Three things happened almost simultaneously in May 2026. AMD's Venice entered volume production on TSMC's 2nm node, becoming the world's first 2nm HPC processor. NVIDIA's Vera CPU shipped its first units to OpenAI and Anthropic — 88 custom Arm cores with benchmark numbers reviewers called "unprecedented." And Intel disclosed that CPU-to-GPU ratios in AI clusters are shifting from 1:8 toward 1:4, even 1:1. Meanwhile, Citi projected the server CPU market would hit $132 billion by 2030, with a new category — "Agentic CPUs" — growing at a 185% CAGR.
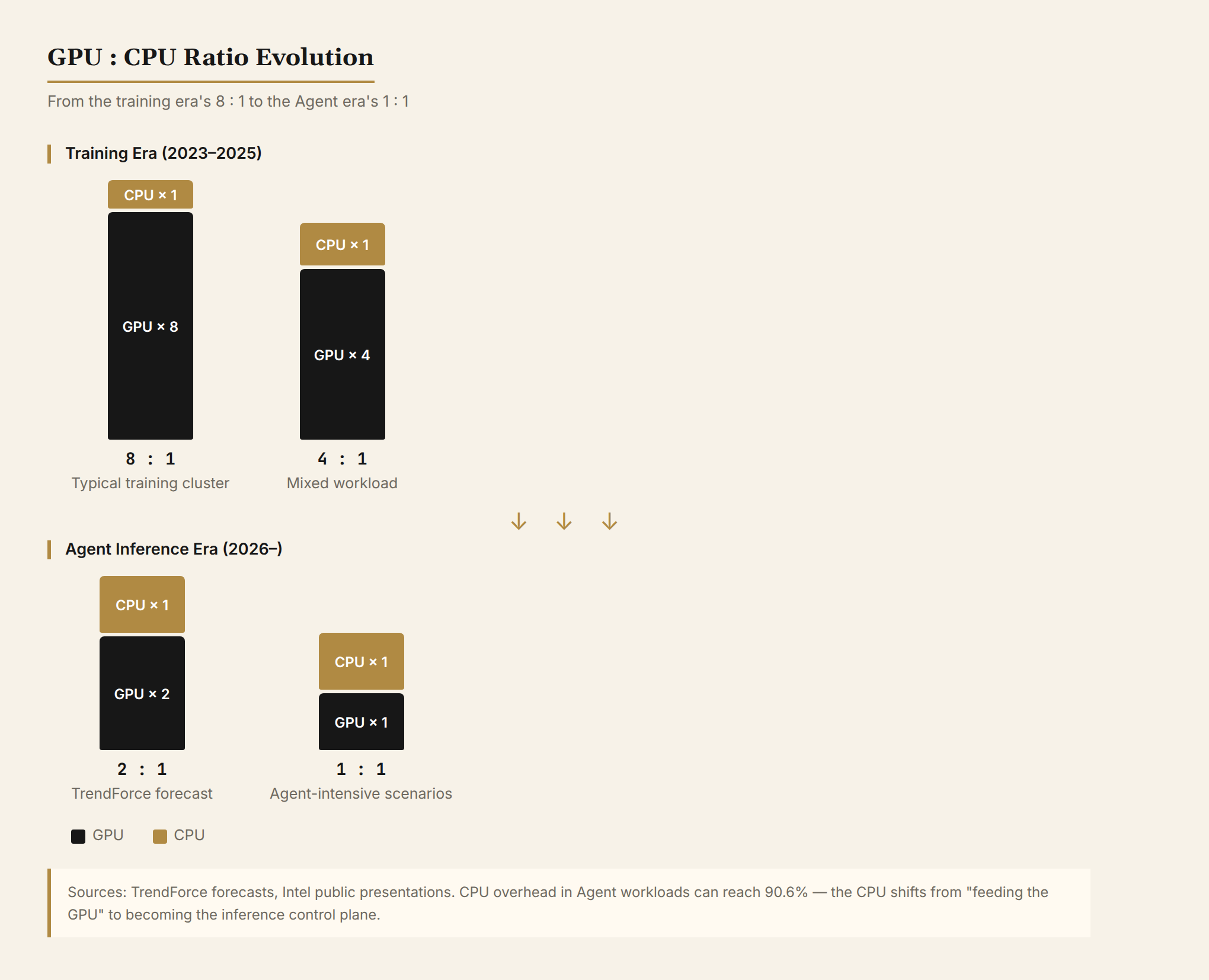
For three years, all eyes were on GPUs. CPUs in AI servers were just there to feed the GPUs. Now, the CPU is going from afterthought to bottleneck.
1. Why AI Inference Needs So Much CPU
Training and inference place fundamentally different demands on the CPU.
During training, GPUs handle nearly all the heavy lifting — large matrix multiplies, gradient backpropagation, parameter updates. The CPU's job is simple: decompress data, tokenize, schedule batches, and feed the GPU. At this stage, a GPU-to-CPU ratio of 8:1 works fine. The CPU accounts for roughly 12% of the data center compute budget.
Inference, especially agentic inference, changes everything.
An agent request is not a single model call. It's an entire workflow: retrieve context, invoke tools (search, databases, APIs), route to different models, evaluate intermediate results, maintain long-context state, and decide the next step. The GPU handles the model's forward pass, but task orchestration, thread scheduling, process management, sandbox execution, KV Cache management, sampling, and guardrails processing — that's all CPU work.
