Deconstructing the HPE AI Factory: The Integration Experiment of Compute, Storage, Software, and Cray
At HPE Discover in June 2026, CEO Antonio Neri said:
"An AI factory does one thing: convert electrical power into tokens."
This reframes AI infrastructure from "data center" to "factory" — an industrial system with input (electricity), output (tokens), yield rates (utilization), and production lines (the four layers of compute–network–storage–software).
But a factory needs equipment. What equipment did HPE announce at Discover 2026? Which is genuinely new and which is repackaged? Where is Cray's supercomputing legacy in all this? This article takes the AI factory's equipment landscape apart, layer by layer.
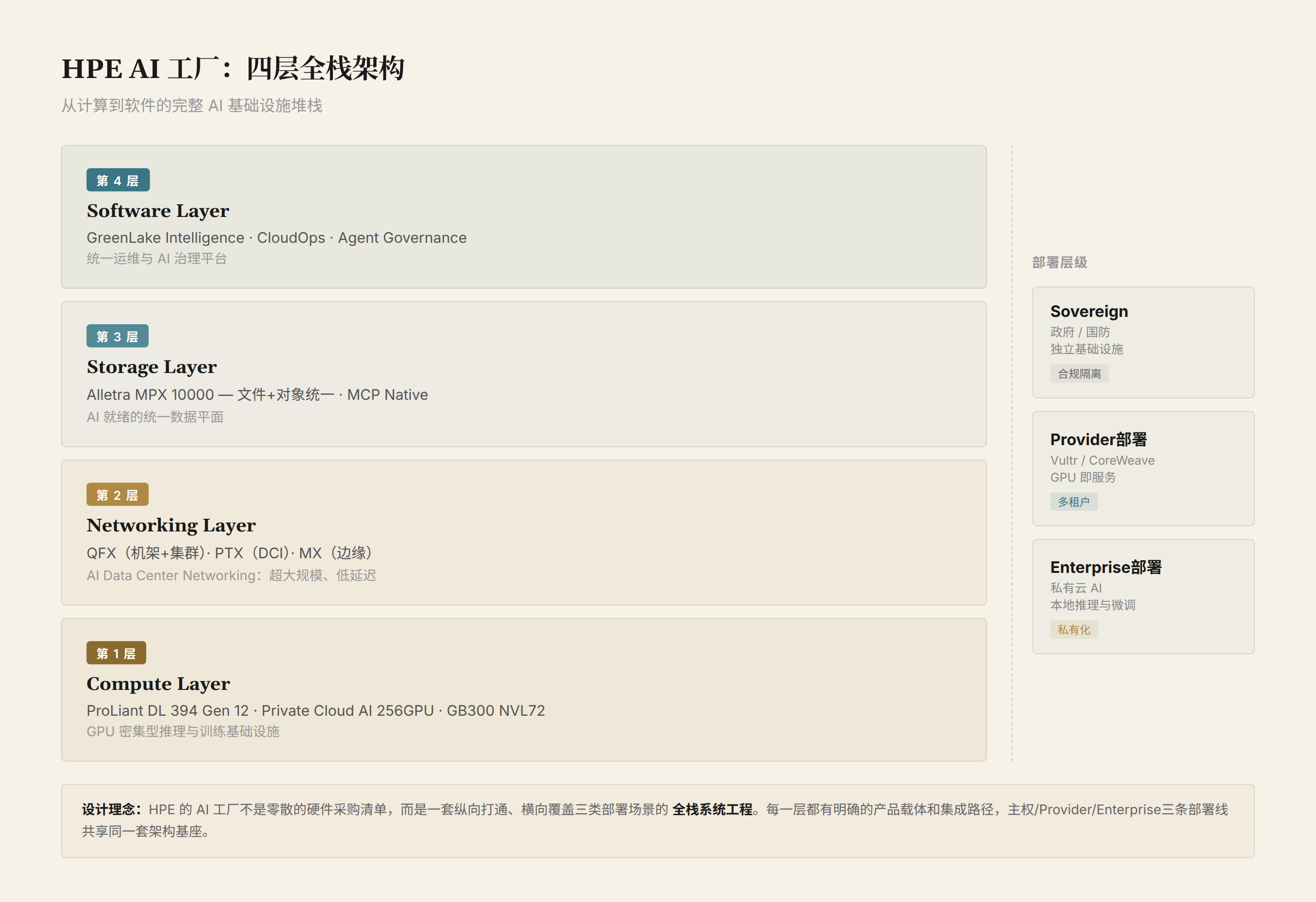
The Four-Layer Architecture of the AI Factory
At Discover 2026, HPE divided the AI factory into four deployment tiers and four technology layers.
