When the Network Becomes the AI Control Plane: HPE's Networking Wager
At HPE Discover in June 2026, CEO Antonio Neri repeated one line three times:
"Every byte, every token, every decision traverses the network."
This is not a networking vendor's self-promotion — HPE just spent $14 billion acquiring Juniper Networks, and it needs to prove to the industry that the money was well spent.
Neri's judgment is more direct: "The network layer will be the next big opportunity." The reasoning: GPUs have dominated the compute conversation, but the network layer's pace of development has fallen far behind the growth in compute capability. In 10,000-GPU training clusters, 30–50% of the time is spent waiting for data, not computing.
HPE's response is a full refresh of its networking product line — from intra-rack to data center interconnect to edge inference — plus an AI engine that consolidates four operations platforms into one. This article dissects the technical details and competitive dynamics of this networking wager.
Neri's Latency Arithmetic
In his keynote, Neri used straightforward math to explain why networking matters:
"Multiplying a tiny network latency over weeks of training time across millions of GPUs can mean it takes 90 days instead of 30 to train a new model. This is the gap between chasing breakthroughs and creating them."
The implication: AI training is not about "running fast" — it's about "not being able to stop and wait." No matter how high the GPU FLOPS, if the data can't arrive, the compute units idle. The effective utilization rate (MFU) of a training cluster depends heavily on the network's congestion-free transmission rate — not on per-card peak compute.
This is why HPE is elevating networking to "control plane" status. In the AI factory narrative, compute is the production line; networking is the scheduling system — and the scheduling system's efficiency determines the production line's utilization.
The QFX Product Line: Six Tiers of Coverage
At Discover 2026, HPE showcased the full Juniper QFX data center switch product line:
| Model | Positioning | Capacity | Port Spec | Key Tech |
|---|---|---|---|---|
| QFX5220 | AI training clusters | Not disclosed | Large-scale fabric-oriented | High-density 400G/800G |
| QFX5140 | AI inference / edge | 16T | 24×400G QSFP112 + 8×800G OSFP800 + 2×SFP28 | RoCEv2, PFC, ECN, dynamic load balancing |
| QFX5130 | Distributed inference | Not disclosed | Inference deployment-oriented | Medium density |
