2026年3月,黄仁勋发表了一篇罕见的长文《AI Is a 5-Layer Cake》。他说 AI 不是单一的应用或模型,而是一种新型基础设施——像电力和互联网一样。他把 AI 产业分成五层:能源、芯片、基础设施、模型、应用,自下而上,彼此支撑。
五层里最容易被忽略的是最底下的能源层。黄仁勋的原话是:"能源是智能生成的物理基础,也是产业规模的最终上限。"这句话的意思是,不管你在上面几层做出多好的芯片、多聪明的模型,如果电送不到、送不稳、送不起,一切都归零。
美银证券显然听懂了这句话。两个月后他们发布了一份不太像半导体研报的报告——标题叫 "Watts to Tokens",把每一度电都换算成 AI 产出的 token,功率半导体成了新时代的"卖铲人"。
机架功耗涨了100倍,配电架构被逼到了墙角
2026年5月25日,美银证券发布了一份不太像半导体研报的报告。标题叫 "Watts to Tokens",把每一度电都换算成AI产出的 token,功率半导体成了新时代的"卖铲人"。
报告的核心数字很刺眼:
| GPU 平台 | 单机架功耗 | 时期 |
|---|---|---|
| 传统服务器 | 10-15 kW | 2023 |
| Hopper (H100) | ~32 kW | 2024 |
| Blackwell (B200) | ~120 kW | 2025 |
| Rubin Ultra | >600 kW | 2026-2027 |
| Feynman | >1,500 kW (1.5 MW) | 2029-2030 |
十年内机架功耗涨了近百倍。但配电商能扛住这个增速吗?
扛不住。现有的54V直流配电架构已经撞上了物理天花板。一个兆瓦级机架如果还用54V供电,电源系统需要占据64U机架空间,整个机柜都给了电源,GPU 往哪放?铜母排的重量、线缆的截面积、多级AC/DC转换的热损耗,每个环节都在说同一句话:这条路的物理余量已经耗尽了。
800V 直流配电:不是可选升级,是物理定律逼出来的必然
NVIDIA 在2025年10月 OCP 峰会上发布了一份白皮书:《800VDC Architecture for AI Infrastructure》。不是概念演示,是生产路线图。
核心思路:把传统4-5级电力转换压缩到1-2级。
传统配电链路(415V AC 系统):
13.8kV 中压交流 → 低压开关 → UPS → PDU → PSU(AC/DC) → 板级DC-DC → GPU
↓ ↓ ↓ ↓ ↓ ↓
效率损失 效率损失 效率损失 效率损失 效率损失 效率损失
每级转换都有损耗,末端54V传输时电流极大——P=I²R,电阻损耗按电流平方增长。
800V 直流配电链路:
13.8kV 中压交流 → SST/集中整流 → 800V 直流母线 → 机架级 DC-DC → GPU
↓ ↓ ↓ ↓
单级转换 1-2级 低电流传输 最终调压
关键收益不是"效率高了几个点",而是结构性简化:
- 800V 传输相同功率,电流降到54V的约1/15,电阻损耗暴跌到约1/225
- 在1GW IT负载下,设施层面功耗直降约5%,等于连续省出69MW——每年电费少烧几千万美元
- 直流母线是两根导体,省掉了交流开关设备、低压交流 PDU、机架内 AC/DC 电源
- 储能系统(超级电容+电池)直接挂在直流母线上,平抑AI训练带来的毫秒级30%-100%负载波动,省掉了传统UPS的AC→DC→AC双转换
NVIDIA 的演进路线很清晰:
| 阶段 | 方案 | 效率 | 状态 |
|---|---|---|---|
| 当前主流 | 传统UPS(3-4级转换) | ~92% | 仍在用但逼近极限 |
| 过渡期 | 240V/380V HVDC | ~95-97.5% | 正在铺开 |
| 2026-2027 | 800V HVDC(Sidecar边柜方案) | ~97% | 与 Kyber 机架同步推进 |
| 2028+ | SST(固态变压器,中压AC直转800V DC,1级) | ~98.5% | 示范 → 规模化 |
NVIDIA 明确:从2027年开始,800V HVDC 将与 Kyber 机架级系统同步全面投产。合作生态囊括 Infineon、TI、Delta(台达)、Flex Power、Megmeet(麦格米特)、Vertiv、Schneider 等近30家企业。不是独家绑定,但进入名录的门槛很高。

设备侧逐环节拆解:从电网到 GPU 核心,每一级发生了什么
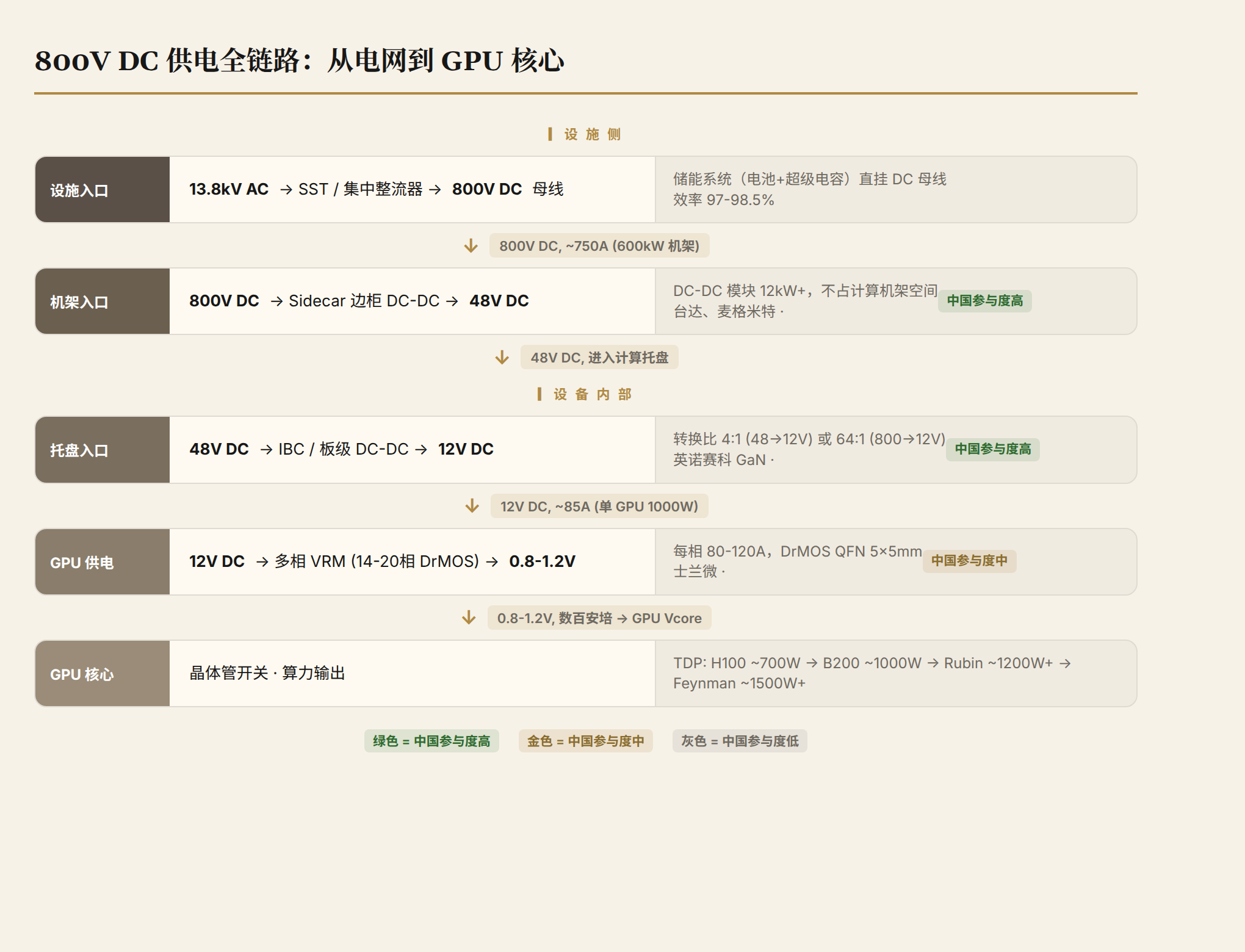
前面的对比是 facility 层面的,电网到机架入口。但 800V 转型不只是机房的事,它改变了服务器和交换机内部的电源架构。这一节把供电链路上的每个环节掰开,逐级看新旧两种模式下设备的物理形态、关键器件和改造要求。
环节一:设施入口——中压 AC 到机房配电
旧模式(415V AC 系统):
13.8kV AC → 变电站降压 → 415V 三相 AC → 交流 UPS → 交流 PDU → 机架
- 变电站将中压降到 415V 三相交流,经过交流 UPS(电池+逆变器)做备电保护
- 交流 PDU 分配到每排机架,需要处理三相平衡、无功功率、接地检测
- 机房内铺设大量交流电缆,每排机架一套开关柜
- 设施级 UPS 效率 92-95%,体积大、占地大
新模式(800V DC 系统):
