Compute Power Is Not Fighting Power: What the SpaceX Colossus Lease Tells Us About AI Infrastructure Reality
220,000 GPUs built and leased out within a year. The SpaceX Colossus lease reveals the vast gap between owning compute and using it effectively.
220,000 NVIDIA GPUs. 300 megawatts of power. Built inside a former appliance factory in Memphis, Tennessee. This is Colossus 1 — Elon Musk's AI supercomputer and one of the largest AI training clusters in the world. On June 12, 2026, SpaceX completed its IPO at a $2.1T valuation, the largest public offering in history. A core narrative underpinning that valuation: AI compute.
But the day before the IPO, Bloomberg revealed an awkward truth: SpaceX had decided to lease out the entirety of Colossus 1's compute capacity because xAI's own team had "encountered technical difficulties" using the cluster to train Grok models.
There is a wide gulf between owning compute and using it effectively — an entire chain of engineering capability, product capability, and commercial capability. The Colossus 1 lease laid bare every broken link in that chain.
I. The Event: A Supercomputer Changes Hands
The timeline is straightforward.
In mid-2025, xAI (by then merged into SpaceX) rapidly built Colossus 1 in Memphis. 220,000 GPUs spanning three architecture generations — H100, H200, and GB200 — delivering 300 megawatts of compute. The project reportedly went from groundbreaking to online in a matter of months. This was classic Musk: turbine generators burning natural gas to bypass federal environmental review, firing up over community protests.
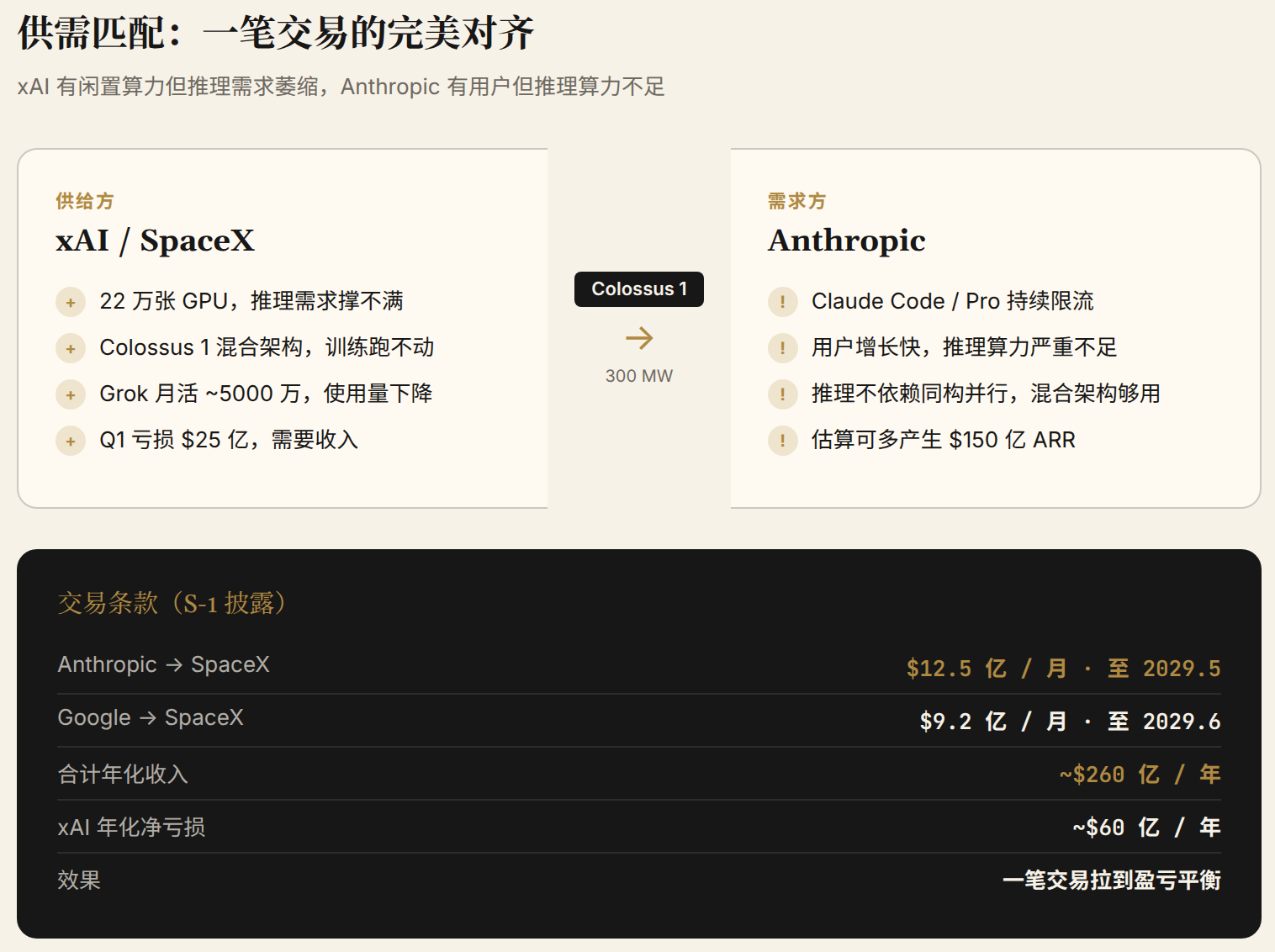
On May 6, 2026, Anthropic announced it was leasing the full capacity of Colossus 1. Two weeks later, SpaceX's S-1 filing disclosed the price: $12.5B per month, with the contract running through May 2029 and a total value potentially exceeding $400B. Shortly after, Google followed suit, leasing roughly 110,000 GPUs at $9.2B per month.
Musk himself posted on X that these were merely 180-day short-term leases and that the compute "might be reclaimed if capacity gets tight." But the S-1 contained no language suggesting short-term arrangements. The 90-day termination right was mutual, but neither Anthropic nor Google would trigger an exit clause right after moving in.
The key numbers: SpaceX's AI segment lost $2.5B in Q1 2026 on revenue of just $818M. Meanwhile, the Anthropic contract alone represents $15B in annualized revenue.