| QFX5240/5250 | High-end core | 102T | Backbone / hyperscale | Top-tier switching capacity |
| QFX5100 | Entry-level | 100GbE | General-purpose data center | Mature product |
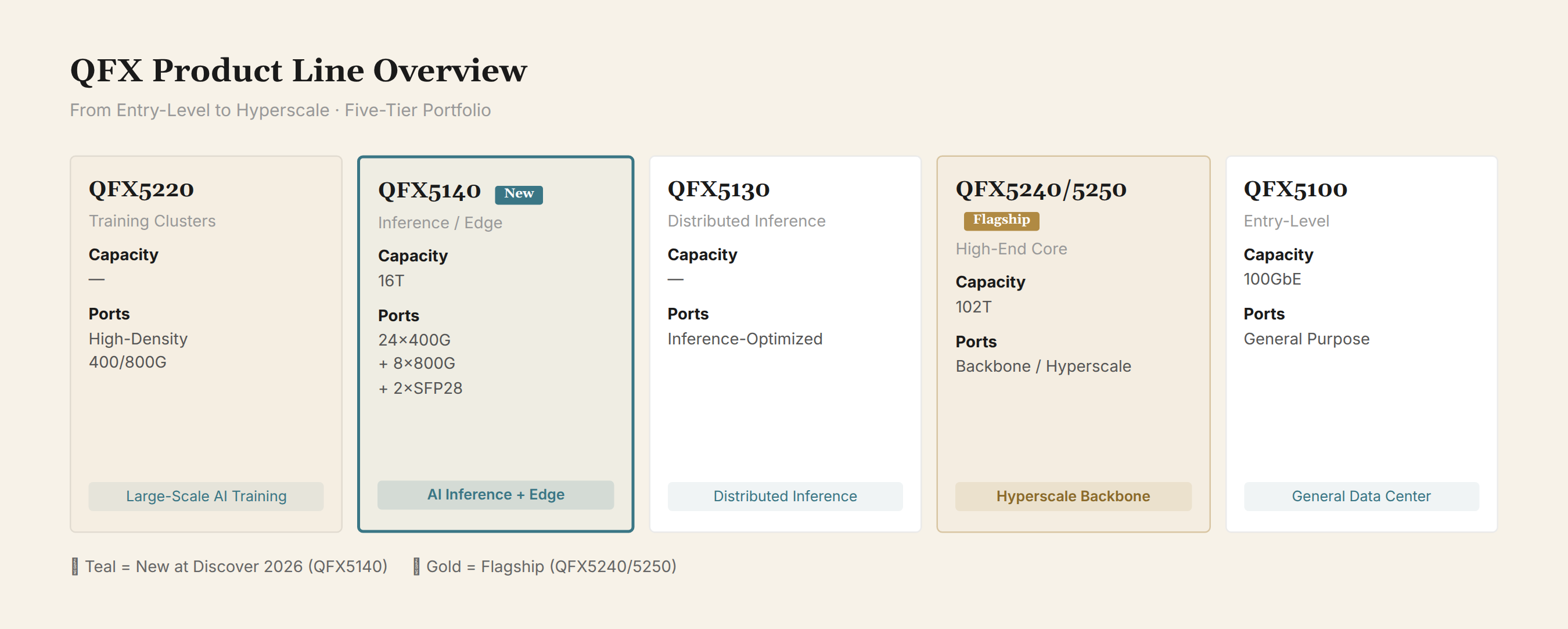
QFX5140: Filling the Mid-Range Gap
The QFX5140 is the most concrete new product announced at the conference. A 1RU fixed-configuration switch with 16T switching capacity.
Flexible port configuration: the 24 400G QSFP112 ports can be broken out into lower-speed ports, and the 8 800G OSFP800 ports are aimed at next-generation high-speed interconnects. It supports RoCEv2 (RDMA over Converged Ethernet), meaning data transfers between GPUs can bypass the operating system kernel and move directly from one GPU's VRAM to another — dramatically reducing latency.
HPE CTO Fidelma Russo highlighted three features directly tied to GPU communication efficiency:
- Priority Flow Control (PFC): High-priority traffic (e.g., GPU training data) won't be blocked by lower-priority flows
- Explicit Congestion Notification (ECN): The switch notifies senders to reduce rate before congestion occurs, avoiding packet loss and retransmission
- Dynamic Load Balancing: Unlike traditional ECMP that uses static hashing, this dynamically distributes traffic paths based on real-time link load — significantly reducing "tail latency" (the phenomenon where a few slow links drag down overall training performance)
The QFX5140 fills the biggest gap in the QFX lineup: the high-end QFX5240/5250 (102T) is too expensive for most AI inference scenarios, while the entry-level QFX5100 (100GbE) lacks sufficient bandwidth. The 16T QFX5140 sits right in the sweet spot for AI inference and edge AI workloads.
QFX5220: The Workhorse for Training Clusters
The QFX5220 is aimed at large-scale AI training clusters. HPE did not release detailed specifications at Discover, but based on its product positioning, it should be a streamlined version of the QFX5240 (102T) — sufficient for building the spine and leaf layers of thousand-GPU training clusters without needing the top-tier throughput of the 102T-class switch for hyperscale scenarios.
Training cluster networks have special requirements: AllReduce operations (gradient synchronization) between GPUs generate massive east-west traffic with high peak bandwidth, short duration, and high latency sensitivity. If the network can't handle it in time, GPUs sit idle — this is the source of what Neri calls "30–50% of the time spent waiting for data."
