一颗芯片,33 年
2026 年 6 月 1 日,台北南港展览馆旁的音乐中心。黄仁勋站在台上,身后的屏幕显示一颗芯片的截面图。
"Everything we've learned over 33 years, distilled into one chip."
这颗芯片叫 RTX Spark。它不是一块新 GPU——它是 NVIDIA 第一颗面向 Windows 笔记本的完整 SoC:20 核 ARM CPU(与 MediaTek 联合设计)+ 6,144 核心 Blackwell RTX GPU + 最高 128GB 统一内存 + 1 PetaFLOP FP4 AI 算力。
但 RTX Spark 只是这场 Keynote 的消费端故事。两小时里,黄仁勋还宣布了:Vera Rubin 数据中心平台全面量产、DSX 开源 AI 工厂框架、88 核 Vera CPU、550B 参数开源模型 Nemotron 3 Ultra、开放物理 AI 模型 Cosmos 3……
如果把所有发布串起来看,一个清晰的叙事浮出水面:NVIDIA 不再只是 GPU 公司。它在构建从数据中心到 PC 到机器人的全栈 AI 基础设施。
这篇文章试图回答三个问题:RTX Spark 到底意味着什么?Vera Rubin + DSX 为什么不只是"新一代 GPU"?这些发布对产业格局有什么影响?
RTX Spark:不只是 ARM 笔记本芯片
正式规格
NVIDIA 在 Keynote 后发布了官方新闻稿,规格如下:
| 参数 | RTX Spark(完整版) | N1 标准版 |
|---|---|---|
| GPU | Blackwell RTX, 6,144 CUDA 核心 + 第五代 Tensor Core | 2,048-2,560 CUDA 核心 |
| CPU | 20 核 NVIDIA Grace CPU(MediaTek 联合设计) | 10-12 核 (7+3 / 8+4) |
| 互联 | NVLink-C2C chip-to-chip | NVLink-C2C |
| 内存 | 最高 128GB 统一内存 | 最高 64GB LPDDR5X |
| 内存带宽 | 600 GB/s | — |
| AI 性能 | 1 PFLOP FP4 | — |
| TDP | 45-80W | 18-45W |

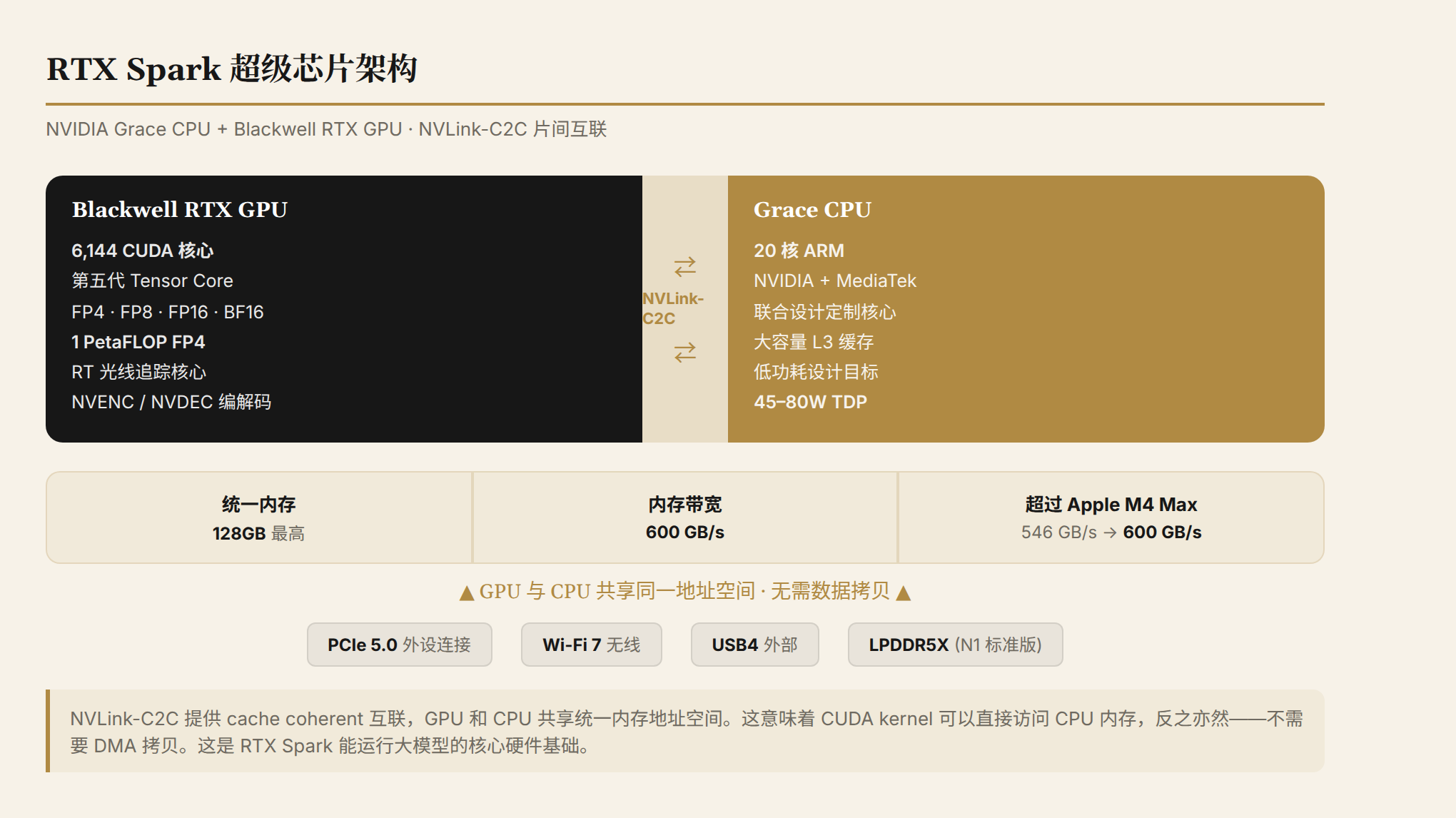
需要关注的几个数字:
600 GB/s 内存带宽。 之前的泄露数据是 273 GB/s,实际翻了一倍多。作为参照:Apple M4 Max 的统一内存带宽是 546 GB/s,RTX Spark 已经超过了它。对 AI 推理来说,内存带宽是瓶颈——模型参数要搬到计算单元面前才能运算,带宽直接决定推理速度。