13.8kV AC → SST/集中整流器 → 800V DC 母线 → 直流配电 → 机架
- SST(固态变压器)或集中整流器把 13.8kV AC 一次转到 800V DC
- 直流母线只有正负两根导体,走线槽大幅简化
- 储能系统(电池+超级电容)直接挂在直流母线上,替代传统交流 UPS
- 设施级效率 97-98.5%,省掉整个交流开关柜层
对服务器/交换机的影响: 这个环节的设备都在设施侧,服务器不直接参与。但有一个间接影响:旧模式下每台服务器 PSU 需要接受 AC 输入并自己做 AC/DC 转换;新模式下 PSU 的输入变成了 800V DC,拓扑结构完全不同。
环节二:机架入口——Power Shelf vs Sidecar
旧模式:Power Shelf(电源架)
AI 服务器机架(如 GB200 NVL72)在机架中部或侧面安装 Power Shelf,一个集中放置 PSU 模块的机箱。
415V AC → Power Shelf(多个 PSU 并联)→ 54V DC 铜母线 → 计算托盘
- 每台 PSU 接受 415V AC 输入,输出 54V DC
- PSU 典型功率 3-5kW,一台 120kW 机架需要 24-40 个 PSU 模块
- 54V DC 通过铜母线(busbar)分配到各计算托盘
- 120kW 时 54V 母线电流超过 2500A,铜母排截面积大、发热严重
- Power Shelf 占用 6-12U 机架空间,挤压计算设备空间
- 典型效率:AC/DC PSU ~94%,Power Shelf 整体 ~93%
- 标准:OCP Open Rack V3 规范定义了 48V/54V 电源架接口
新模式:Sidecar(电源边柜)+ 800V DC 直入
800V DC → Sidecar 边柜(集中 DC-DC)→ 48V/50V DC → 计算托盘
或
800V DC → 机架内 DC-DC 模块 → 12V DC → 计算托盘
NVIDIA Kyber 机架采用 Sidecar 方案——电源模块放在独立的边柜中,与计算机架并排:
- Sidecar 接受 800V DC 输入,集中转换为 48V/50V DC(过渡方案)或 12V DC(终极方案)
- 600kW 机架在 800V 下仅约 750A 总电流,铜排截面积降到原来的 1/15
- Sidecar 不占用计算机架的 U 位空间,计算密度释放
- 单台 DC-DC 模块功率可达 12kW+,仅需约 50 个模块覆盖 600kW
- 意法半导体在 GTC 2026 展示了 800V DC 直转 12V 和 6V 的完整链路方案
- 典型效率:800V→50V DC-DC ~97%,800V→12V DC-DC ~96%
关键区别: 旧 PSU 做 AC→DC 转换(415V AC→54V DC),新模块做 DC→DC 转换(800V DC→48V/12V DC)。拓扑、器件、控制逻辑完全不同。你不能在旧 Power Shelf 里插 800V 模块,机架配电的物理接口需要重新设计。
环节三:计算托盘入口——板级 DC-DC
旧模式(54V→12V→GPU):
54V DC 铜母线 → 托盘连接器 → 板级 DC-DC(54V→12V) → 12V 配电平面 → GPU
- 计算托盘(compute tray)通过边缘连接器从铜母线取 54V
- 板上 DC-DC 把 54V 降到 12V,典型用 LLC 谐振或 Buck 拓扑
- 12V 配电通过 PCB 走线分配到 GPU 和 CPU
- 单个 GPU(TDP 700-1000W)在 12V 下需要 60-85A 电流,PCB 铜层厚度和走线宽度是硬约束
- 这一级 DC-DC 的器件:硅基 MOSFET + 驱动 IC + 电感电容,是模拟/功率半导体的传统领地
新模式(800V 直入托盘 / 48V 过渡):
过渡方案:
48V/50V DC → 托盘连接器 → 板级 DC-DC(48V→12V)→ 12V 配电 → GPU
终极方案(NVIDIA 推进方向):
800V DC → 托盘连接器 → 板级 DC-DC(800V→12V,64:1 转换比)→ 12V 配电 → GPU
800V 直转 12V 是整个链路中技术挑战最大的一级:64:1 的转换比、单模块 12kW 功率,要求在极度紧凑的空间里实现 96%+ 效率。
- 拓扑选择:LLC 谐振为主,SiC/GaN 器件替代硅 MOSFET 做高侧开关 必须使用嵌埋式 PCB(embedded PCB),将磁性元件和功率器件埋入 PCB 内部层,用垂直供电减少平面占用。嵌埋式 PCB 的价值量比传统 PCB 高出数倍,仅 800V→12V 一次电源领域的嵌埋式 PCB 市场空间就超过 350 亿元。
如果 800V 直入托盘,主板上不再有 54V→12V 这一级,取而代之的是 800V→12V 的高压 DC-DC。PCB 布局、绝缘间距(800V 安全间距远大于 54V)、散热路径都需要重新设计。不是改个电源模块能解决的,是整块主板重新 layout。
环节四:GPU 核心供电——VRM / 多相供电
这一级是 GPU 供电的最后一公里。新旧模式下变化最小,因为输入都是 12V 左右,输出都是 0.8-1.2V 的核心电压。但电流规模在急剧攀升。
VRM(Voltage Regulator Module,电压调节模块):
12V DC → 多相 VRM(每相 80-120A)→ 0.8-1.2V GPU Vcore