II. The Technical Cause: Built Too Fast to Run Cohesively
Colossus 1 was leased out not because SpaceX was feeling generous, but because xAI's own team couldn't make it work.
Bloomberg's reporting used two key phrases: latency issues and hardware variations. Tom's Hardware offered a more direct diagnosis: Colossus 1's mixed architecture (H100, H200, and GB200 — three different GPU generations housed in the same cluster) was the structural cause of training inefficiency.
Some background is in order. Large-scale AI training — particularly the pre-training phase for frontier models — demands extremely high cluster homogeneity. Different GPU generations differ in interconnect bandwidth, memory capacity, and compute precision. When you assemble 220,000 mixed-architecture GPUs into a single cluster for parallel training, the slowest node dictates overall throughput. H100s can't keep pace with GB200s, and the entire pipeline drags. This is not a software problem. It is architectural fragmentation at the physical level.
xAI had originally planned to integrate three Memphis-area data center campuses (Colossus 1 and adjacent facilities) into a unified training cluster. But hardware generational divergence made cross-campus integration unworkable. Ultimately, xAI chose to migrate frontier training to Colossus 2 — a new cluster built exclusively on Blackwell architecture — while Colossus 1 became "a first-generation asset in search of a better use case."
Tom's Hardware nailed it: Colossus 1 was downgraded from a training asset to an inference asset. Training requires massive homogeneous parallelism. Inference does not. Inference runs fine on single nodes or small-scale parallel setups. A mixed-architecture cluster that chokes on training can still serve inference workloads without issue.
Colossus 1 went from operational to proven-unsuitable-for-frontier-training in less than a year. A 220,000-GPU supercluster on a five-year depreciation schedule became a "second-hand inference farm" in year one. This is not Musk's personal failing — it is a structural dilemma facing the entire AI industry in the compute arms race: hardware iteration cycles (Hopper → Blackwell → Rubin) move far faster than data center construction timelines. The cluster you desperately build today is obsolete next year.

