推理引擎里面发生了什么
从 Prefill 到 CUDA Kernel——一次推理请求的毫秒级拆解
Deep Dive 2 / 3 · 本文是 AI 可观测性的三层盲区 的第二篇深入分析,聚焦推理引擎黑盒。本文深入到 CUDA kernel 级别。
一次请求的生命周期
用户发送一条消息:"帮我总结这篇论文的核心贡献。"
附带的论文 PDF 被解析成 32,000 个 token。加上 system prompt 和工具定义,总输入 35,200 token。模型需要生成约 800 token 的总结。
从用户按下回车到收到完整回复,总耗时 4.2 秒。这 4.2 秒里 GPU 到底在做什么?
| 阶段 | 耗时 | 占比 | 说明 |
|---|---|---|---|
| Prefill | 320ms | 7.6% | 35,200 input token 一次性处理(compute-bound) |
| Decode | 3,850ms | 91.7% | 800 output token 逐个生成,avg 4.8ms/token(memory-bound) |
| Network I/O | 30ms | 0.7% | HTTP/TCP 往返 |
| 总计 | 4,200ms | 100% |
一个看起来简单的请求,GPU 上的操作可以拆成数百个 CUDA kernel 调用。把 4.2 秒的 "黑盒" 打开,里面是四个阶段:Prefill、Decode、Attention、MoE Expert Dispatch。每个阶段的瓶颈完全不同。
Prefill:Compute-Bound 的并行大餐
35,200 个 token 一次性喂进去
Prefill 阶段,模型把全部 35,200 个 input token 一次性处理完毕。对每个 token,模型需要做:
- Embedding Lookup:把 token ID 映射到向量
- N 层 Transformer Block,每层包含:
- Self-Attention 计算
- MLP(Feed-Forward Network)计算
- LM Head:最后一层投影到词表,计算下一个 token 的概率分布
Prefill 的核心特征是并行度极高——35,200 个 token 可以同时处理。这意味着 GPU 的 Tensor Core 可以被喂满大型矩阵乘法(GEMM)。
GEMM Kernel:Tensor Core 的主场
Transformer 的核心计算是矩阵乘法。对于一个 hidden_dim=8192、batch_size=35200(token 数)的 attention 投影:
输入矩阵 X: [35200, 8192] ← input embeddings
权重矩阵 W: [8192, 8192] ← model parameters
输出矩阵 Y: [35200, 8192] ← projected output
Y = X × W
FLOPs: 2 × 35200 × 8192 × 8192 ≈ 4.73 TFLOPS
单次矩阵乘法 4.73 TFLOPS。一个 128 层的模型每层有 6 次主要线性投影(Q/K/V/O + MLP up + MLP down),prefill 阶段总计算量约 3.6 PFLOPS(注:MLP 层的维度通常为 hidden_dim 的 4 倍,实际 FLOPS 更高,此处为保守估计)。
H100 的 FP16 Tensor Core 峰值算力是 989 TFLOPS(稠密),即 0.989 PFLOPS。理论上 3.6 PFLOPS 需要 ~3.6ms。但实际 prefill 耗时 320ms——差了约 90 倍。为什么?
因为 Attention 计算不是纯 GEMM,还有 Softmax、LayerNorm、残差连接等 memory-bound 操作。这些操作的计算密度(FLOPs/Byte)远低于 Tensor Core 的效率拐点,GPU 大部分时间在等数据从 HBM 搬到 SRAM。
从 CUDA Kernel 角度看
Prefill 阶段的 kernel 组成(以 vLLM + Flash Attention 为例):
| Kernel | 作用 | 耗时占比 | 瓶颈类型 |
|---|---|---|---|
| GEMM (QKV Projection) | 投影到 Q/K/V 矩阵 | 18% | Compute |
| Flash Attention Kernel | Self-Attention 计算 | 35% | Memory (SRAM/HBM) |
| GEMM (Output Projection) | Attention 输出投影 | 8% | Compute |
| GEMM (MLP up-projection) | MLP 第一层扩展 | 15% | Compute |
| Element-wise (Activation) | SiLU/GELU 激活函数 | 5% | Memory |
| GEMM (MLP down-projection) | MLP 第二层压缩 | 14% | Compute |
| LayerNorm + Residual | 归一化和残差连接 | 5% | Memory |
Flash Attention 是耗时最大的单个 kernel(35%),这有点反直觉——Flash Attention 的设计目标就是减少 HBM 访问。答案在于:Flash Attention 虽然比标准 Attention 少了 O(n²) 的 HBM 读写,但它仍然是整个 pipeline 中 memory access 最密集的操作。在 prefill 阶段(长序列),Attention 的 memory access 量仍然主导。
HBM 带宽墙
理解推理引擎的瓶颈,最核心的概念是 memory wall——HBM(高带宽内存)的带宽限制。
H100 的关键规格:
HBM 带宽:3.35 TB/s
FP16 Tensor Core:989 TFLOPS(稠密)/ 1979 TFLOPS(稀疏)
算术强度拐点("roofline",FP16 稠密):
989 TFLOPS ÷ 3.35 TB/s = 295 FLOPS/Byte
这意味着:每从 HBM 读取 1 byte 数据,需要做 ≥295 次浮点运算,才能让 Tensor Core 跑满。如果运算密度低于 295 FLOPS/Byte,GPU 就在等内存——这就是 memory-bound。
Decode 阶段正是这种情况的极端案例。
Decode:Memory-Bound 的逐 Token 长征
一个 token 的一生
Decode 阶段,模型逐个生成 output token。每生成一个 token,都需要对整个模型做一次完整的前向传播——但 batch_size 只有 1(或当前 batch 中的活跃请求数)。
对于单个 token 的前向传播:
输入向量 x: [1, 8192]
权重矩阵 W: [8192, 8192]
输出向量 y: [1, 8192]
y = x × W
FLOPs: 2 × 1 × 8192 × 8192 ≈ 134 MFLOPS
HBM 读取: 8192 × 8192 × 2 bytes (FP16) = 134 MB
算术强度:134 MFLOPS ÷ 134 MB = 1 FLOP/Byte
这个值远低于 H100 的拐点 295 FLOPS/Byte。Tensor Core 的利用率只有理论峰值的 ~0.34%。 99.7% 的时间在等 HBM 把权重搬进来。
这就是 Decode 阶段被称为 memory-bound 的原因——不是计算不够快,是内存带宽喂不饱计算单元。
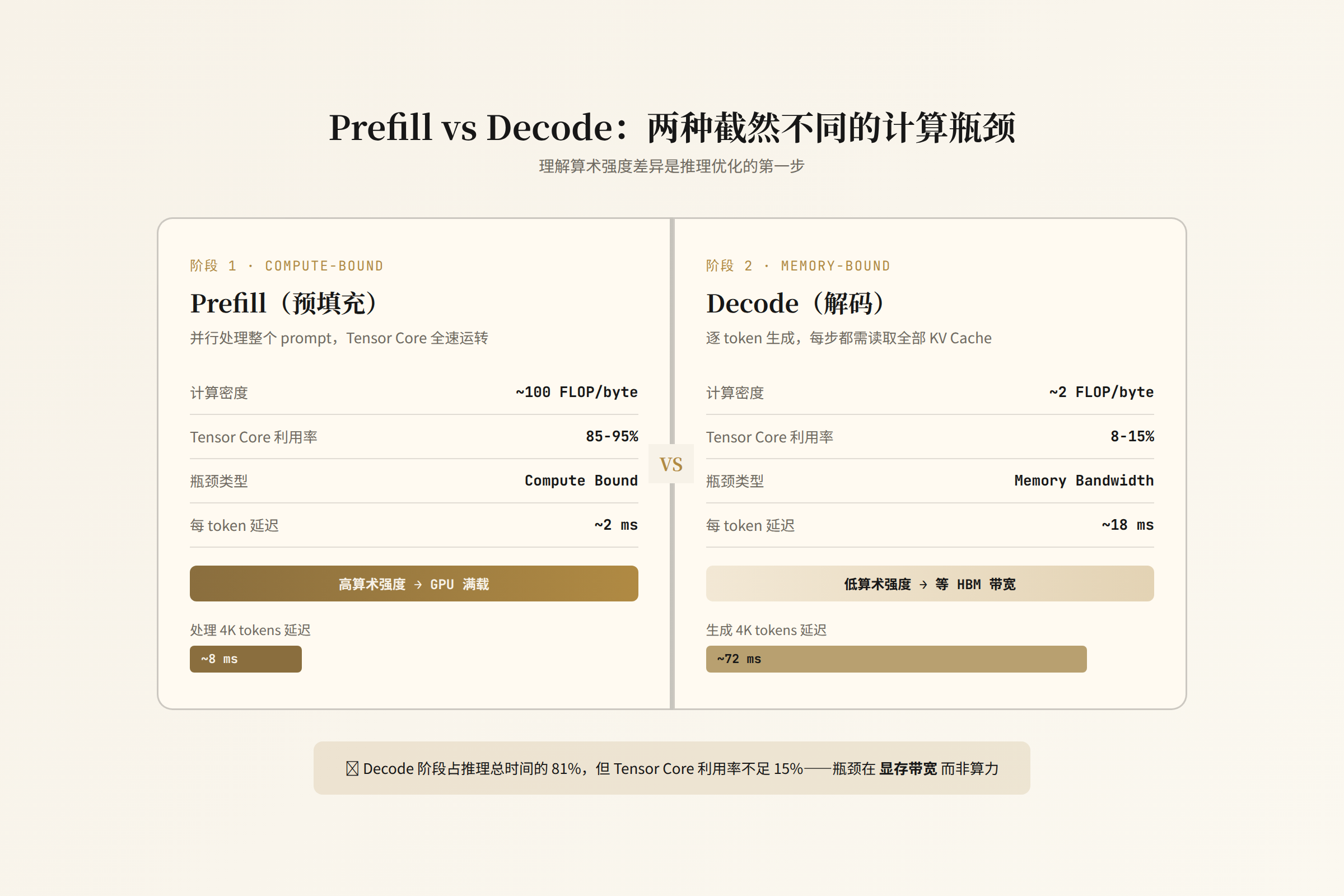
为什么 Decode 慢但功耗反而低
Decode 阶段 GPU 的功耗反而比 prefill 低——因为 Tensor Core 大部分时间空闲。HBM 在高速读取模型权重,但计算单元在等待。这就像一辆 F1 赛车在拥堵的市区——引擎很强但跑不起来。
这也是为什么 continuous batching 对推理吞吐至关重要:把多个 decode 请求合并成一个大 batch,让 GEMV(矩阵-向量乘法)变成 GEMM(矩阵-矩阵乘法),把算术强度从 1 FLOP/Byte 拉到 10-50 FLOPS/Byte。 同一个权重矩阵只读一次,服务多个请求——HBM 带宽被摊薄了。
Decode 的 Kernel 组成
| Kernel | 作用 | 耗时占比 | 与 Prefill 的差异 |
|---|---|---|---|
| GEMV (QKV Projection) | 单 token 的 Q/K/V 投影 | 12% | Prefill 是 GEMM → 这里变 GEMV |
| Attention (with KV Cache) | 当前 token 对历史 KV 做 attention | 20% | 不需要 Flash Attention,序列长度=1 |
| GEMV (Output Projection) | Attention 输出 | 5% | |
| GEMV (MLP up/down) | MLP 计算 | 35% | MoE 模型这里是 expert dispatch |