Dylan Patel, chief analyst at SemiAnalysis, puts it bluntly: AI workloads are evolving from simple text generation toward complex agents and reinforcement learning, and CPUs are facing an "extremely severe capacity shortage." Research shows that in agent workloads, CPU overhead can account for up to 90.6% of total compute time, with GPUs often sitting idle waiting for data.
The result: ratios are shifting fast from the training-era 1:8 (one CPU per eight GPUs) toward 1:4, 1:2, or even 1:1. TrendForce predicts the agent era will settle at 1:1 to 1:2. Intel itself says the GPU:CPU ratio was 8:1 during training, has dropped to 4:1, and could reach 1:1 — or even flip.
The CPU isn't just "the thing that feeds the GPU" anymore. It's the control plane of AI inference.
2. The Big Three's New CPU Hands
NVIDIA Vera: From GPU Company to CPU+GPU Duopolist
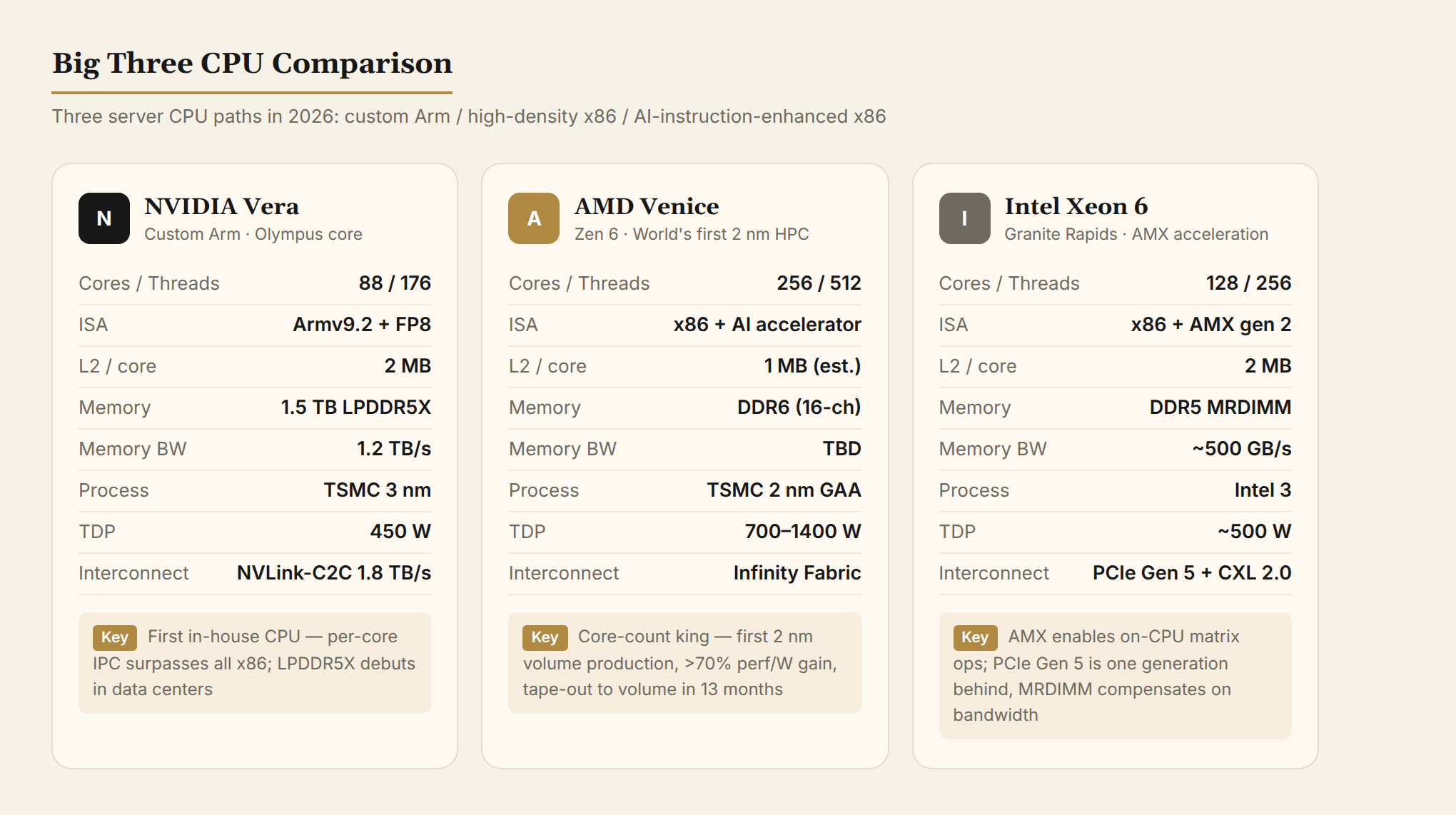
Vera is NVIDIA's first "truly self-designed" CPU. The previous generation, Grace, used Arm's off-the-shelf Neoverse V2 cores. Vera swaps in NVIDIA's own Olympus core — NVIDIA isn't optimizing someone else's design anymore. They're starting from the architecture up.
