At HPE Discover in June 2026, the most underappreciated announcement wasn't the QFX switches.
CEO Antonio Neri said this in his keynote:
"Agents can now reason across data, applications, models, and workflows to help enterprises make decisions, automate processes, and increasingly act on behalf of users. IT departments will be responsible for managing thousands of agents that are part of the enterprise workforce."
The core judgment embedded in this statement: AI agents are no longer just "conversation tools" — they are becoming a new type of workload that, like web servers, databases, and microservices, requires infrastructure to run on.
HPE is the first traditional vendor to build a full infrastructure stack for agents. This article deconstructs its agent infrastructure blueprint and what this direction means.
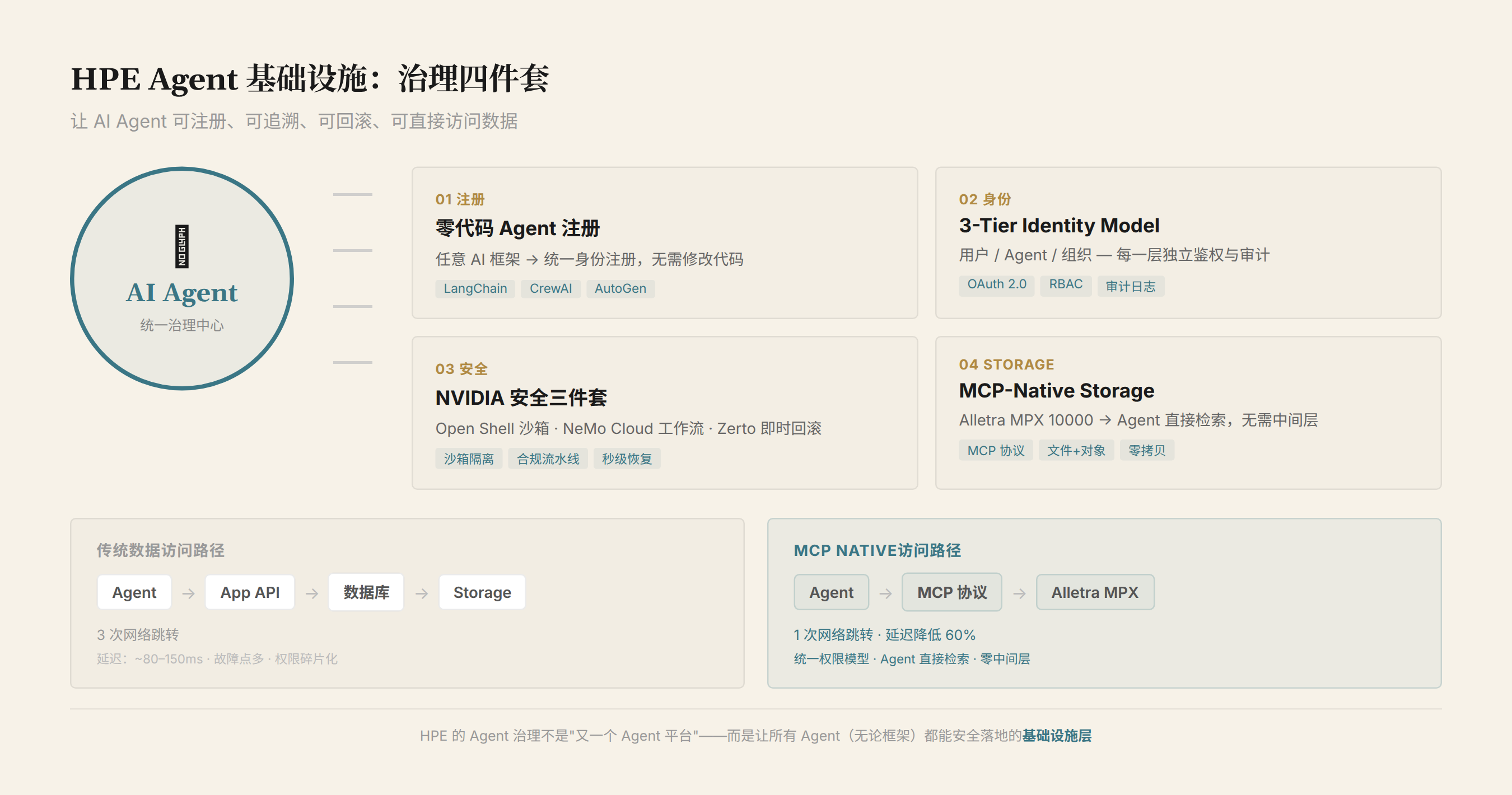
Agents: From Applications to Workloads
To understand what HPE is doing, we first need to see how the positioning of agents is shifting.