128GB 统一内存。 这意味着一台 14mm 厚、3 磅重的笔记本可以本地运行一个 120B 参数的模型(FP16 约 240GB,但 FP4/INT4 量化后可以塞进 128GB)。CUDA 生态、TensorRT、NVIDIA 的全套 AI 软件栈都带进了 Windows 笔记本——这不是 ARM PC 的第一次尝试,但这是 CUDA 生态第一次完整地进入 Windows 笔记本。
1 PFLOP FP4。 一台笔记本的 AI 算力达到 1 PetaFLOP。两年前,这需要一台桌面工作站。
七家 OEM 同时站台
Keynote 上出现了罕见的阵容——七家 PC 厂商同时站台确认首发:
| 厂商 | 确认产品 | 发言人 |
|---|---|---|
| Dell | XPS 16 Creator Edition | Michael Dell |
| HP | OmniBook("最薄的 RTX Spark 笔记本之一") | Bruce Broussard(临时 CEO) |
| Lenovo | 未公布具体型号 | Yuanqing Yang(CEO) |
| Microsoft | Surface Laptop Ultra | Brett Ostrum |
| ASUS | 未公布具体型号 | Jonney Shih(董事长) |
| MSI | 未公布具体型号 | Jeans Huang(CEO) |
| Acer / GIGABYTE | 第一批之后推出 | — |
Microsoft 的参与尤其值得注意。Surface Laptop Ultra 意味着微软不只是提供了 Windows on ARM 的系统支持,而是亲自下场做硬件——这和当年的 Surface Pro 推动触屏笔记本的逻辑类似。

不是"又一个 ARM 笔记本芯片"
过去十年,ARM 笔记本有几次不太成功的尝试:Qualcomm 的 Windows on ARM、Samsung 的 Exynos 笔记本、Apple 的 M 系列(成功但封闭)。
RTX Spark 的不同之处在于它不是在"替代 x86"——它是在创造一个 x86 根本无法覆盖的新品类:AI 原生 PC。

黄仁勋在台上的定位很明确:
"For forty years, you launched apps. Click. Type. With RTX Spark and Microsoft Windows, you ask — and the PC does the work."