- GPU 核心电压约 0.8-1.2V,但电流可达数百安培甚至上千安培
- 多相并联:单相 80-120A,一颗 TDP 1000W 的 GPU 可能需要 12-16 相
- 每相核心器件:DrMOS(集成了驱动器+高侧MOSFET+低侧MOSFET 的单封装芯片)+ 电感
- DrMOS 封装以 QFN(5×5mm 或 6×6mm)为主,追求极低寄生电感
- 控制器IC 通过 PMBus 或 SVID 接口与 GPU 通信,实时调节电压和相数
新旧模式对比: VRM 这一级在新旧模式下几乎一样——输入都是 12V。真正变化的是 VRM 的规模:
| GPU 代际 | TDP | 12V 电流 | VRM 相数 | DrMOS 数量 |
|---|---|---|---|---|
| H100 | ~700W | ~60A | 10-12 相 | 10-12 颗 |
| B200 | ~1000W | ~85A | 14-16 相 | 14-16 颗 |
| Rubin | ~1200W+ | ~100A | 16-20 相 | 16-20 颗 |
| Feynman(预计) | ~1500W+ | ~125A+ | 20-24 相 | 20-24 颗 |
每代 GPU 增加约 20% 的 TDP,驱动 VRM 相数和 DrMOS 用量持续增长。这是模拟芯片增量最确定的一级,不管配电架构怎么变,GPU 核心供电的 VRM 需求只会越来越多。
环节五:保护与监控——eFuse、热插拔、电流检测
这级常被忽略,但在兆瓦级机架里至关重要。
旧模式:
- 每个计算托盘入口有 eFuse(电子保险丝),在 54V 下做热插拔保护
- 电流检测用分流电阻(shunt resistor)或霍尔传感器
- 过流保护响应时间毫秒级,够用
新模式:
- 800V DC 下 eFuse 的设计难度陡增——断开 800V 直流电弧比断开 54V 困难得多,需要 SiC 器件做固态断路器
- 电流检测需要更高精度的传感器(800V 下小误差 = 大功率偏差)
- 热插拔控制必须在亚毫秒级响应,否则电弧会损坏连接器
- 英飞凌已推出面向 400V/800V 供电架构的 48V eFuse 系列和热插拔控制器参考设计
环节六:交换机供电
网络交换机在 AI 集群里的功耗也在暴涨。
旧模式: 交换机 PSU 接受 AC 输入(内部 AC→DC 转换),或用 48V/54V 直供。典型功耗 500W-2kW,在 54V 下电流约 10-40A,问题不大。
新模式: 高端口数 InfiniBand 或以太网交换机(如 NVIDIA Quantum-X 800G)功耗向 3-5kW 演进。在 800V DC 环境下:
- 交换机需要新的 PSU 模块接受 800V DC 输入
- 交换机内部空间更紧凑(要留给光模块和 ASIC),电源模块必须极度小型化
- 800V→12V/5V 的 DC-DC 转换要塞进 1U 甚至半 U 的空间
SemiAnalysis 预估,交换机和网络设备的 800V 适配将比 GPU 服务器慢 1-2 年,因为交换机功耗还没到 54V 的物理极限。但到 2028-2029 年,当 51.2T 甚至 102.4T 交换机功耗超过 10kW 时,同样会面临转型压力。
Apple-to-Apple 全链路对比总表
| 供电环节 | 旧模式(54V AC 系统) | 新模式(800V DC 系统) | 关键变化 |
|---|---|---|---|
| 设施入口 | 13.8kV AC → 变电站 → 415V AC → 交流 UPS → AC PDU | 13.8kV AC → SST/整流器 → 800V DC 母线 → DC 配电 | 去掉交流 UPS/PDU 层,储能挂 DC 母线 |
| 机架入口 | AC PDU → Power Shelf(24-40 个 AC/DC PSU)→ 54V 铜母线 | 800V DC → Sidecar 边柜(~50 个 DC-DC 模块)→ 48V/12V | PSU 从 AC/DC 变 DC/DC;机架内无 AC 线缆 |
| 托盘入口 | 54V → 板级 DC-DC → 12V | 48V/800V → 板级 DC-DC → 12V | 800V 直入时转换比从 4.5:1 升至 64:1 |
| GPU VRM | 12V → 多相 VRM → 0.8-1.2V | 12V → 多相 VRM → 0.8-1.2V | 输入不变,但相数随 TDP 增加而增长 |
| 保护/监控 | 54V eFuse + 分流电阻 | 800V SiC 固态断路器 + 高精度传感器 | 电压升高 15 倍,保护器件需重新选型 |
| 交换机 PSU | AC 输入 或 54V 直供 | 800V DC 输入(2028+) | 交换机功耗尚低,转型滞后 1-2 年 |
| 典型效率 | 92-93%(端到端) | 97-98.5%(端到端) | 每省 1% 在 GW 级 = 年省千万美元电费 |
| 铜材用量 | 基准 | 减少约 80% | 电流降 15 倍,线径成比例缩小 |
| 机架空间 | Power Shelf 占 6-12U | Sidecar 与计算机架分离 | 计算密度释放,更多空间给 GPU |
改造的现实挑战
看完逐环节对比,一个自然的问题是:现有的服务器和交换机能不能改造升级到 800V?