End-to-End Network Architecture: From Rack to Edge
QFX isn't everything. At Discover 2026, HPE presented a four-tier end-to-end AI network architecture:
| Tier | Equipment | Role |
|---|---|---|
| Intra-Rack | QFX5220/5140 | East-west interconnect between GPUs (training + inference) |
| Inter-Cluster | QFX5240/5250 | Horizontal scaling across multiple GPU clusters |
| Data Center Interconnect | PTX 12000 | High-speed cross-data center routing, supports 800G |
| Edge Inference | MX 301 | Based on Juniper's 6th-gen Trio chipset, extending network capability to the inference edge |
The PTX 12000 is a core router responsible for high-volume cross-data center interconnect — a typical scenario being a training cluster in data center A, storage in data center B, and inference services in data center C. The PTX 12000 handles high-speed forwarding in the middle.
The MX 301 is an edge router based on Juniper's self-developed 6th-generation Trio chipset. Its design goal is to push AI inference routing capability down to edge nodes — branch offices, factories, retail stores — enabling inference results to be quickly transmitted back to the core.
Together with the SRX 4700 quantum-safe firewall (1.44 Tbps throughput in a single rack unit, with encryption capabilities resistant to quantum computing attacks), HPE has built a complete networking product stack from GPU rack to enterprise edge.
SRX 4700: Getting Ahead of Quantum-Safe
The SRX 4700's appearance at Discover 2026 deserves a closer look. "Quantum-safe" sounds like a futuristic concept — quantum computers cannot yet crack RSA/ECC encryption. But HPE's logic is: attackers can "store now, decrypt later." For data requiring long-term confidentiality (healthcare, finance, defense), quantum-safe encryption needs to be deployed now.
The SRX 4700's 1.44 Tbps throughput means it can execute post-quantum cryptographic algorithms without becoming a network bottleneck — traditional firewalls suffer severe throughput degradation when running encryption algorithms.
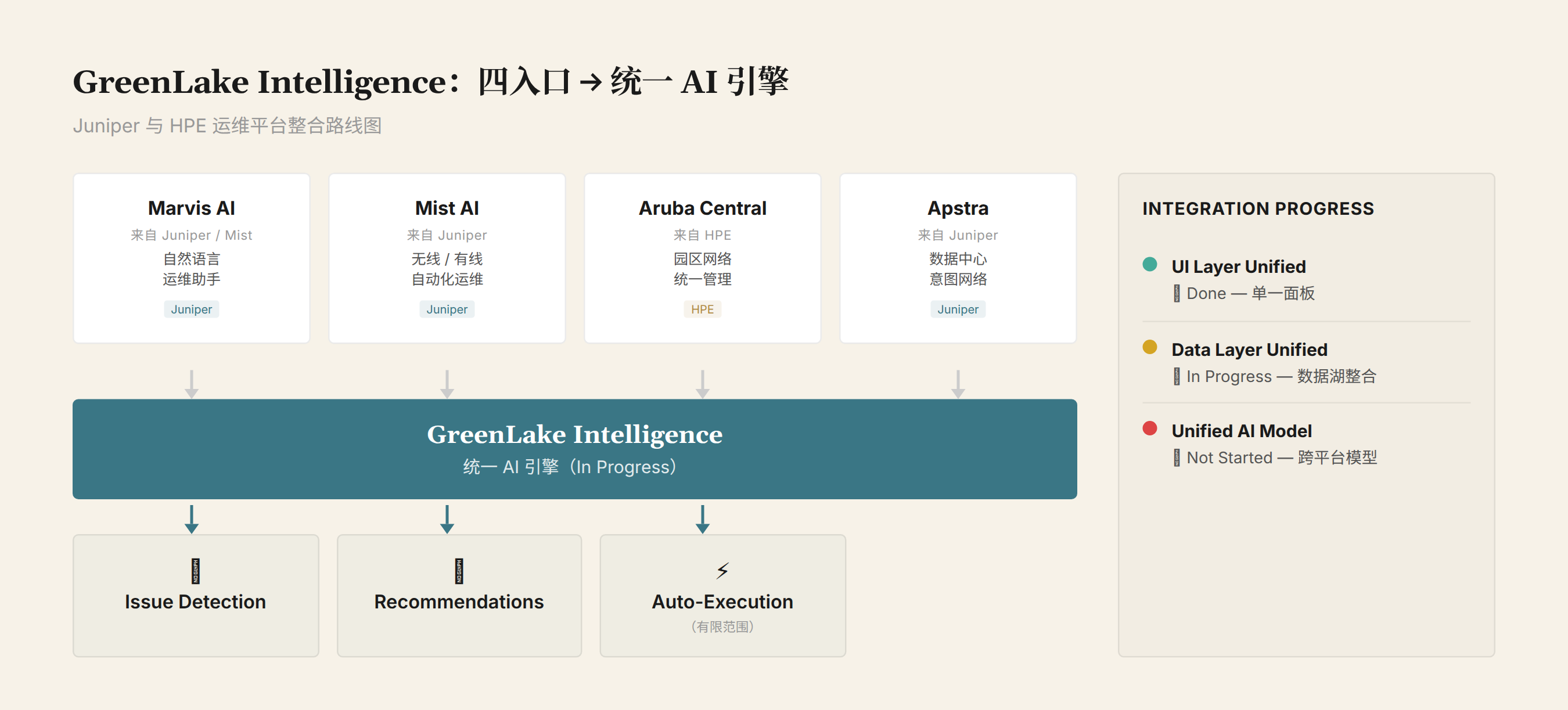
GreenLake Intelligence: Four Operations Entries Unified into One Engine
QFX and PTX are hardware. The story HPE really wants to tell is software: handing network operations over to AI.
Four Entry Points
HPE currently has four network operations platforms, originating from three different acquisitions:
| Platform | Origin | Positioning |
|---|---|---|
| Marvis AI | Juniper (Mist acquired 2019) | Virtual network assistant, natural language interaction |