翻译成技术语言:传统 PC 的交互模式是"人驱动软件",RTX Spark 要做的是"agent 驱动工作流"。128GB 统一内存 + CUDA + 本地 AI 推理能力的组合,让 PC 从"运行应用的终端"变成"运行 agent 的节点"。
这个定位能不能成立,取决于两件事:
第一,ARM 上的游戏和创作软件兼容性。 NVIDIA 在 Keynote 上宣布 XBOX、NetEase、Remedy 已签约支持 RTX Spark 的游戏生态。具体兼容方案(原生移植还是转译层)没有公布。这是最大的风险点——如果 AAA 游戏不能流畅运行,RTX Spark 就只是一个"AI 开发者的专用本",成不了主流。
第二,定价。 NVIDIA 没有公布芯片价格。128GB 统一内存 + Blackwell GPU 的 BOM 成本不会低。如果 OEM 把 RTX Spark 笔记本定在 $2,000+,它就和大部分消费者无缘了。
Vera Rubin 全面量产:AI 工厂的"第二台发动机"
如果说 RTX Spark 是消费端的故事,Vera Rubin 就是这场 Keynote 的工业基础。
供应链规模翻倍
黄仁勋宣布 Vera Rubin 进入全面量产,供应链规模是 Grace Blackwell 的两倍。覆盖 350+ 工厂、30 个国家、150 家台湾合作伙伴。
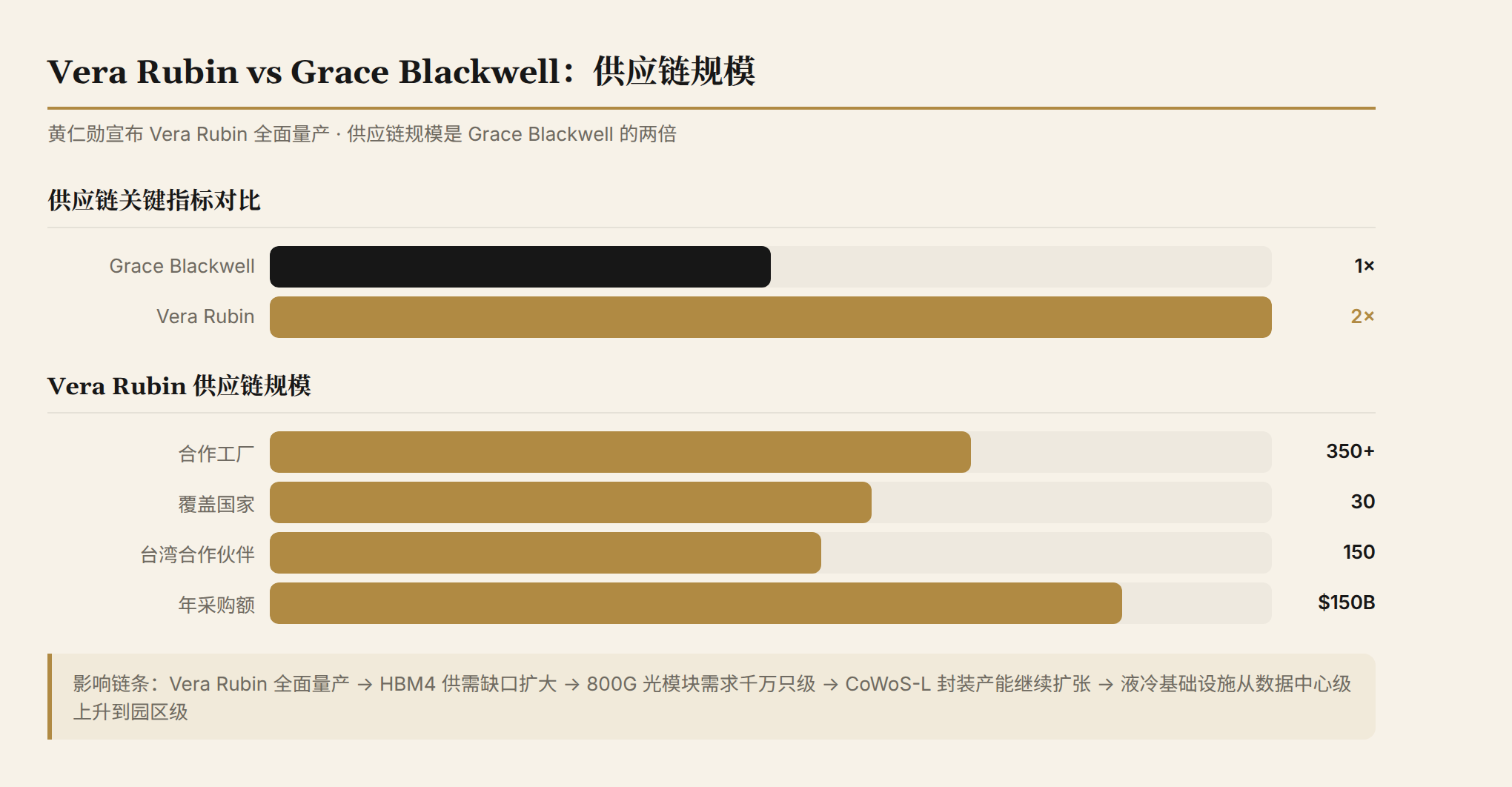
"两倍"这个数字需要仔细解读。它不只是说芯片出货量翻倍——而是整个供应链的产能、组件种类、合作伙伴数量都翻了一倍。Grace Blackwell 已经是半导体史上最大规模的芯片生产项目之一,Vera Rubin 在此基础上再翻一倍,意味着:
- HBM4 的需求量将再次超过供应能力(HBM3E 目前就已经供不应求)
- 800G 光模块的采购量会从数百万只级别上升到千万只级别
- 台积电的 CoWoS-L 封装产能需要继续扩张
- 液冷基础设施的需求从数据中心级别上升到园区级别
Vera CPU:为 Agent 设计的处理器
Keynote 上单独公布了 Vera CPU 的规格:
| 参数 | Vera CPU |
|---|---|
| 核心数 | 88 核 |
| 内存带宽 | 1.2 TB/s LPDDR5X |
| 片上互联 | 3.6 TB/s,无 chiplet 边界 |
| 每时钟指令数 | 10 条 |
黄仁勋的原话:
"We created CPUs for humans in the past... There will be billions of agents, and these agents are going to be using the CPUs with very little patience."