Key specs:
- 88 Olympus cores, 176 threads (spatial multithreading, similar to SMT but without shared ALUs)
- Armv9.2 instruction set with FP8 support (8-bit floating point, a precision format designed for AI inference)
- 2 MB L2 cache per core (double Grace's), 164 MB unified L3
- 1.5 TB LPDDR5X system memory, 1.2 TB/s memory bandwidth
- NVLink-C2C (NVIDIA's custom chip-to-chip interconnect) at 1.8 TB/s
- PCIe Gen 6 + CXL 3.1 (Compute Express Link, a protocol that lets CPUs and devices share memory pools)
- 450W TDP, TSMC 3nm
One design choice worth noting: Vera is the world's first data center CPU to use LPDDR5X. Traditional server CPUs use DDR5 or HBM (High Bandwidth Memory, the stacked memory commonly found on GPUs). LPDDR5X was previously confined to phones and thin laptops. NVIDIA chose it for energy efficiency — LPDDR5X delivers high bandwidth at low power, with industry-leading performance per watt. The tradeoff: each CPU consumes a massive quantity of LPDDR5X dies, and large-scale shipments could strain the supply chain.
First customers have been delivered: OpenAI, Anthropic, CoreWeave, Meta, Oracle. Vera comes in two form factors — standalone LPX servers and the host CPU inside the Vera Rubin NVL72 rack. NVIDIA's CFO says the CPU business (standalone CPUs + built-in superchip CPUs) is a $20 billion opportunity.
Phoronix First Benchmarks (May 26, 2026):
Testing was conducted by Phoronix's Michael Larabel at NVIDIA's Santa Clara headquarters, covering code compilation, Python performance, OpenJDK Java, AV1 video encoding, 7-Zip compression, LuaJIT, ClickHouse database, and Renaissance JVM — all enterprise-grade workloads.
| Comparison | Result |
|---|---|
| vs. 72-core Grace (previous gen) | Geometric mean 63% faster |
| vs. AMD EPYC 9575F (64-core Zen 5, 5 GHz) | Geometric mean 10% faster |
| vs. Intel Xeon 6980P (128-core Granite Rapids) | Geometric mean 55% faster |
| 7-Zip single-threaded | ~20% higher than all x86 chips |
| Linux kernel compilation | 2× faster than x86 (NVIDIA's claim) |
| vs. all ARM server chips | "Comfortably surpasses" Ampere, Google Axion, Microsoft Cobalt |
Key caveat: Larabel noted that Vera showed "competitiveness with Intel/AMD x86_64 processors that I have not seen on any other ARM or non-x86_64 processor." However, the test suite was selected by NVIDIA and doesn't represent full-spectrum performance. Power consumption data was not available for monitoring. Per-watt efficiency numbers have not yet been published.
The more important story is single-threaded performance. Historically, ARM server chips compensated for weak single-core performance by stuffing in more cores to inflate multi-threaded scores. Vera's single-threaded compilation was beaten only by the EPYC 9575F, and in Linux kernel builds it actually came out on top. Going from "padding scores with cores" to "going toe-to-toe on single-thread" is a watershed moment for ARM server chips.
How Does Olympus Achieve Such High Single-Thread IPC?
NVIDIA hasn't published an Olympus microarchitecture whitepaper, but from the specs, industry patterns, and NVIDIA's own engineering history, several key factors emerge:
1. Custom vs. off-the-shelf is the fundamental difference. Grace used Arm's stock Neoverse V2 cores — a general-purpose design that has to balance the needs of all licensees. Olympus was designed from scratch by NVIDIA for one scenario: AI data centers. This means NVIDIA can make aggressive architectural tradeoffs tuned for AI workload characteristics (long contexts, high-frequency tool calls, state management) without worrying about generality.
2. Massive L2 cache. Each Olympus core gets 2 MB of L2 — double Grace's 1 MB, and well above typical server cores (Zen 5 is 1 MB; Xeon is 2 MB but with fewer cores). Larger L2 means fewer cache misses and a higher IPC ceiling. Compilation workloads are particularly sensitive to L2 hit rates — which explains why Vera excels at Linux kernel builds.
3. 1.2 TB/s memory bandwidth eliminates starvation. IPC isn't just about compute width. If data can't be fed fast enough, even the widest execution units stall. LPDDR5X at 1.2 TB/s reduces the penalty of a cache miss from hundreds of cycles to tens. For comparison: Zen 5's DDR5 delivers roughly 460 GB/s. Vera's memory bandwidth is 2.6× that.
4. Likely a wider decode/execution engine. Arm's stock Neoverse V2 is a 4-wide decode design. Apple's custom M-series achieved 8-wide, giving it industry-leading single-thread IPC. NVIDIA has every incentive to go wide — a custom architecture isn't constrained by the die area budgets that Arm has to work within for its off-the-shelf cores. The 20% single-thread lead in 7-Zip hints at execution width or instruction fusion advantages.
5. Twelve years of custom CPU experience. Olympus isn't NVIDIA's first CPU. The Denver core in the 2014 Tegra K1 used VLIW + dynamic binary optimization — software-managed pipeline scheduling to maximize IPC. Denver's single-thread performance crushed the contemporary Cortex-A15 in mobile benchmarks. While Olympus is almost certainly not VLIW (server workloads are too diverse for VLIW to work well), NVIDIA has accumulated 12 years of microarchitecture design and verification methodology since Denver.