Deployment tiers (from largest to smallest):
| Tier | Scenario | Typical Customer |
|---|---|---|
| Sovereign | National-scale AI infrastructure | Government, defense, research institutions |
| Service Provider | Public cloud / AI inference service providers | Vultr, CoreWeave, emerging GPU clouds |
| Enterprise | Private cloud AI | Large enterprises, finance, healthcare |
| Edge | Distributed inference | Branch offices, factories, retail stores |
Technology layers: Compute → Network → Storage → Software. We'll deconstruct each layer below.
The Compute Layer: From General-Purpose Servers to AI Factory Production Lines
ProLiant DL 394 Gen 12: The Agent-Dedicated Server
The only entirely new compute product announced at Discover 2026. HPE officially positions it as "purpose-built for agentic AI and long-context workloads."
The design intent behind this server is clear: AI agent workloads differ from traditional enterprise applications — they need to handle long contexts (hundreds of thousands of tokens of conversation history), require frequent vector retrieval, and demand multi-model coordination (a single agent might call three models simultaneously). This means data movement between CPU and GPU is more intensive than in traditional inference, requiring higher memory bandwidth.
The "394" model number in the ProLiant family is a new sequence — the existing DL 360 (1U general-purpose), DL 380 (2U general-purpose), and DL 580 (4U multi-socket) don't include this model. HPE has opened a new product line dedicated to agent workloads.
Unpublished specifications: CPU model, GPU slot count, maximum memory, power consumption, liquid cooling support — none of these critical parameters were disclosed in the public coverage of Discover 2026. This is an information gap. In contrast, the Dell PowerEdge XE9680 (8 GPU slots) and Supermicro GPU SuperServer both published complete spec sheets at their respective launches.
Private Cloud AI: Multi-Node Inference at 256 GPUs
HPE's "Private Cloud AI" is not a single server but a pre-integrated AI platform. The most critical performance claims at Discover 2026:
- Training GPU requirements reduced to one-quarter of the previous-generation Blackwell platform
- Inference cost reduced to one-tenth per million tokens
- Supports 256 GPUs across multiple nodes for inference
- Unified API gateway: a single interface to access frontier models (GPT, Claude, Gemini) and open-source models (Llama, DeepSeek)
- Shared cache: reduces the cost of generating the first token
What does "training GPU needs reduced to one-quarter" mean? If a task previously required 1,024 GPUs, it might now only need 256. This 4× efficiency gain is not HPE magic — HPE doesn't make its own GPUs; it uses NVIDIA's chips. The generational efficiency leap is NVIDIA's engineering achievement (Blackwell to Rubin). What HPE does is system-level integration optimization: network topology that reduces waiting, storage latency that eases I/O bottlenecks, liquid cooling that improves stability. These are marginal improvements, not the source of the 4× gain.
NVIDIA AI Computing by HPE: Hyperscale Delivery
HPE doesn't make its own GPUs, but it can rack and deliver NVIDIA's latest GPU systems. The case study at Discover 2026: cloud service provider Vultr deployed GB300 NVL72 systems through the "NVIDIA AI Computing by HPE" product portfolio, integrating NVIDIA Spectrum-X Ethernet and HPE liquid cooling technology.
This case illustrates that HPE's role in large-scale AI cluster delivery is "systems integrator + infrastructure operations provider" — NVIDIA supplies the chips and networking; HPE supplies the servers, liquid cooling, operations software, and delivery capability.
This role overlaps with Dell and Supermicro. The difference is that HPE also brings GreenLake's consumption-based model and Juniper's networking capabilities — Dell doesn't have Juniper; Supermicro doesn't have Mist AI.