这是一个有意思的定位:Vera 不是要和 AMD EPYC 或 Intel Xeon 竞争通用服务器 CPU 市场。它是为 AI agent 工作负载专门设计的——高内存带宽(1.2 TB/s)、低延迟片上互联(3.6 TB/s,monolithic 无 chiplet)、高 IPC。这些特性在传统服务器 CPU 里不是首要设计目标,但对 agent 密集的推理和编排工作负载至关重要。
五机架统一平台
Vera Rubin 的部署形态是五机架平台:
| 组件 | 功能 |
|---|---|
| Vera Rubin NVL72 | GPU 计算(72 GPU per rack) |
| Vera CPU | Agent 编排和推理 |
| Groq 3 LPX | 推理加速 |
| Spectrum-6 SPX Ethernet | 网络 |
| BlueField-4 STX | 安全和多租户 |
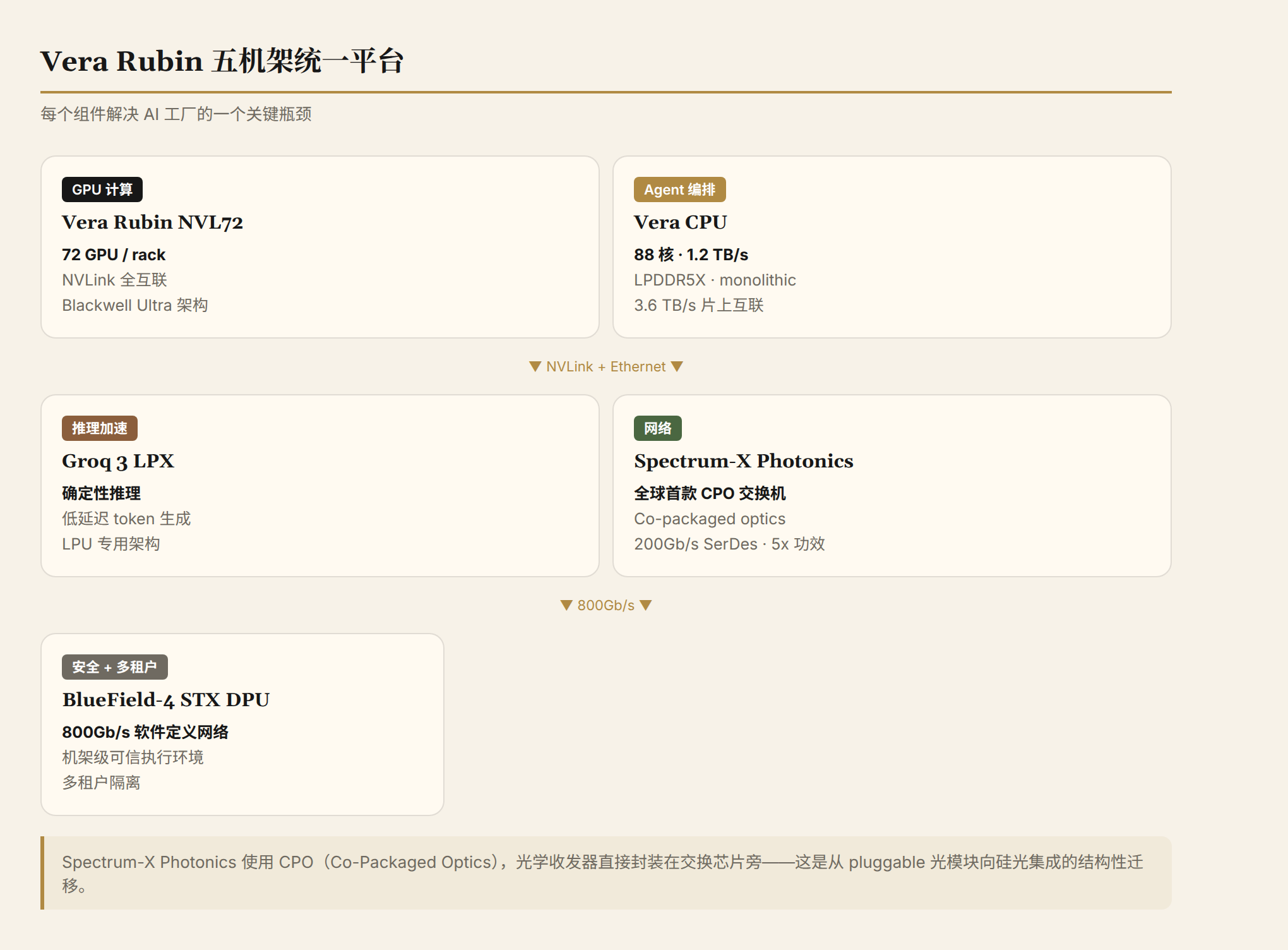
这个"五机架"组合值得关注的是 Spectrum-X Ethernet Photonics——全球首款基于 co-packaged optics (CPO) 的交换机。CPO 把光学收发器直接封装在交换机芯片旁边,省掉了传统 pluggable transceiver 的光电转换损耗。NVIDIA 声称 CPO 方案相比传统方案有 5x 功耗效率提升。
这意味着 AI 工厂的网络正在从"铜缆 + pluggable 光模块"向"硅光集成"迁移。对光模块厂商来说,这是一个需要警惕的结构性变化。
DSX:开源 AI 工厂操作系统
Vera Rubin 是硬件,DSX 是软件。两者合在一起才是完整的 AI 工厂方案。
四个组件
| 组件 | 功能 | 类比 |
|---|---|---|
| DSX MaxLPS | 45°C 液冷 + 机架技术,同功耗多塞 40% GPU | 数据中心的"空间优化" |
| DSX OS | 开源模块化 AI 工厂运营软件 | 数据中心的"操作系统" |
| DSX Sim | 高保真工厂仿真(Cadence/Dassault/PTC/Siemens 合作) | 数据中心的"数字孪生" |