6. 3nm process. Higher transistor density means NVIDIA can spend more transistors on branch predictors, prefetchers, and reorder buffers (ROBs) — the key IPC-building blocks — without worrying about die area or power budgets.
In short: Olympus's single-thread advantage isn't one magic trick. It's the systemic dividend of a custom architecture — bigger caches, wider execution, faster memory, freer microarchitectural tradeoffs. This is the Apple playbook successfully replicated on server CPUs for the first time.
AMD Venice: The World's First 2nm HPC Processor
On May 21, 2026, AMD announced that its sixth-generation EPYC "Venice" had entered volume production ramp. This is the world's first high-performance computing CPU on TSMC's N2 (2nm) process, and the first outing for the Zen 6 architecture.
Key specs:
- Zen 6 architecture: 96-core standard + 256-core high-density (512-thread) configurations
- vs. previous-gen Turin (Zen 5): >70% improvement in performance and efficiency, >30% increase in thread density
- PCIe Gen 6, DDR6 (yes, DDR6 — not DDR5)
- 700–1400W TDP, entering the kilowatt class for the first time
- Taped out April 2025; 13 months from tapeout to production
256 cores and 512 threads — what does that mean in practice? The current top-end Turin maxes out at 192 cores / 384 threads. Venice pushes straight to 256. For agent inference, where multiple agents run concurrent, independent workflows, core count equals concurrency capacity.
AMD CEO Dr. Lisa Su has doubled the long-term server CPU TAM forecast from $60 billion to over $120 billion. Citi is even more aggressive at $131.5 billion.
Roadmap: After Venice comes "Verano," purpose-built for AI agent workloads, with enhanced LPDDR memory integration and energy efficiency.
Intel Granite Rapids: Holding the x86 Line
Intel took a different path on CPUs. Instead of chasing maximum core counts (Xeon 6 tops out at 128 cores), they invested most heavily in AI acceleration instructions.
Key moves:
- Xeon 6 (Granite Rapids) integrates AMX (Advanced Matrix Extensions — Intel's hardware matrix accelerator built into x86), enabling INT8/BF16 matrix operations directly on the CPU
- AMX debuted in Sapphire Rapids; Granite Rapids is the second generation, with TMUL (Tile Matrix Multiply Unit) capable of 8×8 tile matrix multiply-accumulate
- 128 cores + 144 MB L3 + DDR5-6400 (MRDIMM up to 8800 MT/s) + CXL 2.0
- PCIe Gen 5 (one generation behind), but memory bandwidth is boosted to ~500 GB/s via MRDIMM (Multiplexed RDIMM, which multiplexes bandwidth on a single DIMM)
- TDX (Trusted Domain Extensions, Intel's confidential computing ISA) support
Intel's logic: the things GPUs can't do — tool invocation, state management, data orchestration — the CPU needs to do as fast as possible. AMX lets the CPU run matrix operations in scenarios where dispatching to a GPU isn't worth the overhead: small-batch inference, pre-processing, post-processing.
3. Three Rapidly Advancing CPU Technology Vectors
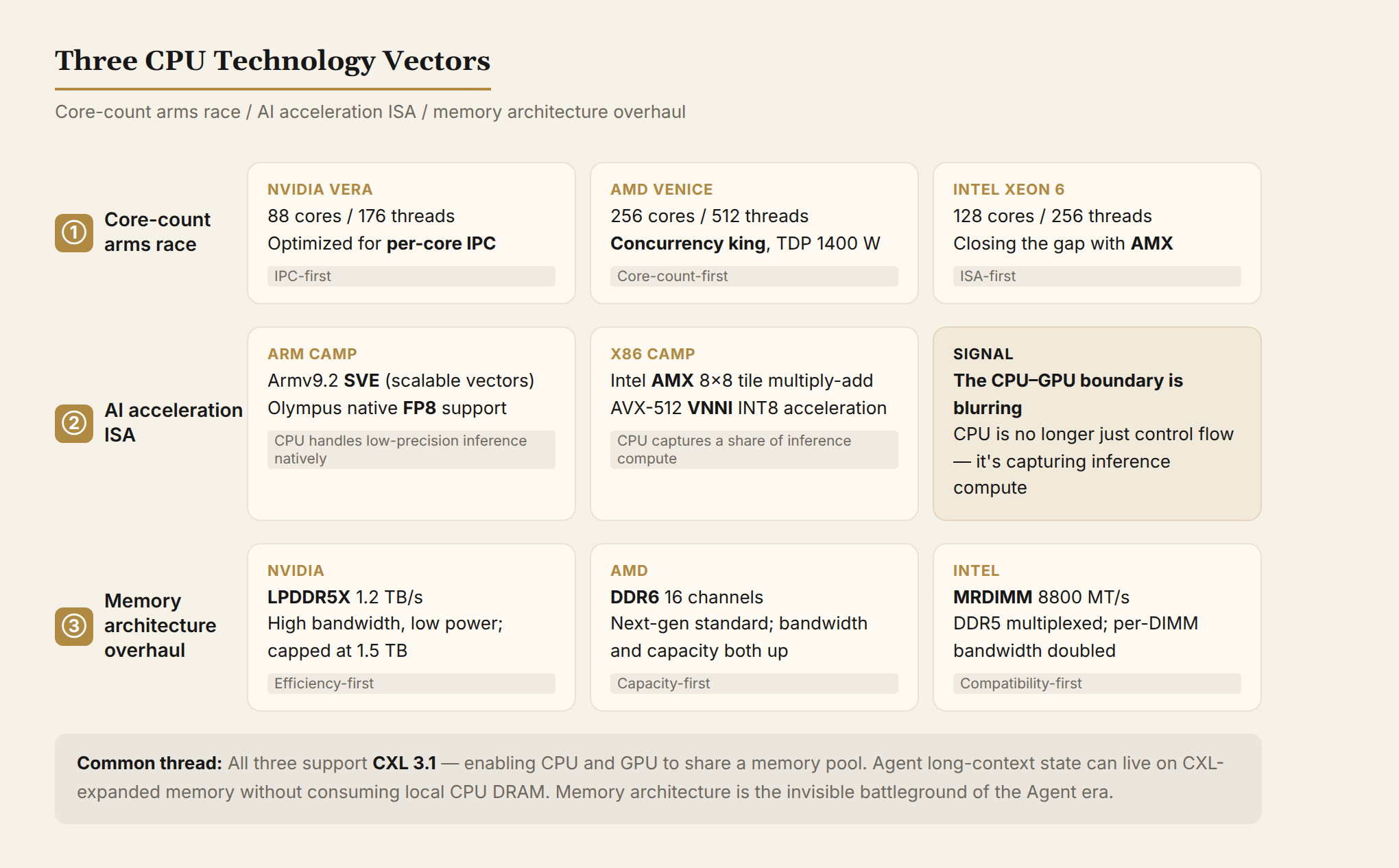