答案是:几乎不能。原因不在某个单一器件,而是整条链路的接口定义都变了:
- PSU 模块不兼容:旧 PSU 接受 AC 输入,新模块接受 800V DC 输入。插座形状、引脚定义、安全间距完全不同
- 铜母线要换:54V 铜母线的绝缘等级、截面积、连接器规格不适用于 800V。安全间距从几毫米增加到数十毫米
- 主板要重新设计:800V 直入托盘时,PCB 绝缘间距、散热路径、DC-DC 布局全部推倒重来
- 保护电路要重做:54V eFuse 在 800V 下会击穿,需要 SiC 器件做新的固态断路器
- 监控软件要适配:直流配电的故障特征(电弧、短路行为)与交流完全不同,DCIM 系统需要更新
所以现实路径是:新数据中心用 800V 从头建设,老数据中心继续用 54V 直到退役。不存在平滑过渡,这是两代不兼容的配电架构。NVIDIA 的方案也印证了这一点:Kyber 机架是一个全新设计,不是在任何现有机架基础上改造的。
800V 之外另一条线:设备内部供电的三代演进
到此为止讨论的都是 facility 侧,从电网到机架入口的配电架构转型。但设备内部还有一条并行的供电演进线,跟 800V 不是替代关系,而是分头推进:800V 解决"怎么把电送到机架",设备内部供电解决"怎么把电送到芯片核心"。两条线最终汇合。
第一代:12V 中间总线架构(传统服务器)
绝大多数传统服务器的供电路径:
PSU (AC→12V DC) → 12V 中间总线 → PCB 配电平面 → VRM → CPU/GPU (0.8-1.2V)
12V 总线架构统治了数据中心超过二十年。优点是简单——一个电压平面分配给所有组件。但当单颗 GPU 功耗超过 300W 后,12V 的物理瓶颈暴露了:
- 一颗 700W 的 H100 在 12V 下需要约 60A 电流,通过 PCB 走线传输的 I²R 损耗显著
- GPU 插槽和 PCB 铜层的电流承载能力有上限
- VRM(12V→0.8V)转换比 15:1,占空比极低(约 5-7%),效率优化空间有限
12V 架构在传统 CPU 服务器(TDP 200-350W)上够用,但在 AI 加速器时代已是强弩之末。
第二代:48V 直入(正在规模化)
Google 是最早推动 48V 进入服务器内部的。2017 年 Google 发布 Zaius POWER9 服务器,将 48V 直接送入主板,绕过 12V 中间总线。此后 OCP(开放计算项目)将 48V 纳入 Open Rack V3 规范,成为行业标准的演进方向。
48V 架构的关键变化:
PSU (AC→48V DC) 或 800V DC → DC-DC → 48V 总线 → IBC (48V→12V) → VRM → GPU
或
48V 直转 VRM → GPU (0.8-1.2V)
48V 相比 12V 的收益是数学层面的:传输相同功率,电流降到 1/4,I²R 损耗降到 1/16。对于单 GPU 功耗 700W+ 的 AI 服务器,这意味着:
- PCB 走线和连接器的热应力大幅降低
- 铜层厚度要求放松,给信号走线腾出更多 PCB 层
- 可以使用更细的电缆和更小的连接器
48V 进入设备内部后,有两种路径:
路径 A:48V→IBC→12V→VRM→GPU(两步转换,过渡方案)
IBC(中间总线转换器,Intermediate Bus Converter)把 48V 降到 12V,再由传统 VRM 从 12V 降到核心电压。好处是 VRM 不用改,兼容现有设计。坏处是多一级转换,效率损失约 2-3%。
路径 B:48V 直转 VRM→GPU(一步到位,终极方向)
48V 直接送入 VRM,由 VRM 直接降压到 0.8-1.2V 核心电压。省掉 IBC 这一级,效率更高。但挑战很大:
- 转换比 48:1(48V 到 1V),占空比约 2%,传统 Buck 拓扑在这个占空比下的效率和瞬态响应都不好
- 必须用开关电感(Switched Tank)或 LLC 谐振拓扑,配合耦合电感技术扩展有效占空比
- Vicor、MPS、Infineon 等企业已推出 48V 直转核心电压的方案,功率密度超 1000W/in³