| DSX Flex | 电网响应式功耗调节 | 数据中心的"智能电表" |
DSX OS 的"开源"是一个精明的策略。NVIDIA 不只是在卖硬件,它在定义 AI 工厂的运营标准。如果 DSX OS 成为事实标准,NVIDIA 就不只是芯片供应商,而是 AI 基础设施的平台方——类似 Red Hat 在 Linux 生态中的角色。
"Compute is Revenue"
黄仁勋在 Keynote 上反复强调一个逻辑:
"If you have 1 gigawatt of power, then throughput per watt is revenue. Choosing the wrong architecture just because the chips are cheaper doesn't make sense."
"The more you buy, the more you make."
这两句话背后的逻辑是:在 AI 工厂里,GPU 不是成本中心,而是收入中心。每个 GPU 每小时能产生的 AI 推理 token 数直接对应收入。所以,选更贵但吞吐量更高的架构(Vera Rubin),比选更便宜但吞吐量低的架构更划算。
这个逻辑在推理(Inference)场景下是成立的——推理可以按 token 计费。但在训练场景下是否成立?训练是一次性投入,产出是模型权重,不能按 token 卖。这个论点可能在训练市场上遇到挑战。
DGX Station for Windows:桌边的万亿参数
Keynote 展示的 RTX Spark 产品矩阵中,最高端是 DGX Station for Windows:
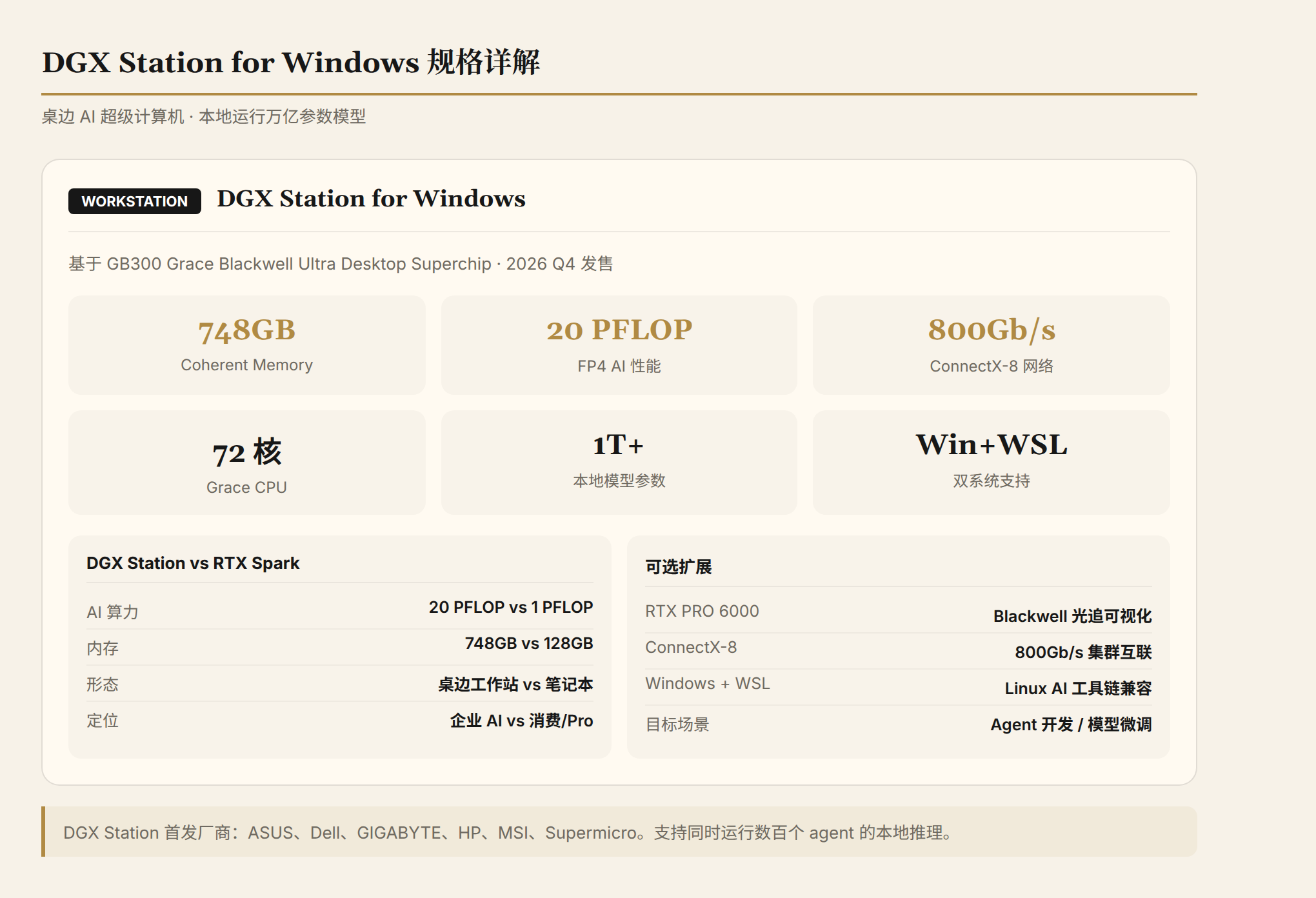
| 参数 | 规格 |
|---|---|
| 芯片 | GB300 Grace Blackwell Ultra Desktop Superchip |
| CPU | 72 核 Grace CPU |
| GPU | Blackwell Ultra GPU |
| 内存 | 最高 748GB coherent memory |
| AI 性能 | 20 PFLOP FP4 |
| 网络 | ConnectX-8 SuperNIC, 800Gb/s |