In 2024, an AI agent was an application-layer concept — a chatbot running in the cloud, calling a few APIs, answering questions. Its infrastructure requirements were similar to those of an ordinary web application: one server, one model API, one vector database.
In 2026, agents are becoming distributed systems. An agent inside an enterprise might simultaneously:
- Call multiple large models (GPT for reasoning, Claude for analysis, open-source models for embedding)
- Search across the enterprise's file storage, databases, and knowledge bases
- Communicate with other agents via the MCP protocol
- Execute real-world actions (send emails, modify databases, call APIs)
- Run across multiple servers or even multiple data centers
This level of complexity is no longer an "application" — it's a "workload." It demands: compute resources (long-context inference is memory-intensive), storage access (agents need to retrieve data), network communication (agents call each other), security isolation (one misbehaving agent must not bring down the entire system), and lifecycle management (agents must be registered, monitored, and rolled back).
Anthropic launched the MCP protocol, OpenAI released the Agents SDK, and Microsoft promoted the Copilot ecosystem — all defining the upper-layer architecture of agents. But who hosts these agents? Who manages their identities and permissions? Who rolls them back when they err?
This is the question HPE is trying to answer.
HPE's Agent Infrastructure: A Four-Piece Suite
Piece 1: Zero-Code Agent Registration
HPE added an agent registration capability to its Private Cloud AI platform. Enterprises can build agents on any framework (LangChain, CrewAI, OpenAI Agents SDK, Anthropic MCP, etc.) and register them without modifying any code.
During registration, agents automatically receive:
- API access credentials
- Identity verification keys
- Encrypted data channels
What this means: regardless of what framework an agent is built on, once it arrives on HPE's platform, it operates under a unified identity and permission model.
Piece 2: A Three-Layer Identity Model
HPE designed a three-layer identity architecture to manage agent permissions:
| Layer | Subject | What It Validates |
|---|---|---|
| Layer 1 | User | "Who you are" — verifies the person using the AI agent |
| Layer 2 | Agent | "What the agent can do" — controls the agent's behavioral permissions |
| Layer 3 | Organization | "What operations require human approval" — enforces mandatory human confirmation for sensitive actions |
The key design element: sensitive operations are not auto-executed by agents — they require human approval. For example, if an agent wants to modify a customer database, send an external email, or execute a transaction exceeding a certain threshold — these operations are intercepted and pushed to the appropriate person for approval.
This addresses a core enterprise concern: if an agent can autonomously execute actions, who is responsible when something goes wrong? The three-layer model separates "what the agent can do" from "what the agent is allowed to do," enabling enterprises to embrace automation while retaining control.
Piece 3: Three NVIDIA Integrations
HPE didn't build the agent runtime from scratch. Instead, it deeply integrated three NVIDIA technologies:
NVIDIA Open Shell — provides policy-isolated agent execution environments. Each agent (or group of agents) runs in its own sandbox, with resource isolation and permission isolation. If one agent errs or is compromised, it won't affect other agents or the underlying infrastructure. This is the agent-domain equivalent of containerization technology (Docker/Kubernetes).