| Mist AI | Juniper (acquired Mist Systems 2019) | AI-driven wireless/wired operations |
| Aruba Central | HPE (acquired Aruba 2015) | Campus network management |
| Apstra | Juniper (acquired Apstra 2021) | Data center network automation |
Each of the four platforms is mature and has its own customer base. But they come from three different companies (Juniper, Mist, Aruba), with different technology stacks, different data models, and different APIs.
GreenLake Intelligence's Unification Goal
What HPE wants to do: aggregate telemetry data from these four platforms into a single AI engine (GreenLake Intelligence), where the AI engine performs unified analysis, recommendations, and execution. The operations person faces not four consoles, but one AI assistant (Marvis).
The ideal scenario: an operator types into Marvis, "Why is inference cluster latency 30% higher?" Marvis automatically analyzes network topology, traffic patterns, device status, and application logs, pinpoints the issue (e.g., a specific leaf switch uplink is congested), provides remediation recommendations, and even auto-executes (adjusting traffic paths, increasing bandwidth reservations).
Where Are They Now?
From the public information at Discover 2026, HPE's current integration progress is:
Completed: Aruba CX switches onboarded to the Mist platform; Marvis Actions features introduced into Aruba Central. This is UI-level integration — one interface can display data from two platforms.
In Progress: Data-layer unification across the four platforms. Telemetry data format standardization, alert logic unification, cross-platform automation workflow execution.
Not Started: A truly unified AI engine — one model that understands data from all four platforms and makes decisions. This requires deep data-layer integration, with an engineering timeline of at least 2–3 years.
CTO Fidelma Russo said in her presentation that "GreenLake Intelligence embeds generative AI into infrastructure operations," but the demoed capabilities were primarily "issue identification + operational recommendations" — auto-execution cases were limited. This suggests the current phase is "AI-assisted" rather than "AI-autonomous."
Self-Driving Networks: HPE vs. Nile
HPE's "self-driving network" narrative competes directly with one company: Nile.
Nile is a company focused on enterprise-grade NaaS (Network as a Service). Its model is to build a fully automated network from scratch — hardware, software, and operations all bundled, with customers paying monthly and not worrying about any configuration.
