- "Brain" / data-driven operating system — core data plus decision engine
- Embedded Judgment (strongest) — organization + process + data + domain expertise combined
Applying this framework to Cognite:
- Cognite Data Fusion sits between layers 2 and 4. Connector breadth = layer 2; industrial knowledge graph = layer 4.
- Its moat is not at layer 5 (Embedded Judgment) — because Cognite doesn't make operational decisions; it provides the data foundation for decisions.
- But this also reveals its vulnerability: if general-purpose models' data ingestion capabilities significantly improve over the next 2–3 years, the value of Cognite's data contextualization layer will compress.
3.3 The Core Question: Can Vertical Models Outrun the Evolution of General-Purpose Models?

Vertical vs general model competition timeline — short-term data moat → medium-term gap narrowing → long-term structural moat
This is the most critical question in the entire article. Using Cognite as the specimen, my assessment unfolds in three phases:
Short-Term (1–2 years, 2026–2028): Vertical solutions have clear interim advantages
In this window, a solution deeply customized on industry data is unambiguously superior to general-purpose models on narrow, deep, high-value tasks. The reasons are straightforward:
- Data barriers. Ask GPT-6 "what was the energy efficiency trend over the past 72 hours for Distillation Column 3 at TotalEnergies' French refinery?" — GPT-6 doesn't know. It doesn't own TotalEnergies' P&ID diagrams, real-time sensor data, or maintenance records.
- Engineering cost of domain knowledge. A general-purpose model won't automatically know that "pressure transmitter PID-1234's reading drifts above 85°C" — this is equipment-level knowledge that must be engineered into the data layer (annotated, correlated, rule-based).
- Trust cost. No industrial customer will dump operational data into GPT, act on the response, and call it done. There must be data governance, access controls, audit trails.
So in the short term, vertical AI's value is real and measurable. Cognite's 80% reduction in data discovery time for Neptune Energy [source: Cognite official case study, no independent third-party verification] wasn't about the model — it was about connecting the PROSPER simulator to real-time data streams and correlating equipment context via the knowledge graph.
Medium-Term (2–4 years, 2028–2030): The gap narrows rapidly
Several directions of general-purpose model evolution will directly erode vertical moats:
1. Ultra-long context windows. From 1M tokens to 10M tokens or more — theoretically, an entire plant's historical data, P&ID diagrams, and operating manuals could be stuffed into a single prompt. If the model can "read" the entire plant's data by itself, Cognite's "data preparation" layer gets breached.
2. Agent capability maturity. General-purpose models will no longer just answer questions — they'll actively call APIs, query databases, run simulators. But there's a critical precondition here: HYSYS is owned by AspenTech, and the openness of its API and its commercialization strategy are determined by AspenTech, not by OpenAI or Schneider. A general-purpose model being able to call APIs means nothing if the APIs don't exist or aren't open. Making Cognite's Atlas AI Agent layer redundant requires three conditions to be simultaneously met — ① industrial software vendors open standard REST interfaces ② industrial customers accept operational data being transmitted through third-party models ③ the security and compliance framework allows it. None of these three conditions is necessarily true today.
3. Multimodal understanding. General-purpose models reading P&ID scans, CAD drawings, and handwritten maintenance records directly, without OCR + structured preprocessing. If the model can complete the full chain of "read diagram → correlate equipment → query data → output judgment" by itself, then the data contextualization layer is bypassed.
But no matter which path, there's a critical "asymmetry": to bypass Cognite, GPT-6 must simultaneously do three things — read the data, access the data, and have the customer's permission to directly access operational data. The third constraint may be harder to solve than the first two.
Long-Term (4+ years, 2030+): The sustainable moat is not the model
If the ceiling of general-purpose model capability (reading diagrams, calling APIs, understanding time-series data) keeps rising, what can a vertical solution actually hold onto?