目前主流 AI 服务器(GB200 等)走的是路径 A——48V 进机架,IBC 转 12V,VRM 再转核心电压。路径 B 是下一步,需要 VRM 器件和 PCB 设计的进一步成熟。
第三代:垂直供电 / 背面供电(前沿探索)
这是设备内部供电最前沿的方向,还没规模化,但所有头部企业都在投入。
传统供电是"侧面供电",VRM 芯片排在 GPU 旁边,通过 PCB 平面走线把电流送到 GPU 的供电引脚。问题在于当 GPU 电流超过 500A 时,PCB 平面走线本身就成了瓶颈。铜的电阻率不随工艺进步而降低。
垂直供电的思路是把 VRM 做到 GPU 的正下方(或正上方),电流垂直穿过 PCB,走线长度从几十毫米缩短到几百微米。
传统侧面供电(俯视图):
[VRM] [VRM] [VRM] ← 侧面排列
----PCB平面走线----
[ GPU 芯片 ]
垂直供电(侧视图):
[GPU 芯片]
═══════════ ← 垂直互连(通孔/微凸点)
[VRM 层] ← GPU 正下方
两种实现路径:
MPSP(Molded Power Supply Package,模塑电源封装): 在 PCB 制造阶段将功率器件和磁性元件嵌入 PCB 内部层。英飞凌是主要推动者,已在数据中心服务器领域推广。嵌埋式 PCB 价值量比传统 PCB 高出数倍,仅 800V→12V 一次电源领域就超过 350 亿元市场空间。
BPDN(Backside Power Delivery Network,背面供电网络): 在晶圆制造阶段从芯片背面打供电通孔,直接在晶圆层面实现。Intel 已在 18A 制程量产 PowerVia 背面供电;台积电计划在 A16(16 埃米)制程推出超级电源轨(Super Power Rail);三星计划在 SF2(2nm)引入背面供电。
BPDN 目前主要面向 CPU/GPU 核心逻辑的供电(1V 以下),解决最末端的"最后一微米"。MPSP 解决板级到封装级的"最后一厘米"。两者互补,不是竞争。
ADI 15 亿美元收购 Empower:信号很明确
2026 年 5 月 19 日,ADI 宣布以 15 亿美元全现金收购电源管理初创企业 Empower Semiconductor。Empower 的核心能力是用 CMOS 工艺实现超高功率密度、超快瞬态响应的电源管理 IC,专门解决 AI 处理器的供电瓶颈。
ADI CEO Vincent Roche 的说法很直白:"AI 基础设施正在从根本上重塑供电方式,能源已成为制约新一代系统拓展的核心因素。"
供电架构的价值正在被重新定价。传统上电源管理 IC 是模拟芯片里的"脏活累活",毛利率低、技术门槛看起来不高。但当 AI 处理器功耗密度逼近物理极限时,供电方案的优劣直接决定了系统能不能跑满算力。15 亿美元买一家电源管理初创,估值远超传统模拟芯片的并购倍数,资本市场已经认可了这个逻辑。
三代演进总览

| 维度 | 第一代(12V 中间总线) | 第二代(48V 直入) | 第三代(垂直供电) |
|---|---|---|---|
| 供电路径 | 12V 总线 → VRM → 核心 | 48V 直入 → VRM → 核心 | VRM 在芯片正下方/背面 |
| 转换级数 | 2-3 级 | 1-2 级 | 0-1 级(最短路径) |
| 电流传输距离 | 数十毫米(PCB 平面) | 数毫米(缩短走线) | 数百微米(垂直通孔) |
| 功率密度 | ~200W/in³ | ~1000W/in³ | 目标 >3000W/in³ |
| 主要瓶颈 | PCB 铜层载流能力 | VRM 占空比优化 | 制造工艺(晶圆级/PCB 嵌埋) |
| 成熟度 | 成熟,存量巨大 | 规模化中(GB200 等) | 前沿探索,2028+ 规模化 |
| 关键器件 | 硅 MOSFET DrMOS | SiC/GaN + 耦合电感 | 嵌埋式器件 / 背面通孔 |
| 中国参与度 | 高(华为、浪潮等均有设计能力) | 中(英诺赛科 GaN、士兰微 DrMOS) | 低到中(PCB 嵌埋有基础,晶圆级落后) |
800V 和 48V 不是二选一
这是一个常见的混淆点。澄清一下:
- 800V DC 解决 facility 侧,从电网到机架入口。它替代的是交流配电(415V AC + UPS + PDU)
- 48V 直入解决设备内部,从机架入口到 GPU 板卡。它替代的是 12V 中间总线
- 两者是同一条链路的不同区段,互不冲突。完整路径:
13.8kV AC → SST → 800V DC → Sidecar DC-DC → 48V → VRM → GPU (0.8-1.2V)
↑ 设施侧 ↑ 设备内部
800V 的范围 48V 的范围
NVIDIA 的 800V 架构白皮书里明确写了:Sidecar 输出 48V DC,然后 48V 进入计算托盘,由板级 VRM 完成最终降压。800V 送电到门口,48V 送电到桌面,垂直供电送电到手上。三级接力,各有各的技术挑战。
270亿美元从哪来:把机架拆成一颗颗芯片
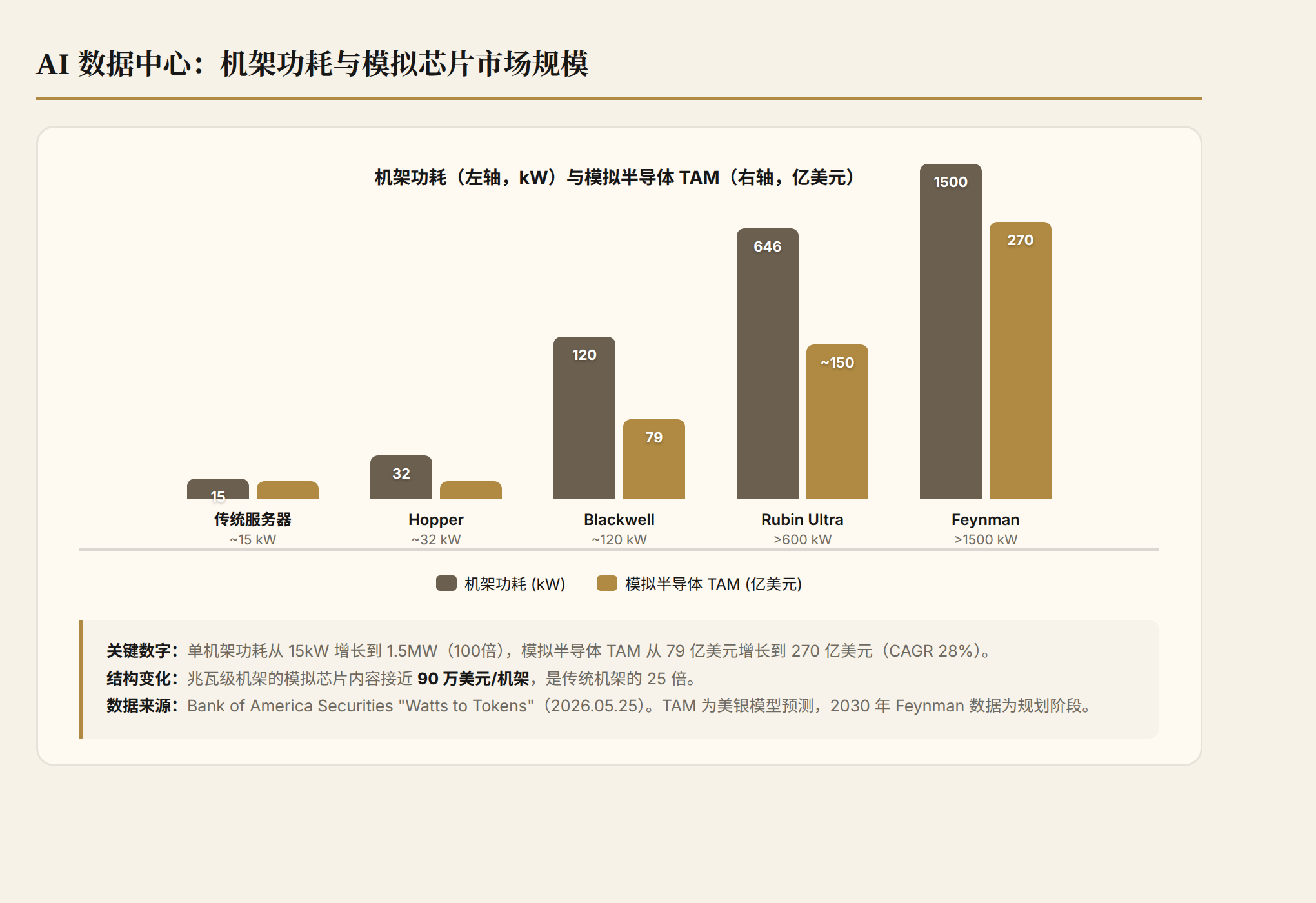
美银的自下而上需求模型是这篇报告最有价值的部分。他们不是简单给个TAM(Total Addressable Market,可寻址市场),而是把AI数据中心里每个配电环节的半导体含量拆开算:
单机架模拟半导体内容价值:
| 机架功耗等级 | 模拟半导体内容 | 对应平台 |
|---|---|---|
| ~15 kW(传统) | ~3.6 万美元 | 传统服务器 |
| ~120 kW | — | Blackwell |
| ~600 kW | ~30 万美元 | Rubin Ultra |
| ~1,500 kW (1.5 MW) | >90 万美元 | Feynman |
兆瓦级机架的模拟芯片含量接近百万美元——每台机架里的功率器件、电源管理IC、驱动IC、电流传感器、保护电路加在一起,比很多人想象的贵得多。
汇总到市场规模:
| 指标 | 2025年 | 2030年 | CAGR |
|---|---|---|---|
| AI数据中心模拟半导体 TAM | 79 亿美元 | 270 亿美元 | 28% |
| AI数据中心新增电力需求 | ~17 GW/年 | ~60 GW/年 | — |
28%的复合年增长率,在半导体领域属于高速扩张。而且这个增长不是周期性的——它跟着AI算力部署走,只要GPU功耗还在涨,配电架构的半导体含量就会继续升。
最大的受益方向:SiC(碳化硅)和 GaN(氮化镓)。这两种宽禁带半导体材料正在从汽车/工业的周期性需求,加速向AI数据中心的长期结构性需求迁移。
为什么是SiC和GaN
传统硅基功率器件在 800V/兆瓦级场景下力不从心,击穿电压、导通损耗、开关频率都不够。宽禁带半导体不是锦上添花,而是 800V 架构落地的必要条件:
SiC 负责高压前端:
- 额定电压1200V以上,在数据中心主电源输入环节做中压AC到800V DC的一次转换
- 成熟度高于GaN,是数据中心入口侧的首选
- 英飞凌 CoolSiC、安森美 EliteSiC、意法半导体 STPOWER 是当前主流产品线
GaN 负责高密度机架内转换:
- 开关频率可达MHz级,允许使用更小的电感和电容
- 基于GaN的转换器功率密度已超过 4.2 kW/L,能把800V DC高效降压到GPU需要的12V
- 器件体积仅为硅基方案的1/5,在高密度机架里空间就是算力
两者不是竞争关系,而是互补:SiC 做入口大功率,GaN 做末端高密度。一个数据中心里两者都需要。
中国的位置:比你想的要靠前
这是国内媒体和产业报告里最容易被低估的部分。大多数人知道英飞凌、TI、安森美在功率半导体领域的地位,但中国在 800V 数据中心配电的产业链上卡了几个关键位置。
英诺赛科:NVIDIA 800V 生态唯一中国芯片供应商
2025年8月1日,NVIDIA 官网更新 800V 直流电源架构合作商名录,英诺赛科(Innoscience,港股02577)入选,名单里唯一的中国芯片企业。
英诺赛科的定位是为 NVIDIA Kyber 机架系统提供全链路 GaN 电源解决方案。能入选不是因为政治平衡,而是技术实力:
- IDM 全链自主:从衬底、外延、芯片设计到封装测试全部自研,8英寸硅基GaN量产线良率超95%