Key differences between the two:
| Dimension | HPE | Nile |
|---|---|---|
| Starting point | Integrating across four existing platforms | Designed from scratch as a unified system |
| Hardware | QFX/Aruba full product line (mature) | Proprietary hardware (narrow product line) |
| AI Engine | GreenLake Intelligence (integrating) | Native AI engine (Day 1 design) |
| Customers | Existing HPE/Aruba/Juniper customers (massive installed base) | Mostly new customers (limited incremental base) |
| Consumption Model | GreenLake pay-per-use | NaaS subscription |
| Weakness | Engineering difficulty of integrating four platforms | Narrow product line; weak large-scale AI cluster capability |
Nile's advantage is "built from scratch" — no legacy baggage, better architectural consistency. HPE's advantage is "installed base + full product line" — a large number of enterprises already use Aruba and Juniper equipment, and GreenLake's consumption model is already mature.
Nile's weakness is scale: it can't do the networking for 10,000-GPU AI training clusters. That requires QFX5240-class 102T switches, which Nile doesn't have.
HPE's weakness is integration difficulty: four platforms aren't a single codebase, and achieving a truly unified AI engine requires massive engineering investment. Moreover, the Juniper and Aruba engineering teams were competitors before — organizational alignment is itself a challenge.
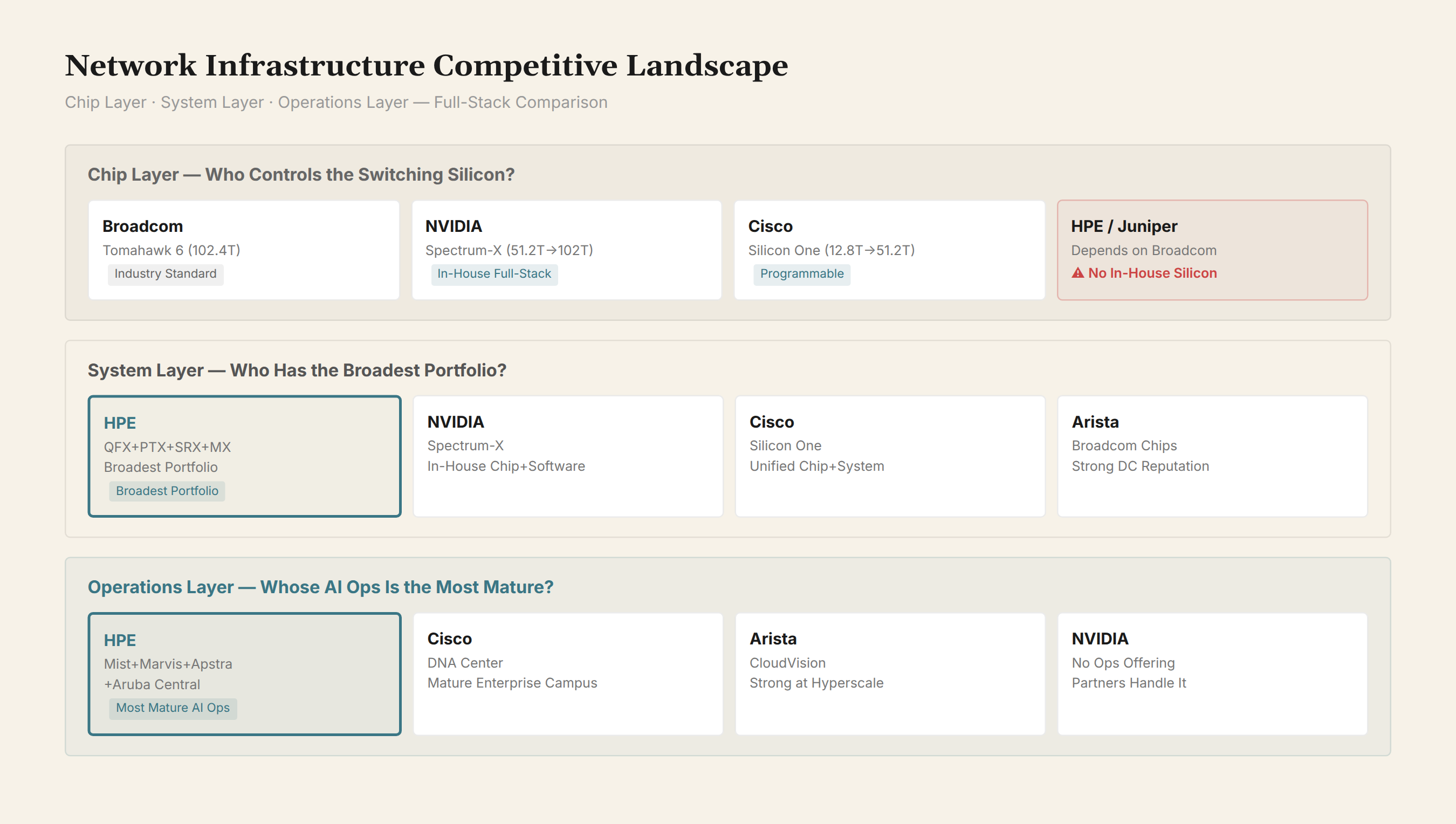
The Competitive Landscape: A Three-Layer Comparison
Data center networking currently has three technological paths:
Layer 1: Silicon — Who Can Make Switching ASICs
| Vendor | ASIC | Capacity | Characteristics |
|---|---|---|---|
| Broadcom | Tomahawk 6 | 102.4T | Industry standard, used by most switch vendors |
| NVIDIA | Spectrum-X | 51.2T → 102T | Proprietary ASIC + proprietary networking software stack |
| Cisco | Silicon One | 12.8T → 51.2T | Programmable data plane, unified routing + switching |