NVIDIA NeMo Cloud — provides governed agent workflow blueprints. Enterprises can define standardized agent workflows in NeMo Cloud (e.g., a "customer complaint handling process") and then have multiple agents collaborate according to the blueprint. This addresses the standardization problem of inter-agent collaboration — not every enterprise needs to design its own agent orchestration logic.
Zerto integration — enables clean state rollback when an agent errs. Zerto is the disaster recovery company HPE acquired in 2022. Here, its capabilities are applied to agents: if an agent executes a series of operations and then errs, Zerto can roll the system state back to a clean pre-error state. It's essentially an "undo" button for agent operations.
These three integrations show that HPE is taking a "borrow the NVIDIA ecosystem" approach to agent infrastructure, rather than building everything in-house. The upside: a faster start — NVIDIA's technologies are mature. The risk: HPE has no ownership of the core agent runtime technologies — NVIDIA itself has DGX Cloud and full-stack AI solutions. The two companies are partners in agent infrastructure today, but competitors in the long run.
Piece 4: Alletra MPX 10000 + MCP
The Alletra MPX 10000 storage natively supports the MCP protocol. This means agents can retrieve data directly from the storage layer without going through an application layer.
Traditional path: Agent → Application API → Database → Storage MCP path: Agent → MCP → Storage
One fewer middleware layer. Lower latency. Simpler architecture. The efficiency with which agents access data directly determines their response speed — especially in long-context scenarios, where agents need to retrieve large volumes of background data frequently.
The Alletra MPX's "inline data intelligence" also plays a role here: metadata (tags, classifications, entities) is extracted in real time at data ingest. Agents can use these metadata directly for filtering during retrieval, without needing to build their own index.
This is one of the few areas of in-house differentiation HPE has in agent infrastructure — NVIDIA's technologies provide the runtime and governance, but the data access layer is HPE's own storage product.
ProLiant DL 394 Gen 12: A Server Purpose-Built for Agent Workloads
The DL 394 Gen 12 is the only entirely new compute product announced at Discover 2026. HPE positions it as "purpose-built for agentic AI and long-context workloads."
Why do agents need a dedicated server? Because agent workload characteristics differ from traditional inference:
- Long context: An agent may need to handle hundreds of thousands of tokens of conversation history, requiring far higher memory bandwidth than short-conversation inference
- Multi-model coordination: A single agent might call three models simultaneously (primary reasoning + tool calling + embedding), demanding higher GPU concurrency
- Frequent vector retrieval: Before every decision, an agent must search a knowledge base — it is sensitive to storage I/O latency
- Continuous operation: Agents run 24×7, unlike batch inference that can be queued
The "394" in DL 394 Gen 12 is a new sequence in the ProLiant family — the existing DL 360 (1U), DL 380 (2U), and DL 580 (4U) don't include this model. HPE has opened a new product line dedicated to agent workloads.
However, detailed specifications (GPU slots, memory, power consumption, liquid cooling support) were not publicly disclosed at Discover 2026. This is an information gap — customers can't directly benchmark against the Dell XE9680 or Supermicro GPU Server.
The Shadow AI Agent Crisis
Neri flagged a very real industry pain point in his keynote:
"Agents are rapidly proliferating across enterprises, often deployed by developers and small teams outside of formal IT governance."
This is "shadow AI agents" — the same logic as "shadow IT." A developer runs an agent on their own workstation, connected to the company's databases and email systems, without IT department approval, without security review, without permission controls. If the agent errs — say, sends incorrect pricing to all customers, or accidentally drops a database table — the IT department doesn't even know the agent exists.
HPE's solution: bring agents into the Private Cloud AI governance framework — registration, identity, permissions, auditing, rollback. Use a unified platform to govern all agents.
But there's a paradox here.
Shadow AI agents are "shadow" precisely because developers want to bypass IT approval. You have IT set up an agent governance platform and require all agents to register — will the developers who were already bypassing IT voluntarily come forward to register?