III. The Demand Side: Why Anthropic Needed It Desperately
Colossus 1 was compute that xAI couldn't use. For Anthropic, it was a lifeline.
Anthropic's problem is the exact inverse of xAI's: strong models, rapid user growth, but severely insufficient inference compute. Claude Code, Claude Pro, and Claude Max have been persistently rate-limited. Users queue for tokens. Product experience suffers. In the AI application layer, model availability matters just as much as model quality. Your model can be the best in the world — if users can't access it, it equals zero.
What do 220,000 GPUs mean for Anthropic? SemiAnalysis's assessment: this compute translates directly into rate-limit relief for Claude Code and Opus. More users can get on. More API requests can be processed. More subscription revenue comes in.
The brilliance of this deal lies in a perfect supply-demand match. xAI has compute but shrinking inference demand. Anthropic has users but not enough inference compute. Colossus 1's mixed architecture — a liability for frontier training (low parallel efficiency) — is irrelevant for inference (which doesn't depend on massive homogeneous parallelism). One party's waste is the other's treasure.
Analysts at Mirae Asset estimated that Colossus 1 could theoretically generate $5–6B in annual revenue, neatly covering xAI's roughly $6B annualized net loss. Meanwhile, Anthropic, armed with this compute, could generate an estimated additional $15B in annualized recurring revenue (ARR). One transaction, and both sides got exactly what they needed most.
IV. Grok's Real Position: Decent Model, Not Enough Users to Fill the Compute
On why xAI chose to lease its compute, two popular misconceptions need correcting.
Misconception one: "Grok is too bad, so they don't need compute."
Not quite. Grok 4.3 launched on April 30, 2026, supporting 1M token context and native video input. Grok 4 Fast supports 2M context at $0.20/1M input tokens — the cheapest long-context frontier model on the market. Grok Heavy ($300/month) uses a parallel agent mode to push SWE-bench from ~69% to ~72%. In May, Grok Build 0.1 launched — a model specifically optimized for coding scenarios.
This iteration pace is not slow. Model quality is competitive in the first tier, and pricing is more aggressive than OpenAI's.
Misconception two: "xAI gave up on model training."
Wrong. xAI's frontier training continues on Colossus 2. Colossus 2 uses a unified Blackwell architecture, purpose-built and designed for frontier training. Leasing Colossus 1 does not mean stopping training — it means repurposing an asset that wasn't suited for training.
The real picture is more nuanced: Grok's model iteration is keeping pace, but the user base isn't large enough to absorb the inference capacity of 220,000 GPUs. Third-party estimates put Grok's monthly active users at roughly 50 million. That's not small, but it's an order of magnitude below ChatGPT's 800M+ weekly actives. More critically, TechCrunch reported that Grok's usage has "declined significantly" in recent months.
Compute was built faster than user growth. The inference capacity of 220,000 GPUs exceeds Grok's current request volume. Rather than let GPUs idle and depreciate, xAI chose to lease them to whoever needed them most.
This points to a problem the industry has systematically underestimated: the value of AI compute is realized not in owning it, but in having enough users and products to consume it. A good model doesn't guarantee a large user base. A large user base doesn't guarantee inference revenue that covers compute depreciation. xAI is doing well at the model layer but still playing catch-up on productization and commercialization.
Grok also lacks enterprise compliance certifications — SOC 2, HIPAA — the basic prerequisites for regulated industries. xAI hasn't obtained them yet. This means high-value enterprise clients in finance, healthcare, and legal sectors are essentially walled off. GPT models on Azure and AWS come with full compliance backing. Grok doesn't. This is a structural bottleneck constraining its inference demand growth.