Gaps in the Compute Layer
| Gap | Impact |
|---|---|
| DL 394 Gen 12 full specs not published | Customers can't directly benchmark against Dell XE9680, Supermicro |
| Standard ProLiant Gen 12 full line | Discover only showcased the 394; Gen 12 updates for other models (360/380/580) were not mentioned |
| GPU dependency on NVIDIA | HPE has no proprietary AI accelerator chip; product pricing power and differentiation are constrained |
| AMD/Intel AI accelerator support | No mention in public coverage of support for AMD Instinct or Intel Gaudi |
The Storage Layer: Alletra MPX 10000
A New Storage Paradigm?
The Alletra MPX 10000 was already announced before Discover 2026 (China debut in May 2026), but at Discover it was repositioned as "the storage layer of the AI factory."
Core specifications:
- Fully disaggregated architecture: compute nodes (storage controllers) and data nodes (disk/SSD shelves) separated, independently scalable
- Native file + object unification: a single system simultaneously supports POSIX file access and S3 object access, no need for two storage pools
- Inline data intelligence: metadata (tags, classifications, entities) extracted in real time at data ingest, no additional indexing service required
- Native MCP protocol: AI agents can directly retrieve data from storage via MCP (Model Context Protocol)
- NVIDIA-Certified Storage: validated through the NVIDIA-Certified Storage program
- 100% data availability guarantee
HPE claims 7–12× faster "time to value" compared to DIY environments — the context for this metric is that traditional enterprise storage requires months of configuration and tuning before going into production; the Alletra MPX is ready out of the box.
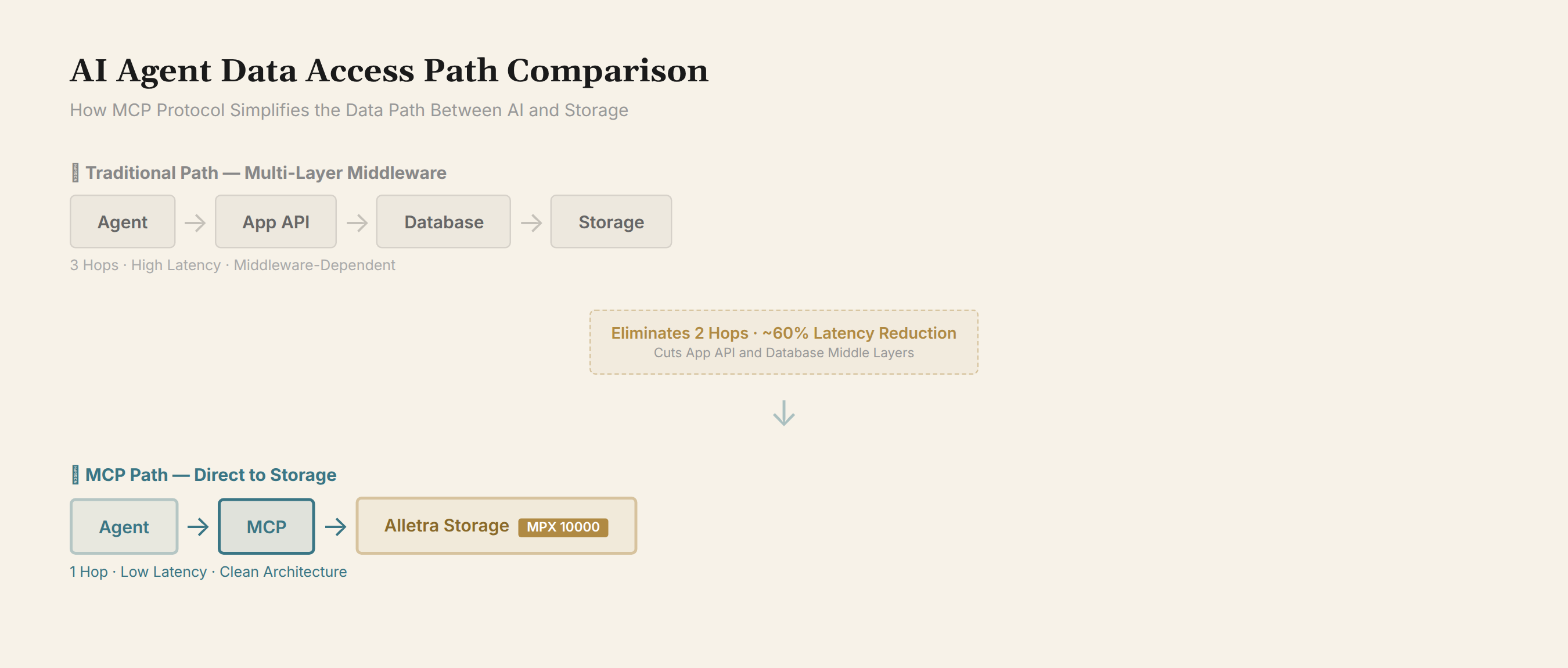
Why Native MCP Protocol Support Matters
MCP (Model Context Protocol) is an open protocol launched by Anthropic that enables AI applications to access external data sources in a standardized way. The Alletra MPX 10000 natively supports MCP at the storage layer, meaning AI agents don't need to go through an intermediate application layer to access data — they can retrieve directly from storage.