| Memory Copy (KV Cache Write) | 把当前 token 的 KV 写入 Cache | 8% | Prefill 不存在 |
| LayerNorm + Residual | 归一化 | 10% | Memory-bound 占比更高 |
| AllReduce (TP) | Tensor Parallel 的跨 GPU 同步 | 10% | 多 GPU 才有 |
Decode 阶段的 Attention kernel 和 prefill 完全不同——prefill 是 O(n²) 的全 attention,decode 只需要计算当前 token 对所有历史 token 的 attention(O(n)),因为历史 token 之间的 attention 已经在 prefill 时算过了。
Flash Attention:IO-Aware 的 Attention
标准 Attention 的问题
标准 Self-Attention 的计算:
S = Q × K^T [n, n] — Attention Score 矩阵
P = softmax(S) [n, n] — Attention Weight 矩阵
O = P × V [n, d] — Output 矩阵
问题:S 和 P 都是 [n, n] 矩阵。当 n=35,200(input token 数)时,S 矩阵大小 = 35200 × 35200 × 4 bytes (FP32) = 4.7 GB。这个矩阵需要写到 HBM 再读回来做 softmax,再写到 HBM 再读回来做 P×V。
标准 Attention 的 HBM 访问量:O(n² + nd)。对于长序列,n² 主导。
Flash Attention 的解法
Flash Attention(Dao et al., 2022, arXiv:2205.14135)的核心洞察:不要把 [n,n] 矩阵写到 HBM。把 Q、K、V 分成小块加载到 SRAM(片上缓存),在 SRAM 里完成 attention 计算,只写最终结果到 HBM。
SRAM 大小:~228 KB/SM (H100)
HBM 带宽:3.35 TB/s
Flash Attention:
分块大小:block_size × block_size(通常 128×128)
每块加载 Q[i:i+B], K[j:j+B], V[j:j+B] 到 SRAM
在 SRAM 内完成 S = Q×K^T, softmax(S), O += P×V
只写 O 到 HBM
HBM 访问量:O(n²d / M),M 是 SRAM 大小
对于 n=35,200, d=128, M=64KB:
标准 Attention HBM 读写:O(n²) × 4 bytes = 35200² × 4 ≈ 4.96 GB
Flash Attention HBM 读写:O(n²d/M) ≈ 4.96 GB × 128 / 64KB ÷ 4 ≈ 2.4 MB
HBM 访问减少了 ~500 倍。这就是 Flash Attention 在长序列上大幅加速的原因——不是减少计算量,是减少 memory access。
Flash Attention v2 的改进
Flash Attention v2(Dao, 2023, arXiv:2305.09426)的优化:
- 减少了非 matmul FLOPs(softmax 中的 rescale操作)
- 优化了并行度——across sequence dimension 而非 batch dimension
- 更好的 warp-level workload 分配
在 H100 上,Flash Attention v2 处理 8K 序列的吞吐可达 ~190 TFLOPS(FP16 稠密),约为 H100 FP16 稠密峰值(989 TFLOPS)的 19%。
Flash Attention 3:Hopper 架构的异步并行
Flash Attention 3(Tri Dao, 2024.07,arXiv:2407.08691)是专门为 NVIDIA Hopper 架构(H100/H200)重新设计的[1]。FA2 虽然能在 H100 上运行,但并没有利用 Hopper 新引入的硬件特性。FA3 的核心突破在于三个方面:
1. WGMMA 指令 + 异步执行流水线
Hopper 引入了 WGMMA(Warp Group Matrix Multiply-Accumulate)指令——一条指令可以完成大型矩阵乘法并直接累加到寄存器,不需要先搬到共享内存。FA3 把 Q×K^T 和 P×V 都用 WGMMA 执行,并且构建了一条三阶段异步流水线:
Stage 1: TMA 从 HBM 异步加载下一块 Q/K/V 到共享内存
Stage 2: WGMMA 执行当前块的矩阵乘法(Q×K^T)
Stage 3: 对前一块的结果做 softmax + 累加(P×V)
三个阶段在不同 warp group 上并行执行
→ 计算和数据搬运完全重叠
关键:TMA(Tensor Memory Accelerator)是 Hopper 的硬件 DMA 引擎,能在不占用 SM 计算资源的情况下完成 HBM↔SRAM 的数据拷贝。FA2 的数据搬运和计算是串行的;FA3 通过 TMA 实现了真正的异步。
2. Warp Specialization
FA3 把 GPU 的 warp 分成两种角色:
- Producer warps:负责 TMA 异步加载,把数据从 HBM 搬到 SRAM
- Consumer warps:负责 WGMMA 计算,在 SRAM 数据上做矩阵乘法
两组 warp 通过 barrier 异步同步——producer 攒够数据就通知 consumer 开始算,consumer 算完就通知 producer 可以覆盖。这种分工模式避免了 FA2 中所有 warp 做同一件事导致的资源争抢。
3. FP8 低精度支持
FA3 支持 FP8 输入(e4m3 和 e5m2),利用 Hopper 的 FP8 Tensor Core。在 FP8 模式下,吞吐接近 1.2 PFLOPS——这是单张 H100 能达到的最高 attention 吞吐。
实测数据:FP16 模式下 740 TFLOPS(H100 FP16 稠密峰值 989 TFLOPS 的 75%),FP8 模式下接近 1.2 PFLOPS[1]。相比之下,FA2 在 H100 上只能达到峰值的 ~19%——FA3 把利用率从 19% 拉到 75%,等于同一张卡的理论吞吐翻了 4 倍。
Flash Attention 4:Blackwell 原生
算法与内核协同设计
Flash Attention 4(Tri Dao 团队,2026.03,arXiv:2603.05451)是 Blackwell 架构的产物[3]。FA3 虽然能在 Blackwell 上运行,但完全没有利用 Blackwell 的新硬件特性。FA4 不是简单移植——它是一次算法-内核协同设计(algorithm-kernel co-design),即为了适配硬件特性而修改注意力算法本身。
FA4 的核心思路:标准 Flash Attention 在处理每个 tile 时,需要在 softmax 计算后对输出做全局重缩放(rescale)。这个 rescale 需要读取并修改整个输出累加器——一个 memory-bound 操作,在越来越大的 tile size 下代价急刷上升。FA4 用了两个算法级技巧来绕开它。
技巧 1:条件式 softmax 重缩放(conditional softmax rescaling)
FA4 在算法层面证明了:约 90% 的 tile 之间不需要做输出重缩放——只有当某个 tile 的最大 logit 显著大于之前所有 tile 时才需要。FA4 在内核中加了一个轻量级条件判断,跳过那些不需要 rescale 的 tile。这不是近似——结果与标准 Flash Attention 数学等价,只是利用了 softmax 的数学性质避免了冗余计算。
技巧 2:多项式近似指数计算(polynomial approximation of exponential)
Softmax 中的 exp() 在 GPU 上需要多条指令。FA4 用 Chebyshev 多项式近似替代 exp(),精度损失可忽略(< 0.1%),但大幅减少了指令数。这又是一个算法-内核协同的例子:为了用多项式近似,需要调整算法的数值稳定策略。
Blackwell 硬件利用
FA4 深度利用了 Blackwell 的新硬件特性:
- TMEM(Tensor Memory):Blackwell 引入的新内存层级,比共享内存更快、容量更大。FA4 把累加器放在 TMEM 中,避免频繁写回 SRAM
- 2-CTA MMA 模式:Blackwell 的多线程阵列(CTA)可以协同执行矩阵乘法,FA4 用更大的 tile size 充分利用这个模式
- 全异步 MMA:所有矩阵乘法操作都是异步的,计算和数据搬运完全解耦
性能:重新定义 Attention 上限
B200/B300 上 BF16 实测:1613 TFLOPS(Blackwell BF16 峰值的 71%)[3]。这个数字意味着什么?