Before answering, let's build an asset erosion assessment — Cognite's assets ranked from most fragile to most durable:
| Asset Layer | Erosion Risk | Time Horizon | Substitutability |
|---|---|---|---|
| LLM workbench / Agent orchestration (Atlas AI's surface-level LLM integration) | High | 2–3 years — commoditized by general-purpose Agent frameworks | Substitutable — e.g., AWS/Azure managed Agent services covering industrial scenarios |
| Industrial data connectors (adapters for dozens of data sources) | Medium–High | Depends on standardization pace (OPC UA progress) | Conditionally substitutable — if source vendors open standard APIs |
| Automated data contextualization engine (OCR → entity correlation → knowledge graph) | Medium | Depends on pace of multimodal model capability improvement | Partially substitutable — model advances will erode some of this, but domain tuning still required |
| Industrial knowledge graph model templates (refining/chemicals/power/manufacturing data structures) | Low–Medium | 5+ years | Hard to substitute — requires domain experts + data engineers working together |
| Data governance + permissions + compliance (deployed within customer security boundaries) | Low | Structural barrier, not weakened by model progress | Not substitutable — structural problem, not a capability problem |
| Customer workflow integration (embedded in AVEVA / PI System / Excel / HYSYS) | Very Low | Self-reinforcing with usage duration | Not substitutable — switching costs increase with integration depth |

From most fragile (LLM workbench, 2–3 year commoditization) to most resilient (workflow integration, self-reinforcing) — six asset layers ranked by substitutability
This table reveals Cognite's evolution path: the surface-layer assets will be commoditized by general-purpose model progress, while the foundational assets (governance + integration + graph templates) will persist and even self-reinforce.
Within this layered framework, I believe three things can be held long-term — things no model, however capable, can replace because they aren't capability problems, they are structural and trust problems:
1. Data governance + permissions + compliance. No chemical company is going to expose its real-time operational data to an external API directly. No matter how smart the model, who handles data access control, version management, and audit compliance? The factory's problem is "data can't leave," not "the model isn't smart enough." Cognite's value isn't that it knows how to analyze data — it's that it's already deployed inside the customer's security perimeter.
2. Deep integration with existing tool ecosystems. An engineer's daily workflow runs on AVEVA / PI System / Excel / HYSYS. Cognite's data layer is already embedded in this ecosystem — Excel's OData can pull CDF's contextual data directly; AVEVA can consume CDF's knowledge graph natively. Migration means changing a decade-long working habit. This depth of integration isn't something a better model can replace.
3. The engineered form of domain knowledge. "This vibration pattern means imminent bearing failure on a centrifugal pump, but cavitation on a screw pump" — this kind of knowledge isn't something a general-purpose model can learn through more training data alone. It must be explicitly engineered into the data layer (templates, rules, benchmarks). Cognite's perfect score on "data modeling" in the Verdantix evaluation is a reflection of this capability.
The Core Premise of This Framework
These three-phase assessments depend on an implicit premise: The capability ceiling of general-purpose models > the requirement ceiling of industrial scenarios.
In other words, GPT-6's capabilities are already good enough for the task of "reading real-time refinery data and pushing it to an engineer's dashboard." The bottleneck is not at the model's capability boundary (which keeps expanding) but at whether the data can be cleanly, securely, and in real-time delivered to the model (a structural problem).
This premise currently holds. What industrial scenarios demand from AI is not "smarter" but "more controllable, more auditable, more secure, more compatible with existing workflows." As long as general-purpose model progress covers industrial scenarios' cognitive requirements, the bottleneck stays at the data layer, not the model layer. Cognite is betting on this.
3.4 The Hourglass Model: Is the Middle Layer Fragile or Indispensable?
Zooming out, the value distribution of vertical industrial AI forms an "hourglass" structure:
Upstream: Foundation Models (GPT / Gemini / DeepSeek / Claude)
│ (value flows toward scale: marginal cost → zero)
▼
Middle Layer: Data Contextualization & Industry Knowledge Graphs
↕ (value flows toward proprietary data: marginal value ↑)
▲
Downstream: Industry Applications (Ops Optimization / Root-Cause Analysis / Scheduling)
The middle of the hourglass is both the most fragile and the most critical position.
Most fragile because it's squeezed from both ends:
- Upstream general-purpose models grow stronger and may gradually be able to "directly understand raw data," bypassing the middle layer
- Downstream industry applications, if they go deep enough to build their own data layer (e.g., AVEVA gradually building contextualization capabilities in-house), can also bypass an independent data platform
Most critical because, in the current time window, it is unbypassable — general-purpose models can't even get through the factory door. Without the middle layer's "translation," there is no intersection between upstream general-purpose capability and downstream industry scenarios.