This is a significant architectural shift. The traditional data access path is: AI Agent → Application API → Database → Storage. With MCP, it becomes: AI Agent → MCP → Storage. One less middleware layer, lower latency, simpler architecture.
Gartner predicts that by 2029, the global storage capacity required for generative AI will exceed 2 exabytes. The Alletra MPX 10000 is HPE's opening hand for this market.
The Storage Competitive Landscape
| Vendor | Product | Characteristics |
|---|---|---|
| HPE | Alletra MPX 10000 | Fully disaggregated, MCP-native, NVIDIA-certified |
| Pure Storage | FlashBlade // EXA | AI-optimized, Evergreen consumption model |
| NetApp | ONTAP AI | AFF A800 + NVIDIA DGXFoundry |
| Dell | PowerScale | File storage + object storage |
| VAST Data | Universal Storage | All-flash, disaggregated architecture |
HPE's differentiator: native MCP support is unique. Other vendors' storage products currently require an application layer to interact with AI agents. But how long this advantage lasts depends on the adoption speed of the MCP protocol — if MCP becomes an industry standard, other storage vendors will quickly follow.
The Software Layer: From Hardware Manager to AI Factory "Operating System"
HPE's software took center stage at Discover 2026 and can be broken down into three layers:
Layer 1: Infrastructure Operations
| Platform | Origin | Function |
|---|---|---|
| GreenLake Intelligence | HPE in-house | AI-driven global operations (network + compute + storage + cloud) |
| Marvis AI | Juniper (Mist) | Natural language interactive network operations |
| Mist AI | Juniper | Wireless/wired network automation |
| Aruba Central | HPE | Campus network management |
| Apstra | Juniper | Data center network configuration automation |
These five platforms are being consolidated under a single GreenLake Intelligence interface. The ultimate goal of this consolidation: operations personnel face not five consoles, but one AI assistant (Marvis), able to ask in natural language, "Why is inference cluster latency 30% higher?" and have remediation auto-executed.
But the engineering difficulty of this integration is extreme. The five platforms come from three different acquisitions (Juniper, Mist, Aruba), with different technology stacks, different data models, and different APIs. What HPE has achieved so far is "unified console" (UI integration); the distance to "unified AI engine" (data-layer integration) is at least 2–3 years.
Layer 2: Hybrid Cloud Management
CloudOps is a newly launched unified hybrid operations layer at Discover 2026, bringing together virtualization, data protection, and cloud management. This directly targets the migration needs of VMware customers — Broadcom's post-acquisition price hikes on VMware have driven large numbers of enterprises to seek alternatives.
HPE CloudOps's selling point: a single platform that simultaneously manages private cloud (HPE GreenLake) and public cloud (AWS/Azure/GCP), plus virtualization management (replacing vCenter) and data protection (Zerto providing state rollback).
The Unleash AI program already covers 60+ validated partners, forming an ecosystem network.