V. The Arithmetic: From Liability to Revenue Line
The numbers make it clearer.
xAI's financials (S-1 disclosure):
- Q1 2026 AI segment operating loss: ~$2.5B
- Q1 2026 AI segment revenue: $818M
- Annualized net loss: ~$6B
- Grok usage: declining
Colossus 1 lease revenue:
- Anthropic contract: $12.5B/month → $15B annualized
- Google contract: $9.2B/month → $110B annualized
- Combined annualized: ~$260B
A single leasing transaction pulled a segment losing $6B a year above the breakeven line. SpaceX's S-1 called this a "dual monetization strategy" — doing AI models (Grok) and AI infrastructure (leasing GPUs) simultaneously. But the subtext is clear: xAI overbuilt compute and needed a path to monetization before the IPO.
IPO valuation support:
- Market pricing: $2.1T
- Morningstar independent valuation: $780B
- Gap: ~63%
This $260B/year in lease revenue is a critical pillar propping up the $2.1T valuation. Strip out that revenue, and xAI's AI segment is a story of $6B annual losses, declining users, and decent-but-underutilized model competitiveness. Add that revenue, and it becomes an "AI infrastructure platform company" with $260B in annualized infrastructure revenue + space + satellite internet.
SpaceX is essentially doing GPU-style cloud reselling. Same logic as AWS selling EC2: you have surplus compute, you lease it out. The difference is that AWS sells general-purpose cloud, while SpaceX is leasing AI-specific GPU clusters — more vertical, more scarce, more expensive.
VI. Industry Signals: Capital Running Ahead of Engineering
The Colossus 1 lease is not an isolated event. Two other developments the same day point to the same conclusion.
Signal one: Meta begins limiting internal token usage. The Information reported that Meta instructed employees in an internal memo to reduce AI inference consumption, encouraging use of the internal MetaCode tool rather than external APIs. Meta's internal AI spending projections for 2026 reached the "billions" scale. Wired reported the same day that Meta's Applied AI team — formed in March — was riddled with internal complaints about trivial projects and "soul-crushing" work. The chip integration plan was also paused due to difficulties with Rivos integration.
Signal two: KPMG withdraws AI benefits report. Financial Times reported that KPMG retracted a report on the commercial value of AI after discovering that the adoption case studies in the report appeared to be fabricated by AI hallucinations. A top-tier global consulting firm used AI to write a report exaggerating AI's benefits, got caught, and retracted it. A perfect meta-irony: AI itself proved that AI adoption data is unreliable.