Historically, the solution to "shadow IT" wasn't "a better IT governance platform" — it was "making IT governance lightweight enough that developers don't perceive it as a burden." AWS won enterprise IT not because it built a better IT management platform, but because it let developers bypass IT and spin up servers directly with a credit card.
Can HPE's agent governance platform be lightweight and developer-friendly enough to earn voluntary adoption? This is a product design question, not just a technical capability question. From the public information at Discover 2026, HPE leans more toward "enterprise-grade governance" than "developer self-service" — consistent with its customer profile (large enterprise CIOs), but limiting the platform's spread within the developer community.

The Competitive Landscape for Agent Infrastructure
HPE is not the only company seeing this direction. Agent infrastructure is becoming a new battleground:
| Player | Positioning | Strengths | Weaknesses |
|---|---|---|---|
| HPE | Full-stack infrastructure (compute + network + storage + governance) | Full hardware stack, GreenLake consumption model, enterprise customers | No defining power in agent ecosystem, depends on NVIDIA |
| NVIDIA | Full-stack AI (GPU + networking + DGX Cloud + software) | Silicon design ownership, CUDA ecosystem, strongest technology | Not an enterprise IT supplier, competes with its own customers |
| Microsoft | Agent platform (Copilot + Azure + Fabric) | Enterprise customer relationships, Office ecosystem, Azure compute | Weak hardware, insufficient private deployment capability |
| OpenAI | Agent SDK + ChatGPT Enterprise | Largest model platform, Agents SDK first-mover advantage | No infrastructure, relies on Azure |
| Anthropic | MCP protocol definer + Claude | Defined the agent data access standard | Pure software company, no infrastructure |
| Cloud Providers | Managed agent services (AWS Bedrock Agents, Vertex AI Agent Builder) | Elastic compute, pay-per-use | Weak private deployment, large enterprise compliance concerns |
The key question: Who defines the architectural standards for agents?
At present, agent architectural standards are primarily being defined at the software layer:
- Anthropic's MCP protocol — how agents access external data
- OpenAI's Actions API — how agents execute operations
- LangChain/CrewAI — how agents orchestrate and collaborate
HPE doesn't have the lead on any of these standards. What it does is "the servers and networking for agents" — the hardware-layer and operations-layer hosting. This is the same role it played in the cloud computing era: it doesn't define the operating system; it sells the servers that run the operating system.
But the agent era has one variable that the cloud era didn't: the MCP protocol. Anthropic defined MCP, but HPE is the first vendor to natively support MCP at the hardware layer (storage). If MCP becomes an industry standard, HPE's "MCP-native storage" would be a first-mover advantage.
Conclusion: The Infrastructure Player's Opportunity and Ceiling
At Discover 2026, HPE did something interesting: it reframed AI agents from an "application-layer concept" to an "infrastructure workload." If this redefinition holds — if agents genuinely need dedicated servers, dedicated storage, dedicated networking, and dedicated governance — then HPE, as an infrastructure supplier, has a new market.
But the ceiling is also clear. The core agent technology stack (models, frameworks, protocols, orchestration) is not in HPE's hands. HPE does the hosting layer — running agent architectures defined by others on its own hardware. This is not fundamentally different from its role in the cloud computing era.
The one difference is MCP. If HPE can turn "MCP-native infrastructure" into a category — starting from storage and expanding to networking and compute — it could potentially build a technology moat of its own in the agent era.
Is this bet worth placing? The answer depends on how far the MCP protocol can go. If MCP becomes the global standard for AI agent data access (like HTTP for the Web), then HPE's first-mover advantage has long-term value. If MCP is replaced by another protocol, HPE's bet is a write-off.
Based on the information from Discover 2026, HPE has already put its chips on the table.
Disclosure: This article is based on public coverage of HPE Discover 2026, drawing comprehensively on reports from Zhiding Technology, Tencent News, and other media outlets. Product capability descriptions for NVIDIA Open Shell, NeMo Cloud, Zerto, and others are based on official HPE and NVIDIA releases. This does not constitute investment advice.