The length of this window depends on a race between two variables:
| Variable | Direction | Impact on Cognite |
|---|---|---|
| Rate of improvement in general-purpose models' native data understanding | Accelerating (context windows, agents, multimodality) | Compresses the middle layer |
| Heterogeneity and closed nature of industrial data | Slowly converging (standards move slowly, legacy data abundant) | Protects the middle layer |
Cognite bets that the latter changes slower than the former — industrial data heterogeneity is not a temporary engineering problem but a structural characteristic: every plant has its own equipment vendors, modification history, naming conventions, and OS versions. OPC UA has been promoted for twenty years, and implementations across equipment vendors remain not fully compatible.
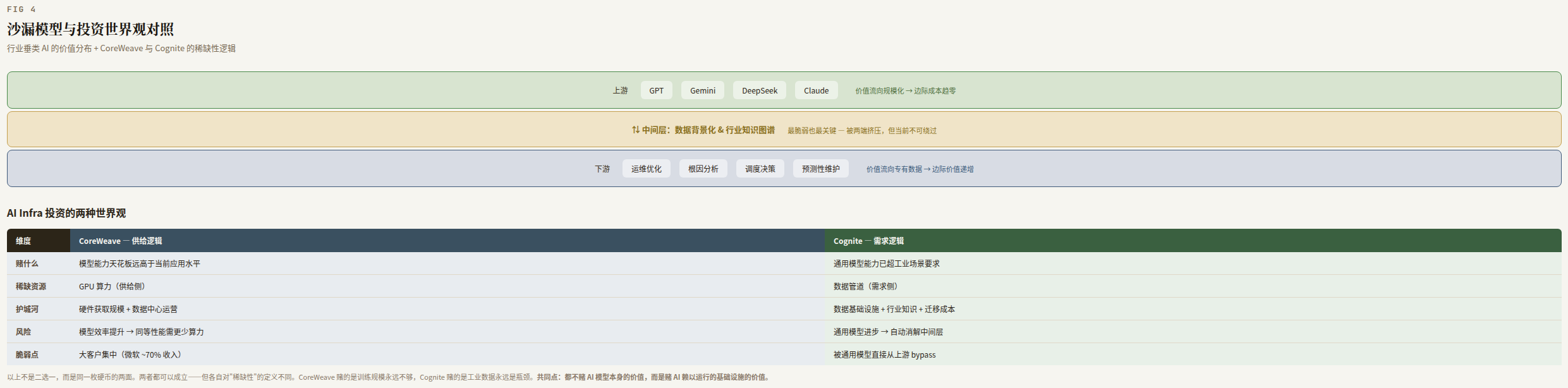
Hourglass model (upstream foundation models → middle data layer → downstream industry applications) with CoreWeave vs Cognite investment logic
3.5 Thought Experiment: CoreWeave's Supply-Side Logic vs. Cognite's Demand-Side Logic
Putting Cognite and CoreWeave side by side reveals two competing worldviews in AI infrastructure investing. The following comparison is not about choosing one over the other — they are two sides of the same coin, and both can be simultaneously true. But each defines "scarcity" very differently.
| Dimension | CoreWeave | Cognite |
|---|---|---|
| Bet | Model capability ceiling is far above current application levels | General model capability ceiling already exceeds industrial scenario requirements |
| Scarce resource | GPU compute (supply side) | Data pipeline (demand side) |
| Moat | Hardware procurement scale + data center operations | Data infrastructure + domain knowledge + customer switching costs |
| Risk | Model efficiency gains → same performance requires less compute | General model progress → auto-dissolves the middle layer |
| Value signal | Training scale keeps growing → GPU demand only goes up | Industrial AI penetration is extremely low → data pipeline demand has 10 more years of growth |
| Vulnerability | Large customer concentration (Microsoft ~70% of revenue) | Being bypassed directly from upstream by general-purpose models |
CoreWeave represents the conviction that "supply is value": the bottleneck in AI is compute, and whoever gets the most GPUs wins. This is a classic "selling shovels in a gold rush" logic. It's right in the short term — GPUs are genuinely in short supply. But its vulnerability is: if model efficiency gains (MoE, distillation, quantization) outpace the expansion of training scale, total GPU demand could peak.
Cognite represents the conviction that "demand-side scarcity" is the real story: the bottleneck in AI isn't model capability, but whether industry data can be made understandable to models. Industrial demand is extremely certain — improve efficiency, reduce downtime, optimize energy consumption — but the obstacle to meeting this demand is data infrastructure, not the model.