Three Signals, One Judgment
Put all three together:
- SpaceX has 220,000 GPUs but its own team can't run them. Owning compute ≠ Having engineering capability
- Meta has a multi-billion AI budget but low internal morale and cost overruns. Having budget ≠ Having execution efficiency
- KPMG had an AI report, but the content was AI-generated fiction. Having data ≠ Having real signal
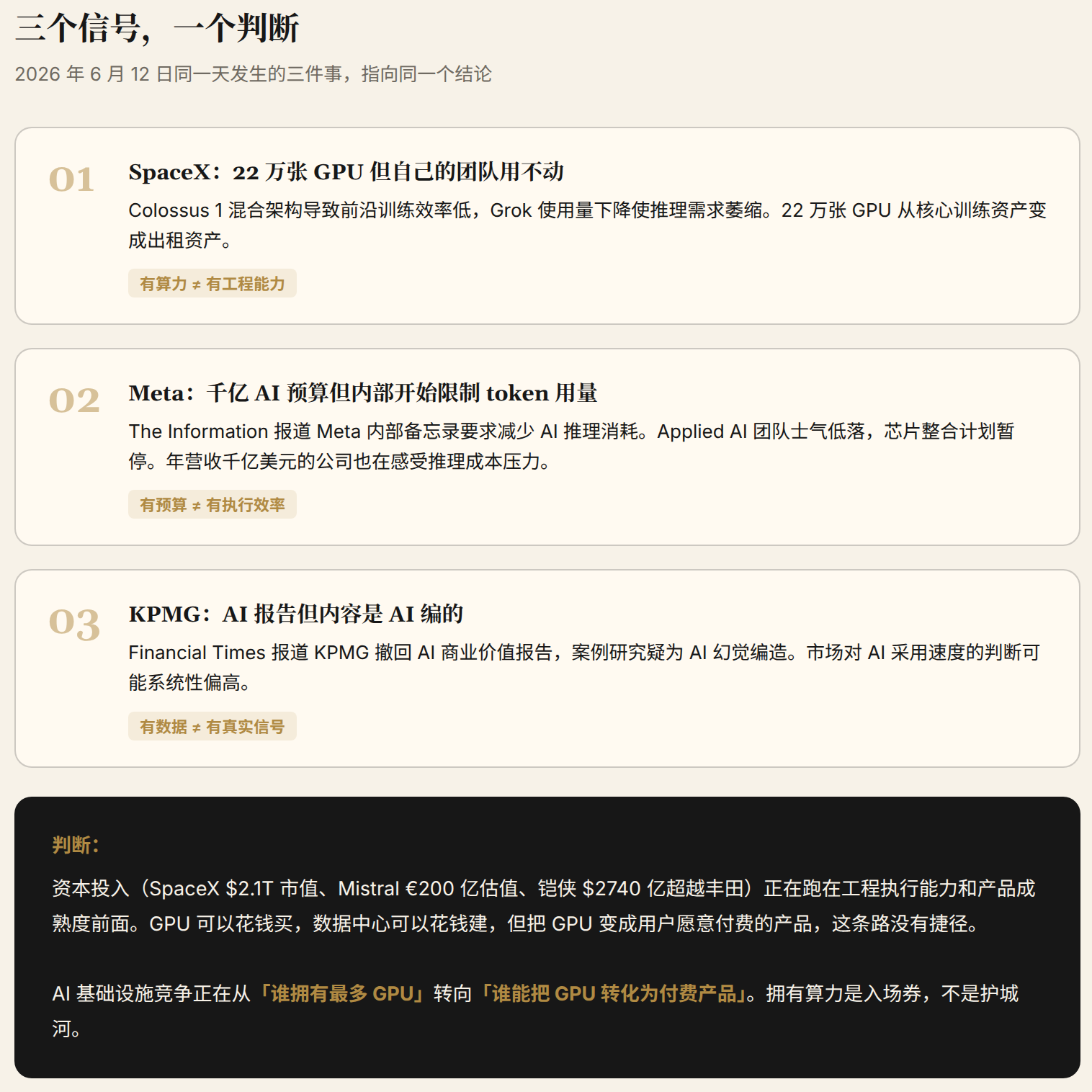
Dense capital deployment (SpaceX's $2.1T market cap, Mistral's €20B valuation, Kioxia's $274B market cap surpassing Toyota) is running ahead of engineering execution capability and product maturity. GPUs can be bought. Data centers can be built. But turning GPUs into products that users will pay for — that path has no shortcuts.
Conclusion: Compute Gets You In the Door — It's Not a Moat
The AI infrastructure competition is shifting from Phase One to Phase Two.
Phase One (2023–2025): Who has the most GPUs, the biggest clusters, the fastest build speed. Colossus 1 is the quintessential product of this era — fast, enormous, aggressive.
Phase Two (2026–): Who can convert compute into products that users will pay for. xAI has compute but a shrinking user base. Anthropic has users but not enough compute. The Colossus 1 lease is fundamentally a re-division of labor across the industry value chain: the infrastructure layer (SpaceX) selling compute to the application layer (Anthropic).
Musk leasing Colossus 1 before the IPO was a shrewd business move: converting idle assets into the biggest revenue growth line in the prospectus. But it also exposed a problem every AI compute player must face: hardware iteration outpaces data center construction cycles. Hopper → Blackwell → Rubin, each generation roughly two years. A hyperscale cluster takes a year from groundbreaking to going online — and in its first year of operation, a new GPU generation may already render it a "mixed-architecture inefficient asset."
Colossus 1 is not a failed experiment. It proved you can build a 220,000-GPU cluster in months — itself an engineering marvel. But it also proved: building fast doesn't mean building right, and owning compute doesn't mean creating value from it.
A lighthouse can be built at the edge of the land. But if no ships need its guidance, no matter how bright the light, it's only a cost.