3.1 Core Count Arms Race: From 64 to 256 Cores
Agent inference is a naturally concurrent workload. A single user request might decompose into multiple sub-tasks, each with its own independent tool-call chain. This means the CPU needs to manage dozens to hundreds of execution contexts simultaneously.
How the three are responding:
- AMD Venice: 256 cores, 512 threads — the chip-level concurrency king
- NVIDIA Vera: 88 cores, 176 threads — betting on single-thread performance and efficiency
- Intel Xeon 6: 128 cores — using AI instructions to compensate for fewer cores
More cores aren't always better. 256 cores mean a large die and enormous power draw (Venice TDP hits 1400W), with severe cooling challenges. But for CPU-bottlenecked agent workloads, multi-core concurrency is a hard requirement.
3.2 AI Acceleration Instructions: CPUs Are Doing Tensor Math Too
The CPU is no longer just a "general-purpose processor." All three vendors are adding AI acceleration units to their CPUs:
x86 camp (Intel/AMD):
- Intel AMX: hardware-level tile matrix multiply-accumulate; INT8 inference throughput is 4× over pure AVX-512
- AMD Zen 6 introduces similar AI acceleration units (details pending Computex)
- AVX-512 VNNI (Vector Neural Network Instructions): each instruction performs 64 INT8 multiply-accumulate operations
Arm camp (NVIDIA/custom/cloud vendors):
- Armv9.2 SVE (Scalable Vector Extension): variable-length vectors, from 128-bit to 2048-bit
- NVIDIA Olympus supports FP8 (8-bit floating point): CPU cores can directly execute low-precision floating-point operations
- AWS Graviton, Google Axion, and other cloud-vendor custom Arm CPUs are also adding AI acceleration
The signal: the boundary between CPU and GPU is blurring. CPUs aren't just handling control flow anymore — they're also claiming a share of inference compute, especially for low-latency, small-batch scenarios.
3.3 Memory Architecture Overhaul: LPDDR5X, MRDIMM, CXL
Agent inference has two memory characteristics: long contexts (KV Cache can reach tens of GB) and high-frequency random access (state management, tool calls).
- NVIDIA Vera chose LPDDR5X: high bandwidth (1.2 TB/s) + low power, but capacity-capped at 1.5 TB
- AMD Venice supports DDR6: next-generation memory standard with simultaneous bandwidth and capacity improvements
- Intel Xeon 6 supports MRDIMM: multiplexed DDR5, doubling per-DIMM bandwidth to 8800 MT/s
- CXL 3.1: all three support it. CXL (Compute Express Link) allows CPUs and GPUs to share memory pools, so agent long-context state can live on CXL-expanded memory without consuming CPU-local memory
Memory architecture is the hidden battleground of the agent era. Whoever can read and write state faster, whoever manages context more efficiently, will be the better fit for the agent control plane.
4. x86 vs. Arm: Who's Capturing the Incremental Demand?
Bank of America's projection is worth noting: by 2030, in server CPU value share, Intel and AMD each hold about 28%, commercial Arm CPUs about 7%, and custom Arm/ASIC about 37%.