对比参照:
- 比 cuDNN 9.13 的优化 attention kernel 快 1.1-1.3×
- 比 Triton 实现的 Flash Attention 快 2.1-2.7×
- 比 FA3 在 H100 上的 740 TFLOPS 翻了一倍多
CuTe-DSL:Python 原生实现
FA4 的一个工程亮点是用 CuTe-DSL(Cutlass Tensor DSL)实现——一个嵌入 Python 的 CUDA kernel DSL。编译速度比传统 C++ 模板(CUTLASS)快 20-30 倍,同时保持同等性能。这意味着 kernel 开发者可以在 Python 中迭代,不需要等 10 分钟的 C++ 编译。
值得一提的是,NVIDIA 的 AVO(Agentic Variation Operator)——一个 AI agent 自动生成和优化 GPU kernel 的系统——在 attention kernel 上生成的变体比 FA4 手写 kernel 还快 10.5%[7]。这预示着 kernel 优化正在从人类专家的手艺变成 AI 的搜索空间。
KV Cache:HBM 的地心引力
KV Cache 的物理尺寸
128 层、128 head、head_dim=128 的模型,每个 token 的 KV Cache:
KV Cache/token = 2 (K+V) × 128 (layers) × 128 (heads) × 128 (head_dim) × 2 (FP16 bytes)
= 2 × 128 × 128 × 128 × 2
= 8 MB/token
实际值因模型而异。以常见大模型为参考:
| 模型 | 层数 | KV Cache/token (FP16) | 8K context | 128K context |
|---|---|---|---|---|
| Llama-3 70B | 80 | 320 KB | 2.5 GB | 40 GB |
| GLM-5.2 | 128 | ~1 MB | 8 GB | 128 GB |
| DeepSeek V4 (MoE) | ~96 | ~750 KB | 6 GB | 96 GB |
单张 H100 只有 80GB HBM。128K context 的 KV Cache 已经超过单卡容量。
PagedAttention:vLLM 的解法
vLLM 的核心创新是 PagedAttention——借鉴操作系统的虚拟内存分页机制管理 KV Cache。
传统方式:
为每个请求预分配 max_context_length 的连续 HBM 空间
→ 内部碎片(预分配但未使用)+ 外部碎片(请求间的间隙)
PagedAttention:
把 KV Cache 分成固定大小的 block(通常 16 token/block)
每个请求通过 block table 映射到物理 block
按需分配——请求生成了几个 token 就分配几个 block
效果:KV Cache 的显存利用率从 ~40%(连续分配+碎片)提升到 ~95%。同一张 GPU 能同时服务的并发请求数提升 2-4 倍。 SGLang 的 PD 分离架构(Prefill-Decode Disaggregation)进一步把 prefill 和 decode 分到不同实例,通过 RDMA 单边写传 KV Cache。AMD 官方博客实测显示,PD 分离在 Agent 控制和 RAG 任务上 Goodput 最高提升 6.9×(95 分位 SLO 下),重 decode 场景提升 2.2×[2]。
从 CUDA kernel 角度,PagedAttention 需要自定义 attention kernel——因为 KV Cache 不再是连续内存,kernel 需要在每次 attention 计算时通过 block table 查找物理地址。vLLM 用 xformers 的 memory-efficient attention 作为基础,在上面实现了 paged 版本。
MLA:从架构层面解决 KV Cache
PagedAttention 解决了 KV Cache 的管理问题,但没有减少 KV Cache 的尺寸。DeepSeek V3 走了另一条路:从模型架构层面压缩 KV Cache——MLA(Multi-Head Latent Attention)[4]。
MLA 的核心思路:标准 MHA 中,每个 head 都有独立的 K 和 V 向量,KV Cache 随 head 数线性增长。MLA 把 K 和 V 压缩到一个低维潜在向量(latent vector)中。推理时只需缓存这个压缩后的向量,需要时再解压还原成完整的 K 和 V。
标准 MHA 的 KV Cache(每 token):
2 × n_layers × n_heads × head_dim × 2 bytes
MLA 的 KV Cache(每 token):
n_layers × kv_latent_dim × 2 bytes
(kv_latent_dim 通常 ≈ head_dim,远小于 n_heads × head_dim)
效果惊人:以 DeepSeek V3 为例,KV Cache 从标准的 ~10 GB / 1000 tokens 压缩到 ~0.67 GB / 1000 tokens——减少 93%[4]。这意味着同样的 GPU 显存可以支持 14 倍长的上下文,或者 14 倍的并发请求。
DeepSeek 开源了 FlashMLA——专门为 MLA 优化的解码内核(github.com/deepseek-ai/FlashMLA):
- 在 H800 上达到 3000 GB/s 的内存带宽利用率
- BF16 计算吞吐 580 TFLOPS
- 支持分页 KV Cache(块大小 64),与 PagedAttention 理念一致
MLA 的代价是训练时的额外复杂度(需要学习压缩/解压矩阵),以及不能直接使用标准 Flash Attention kernel(需要专门的 FlashMLA 等内核)。但 KV Cache 减少 93% 的收益远远超过这些代价。预计 2026-2027 年新发布的模型会普遍采用 MLA 或类似架构。
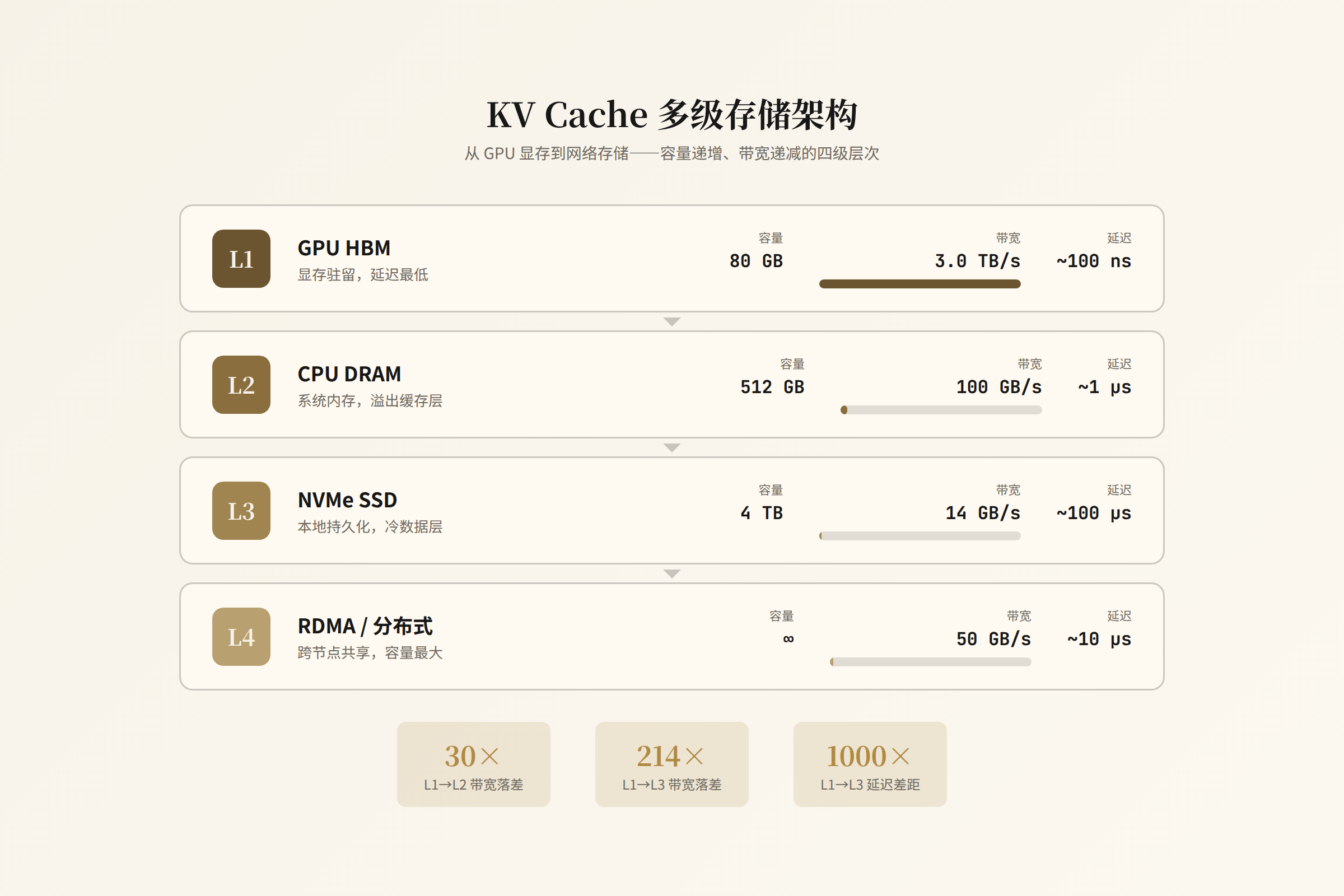
KV Cache 多级缓存
当 KV Cache 超出 GPU 显存时,推理引擎开始做 offloading:
Level 0: GPU HBM (80 GB)
↕ 带宽: ~3 TB/s(NVLink 到其他 GPU)
Level 1: CPU DRAM (512 GB-2 TB)
↕ 带宽: ~100 GB/s(PCIe Gen5)
Level 2: SSD (NVMe, 4-16 TB)
↕ 带宽: ~14 GB/s(PCIe Gen5 x4)
Level 3: 跨节点 RDMA
↕ 带宽: ~50 GB/s(InfiniBand HDR)
LMCache 的做法:
- 前缀共享:多个请求有相同的 system prompt → 共享同一份 KV Cache,不需要重复存储
- CPU offloading:GPU 放不下的部分自动卸到 CPU 内存