These two logics aren't contradictory — they may even both be true simultaneously. But they point to very different valuation yardsticks:
- CoreWeave's valuation looks at GPU deployment scale and customer lock-in
- Cognite's valuation looks at depth of data connectors, customer retention rates, and the irreplaceability of the industry knowledge graph
3.6 Implications for Investors
Back to the opening question: Through the lens of "what has more value in vertical AI scenarios," what does this deal tell us?
Insight 1: Data infrastructure is worth more than the AI model itself. Schneider paid an 18x revenue multiple for data connectors, knowledge graph templates, and customer switching costs — not an AI model. In evaluating vertical AI companies, the "data layer" should carry far more weight than the "AI layer."
Insight 2: Vertical AI value must be assessed across three time windows. Short-term (outperform behind data barriers), medium-term (gap narrows but asymmetric points remain), long-term (model capability keeps improving but data governance + workflow integration + domain engineering create structural barriers no model can replace). Companies that can defend across all three phases have genuine long-term value.
Insight 3: Switching costs are the most durable moat for vertical AI; AI capability is the least durable. If a vertical AI company's core selling point is "use our AI," it will have to prove every year that its models are better than general-purpose models — a race it is destined to lose. If the core selling point is "your data already runs on our platform," its position three years from now will be stronger than it is today.
Insight 4: The race between industrial data standardization and general-purpose model progress determines the middle layer's premium. If general-purpose models' data understanding capabilities make a qualitative leap within three years — with deep contextual understanding becoming table stakes — then Cognite's "data contextualization" premium will compress. But if industrial data heterogeneity persists (my leaning is toward this assumption) — because every plant has its own unique equipment mix, modification history, and data conventions — the middle layer's value may prove more durable than the market expects.
Insight 5: Embedded Judgment is the 5th layer, but the hardest to reach. Cognite is not at this layer — it provides the foundation for decisions but doesn't make the decisions themselves. Companies that truly reach Embedded Judgment (Harvey in legal, Tempus in cancer diagnostics) share a common trait: AI output flows directly into decision nodes within the workflow, rather than being reviewed by humans before use. In the industrial domain, reaching this layer means moving from "decision support" to "autonomous operation" — which requires not just better AI but changes to regulatory frameworks, insurance liability, and safety standards. This transition likely takes five years or more, possibly a decade, and the timeline is highly uncertain.
Epilogue
What Schneider spent $3.1 billion on is not AI capability — it's data order.
Along the value chain of vertical AI, general-purpose model capability is in a state of continuous collapse — growing stronger, cheaper, and more accessible by the day. But this doesn't mean vertical AI has no value; quite the opposite — it means the "pipeline" that connects general-purpose capability to industry data is scarcer than general-purpose capability itself.
And the scarcity of that pipeline depends on the outcome of two races:
-
Race one: General-purpose models' native data understanding vs. industrial data heterogeneity. The former is accelerating (ultra-long context windows, agentic access, direct multimodal reading); the latter is slowly converging (standards are hard to unify, legacy equipment retrofit is slow). Looking back three years from now, if models can autonomously understand and analyze industrial data within security boundaries, the middle layer will compress. If industrial data remains "a headache for everyone who touches it," then Cognite's layer is a mandatory pathway.
-
Race two: The speed at which vertical companies can migrate their asset composition. If Cognite can, within the next two years, transform from a "data connector vendor" into a "standard-setter for industry knowledge graphs" and achieve deeply embedded decision-making (layer 5), then its 18x valuation is not expensive. If it remains stuck between layers 2 and 4, it will face the squeeze of upstream model progress on one side and downstream application self-build on the other.
Together with CoreWeave, this deal forms two extreme specimens of 2026 AI infrastructure investing — one betting on the supply side (compute will never be enough), the other on the demand side (data will always be the bottleneck). Their common ground: neither is betting on the value of the AI model itself. Both are betting on the value of the infrastructure that AI models depend on to run. This consensus, in itself, is the most authentic signal from the AI industry in 2026.
Sources: Bloomberg, Reuters, Schnitger Corp, Cognite official press releases, Verdantix Green Quadrant 2025, ARC Advisory Group, Stanford Law School "Defensible Moats for Vertical AI Application Companies" (June 2026), Euclid Ventures "The Vertical Report 2026." Data as of June 30, 2026. Not investment advice.
[1] Stanford Law School, "Defensible Moats for Vertical AI Application Companies in a New Competitive Landscape," June 2026. Source link: https://law.stanford.edu/wp-content/uploads/2026/06/Defensible-Moats-for-Vertical-AI-Application-Companies-in-a-New-Competitive-Landscape.pdf