| 能力 | 本地运行万亿参数模型 |
748GB 内存、20 PFLOP 算力、800Gbps 网络——这不是工作站,这是一台放在桌边的 AI 超级计算机。支持 Windows + WSL,意味着开发者可以在 Windows 环境下使用 Linux AI 工具链。
定价没有公布,但考虑到 GB300 + 748GB 内存 + ConnectX-8 的 BOM,价格很可能在 $15,000-25,000 区间。目标客户是企业 AI 团队和研究机构。
其他发布:从模型到机器人
Nemotron 3 Ultra:550B 开源 MoE
NVIDIA 发布了 Nemotron 3 Ultra——550B 参数的 mixture-of-experts 模型。核心卖点是对标当前领先的开放模型有 5x 推理加速 和约 30% 更低运行成本。
后训练适配了主流 agent 平台:Hermes Agent、LangChain Deep Agents、OpenClaw、OpenHands、OpenCode。CrowdStrike 和 Palantir 已首批采用。
6 月 4 日通过 Hugging Face、ModelScope、OpenRouter 发布。
Cosmos 3:开放物理 AI 基础模型
基于 mixture-of-transformers 架构的物理 AI omnimodel,原生支持 text、image、video、ambient sound、action 多模态。在多个物理 AI benchmark 上排名第一。
三个版本:Cosmos 3 Super(最高精度)、Nano(实时推理)、Edge(边缘端)。
Isaac GR00T:开放人形机器人参考设计
基于 Jetson Thor 平台的完整开源人形机器人参考设计。这是 NVIDIA 第一次提供机器人硬件的完整开源方案。
Agent Toolkit + CUDA-X Agent Skills
黄仁勋定义了 agentic computing pattern:
"An agent that is a model, wrapped in a harness that uses tools with skills and runs in a runtime."