- 全电压覆盖:GaN 器件覆盖15V到1200V,适配800V DC配电链路上从整流到末端调压的每个环节
- 效率数据:第三代GaN器件效率达98.5%,较传统硅基方案损耗降低约30%
- 全球8英寸GaN唯一量产:竞争对手还在6英寸,英诺赛科已跑通8英寸,成本和产能优势明显
消息发布当天英诺赛科港股盘中一度暴涨64%。这不是情绪化炒作,NVIDIA 的供应商准入极其严格,被选中意味着技术指标通过了英伟达工程团队的实测验证。
SiC 方向:斯达半导、士兰微、三安光电
SiC 产业链最核心的环节是衬底和外延(占器件成本约70%),技术壁垒最高。
| 企业 | 定位 | 进展 |
|---|---|---|
| 三安光电 | 国内唯一6英寸SiC全产业链(衬底+外延+器件)IDM | 已量产,8英寸研发推进中 |
| 天岳先进 | SiC衬底,技术路线对标 Wolfspeed | 6英寸导电型衬底批量出货 |
| 斯达半导 | IGBT/SiC模块,车规级验证 | 向工业和数据中心扩展 |
| 士兰微 | 硅基+SiC+模拟三线并进 | DrMOS、eFuse等AI服务器电源芯片组合已部分量产 |
距离英飞凌、意法半导体的成熟度还有差距。国际头部企业率先推动 8 英寸 SiC 量产,中国企业还在 6 英寸向 8 英寸过渡。但差距在缩小,而且 800V 数据中心是一个全新领域,所有人面对的技术挑战类似,历史包袱反而少。
电源系统与集成:台达、麦格米特、芯朋微
芯片是底层,但 800V 配电最终落地靠电源模块和系统集成商。这个方向中国企业有明显优势:
| 企业 | 角色 | 关键信息 |
|---|---|---|
| 台达电子(Delta) | NVIDIA 800V HVDC 供应商联盟成员 | 全球数据中心电源模块市占率超15%,单台PSU功率达27.5kW,效率98%+ |
| 麦格米特(Megmeet) | NVIDIA 官方合作商名录 | 电源模块供应商,与NVIDIA合作开发800V HVDC方案 |
| 芯朋微 | AI数据中心电源芯片 | 1700V SiC辅助电源方案、多相VRM、高频数字电源控制器 |
| 英维克/申菱环境 | 液冷+配电一体化 | 高密度配电与散热协同设计 |
台达是 NVIDIA 800V 生态里非常重要的存在。不生产芯片,但做系统级集成,把芯片能力变成可交付的电源模块。全球数据中心电源市场,台达的份额和英飞凌的芯片份额一样,属于基础设施级别的存在。
产业链全景:谁在哪个环节
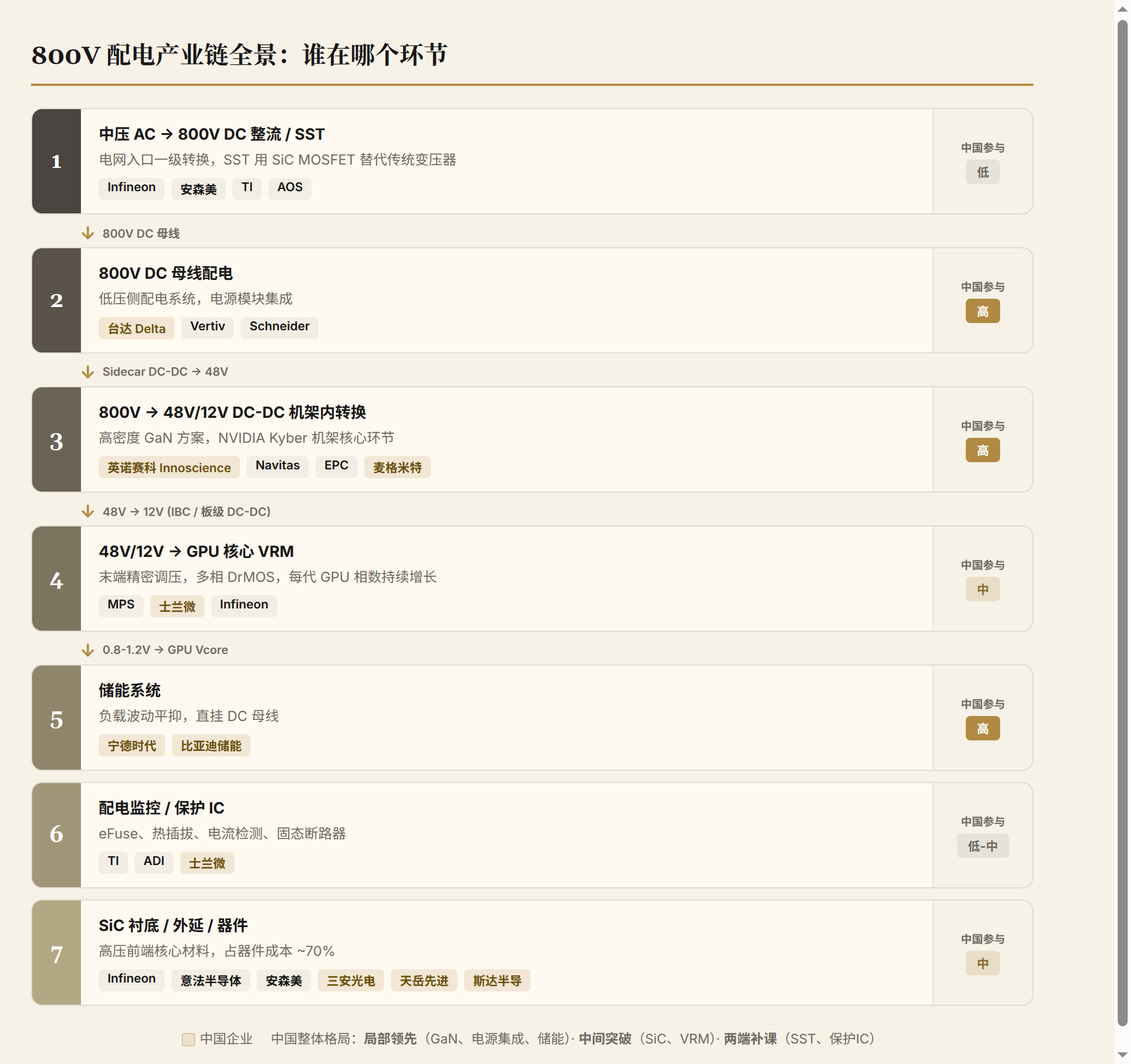
把800V配电从电网到GPU的完整链路画出来,每个环节的主要玩家是这样的:
| 环节 | 功能 | 主要玩家 | 中国参与度 |
|---|---|---|---|
| 中压AC→800V DC 整流/SST | 电网入口一级转换 | Infineon、安森美、TI、AOS | 低(SiC衬底有参与,器件端刚起步) |
| 800V DC 母线配电 | 低压侧配电 | Vertiv、Schneider、台达 | 高(台达是核心供应商) |
| 800V→50V/12V DC-DC | 机架内高密度转换 | 英诺赛科(GaN)、Navitas、EPC | 高(英诺赛科是NVIDIA唯一中国GaN供应商) |
| 50V/12V→GPU核心 VRM | 末端精密调压 | MPS、士兰微、Infineon | 中(士兰微进入,整体份额还小) |
| 电源模块/PSU | 系统集成 | 台达、麦格米特、Flex Power | 高 |
| 储能系统 | 负载波动平抑 | 宁德时代、比亚迪储能 | 高(电池是中国的绝对优势领域) |
| 配电监控/保护IC | 电流检测、eFuse、热插拔 | TI、ADI、士兰微 | 低到中 |
把整条链路画出来会发现,中国在800V配电上的参与度不是"全面追赶",而是"局部领先、中间突破、两端补课"。GaN器件(英诺赛科)和电源系统集成(台达、麦格米特)已经有全球竞争力;SiC衬底和外延在追赶;入口侧高压器件和精密保护IC还有差距。
几个值得注意的判断