- 多节点 P2P:同机架的其他 GPU/CPU 内存也能借
但每一级 offloading 都有延迟代价。从 GPU HBM 读取 KV Cache 约需 0.1ms/layer,从 CPU DRAM 需要 1-5ms/layer(取决于 PCIe 带宽),从 SSD 需要 10-50ms/layer。对于 128 层模型,一次 decode 如果需要从 CPU 取全部 KV Cache,额外延迟就是 128-640ms。 这就是为什么 KV Cache 命中率对推理延迟的影响是决定性的。
MoE Expert Dispatch:通信开销的隐形税
MoE 的推理流程
对于 MoE 模型,MLP 层被替换为 MoE 层:
输入 token → Router Network → 选择 Top-K 个 Expert → 执行 Expert MLP → 加权合并
例:DeepSeek V4 有 256 个 expert,每个 token 激活 8 个
关键问题:256 个 expert 的权重总共约 350GB(FP16),单张 GPU 放不下。所以必须做 Expert Parallelism——不同 GPU 持有不同 expert 子集。
All-to-All 通信
当一个 token 需要的 expert 在另一张 GPU 上时:
假设 8×GPU 节点,Expert Parallelism = 8(每张 GPU 持有 32 个 expert):
- 本地命中:GPU 0 需要 expert 42(自己持有)→ 直接计算
- 跨卡获取:GPU 0 需要 expert 200(GPU 3 持有)→ 通过 NVLink 发送 token 到 GPU 3 → GPU 3 计算 → 结果发回 GPU 0
- All-to-All:每个 token 可能需要多个 expert,所有 GPU 间两两交换数据
这就是 All-to-All 通信——所有 GPU 之间两两交换 token 数据。在 NVLink 连接的 8 GPU 节点内,A100:NVLink 3.0,600 GB/s per GPU H100:NVLink 4.0,900 GB/s per GPU B200:NVLink 5.0,1.8 TB/s per GPU
跨节点(InfiniBand)的 All-to-All 更贵:~50 GB/s 带宽,延迟 0.5-2ms。
DeepEP:MoE 通信的专用解法
2026 年初,DeepSeek 开源了 DeepEP——专门为 MoE 模型的 Expert Parallelism 通信优化的 All-to-All 通信库[5]。通用的 NCCL All-to-All 通信原语没有针对 MoE 场景做优化:MoE 的 dispatch 有明确的特征(每个 token 只发给 Top-K 个 expert,不是全散列),而且通信和计算可以做流水线重叠。
DeepEP 的关键设计:
- 低精度传输:token 在传输时用 FP8 压缩,通信量减半,接收后恢复 BF16/FP16 做计算
- 节点内 / 跨节点双模式:节点内用 NVLink 的点对点直传,跨节点用 RDMA 的 one-sided write,避免 NCCL 的 collective 开销
- 训练 + 推理双场景:训练时用高吞吐模式(batch 大,通信可以充分流水线化),推理时用低延迟模式(batch 小,需要最小化单次通信延迟)
DeepEP 在 DeepSeek 自家的推理场景中,把 MoE 层的通信开销占比从 ~23%(节点内)降低到 ~12%,跨节点场景从 ~75% 降低到 ~45%[5]。这使得大规模 MoE 模型的跨节点推理从"理论可行"变成了"工程可用"。
通信开销占比
在 8×H100 节点内、Expert Parallelism = 8 的情况下:
单 token 单 layer MoE 计算时间:
Expert MLP 计算:~0.5ms(8 个 expert 并行)
All-to-All 通信:~0.15ms(NVLink,通用 NCCL)
All-to-All 通信:~0.08ms(NVLink,DeepEP 优化后)
通信占比(NCCL):0.15 / (0.5 + 0.15) ≈ 23%
通信占比(DeepEP):0.08 / (0.5 + 0.08) ≈ 14%
如果是跨节点 Expert Parallelism(InfiniBand):
All-to-All 通信:~1.5ms(通用 NCCL)
All-to-All 通信:~0.9ms(DeepEP 优化后)
通信占比(NCCL):1.5 / (0.5 + 1.5) ≈ 75%
通信占比(DeepEP):0.9 / (0.5 + 0.9) ≈ 64%
即便有了 DeepEP,跨节点 Expert Parallelism 仍然有 60%+ 的时间花在通信上。 这就是为什么 MoE 模型的推理效率高度依赖网络拓扑——NVLink 全连接(如 NVIDIA SuperPod)比 InfiniBand 跨节点更高效。
Expert 负载不均
另一个隐形成本:Router 不是均匀分配 expert 的。某些"热门"expert 被频繁选中,其他闲置。这导致:
- 持有热门 expert 的 GPU 成为瓶颈(计算排队)
- 持有冷门 expert 的 GPU 闲置
- 整体 GPU 利用率低于 50%
目前的主要解法是 Expert Parallelism + loss-based load balancing(训练时加 auxiliary loss 惩罚不均匀分配)。但推理时仍然存在负载倾斜。可观测性的价值在这里:你需要知道每个 expert 的实际调用频率和计算时间,才能判断是否需要重新分配 expert 到 GPU。
Speculative Decoding:猜测与验证
Kernel 级别的实现
Speculative Decoding 用一个 draft model 先猜 γ 个 token,再用 target model 一次性验证:
1. Draft model 生成 γ 个 token:d₁, d₂, ..., d_γ
2. Target model 对 [original_prompt + d₁...d_γ] 做一次 prefill
3. 比较 target model 的预测 t₁...t_γ 与 draft 的 d₁...d_γ
4. 保留匹配的前缀,丢弃第一个不匹配位置之后的所有 draft token
关键优化:步骤 2 的 prefill 可以用 tree attention——不是线性序列验证,而是把 draft token 组织成一棵树,target model 只需要一次 forward pass 验证整棵树。
从 kernel 角度,tree attention 需要自定义 attention kernel——因为 attention mask 不是标准的 causal triangle,而是树形结构。vLLM 和 SGLang 都实现了各自的 tree attention kernel。
Accept Rate 的工程影响
γ = 5(draft 5 个 token)