Layer 3: Agent Governance
This layer was the most underappreciated at Discover 2026. HPE embedded a "governance agent layer" within Private Cloud AI:
- Zero-code agent registration: Agents built on any framework (LangChain, CrewAI, OpenAI Agents SDK, etc.) can be registered without code modifications
- Three-layer identity model: User identity → Agent identity → Organizational identity, with independent permissions at each layer
- NVIDIA Open Shell: Provides policy-isolated agent execution environments (sandboxes)
- NVIDIA NeMo Cloud: Provides governed agent workflow blueprints
- Zerto integration: Enables clean state rollback when an agent errs — essentially an "undo" button for agent operations
These three layers together form the embryo of an "agent infrastructure operating system."
The Core Challenge of the Software Layer
HPE's historical software capability is not strong. Autonomy ($11.1B acquisition → $8.8B write-down → spun off) is one of the largest software debacles in the industry. Micro Focus (enterprise software) was fully divested. Vertica was retained but marginalized.
The current software landscape is entirely concentrated in infrastructure operations — no applications, no AI frameworks, no large models. This positioning is more focused than Dell (trapped by VMware/Broadcom) and Cisco (bought Splunk for observability).
But "five platforms unified into one AI engine" is an engineering feat HPE has never pulled off. This requires not just technical capability but organizational alignment — Juniper engineers, Aruba engineers, and Mist engineers collaborating within a single codebase.

Cray/HPC: Technology Repurposing or Brand Disappearance?
Recalling the Cray Acquisition
In 2019, HPE acquired Cray for $1.3 billion. At the time, the industry interpreted this as a strategic move by HPE to compete head-to-head with Lenovo and Fujitsu in supercomputing. The core assets Cray brought:
- Cray EX supercomputer architecture: modular, liquid-cooled, high-density
- Slingshot interconnect: high-bandwidth, low-latency networking designed specifically for HPC workloads
- Cray Programming Environment: the development toolchain for supercomputing
- Customer relationships: U.S. Department of Energy (DOE), Oak Ridge (ORNL), Lawrence Livermore (LLNL), and others
Cray's Position at Discover 2026
The Cray brand still exists at Discover 2026 — hpe.com has a dedicated "HPE Cray Supercomputing" product line. But:
- No new supercomputing systems were announced. No new Exascale projects were declared.
- Cray technology is being folded into the AI factory architecture. Liquid cooling technology is used for GB300 NVL72 deployments; high-density cabinet design is used for the "Sovereign AI" tier.
- No dedicated Cray sessions. After being absorbed into the AI factory narrative, Cray had no standalone product roadmap presentation.
Slingshot vs. Juniper QFX: Two Networking Paths
HPE now has two data center networking technologies:
| Dimension | Juniper QFX | Cray Slingshot |
|---|---|---|
| Design Target | Enterprise AI, general-purpose data center | HPC, supercomputing |
| Protocol | Ethernet / RoCEv2 | Slingshot proprietary protocol + Ethernet-compatible |
| Typical Scenario | LLM training clusters | Scientific computing, climate simulation, molecular dynamics |
| Capacity | QFX5240: 102T | Slingshot 11: 13.6 Tbps/node |
| Customers | Enterprises, cloud service providers | National labs, universities |
HPE did not present a side-by-side roadmap comparison of these two networking technologies at Discover. This is an integration risk: the two product lines heavily overlap technically but target different customers. In the long run, HPE may need to make a choice — preserve Slingshot for HPC scenarios, or fold it into Juniper's Ethernet roadmap.
The HPC → AI Technology Repurposing
The specific paths by which Cray technology enters AI factory scenarios:
- Liquid cooling: Cray's direct liquid cooling (DLC) technology is used to cool high-power GPU systems like the GB300 NVL72
- High-density cabinets: Cray EX cabinet design expertise is applied to hardware design for the "Sovereign AI" deployment tier
- System-level integration: Cray's decades of experience building large-scale scientific computing systems directly applies to the system integration of 10,000-GPU AI clusters
This "technology repurposing" logic holds up — supercomputing and AI factories have substantial overlap at the infrastructure level (high power, high density, liquid cooling, large-scale interconnects). But traditional HPC customers may worry: if HPE is shifting Cray's attention toward enterprise AI, will investment in traditional research supercomputing be reduced?
Frontier (Oak Ridge National Laboratory, the world's first Exascale system) remains the flagship showcase of Cray's engineering legacy. But Discover 2026 did not announce a successor system to Frontier — this may simply be a matter of timing (Exascale system procurement cycles are 5–7 years), but silence itself is a signal.