CUDA-X 库(cuDF、cuOpt、AI-Q、NeMo、PhysicsNeMo、CUDA-Q)被包装成 agent skills,在 Claude Code plugin marketplace 和 Hermes Skills Hub 上线。Cadence 联合 NVIDIA 的芯片验证 agent 声称 40x 验证加速。
产业格局:NVIDIA 的三个身份
如果把所有发布放在一起看,NVIDIA 在这场 Keynote 上同时扮演了三个角色:
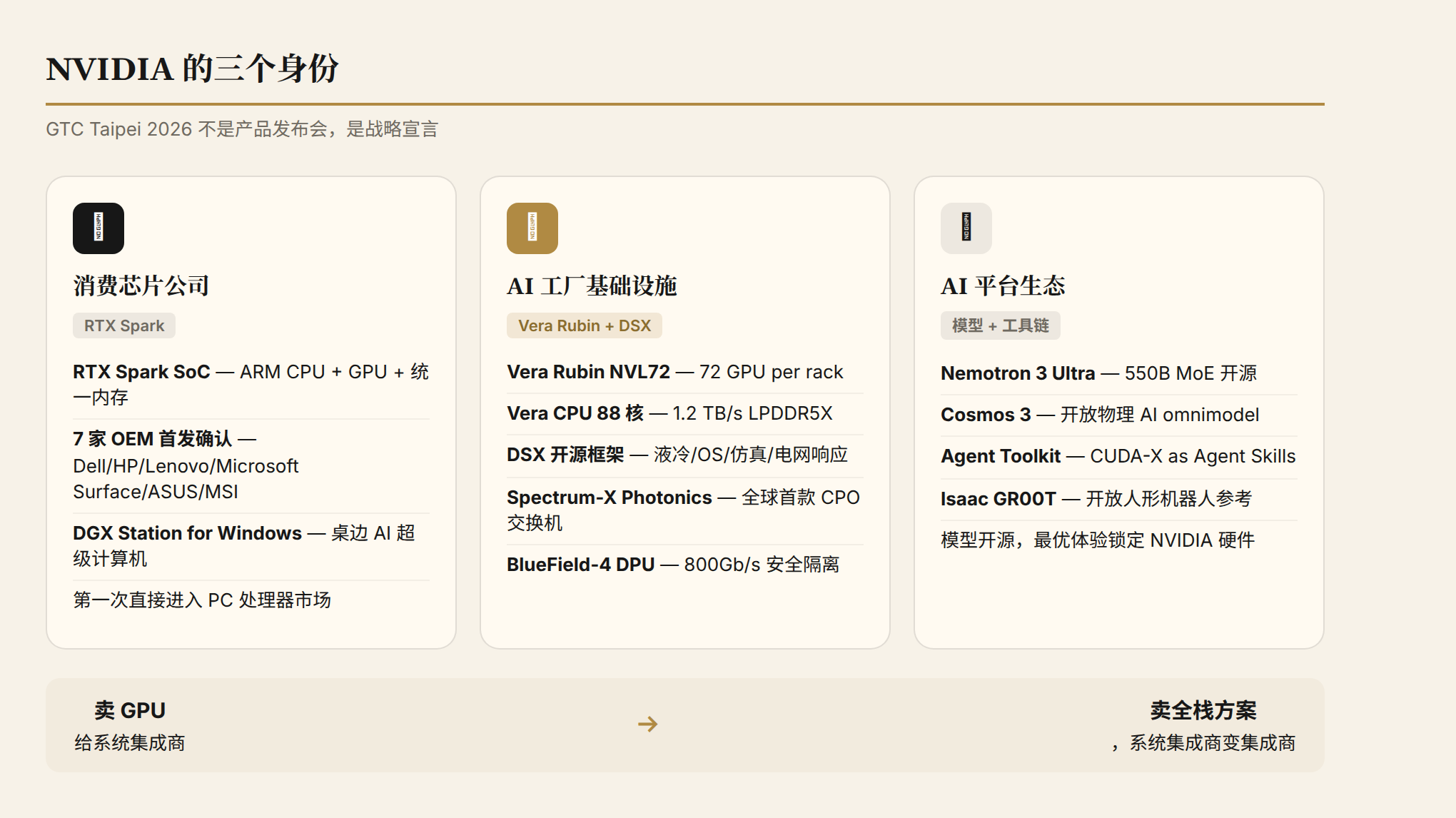
第一,消费芯片公司。 RTX Spark 让 NVIDIA 第一次直接进入 PC 处理器市场。不是卖 GPU 给 PC 厂商,而是卖完整的 SoC。这改变了 NVIDIA 和 Intel/AMD/Qualcomm 的关系——以前是合作伙伴(NVIDIA 卖独立 GPU,Intel 卖 CPU),现在是直接竞争对手。
第二,AI 工厂基础设施公司。 Vera Rubin + DSX + Spectrum-X + BlueField,NVIDIA 提供的不只是 GPU,而是整个 AI 工厂的全栈方案。从芯片到网络到液冷到操作系统到仿真软件。这和传统数据中心供应商(Dell、HPE、Lenovo)的关系也变了——它们从 NVIDIA 的客户变成了 NVIDIA 方案的集成商。
第三,AI 平台生态公司。 Nemotron 3 Ultra、Cosmos 3、Agent Toolkit、CUDA-X Agent Skills——NVIDIA 在构建自己的 AI 生态。模型是开源的,工具链是开放的,但最优体验永远在 NVIDIA 硬件上。这是一个"开放的封闭"策略。
对竞争格局的影响
| 公司 | 受影响程度 | 原因 |
|---|---|---|
| Intel | 🔴 高 | RTX Spark 直接竞争消费端 CPU;Vera CPU 竞争数据中心 CPU;Arc G3 在掌机品类首次有方案但规模远不如 NVIDIA |
| AMD | 🟠 中高 | Zen 6 要到 2027 年才上市,2026 年 NVIDIA 的 ARM PC 方案将占据一整年的窗口期;数据中心 GPU(MI400)需要在下半年证明自己 |
| Qualcomm | 🟡 中 | Snapdragon C 覆盖 $300 低端,和 RTX Spark 不直接竞争;但 ARM PC 市场的定义权可能从 Qualcomm 转向 NVIDIA |
| Apple | 🟡 中 | M 系列在 ARM 笔记本有先发优势,但 CUDA 生态是 Apple Silicon 没有的。AI 开发者和创作者是争夺焦点 |
| 中国 GPU 厂商 | 🔴 高 | Vera Rubin 全面量产 + DSX 标准化,拉大了 AI 基础设施的代差 |
Computex 2026 其他看点
Intel Arc G3:掌机有了专用硅
Intel 发布了 Arc G3 系列,第一次为掌机做了专用芯片:
- Arc G3 Extreme:14 核 Panther Lake + 12 Xe3 核心 + 50 TOPS NPU,Intel 18A 工艺
- 标准版 Arc G3:10 Xe3 核心,性能低 10-20%
- 首发设备:Acer Predator Atlas 8、MSI Claw 8 EX AI+
Intel 18A 是 Intel 最先进的工艺节点。Arc G3 是第一款在 Intel 18A 上制造的消费级游戏芯片。如果这颗芯片的良率和性能达标,对 Intel Foundry 拓展外部客户有信号意义。