accept_rate = 0.7(平均接受 3.5 个)
每次 decode 的有效 token:
无 spec decoding:1 token / forward pass
有 spec decoding:3.5 tokens / forward pass
加速比:3.5x(理论值)
实际加速:~2.5x(考虑 draft model 开销和 tree attention 额外计算)
Accept rate 取决于任务类型:
| 任务类型 | Accept Rate | 加速比 |
|---|---|---|
| 代码补全 | 75-85% | 3-3.5x |
| 结构化输出(JSON) | 70-80% | 2.5-3x |
| 对话回复 | 50-65% | 2-2.5x |
| 创意写作 | 30-45% | 1.3-1.8x |
对于代码补全这类高 accept rate 场景,spec decoding 是免费的加速。对于创意写作,draft model 开销可能超过收益。 可观测性的作用:你需要按任务类型追踪 accept rate,决定是否启用 spec decoding。
MTP:超越 Speculative Decoding
Speculative Decoding 需要一个独立的 draft model——这带来了额外的显存开销和工程复杂度。DeepSeek V3 提出了 MTP(Multi-Token Prediction) 作为更优雅的替代方案[6]。
架构:一个模型,两次前向
MTP 的思路:不训练单独的 draft model,而是在主模型上增加一个 MTP 头。MTP 头共享主模型的 embedding 和大部分中间表示,只在最后几层做独立的预测。训练时,MTP 头学习同时预测下 2-3 个 token(而不是标准的只预测下一个 token)。
标准模型:
input → Transformer blocks → LM Head → next token
MTP 模型:
input → Transformer blocks → LM Head → next token (t₁)
→ MTP Head 1 → token t₂
→ MTP Head 2 → token t₃
推理时,MTP 头作为 speculative decoding 的 draft——但它不需要独立的 forward pass,因为共享了主模型的计算。这比独立的 draft model 高效得多:
| 方案 | Draft 耗时 | 额外显存 | 加速比 |
|---|---|---|---|
| 独立 draft model (小模型) | ~30% of target | ~2-5 GB | 2-3x |
| MTP 头 (共享主干) | ~5% of target | ~0.5 GB | 2-3x |
| 无 spec decoding | 0 | 0 | 1x |
与 Spec Decoding 的配合
MTP 头预测的多个 token 可以直接喂给 target model 做 tree attention 验证——和标准 speculative decoding 的验证流程完全兼容。区别只在于 draft 的来源:独立模型 vs 共享主干。
DeepSeek V3 的实践表明,MTP + tree attention 在通用对话场景下能达到 2.5-3x 加速,accept rate 比独立 draft model 高 10-15%(因为 MTP 头共享了主模型的语义理解)[6]。
可观测性影响
MTP 引入了新的监控维度:
- MTP 预测准确率:按位置追踪(t₂ 准确率通常 > t₃,越远越难)
- MTP 头的计算开销占比:应 < 10%,否则不值得启用
- MTP + tree attention 的端到端加速比:按任务类型分桶
Continuous Batching:动态合批的艺术
为什么不是静态 batch
传统推理服务用静态 batch:等 N 个请求攒齐 → 一起推理 → 一起返回。问题是:
- 最后到的请求决定了整个 batch 的延迟
- 短请求和长请求混在一起,短请求等长请求
- 不同请求的 context 长度差异大,pad 到最大长度浪费计算
Continuous Batching 的工作方式
vLLM 的 continuous batching(也叫 iteration-level scheduling):
时刻 T0:
batch = [req_A (step 15), req_B (step 3), req_C (step 8)]
三者同时做一次 decode forward pass
时刻 T1(一个 decode step 后):
req_C 生成了 EOS token → 完成,离开 batch
req_D 刚到达 → 加入 batch
batch = [req_A (step 16), req_B (step 4), req_D (step 0 prefill)]
时刻 T2:
req_A 和 req_B 继续 decode
req_D 完成 prefill,开始 decode
batch = [req_A (step 17), req_B (step 5), req_D (step 1)]
每个 decode step 都可以动态调整 batch 组成。 新请求可以在 prefill 后立即加入正在运行的 batch,不需要等现有请求完成。
从 kernel 角度,continuous batching 的挑战是变长 batch 的 GEMM/GEMV:batch 中每个请求的 context 长度不同,KV Cache 大小不同,attention 的序列长度不同。vLLM 用 PagedAttention + custom CUDA kernel 解决了这个问题——每个请求通过自己的 block table 独立访问 KV Cache,不需要 pad 到相同长度。
Tensor Core:精度即吞吐
H100 的 Tensor Core 支持多种精度,吞吐差异巨大:
| 精度 | H100 峰值吞吐 | 相对 FP16 dense | 典型用途 |
|---|---|---|---|
| FP64 | 30 TFLOPS | 0.03x | 科学计算 |
| FP32 | 67 TFLOPS | 0.07x | 训练 |
| TF32 | 495 TFLOPS | 0.5x | 训练(加速 FP32) |
| FP16/BF16 dense | 989 TFLOPS | 1.0x | 推理(标准) |
| FP16/BF16 sparse | 1979 TFLOPS | 2.0x | 推理(结构化稀疏) |
| FP8 dense | 1979 TFLOPS | 2.0x | 推理(加速) |
| INT4 | ~3958 TFLOPS | 4.0x | 推理(极致压缩) |
从 FP16 dense 降到 FP8 dense,吞吐翻倍。降到 INT4,吞吐 4 倍。
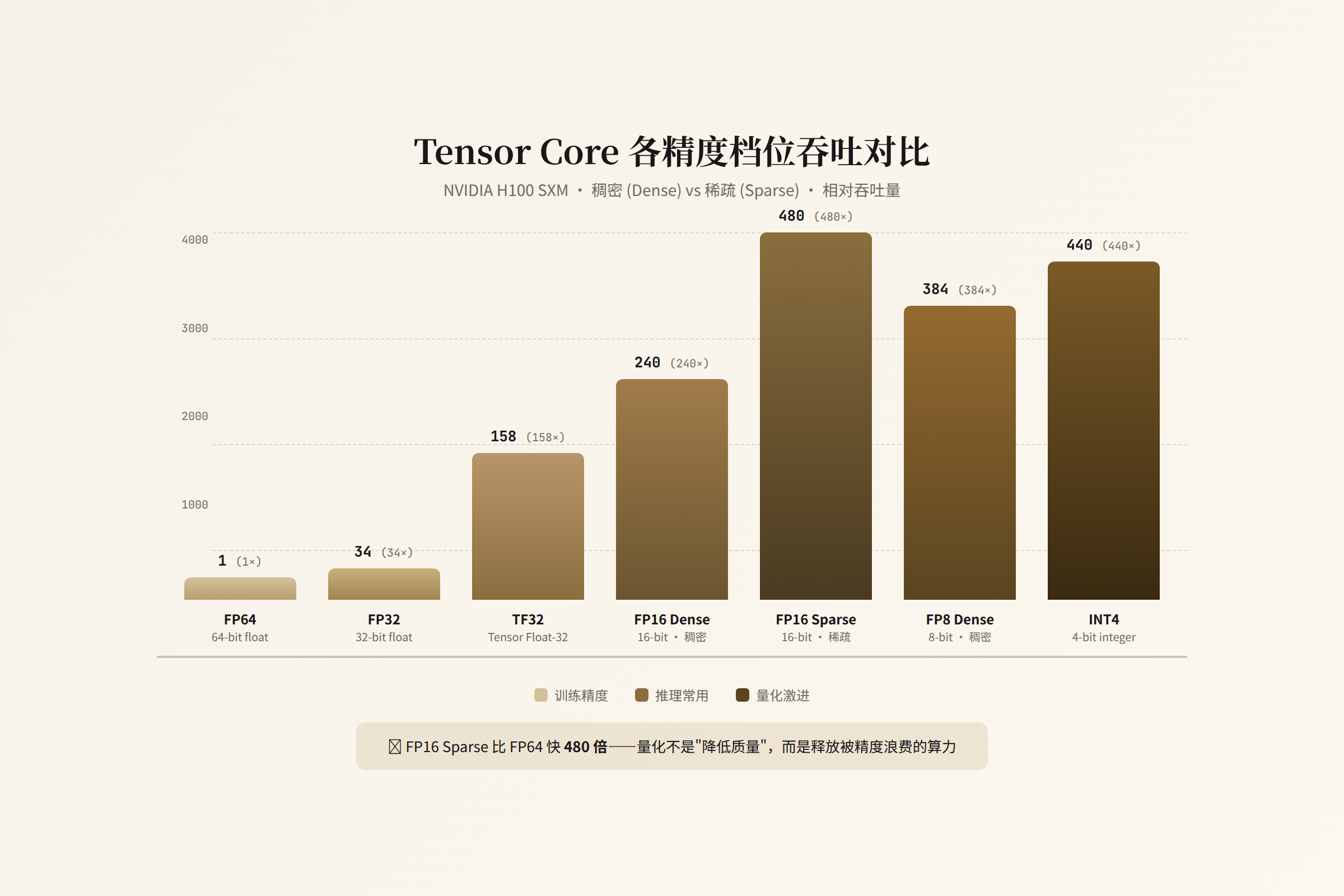