回到黄仁勋的五层框架:能源→芯片→基础设施→模型→应用。上面四层的创新速度都在加快,但能源层的物理约束不会因为你软件写得好就消失。以下判断都建立在这个基本不对称之上——上层创新越快,底层瓶颈越痛。
1. 800V DC 渗透速度可能超预期
美银预测到2030年78%的新增数据中心容量将采用 800V DC。这个数字看着激进,但逻辑链硬:不是技术选型偏好,而是兆瓦级机架没有其他物理上可行的方案。当 Rubin Ultra 机架功耗超过 600kW,54V 在工程上已经是死路。800V 不是"好一点",而是"只能这样"。
2. 模拟芯片不像数字芯片那样受制程卡脖子
这是一个重要的结构性判断。GPU 受先进制程制约,但功率器件和模拟 IC 主要用成熟工艺(65nm到280nm),不在 EUV 光刻机的限制范围内。SiC 和 GaN 的瓶颈在材料生长和器件设计,不在光刻精度。
这意味着中国在模拟/功率半导体领域的国产替代路径比数字芯片更短。英诺赛科已经证明了:在没有先进 EUV 的条件下,IDM 全链自主也能做出 NVIDIA 认可的产品。
3. 但有隐忧:产业格局偏"点"不偏"面"
中国目前的卡位更像是在特定节点上有明星企业(英诺赛科在 GaN、台达在电源模块),但缺乏像 Infineon 或 TI 那样覆盖功率+模拟+保护的完整产品线。在 NVIDIA 的 800V 生态里,中国企业提供的是关键组件,而不是完整解决方案。
从商业角度看这既是机会也是风险。800V 架构对供应链的可靠性要求极高,NVIDIA 会倾向于选择能提供全链路支持的供应商。如果中国企业只能做单点器件而无法做系统集成,长期价值天花板会被压低。
4. SST(固态变压器)是下一个技术分水岭
当前 800V DC 的落地方案还依赖传统变压器做中压 AC 到 800V DC 的转换。真正的终极形态是 SST,用电力电子器件替代变压器,把 13.8kV AC 直接一次转到 800V DC,效率从 97% 推到 98.5%。
SST 的核心器件是高压 SiC MOSFET 和数字控制 IC。这个环节目前完全是 Infineon、安森美、TI 的地盘,中国企业的参与度很低。如果 SST 在 2028 年后开始规模化部署(NVIDIA 的路线图暗示了这个时间节点),这里会出现新的竞争格局分化。
数据交叉验证与不确定性
已验证的核心数据:
- NVIDIA 800V DC 白皮书存在且公开(2025年10月OCP发布)
- 英诺赛科入选NVIDIA官方供应商名录(2025年8月1日,NVIDIA官网可查)
- 台达、麦格米特是NVIDIA HVDC供应商联盟成员
- 美银报告发布日期2026年5月25日,核心数据可交叉验证
需要独立确认的数据:
- 美银的79→270亿美元TAM模型假设(未看到完整方法论,可能对800V渗透率假设偏乐观)
- "78%新增数据中心容量采用800V DC"到2030年的预测——这个数字在行业里有争议,部分分析机构认为30-50%更现实
- 单机架模拟芯片内容"超90万美元"——这可能是峰值配置(Feynman平台),实际部署可能用混合方案压低成本
关键不确定性:
- Feynman平台的功耗是否真能达到1.5MW——这还在产品规划阶段
- SST的大规模商业化时间——目前还在示范阶段
- 地缘政治因素对NVIDIA供应链选择的潜在影响
观察节点
接下来几个值得跟踪的事件:
- COMPUTEX 2026(6月1-5日):NVIDIA 可能在黄仁勋 keynote 上更新800V架构的商用进展
- Rubin Ultra 量产时间:这是800V HVDC从"规划"变成"落地"的触发器
- 英诺赛科在NVIDIA Kyber机架中的实际供货份额——入选名录和拿到大单是两件事
- 国内SiC 8英寸产线进展:三安光电、天岳先进等能否在2027年实现量产
数据来源:Bank of America Securities "Watts to Tokens" 报告(2026年5月25日);NVIDIA 800VDC Architecture 白皮书(2025年10月);公开新闻报道与公司公告。市场规模数据来自美银研报,未经独立验证的推断已在文中标注。