| Juniper (HPE) | Mix of proprietary and Broadcom-sourced | 16T (QFX5140) / 102T (QFX5240) | Depends on Broadcom ASICs, proprietary system software |
The key issue: HPE/Juniper does not make its own switching ASICs. The core switching ASICs in the QFX5140 and QFX5240 come from Broadcom. This means HPE has no differentiation at the silicon layer — any vendor using Broadcom ASICs (Arista, Dell, Extreme) can achieve similar port specifications.
NVIDIA's Spectrum-X follows a proprietary-ASIC + proprietary-networking-software-stack path — fully in-house from silicon to software, with optimization spanning from the die to the application. Cisco's Silicon One is similar. Both have silicon-layer control that HPE lacks.
HPE's differentiation lies at the system software layer: Juniper's Junos OS + Mist AI + Apstra's operations capabilities. But this is also catchable — Arista is advancing rapidly in AI operations as well.
Layer 2: Systems — Whose Networking Portfolio Is More Complete
| Dimension | HPE/Juniper | NVIDIA | Cisco | Arista |
|---|---|---|---|---|
| AI Training Switch | QFX5220/5240 | Spectrum-X SN5600 | Silicon One G200 | 7800R3 |
| AI Inference Switch | QFX5140/5130 | Spectrum-X SN5610 | Silicon One G100 | 7060X5 |
| Data Center Interconnect | PTX 12000 | N/A | ASR 9923 | 7280R3 |
| Edge Routing | MX 301 | N/A | Catalyst 8500 | N/A |
| Quantum-Safe Firewall | SRX 4700 | N/A | Secure Firewall 4250 | N/A |
| AI Operations | Mist + Marvis + Apstra + Aruba Central | N/A (delegates to partners) | DNA Center | CloudVision |
| Switching ASIC | Broadcom (sourced) | In-house | In-house | Broadcom (sourced) |
HPE has the broadest product coverage (training + inference + interconnect + edge + security + operations), but depends on Broadcom at the silicon layer. NVIDIA and Cisco have silicon sovereignty but narrower product lines. Arista, like HPE, depends on Broadcom and is also advancing its operations software.