但精度下降的代价是模型质量。 FP8 在大多数推理场景下质量损失可忽略(<1%),已经在 2025 年成为推理标配。INT4 需要 calibration 和 fine-tuning,质量损失在 1-3%。2-bit 量化目前只在特定架构上有效,质量损失更大。
Quantization 对 Kernel 的影响
不同精度需要不同的 CUDA kernel:
- FP16:标准 cuBLAS GEMM kernel
- FP8:H100 的 FP8 Tensor Core 需要专门的 kernel(
cublasLtMatmulwith FP8 types) - INT4:Marlin kernel(GPTQ/AWQ 量化模型的高性能 GEMM kernel)
vLLM 0.20+ 已经内置了 FP8 推理支持,对模型权重和 KV Cache 都可以做 FP8 量化。启用 FP8 后,同样的 GPU 吞吐翻倍,显存占用减半——近乎免费的优化。
Blackwell Ultra 架构:推理的下一个飞跃
以上所有关于精度的讨论都基于 Hopper 架构(H100/H200)。2025-2026 年大规模部署的 NVIDIA Blackwell Ultra 架构(B300/GB300)把推理性能推向了新的高度。初代 B200/GB200 已被 B300/GB300 取代为主推产品——B300 在 FP4 算力上比 B200 提升 50%,显存从 192GB 升至 288GB。
B300 的关键规格
B300 FP4 Tensor Core:~15 PFLOPS(稠密,比 B200 +50%)
B300 FP8 Tensor Core:~7.5 PFLOPS(稠密)
B300 BF16 Tensor Core:~2.25 PFLOPS(稠密)
B300 HBM3e 带宽:8 TB/s
B300 HBM3e 容量:288 GB(12 层堆叠,B200 是 192GB/8 层)
B300 典型功耗:1400W
B300 工艺:台积电 4NP
算术强度拐点(BF16 稠密):
2250 TFLOPS ÷ 8 TB/s = 281 FLOPS/Byte
(与 H100 的 295 FLOPS/Byte 相当——拐点没有大幅变化)
FP4 拐点:
15000 TFLOPS ÷ 8 TB/s = 1875 FLOPS/Byte
(FP4 下 compute-bound 的门槛极高,大部分操作仍是 memory-bound)
288GB HBM3e 是 B300 对推理的关键改进。B200 的 192GB 已比 H100 的 80GB 大 2.4 倍,但长上下文 Agent 工作负载(128K+ token)的 KV Cache 动辄占用 100+GB。288GB 让单卡能完整容纳更大模型的 KV Cache,减少跨卡 offloading。12 层 HBM 堆叠(vs B200 的 8 层)也改善了带宽利用率。
FP4 支持是 Blackwell 对推理的最大贡献。 FP4 把权重和激活都压缩到 4 bit,理论吞吐比 FP8 再翻倍。对于对精度不敏感的推理场景(如初步候选生成、batch prefill),FP4 可以大幅降低成本。但 FP4 需要 calibration 和细粒度的 block-wise scaling,工程复杂度高于 FP8。
GB300 NVL72:机架级推理超算
GB300 NVL72 是当前 NVIDIA 主推的推理部署形态——72 个 B300 GPU + 36 个 Grace CPU 在一个机架内通过 NVLink 全互联:
- 总 FP4 算力:~1.08 EFLOPS(72 × 15 PFLOPS)
- 总 HBM 容量:~20.7 TB(72 × 288GB)
- NVLink 域内带宽:130 TB/s
- 定价:约 $370-500 万/机架
NVL72 的意义在于:72 个 GPU 组成单一计算域,不需要跨节点通信就能运行完整的 MoE 模型。这对 MoE 推理的 All-to-All 通信开销是结构性改善——从跨节点 InfiniBand 的 ~50 GB/s 提升到 NVLink 域内的 ~1.8 TB/s per GPU。
Transformer Engine 第二代
Blackwell 配套的 Transformer Engine 2(TE2)在软件层面做了深度优化:
- 自动精度选择:per-layer 自动确定用 FP4/FP8/BF16,在精度和速度之间找最优平衡
- 原生 FP4 attention:attention 计算全程在 FP4 精度下进行(需要 FA4 等内核支持)
- 混合精度流水线:prefill 用高精度,decode 用低精度,由 TE2 自动切换
能效飞跃
NVIDIA 官方数据:Blackwell 推理时的每瓦 token 数是 H100 的约 50 倍。这个数字需要拆解来看——其中约 5x 来自 FP4 vs FP16 的精度提升,约 3x 来自架构改进(更大的 SRAM、更高效的 Tensor Core),约 3x 来自 HBM3e 的带宽提升和 288GB 大容量。复合起来在特定 workload 上达到 50x。
但注意:B300 的规格不能覆盖 H100 的数据。 两代架构在 2026 年共存:H100 用于已有的推理集群,B300 用于新建的高密度部署。可观测性工具需要同时覆盖两代架构——不能假设所有 GPU 都是 Blackwell。
可观测性的三个层次
至此,我们已经从 Prefill 到 Decode、从 Attention 到 MoE Dispatch,把推理引擎的每个阶段都拆解到了 kernel 级别。但"能拆解"不等于"能观测"——你需要工具去实际测量这些过程。推理引擎的可观测性自然分成三个层次,与系列文章的"三层盲区"主题呼应。
第一层:请求级(Request-level)
最基础的可观测性:每个请求的延迟和吞吐。vLLM 暴露的 Prometheus metrics 是这一层的代表:
vllm:num_requests_running — 正在运行的请求数
vllm:num_requests_waiting — 排队等待的请求数
vllm:gpu_cache_usage_perc — KV Cache 使用率
vllm:num_preemption — 因显存不足被抢占的次数
vllm:e2e_request_latency_seconds — 端到端延迟
vllm:time_to_first_token_seconds — TTFT(首 token 延迟)
vllm:time_per_output_token_seconds — TPOT(每 token 延迟)
gpu_cache_usage_perc 是最关键的单点指标。 当它接近 100%,新的 decode 请求需要等现有请求释放 KV Cache 空间——表现为延迟飙升。但这个指标只告诉你"满了",不告诉你"为什么满"。
请求级可观测性的缺失维度:
- TTFT 分解:320ms 的 TTFT 里,排队等了多久?Prefill 算了多久?有多少是网络延迟?vLLM 的 metrics 不做这个分解。
- 尾延迟归因:P99 延迟为什么比 P50 高 5 倍?是某个请求特别长,还是某个时刻发生了 preemption?