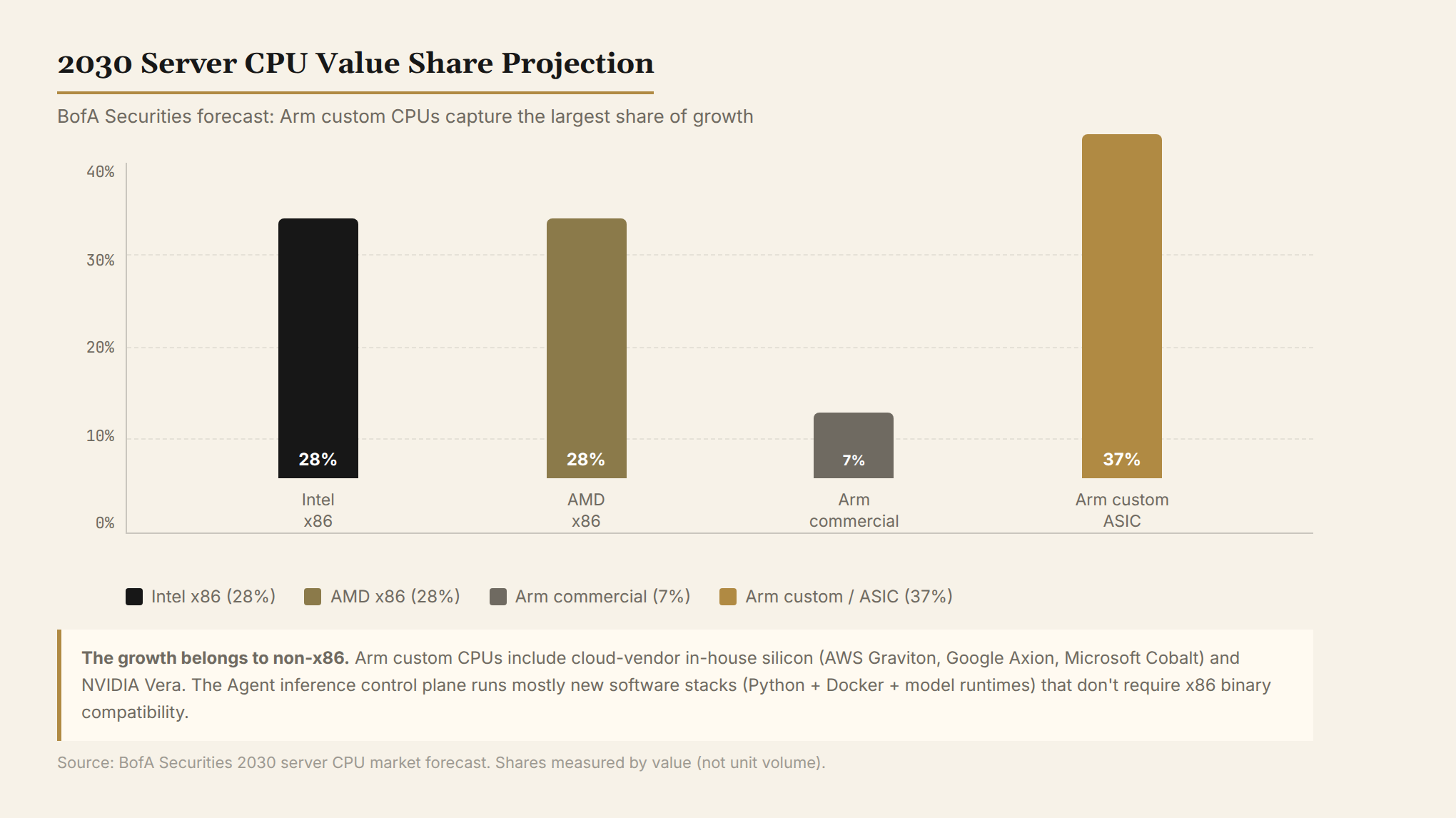
The incremental demand isn't going to x86.
"Custom Arm CPUs" refers to cloud-vendor designs (AWS Graviton, Google Axion, Microsoft Cobalt) and NVIDIA's Vera. These chips don't pursue x86 compatibility — they're designed from scratch for specific workloads like agent orchestration and inference control planes.
This is not good news for Intel and AMD. x86's moat is ecosystem compatibility — decades of accumulated software. But the agent inference control plane software stack is mostly new: Python runtimes, container sandboxes, KV Cache management, tool-calling frameworks. These don't require x86 binary compatibility. Arm can run them, and often more power-efficiently.
AMD is the strongest x86 player (Zen architecture leads on efficiency), but in the incremental market, custom Arm CPUs are eating faster. NVIDIA, thanks to Vera + the full CUDA ecosystem, is capturing both GPU budgets and CPU budgets.
5. China's CPU Landscape: Four Routes, Who's Catching the Agent Wave
In 2025, China's domestic PC and server CPU market share broke 20% for the first time. By Q1 2026, it had surged to 25%. Government cloud adoption is at 94.7%; finance and telecom exceed 30%; even the server market — the hardest nut to crack — has jumped from 10% two years ago to 25%.
This isn't a policy-driven numbers game. Hygon had ¥12.8 billion in backlog orders stretching into Q3 2026. Loongson's 3A6000 shipped over one million units. Phytium's server CPU shipments grew 60% year-over-year. Domestic CPUs are moving from "usable" to "genuinely good."