The Energy Layer: The Engineering Challenge of Electricity → Tokens
Neri used a statistic in his keynote: the U.S. will face a 19-gigawatt power shortfall by 2028. Data centers are projected to account for nearly half of total U.S. electricity consumption by 2031.
HPE's moves in the energy direction operate on two levels:
Level 1: Liquid cooling technology. HPE has its own liquid cooling solutions (derived from Cray's DLC technology plus in-house rack-level liquid cooling), deployed directly in the Vultr + GB300 NVL72 case. Liquid cooling is not optional — a single GB300 NVL72 rack draws over 120 kilowatts; air cooling is theoretically incapable of supporting it.
Level 2: Energy planning partnerships. HPE is collaborating with Siemens Energy, using HPE's AI tools to accelerate power grid engineering design and project construction. This is not HPE doing power infrastructure itself — it's selling AI tools to power companies.
HPE's positioning in the energy direction is clear but not deep: it does liquid cooling hardware (it has products), does AI-assisted grid design (it has partnerships), but doesn't touch power generation or transmission (it's not a power company). Neri says "an AI factory is a device that converts electricity into tokens," but HPE is fundamentally only a supplier of the token-conversion machine, not a power supplier.
Six Gaps in the Equipment Layout
Looking at the AI factory's equipment landscape as a whole, six noteworthy gaps emerge:
1. DL 394 Gen 12 lacks specifications. A server positioned as "agent-dedicated" with no public GPU slot count, memory bandwidth, or power consumption — customers can't directly benchmark against the Dell XE9680 (8 GPUs) or Supermicro GPU SuperServer.
2. Standard server refresh gap. Discover 2026 only showcased one new model, the DL 394. Will the DL 360/380/580 in the ProLiant family receive Gen 12 updates? If only the 394 is new, then HPE's standard server product line is absent in this generation.
3. Zero new Cray supercomputing systems. No news of a next-generation Exascale system after Frontier. The supercomputing community's procurement cycle is 5–7 years, but if HPE doesn't announce a successor system in 2026, Lenovo and Atos will fill the gap.
4. Liquid cooling is not productized independently. HPE's liquid cooling technology appeared in the Vultr case study, but Discover 2026 did not launch a standalone liquid cooling product line or solution bundle. In contrast, CoolIT, Asperitas, and Boyd are all releasing new products.
5. AI Factory at Scale lacks standardized configurations. HPE repeatedly talks up the "AI factory" concept but provides no standardized configuration checklist comparable to NVIDIA's DGX SuperPOD — customers don't know exactly what equipment, how many racks, and what network topology an "AI factory" entails.
6. Complete GPU dependency on NVIDIA. HPE has no proprietary AI accelerator chip. Discover 2026 also had no mention of support for AMD Instinct MI400 or Intel Gaudi 3. This means HPE's AI factory has no differentiation from Dell or Supermicro at the GPU layer — everyone uses NVIDIA cards.
Conclusion: The Integration Experiment
HPE's AI factory is a "super integration experiment" — compute (ProLiant + Cray), networking (Juniper QFX + Aruba), storage (Alletra), software (GreenLake + Mist + CloudOps), all four layers with their own products, plus NVIDIA GPUs and partner ecosystems.
No company in history has successfully integrated a full infrastructure stack spanning this breadth. IBM tried, but sold off its x86 server business. Dell tried, but was trapped by VMware's equity structure. Cisco tried, but abandoned hyperscale compute for UCS.
Can HPE be the first? From the equipment landscape at Discover 2026, the direction is right: every layer has a credible product (DL 394, QFX5140, Alletra MPX, GreenLake Intelligence). But the number of gaps is also significant — spec transparency, the Cray roadmap, liquid cooling productization, GPU diversification. Each gap could become an angle of attack for competitors.
The 2027 revenue numbers will deliver the first report card.
Disclosure: This article is based on public coverage of HPE Discover 2026, drawing comprehensively on reports from Zhiding Technology, Tencent News, Qiehao, and other media outlets. Product specifications are based on official HPE releases. The Gartner forecast data for Alletra MPX 10000 comes from publicly available reports. This does not constitute investment advice.