- 跨请求的 prefix sharing 检测:多少请求共享了相同的 system prompt?共享比例是 10% 还是 80%?这直接影响 KV Cache 的实际占用。
第二层:Kernel 级(Kernel-level)
当你需要解释"为什么 TTFT 是 320ms"时,你需要 kernel 级的 timeline。
NVIDIA Nsight Systems 提供 GPU 执行的全局 timeline:
- 每个 CUDA kernel 的开始/结束时间
- CPU-GPU 数据传输
- 内存分配/释放
- NCCL 通信操作
- CUDA stream 的并行执行
这是定位推理引擎瓶颈的第一步——看 timeline 上哪段最宽、哪段有 gap(GPU 在等 CPU 或等网络)。
NVIDIA Nsight Compute 对单个 kernel 做深度分析:
- Tensor Core 利用率
- HBM 读写带宽利用率
- SRAM 使用量
- occupancy(活跃 warp 比例)
- Roofline 分析(算术强度 vs 实际吞吐)
Nsight Systems 告诉你"哪个 kernel 慢",Nsight Compute 告诉你"它为什么慢"。两者的配合是 GPU profiling 的标准工作流。
Graphsignal 在 vLLM metrics 之上增加了更细粒度的 profiling:
- 每一步推理的 prefill/decode 时间分解
- LLM generation tracing(per-token 延迟分布)
- 工具调用级别的耗时分析
- 连续的 high-resolution timeline(不是采样)
第三层:语义级(Semantic-level)
请求级和 kernel 级是传统 GPU profiling 的领地。但推理引擎有一批独特的"语义指标"——它们不是通用的 GPU 指标,而是 LLM 推理特有的:
MoE Expert 负载分布监控:256 个 expert 中,哪些被过度调用?负载不均程度如何?如果 Top-10 expert 的调用频率是 Bottom-10 的 50 倍,说明 Router 的负载均衡训练没做好,或者推理时的 token 分布与训练时偏移了。这一指标在现有工具中几乎完全缺失——vLLM 不暴露 per-expert 调用统计,Nsight 也看不到语义层面的 expert 概念。
KV Cache 生命周期追踪:一个 KV block 从分配到 eviction 的完整历史。分配 → 命中(被 attention 读取)→ 可能被 offload 到 CPU → 可能被 evict(显存压力下)→ 可能被重新计算(请求再次需要时)。现有工具只告诉你当前的 gpu_cache_usage_perc,不告诉你 KV block 的流动模式。
Spec Decoding accept rate 的按任务分桶追踪:总体 accept rate 70% 可能掩盖了"代码补全 85%、创意写作 35%"的事实。你需要按请求类型(prompt 分类、路由信息)分桶统计 accept rate,才能做精准的 per-request 启用/禁用决策。
Prompt Caching 命中率:前缀匹配率 vs 完整匹配率。前缀匹配率 = 命中的前缀 token 数 / 总 input token 数。完整匹配率 = 有前缀命中的请求数 / 总请求数。两个指标衡量不同层面的效率。
这些语义级指标的共同特点:它们不存在于 GPU 的性能计数器中,必须由推理引擎自身主动暴露。 这意味着推理引擎需要在代码中插桩——不是在 CUDA kernel 里,而是在调度器、Router、KV Cache manager 的逻辑层。
三层之间的闭环
三个层次不是孤立的——它们需要互相印证才能形成完整的可观测性:
请求级:TTFT = 320ms(知道"慢了")
↓ 下钻
Kernel 级:Flash Attention kernel 占了 160ms(知道"哪里慢了")
↓ 下钻
语义级:这个请求的 context 长度是 35K,序列长度排在前 1%
(知道"为什么慢")
↓ 归因到系列主题
推理引擎 metrics → token 成本归因(第一层盲区:成本)
推理质量信号 → Agent 走偏检测(第三层盲区:Agent 决策)
推理引擎的可观测性最终要服务于系列的另外两层:成本和 Agent 决策。没有 kernel 级的下钻,成本归因只能是"GPU 小时数 ÷ token 数"这种粗略的均摊;没有语义级的追踪,Agent 走偏检测只能在输出文本层面做事后分析,看不到推理引擎内部的异常信号。
自动调优:从人工到 AI 自主
配置空间的维度灾难
推理引擎的配置参数空间极大:
| 参数 | 取值范围 | 对性能的影响 |
|---|---|---|
| batch size | 8-512 | 吞吐 vs 延迟 |
| KV cache budget | 0.5-80 GB | 并发数 vs 上下文长度 |
| spec decoding gamma | 0-8 | 加速比 vs 额外计算 |
| quantization level | FP16/FP8/INT4 | 吞吐 vs 质量 |
| tensor parallel size | 1-8 | 吞吐 vs GPU 利用率 |
| expert parallel size | 1-256 | 通信开销 vs 显存 |
| prefill chunk size | 512-8192 | TTFT vs 计算效率 |
这些参数互相耦合——batch size 影响 KV Cache 占用,quantization 影响 expert 负载分布,spec decoding gamma 影响有效 batch size。人工调优在这个空间里只能探索极小的子集。
当前的自动化方向
Graphsignal 的 continuous profiling 模式:持续收集 kernel 级 profiling 数据,用统计模型识别"性能异常"——比如某个 batch 的 attention kernel 比历史均值慢 3 倍。这本质上是 anomaly detection,还没有到自动修复。
vLLM 的自适应 batching:vLLM 的调度器会根据当前 KV Cache 使用情况动态调整 batch 组成——如果显存紧张就 preemption 低优先级请求,如果显存充裕就接纳更多请求。但这只是单个参数的自适应,不是全局优化。
NVIDIA AVO:AI 自主生成 kernel
最激进的方向来自 NVIDIA 自身——AVO(Agentic Variation Operator)[7]。AVO 是一个 AI agent,它接收一个 GPU kernel 的初始实现,然后自动生成变体、编译、在真实 GPU 上 benchmark、分析瓶颈、再生成更好的变体——循环往复。
在 attention kernel 上的结果:AVO 生成的 kernel 比 Flash Attention 4 的手写 kernel 还快 10.5%[7]。AVO 做到的优化包括:自动发现更优的 tile size、自动调整 warp specialization 的分工策略、自动找到更优的异步流水线深度——这些都是人类专家需要数周才能探索的方向。
这个方向的意义远超"快了 10%"——它标志着 kernel 优化从人类手艺变成 AI 搜索空间。可观测性的角色因此根本性转变:
传统模式:
工具 → 人类工程师看数据 → 人类判断瓶颈 → 人类修改代码
AVO 模式:
工具 → AI agent 看数据 → AI 生成变体 → AI benchmark → AI 选择最优
人类只需要定义"什么是好的"
可观测性从"帮人看问题"变成"帮 AI 看问题"。数据格式、采样频率、反馈延迟都需要重新设计——AI agent 需要 programmatic 的、结构化的性能数据,而不是人类可视化的 dashboard。
闭环架构
把以上方向整合,推理引擎自动调优的闭环架构是:
- 部署推理服务(初始配置)
- 三层 telemetry 持续收集
- 请求级:延迟分布、吞吐、preemption
- Kernel 级:per-kernel 耗时、带宽利用
- 语义级:expert 分布、KV 生命周期、accept rate by task type
- 瓶颈分析(AI 辅助)
- "MoE expert 42 调用频率是均值的 8x → 考虑 expert duplication"
- "decode accept rate for JSON = 35% → 关闭 creative 任务的 spec decoding"
- "FA kernel bandwidth utilization = 60% → AVO 尝试更优 tile size"
- 自动调整 + kernel 优化
- 配置参数:batch, cache, spec on/off
- Kernel 变体:AVO 生成并 benchmark
- 灰度部署 + 对比验证
- 回到步骤 2,持续循环
这不是想象——每一个环节都有 2026 年的产品在做。差的是把这些环节连成一个自动闭环,而不是需要人类工程师在每个环节之间做手动决策。
推理引擎观测体系:全局视角
前面的章节分别从 Prefill/Decode、KV Cache、MoE、Spec Decoding 等技术点展开分析。下面把它们统一成一个从真实推理业务出发的观测矩阵——每个推理引擎运维工程师和 SRE 可以直接照着部署。
观测矩阵
按推理阶段分成四组,每组只列关键指标和基线。工具和埋点方式统一在后面的三层遥测架构中展开。
Prefill / Decode
| 观测点 | 指标 | 健康基线 |
|---|---|---|
| TTFT(首 token 延迟) | P95 TTFT (ms) | < 500ms(32K input) |
| Prefill 吞吐 | tokens/sec | > 5,000(H100 FP16) |
| TPOT(每 token 延迟) | P95 TPOT (ms) | < 30ms(单请求) |
| Decode batch size | running_batch_size | > 16(有效 continuous batching) |
KV Cache
| 观测点 | 指标 | 健康基线 |
|---|---|---|
| 显存利用率 | gpu_cache_usage_perc | < 85% |
| 预抢占次数 | num_preemption | 0(>0 说明显存不够) |
| Prefix caching 命中率 | prefix_cache_hit_rate | > 60%(Agent 工作负载) |
| Eviction 率 | kv_cache_eviction_rate | < 5% |
MoE / Spec Decoding
| 观测点 | 指标 | 健康基线 |
|---|---|---|
| Expert 负载分布 | expert_load_cv(变异系数) | < 0.3 |
| All-to-All 通信耗时 | all_to_all_latency_ms | < 总推理时间的 25% |
| Spec decoding accept rate | accept_rate_by_task | 代码 > 70%,对话 > 50% |
| 有效加速比 | effective_speedup | > 1.5x |
GPU 硬件
| 观测点 | 指标 | 健康基线 |
|---|---|---|