The x86-Compatible Route: Hygon Leads
Hygon Information is the undisputed leader in domestic commercial server CPUs. Through a permanent AMD Zen architecture license, Hygon's 5000 series (7nm) and 6000 series (5nm) deliver performance close to international mainstream, with 100% x86 ecosystem compatibility and near-zero migration cost. 2025 revenue hit ¥14.377 billion; Q1 2026 revenue was ¥4.034 billion (+68% YoY), with ¥12.8 billion in backlog orders. Domestic x86 CPU market share: approximately 28–30%.
Hygon's advantage is speed to market — the fastest path to a competitive product. The weakness is equally clear: dependency on AMD licensing limits self-sufficiency. CPU TDP sits at 250W, on the high side. No mobile CPU roadmap exists. More critically, the AMD license covers Zen 3, which is now two generations behind AMD's current Zen 5/Zen 6. Future license upgrades are uncertain.
Zhaoxin takes a differentiated approach — the best Windows compatibility among x86 licensees, targeting commercial office and education markets. Its upcoming KX-8000, launching later this year, will approach 4 GHz clock speeds. Zhaoxin's positioning is closer to "the cost-effective choice for government-procured desktop CPUs" than a high-performance server play.
The ARM Route: Kunpeng and Phytium Divide the Market
Huawei Kunpeng's core competitive advantage isn't the chip itself — it's the full-stack ecosystem: chip + EulerOS + GaussDB + Huawei Cloud, with over 5,000 partner companies in the光合组织 (Photosynthesis Alliance). In financial and telecom procurement, Kunpeng's market share exceeds 50%. The Kunpeng 950 has been announced, with 96-core and 192-core variants optimized specifically for AI large models and supercomputing.
Kunpeng leads the domestic ARM server CPU field, but its iteration speed — four years from Kunpeng 920 to 950 — lags far behind international peers (AMD EPYC ships a new generation every two years). The high-end Kunpeng 950-96 is expected to enter volume production in Q4 2026; current competitiveness at the top end remains insufficient.
Phytium is the ARM shipment champion for government procurement — cumulative sales exceeding 13 million units, the default choice for government office desktops. The D3000 (desktop) draws only 18W; the Tengyun S5000C (64-core server) has entered top-tier cloud vendor supply chains. But Phytium's process is stuck at 14nm, a glaring gap versus TSMC's 2nm/3nm, placing a hard ceiling on high-end performance.
The Self-Designed ISA Route: Loongson's Ecosystem Inflection
Loongson Technology is China's only fully self-designed CPU company — the LoongArch instruction set is 100% original, with zero reliance on foreign licenses. The 3A6000 desktop CPU scores 51 on SPEC CPU2006 single-threaded integer — smooth enough for everyday office work. The 3C6000 server CPU (16–64 cores) is in development.
In May 2026, Loongson's 3A6000 shipments surpassed one million units. This isn't just a sales figure — it marks crossing the "ecosystem inflection point." Loongson's browser and binary translation technology allows existing x86 applications to run on LoongArch, with over 20,000 software titles now adapted, covering tax, education, and government. Q1 2026 orders exceeded ¥8.2 billion; full-year profitability is expected.
Loongson's positioning is the highest-security-controllable route — the first choice for government, military, and classified domains. The weakness: performance still trails (single-thread roughly 60–70% of a comparable Intel part), and ecosystem migration carries extra adaptation costs.
Sunway uses the SW-64 fully autonomous architecture, positioned exclusively for military and supercomputing applications — the highest self-controllability rating, but not competing in commercial markets.
RISC-V: The Open-Source Variable
RISC-V is the only CPU instruction set that requires no licensing fee to any foreign company. For China's CPU industry, its strategic value is straightforward: "never worry about supply cutoff."
Alibaba's T-Head Xuantie series represents the RISC-V camp. In May 2026, the Xuantie 9 series became the first RISC-V chip to successfully run Android 16, passing over 68,000 core compatibility tests — meaning RISC-V has formally entered the mainstream consumer electronics ecosystem. Chipreply's K3 chip has been adapted for HarmonyOS 6.1; the Chinese Academy of Sciences released the "Ruyi" native OS. RISC-V's hardware-software ecosystem is connecting fast.
But RISC-V currently covers mainly embedded and edge scenarios. Server-grade high-performance CPUs are still early-stage. Nuclei System Technology, Sophgo, and others are pushing RISC-V server chips, but performance and ecosystem remain far from x86/Arm. JJW.com judges that RISC-V's "golden window" comes from the CPU supercycle, but forming genuine competitiveness in the server market may take another 3–5 years.
Four Routes: Market Share and Trajectories
| Route | Key Players | 2026 Share (domestic) | Strength | Weakness |
|---|---|---|---|---|
| x86-compatible | Hygon, Zhaoxin | ~35% | Seamless ecosystem migration; commercial default | License dependency; limited autonomy |
| ARM | Kunpeng, Phytium | ~40% | Low power; high government-procurement volume | Process gap (14nm); insufficient high-end competitiveness |
| Self-designed ISA | Loongson, Sunway | ~20% | Fully self-controlled; default for classified domains | Performance gap; ecosystem migration cost |
| RISC-V | Xuantie, Nuclei, Sophgo | ~5% | Open-source, royalty-free; immune to supply cutoff | Server scene immature; early-stage ecosystem |
System Integrators: Who's Getting Domestic CPUs into Data Centers
Domestic CPUs don't ship in a vacuum — they rely on system integrators for adaptation, integration, and the last mile into customer data centers.