AMD:保守的一年
AMD 今年 Computex 的节奏偏保守。Zen 6 "Medusa Point" 已在 Geekbench 出现(10C/20T, 32MB L3),但上市要等 2027 年。今年是 Zen 5 刷新 + Gorgon Halo 移动端过渡。
Biostar 预告了 next-gen AMD 主板,暗示 Zen 6 桌面平台可能比移动更早。iGPU 继续用 RDNA 3.5 而非 RDNA 4,可能暗示 RDNA 5 在 2027 年随 Zen 6 统一推出。
DDR6 + CAMM2
JEDEC 确认 CAMM2 将成为桌面 PC 新标准。DDR6 起步 8.8 Gbps,最高 17.6 Gbps。MSI 在本届 Computex 展出全球首款 CAMM2 DDR5 桌面主板。
32GB LPDDR6 CAMM2 估价约 $500——成本是大规模采用的障碍。但方向已经确定:DIMM 时代正在走向终结。

判断
NVIDIA 的 RTX Spark 能不能成?
大概率能成,但不会一帆风顺。
有利的因素:
- CUDA 生态是杀手级优势。AI 开发者、创作者、研究人员没有替代选择——AMD ROCm 和 Intel oneAPI 在生态成熟度上差了好几年
- Microsoft + 7 家 OEM 的联合站台提供了足够的启动势能
- 128GB 统一内存 + 1 PFLOP 在笔记本形态里没有竞争对手
风险点:
- ARM 上的游戏兼容性。如果 AAA 游戏不能流畅运行,RTX Spark 就被限制在"AI 专业本"的小众市场
- 定价。Blackwell GPU + 128GB 统一内存的 BOM 不低
- ARM PC 已经有过多次"这次不一样"的失败先例(Windows RT、Qualcomm 8cx)
Vera Rubin 对供应链意味着什么?
Vera Rubin 全面量产意味着 2026-2027 年的供应链瓶颈将更严重。HBM4、800G 光模块、CoWoS-L 封装、液冷基础设施的供需缺口会进一步扩大。对相关供应链公司来说,问题是产能能不能跟上,而不是需求够不够。
AI 基础设施的竞争进入"全栈"阶段
以前买 GPU 插到服务器里就行。现在 NVIDIA 卖的是完整的 AI 工厂——芯片、网络、液冷、操作系统、仿真、模型。竞争对手如果不能提供同等完整的方案,就只能做组件供应商。
这对 Dell、HPE、Lenovo 等传统服务器厂商意味着角色转变:从"设计服务器"变成"集成 NVIDIA 方案"。利润空间会被压缩。
下一个观察节点
- Microsoft Build(6 月 2-3 日):Windows agent 开发细节,RTX Spark 的软件支持
- 2026 Fall:RTX Spark 笔记本发售,首批 benchmark 和游戏兼容性测试
- 2026 Q3-Q4:Vera Rubin 首批量产发货,实际性能数据
- 2027 Q1-Q2:AMD Zen 6 上市,ARM PC 竞争格局更清晰
声明: 本文基于 NVIDIA GTC Taipei Keynote(2026 年 6 月 1 日)官方新闻稿及发布会内容,结合 The Verge、Tom's Hardware、XDA Developers、HotHardware、TechRadar、STORDIS、ServeTheHome 等媒体报道进行交叉验证后撰写。不构成投资建议。文中数据截至 2026 年 6 月 1 日。