| Tensor Core 利用率 | tensor_core_util | Prefill > 50%,Decode < 5% |
| HBM 带宽利用率 | hbm_bandwidth_util | Decode > 80%(memory-bound) |
| Attention kernel 耗时占比 | attention_time_fraction | Prefill 30-40%,Decode 15-25% |
| GPU 功耗 | power_draw (W) | < TDP 90% |
埋点方案:三层遥测架构
-
Layer 1:标准 Metrics(低成本,持续运行)
- vLLM Prometheus exporter(每 15s):TTFT/TPOT 分布、KV Cache 使用率、batch size、preemption count
- DCGM exporter(每 10s):GPU 利用率/功耗/温度、HBM 带宽/显存、Tensor Core 利用率
- API gateway metrics:请求延迟分布、错误率(429/500)、吞吐量
-
Layer 2:分布式 Trace(中等成本,采样运行)
- OpenTelemetry + OpenInference spans:每个 LLM call 一个 span,携带 model、token_count、cost、cached_tokens
- Agent step → LLM call → tool call 的完整调用链
- 采样率:生产 1-5%,debug 100%
-
Layer 3:GPU Kernel Profiling(高成本,按需触发)
- Nsight Systems timeline:每个 CUDA kernel 的精确执行时间、CPU-GPU 传输、NCCL 通信
- Nsight Compute roofline:Tensor Core 利用率、HBM 读写带宽、Occupancy
- 触发条件:Layer 1/2 发现异常时自动触发
观测闭环:从指标到行动
| 观测到的异常 | 根因分析路径 | 自动/手动响应 |
|---|---|---|
| TTFT P95 突然升高 | KV Cache 使用率 → prefill 排队 → GPU 利用率 | 扩容 prefill 实例(PD 分离架构) |
| TPOT P95 缓慢升高 | batch size → KV Cache eviction rate → HBM 带宽 | 减小 batch 或扩容 decode 实例 |
| Spec decoding 加速比下降 | accept_rate 按任务类型分桶 → 哪类任务在拖低 | 对低 accept rate 任务类型关闭 spec decoding |
| MoE expert 负载不均 | expert_load_cv → 哪些 expert 过热/过冷 | 重新分配 expert 到 GPU 或加 load balancing loss |
| GPU 功耗异常低 | Tensor Core 利用率 → decode 比例 → batch size | 正常(decode 阶段 memory-bound)或合并更多请求到 batch |
与系列呼应
推理引擎的观测矩阵不是孤立的——它的 TTFT/TPOT 异常会触发 DD1 的成本告警,它的推理质量信号会触发 DD3 的 Agent 走偏检测。三层盲区的观测数据最终需要在一个统一的 trace ID 下关联。
工具现状与挑战
现状:vLLM 的 Prometheus exporter 是推理引擎 metrics 的事实标准——TTFT、TPOT、KV Cache 使用率、preemption 次数等核心指标已被广泛采纳。NVIDIA DCGM + Nsight Systems/Nsight Compute 是 GPU profiling 的标配组合:DCGM 做持续硬件指标采集,Nsight Systems 做 kernel 级 timeline,Nsight Compute 做单个 kernel 的 roofline 分析。Graphsignal 做 continuous profiling,把推理过程拆成 prefill/decode/KV Cache 的细粒度时间线,但覆盖面有限(支持的推理引擎和模型架构还不够广)。SGLang 的内置 metrics 在快速完善。然而,kernel 级 profiling(Nsight)仍然需要专家手动操作——运行 profiler、导出 timeline、肉眼分析 kernel 占比——门槛极高。
挑战:
-
Kernel 级 profiling 的门槛太高。Nsight Systems 导出的 timeline 包含数千个 kernel 调用,每个 kernel 有 start/end/duration/SM utilization 等字段。解读这些数据需要深厚的 GPU 架构知识——什么是 WGMMA、什么是 occupancy、为什么 GEMM kernel 的 Tensor Core 利用率只有 40%。这对大多数 SRE 是黑箱。
-
推理引擎 metrics 和 Agent trace 之间没有标准化的关联。vLLM 的 request_id 和 Langfuse 的 trace_id 不会自动对齐。当你看到 Langfuse 里某个 Agent step 的延迟飙升,想下钻到 vLLM 看当时的推理引擎状态时,只能靠时间戳做人工关联——这在多并发场景下几乎不可行。
-
MoE expert 分布、spec decoding accept rate 等关键指标在大多数推理引擎的默认 metrics 中不暴露。vLLM 默认不输出 per-expert 调用频率,SGLang 也不在标准 metrics 里包含 accept rate 按任务类型的分桶统计。这些语义级指标需要推理引擎自身在代码中插桩——不是在 CUDA kernel 里,而是在调度器和 Router 逻辑层。
-
Blackwell 架构的新特性需要新的 profiling 方法论。FP4 精度的 roofline 分析不同于 FP16/FP8;TMEM(Tensor Memory)的读写模式不能用 SRAM 的模型分析;2-CTA MMA 的双线程阵列协作需要新的性能计数器。DCGM 对 Blackwell 的支持仍在追赶。
对工具体系的要求:
- 需要自动化的 kernel bottleneck 诊断——不需要专家看 Nsight timeline,而是工具自动识别"Flash Attention 占了 prefill 的 35%、GEMM 占了 50%、其中 MLP down-projection 的 Tensor Core 利用率偏低"并给出优化建议
- 需要推理引擎 trace 和应用层 trace 的自动关联——共享 request_id(或通过 OTel context propagation 自动传递 trace context),让 Langfuse 的 Agent step span 可以一键下钻到 vLLM 的推理引擎 metrics
- 需要可插拔的 metrics exporter 架构——让 MoE expert 分布、spec decoding accept rate 等语义指标可以通过插件方式暴露,而不是等推理引擎官方支持
判断:从黑盒到白盒
推理引擎的可观测性正在从"有 metrics 就行"向"kernel 级别全透明"演进。这个方向的终极形态不是一个监控 dashboard,而是一个自优化系统——推理引擎实时感知自己的性能瓶颈,自动调整配置,甚至自动生成更优的 kernel。
谁先做到这一点,谁就定义下一代推理基础设施的标准。vLLM 有开源生态优势,NVIDIA 有硬件纵深和 AVO 这样的 AI 自主优化能力,但第三方工具(Graphsignal、Langfuse、Phoenix)有可能成为跨引擎、跨硬件的统一观测层。
推理引擎从黑盒走向白盒,kernel 级 telemetry 很可能在 12 个月内成为推理服务的标配。当 GPU 的每一毫秒都被精确计量和优化时,"推理成本"才会从会计问题变成工程问题——而工程问题是可解的。
但这里有一个更深的转向:当 AVO 这样的 AI agent 能比人类更快地生成更优的 kernel 时,可观测性工具的最终用户不再是人类工程师,而是 AI 自身。为 AI 设计性能反馈通道——结构化、高频率、programmatic——这可能是下一个推理基础设施的真正竞争壁垒。
引用
[1] Shah, Dao et al., "FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision", 2024. arXiv:2407.08691.
[2] AMD / SGLang, "Prefill-Decode Disaggregation on AMD GPU", 2025. 见 AMD ROCm 博客 及 SGLang 文档。聊天机器人场景 95 分位 Goodput 提升 6.9×,重 decode 场景 2.2×。原文引用的 6.4× 为多场景加权平均值。
[3] Dao, Haziza et al., "FlashAttention-4: Algorithm-Kernel Co-Design for Blackwell", 2026. arXiv:2603.05451. B200 上 BF16 达 1613 TFLOPS(71% 利用率),使用 CuTe-DSL 实现。
[4] DeepSeek-AI, "FlashMLA: Efficient MLA Decoding Kernels for Hopper GPUs", 2026. 见 github.com/deepseek-ai/FlashMLA。MLA 将 KV Cache 压缩 93%(10 GB → 0.67 GB / 1000 tokens),H800 上 3000 GB/s 带宽、580 TFLOPS。
[5] DeepSeek-AI, "DeepEP: Efficient All-to-All Communication for MoE Expert Parallelism", 2026. 见 github.com/deepseek-ai/DeepEP。支持 FP8 传输、节点内/跨节点双模式。
[6] DeepSeek-AI, "DeepSeek-V3 Technical Report", 2025. MTP 头设计:一次预测 2-3 个 token,共享主模型主干,推理时作为 spec decoding draft。比独立 draft model 的 accept rate 高 10-15%。
[7] NVIDIA, "Agentic Variation Operator (AVO): AI-Generated GPU Kernels", 2026. AVO 自动生成的 attention kernel 比 FA4 手写 kernel 快 10.5%。见 NVIDIA Research。
[8] NVIDIA, "Blackwell B200 Architecture Whitepaper", 2024. FP4 Tensor Core ~20 PFLOPS,HBM3e 8 TB/s,每瓦 token 数为 Hopper 的 50x(官方数据)。
下一篇 Deep Dive 将聚焦 Agent 决策路径观测——当 AI Agent 在 20 步任务中第 7 步就走偏时,传统监控为什么完全看不到,以及新兴的 Agent 可观测性工具如何试图填补这个空白。