IDC 2025 data on China's x86 server system integrators:
| Vendor | 2025 Share | YoY Change | Positioning |
|---|---|---|---|
| Inspur Information | 31.3% | ↑ (from 27.8% in 2024) | #1; AI server leader, storage business top 2 in China |
| xFusion | 12.7% (x86 measure) | ↑ | #2; #1 in domestic server revenue by value; liquid-cooled servers #1 four years running |
| H3C (Unisplendour) | 12.5% | — | #3; AI compute infrastructure revenue +45% YoY |
| Lenovo | 10.7% | — | #4; AI server revenue +50% YoY; ISG profitable for full year |
| ZTE | 8.5% | — | #5; strong in telecom operator market |
| Huawei (Kunpeng servers) | Outside x86 scope | — | ARM servers; ARM share in operator procurement at 65% |
Several signals stand out:
xFusion's rise is the most dramatic story of this cycle. Huawei spun off its x86 server business to Henan state capital in 2021; within five years, revenue surged from ¥10 billion to ¥58.2 billion (2025). In May 2026, xFusion filed for a ChiNext IPO with a valuation up to ¥80 billion. xFusion is the highest-tier partner in the Ascend ecosystem, ranking first in both Ascend shipment value and volume — meaning it's capturing not just general-purpose server demand, but also the AI accelerator substitution wave. Its liquid-cooled servers have led the market for four consecutive years, with over 100,000 liquid-cooled nodes deployed, making it the preferred vendor for hyperscale liquid-cooled deployments at top internet companies.
Lenovo ISG's inflection point has arrived. The Infrastructure Solutions Group recorded full-year revenue exceeding ¥136 billion (+32% YoY) and turned its first full-year profit. AI server revenue grew 50% YoY with an order backlog exceeding ¥140 billion. Lenovo CEO Yang Yuanqing's judgment: "In the future, 70% of GPU servers will be used for inference, 30% for training." If that holds, agent inference will continue to amplify demand for CPU-intensive servers.
Inspur Information remains #1 at 31.3%, but growth is primarily driven by AI servers and storage. Q1 2026 net profit was ¥605 million (+30.7% YoY). Inspur is one of Hygon's largest integration platforms — a significant share of Hygon's total shipments go through Inspur systems.
The integrator landscape tells us this: domestic CPUs aren't just running benchmarks in labs. They've entered the data centers of telecom operators, banks, and top internet companies through these integrators. xFusion's ¥58.2 billion revenue and 10,000+ customer base in 2025 proves that domestic CPU servers have moved from "usable" to "procured at scale."
Trend calls:
-
The x86-compatible route is strongest in the near term, but license-limited long-term. Hygon is the primary beneficiary of the agent CPU wave — x86 ecosystem compatibility means the lowest migration cost for customers. But the licensed architecture is two generations behind, and future upgrades carry uncertainty.
-
The ARM route captures the largest incremental share. ARM-architecture servers now account for 65% of telecom operator procurement. If Kunpeng 950's AI-scene optimizations can catch the agent inference wave, it has a shot at anchoring a core position in domestic AI clusters.
-
Loongson's "million-unit shipment" is a landmark event. It proves that a fully self-designed CPU can transition from policy-driven to market-driven. If LoongArch can run the agent stack (Python + Docker + inference engines), the barrier to entry is far lower than for traditional enterprise workloads.
-
RISC-V is a variable 3–5 years out. Xuantie's Android compatibility is a critical ecosystem breakthrough. But the server market demands high-performance cores, mature OS support, and a complete toolchain — RISC-V is still building these.
6. Judgments
-
The CPU "supercycle" is real, not hype. The GPU:CPU ratio shifting from 8:1 toward 1:1 means CPU demand grows 4–8×. GPUs aren't being replaced — agent inference is introducing entirely new CPU-intensive workloads.
-
NVIDIA is the biggest winner of this cycle. It's not just selling GPUs anymore — it's selling Vera CPUs, even standalone CPU racks. The transition from "GPU company" to "AI infrastructure company" hinges on the CPU.
-
x86 won't die, but the incremental demand goes to Arm. Intel and AMD can hold the installed base (enterprise, databases, traditional cloud), but the CPU budgets for agent inference — the new growth segment — will mostly flow to custom Arm chips.
-
AI acceleration instructions like AMX and FP8 are the CPU's "second curve." CPUs aren't just doing general-purpose compute anymore. They're claiming a share of inference compute, further blurring the CPU-GPU boundary.
-
The barrier to entry for Chinese CPUs is lower than expected. The agent software stack is new; x86 compatibility isn't a hard constraint. The process gap is a long-term challenge, but in agent scenarios, architectural optimizations (core count, memory bandwidth, instruction sets) can partially compensate for process disadvantages.
Data as of May 28, 2026. International technical specifications sourced from AMD's official announcement, NVIDIA's GTC 2026 launch, GF Securities/Citi/Bank of America research reports, SemiAnalysis, and Phoronix's early Vera benchmarks. Domestic data sourced from IDC China server market reports, company financial disclosures and announcements, and JJW.com analysis. Some specs (Zen 6 AI acceleration unit details, DDR6 parameters) are pending formal disclosure at Computex 2026.