Layer 3: Operations — Whose AI Engine Is Stronger
Mist AI (acquired by Juniper in 2019) is one of the most mature AI network operations engines in the industry today. Marvis's natural language interaction capability — operators can ask network questions in plain language — is more mature than most competitors'.
But Mist's strength lies in wireless and campus networking. AI operations for data center scenarios (large-scale RoCEv2 parameter tuning, GPU communication path optimization) are still in early stages. Apstra supplements some data center automation capability, but the deep integration of the two is not yet complete.
Cisco's DNA Center is mature in enterprise campus scenarios; its data center scenario relies on a tighter partnership with NVIDIA. Arista's CloudVision has an excellent reputation in large-scale data center operations — many hyperscale cloud providers use Arista + CloudVision.
Three Challenges
Challenge 1: No Differentiation at the Silicon Layer
HPE/Juniper doesn't make its own switching ASICs. The core switching ASICs in the QFX product line come from Broadcom. This means:
- The QFX5140's 16T/800G specs can be matched by Arista using the same Broadcom ASICs
- NVIDIA Spectrum-X's full-stack optimization from silicon to software is something HPE cannot match
- The ASIC iteration cadence is set by Broadcom, not by HPE
What HPE can do is build differentiation at the system software layer (Junos OS) and the operations layer (Mist/Apstra). But these two layers have lower barriers than the silicon layer — software can be replicated; silicon cannot.
Challenge 2: Four-Platform Integration Is Engineering Hell
Unifying Marvis, Mist, Aruba Central, and Apstra into a single GreenLake Intelligence AI engine — each platform has its own data format, API design, alerting logic, and automation workflow. Unifying the data layer is the bottleneck of the entire integration.
HPE has no historical track record of successfully integrating software platforms at this scale. Autonomy failed. The Juniper and Aruba engineering teams were previously competitors; collaborating in a single codebase requires organizational alignment — this is a management problem, not just a technical one.
Challenge 3: QFX5140 Delivery Cadence
The QFX5140 was announced at Discover 2026, but actual shipments may not begin until late 2026 or early 2027. During the same period, Broadcom Tomahawk 6 is already shipping in Cisco and Arista products. NVIDIA Spectrum-X's next generation is also on the way.
HPE's window is narrow — if the QFX5140 slips to mid-2027, customers may have already purchased competitors' 800G solutions.
Conclusion
HPE is elevating networking to "AI control plane" status — this directional judgment is correct. No matter how strong the GPU compute, if the network can't keep up, that compute is wasted. The effective utilization of a 10,000-GPU cluster depends on the network's congestion-free transmission rate, not per-card FLOPS.
But judging correctly and executing correctly are two different things.
HPE's networking product line (QFX + PTX + SRX + MX) has the broadest coverage in the industry. Its operations software (Mist + Marvis + Apstra + Aruba Central) is in the top tier of maturity. But two structural weaknesses cap its ceiling: silicon-layer dependency on Broadcom, and software integration still in progress.
Over the past five years, the power to define data center networking has been shifting toward NVIDIA (Spectrum-X) and Broadcom (the Tomahawk roadmap) — both of which have control at the silicon layer. HPE's role is more like a systems integrator: taking others' silicon, its own software, plus Juniper's operations capabilities, and packaging them into a complete solution.
This solution has a market — not every customer wants to assemble silicon + software + operations themselves. But an "integrator's" margins and strategic room will always be less than a "silicon definer's." HPE knows this. Neri said "the network layer will be the next big opportunity," but he also knows deep down: the biggest winner of that opportunity might not be HPE — it might be NVIDIA and Broadcom.
Disclosure: This article is based on public coverage of HPE Discover 2026, drawing comprehensively on reports from Zhiding Technology, Tencent News, Qiehao, and other media outlets. Product specifications are based on official HPE and Juniper releases. Competitive information is based on publicly available vendor materials. This does not constitute investment advice.